Blog
Continuamos en esta segunda entrega de la serie de artículos con la aplicación de las especificaciones UNE. Antes de nada, recordemos que las Especificaciones UNE 0077, UNE 0078 y UNE 0079 introducen las buenas prácticas en el gobierno del dato, gestión del dato y gestión de calidad del dato con una aproximación a procesos (véase Fig.1).

Fig. 1. Procesos contenidos en las especificaciones UNE 0077, UNE 0078 y UNE 0079
Anteriormente, hemos analizado la especificación UNE 0077:2023 sobre los procesos del gobierno del dato. En esta ocasión, nos centraremos en la UNE 0079 dedicada a la gestión de la calidad del dato para ilustrar su aplicación en el contexto de datos abiertos. En este sentido, es importante considerar que la calidad de los datos abiertos va más allá de las conocidas características FAIR. Los principios FAIR (por sus siglas en inglés: Findable, Accesible, Interoperable y Reusable) son aspectos específicos de diseño relacionados con la naturaleza de los datos abiertos que, aun cumpliéndose, no garantizan que los datos puedan ser usados para una tarea específica si no tienen el nivel de calidad adecuado.
Para evaluar la calidad de los datos se necesitan criterios objetivos expresados en términos de características o dimensiones de los mismos. Esto permite formular los requisitos de calidad de datos de los distintos usuarios. Se recogen clasificaciones de estos requisitos en publicaciones más genéricas como “Normas Técnicas para alcanzar la Calidad del Dato” (véase Fig.2. con una identificación de estas características de calidad del dato según ISO/IEC 25012) o bien en otras más específicas, como el caso que nos ocupa de los datos abiertos, tales como la Reunión de Sebastopol, o la Carta Internacional de Datos abiertos.
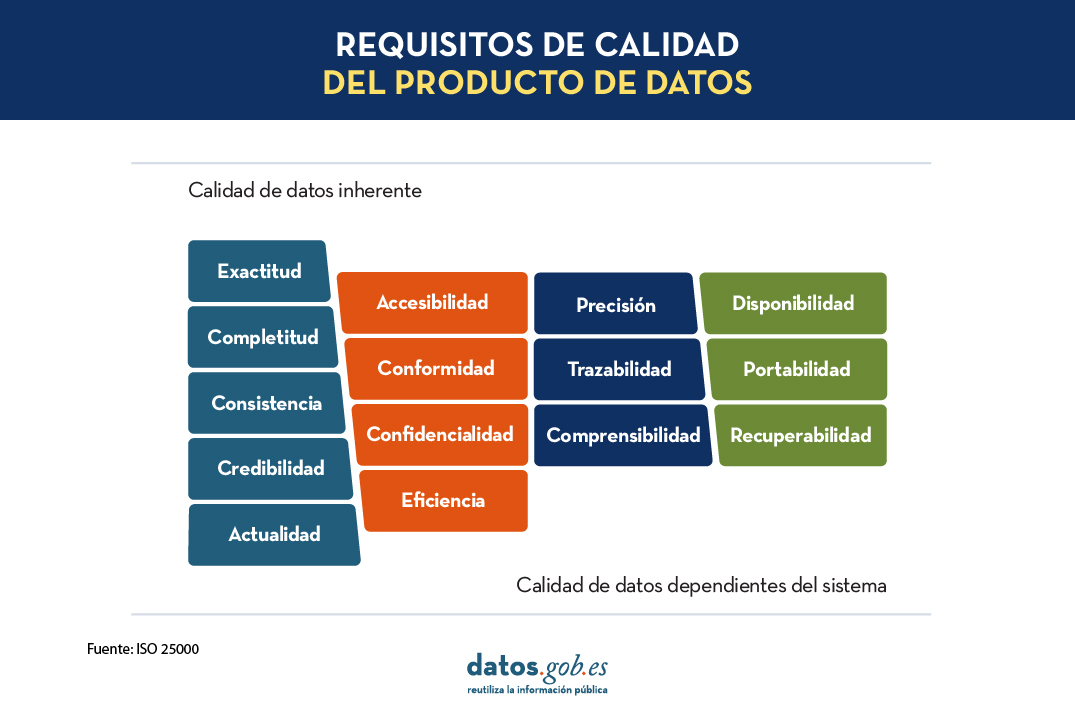
Fig. 2. Características de calidad de datos según ISO/IEC 25012 (de Normas Técnicas para alcanzar la Calidad del Dato)
Es posible que en diferentes foros se den nombre distintos o muy similares a las mismas características, lo que puede provocar malentendidos, o que lleguen a producirse debates entre los partidarios o detractores de un nombre en concreto. Al margen de los nombres, lo más importante es la interpretación de las definiciones de cada característica o dimensión, y sobre todo la definición de cómo medir esa dimensión o característica y entender el significado de las mediciones para poder actuar sobre los datos en caso de que se necesite.
En este segundo artículo se va a describir cómo el personal a cargo del proyecto de datos abiertos del Ayuntamiento de Vistabella ha abordado algunas de las recomendaciones que se especifican en el Manual práctico para mejorar la calidad de los datos abiertos como parte de su estrategia de potenciar la publicación de datos abiertos en los correspondientes portales del Ayuntamiento. Tal y como se señalaba en el artículo sobre la Aplicación de la especificación UNE 0077:2023, este ayuntamiento quiere potenciar la publicación de datos abiertos de transportes públicos urbanos y sobre la organización de eventos culturales del municipio.
En dicho artículo también se señalaba que, uno de los proyectos que forma parte del programa de gobierno de datos para implementar la estrategia, es el de “Planificación, control y mejora de la calidad de los datos abiertos”. Este proyecto vertebra el contenido de este artículo, una vez que los responsables de datos abiertos del Ayuntamiento han comprendido que la calidad de los datos publicados es casi tan importante como la cantidad.
La aplicación de la Especificación UNE 0079 se va a realizar en dos partes de este proyecto:
- Control de la calidad de los datos que se recogen desde las distintas concejalías y agentes asociadas, para lo que se aplicará el proceso de control y monitorización de calidad del dato.
- Producción y publicación de datos con niveles adecuados de calidad, para lo que se usará el proceso de planificación de calidad del dato.
Los otros dos procesos restantes de UNE 0079 (aseguramiento de calidad del dato y mejora de calidad del dato) se quedan fuera de este artículo por simplicidad.
Aplicación del proceso de Control y Monitorización de calidad del dato.
Como se comentó en el artículo anterior, la ejecución exitosa de los procesos de negocio se manifiesta porque se han conseguido los resultados de procesos específicos de cada uno de ellos (véase Figura 3 con los resultados de proceso para el proceso “control y monitorización de calidad del dato). Así, el primer resultado de proceso (RP.01) consiste en identificar los datos cuya calidad debe ser controlada y monitorizada: estos son aquellos datos en bruto que se reciben de las distintas concejalías y empresas públicas de transportes urbanos para crear los correspondientes conjuntos de datos que se pretenden publicar en el portal de datos abiertos.
|
Los resultados de la realización satisfactoria de este proceso son:
Nota: RP es el acrónimo de Resultado de Proceso |
Figura 3. Resultados de proceso del Proceso de Control y Monitorización de calidad del dato
Uno de los problemas más frecuentes con los que se encuentran los gestores de los proyectos de datos abiertos del Ayuntamiento de Vistabella con respecto a los datos de transporte es que para construir los conjuntos de datos que van a ser publicados, los datos en bruto recibidos están muy fragmentados, y no hay un plazo de entrega establecido, siendo éste además imprevisible. Esto provoca que la construcción de dichos conjuntos de datos esté amenazada por una serie de factores que hace que los resultados producidos sean en muchas ocasiones difícilmente aprovechables. Por ello, y como parte del segundo resultado de proceso (RP.02), se ha decidido estudiar el patrón de envíos de los datos en bruto por parte de los agentes colaboradores, así como los niveles de calidad mínimos necesarios para construir conjuntos de datos. Se llegó a la conclusión, consultando el Manual práctico para mejorar la calidad de los datos abiertos de datos.gob.es, de que las características de calidad afectadas eran la consistencia, la completitud, la credibilidad, la disponibilidad y la actualidad de esos datos. Conscientes de esta necesidad, y tomando como punto de partida los resultados de estas conclusiones, se desarrollaron como tercer resultado de proceso (RP.03) mecanismos de medición para esas características de calidad del dato sobre los datos en brutos recibidos desde cada uno de los agentes que se consideran que deben contribuir a elaborar los conjuntos de datos de transporte que el Ayuntamiento quiere publicar.
Además, como parte del cuarto resultado de proceso (RP.04), se establecen y aplican mecanismos para corregir aquellos valores de los datos que no satisfacen los umbrales mínimos de calidad necesarios para considerar que los datos en bruto pueden ser incorporados al proceso de creación de datos de transporte a ser publicados, dejando registros de los cambios proporcionados (como manifestación del quinto resultado de proceso RP.05).
El estudio de estos registros de cambios se utilizará para proponer cambios en la forma en la que los agentes colaboradores del ayuntamiento interactúan con el Ayuntamiento (como manifestación del sexto resultado de proceso RP.06).
Aplicación del proceso de planificación de calidad del dato
Al haberse invertido una cantidad importante de dinero público en la construcción del conjunto de datos, la principal preocupación de los responsables de datos abiertos del Ayuntamiento de Vistabella es asegurar que los conjuntos de datos publicados tengan niveles de calidad suficientes para asegurar que pueden ser usados y reusados. Tal y como se recoge en el proceso de construcción de los conjuntos de datos, es necesario planificar la calidad del conjunto de datos (en algunos entornos a esto lo llaman data quality by design). Conocedores de esta necesidad, desde el Ayuntamiento entienden las ventajas de ejecutar el proceso de planificación de calidad del dato, y de conseguir los correspondientes resultados de procesos (véase Figura 4, con los resultados de proceso del proceso “Planificación de calidad del dato”).
|
Los resultados de la realización satisfactoria de este proceso son:
Nota: RP es el acrónimo de Resultado de Proceso |
Figura 4. Resultados de proceso del Proceso de Planificación de calidad del dato
Para eso, los responsables de la oficina del dato combinan las actividades propias de este proceso con el proceso de producción y publicación de los conjuntos de datos. En este sentido, resulta de gran utilidad el Manual práctico para mejorar la calidad de los datos abiertos que identifica algunos problemas típicos en la publicación de datos abiertos (véase Fig.2) y proporciona recomendaciones para evitar que dichos problemas sucedan. Además, en el manual se identifican las características de calidad afectadas, lo que facilita su incorporación al diseño de los conjuntos de datos. Es muy importante tener en cuenta que algunas de estas recomendaciones afectan directamente a los propios datos (características inherentes de los datos en términos de ISO/IEC 25012), mientras que otras afectan al entorno de los datos (características dependientes del sistema en términos de ISO/IEC 25012). Para una mejor referencia de las características de calidad de datos, véase Fig.2.
Exploremos algunos ejemplos.
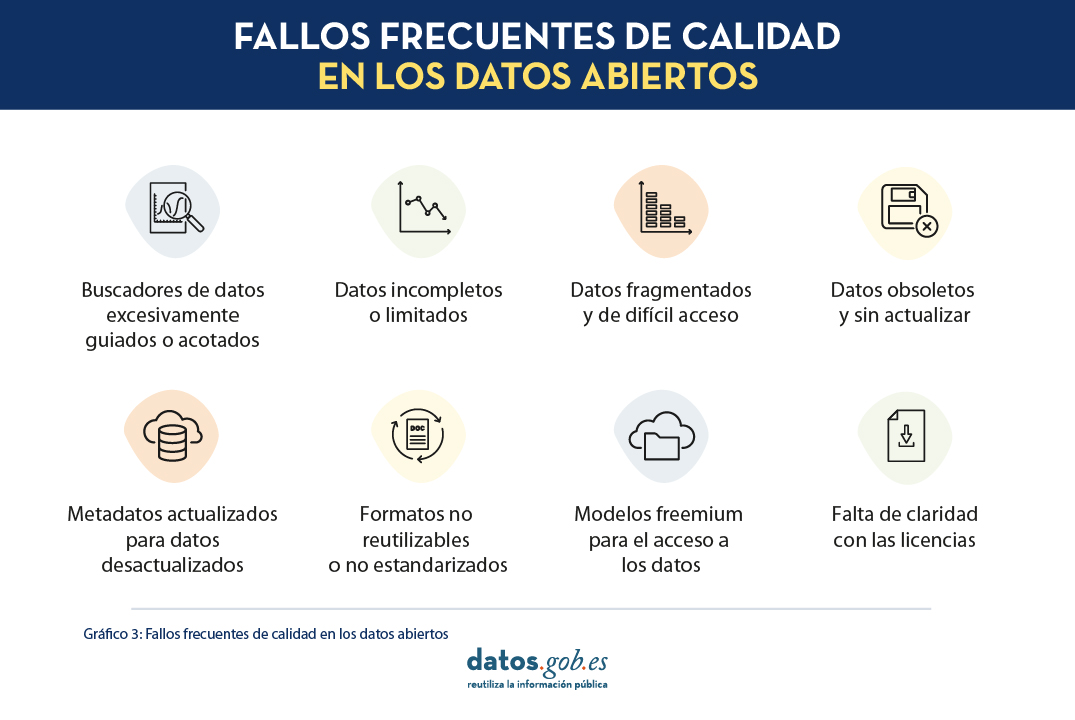
Fig. 5. Fallos frecuentes de calidad en los datos abiertos. Fuente: Manual práctico para mejorar la calidad de los datos abiertos
Uno de los problemas que los responsables de la Oficina del Dato del Ayuntamiento de Vistabella están más interesados en evitar es la publicación de datos incompletos o limitados (que afectan a las características de completitud, disponibilidad, actualidad, credibilidad y precisión) y la publicación de datos obsoletos y sin actualizar (que afecta a las características de disponibilidad, completitud y actualidad). El mismo manual nos está ayudando a completar el primer resultado de proceso (RP.01), ya que nos ha permitido identificar los requisitos de calidad del dato, expresado en esta ocasión en términos de las características de calidad mencionadas anteriormente. Además, teniendo en cuenta los problemas típicos relacionados con el uso de datos de transportes por distintos agentes consumidores de datos, las dos características que los responsables del servicio de publicación de datos abiertos del Ayuntamiento quieren priorizar son las de completitud y actualidad.
En este sentido, y como forma de abordar el segundo resultado de proceso RP.02, se pueden explorar las recomendaciones que hace el Manual práctico para mejorar la calidad de los datos abiertos. Este manual propone desarrollar un plan de publicación de datos en el que se incorporarán, por un lado, un inventario y catálogo de los datos que formarán parte del proceso de producción del conjunto de datos de transporte de los datos a publicar (para asegurar la completitud) y, por otro lado, se generará un plan de publicaciones que incluirá tanto los momentos de recogida de los datos desde los agentes colaboradores del ayuntamiento, como los momentos en que se deben publicar los datos de transportes resultantes de la integración de los diferentes conjuntos de datos (como forma de asegurar la actualidad).
Tanto los catálogos como los planes de publicación serán implementados y puestos en práctica como parte de los proyectos (se sustentarán en los procesos de gestión de datos que se abordarán en el tercer y último artículo de esta serie) y se establecerán mecanismos para monitorizar el desempeño de estas acciones (como parte del tercer resultado de proceso RP.03).
Por último, y como manifestación del RP.04, se abordarán qué problemas no se han cubierto adecuadamente con las acciones previstas, de modo que se puedan iterar nuevamente sobre el diseño del proceso de producción de los conjuntos de datos y desarrollar los mecanismos necesarios que eviten la aparición de problemas derivados de niveles inadecuados de calidad de datos que malogren su uso en diferentes aplicaciones.
Y con este pequeño extracto sobre cómo los responsables del Ayuntamiento de Vistabella aplican la especificación UNE 0079 en combinación con el Manual práctico para mejorar la calidad de los datos abiertos para abordar los problemas potenciales de calidad de datos llegamos al final de este segundo artículo.
En el tercer artículo de la serie se abordará cómo usar la especificación 0078, correspondiente a la gestión de los datos para implementar los proyectos derivados de la estrategia del dato.
El contenido de esta guía puede visualizarse de forma libre y gratuita desde el portal de AENOR a través del enlace que figura a continuación accediendo al apartado de compra y marcando “lectura” en el desplegable en el que aparece preseleccionado “pdf”. El acceso a esta familia de especificaciones UNE del dato está patrocinado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, Dirección General del Dato. Aunque la visualización requiere registro previo, se aplica un descuento del 100% sobre el total del precio que se aplica en el momento de finalizar la compra. Tras finalizar la compra se podrá acceder a la norma o normas seleccionadas desde el área de cliente en el apartado mis productos.
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM y Dr. Fernando Gualo PhD en Ciencia computacional y Chief Executive Officer and Data Quality and Data Governance Consultant
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de sus autores.
Blog
La principal motivación de este primer artículo -de una serie de tres- es explicar cómo usar la especificación UNE 0077 de gobierno del dato (véase Fig.1), para establecer mecanismos aprobados y validados que den soporte organizacional a los aspectos relacionados con la apertura y publicación de datos, para su posterior uso por la ciudadanía y otras organizaciones.
Para entender la necesidad y utilidad del gobierno del dato, debe tenerse en cuenta que, como premisa, toda organización debería partir de una estrategia organizacional. Para ilustrar mejor el artículo consideremos el ejemplo del ayuntamiento de una localidad imaginaria llamada Vistabella. Supongamos que la estrategia organizacional del Ayuntamiento de Vistabella es maximizar la transparencia y calidad de los servicios públicos, reutilizando la información del servicio público.

Fig. 1. Procesos contenidos en las especificaciones UNE 0077, UNE 0078 y UNE 0079
Para dar soporte a esta estrategia organizacional, el Ayuntamiento de Vistabella necesita una estrategia del dato, cuyo objetivo principal es potenciar la publicación de datos abiertos en los correspondientes portales de datos abiertos y fomentar su reutilización para ofrecer a sus vecinos datos de calidad de manera transparente y responsable. El alcalde del Ayuntamiento de Vistabella debe lanzar un programa de gobierno del dato que permita conseguir este objetivo principal. Para ello, encarga a un grupo de trabajo formado por técnicos especializados en datos abierto del Ayuntamiento que aborden dicho programa. A este grupo de técnicos se les dota de la autoridad necesaria, de un presupuesto y se les asigna una serie de responsabilidades.
A la hora de comenzar, estos técnicos deciden seguir la aproximación a procesos propuesta en UNE 0077, ya que les proporciona una guía adecuada para ejecutar las acciones necesarias de gobierno del dato, identificando cuáles deben ser los resultados de proceso de cada uno de los procesos, y cómo estos pueden materializarse en determinados artefactos o productos de trabajo.
En este artículo se explica cómo los técnicos han usado los procesos de la especificación UNE 0077 para conseguir su objetivo. De los cinco procesos que se detallan en la especificación, nos centraremos a modo de ejemplo sólo en tres de ellos: el que describe cómo establecer la estrategia del dato, el que describe cómo establecer políticas y buenas prácticas y el que describe cómo establecer estructuras organizativas.
Antes de comenzar es preciso recordar la estructura que tiene la descripción de los procesos en las diferentes especificaciones UNE 0077, UNE 0078, y UNE 0079. Todos los procesos están descritos mediante un propósito, un listado de los resultados esperados del proceso (es decir qué se espera conseguir cuando se ejecuta el proceso), una serie de tareas que se pueden seguir, y una serie de artefactos o productos de trabajo que son la manifestación de los resultados del proceso.
Proceso “Establecimiento de la estrategia del dato”
El grupo de técnicos del Ayuntamiento de Vistabella decidió seguir cada una de las tareas propuestas en la especificación UNE 0077 para este proceso. A continuación, se muestran algunos aspectos de la ejecución de dichas tareas:
T1. Evaluar capacidades, desempeño y madurez del Ayuntamiento para la publicación de datos abiertos. Para ello, el grupo de trabajo recopiló toda la información posible sobre las habilidades, competencias y experiencias en publicación de datos abiertos que ya tenía el Ayuntamiento de Vistabella; también recopiló información sobre las descargas que se han hecho hasta ahora de datos publicados, así como una descripción de los propios datos y los diferentes formatos en que se han publicado. También se analizó el entorno del Ayuntamiento para conocer la forma de trabajo con los datos abiertos. El producto de trabajo generado fue un Informe de evaluación de las capacidades, desempeño y madurez de datos de la organización.
T2. Elaborar y comunicar la estrategia del dato. Dada su importancia, para elaborar la estrategia del dato, el grupo de trabajo tomó como referencia el Plan de medidas de impulso de la apertura y reutilización de datos abiertos para moldear la estrategia del dato enunciada anteriormente sobre “potenciar la publicación de datos abiertos en los correspondientes portales de datos abiertos y fomentar su reutilización para ofrecer a sus vecinos datos de calidad de manera transparente y responsable”. Además, es importante tener en cuenta que los proyectos de apertura de datos serán planteados para terminar formando parte de los servicios estructurales del Ayuntamiento de Vistabella. Los productos de trabajo generados serán: la estrategia del Dato propiamente adaptada y un plan de comunicación concreto de dicha estrategia.
T3. Identificar qué datos deben ser gobernados de acuerdo con la estrategia del dato. El Ayuntamiento de Vistabella ha decidido que va a publicar más datos sobre los medios de transportes públicos urbanos y sobre la organización de eventos culturales del municipio, por tanto, estos son los datos que deben ser gobernados. Esto incluiría datos de distinta naturaleza: datos estadísticos, datos geoespaciales y algunos datos financieros. Para ello se propone utilizar nuevamente el Plan de medidas de impulso de la apertura y reutilización de datos abiertos. El producto del trabajo será un listado de los datos que deben ser gobernados, y en este caso también publicados en la plataforma. Más adelante, se les pedirá a los técnicos que lleguen a un acuerdo sobre el significado de los datos y que elijan los metadatos más representativos para describir las diferentes características de negocio, técnicas y/u operativas.
T4. Elaborar la cartera (portfolio) de programas y proyectos de datos. Para conseguir el objetivo específico de la estrategia del dato, se identifican una serie de proyectos concretos relacionados entre sí y se determina si son viables. El producto de trabajo generado mediante esta tarea será una cartera de proyectos que cubra estos objetivos:
- Planificación, control y mejora de calidad de datos abiertos
- Aseguramiento del cumplimiento de estándares de seguridad
- Despliegue de mecanismos de control para la intermediación de datos
- Gestión de la configuración de los datos publicados en el portal
T5. Monitorizar el grado de cumplimiento de la estrategia del dato. Para ello, el grupo de trabajo define una serie de indicadores clave de rendimiento que son medidos periódicamente para monitorizar aspectos claves relacionados con la calidad de los datos abiertos, con el cumplimiento de estándares de seguridad, con el uso de los mecanismos de intermediación de datos y con la gestión de cambios a los datos publicados en el portal. El producto de trabajo generado consta de informes periódicos sobre el seguimiento de la estrategia del dato.
Proceso de “Establecimiento de políticas, buenas prácticas y procedimientos del dato”
La estrategia del dato se instrumenta a través de una serie de políticas, buenas prácticas y procedimientos. Para determinar estás políticas o procedimientos, se puede seguir el proceso de Establecimiento de políticas, buenas prácticas y procedimientos del dato detallado en la UNE 0077. Para cada uno de los datos identificados en el proceso anterior, puede ser preciso definir una y otra vez políticas específicas por cada área de actuación descrita en la estrategia del dato establecida. Para tener una forma de actuación sistemática y consistente y para evitar errores, el grupo de trabajo del Ayuntamiento de Vistabella decide modelar y publicar un proceso propio de definición de estrategias basado en la definición genérica de dicho proceso contenido en Especificación UNE 0077, y particularizado de acuerdo con las características propias del Ayuntamiento de Vistabella. Este proceso podría ya ser seguido por el grupo de trabajo cuantas veces hiciera falta para definir y aprobar las políticas, buenas prácticas y procedimientos del dato.
En cualquier caso, resulta importante para la particularización de este proceso, la identificación y selección de los principios, estándares, aspectos éticos y legislación vigente relacionada en este caso con los datos abiertos. Para ello, se define un marco de trabajo formado por un marco regulatorio y un marco de estándares.
El marco regulatorio incluye:
- El marco legal relacionado con la reutilización de información del sector público.
- El Reglamento General de Protección de Datos (RGPD) para asegurar que se cumplen los mínimos en cuanto a seguridad y privacidad de la información a la hora de publicar los datos abiertos en el portal.
El marco de estándares incluye entre otros:
- La guía práctica para la mejora de calidad de datos abiertos, que proporciona soporte para asegurar que los datos compartidos son de calidad.
- Las propias especificaciones UNE 0077,0078, y 0079 que contienen las buenas prácticas de gobierno, gestión y calidad de datos.
Este marco de trabajo junto con el proceso definido, será usado por el grupo de trabajo para elaborar las políticas del dato específicas que deberán ser comunicadas mediante la publicación correspondiente, teniendo en cuenta las herramientas jurídicas más apropiadas de las que disponen. Algunas de estas políticas, se podrán publicar por ejemplo como resoluciones o bandos municipales, cumpliendo con la legislación vigente a nivel regional o nacional.
Proceso “Establecimiento de estructuras organizativas para el gobierno, gestión y uso del dato”
Aunque el Grupo de Trabajo establecido sea el que esté haciendo los esfuerzos iniciales para abordar la estrategia, es necesario crear una estructura organizativa que se encargue de coordinar los trabajos necesarios relacionados con el gobierno, gestión y gestión de la calidad de los datos abiertos. Para ello se seguirá el proceso correspondiente detallado en la UNE 0077. Al igual que en el primer apartado, se aborda la explicación con la estructura de las tareas a desarrollar:
T1. Definir una estructura organizativa para el gobierno, gestión y uso del dato. Es interesante visualizar el Ayuntamiento de Vistabella como un conjunto federado de concejalías y otros servicios municipales, que podría compartir una forma común de trabajar, aunque cada uno con la independencia necesaria para poder definir y publicar sus datos abiertos. Recordemos que inicialmente estos datos eran los correspondientes a transportes y eventos culturales. Esto implica la identificación de roles unipersonales y colectivos, de cadenas de responsabilidades y rendición de cuentas, así como la definición de una forma de comunicarse entre ellas. El principal producto del trabajo será una estructura organizativa para dar soporte a las distintas actividades. Estas estructuras organizativas tienen que ser compatibles con las estructuras de roles funcionales que ya existen en el Ayuntamiento. En este sentido, puede citarse y a modo de ejemplo, la unidad responsable de información, cuya figura viene recogida en la Ley 37/2007, como uno de los roles más importantes. La unidad responsable de información tiene fundamentalmente las siguientes cuatro funciones:
- Coordinar las actividades de reutilización de la información con las políticas existentes en materia de publicaciones, información administrativa y administración electrónica.
- Facilitar la información sobre los órganos competentes, dentro de su ámbito, para la recepción, tramitación y resolución de las solicitudes de reutilización que se transmiten.
- Promover que la información sea provista en los formatos adecuados y esté actualizada en la medida de lo posible.
- Coordinar y fomentar las actividades de promoción, concienciación y formación.
T2. Establecer las habilidades y conocimientos necesarios. Para cada una de las funciones mencionadas anteriormente de las unidades responsables de información, será necesario identificar qué habilidades y conocimiento son necesarios para poder gestionar y publicar los datos abiertos de los que son responsables. Es importante tener en cuenta que los conocimientos y habilidades deben ser tanto técnicos en el ámbito de la publicación de datos abiertos, como específicos del dominio de los datos que se están abriendo. Todos estos conocimientos y habilidades deberían estar convenientemente reconocidos y listados. Más adelante, se le podrá pedir a un grupo de trabajo que se encargue de diseñar planes de formación para garantizar que las personas implicadas en las unidades responsables de información cuentan con dichos conocimientos y habilidades.
T3. Monitorizar el desempeño de las estructuras organizativas. A fin de poder cuantificar el desempeño de las estructuras organizativas, será necesario definir y medir una serie de indicadores que permitan modelar diferentes aspectos del trabajo de las personas incluidas en las estructuras organizativas. Esto puede incluir aspectos tales como la eficiencia y eficacia de su trabajo o su capacidad de resolver problemas.
Llegamos al final de este primer artículo en el que se han descrito algunos aspectos sobre cómo utilizar tres de los cinco procesos de la especificación UNE 0077:2023 para perfilar cómo debería ser el gobierno de los datos abiertos usando para ello un ejemplo de un Ayuntamiento de una ciudad imaginaria llamada Vistabella que tiene interés en publicar datos abiertos de transportes urbanos y eventos culturales.
El contenido de esta guía puede descargarse de forma libre y gratuita desde el portal de AENOR a través del enlace que figura a continuación accediendo al apartado de compra. El acceso a esta familia de especificaciones UNE del dato está patrocinado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, Dirección General del Dato. Aunque la descarga requiere registro previo, se aplica un descuento del 100% sobre el total del precio que se aplica en el momento de finalizar la compra. Tras finalizar la compra se podrá acceder a la norma o normas seleccionadas desde el área de cliente en el apartado mis productos.
https://tienda.aenor.com/norma-une-especificacion-une-0077-2023-n0071116
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM y Dr. Fernando Gualo PhD en Ciencia computacional, Chief Executive Officer and Data Quality and Data Governance Consultant. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Motivación
Hoy en día, en un entorno en constante cambio y en el que la generación de datos está creciendo de forma exponencial, es necesario establecer procesos comunes a lo largo del ciclo de vida de los activos de datos de toda organización. Disponer de datos bien gobernados, gestionados y con niveles adecuados de calidad se convierte en una necesidad para todo tipo de instituciones, siendo necesaria una metodología de evaluación común que pueda ayudar a una mejora continua de dichos procesos y permita evaluar la madurez de una organización de forma estandarizada.
El desarrollo de un marco homogéneo de evaluación de la madurez para una organización, con relación al tratamiento que hace de los datos, brinda la oportunidad de analizar detalladamente los procedimientos internos que realiza, identificando debilidades asociadas a esos procedimientos y permitiendo establecer planes de acción para su optimización y mejora. Al fortalecer estos procesos internos se garantiza una mayor confiabilidad y calidad de los datos, lo que también redunda en una mayor y más fácil participación en los nuevos mercados de datos, habilitando estos la comercialización y compartición de datos con soberanía, confianza y seguridad. Este innovador paradigma favorece la colaboración entre organizaciones, aprovechando sus sinergias, y generando además un desarrollo de entornos empresariales más eficientes y de mayor innovación.
El mencionado proceso de evaluación se podrá llevar a cabo de forma estandarizada gracias al desarrollo y publicación de la nueva especificación UNE 0080, y debe considerarse como un proceso de mejora continua. A lo largo de ese camino, entidades reconocidas e independientes podrán emitir certificaciones que validen que una organización cumple con ciertos estándares y requisitos establecidos, de tal forma que una organización pueda demostrar su compromiso y excelencia con los estándares, lo cual servirá para lograr un buen posicionamiento en el competitivo mercado de la economía del dato.
Especificaciones UNE – Guía de Evaluación del Gobierno, Gestión y Gestión de la Calidad del Dato
La Oficina del Dato ha patrocinado, promovido y participado en la generación de la especificación nacional UNE 0080:2023, con la que dar respuesta a la necesidad de contar con una guía de evaluación de procesos basada en estándares internacionales, con la que organizaciones tanto públicas como privadas, puedan evaluar de forma sistemática el estado actual o grado de consecución de sus procesos de trabajo en materia de gobierno, gestión y gestión de calidad del dato en base a la definición dada para esos procesos en las especificaciones UNE de Gobierno del dato UNE 0077:2023, Gestión del dato UNE 0078:2023, y Gestión de la calidad del dato UNE 0079:2023. Esta nueva especificación se encuentra dirigida a los responsables de implantar y supervisar los procesos de gobierno, gestión y calidad del dato en sus respectivas organizaciones, de tal forma que aseguren su buen funcionamiento o, en caso de que sea necesario, sean capaz de mejorarlos, así como a los consultores y auditores que necesiten llevar a cabo una evaluación de dichos procesos.
El modelo de evaluación de los procesos desarrollado en la guía está basado en la familia de normas internacionales ISO/IEC 33000, mientras que el modelo de madurez de la organización asociado a esa evaluación de los procesos está basado en el Modelo Alarcos de Madurez de Datos (MAMD) según las normas ISO 8000.
En la siguiente figura se pueden ver los 22 procesos definidos en las especificaciones UNE (0077, 0078 y 0079) distribuidos por los diferentes niveles de madurez organizacional con los que están relacionados. Es importante matizar que en esta figura no se muestran los niveles de capacidad de cada proceso, los cuales se desarrollan a continuación.

Modelo de Evaluación de procesos
El modelo de evaluación de procesos establece que cada uno de los 22 procesos definidos en las diferentes especificaciones (5 de Gobierno, 13 de gestión y 4 de gestión de la calidad) tienen distintos niveles de capacidad o grados de mejora, siendo el nivel 0 el más básico (no implementado) y el nivel 5 el más avanzado (innovado).

Cada nivel de capacidad de un proceso lleva asociados unos atributos de proceso (o requisitos) que es necesario cumplir para alcanzar dicho nivel de capacidad, siendo necesario no sólo cumplir los atributos de proceso del nivel a alcanzar, sino también los relativos a niveles inferiores. Los atributos de proceso por nivel de capacidad son los siguientes:

En la guía de evaluación se detallan exactamente qué requisitos son necesarios satisfacer para dar por cumplido cada atributo de proceso, así como sus métricas de evaluación para concluir si un atributo de proceso está No implementado (N), Parcialmente implementado (P), Ampliamente implementado (A) o Totalmente implementado (T). Por tanto, si por ejemplo queremos afirmar que un determinado proceso de nuestra organización está a un nivel de capacidad “Nivel 2 - Proceso Gestionado”, los atributos del proceso relativos al nivel 1 deben de estar Totalmente implementados (T) y los relativos al nivel 2 al menos Ampliamente implementados (A) o Totalmente implementados (T).
Modelo de Evaluación de madurez de la organización
La guía propone que para determinar el nivel de madurez de la organización en conjunto, será necesario no sólo que ésta realice los procesos propios de cada nivel, tal y como se muestra en la figura anterior, sino que estos también alcancen el nivel de capacidad acorde al nivel de madurez contra el que se evalúa.
Pongamos un ejemplo: si una organización quiere evaluar y acreditar que cumple con el nivel 2 de madurez organizacional “Gestionado”, necesita realizar al menos todos los procesos relativos al nivel de madurez 1 (2 procesos) y al nivel 2 (7 procesos), y que estos además estén desarrollados a un nivel de capacidad mínimo de grado 2 (proceso gestionado) mediante la certificación de sus respectivos atributos de proceso (‘totalmente implementado’ los atributos de procesos del nivel de capacidad 1 y ‘ampliamente implementados’ o ‘totalmente implementados’ los atributos de procesos relativos al nivel 2). Así, tal y como se muestra en la Figura 4 resumen de la evaluación de madurez organizacional, puede observarse como todos los procesos relativos al nivel gestionado han sido evaluados en cuanto a su capacidad como implementados al menos ampliamente.

En resumen, gracias al desarrollo de esta especificación o guía, las organizaciones van a disponer de una herramienta estandarizada para ser capaces de autoevaluar sus procesos en torno al gobierno del dato, gestión del dato, y gestión de la calidad del dato. Además, resulta también posible que puedan ser evaluadas por entidades externas certificadoras en última instancia, que acrediten no sólo la madurez organizacional, sino también una calidad del dato mínima, para escenarios en que éste vaya a ser compartido con otros participantes del ecosistema.
El contenido de esta guía, así como del resto de especificaciones UNE mencionadas, puede visualizarse de forma libre y gratuita desde el portal de AENOR a través del enlace que figura a continuación accediendo al apartado de compra y marcando “lectura” en el desplegable en el que aparece preseleccionado “pdf”. El acceso a esta familia de especificaciones UNE del dato está patrocinado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, Dirección General del Dato. Aunque la visualización requiere registro previo, se aplica un descuento del 100% sobre el total del precio que se aplica en el momento de finalizar la compra. Tras finalizar la compra se podrá acceder a la norma o normas seleccionadas desde el área de cliente en el apartado mis productos.
- ESPECIFICACION UNE 0077:2023
- ESPECIFICACION UNE 0078:2023
- ESPECIFICACION UNE 0079:2023
- ESPECIFICACION UNE 0080:2023
En el siguiente vídeo se presenta un resumen de las mencionadas guías.
Blog
Con el avance que la tecnología y la conectividad han venido experimentando durante los últimos años hemos entrado de lleno en una nueva era en la que los datos nunca duermen y la cantidad de datos circulando es mayor que nunca. En la actualidad, podríamos decir que vivimos encerrados en una esfera rodeados de datos y eso nos ha ido haciendo cada vez más dependientes de ellos. Por otro lado, nos hemos ido también transformando poco a poco en seres tanto productores como recolectores de datos.
El término datasfera se ha venido utilizado históricamente para definir el conjunto de toda la información existente en los espacios digitales, incluyendo también otros conceptos relacionados como los flujos de datos y las plataformas implicadas. Pero este concepto ha ido desarrollándose y cobrando cada vez más relevancia de forma paralela al creciente peso de los datos en nuestra sociedad actual, convirtiéndose en un concepto importante a la hora de definir el futuro de las relaciones entre tecnología y sociedad.
En los inicios de la era digital podíamos considerar que vivíamos en nuestras propias burbujas de datos que íbamos alimentando poco a poco a lo largo de nuestras vidas hasta acabar totalmente inmersos en los datos del mundo online, donde la distinción entre lo real y lo virtual es cada vez más irrelevante. Hoy en día vivimos en una sociedad interconectada a través de los datos y también mediante algoritmos que nos unen y establecen relaciones entre nosotros. Todos aquellos datos que compartimos de forma más o menos consciente ya no nos afectan únicamente a nosotros mismos como individuos, sino que pueden tener también su efecto en el resto de la sociedad, incluso de forma a veces totalmente imprevisible – como en una versión digital del efecto mariposa.
Por tanto, los modelos de gobernanza que se basen en trabajar con los datos y su relación con las personas, como si se tratasen simplemente de instancias aisladas con las que podemos trabajar individualmente, ya no nos serán de utilidad en este nuevo entorno.
La necesidad de una aproximación a los datos basada en sistemas
En la actualidad, ese concepto relativamente simple de la dataesfera ha ido evolucionando hasta convertirse en un ecosistema digital completo, altamente interconectado y complejo – compuesto por una amplia gama de datos y tecnologías – que nosotros habitamos y que afecta a la forma en la que vivimos nuestras vidas. Es un sistema en el que los datos tienen valor solo en el contexto de su relación con otros datos, con las personas y con las normas que regulan esas relaciones.
Por lo tanto, para una gestión eficaz de este nuevo ecosistema, será necesaria una mejor comprensión de cómo los diferentes componentes de la dataesfera se relacionan entre sí, de cómo los datos fluyen a través de estos componentes y de cuáles serán las normas adecuadas necesarias para que este sistema interconectado funcione.
Los datos como componente activo del sistema
En una aproximación basada en sistemas, los datos se consideran un componente activo dentro del ecosistema. Esto significa que los datos ya no son sólo información estática, sino que también tienen la capacidad de influir en el funcionamiento del propio ecosistema y, por tanto, serán un componente más a tener en cuenta para la gestión eficaz del mismo.
Por ejemplo, los datos pueden utilizarse para ajustar el funcionamiento de los algoritmos, mejorando la precisión y la eficiencia de los sistemas de inteligencia artificial y de aprendizaje automático. De forma similar, también podrían utilizarse para ajustar la forma en que se toman decisiones y se aplican políticas en diferentes sectores, como la atención médica, la educación y la seguridad.
La dataesfera y la evolución del gobierno de los datos
Por lo tanto, será necesario explorar nuevos marcos colectivos de gobernanza de datos que tengan en consideración a todos los elementos del ecosistema en su diseño, controlando la forma en que se accede, se utiliza y se protege la información en el conjunto de la dataesfera.
Así se podría garantizar que los datos sean utilizados de manera segura, ética y responsable para el conjunto del ecosistema y no sólo en casos individuales o aislados. Por ejemplo, algunas de las nuevas herramientas de gobernanza de datos que hace ya tiempo que se están experimentando y nos pueden servir a la hora de gestionar la dataesfera de forma colectiva son los data commons o bienes digitales de datos, los data trusts o fideicomisos de datos, las cooperativas de datos, o los data collaboratives o colaboraciones de datos, entre otros.
El futuro de la dataesfera
La dataesfera seguirá creciendo y evolucionando en los próximos años, impulsada una vez más por los nuevos avances tecnológicos y el aumento de la conectividad y la ubicuidad de los sistemas. Será importante que los gobiernos y las organizaciones se mantengan al día de estos cambios y adapten sus estrategias de gobierno y gestión de datos en consecuencia mediante marcos regulatorios sólidos, acompañados de pautas éticas y prácticas responsables que aseguren que los beneficios que nos prometen la explotación de los datos se puedan finalmente materializar al mismo tiempo que se minimizan los riesgos.
Para poder atender adecuadamente estos desafíos, y aprovechar así todo el potencial de la dataesfera para un cambio positivo y por el bien común, será esencial dejar de pensar en los datos como algo que podamos tratar de forma aislada y adoptar un enfoque basado en sistemas que reconozca la naturaleza interconectada de los datos y su impacto en el conjunto de la sociedad.
Hoy en día, podríamos considerar que los espacios comunes de datos (data spaces), que la Comisión Europea lleva ya algún tiempo desarrollando como parte clave de su nueva estrategia de datos, son precisamente una evolución lógica del concepto de la dataesfera adaptada a las necesidades particulares de nuestro tiempo y actuando sobre todos los componentes del ecosistema simultáneamente: técnico, funcional, operacional, legal y de negocio.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La ‘Estrategia europea de datos’ de la Comisión Europea establece que es clave la creación de un mercado único de datos compartidos. En dicha estrategia, la Comisión se ha marcado como uno de sus principales objetivos el impulso de una economía del dato acorde a los valores europeos de autodeterminación en la compartición de datos (soberanía), confidencialidad, transparencia, seguridad y competencia justa.
Los espacios de datos comunes a nivel europeo son un recurso fundamental en la estrategia de datos porque actúan como habilitadores del impulso de la economía del dato. De hecho, poner en común los datos europeos de sectores clave, fomentar la circulación de los datos y crear espacios de datos colectivos e interoperables son acciones que contribuyen al beneficio de la sociedad.
Aunque los entornos de compartición de datos existen desde hace tiempo, se plantea la creación de espacios de datos que garanticen los valores y principios de la UE. Desarrollar iniciativas legislativas que los habiliten no solo es un reto tecnológico, sino también de coordinación entre los participantes, de gobernanza, de adopción de estándares y de interoperabilidad.
Para abordar un desafío de tal magnitud, la Comisión tiene previsto invertir cerca de 8.000 millones de euros hasta 2027 en el despliegue de la transformación digital europea. Como parte del proyecto se incluye el fomento de infraestructuras, herramientas, arquitecturas y mecanismos para compartir datos. Para que triunfe esta estrategia es necesario que, desde el cumplimiento de los valores europeos, se plantee un paradigma de espacio de datos que tenga calado en la industria. Este paradigma de espacio de datos actuará como un estándar tecnológico de facto y permitirá que avance la concienciación social sobre las posibilidades del dato, algo que posibilitará el retorno económico de las inversiones requeridas para crearlo.
Con el fin de hacer realidad el paradigma de espacios de datos, desde la convergencia de las actuales iniciativas, la Comisión Europea ha apostado por el desarrollo del proyecto Simpl.
¿En qué consiste exactamente Simpl?
Simpl es un proyecto financiado por el programa Digital Europe de la Comisión Europea, dotado con 150 millones de euros y con un plazo de ejecución de tres años. Su objetivo es poner a disposición de la sociedad un software (middleware) para la construcción de ecosistemas de datos y servicios de infraestructuras en la nube que soporten los valores europeos de soberanía el dato, privacidad y mercado justo.
El proyecto Simpl consiste en la entrega de 3 productos:
- Simpl-Open: Middleware propiamente dicho. Se trata de una solución de software para crear ecosistemas de servicios de datos (compartición de datos y aplicaciones) y servicios de infraestructura en la nube (IaaS, PaaS, SaaS, etc). Este software debe incluir agentes que habiliten la conexión al espacio de datos, servicios operacionales y servicios de intermediación (catálogo, vocabulario, registro de actividad, etc). El resultado deberá entregarse bajo licencia de fuentes abiertas y se intentará construir una comunidad open source que garantice su evolución.
- Simpl-Labs: Infraestructura para crear entornos de trabajo de pruebas (test bed) para que los usuarios interesados pueden probar la última versión del software en la modalidad de autoservicio. Este entorno está pensado principalmente para promotores de espacios de datos que quieran hacer las oportunas pruebas técnicas antes de un despliegue.
- Simpl-Live: Despliegues de Simpl-open en entornos de producción que se corresponderán a espacios sectoriales contemplados en el programa Digital Europe. En concreto, se plantea el despliegue de espacios de datos gestionados por la propia Comisión Europea (Salud, Procurement, Lenguaje).
El proyecto tiene una orientación práctica y busca obtener resultados a la mayor brevedad. Por lo que se pretende que, además de suministrar el software, el contratista preste un servicio de laboratorio para que los usuarios puedan realizar pruebas. La empresa que desarrolle Simpl también deberá adaptar el software para el despliegue de espacios de datos comunes europeos previstos en el programa Digital Europe.
La asociación Gaia-X está considerada como la más próxima en sus objetivos al proyecto Simpl, así que el resultado del proyecto deberá esforzarse en la reutilización de los componentes que Gaia-X ponga a su disposición.
Por su parte, el centro Data Space Support Center, en el que participan las principales iniciativas europeas de creación de marcos tecnológicos y estándares para la construcción de espacios de datos, deberá definir los requisitos del middleware mediante especificaciones, modelos arquitectónicos y selección de estándares.
Los trabajos preparatorios de Simpl finalizaron en mayo de 2022, fijando el alcance y los requerimientos técnicos del proyecto que han sido objeto de detalle en el proceso contractual actualmente abierto. La licitación se puso en marcha el pasado 24 de febrero de 2023. Toda la información está disponible en TED eTendering, incluida la manera de formular preguntas sobre el proceso de licitación. El plazo para la presentación de solicitudes finaliza el 24 de abril de 2023 a las 17: 00 (hora de Bruselas).
Simpl espera disponer de una plataforma viable mínima publicada a principios de 2024. Paralelamente, y lo antes posible, el entorno abierto de pruebas (Simpl-Labs) se pondrá a disposición de las partes interesadas en experimentar. A continuación, se procederá a integrar progresivamente diferentes casos de uso, ayudándolos a ajustar Simpl a las necesidades específicas, considerando prioritarios los casos financiados de otro modo en el marco del programa de trabajo Europa DIGITAL.
Como conclusión, cabe remarcar que Simpl es la apuesta de la Comisión Europea para el despliegue e interoperabilidad de las diferentes iniciativas de espacios de datos sectoriales, garantizándose su concordancia con las especificaciones y requisitos emanados del Data Space Support Center y, por tanto, con el proceso de convergencia de las diferentes iniciativas europeas de construcción de espacios de datos (Gaia-X, IDSA, Fiware, BDVA).
Blog
El sector público en España tendrá el deber de garantizar la apertura de sus datos desde el diseño y por defecto, así como su reutilización. Así lo recoge la modificación de la Ley 37/2007 sobre la reutilización de la información del sector público en aplicación de la Directiva Europea 2019/1024.
Esta nueva redacción de la norma busca ampliar el ámbito de aplicación de la Ley para acercar las garantías y obligaciones jurídicas al contexto tecnológico, social y económico actual. En este escenario, la normativa vigente tiene en cuenta que una mayor disponibilidad de los datos del sector público puede contribuir al desarrollo de tecnologías tan punteras como la inteligencia artificial y todas sus aplicaciones.
Además, esta iniciativa está alineada con la Estrategia de datos de la Unión Europea dirigida a la creación de un mercado único de datos en el que la información fluya libremente entre los estados y el sector privado en un intercambio que beneficie ambas partes.
De los datos de alto valor a la unidad responsable de información: obligaciones de la Ley 37/2007
En la siguiente infografía, destacamos las principales obligaciones que recoge el texto consolidado de la ley. Se enfatiza en deberes como impulsar la apertura de datos de alto valor (HVDS, por sus siglas en inglés, High Value Datasets), es decir, conjuntos de datos con un gran potencial para generar beneficios sociales, medioambientales y económicos. Tal y como dicta la Ley, los HVDS deberán publicarse con licencia de atribución de datos abiertos (CC BY 4.0 o equivalente), en formato legible por máquinas y acompañados de metadatos que describan las características de los conjuntos de datos. Todo ello será de acceso público y gratuito con el objetivo de incentivar el desarrollo tecnológico, económico y social, especialmente de las PYMEs.
Además de la publicación de los datos de alto valor, todas las administraciones públicas tendrán la obligación de disponer de catálogos propios de datos que interoperarán con el Catálogo Nacional siguiendo la NTI-RISP, con el objetivo de contribuir a su enriquecimiento. Como ocurre con los HVDS, el acceso a los conjuntos de datos de las AA. PP. deberá ser gratuito salvo excepciones en las que se podrían aplicar costes marginales resultado del tratamiento de los datos.
Para garantizar la gobernabilidad del dato, la ley establece la necesidad de designar una unidad responsable de información para cada entidad que coordine la apertura y reutilización de los datos, y que se encargue de responder a las solicitudes y demandas ciudadanas.
En definitiva, la Ley 37/2007, ha sido modificada con el objetivo de ofrecer garantías jurídicas a las exigencias de competitividad e innovación que suscitan tecnologías como la inteligencia artificial o el internet de las cosas, así como a realidades como los espacios de datos donde los datos abiertos se presentan como una pieza clave.
Haz clic en la infografía para verla a tamaño real:

Noticia
El pasado 21 de febrero tuvo lugar la entrega de premios a los ganadores de la VI edición del Concurso de Datos Abiertos de Castilla y León. Esta competición, organizada por la Consejería de la Presidencia de la Junta de Castilla y León, reconoce la realización de proyectos que suministran ideas, estudios, servicios, sitios web o aplicaciones móviles, utilizando para ello conjuntos de datos de su Portal de Datos Abiertos.
El acto ha contado con la participación entre otros, de Jesús Julio Carnero García, Consejero de la Presidencia, y Rocío Lucas Navas, Consejera de Educación de la Junta de Castilla y León.
En su discurso, el consejero Jesús Julio Carnero García ha destacado que la Junta va a poner en marcha el proyecto de Gobierno del Dato, con el que pretenden sumar Transparencia y Datos Abiertos, para de este modo, mejorar los servicios que ofrecidos a los ciudadanos.
Así, el proyecto de Gobierno del Dato cuenta con una asignación aprobada de casi 2,5 millones de euros de los Fondos Next Generation, que incluye dos líneas de trabajo: tanto el diseño e implantación del modelo de Gobierno del Dato, como la capacitación de los empleados públicos.
Se trata de una acción de Gobierno abierto que, según ha añadido el propio Consejero, “tiene una estrecha relación con la transparencia, puesto que pretendemos que los Datos Abiertos estén disponibles de forma libre para todo el mundo, sin restricciones de copyright, patentes u otros mecanismos de control o registro”.
Nueve premiados en la VI edición del concurso de Datos Abiertos de Castilla y León
Es precisamente en este contexto donde destacan iniciativas como la VI edición del Concurso de Datos Abiertos de Castilla y León. En su sexta convocatoria, ha recibido un total de 26 propuestas procedentes de León, Palencia, Salamanca, Zamora, Madrid y Barcelona.
De esta forma, los 12.000 euros repartidos en las cuatro categorías definidas en las bases han quedado repartidos entre nueve de las propuestas mencionadas anteriormente. Así ha quedado el palmarés de galardones distribuido por categorías:
Categoría Productos y Servicios: destinada a reconocer proyectos que proporcionen estudios, servicios, sitios web o aplicaciones para dispositivos móviles y que estén accesibles para toda la ciudadanía vía web mediante una URL.
- Primer premio: 'Oferta de Formación profesional de Castilla y León. Una alternativa atractiva y accesible con herramientas no-cod'”. Autora: Laura Folgado Galache. (Zamora). 2.500 euros.
- Segundo premio: 'Enjoycyl: recogida y explotación de asistencia y valoración de actividades culturales'. Su autor es José María Tristán Martín. (Palencia) 1.500 euros.
- Tercer premio: 'Aplicación del problema de la p-mediana a la Atención Primaria en Castilla y León'. Autores: Carlos Montero y Ernesto Ramos (Salamanca) 500 euros.
- Premio estudiantes: 'Play4CyL'. Sus autores son Carlos Montero y Daniel Heras (Salamanca) 1.500 euros.
Categoría Ideas: busca premiar proyectos que describan una idea para desarrollar estudios, servicios, sitios web o aplicaciones para dispositivos móviles.
- Primer premio: 'Elige tu Universidad (Castilla y León)'. Autores: Maite Ugalde Enríquez y Miguel Balbi Klosinski (Barcelona) 1.500 euros.
- Segundo premio: 'Bots para interactuar con datos abiertos – Interfaces conversacionales para facilitar el acceso a los datos públicos (BODI)'. Autores: Marcos Gómez Vázquez y Jordi Cabot Sagrera (Barcelona) 500 euros.
Categoría Periodismo de Datos: premia piezas periodísticas publicadas o actualizadas (de forma relevante) en cualquier soporte (escrito o audiovisual).
- Primer premio: 'Elecciones 13-F en Castilla y León: habrá 186 colegios electorales menos que en las autonómicas de 2019'. Autores: Asociación Maldita contra la desinformación (Madrid) 1.500 euros.
- Segundo premio: 'Más de 2.500 alcaldes no cobraron nada de su ayuntamiento en 2020 y otros 1.000 no han informado de su sueldo'. Autores: Asociación Maldita contra la desinformación (Madrid). 1.000 euros.
Categoría Recurso Didáctico: reconoce la creación de recursos didácticos abiertos (publicados con licencias Creative Commons) nuevos e innovadores que sirvan de apoyo a la enseñanza en el aula.
En definitiva y tal y como apuntan desde la misma Consejería de la Presidencia, con este tipo de iniciativas y el Portal de Datos Abiertos se cumplen dos principios básicos: en primer lugar, el de transparencia, al poner a disposición de toda la sociedad datos generados por la Administración de la Comunidad en el desarrollo de sus funciones, en formatos abiertos y con una licencia libre para su uso; y en segundo lugar, el de colaboración, permitiendo el desarrollo de iniciativas compartidas que aporten mejoras sociales y económicas a través del trabajo conjunto entre la ciudadanía y las administraciones públicas.
Blog
16.500 millones de euros. Esos son los ingresos que se estima generarán la inteligencia artificial (IA) y los datos en la industria española para 2025, según se avanzó el pasado febrero en el foro de IndesIA, la asociación para la aplicación de la inteligencia artificial en la industria. La IA ya forma parte de nuestro día a día: ya sea haciendo más sencillo nuestro trabajo al realizar tareas rutinarias y repetitivas, o bien complementando las capacidades humanas en diversos ámbitos a través de modelos de aprendizaje automático que facilitan, por ejemplo, el reconocimiento de imágenes, la traducción automática o la predicción de diagnósticos médicos. Todas ellas, actividades que nos ayudan a mejorar la eficiencia de negocios y servicios, impulsando una toma de decisiones más certera.
Pero para que los modelos de aprendizaje automático (también conocidos por el término en inglés machine learning) funcionen correctamente, se necesitan datos de calidad y bien documentados. Todo modelo de aprendizaje automático se entrena y evalúa con datos. Las características de estos conjuntos de datos condicionan el comportamiento del modelo. Por ejemplo, si los datos de entrenamiento reflejan sesgos sociales no deseados es probable que estos también se incorporen en el modelo, lo cual puede tener graves consecuencias cuando se utiliza en ámbitos de gran importancia, como la justicia penal, la contratación de personas o el préstamo de créditos. Además, si no conocemos el contexto de los datos, puede que nuestro modelo no funcione correctamente, ya que en su proceso de construcción no se han tenido en cuenta las características intrínsecas de los datos sobre los cuales se sustenta.
Por estas y otras razones, el Foro Económico Mundial sugiere que todas las entidades deben documentar la procedencia, la creación y el uso de los conjuntos de datos de aprendizaje automático con el fin de evitar resultados erróneos o discriminatorios.
¿Qué son Datasheets for datasets?
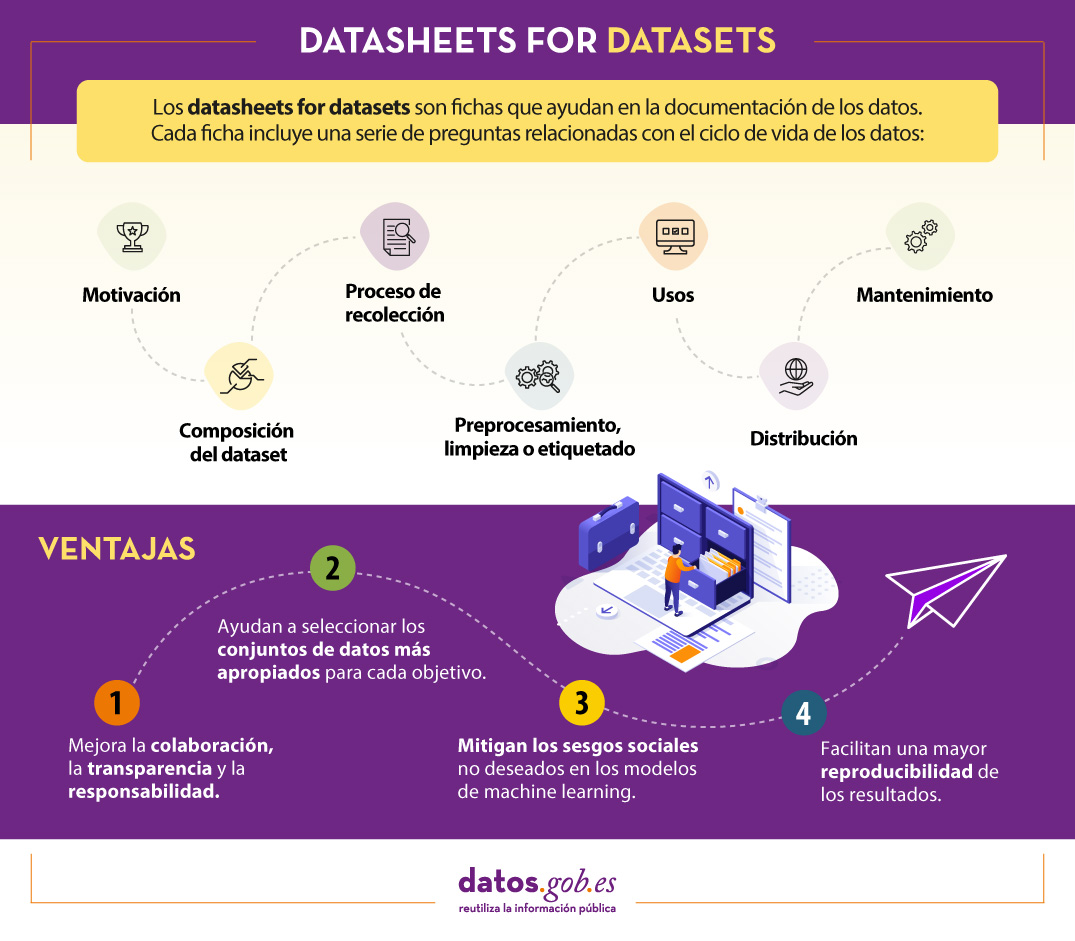
Un mecanismo para documentar esta información son las conocidas como Datasheets for datasets. Este marco de trabajo propone que todo conjunto de datos debe ser acompañado de una “ficha de datos”, llamada datasheet, que consiste de un cuestionario que guía en la documentación de los datos y la reflexión a lo largo del ciclo de vida de los datos. Algunas de las ventajas que supone son:
- Mejora la colaboración, la transparencia y la responsabilidad dentro de la comunidad de aprendizaje automático.
- Mitiga los sesgos sociales no deseados en los modelos.
- Ayuda a los investigadores y desarrolladores a seleccionar los conjuntos de datos más apropiados para alcanzar sus objetivos específicos.
- Facilita una mayor reproducibilidad de los resultados.
Los datasheets variarán dependiendo de factores tales como el área de conocimiento, la infraestructura organizacional existente o los flujos de trabajo.
Para ayudar en la creación de las datasheet, se ha diseñado un cuestionario con una serie de preguntas, acordes a las etapas del ciclo de vida de los datos:
- Motivación. Recoge las razones que han llevado a la creación de los conjuntos de datos. También se pregunta sobre quién creó o financió dichos datasets.
- Composición. Ofrece a los usuarios la información necesaria sobre la adecuación del conjunto de datos a sus objetivos. Incluye, entre otras preguntas, qué unidades de observación representan el conjunto de datos (documentos, fotos, personas, países), qué tipo de información ofrece cada unidad o si hay errores, fuentes de ruido o redundancias en él. Reflexiona acerca de los datos que se refieren a personas para evitar posibles sesgos sociales o violaciones a la privacidad.
- Proceso de recolección. Su objetivo es ayudar a los investigadores y usuarios a pensar en cómo crear conjuntos de datos alternativos con similares características. Aquí se detalla, por ejemplo, cómo se adquirieron los datos, quién participó en el proceso de recopilación o cómo fue el proceso de revisión ética. Trata especialmente los aspectos éticos del procesamiento de datos protegidos por la RGPD.
- Preprocesamiento, limpieza o etiquetado. Gracias a estas preguntas, los usuarios de datos podrán determinar si estos han sido procesados de formas compatibles con los usos que les pretenden dar. Indaga sobre si se realizó algún preprocesamiento, limpieza o etiquetado de los datos, o si está disponible el software que se utilizó para preprocesarlos, limpiarlos y etiquetarlos.
- Usos. Esta sección proporciona información sobre aquellas tareas para las cuales los datos pueden o no pueden ser usados. Para ello, se debe responder a preguntas como: ¿El conjunto de datos ya ha sido usado para alguna tarea? ¿Para qué otras tareas pueden ser utilizados? ¿La composición del conjunto de datos o la forma en que se recopiló, preprocesó, limpió y etiquetó puede afectar a otros usos futuros?
- Distribución. Recoge cómo se difundirá el conjunto de datos. Las preguntas se centran en si los datos se distribuirán a terceros y, en caso afirmativo, cómo, cuándo, cuáles son las restricciones de uso y bajo qué licencias.
- Mantenimiento. El cuestionario finaliza con preguntas dirigidas a planificar el mantenimiento de los datos y comunicar el plan a los usuarios de los datos. Por ejemplo, se responde a si se actualizará el conjunto de datos o quién dará soporte.
Se recomienda que todas las preguntas sean tenidas en cuenta antes de la recolección de los datos, para que sus creadores puedan ser conscientes de los posibles problemas. Para ilustrar cómo se podría responder a cada una de ellas en la práctica, los creadores del modelo han elaborado un apéndice con un ejemplo para un conjunto de datos determinado.
¿Es efectivo Datasheets for datasets?
El marco para documentar los datos Datasheets for datasets ha recibido inicialmente buenas críticas, pero su implementación continúa acarreando diversos retos, sobre todo cuando se trabaja con datos dinámicos.
Para conocer si el marco resuelve de forma efectiva las necesidades de documentación de los creadores y los usuarios de los datos, en junio del 2022, Microsoft USA y la Universidad de Michigan llevaron a cabo un estudio sobre su implementación. Para ello realizaron una serie de entrevistas y un seguimiento de la aplicación del cuestionario por parte de varios profesionales del aprendizaje automático.
En resumen, los participantes expresaron la necesidad de que los marcos de documentación sean adaptables a los diferentes contextos, se integren en las herramientas existentes y en los flujos de trabajo, y que sean tan automatizados como sea posible, debido en parte a la extensión de las preguntas. No obstante, también resaltaron sus ventajas, como, por ejemplo, que reduce el riesgo de pérdida de información, promueve la colaboración entre todos los que participan en el ciclo de vida de los datos, facilita el descubrimiento de los datos o impulsa el pensamiento crítico, entre otras.
En definitiva, nos encontramos ante un buen punto de partida, pero que deberá evolucionar, sobre todo para adaptarse a las necesidades de los datos dinámicos y a los flujos de documentación aplicados en diferentes contextos.
Contenido elaborado por el equipo de datos.gob.es.
Blog
Una de las acciones clave que destacamos recientemente como necesarias para construir el futuro de los datos abiertos en nuestro país es la implantación de procesos para mejorar la gestión y gobernanza de los datos. No en vano, el llevar a cabo una gestión adecuada de los datos en nuestras organizaciones se está convirtiendo en una tarea cada vez más compleja y demandada. Buena muestra de ello es, por ejemplo, que los especialistas en data governance están cada vez más demandados – con más de 45.000 ofertas de empleo activas en Estados Unidos para un rol que hace no mucho era prácticamente inexistente – y docenas de plataformas de gestión de datos ahora se anuncian como data governance platforms.
¿Pero qué es lo que hay realmente detrás de esas palabras clave? ¿Qué es lo que debemos entender realmente por gobernanza de los datos? En realidad, de lo que estamos hablando es de una serie de procesos de transformación bastante complejos que afectan al conjunto de la organización.
Esa complejidad queda perfectamente reflejada en el framework que nos proponen desde el Open Data Policy Lab, donde podemos observar claramente las diferentes capas superpuestas del modelo y cuáles son sus principales características – dando lugar a un recorrido a través de la elaboración de los datos, la colaboración con los datos como herramienta principal, la generación de conocimiento, el establecimiento de las condiciones habilitadoras necesarias y la creación de valor añadido.
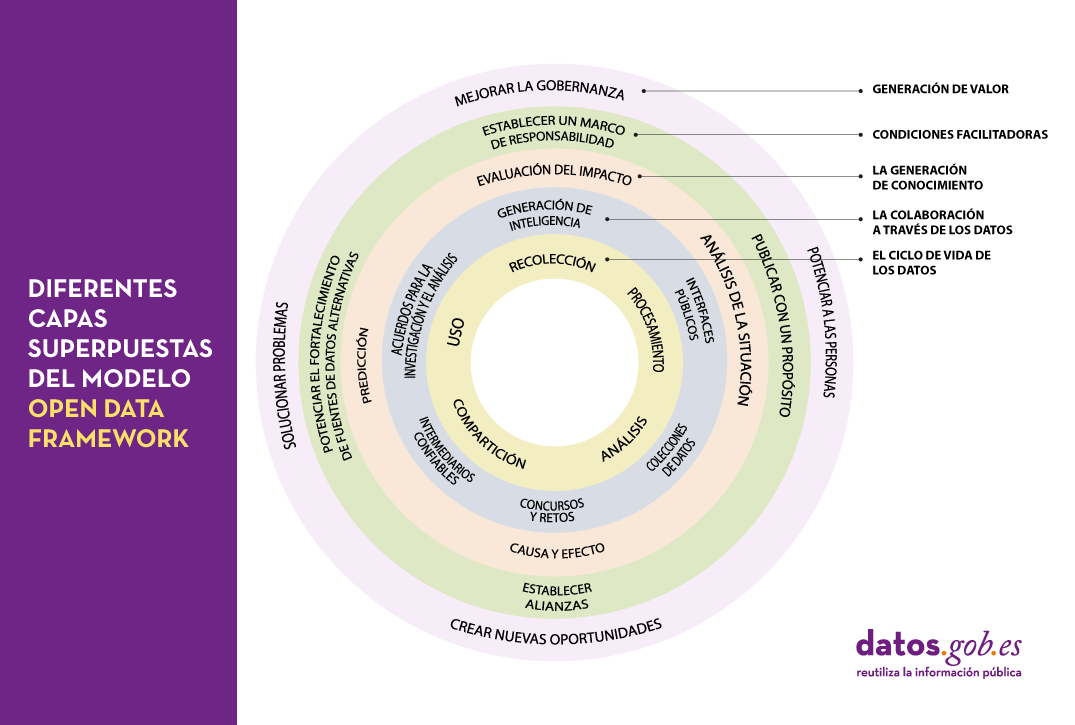
Pasemos entonces a continuación a pelar esa cebolla y observemos más en detalle qué es lo que encontraremos en cada una de esas capas:
El ciclo de vida de los datos
Nunca deberíamos considerar los datos como elementos aislados, sino como parte de un ecosistema mayor, que se encuentra inmerso en un ciclo continuo con las siguientes fases:
- Recolección o recopilación de los datos procedentes de distintas fuentes.
- Procesamiento y transformación de los datos para conseguir que sean utilizables.
- Compartición e intercambio de datos entre los distintos miembros de la organización.
- Análisis para extraer el conocimiento que se está buscando.
- Uso de los datos de acuerdo al conocimiento obtenido.
La colaboración a través de los datos
No es extraño que el ciclo de vida de los datos transcurra únicamente dentro de la organización donde se originan. Sin embargo, podremos aumentar el valor de esos datos exponencialmente, simplemente exponiéndolos a la colaboración con otras organizaciones a través de diversos mecanismos, añadiendo así una nueva capa de gestión:
- Interfaces públicos que ofrecen un acceso selectivo a los datos, habilitando nuevos usos y funciones.
- Intermediarios confiables que funcionan como agentes independientes de datos. Estos agentes coordinan el uso de los datos por parte de terceros, garantizando su seguridad e integridad en todo momento.
- Colecciones de datos que ofrecen una visión común, conjunta, completa y coherente de los datos a través de la agregación de porciones procedentes de distintas fuentes.
- Acuerdos para la investigación y el análisis, por los que se garantiza el acceso a ciertos datos con el objetivo de generar un conocimiento específico.
- Concursos y retos que dan acceso a datos específicos durante un periodo limitado de tiempo para promover nuevos usos innovadores de los mismos.
- Generación de inteligencia, mediante la cual se comparten también los conocimientos adquiridos por la organización a través de los datos y no solo la materia prima.
La generación de conocimiento
Gracias a las colaboraciones establecidas en la capa anterior será posible realizar nuevos estudios de los datos que nos permitirán tanto analizar el pasado como tratar de extrapolar el futuro mediante diversas técnicas como:
- Análisis de la situación, conociendo lo que está pasando en el entorno de los datos.
- Causa y efecto, buscando una explicación al origen de lo que está pasando.
- Predicción, intentando inferir que será lo siguiente que va a pasar.
- Evaluación del impacto, estableciendo lo que esperamos que debería suceder.
Condiciones facilitadoras
Existen una serie de procedimientos que cuando se aplican por encima de un ecosistema de datos colaborativo ya existente pueden dar lugar a un uso todavía más efectivo de los datos mediante técnicas como:
- Publicar con un propósito, con el objetivo de coordinar la oferta y la demanda de datos de la forma más eficiente posible.
- Establecer alianzas, incluyendo en nuestros análisis a aquellos grupos de personas y organizaciones que nos puedan ayudar a entender mejor las necesidades reales.
- Potenciar el fortalecimiento de fuentes de datos alternativas proporcionando los recursos necesarios para crear nuevas fuentes de datos en las áreas aún por explotar.
- Establecer un marco de responsabilidad en torno a los datos que tenga en cuenta los principios de equidad, compromiso y transparencia.
Generación de valor
La ampliación del ecosistema y el establecimiento de las condiciones adecuadas para que ese ecosistema florezca pueden dar lugar a economías de datos de escala de las que podremos obtener nuevos beneficios como:
- Mejorar la gobernanza y la operativa de la propia organización gracias a las mejoras generales en transparencia y eficiencia que acompañan a los procesos de apertura.
- Potenciar a las personas proporcionándoles las herramientas que necesitan para realizar sus tareas de la forma más adecuada y tomar las decisiones correctas.
- Crear nuevas oportunidades para la innovación, la creación de nuevos modelos de negocio y la elaboración de políticas públicas dirigidas por la evidencia.
- Solucionar problemas optimizando los procesos y servicios y las intervenciones dentro del sistema en el que operamos.
Como podemos observar, el concepto de gobernanza de los datos es en realidad mucho más amplio y complejo de lo que en principio uno podría esperar y abarca una serie de actuaciones clave y tareas que en la mayoría de organizaciones será prácticamente imposible tratar de centralizar en un único rol o a través de una única herramienta. Por tanto, a la hora de establecer un sistema de gobernanza de datos en una organización deberíamos afrontar el reto como un proceso de transformación integral o un cambio de paradigma en el que prácticamente todos los miembros de la misma deberán estar implicados en mayor o menor medida. Una buena forma de afrontar este reto con mayor facilidad y mejores garantías sería a través de la adopción e implementación de algunos de los marcos y estándares de referencia que se han ido creando al respecto y que se corresponderías con distintas partes de este modelo.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Transformar los datos en conocimiento se ha convertido en uno de los objetivos principales a los que se enfrentan tanto las organizaciones públicas como privadas en la actualidad. Pero, para poder lograrlo, es necesario partir de la premisa de que los datos tratados están gobernados y son de calidad.
En este sentido, la Asociación Española de Normalización (UNE) ha publicado recientemente un artículo e informe donde se recogen distintas normas técnicas que buscan garantizar que la correcta gestión y gobernanza de los datos de una organización. En este post se recogen ambos materiales, incluyendo una infografía-resumen de las normas destacadas.
En los artículos de referencia señalados se mencionan norman técnicas relativas a gobernanza, gestión, calidad, seguridad y privacidad de datos. En esta ocasión queremos hacer un zoom sobre aquellas centradas en la calidad de los datos.
Estándares de referencia de gestión de la calidad
Tal y como dijo Lord Kelvin, físico y matemático británico del siglo XIX, “lo que no se mide, no se puede mejorar y lo que no se mejora, se degrada siempre”. Pero para medir la calidad del dato y poder mejorarla se necesitan estándares que nos ayuden a homogeneizar primero dicha calidad*. A ello nos pueden ayudar las normas técnicas detalladas a continuación:
Norma ISO 8000
La normativa ISO (International Organization for Standardization), dispone de la norma ISO 8000 como el estándar internacional para la calidad de los datos de transacción, los datos de producto y los datos maestros empresariales. Esta norma se estructura en 4 partes: conceptos generales de la calidad de los datos (ISO 8000-1, ISO 8000-2 e ISO 8000-8), procesos de gestión de la calidad de los datos (ISO 8000-6x), aspectos relacionados con el intercambio de datos maestros entre organizaciones (partes 100 a 150) y aplicación de la calidad de los datos de producto (ISO 8000-311).
Dentro de la familia de las ISO 8000-6X, centrada en los procesos de gestión de la calidad de los datos para crear, almacenar y transferir los datos que dan soporte a los procesos de negocio de manera oportuna y rentable, encontramos:
- La ISO 8000-60 proporciona una visión general de los procesos de gestión de calidad de los datos sometidos a un ciclo de mejora continua.
- La ISO 8000-61 establece un modelo de referencia de procesos de gestión de calidad de los datos. La principal característica es que, para alcanzar la mejora continua, el proceso de implementación debe ser ejecutado continuamente siguiendo el ciclo Plan-Do-Check-Act. Además, se incluyen procesos de implementación relacionados con el aprovisionamiento de los recursos y el procesamiento de datos. Tal y como se muestra en la siguiente imagen, las cuatro etapas del ciclo de implementación deben disponer de datos de entrada, información de control y soporte para una mejora continua, así como contar con los recursos necesarios para el desempeño de las actividades.
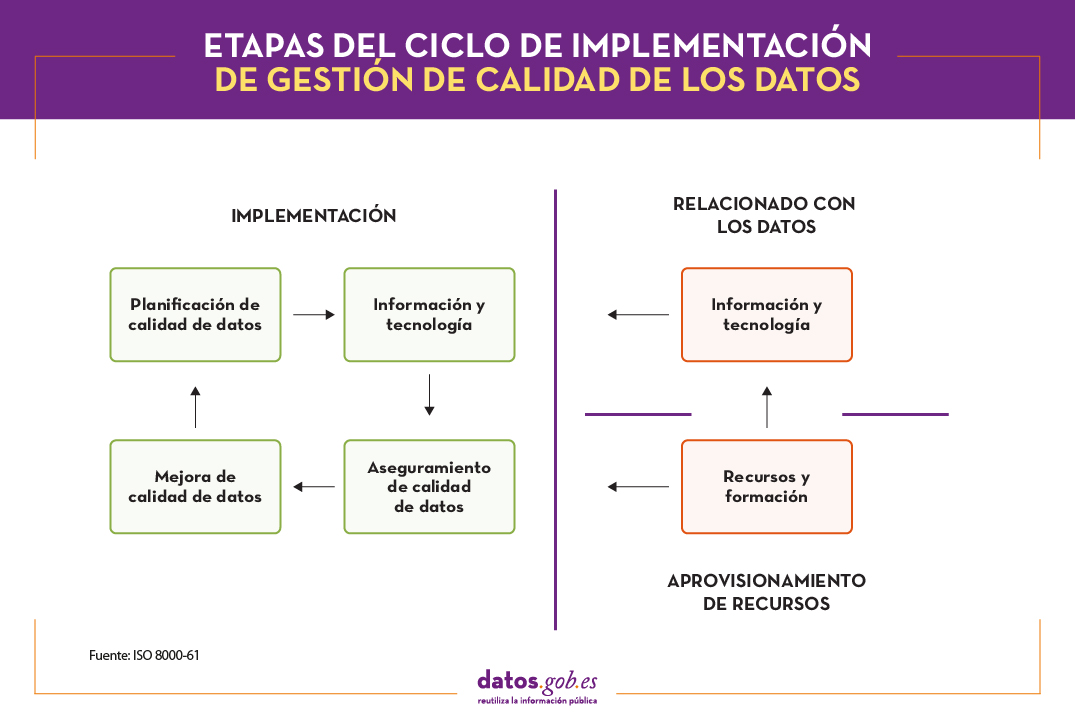
- Por su parte, la ISO 8000-62, la última de la familia de las ISO 8000-6X, se enfoca en la evaluación de madurez de procesos organizacionales. En ella se especifica un marco de trabajo para evaluar la madurez de la gestión de la calidad de datos de la organización, basado en su capacidad de ejecutar las actividades relacionadas con los procesos de gestión de la calidad de datos identificados en la ISO 8000-61. En función de la capacidad del proceso evaluado, se asigna uno de los niveles definidos.
Norma ISO 25012
Otra de las normas ISO que trata sobre la calidad de los datos es la familia de las ISO 25000, que tiene por objetivo la creación de un marco de trabajo común para evaluar la cvalidad del producto de software. En concreto, la norma ISO 25012 define un un modelo general de calidad de datos aplicable a datos almacenados de forma estructurada en un sistema de información.
Además, en el contexto de datos abiertos se considera una referencia de acuerdo al conjunto de buenas prácticas para la evaluación de la calidad de los datos abiertos desarrollado por la red paneuropea Share-PSI, concebida para servir de orientación a todas las organizaciones públicas a la hora de compartir información.
En este caso, la calidad del producto de datos se entiende como el grado en que estos satisfacen los requisitos definidos previamente en el modelo de calidad de datos mediante las siguientes 15 características.
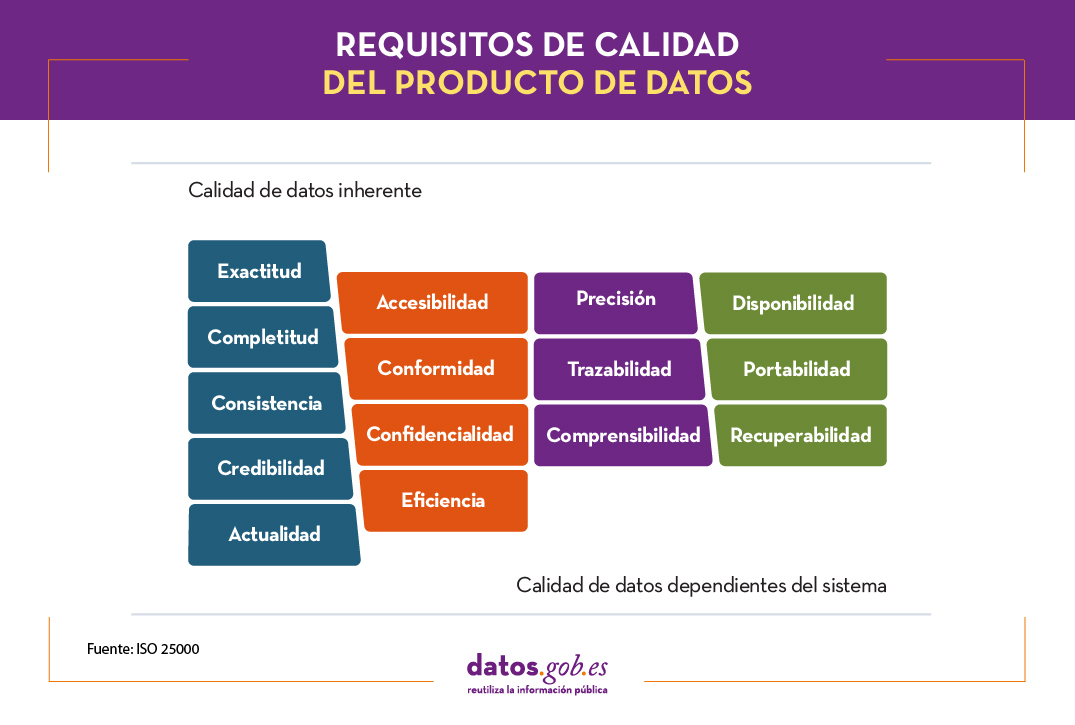
Estas características o dimensiones de calidad, se clasifican principalmente en dos categorías.
La calidad de datos inherente se relaciona con el potencial intrínseco de los datos de satisfacer las necesidades definidas cuando se utilizan en condiciones concretas. Se trata de:
- Exactitud: grado en el que los datos representan el verdadero valor del atributo deseado en un contexto específico, como pueda ser la cercanía de los datos a un conjunto de valores definidos en un determinado dominio.
- Completitud: grado en el que los datos asociados tienen valor para todos los atributos definidos.
- Consistencia: grado de coherencia con otros datos existentes, eliminando contradicciones.
- Credibilidad: grado en que los datos tienen atributos que se consideran ciertos y creíbles en su contexto, incluyendo la veracidad de los orígenes de datos.
- Actualidad: grado de vigencia de los datos para su contexto de uso.
Por otro lado, la calidad de datos dependiente del sistema se relaciona con el grado alcanzado a través de un sistema informático bajo condiciones concretas. Se trata de:
- Disponibilidad: grado en que los datos tienen atributos que permiten ser obtenidos por usuarios autorizados.
- Portabilidad: capacidad de los datos de ser instalados, reemplazados o eliminados de un sistema a otro, preservando el nivel de calidad.
- Recuperabilidad: grado en que los datos tienen atributos que permiten mantener y preservar la calidad incluso en caso de fallos.
Adicionalmente, hay características o dimensiones que pueden englobarse tanto dentro de calidad de datos inherente como dependiente del sistema. Estas son:
- Accesibilidad: posibilidad de acceso a los datos en un contexto concreto por unos roles determinados.
- Conformidad: grado en que los datos contienen atributos en base a estándares, normativas o referencias establecidas.
- Confidencialidad: mide el grado de aseguramiento de los datos en base a su naturaleza para poder acceder a ellos solo por los roles configurados.
- Eficiencia: posibilidades que ofrecen los datos para ser procesados con niveles de rendimiento esperados en situaciones concretas.
- Precisión: exactitud de los datos en base a un contexto de uso específico.
- Trazabilidad: capacidad de auditar el ciclo de vida completo del dato.
- Comprensibilidad: capacidad de los datos de ser interpretados por cualquier usuario, incluyendo la utilización de símbolos y lenguajes determinados para un contexto específico.
Además de las normas ISO, existen otros marcos de referencia que establecen pautas comunes para la medición de la calidad. DAMA Internacional, por ejemplo, tras analizar las similitudes de todos los modelos, establece 8 dimensiones de calidad básicas comunes a cualquier estándar: exactitud, completitud, consistencia, integridad, razonabilidad, oportunidad, unicidad, validez.
La necesidad de mejora continua
La homogeneización de la calidad de los datos de acuerdo a estándares de referencia como los descritos, permiten asentar las bases para una mejora continua de la información. A partir de la aplicación de estas normas, y teniendo en cuenta las dimensiones detalladas, es posible definir indicadores de calidad. Una vez se implementen y ejecuten, arrojarán unos resultados que tendrán que ser revisados por los diferentes propietarios de los datos, estableciendo umbrales de tolerancia e identificando así incidencias de calidad en todos aquellos indicadores que no superen el umbral definido.
Para ello, se tendrán en cuenta diferentes parámetros como la naturaleza del dato o su impacto en el negocio, ya que no se puede tratar de igual forma un campo descriptivo que una clave primaria, por ejemplo.
A partir de ahí, es frecuente poner en marcha un circuito de resolución de incidencias capaz de detectar la causa raíz que genera una deficiencia de calidad en un dato para extraerla y garantizar la mejora continua.
Gracias a ello, se obtienen innumerables beneficios, como minimizar riesgos, ahorro de tiempo y recursos, toma ágil de decisiones, adaptación a nuevos requerimientos o mejora reputacional.
Cabe destacar que las normas técnicas abordadas en este post permiten homogeneizar la calidad. Para tareas de medición de la calidad de los datos per se, deberíamos acudir a otras normas como la ISO 25024:2015.
Contenido elaborado por Juan Mañes, experto en Data Governance.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.