Blog
The main motivation of this first article - of a series of three - is to explain how to use the UNE 0077 data governance specification (see Figure 1) to establish approved and validated mechanisms that provide organizational support for aspects related to data openness and publication for subsequent use by citizens and other organizations.
To understand the need and utility of data governance, it must be noted that, as a premise, every organization should start with an organizational strategy. To better illustrate the article, consider the example of the municipality of an imaginary town called Vistabella. Suppose the organizational strategy of the Vistabella City Council is to maximize the transparency and quality of public services by reusing public service information.

Fig. 1. Specification processes UNE 0077, 0078 and 0079
To support this organizational strategy, the Vistabella City Council needs a data strategy, the main objective of which is to promote the publication of open data on the respective open data portals and encourage their reuse to provide quality data to its residents transparently and responsibly. The Mayor of the Vistabella City Council must launch a data governance program to achieve this main objective. For this purpose, a working group composed of specialized data experts from the City Council is assigned to tackle this program. This group of experts is given the necessary authority, a budget, and a set of responsibilities.
When starting, these experts decide to follow the process approach proposed in UNE 0077, as it provides them with a suitable guide to carry out the necessary data governance actions, identifying the expected process outcomes for each of the processes and how these can be materialized into specific artifacts or work products.
This article explains how the experts have used the processes in the UNE 0077 specification to achieve their goal. Out of the five processes detailed in the specification, we will focus, by way of example, on only three of them: the one describing how to establish the data strategy, the one describing how to establish policies and best practices, and the one describing how to establish organizational structures.
Before we begin, it is important to remember the structure of the process descriptions in the different UNE specifications (UNE 0077, UNE 0078, and UNE 0079). All processes are described with a purpose, a list of expected process outcomes (i.e., what is expected to be achieved when the process is executed), a set of tasks that can be followed, and a set of artifacts or work products that are the manifestation of the process outcomes.
"Data Strategy Establishment Process"
The team of experts from the Vistabella City Council decided to follow each of the tasks proposed in UNE 0077 for this process. Below are some aspects of the execution of these tasks:
T1. Evaluate the capabilities, performance, and maturity of the City Council for the publication of open data. To do this, the working group gathered all possible information about the skills, competencies, and experiences in publishing open data that the Vistabella City Council already had. They also collected information about the downloads that have been made so far of published data, as well as a description of the data itself and the different formats in which it has been published. They also analyzed the City Council's environment to understand how open data is handled. The work product generated was an Evaluation Report on the organization's data capabilities, performance, and maturity.
T2. Develop and communicate the data strategy. Given its importance, to develop the data strategy, the working group used the Plan to promote the opening and reuse of open data as a reference to shape the data strategy stated earlier, which is to "promote the publication of open data on the respective open data portals and encourage their reuse to provide quality data to its residents transparently and responsibly." Additionally, it is important to note that data openness projects will be designed to eventually become part of the structural services of the Vistabella City Council. The work products generated will be the adapted Data Strategy itself and a specific communication plan for this strategy.
T3. Identify which data should be governed according to the data strategy. The Vistabella City Council has decided to publish more data about urban public transport and cultural events in the municipality, so these are the data that should be governed. This would include data of different types: statistical data, geospatial data, and some financial data. To do this, they propose using the Plan to promote the opening and reuse of open data again. The work product will be a list of the data that should be governed, and in this case, also published on the platform. Later on, the experts will be asked to reach an agreement on the meaning of the data and choose the most representative metadata to describe the different business, technical, and operational characteristics.
T4. Develop the portfolio of data programs and projects. To achieve the specific objective of the data strategy, a series of specific projects related to each other are identified, and their viability is determined. The work product generated through this task will be a portfolio of projects that covers these objectives:
- Planning, control, and improvement of the quality of open data
- Ensuring compliance with security standards
- Deployment of control mechanisms for data intermediation
- Management of the configuration of data published on the portal
T5. Monitor the degree of compliance with the data strategy. To do this, the working group defines a series of key performance indicators that are measured periodically to monitor key aspects related to the quality of open data, compliance with security standards, use of data intermediation mechanisms, and management of changes to the data published on the portal. The work product generated consists of periodic reports on the monitoring of the data strategy.
"Establishment of Data Policies, Best Practices, and Procedures Process"
The data strategy is implemented through a series of policies, best practices, and procedures. To determine these policies or procedures, you can follow the process of Establishing Data Policies, Best Practices, and Procedures detailed in UNE 0077. For each of the data identified in the previous process, it may be necessary to define specific policies for each area of action described in the established data strategy.
To have a systematic and consistent way of working and to avoid errors, the Vistabella City Council's working group decides to model and publish its own process for defining strategies based on the generic definition of that process contained in Specification UNE 0077, tailored to the specific characteristics of the Vistabella City Council.
This process could be followed by the working group as many times as necessary to define and approve data policies, best practices, and procedures.
In any case, it is important for the customization of this process to identify and select the principles, standards, ethical aspects, and relevant legislation related to open data. To do this, a framework is defined, consisting of a regulatory framework and a framework of standards.
The regulatory framework includes:
- The legal framework related to the reuse of public sector information.
- The General Data Protection Regulation (GDPR) to ensure that the minimum requirements for the security and privacy of information are met when publishing open data on the portal.
The framework of standards includes, among others:
- The practical guide for improving the quality of open data, which provides support to ensure that the shared data is of quality.
- The UNE specifications 0077, 0078, and 0079 themselves, which contain best practices for data governance, management, and quality.
This framework, along with the defined process, will be used by the working group to develop specific data policies that should be communicated through the appropriate publication, taking into account the most appropriate legal tools available. Some of these policies may be published, for example, as municipal resolutions or announcements, in compliance with the current regional or national legislation.
"Establishment of Organizational Structures for Data Governance, Management, and Use Process"
Even though the established Working Group is making initial efforts to address the strategy, it is necessary to create an organizational structure responsible for coordinating the necessary work related to the governance, management, and quality management of open data. For this purpose, the corresponding process detailed in UNE 0077 will be followed. Similar to the first section, the explanation is provided with the structure of the tasks to be developed:
T1. Define an organizational structure for data governance, management, and use. It is interesting to visualize the Vistabella City Council as a federated set of council offices and other municipal services that could share a common way of working, each with the necessary independence to define and publish their open data. Remember that initially, this data pertained to urban transport and cultural events. This involves identifying individual and collective roles, chains of responsibility, and accountability, as well as defining a way of communicating among them. The main product of this work will be an organizational structure to support various activities. These organizational structures must be compatible with the functional role structures that already exist in the City Council. In this regard, one can mention, by way of example, the information responsible unit, whose role is highlighted in Law 37/2007 as one of the most important roles. The information responsible unit primarily has the following four functions:
- Coordinate information reuse activities with existing policies regarding publications, administrative information, and electronic administration.
- Facilitate information about competent bodies within their scope for receiving, processing, and resolving reuse requests transmitted.
- Promote the provision of information in appropriate formats and keep it updated as much as possible.
- Coordinate and promote awareness, training, and promotional activities.
T2. Establish the necessary skills and knowledge. For each of the functions mentioned above of the information responsible units, it will be necessary to identify the skills and knowledge required to manage and publish the open data for which they are responsible. It is important to note that knowledge and skills should encompass both technical aspects in the field of open data publication and domain-specific knowledge related to the data being opened. All these knowledge and skills should be appropriately recognized and listed. Later on, a working group may be tasked with designing training plans to ensure that individuals involved in the information responsible units possess these knowledge and skills.
T3. Monitor the performance of organizational structures. In order to quantify the performance of organizational structures, it will be necessary to define and measure a series of indicators that allow modeling different aspects of the work of the people included in the organizational structures. This may include aspects such as the efficiency and effectiveness of their work or their problem-solving ability.
We have reached the end of this first article in which some aspects of how to use three of the five processes in the UNE 0077:2023 specification have been described to outline what open data governance should look like. This was done using an example of a City Council in an imaginary town called Vistabella, which is interested in publishing open data on urban transport and cultural events.
The content of this guide can be downloaded freely and free of charge from the AENOR portal through the link below by accessing the purchase section. Access to this family of UNE data specifications is sponsored by the Secretary of State for Digitalization and Artificial Intelligence, Directorate General for Data. Although the download requires prior registration, a 100% discount on the total price is applied at the time of finalizing the purchase. After finalizing the purchase, the selected standard or standards can be accessed from the customer area in the my products section.
https://tienda.aenor.com/norma-une-especificacion-une-0077-2023-n0071116
Content developed by Dr. Ismael Caballero, Associate Professor at UCLM, and Dr. Fernando Gualo, PhD in Computer Science, and Chief Executive Officer and Data Quality and Data Governance Consultant. The content and viewpoints reflected in this publication are the sole responsibility of the authors."
Blog
As technology and connectivity have advanced in recent years, we have entered a new era in which data never sleeps and the amount of data circulating is greater than ever. Today, we could say that we live enclosed in a sphere surrounded by data and this has made us more and more dependent on it. On the other hand, we have also gradually become both producers and collectors of data.
The term datasphere has historically been used to define the set of all the information existing in digital spaces, also including other related concepts such as data flows and the platforms involved. But this concept has been developing and gaining more and more relevance in parallel with the growing weight of data in our society today, becoming an important concept in defining the future of the relationship between technology and society.
In the early days of the digital era we could consider that we lived in our own data bubbles that we fed little by little throughout our lives until we ended up totally immersed in the data of the online world, where the distinction between the real and the virtual is increasingly irrelevant. Today we live in a society that is interconnected through data and also through algorithms that link us and establish relationships between us. All that data we share more or less consciously no longer affects only ourselves as individuals, but can also have its effect on the rest of society, even in sometimes totally unpredictable ways - like a digital version of the butterfly effect.
Governance models that are based on working with data and its relationship to people, as if it were simply isolated instances that we can work with individually, will therefore no longer serve us well in this new environment.
The need for a systems-based approach to data
Today, that relatively simple concept of the data sphere has evolved into a complete, highly interconnected and complex digital ecosystem - made up of a wide range of data and technologies - that we inhabit and that affects the way we live our lives. It is a system in which data has value only in the context of its relationship with other data, with people and with the rules that govern those relationships.
Effective management of this new ecosystem will therefore require a better understanding of how the different components of the datasphere relate to each other, how data flows through these components, and what the appropriate rules will be needed to make this interconnected system work.
Data as an active component of the system
In a systems-based approach, data is considered as an active component within the ecosystem. This means that data is no longer just static information, but also has the capacity to influence the functioning of the ecosystem itself and will therefore be an additional component to be considered for the effective management of the ecosystem.
For example, data can be used to fine-tune the functioning of algorithms, improving the accuracy and efficiency of artificial intelligence and machine learning systems. Similarly, it could also be used to adjust the way decisions are made and policies implemented in different sectors, such as healthcare, education and security.
The data sphere and the evolution of data governance
It will therefore be necessary to explore new collective data governance frameworks that consider all elements of the ecosystem in their design, controlling how information is accessed, used and protected across the data sphere.
This could ensure that data is used securely, ethically and responsibly for the whole ecosystem and not just in individual or isolated cases. For example, some of the new data governance tools that have been experimented with for some time now and can help us to manage the data sphere collectively are data commons or digital data assets, data trusts, data cooperatives, data collaboratives or data collaborations, among others.
The future of the data sphere
The data sphere will continue to grow and evolve in the coming years, driven once again by new technological advances and the increasing connectivity and ubiquity of systems. It will be important for governments and organisations to keep abreast of these changes and adapt their data governance and management strategies accordingly through robust regulatory frameworks, accompanied by ethical guidelines and responsible practices that ensure that the benefits that data exploitation promises us can finally be realised while minimising risks.
In order to adequately address these challenges, and thus harness the full potential of the data sphere for positive change and for the common good, it will be essential to move away from thinking of data as something we can treat in isolation and to adopt a systems-based approach that recognises the interconnected nature of data and its impact on society as a whole.
Today, we could consider data spaces, which the European Commission has been developing for some time now as a key part of its new data strategy, as precisely a logical evolution of the data sphere concept adapted to the particular needs of our time and acting on all components of the ecosystem simultaneously: technical, functional, operational, legal and business.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
The European Commission's 'European Data Strategy' states that the creation of a single market for shared data is key. In this strategy, the Commission has set as one of its main objectives the promotion of a data economy in line with European values of self-determination in data sharing (sovereignty), confidentiality, transparency, security and fair competition.
Common data spaces at European level are a fundamental resource in the data strategy because they act as enablers for driving the data economy. Indeed, pooling European data in key sectors, fostering data circulation and creating collective and interoperable data spaces are actions that contribute to the benefit of society.
Although data sharing environments have existed for a long time, the creation of data spaces that guarantee EU values and principles is an issue. Developing enabling legislative initiatives is not only a technological challenge, but also one of coordination among stakeholders, governance, adoption of standards and interoperability.
To address a challenge of this magnitude, the Commission plans to invest close to €8 billion by 2027 in the deployment of Europe's digital transformation. Part of the project includes the promotion of infrastructures, tools, architectures and data sharing mechanisms. For this strategy to succeed, a data space paradigm that is embedded in the industry needs to be developed, based on the fulfilment of European values. This data space paradigm will act as a de facto technology standard and will advance social awareness of the possibilities of data, which will enable the economic return on the investments required to create it.
In order to make the data space paradigm a reality, from the convergence of current initiatives, the European Commission has committed to the development of the Simpl project.
What exactly is Simpl?
Simpl is a €150 million project funded by the European Commission's Digital Europe programme with a three-year implementation period. Its objective is to provide society with middleware for building data ecosystems and cloud infrastructure services that support the European values of data sovereignty, privacy and fair markets.
The Simpl project consists of the delivery of 3 products:
- Simpl-Open: Middleware itself. This is a software solution to create ecosystems of data services (data and application sharing) and cloud infrastructure services (IaaS, PaaS, SaaS, etc). This software must include agents enabling connection to the data space, operational services and brokerage services (catalogue, vocabulary, activity log, etc.). The result should be delivered under an open source licence and an attempt will be made to build an open source community to ensure its evolution.
- Simpl-Labs: Infrastructure for creating test bed environments so that interested users can test the latest version of the software in self-service mode. This environment is primarily intended for data space developers who want to do the appropriate technical testing prior to a deployment.
- Simpl-Live: Deployments of Simpl-open in production environments that will correspond to sectorial spaces contemplated in the Digital Europe programme. In particular, the deployment of data spaces managed by the European Commission itself (Health, Procurement, Language) is envisaged.
The project is practically oriented and aims to deliver results as soon as possible. It is therefore intended that, in addition to supplying the software, the contractor will provide a laboratory service for user testing. The company developing Simpl will also have to adapt the software for the deployment of common European data spaces foreseen in the Digital Europe programme.
The Gaia-X partnership is considered to be the closest in its objectives to the Simpl project, so the outcome of the project should strive for the reuse of the components made available by Gaia-X.
For its part, the Data Space Support Center, which involves the main European initiatives for the creation of technological frameworks and standards for the construction of data spaces, will have to define the middleware requirements by means of specifications, architectural models and the selection of standards.
Simpl's preparatory work was completed in May 2022, setting out the scope and technical requirements of the project which have been the subject of detail in the currently open contractual process. The tender was launched on 24 February 2023. All information is available on TED eTendering, including how to ask questions about the tendering process. The deadline for applications is 24 April 2023 at 17:00 (Brussels time).
Simpl expects to have a minimum viable platform published in early 2024. In parallel, and as soon as possible, the open test environment (Simpl-Labs) will be made available for interested parties to experiment. This will be followed by the progressive integration of different use cases, helping to tailor Simpl to specific needs, with priority being given to cases otherwise funded under the Europe DIGITAL work programme.
In conclusion, Simpl is the European Commission's commitment to the deployment and interoperability of the different sectoral data space initiatives, ensuring alignment with the specifications and requirements emanating from the Data Space Support Center and, therefore, with the convergence process of the different European initiatives for the construction of data spaces (Gaia-X, IDSA, Fiware, BDVA).
Blog
The public sector in Spain will have the duty to guarantee the openness of its data by design and by default, as well as its reuse. This is the result of the amendment of Law 37/2007 on the reuse of public sector information in application of European Directive 2019/1024.
This new wording of the regulation seeks to broaden the scope of application of the Law in order to bring the legal guarantees and obligations closer to the current technological, social and economic context. In this scenario, the current regulation takes into account that greater availability of public sector data can contribute to the development of cutting-edge technologies such as artificial intelligence and all its applications.
Moreover, this initiative is aligned with the European Union's Data Strategy aimed at creating a single data market in which information flows freely between states and the private sector in a mutually beneficial exchange.
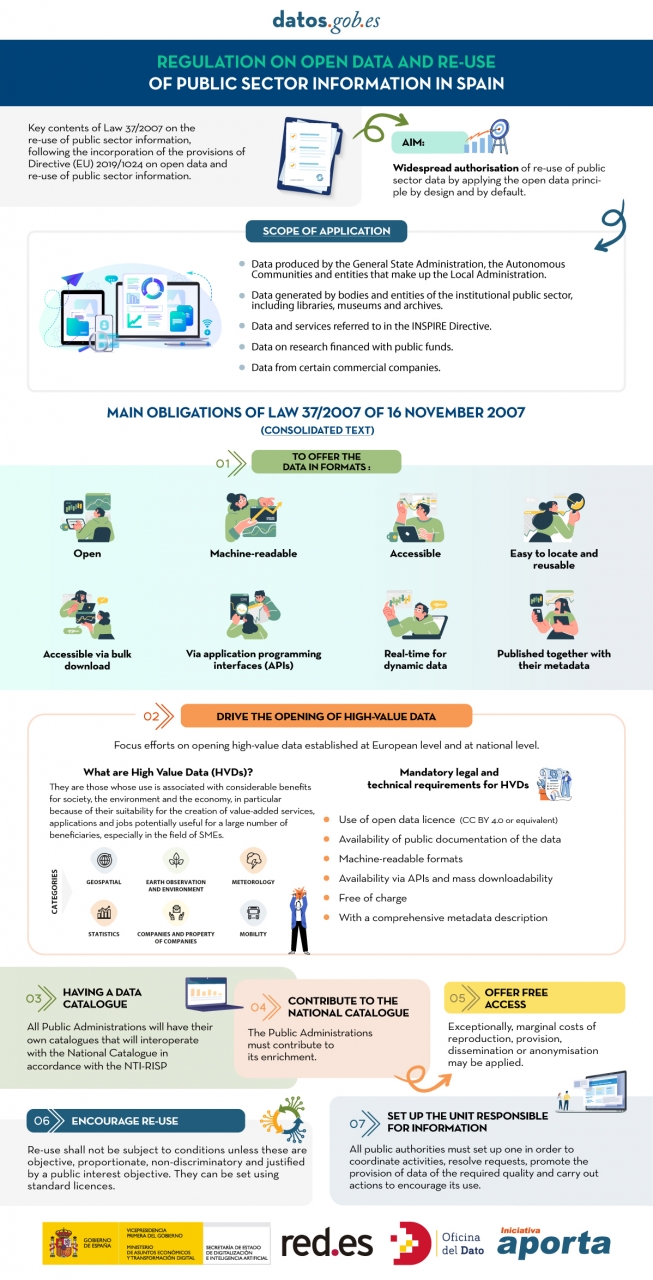
From high-value data to the responsible unit of information: obligations under Law 37/2007
In the following infographic, we highlight the main obligations contained in the consolidated text of the law. Emphasis is placed on duties such as promoting the opening of High Value Datasets (HVDS), i.e. datasets with a high potential to generate social, environmental and economic benefits. As required by law, HVDS must be published under an open data attribution licence (CC BY 4.0 or equivalent), in machine-readable format and accompanied by metadata describing the characteristics of the datasets. All of this will be publicly accessible and free of charge with the aim of encouraging technological, economic and social development, especially for SMEs.
In addition to the publication of high-value data, all public administrations will be obliged to have their own data catalogues that will interoperate with the National Catalogue following the NTI-RISP, with the aim of contributing to its enrichment. As in the case of HVDS, access to the datasets of the Public Administrations must be free of charge, with exceptions in the case of HVDS. As with HVDS, access to public authorities' datasets should be free of charge, except for exceptions where marginal costs resulting from data processing may apply.
To guarantee data governance, the law establishes the need to designate a unit responsible for information for each entity to coordinate the opening and re-use of data, and to be in charge of responding to citizens' requests and demands.
In short, Law 37/2007 has been modified with the aim of offering legal guarantees to the demands of competitiveness and innovation raised by technologies such as artificial intelligence or the internet of things, as well as to realities such as data spaces where open data is presented as a key element.
Click on the infographic to see it full size:
Noticia
On 21 February, the winners of the 6th edition of the Castilla y León Open Data Competition were presented with their prizes. This competition, organised by the Regional Ministry of the Presidency of the Regional Government of Castilla y León, recognises projects that provide ideas, studies, services, websites or mobile applications, using datasets from its Open Data Portal.
The event was attended, among others, by Jesús Julio Carnero García, Minister of the Presidency, and Rocío Lucas Navas, Minister of Education of the Junta de Castilla y León.
In his speech, the Minister Jesús Julio Carnero García emphasised that the Regional Government is going to launch the Data Government project, with which they intend to combine Transparency and Open Data, in order to improve the services offered to citizens.
In addition, the Data Government project has an approved allocation of almost 2.5 million euros from the Next Generation Funds, which includes two lines of work: both the design and implementation of the Data Government model, as well as the training for public employees.
This is an Open Government action which, as the Councillor himself added, "is closely related to transparency, as we intend to make Open Data freely available to everyone, without copyright restrictions, patents or other control or registration mechanisms".
Nine prize-winners in the 6th edition of the Castilla y León Open Data Competition
It is precisely in this context that initiatives such as the 6th edition of the Castilla y León Open Data Competition stand out. In its sixth edition, it has received a total of 26 proposals from León, Palencia, Salamanca, Zamora, Madrid and Barcelona.
In this way, the 12,000 euros distributed in the four categories defined in the rules have been distributed among nine of the above-mentioned proposals. This is how the awards were distributed by category:
Products and Services Category: aimed at recognising projects that provide studies, services, websites or applications for mobile devices and that are accessible to all citizens via the web through a URL.
- First prize: 'Oferta de Formación profesional de Castilla y León. An attractive and accessible alternative with no-cod tools'". Author: Laura Folgado Galache (Zamora). 2,500 euros.
- Second prize: 'Enjoycyl: collection and exploitation of assistance and evaluation of cultural activities'. Author: José María Tristán Martín (Palencia). 1,500 euros.
- Third prize: 'Aplicación del problema de la p-mediana a la Atención Primaria en Castilla y León'. Authors: Carlos Montero and Ernesto Ramos (Salamanca) 500 euros.
- Student prize: 'Play4CyL'. Authors: Carlos Montero and Daniel Heras (Salamanca) 1,500 euros.
Ideas category: seeks to reward projects that describe an idea for developing studies, services, websites or applications for mobile devices.
- First prize: 'Elige tu Universidad (Castilla y León)'. Authors: Maite Ugalde Enríquez and Miguel Balbi Klosinski (Barcelona) 1,500 euros.
- Second prize: 'Bots to interact with open data - Conversational interfaces to facilitate access to public data (BODI)'. Authors: Marcos Gómez Vázquez and Jordi Cabot Sagrera (Barcelona) 500 euros
Data Journalism Category: awards journalistic pieces published or updated (in a relevant way) in any medium (written or audiovisual).
- First prize: '13-F elections in Castilla y León: there will be 186 fewer polling stations than in the 2019 regional elections'. Authors: Asociación Maldita contra la desinformación (Madrid) 1,500 euros.
- Second prize: 'More than 2,500 mayors received nothing from their city council in 2020 and another 1,000 have not reported their salary'. Authors: Asociación Maldita contra la desinformación (Madrid). 1,000 euros.
Didactic Resource Category: recognises the creation of new and innovative open didactic resources (published under Creative Commons licences) that support classroom teaching.
In short, and as the Regional Ministry of the Presidency itself points out, with this type of initiative and the Open Data Portal, two basic principles are fulfilled: firstly, that of transparency, by making available to society as a whole data generated by the Community Administration in the development of its functions, in open formats and with a free licence for its use; and secondly, that of collaboration, allowing the development of shared initiatives that contribute to social and economic improvements through joint work between citizens and public administrations.
Blog
16.5 billion euros. These are the revenues that artificial intelligence (AI) and data are expected to generate in Spanish industry by 2025, according to what was announced last February at the IndesIA forum, the association for the application of artificial intelligence in industry. AI is already part of our daily lives: either by making our work easier by performing routine and repetitive tasks, or by complementing human capabilities in various fields through machine learning models that facilitate, for example, image recognition, machine translation or the prediction of medical diagnoses. All of these activities help us to improve the efficiency of businesses and services, driving more accurate decision-making.
But for machine learning models to work properly, they need quality and well-documented data. Every machine learning model is trained and evaluated with data. The characteristics of these datasets condition the behaviour of the model. For example, if the training data reflects unwanted social biases, these are likely to be incorporated into the model as well, which can have serious consequences when used in high-profile areas such as criminal justice, recruitment or credit lending. Moreover, if we do not know the context of the data, our model may not work properly, as its construction process has not taken into account the intrinsic characteristics of the data on which it is based.
For these and other reasons, the World Economic Forum suggests that all entities should document the provenance, creation and use of machine learning datasets in order to avoid erroneous or discriminatory results..
What are datasheets for datasets?
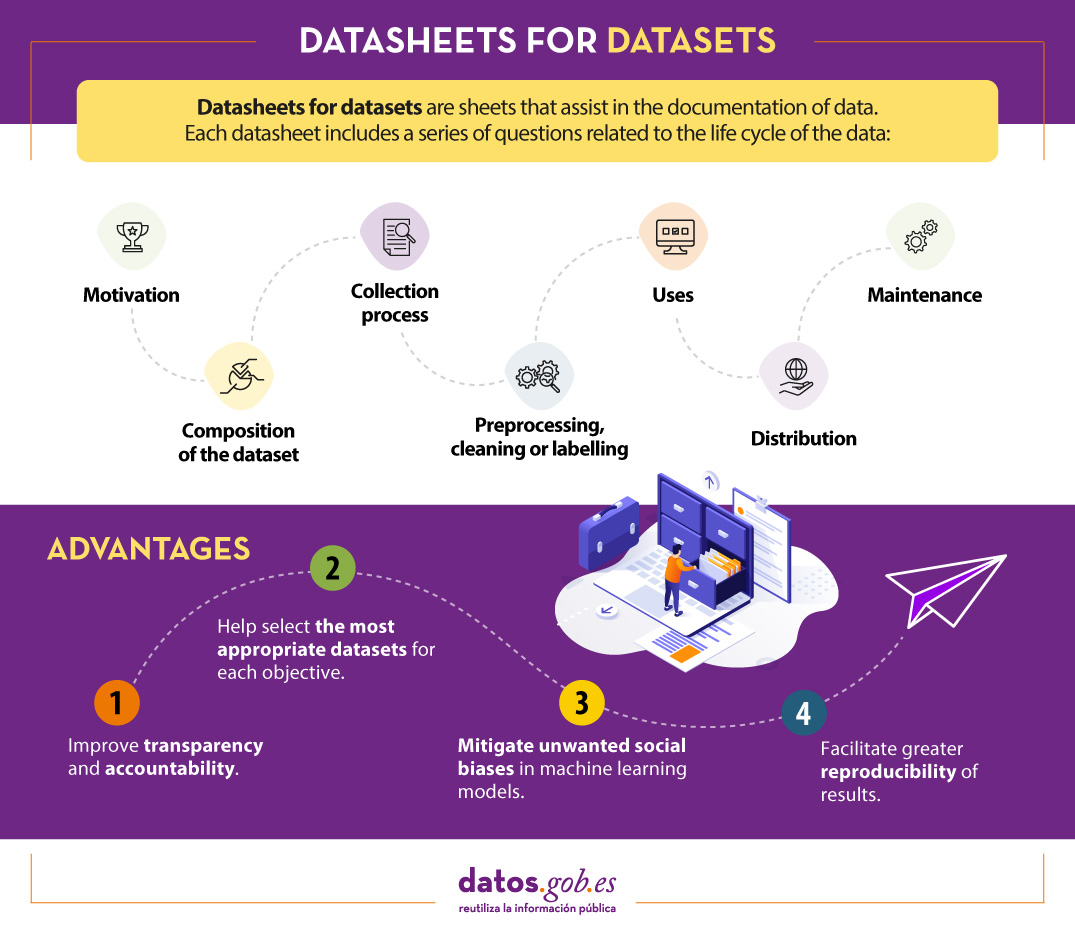
One mechanism for documenting this information is known as Datasheets for datasets. This framework proposes that every dataset should be accompanied by a datasheet, which consists of a questionnaire that guides data documentation and reflection throughout the data lifecycle. Some of the benefits are:
- It improves collaboration, transparency and accountability within the machine learning community.
- Mitigates unwanted social biases in models.
- Helps researchers and developers select the most appropriate datasets to achieve their specific goals.
- Facilitates greater reproducibility of results.
Datasheets will vary depending on factors such as knowledge area, existing organisational infrastructure or workflows.
To assist in the creation of datasheets, a questionnaire has been designed with a series of questions, according to the stages of the data lifecycle:
- Motivation. Collects the reasons that led to the creation of the datasets. It also asks who created or funded the datasets.
- Composition. Provides users with the necessary information on the suitability of the dataset for their purposes. It includes, among other questions, which units of observation represent the dataset (documents, photos, persons, countries), what kind of information each unit provides or whether there are errors, sources of noise or redundancies in the dataset. Reflect on data that refer to individuals to avoid possible social biases or privacy violations.
- Collection process. It is intended to help researchers and users think about how to create alternative datasets with similar characteristics. It details, for example, how the data were acquired, who was involved in the collection process, or what the ethical review process was like. It deals especially with the ethical aspects of processing data protected by the GDPR.
- Preprocessing, cleansing or tagging. These questions allow data users to determine whether data have been processed in ways that are compatible with their intended uses. Inquire whether any preprocessing, cleansing or tagging of the data was performed, or whether the software that was used to preprocess, cleanse and tag the data is available.
- Uses. This section provides information on those tasks for which the data may or may not be used. For this, questions such as: Has the dataset already been used for any task? What other tasks can it be used for? Does the composition of the dataset or the way it was collected, preprocessed, cleaned and labelled affect other future uses?
- Distribution. This covers how the dataset will be disseminated. Questions focus on whether the data will be distributed to third parties and, if so, how, when, what are the restrictions on use and under what licences.
- Maintenance. The questionnaire ends with questions aimed at planning the maintenance of the data and communicating the plan to the users of the data. For example, answers are given to whether the dataset will be updated or who will provide support.
It is recommended that all questions are considered prior to data collection, so that data creators can be aware of potential problems. To illustrate how each of these questions could be answered in practice, the model developers have produced an appendix with an example for a given dataset.
Is Datasheets for datasets effective?
The Datasheets for datasets data documentation framework has initially received good reviews, but its implementation continues to face challenges, especially when working with dynamic data.
To find out whether the framework effectively addresses the documentation needs of data creators and users, in June 2022, Microsoft USA and the University of Michigan conducted a study on its implementation. To do so, they conducted a series of interviews and a follow-up on the implementation of the questionnaire by a number of machine learning professionals.
In summary, participants expressed the need for documentation frameworks to be adaptable to different contexts, to be integrated into existing tools and workflows, and to be as automated as possible, partly due to the length of the questions. However, they also highlighted its advantages, such as reducing the risk of information loss, promoting collaboration between all those involved in the data lifecycle, facilitating data discovery and fostering critical thinking, among others.
In short, this is a good starting point, but it will have to evolve, especially to adapt to the needs of dynamic data and documentation flows applied in different contexts.
Content prepared by the datos.gob.es team.
Blog
One of the key actions that we recently highlighted as necessary to build the future of open data in our country is the implementation of processes to improve data management and governance. It is no coincidence that proper data management in our organisations is becoming an increasingly complex and in-demand task. Data governance specialists, for example, are increasingly in demand - with more than 45,000 active job openings in the US for a role that was virtually non-existent not so long ago - and dozens of data management platforms now advertise themselves as data governance platforms.
But what's really behind these buzzwords - what is it that we really mean by data governance? In reality, what we are talking about is a series of quite complex transformation processes that affect the whole organisation.
This complexity is perfectly reflected in the framework proposed by the Open Data Policy Lab, where we can clearly see the different overlapping layers of the model and what their main characteristics are - leading to a journey through the elaboration of data, collaboration with data as the main tool, knowledge generation, the establishment of the necessary enabling conditions and the creation of added value.
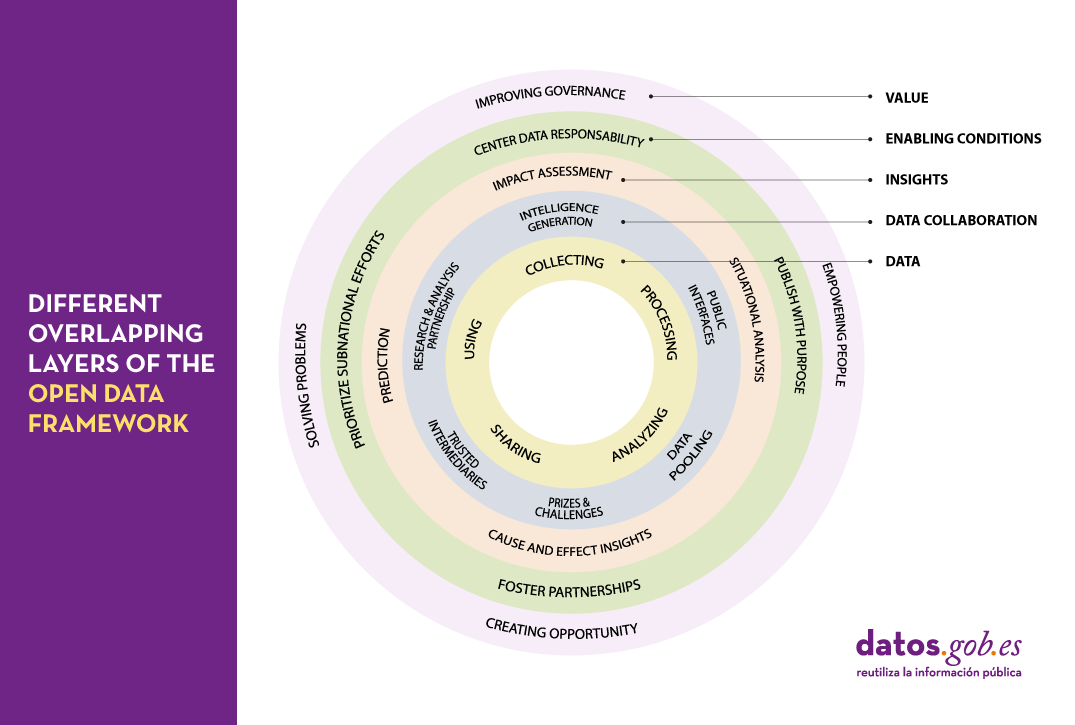
Let's now peel the onion and take a closer look at what we will find in each of these layers:
The data lifecycle
We should never consider data as isolated elements, but as part of a larger ecosystem, which is embedded in a continuous cycle with the following phases:
- Collection or collation of data from different sources.
- Processing and transformation of data to make it usable.
- Sharing and exchange of data between different members of the organisation.
- Analysis to extract the knowledge being sought.
- Using data according to the knowledge obtained.
Collaboration through data
It is not uncommon for the life cycle of data to take place solely within the organisation where it originates. However, we can increase the value of that data exponentially, simply by exposing it to collaboration with other organisations through a variety of mechanisms, thus adding a new layer of management:
- Public interfaces that provide selective access to data, enabling new uses and functions.
- Trusted intermediaries that function as independent data brokers. These brokers coordinate the use of data by third parties, ensuring its security and integrity at all times.
- Data pooling that provide a common, joint, complete and coherent view of data by aggregating portions from different sources.
- Research and analysis partnership, granting access to certain data for the purpose of generating specific knowledge.
- Prizes and challenges that give access to specific data for a limited period of time to promote new innovative uses of data.
- Intelligence generation, whereby the knowledge acquired by the organisation through the data is also shared and not just the raw material.
Insight generation
Thanks to the collaborations established in the previous layer, it will be possible to carry out new studies of the data that will allow us both to analyse the past and to try to extrapolate the future using various techniques such as:
- Situational analysis, knowing what is happening in the data environment.
- Cause and effect insigths, looking for an explanation of the origin of what is happening.
- Prediction, trying to infer what will happen next.
- Impact assessment, establishing what we expect should happen.
Enabling conditions
There are a number of procedures that when applied on top of an existing collaborative data ecosystem can lead to even more effective use of data through techniques such as:
- Publish with a purpose, with the aim of coordinating data supply and demand as efficiently as possible.
- Foster partnerships, including in our analysis those groups of people and organisations that can help us better understand real needs.
- Prioritize subnational efforts, strengthening of alternative data sources by providing the necessary resources to create new data sources in untapped areas.
- Center data responsability, establishing an accountability framework around data that takes into account the principles of fairness, engagement and transparency.
Value generation
Scaling up the ecosystem -and establishing the right conditions for that ecosystem to flourish- can lead to data economies of scale from which we can derive new benefits such as:
- Improving governance and operations of the organisation itself through the overall improvements in transparency and efficiency that accompany openness processes.
- Empowering people by providing them with the tools they need to perform their tasks in the most appropriate way and make the right decisions.
- Creating new opportunities for innovation, the creation of new business models and evidence-led policy making.
- Solving problems by optimising processes and services and interventions within the system in which we operate.
As we can see, the concept of data governance is actually much broader and more complex than one might initially expect and encompasses a number of key actions and tasks that in most organisations it will be practically impossible to try to centralise in a single role or through a single tool. Therefore, when establishing a data governance system in an organisation, we should face the challenge as an integral transformation process or a paradigm shift in which practically all members of the organisation should be involved to a greater or lesser extent. A good way to face this challenge with greater ease and better guarantees would be through the adoption and implementation of some of the frameworks and reference standards that have been created in this respect and that correspond to different parts of this model.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Transforming data into knowledge has become one of the main objectives facing both public and private organizations today. But, in order to achieve this, it is necessary to start from the premise that the data processed is governed and of quality.
In this sense, the Spanish Association for Standardization (UNE) has recently published an article and report where different technical standards are collected that seek to guarantee the correct management and governance of an organization's data. Both materials are collected in this post , including an infographic-summary of the highlighted standards.
In the aforementioned reference articles, technical standards related to governance, management, quality, security and data privacy are mentioned. On this occasion we want to zoom in on those focused on data quality.
Quality management reference standards
As Lord Kelvin, a 19th-century British physicist and mathematician, said, “what is not measured cannot be improved, and what is not improved is always degraded”. But to measure the quality of the data and to be able to improve it, standards are needed to help us first homogenize said quality* . The following technical standards can help us with this:
ISO 8000 standard
The ISO ( International Organization for Standardization ) regulation has ISO 8000 as the international standard for the quality of transaction data, product data and business master data . This standard is structured in 4 parts: general concepts of data quality (ISO 8000-1, ISO 8000-2 and ISO 8000-8), data quality management processes (ISO 8000-6x), aspects related to the exchange of master data between organizations (parts 100 to 150) and application of product data quality (ISO 8000-311).
Within the ISO 8000-6X family , focused on data quality management processes to create, store and transfer data that support business processes in a timely and profitable manner, we find:
- ISO 8000-60 provides an overview of data quality management processes subject to a cycle of continuous improvement.
- ISO 8000-61 establishes a reference model for data quality management processes. The main characteristic is that, in order to achieve continuous improvement, the implementation process must be executed continuously following the Plan-Do-Check-Act cycle . In addition, implementation processes related to resource provisioning and data processing are included. As shown in the following image, the four stages of the implementation cycle must have input data, control information and support for continuous improvement, as well as the necessary resources to carry out the activities.
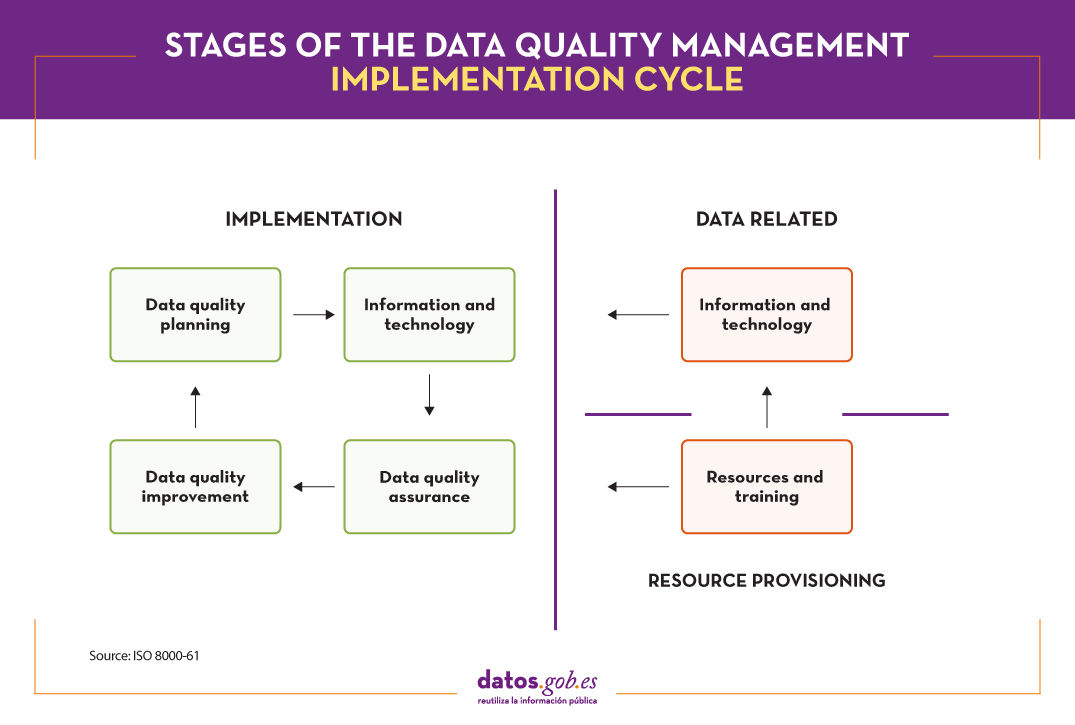
- For its part, ISO 8000-62 , the last of the ISO 8000-6X family, focuses on the evaluation of organizational process maturity . It specifies a framework for assessing the organization's data quality management maturity, based on its ability to execute the activities related to the data quality management processes identified in ISO 8000-61. . Depending on the capacity of the evaluated process, one of the defined levels is assigned.
ISO 25012 standard
Another of the ISO standards that deals with data quality is the ISO 25000 family , which aims to create a common framework for evaluating data quality.cinquality of the software product. Specifically, the ISO 25012 standard defines a general data quality model applicable to data stored in a structured way in an information system.
In addition, in the context of open data, it is considered a reference according to the set of good practices for the evaluation of the quality of open data developed by the pan-European network Share-PSI , conceived to serve as a guide for all public organizations to time to share information.
In this case, the quality of the data product is understood as the degree to which it satisfies the requirements previously defined in the data quality model through the following 15 characteristics.
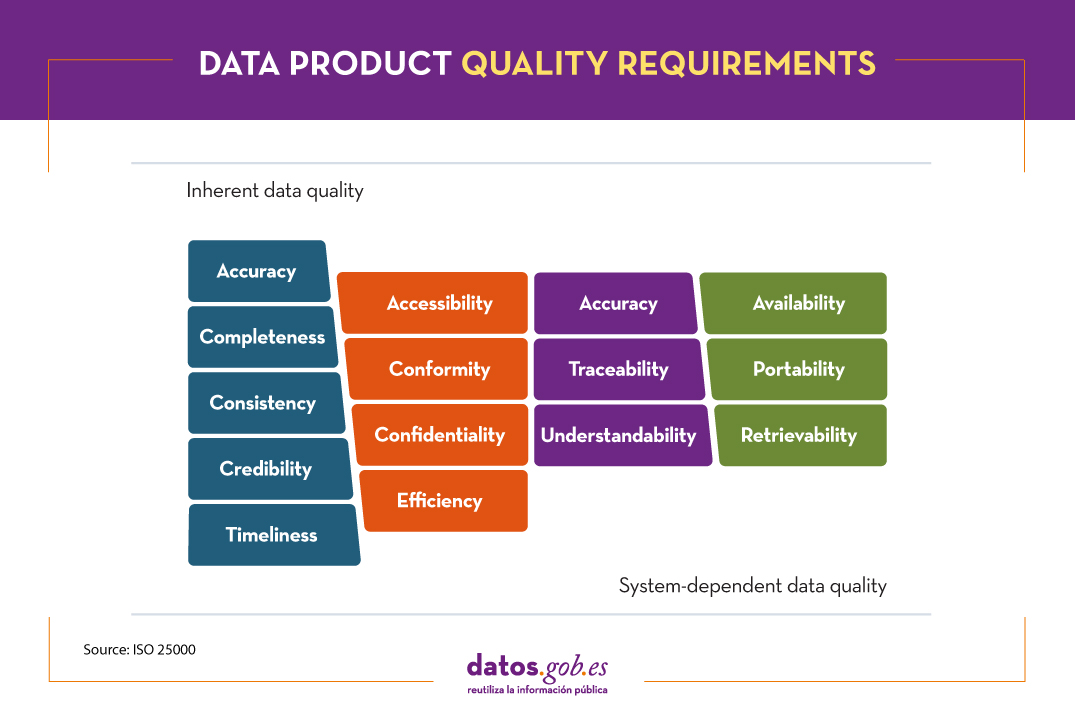
These quality characteristics or dimensions are mainly classified into two categories.
Inherent data quality relates to the intrinsic potential of data to meet defined needs when used under specified conditions. Is about:
- Accuracy : degree to which the data represents the true value of the desired attribute in a specific context, such as the closeness of the data to a set of values defined in a certain domain.
- Completeness – The degree to which the associated data has value for all defined attributes.
- Consistency : degree of consistency with other existing data, eliminating contradictions.
- Credibility – The degree to which the data has attributes that are considered true and credible in its context, including the veracity of the data sources.
- Up-to- dateness : degree of validity of the data for its context of use.
On the other hand, system-dependent data quality is related to the degree achieved through a computer system under specific conditions. Is about:
- Availability : degree to which the data has attributes that allow it to be obtained by authorized users.
- Portability : ability of data to be installed, replaced or deleted from one system to another, preserving the level of quality.
- Recoverability – The degree to which data has attributes that allow quality to be maintained and preserved even in the event of failures.
Additionally, there are characteristics or dimensions that can be encompassed both within " inherent" and "system-dependent" data quality . These are:
- Accessibility : possibility of access to data in a specific context by certain roles.
- Conformity : degree to which the data contains attributes based on established standards, regulations or references.
- Confidentiality : measures the degree of data security based on its nature so that it can only be accessed by the configured roles.
- Efficiency : possibilities offered by the data to be processed with expected performance levels in specific situations.
- Accuracy : Accuracy of the data based on a specific context of use.
- Traceability : ability to audit the entire life cycle of the data.
- Comprehensibility : ability of the data to be interpreted by any user, including the use of certain symbols and languages for a specific context.
In addition to ISO standards, there are other reference frameworks that establish common guidelines for quality measurement. DAMA International , for example, after analyzing the similarities of all the models, establishes 8 basic quality dimensions common to any standard: accuracy, completeness, consistency, integrity, reasonableness, timeliness, uniqueness, validity .
The need for continuous improvement
The homogenization of the quality of the data according to reference standards such as those described, allow laying the foundations for a continuous improvement of the information. From the application of these standards, and taking into account the detailed dimensions, it is possible to define quality indicators. Once they are implemented and executed, they will yield results that will have to be reviewed by the different owners of the data , establishing tolerance thresholds and thus identifying quality incidents in all those indicators that do not exceed the defined threshold.
To do this, different parameters will be taken into account, such as the nature of the data or its impact on the business, since a descriptive field cannot be treated in the same way as a primary key, for example.
From there, it is common to launch an incident resolution circuit capable of detecting the root cause that generates a quality deficiency in a data to extract it and guarantee continuous improvement.
Thanks to this, innumerable benefits are obtained, such as minimizing risks, saving time and resources, agile decision-making, adaptation to new requirements or reputational improvement.
It should be noted that the technical standards addressed in this post allow quality to be homogenized. For data quality measurement tasks per se, we should turn to other standards such as ISO 25024:2015 .
Content prepared by Juan Mañes, expert in Data Governance.
The contents and views expressed in this publication are the sole responsibility of the author.
Documentación
Data is a key pillar of digital transformation. Reliable and quality data are the basis of everything, from the main strategic decisions to the routine operational process, they are fundamental in the development of data spaces, as well as the basis of disruptive solutions linked to fields such as artificial intelligence or Big Data.
In this sense, the correct management and governance of data has become a strategic activity for all types of organizations, public and private.
Data governance standardization is based on 4 principles:
- Governance
- Management
- Quality
- Security and data privacy
Those organizations that want to implement a solid governance framework based on these pillars have at their disposal a series of technical standards that provide guiding principles to ensure that an organization's data is properly managed and governed, both internally and by external contracts.
With the aim of trying to clarify doubts in this matter, the Spanish Association for Standardization (UNE), has published various support materials.
The first is an article on the different technical standards to consider when developing effective data governance . The rules contained in said article, together with some additional ones, are summarized in the following infographic:
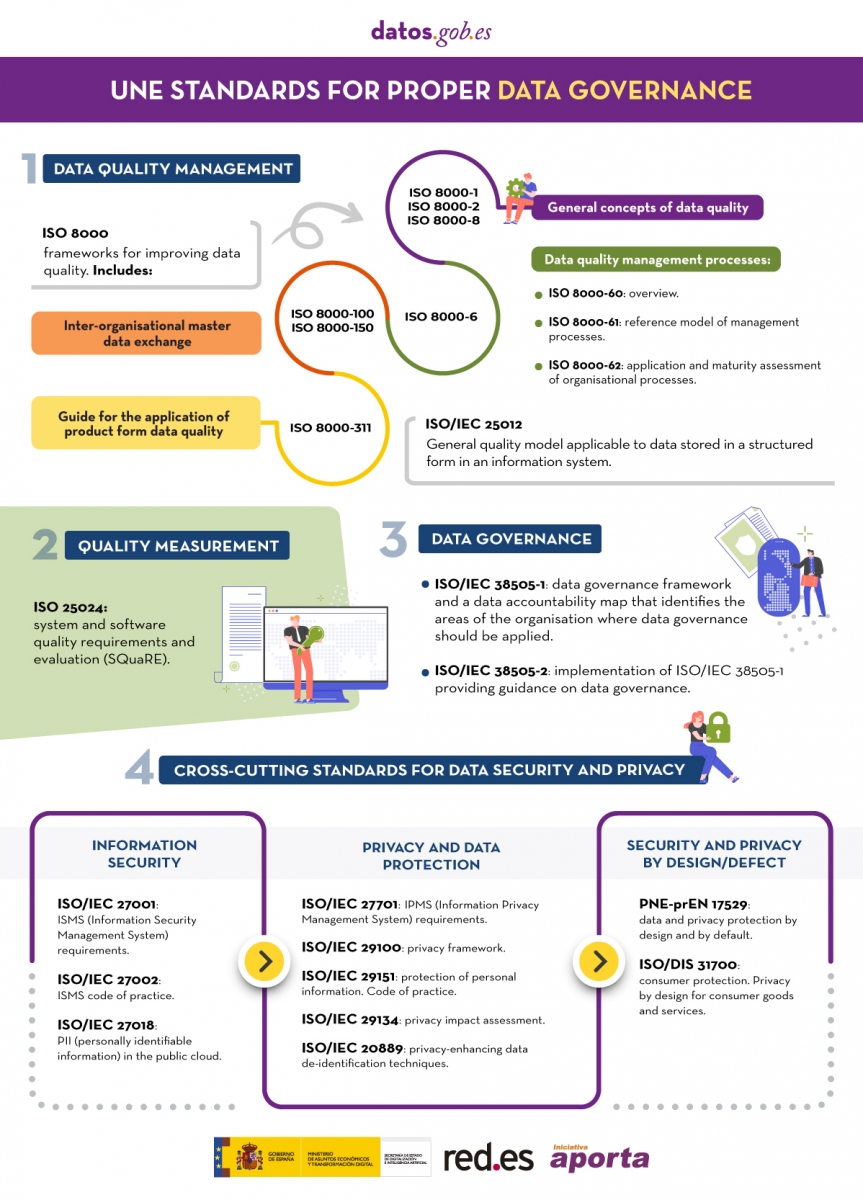
(You can download the accessible version in word here)
In addition, the UNE has also published the report "Standards for the data economy" , which can be downloaded at the end of this article. The report begins with an introduction where the European legislative context that is promoting the Data Economy is deepened and the recognition that it makes of technical standardization as a key tool when it comes to achieving the objectives set. The technical standards included in the previous infographic are analyzed in more detail below.
Blog
Data has occupied a fundamental place in our society in recent years. New technologies have enabled a data-driven globalization in which everything that happens in the world is interconnected. Using simple techniques, it is possible to extract value from them that was unimaginable just a few years ago. However, in order to make proper use of data, it is necessary to have good documentation, through a data dictionary.
What is a data dictionary?
It is common that when we talk about data dictionary, it is confused with business glossary or data vocabulary, however, they are different concepts.
While a business glossary, or data vocabulary, tries to give functional meaning to the indicators or concepts that are handled in a way that ensures that the same language is spoken, abstracting from the technical world, as explained in this article, a data dictionary tries to document the metadata most closely linked to its storage in the database. In other words, it includes technical aspects such as the type of data, format, length, possible values it can take and even the transformations it has undergone, without forgetting the definition of each field. The documentation of these transformations will automatically provide us with the lineage of the data, understood as the traceability throughout its life cycle. This metadata helps users to understand the data from a technical point of view in order to be able to use it properly. For this reason, each database should have its associated data dictionary.
For the completion of the metadata requested in a data dictionary, there are pre-designed guides and templates such as the following example provided by the U.S. Department of Agriculture.
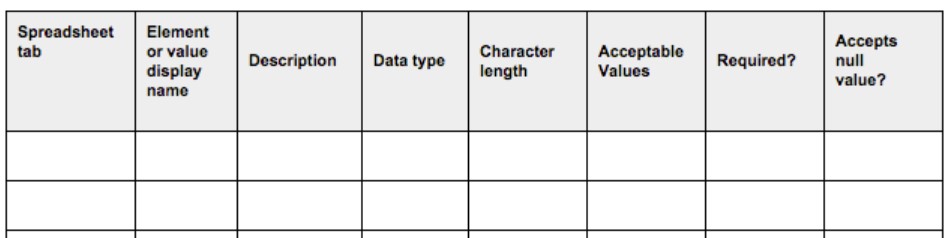
In addition, in order to standardize its content, taxonomies and controlled vocabularies are often used to encode values according to code lists.
Finally, a data catalog acts as a directory to locate information and make it available to users, providing all users with a single point of reference for accessing it. This is made possible by bridging functional and technical terms through the lineage.
Open data applicability
When we talk about open data, data dictionaries become even more important, as they are made available to third parties and their usability is much greater.
Each dataset should be published together with its data dictionary, describing the content of each column. Therefore, when publishing an open dataset, a URL to the document containing its data dictionary should also be published, regardless of its format. In cases where more than one Data Dictionary is required, due to the variety of the originating sources, as many as necessary should be added, generally one per database or table.
Unfortunately, however, it is easy to find datasets extracted directly from information systems without adequate preparation and without an associated data dictionary provided by the publishers. This may be due to several factors, such as a lack of knowledge of this type of tool that facilitates documentation, not knowing for sure how to create a dictionary, or simply assuming that the user knows the contents of the fields.
However, the consequences of publishing data without documenting them correctly may result in the user seeing data referring to unreadable acronyms or technical names, making it impossible to process them or even making inappropriate use of them due to ambiguity and misinterpretation of the contents.
To facilitate the creation of this type of documentation, there are standards and technical recommendations from some organizations. For example, the World Wide Web Consortium (W3C), the body that develops standards to ensure the long-term growth of the World Wide Web, has issued a model recommending how to publish tabular data such as CSV and metadata on the Web.
Interpreting published data
An example of a good data publication can be found in this dataset published by the National Statistics Institute (INE) and available at datos.gob.es, which indicates "the number of persons between 18 and 64 years of age according to the most frequent mother tongue and non-mother tongue languages they may use, by parental characteristics". For its interpretation, the INE provides all the necessary details for its understanding in a URL, such as the units of measurement, sources, period of validity, scope and the methodology followed for the preparation of these surveys. In addition, it provides self-explanatory functional names for each column to ensure the understanding of its meaning by any user outside the INE. All of this allows the user to know with certainty the information he/she is downloading for consumption, avoiding misunderstandings. This information is shared in the "related resources" section, designed for this purpose. This is a metadata describing the dct:references property.
Although this example may seem logical, it is not uncommon to find cases on the opposite side. For illustrative purposes, a fictitious example dataset is shown as follows:

In this case, a user who does not know the database will not know how to correctly interpret the meaning of the fields "TPCHE", "YFAB", "NUMC" ... However, if this table is associated with a data dictionary, we can relate the metadata to the set, as shown in the following image:

In this case, we have chosen to publish the data dictionary by means of a text document describing the fields, although there are many ways of publishing the dictionaries. It can be done following recommendations and standards, such as the one mentioned above by the W3C, by means of text files, as in this case, or even by means of Excel templates customized by the publisher itself. As a general rule, there is no one way that is better than another, but it must be adapted to the nature and complexity of the dataset in order to ensure its comprehension, planning the level of detail required depending on the final objective, the audience receiving the data and the needs of consumers, as explained in this post.
Open data is born with the aim of facilitating the reuse of information for everyone, but for such access to be truly useful, it cannot be limited only to the publication of raw datasets, but must be clearly documented for proper processing. The development of data dictionaries that include the technical details of the datasets that are published is essential for their correct reuse and the extraction of value from them.
Content prepared by Juan Mañes, expert in Data Governance.
The contents and views expressed in this publication are the sole responsibility of the author.