Blog
We live in an era where science is increasingly reliant on data. From urban planning to the climate transition, data governance has become a structural pillar of evidence-based decision-making. However, there is one area where the traditional principles of data management, validation and control are subjected to extreme tensions: the universe.
Space data—produced by scientific satellites, telescopes, interplanetary probes, and exploration missions— do not describe accessible or repeatable realities. They observe phenomena that occurred millions of years ago, at distances impossible to travel and under conditions that can never be replicated in the laboratory. There is no "in situ" measurement that directly confirms these phenomena.
In this context, data governance ceases to be an organizational issue and becomes a structural element of scientific trust. Quality, traceability and reproducibility cannot be supported by direct physical references, but by methodological transparency, comprehensive documentation and the robustness of instrumental and theoretical frameworks.
Governing data in the universe therefore involves facing unique challenges: managing structural uncertainty, documenting extreme scales, and ensuring trust in information we can never touch.
Below, we explore the main challenges posed by data governance when the object of study is beyond Earth.
I. Specific challenges of the datum of the universe
1. Beyond Earth: new sources, new rules
When we talk about space data, we mean much more than satellite images of the Earth's surface. We delve into a complex ecosystem that includes space and ground-based telescopes, interplanetary probes, planetary exploration missions, and observatories designed to detect radiation, particles, or extreme physical phenomena.
These systems generate data with clearly different challenges compared to other scientific domains:
| Challenge | Impact on data governance |
|---|---|
| Non-existent physical access | There is no direct validation; Trust lies in the integrity of the channel. |
| Instrumental dependence | The data is a direct "child" of the sensor's design. If the sensor fails or is out of calibration, reality is distorted. |
| Uniqueness | Many astronomical events are unique. There is no "second chance" to capture them. |
| Extreme cost | The value of each byte is very high due to the investment required to put the sensor into orbit |
Figure 1. Challenges in data governance across the universe. Source: own elaboration - datos.gob.es.
Unlike Earth observation data -which in many cases can be contrasted by field campaigns or redundant sensors -data from the universe depend fundamentally on the mission architecture, instrument calibration, and physical models used to interpret the captured signal.
In many cases, what is recorded is not the phenomenon itself, but an indirect signal: spectral variations, electromagnetic emissions, gravitational alterations or particles detected after traveling millions of kilometers. The data is, in essence, an instrumental translation of an inaccessible phenomenon.
For all these reasons, in space data cannot be understood without the technical context that generates it.
2. Structural uncertainty and extreme scales
Uncertainty refers to the degree of margin of error or indeterminacy associated with a scientific measurement, interpretation, or result due to the limits of the instruments, observing conditions, and models used to analyze the data. If in other areas uncertainty is a factor that is tried to be reduced by direct, repeatable and verifiable measurements, in the observation of the universe uncertainty is part of the knowledge process itself. It is not simply a matter of "not knowing enough", but of facing physical and methodological limits that cannot be completely eliminated.
Therefore, in the observation of the universe, uncertainty is structural. It is not a specific anomaly, but a condition inherent to the object of study.
There are several critical dimensions:
- Extreme spatial and temporal scales: cosmic distances prevent any direct validation. Timescales imply that the data often captures an "instant" of the remote past and not a verifiable present reality.
- Weak signals and unavoidable noise: the instruments capture extremely subtle emissions. The useful signal coexists with interference, technological limitations and background noise. Interpretation depends on advanced statistical treatments and complex physical models.
- Limited-observation phenomena: Some astrophysical phenomena—such as certain supernovae, gamma-ray bursts, or singular gravitational configurations—cannot be experimentally recreated and can only be observed when they occur. In these cases, the available record may be unique or profoundly limited, increasing the responsibility for documentation and preservation.
Not all phenomena are unrepeatable, but in many cases the opportunities for observation are scarce or depend on exceptional conditions.
II. Building trust when we can't touch the object observed
In the face of these challenges, data governance takes on a structural role. It is not limited to guaranteeing storage or availability, but defines the rules by which scientific processes are documented, traceable and auditable.
In this context, governing does not mean producing knowledge, but rather ensuring that its production is transparent, verifiable and reusable.
1. Quality without direct physical validation
When the observed phenomenon cannot be directly verified, the quality of the data is based on:
- Rigorous calibration protocols: instruments must undergo systematic calibration processes before, during, and after operation. This involves adjusting your measurements against known baselines, characterizing your margins of error, documenting deviations, and recording any modifications to your configuration. Calibration is not a one-off event, but an ongoing process that ensures that the recorded signal reflects, as accurately as possible, the observed phenomenon within the physical boundaries of the system.
- Cross-validation between independent instruments: when different instruments – either on the same mission or on different missions – observe a similar phenomenon, the comparison of results allows the reliability of the data to be reinforced. The convergence between observations obtained with different technologies reduces the probability of instrumental bias or systematic errors. This inter-instrumental coherence acts as an indirect verification mechanism.
- Observational repetition when possible: although not all phenomena can be repeated, many observations can be made at different times or under different conditions. Repetition allows to evaluate the stability of the signal, identify anomalies and estimate natural variability against measurement error. Consistency over time strengthens the robustness of the result.
- Peer review and progressive scientific consensus: the data and their interpretations are subject to evaluation by the scientific community. This process involves methodological scrutiny, critical analysis of assumptions, and verification of consistency with existing knowledge. Consensus does not emerge immediately, but through the accumulation of evidence and scientific debate. Quality, in this sense, is also a collective construction.
Quality is not just a technical property; it is the result of a documented and auditable process.
2. Complete scientific traceability
In the spatial context, data is inseparable from the technical and scientific process that generates it. It cannot be understood as an isolated result, but as the culmination of a chain of instrumental, methodological and analytical decisions.
Therefore, traceability must explicitly and documented:
- Instrument design and configuration: information about the technical characteristics of the instrument that captured the signal, such as its architecture, sensing capabilities, resolution limits, and operational configurations, needs to be retained. These conditions determine what type of signal can be recorded and how accurately.
- Calibration parameters: The adjustments applied to ensure that the instrument operates within the intended margins must be recorded, as well as the modifications made over time. The calibration parameters directly influence the interpretation of the obtained signal.
- Processing software versions: the processing of raw data depends on specific IT tools. Preserving the versions used allows you to understand how the results were generated and avoid ambiguities if the software evolves.
- Algorithms applied in noise reduction: since signals are often accompanied by interference or background noise, it is essential to document the methods used to filter, clean, or transform the information before analysis. These algorithms influence the final result.
- Scientific assumptions used in the interpretation: the reading of the data is not neutral: it is based on theoretical frameworks and physical models accepted at the time of analysis. Recording these assumptions allows you to contextualize the conclusions and understand possible future revisions.
- Successive transformations from the raw data to the published data: from the original signal to the final scientific product, the data goes through different phases of processing, aggregation and analysis. Each transformation must be able to be reconstructed to understand how the communicated result was reached.
Without exhaustive traceability, reproducibility is weakened and future interpretability is compromised. When it is not possible to reconstruct the entire process that led to a result, its independent evaluation becomes limited and its scientific reuse loses its robustness.
3. Long-term reproducibility
Space missions can span decades, and their data can remain relevant long after the mission has ended. In addition, scientific interpretation evolves over time: new models, new tools, and new questions may require reanalyzing information generated years ago.
Therefore, data must remain interpretable even when the original equipment no longer exists, technological systems have changed, or the scientific context has evolved.
This requires:
- Rich and structured metadata: the contextual information that accompanies the data – about its origin, acquisition conditions, processing and limitations – must be organized in a clear and standardized way. Without sufficient metadata, the data loses meaning and becomes difficult to reinterpret in the future.
- Persistent identifiers: Each dataset must be able to be located and cited in a stable manner over time. Persistent identifiers allow the reference to be maintained even if storage systems or technology infrastructures change.
- Robust digital preservation policies: Long-term preservation requires strategies that take into account format obsolescence, technological migration, and archive integrity. It is not enough to store; It is necessary to ensure that the data remains accessible and readable over time.
- Accessible documentation of processing pipelines: the process that transforms raw data into scientific product must be described in a comprehensible way. This allows future researchers to reconstruct the analysis, verify the results, or apply new methods on the same original data.
Reproducibility, in this context, does not mean physically repeating the observed phenomenon, but being able to reconstruct the analytical process that led to a given result. Governance doesn't just manage the present; It ensures the future reuse of knowledge and preserves the ability to reinterpret information in the light of new scientific advances.
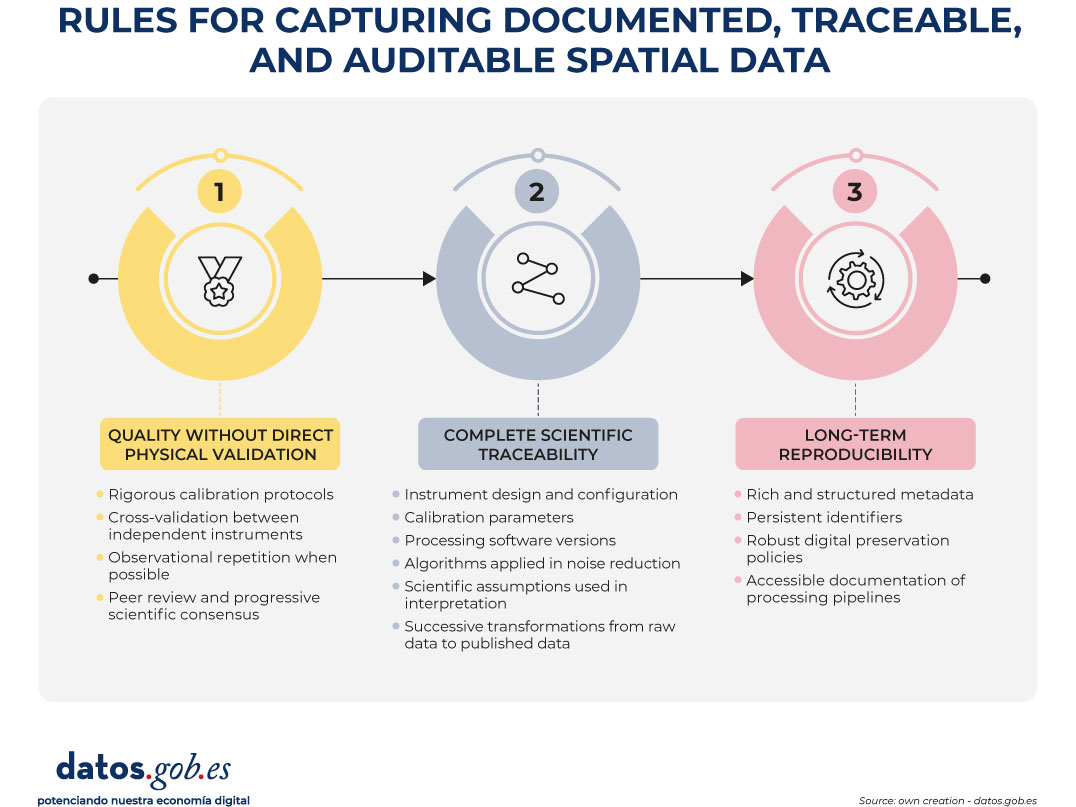
Figure 2. Rules for capturing documented, traceable, and auditable spatial data. Source: own elaboration - datos.gob.es.
Conclusion: Governing What We Can't Touch
The data of the universe forces us to rethink how we understand and manage information. We are working with realities that we cannot visit, touch or verify directly. We observe phenomena that occur at immense distances and in times that exceed the human scale, through highly specialized instruments that translate complex signals into interpretable data.
In this context, uncertainty is not a mistake or a weakness, but a natural feature of the study of the cosmos. The interpretation of data depends on scientific models that evolve over time, and quality is not based on direct verification, but on rigorous processes, well documented and reviewed by the scientific community. Trust, therefore, does not arise from direct experience, but from the transparency, traceability and clarity with which the methods used are explained.
Governing spatial data does not only mean storing it or making it available to the public. It means keeping all the information that allows us to understand how they were obtained, how they were processed and under what assumptions they were interpreted. Only then can they be evaluated, reinterpreted and reused in the future.
Beyond Earth, data governance is not a technical detail or an administrative task. It is the foundation that sustains the credibility of human knowledge about the universe and the basis that allows new generations to continue exploring what we cannot yet achieve physically.
Content prepared by Mayte Toscano, Senior Consultant in technologies related to the data economy. The contents and viewpoints expressed in this publication are the sole responsibility of the author.
Blog
At the crossroads of the 21st century, cities are facing challenges of enormous magnitude. Explosive population growth, rapid urbanization and pressure on natural resources are generating unprecedented demand for innovative solutions to build and manage more efficient, sustainable and livable urban environments.
Added to these challenges is the impact of climate change on cities. As the world experiences alterations in weather patterns, cities must adapt and transform to ensure long-term sustainability and resilience.
One of the most direct manifestations of climate change in the urban environment is the increase in temperatures. The urban heat island effect, aggravated by the concentration of buildings and asphalt surfaces that absorb and retain heat, is intensified by the global increase in temperature. Not only does this affect quality of life by increasing cooling costs and energy demand, but it can also lead to serious public health problems, such as heat stroke and the aggravation of respiratory and cardiovascular diseases.
The change in precipitation patterns is another of the critical effects of climate change affecting cities. Heavy rainfall episodes and more frequent and severe storms can lead to urban flooding, especially in areas with insufficient or outdated drainage infrastructure. This situation causes significant structural damage, and also disrupts daily life, affects the local economy and increases public health risks due to the spread of waterborne diseases.
In the face of these challenges, urban planning and design must evolve. Cities are adopting sustainable urban planning strategies that include the creation of green infrastructure, such as parks and green roofs, capable of mitigating the heat island effect and improving water absorption during episodes of heavy rainfall. In addition, the integration of efficient public transport systems and the promotion of non-motorised mobility are essential to reduce carbon emissions.
The challenges described also influence building regulations and building codes. New buildings must meet higher standards of energy efficiency, resistance to extreme weather conditions and reduced environmental impact. This involves the use of sustainable materials and construction techniques that not only reduce greenhouse gas emissions, but also offer safety and durability in the face of extreme weather events.
In this context, urban digital twins have established themselves as one of the key tools to support planning, management and decision-making in cities. Its potential is wide and transversal: from the simulation of urban growth scenarios to the analysis of climate risks, the evaluation of regulatory impacts or the optimization of public services. However, beyond technological discourse and 3D visualizations, the real viability of an urban digital twin depends on a fundamental data governance issue: the availability, quality, and consistent use of standardized open data.
What do we mean by urban digital twin?
An urban digital twin is not simply a three-dimensional model of the city or an advanced visualization platform. It is a structured and dynamic digital representation of the urban environment, which integrates:
-
The geometry and semantics of the city (buildings, infrastructures, plots, public spaces).
-
Geospatial reference data (cadastre, planning, networks, environment).
-
Temporal and contextual information, which allows the evolution of the territory to be analysed and scenarios to be simulated.
-
In certain cases, updatable data streams from sensors, municipal information systems or other operational sources.
From a standards perspective, an urban digital twin can be understood as an ecosystem of interoperable data and services, where different models, scales and domains (urban planning, building, mobility, environment, energy) are connected in a coherent way. Its value lies not so much in the specific technology used as in its ability to align heterogeneous data under common, reusable and governable models.
In addition, the integration of real-time data into digital twins allows for more efficient city management in emergency situations. From natural disaster management to coordinating mass events, digital twins provide decision-makers with a real-time view of the urban situation, facilitating a rapid and coordinated response.
In order to contextualize the role of standards and facilitate the understanding of the inner workings of an urban digital twin, Figure 1 presents a conceptual diagram of the network of interfaces, data models, and processes that underpin it. The diagram illustrates how different sources of urban information – geospatial reference data, 3D city models, regulatory information and, in certain cases, dynamic flows – are integrated through standardised data structures and interoperable services.
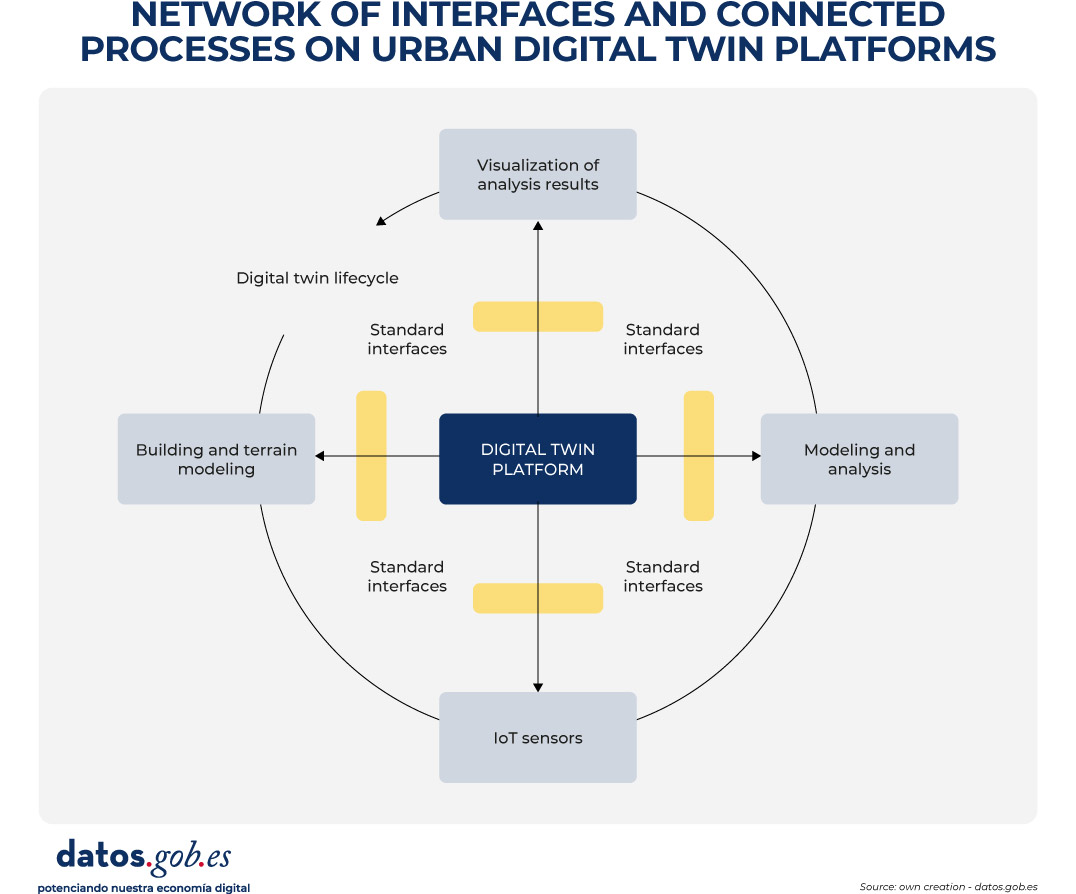
Figure 1. Conceptual diagram of the network of interfaces and connected processes in urban digital twin platforms. Source: own elaboration – datos.gob.es.
In these environments, CityGML and CityJSON act as urban information models that allow the city to be digitally described in a structured and understandable way. In practice, they function as "common languages" to represent buildings, infrastructures and public spaces, not only from the point of view of their shape (geometry), but also from the point of view of their meaning (e.g. whether an object is a residential building, a public road or a green area). As a result, these models form the basis on which urban analyses and the simulation of different scenarios are based.
In order for these three-dimensional models to be visualized in an agile way in web browsers and digital applications, especially when dealing with large volumes of information, 3D Tiles can be incorporated. This standard allows urban models to be divided into manageable fragments, facilitating their progressive loading and interactive exploration, even on devices with limited capacities.
The access, exchange and reuse of all this information is usually articulated through OGC APIs, which can be understood as standardised interfaces that allow different applications to consult and combine urban data in a consistent way. These interfaces make it possible, for example, for an urban planning platform, a climate analysis tool or a citizen viewer to access the same data without the need to duplicate or transform it in a specific way.
In this way, the diagram reflects the flow of data from the original sources to the final applications, showing how the use of open standards allows for a clear separation of data, services, and use cases. This separation is key to ensuring interoperability between systems, the scalability of digital solutions and the sustainability of the urban digital twin over time, aspects that are addressed transversally in the rest of the document.
Real example: Urban regeneration project in Barcelona
An example of the impact of urban digital twins on urban construction and management can be found in the urban regeneration project of the Plaza de las Glòries Catalanes, in Barcelona (Spain). This project aimed to transform one of the city's most iconic urban areas into a more accessible, greener and sustainable public space.

Figure 2. General view. Image by the joint venture Fuses Viader + Perea + Mansilla + Desvigne.
By using digital twins from the initial phases of the project, the design and planning teams were able to create detailed digital models that represented not only the geometry of existing buildings and infrastructure, but also the complex interactions between different urban elements, such as traffic, public transport and pedestrian areas.
These models not only facilitated the visualization and communication of the proposed design among all stakeholders, but also allowed different scenarios to be simulated and their impact on mobility, air quality, and walkability to be assessed. As a result, more informed decisions could be made, contributing decisively to the overall success of the urban regeneration initiative.
The critical role of open data in urban digital twins
In the context of urban digital twins, open data should not be understood as an optional complement or as a one-off action of transparency, but as the structural basis on which sustainable, interoperable and reusable digital urban systems are built over time. An urban digital twin can only fulfil its function as a planning, analysis and decision-support tool if the data that feeds it is available, well defined and governed according to common principles.
When a digital twin develops without a clear open data strategy, it tends to become a closed system and dependent on specific technology solutions or vendors. In these scenarios, updating information is costly and complex, reuse in new contexts is limited, and the twin quickly loses its strategic value, becoming obsolete in the face of the real evolution of the city it intends to represent. This lack of openness also hinders integration with other systems and reduces the ability to adapt to new regulatory, social or environmental needs.
One of the main contributions of urban digital twins is their ability to base public decisions on traceable and verifiable data. When supported by accessible and understandable open data, these systems allow us to understand not only the outcome of a decision, but also the data, models and assumptions that support it, integrating geospatial information, urban models, regulations and, in certain cases, dynamic data. This traceability is key to accountability, the evaluation of public policies and the generation of trust at both the institutional and citizen levels. Conversely, in the absence of open data, the analyses and simulations that support urban decisions become opaque, making it difficult to explain how and why a certain conclusion has been reached and weakening confidence in the use of advanced technologies for urban management.
Urban digital twins also require the collaboration of multiple actors – administrations, companies, universities and citizens – and the integration of data from different administrative levels and sectoral domains. Without an approach based on standardized open data, this collaboration is hampered by technical and organizational barriers: each actor tends to use different formats, models, and interfaces, which increases integration costs and slows down the creation of reuse ecosystems around the digital twin.
Another significant risk associated with the absence of open data is the increase in technological dependence and the consolidation of information silos. Digital twins built on non-standardized or restricted access data are often tied to proprietary solutions, making it difficult to evolve, migrate, or integrate with other systems. From the perspective of data governance, this situation compromises the sovereignty of urban information and limits the ability of administrations to maintain control over strategic digital assets.
Conversely, when urban data is published as standardised open data, the digital twin can evolve as a public data infrastructure, shared, reusable and extensible over time. This implies not only that the data is available for consultation or visualization, but that it follows common information models, with explicit semantics, coherent geometry and well-defined access mechanisms that facilitate its integration into different systems and applications.
This approach allows the urban digital twin to act as a common database on which multiple use cases can be built —urban planning, license management, environmental assessment, climate risk analysis, mobility, or citizen participation—without duplicating efforts or creating inconsistencies. The systematic reuse of information not only optimises resources, but also guarantees coherence between the different public policies that have an impact on the territory.
From a strategic perspective, urban digital twins based on standardised open data also make it possible to align local policies with the European principles of interoperability, reuse and data sovereignty. The use of open standards and common information models facilitates the integration of digital twins into wider initiatives, such as sectoral data spaces or digitalisation and sustainability strategies promoted at European level. In this way, cities do not develop isolated solutions, but digital infrastructures coherent with higher regulatory and strategic frameworks, reinforcing the role of the digital twin as a transversal, transparent and sustainable tool for urban management.
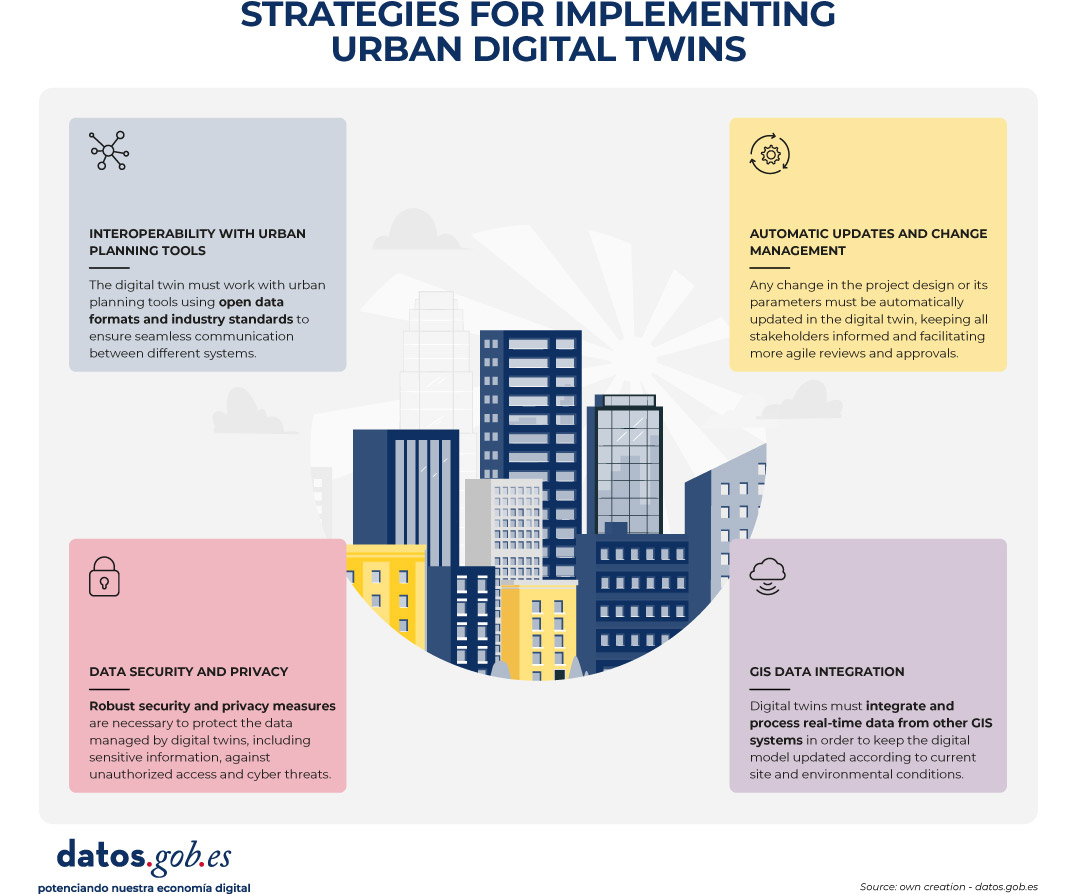
Figure 3. Strategies to implement urban digital twins. Source: own elaboration – datos.gob.es.
Conclusion
Urban digital twins represent a strategic opportunity to transform the way cities plan, manage and make decisions about their territory. However, their true value lies not in the technological sophistication of the platforms or the quality of the visualizations, but in the robustness of the data approach on which they are built.
Urban digital twins can only be consolidated as useful and sustainable tools when they are supported by standardised, well-governed open data designed from the ground up for interoperability and reuse. In the absence of these principles, digital twins risk becoming closed, difficult to maintain, poorly reusable solutions that are disconnected from the actual processes of urban governance.
The use of common information models, open standards and interoperable access mechanisms allows the digital twin to evolve as a public data infrastructure, capable of serving multiple public policies and adapting to social, environmental and regulatory changes affecting the city. This approach reinforces transparency, improves institutional coordination, and facilitates decision-making based on verifiable evidence.
In short, betting on urban digital twins based on standardised open data is not only a technical decision, but also a public policy decision in terms of data governance. It is this vision that will enable digital twins to contribute effectively to addressing major urban challenges and generating lasting public value for citizens.
Blog
In the era of Artificial Intelligence (AI), data has ceased to be simple records and has become the essential fuel of innovation. However, for this fuel to really drive new services, more effective public policies or advanced AI models, it is not enough to have large volumes of information: the data must be varied, of quality and, above all, accessible.
In this context, the data pooling or Data Clustering, a practice that consists of Pooling data to generate greater value from their joint use. Far from being an abstract idea, the data pooling is emerging as one of the key mechanisms for transforming the data economy in Europe and has just received a new impetus with the proposal of the Digital Omnibus, aimed at simplifying and strengthening the European data-sharing framework.
As we already analyzed in our recent post on the Data Union Strategy, the European Union aspires to build a Single Data Market in which information can flow safely and with guarantees. The data pooling it is, precisely, the Operational tool which makes this vision tangible, connecting data that is now dispersed between administrations, companies and sectors.
But what exactly does "data pooling" mean? Why is this concept being talked about more and more in the context of the European data strategy and the new Digital Omnibus? And, above all, what opportunities does it open up for public administrations, companies and data reusers? In this article we try to answer these questions.
What is data pooling, how does it work and what is it for?
To understand what data pooling is, it can be helpful to think about a traditional agricultural cooperative. In it, small producers who, individually, have limited resources decide to pool their production and their means. By doing so, they gain scale, access better tools, and can compete in markets they wouldn't reach separately.
In the digital realm, data pooling works in a very similar way. It consists of combining or grouping datasets from different organizations or sources to analyze or reuse them with a shared goal. Creating this "common repository" of information—physical or logical—enables more complex and valuable analyses that could hardly be performed from a single isolated source.
This "pooling of data" can take different forms, depending on the technical and organizational needs of each initiative:
- Shared repositories, where multiple organizations contribute data to the same platform.
- Joint or federated access, where data remains in its source systems, but can be analyzed in a coordinated way.
- Governance agreements, which set out clear rules about who can access data, for what purpose, and under what conditions.
In all cases, the central idea is the same: each participant contributes their data and, in return, everyone benefits from a greater volume, diversity and richness of information, always under previously agreed rules.
What is the purpose of sharing data?
The growing interest in data pooling is no coincidence. Sharing data in a structured way allows, among other things:
- Detect patterns that are not visible with isolated data, especially in complex areas such as mobility, health, energy or the environment.
- Enhance the development of artificial intelligence, which needs diverse, quality data at scale to generate reliable results.
- Avoiding duplication, reducing costs and efforts in both the public and private sectors.
- To promote innovation, facilitating new services, comparative studies or predictive analysis.
- Strengthen evidence-based decision-making, a particularly relevant aspect in the design of public policies.
In other words, data pooling multiplies the value of existing data without the need to always generate new sets of information.
Different types of data pooling and their value
Not all data pools are created equal. Depending on the context and the objective pursued, different models of data grouping can be identified:
- M2M (Machine-to-Machine) data pooling, very common in the Internet of Things (IoT). For example, when industrial sensor manufacturers pool data from thousands of machines to anticipate failures or improve maintenance.
- Cross-sector or cross-sector data pooling, which combines data from different sectors – such as transport and energy – to optimise services, for example, the management of electric vehicle charging in smart cities.
- Data pooling for research, especially relevant in the field of health, where hospitals or research centers share anonymized data to train algorithms capable of detecting rare diseases or improving diagnoses.
These examples show that data pooling is not a single solution, but a set of adaptable practices, capable of generating economic, social and scientific value when applied with the appropriate guarantees.
From potential to practice: guarantees, clear rules and new opportunities for data pooling
Talking about sharing data does not mean doing it without limits. For data pooling to build trust and sustainable value, it is imperative to address how to share data responsibly. This has been, in fact, one of the great challenges that have conditioned its adoption in recent years.
Among the main concerns are the Protection of personal data, ensuring compliance with the General Data Protection Regulation (GDPR) and minimizing risks of re-identification; the confidentiality and the protection of trade secrets, especially when companies are involved; as well as the Quality and interoperability of the data, as combining inconsistent information can lead to erroneous conclusions. To all this is added a transversal element: the Trust between the parties, without which no sharing mechanism can function.
For this reason, data pooling is not just a technical issue. It requires clear legal frameworks, strong governance models, and trust mechanisms, which provide security to both those who share the data and those who reuse it.
Europe's role: from sharing data to creating ecosystems
Aware of these challenges, the European Union has been working for years to build a Single Data Market, where sharing information is simpler, safer and more beneficial for all actors involved. In this context, key initiatives have emerged, such as the European Data Spaces, organized by strategic sectors (health, mobility, industry, energy, agriculture), the promotion of Standards and Interoperability, and the appearance of Data Brokers as trusted third parties who facilitate sharing.
Data pooling fits fully into this vision: it is one of the practical mechanisms that allow these data spaces to work and generate real value. By facilitating the aggregation and joint use of data, pooling acts as the "engine" that makes many of these ecosystems operational.
All this is part of the Data Union Strategy, which seeks to connect policies, infrastructures and standards so that data can flow safely and efficiently throughout Europe.
The big brake: regulatory fragmentation
Until recently, this potential was met with a major hurdle: the Complexity of the European legal framework on data. An organization that would like to participate in a data pool cross-border had to navigate between multiple rules – GDPR, Data Governance Act, Data Act, Open Data Directive and sectoral or national regulations—with definitions, obligations, and competent authorities that are not always aligned. This fragmentation generated legal uncertainty: doubts about responsibilities, fear of sanctions, or uncertainty about the real protection of trade secrets. In practice, this "normative labyrinth" has for years held back the development of many common data spaces and limited the adoption of the data pooling, especially among SMEs and medium-sized companies with less legal and technical capacity.
The Digital Omnibus: Simplifying for Data Pooling to Scale
This is where the Digital Omnibus, the European Commission's proposal to simplify and harmonise the digital legal framework, comes into play. Far from adding new regulatory layers, the objective of the Omnibus is to organize, consolidate and reduce administrative burdens, making it easier to share data in practice.
From a data pooling perspective, the message is clear: less fragmentation, more clarity, and greater trust. The Omnibus seeks to concentrate the rules in a more coherent framework, avoid duplication and remove unnecessary barriers that until now discouraged data-driven collaboration, especially in cross-border projects.
In addition, the role of data intermediation services, key actors in organizing pooling in a neutral and reliable way, is reinforced. By clarifying their role and reducing certain burdens, it favors the emergence of new models – including technology startups – capable of acting as "arbiters" of data exchange between multiple participants.
Another particularly relevant element is the strengthening of the protection of trade secrets, allowing data holders to limit or deny access when there is a real risk of misuse or transfer to environments without adequate guarantees. This point is key for industrial and strategic sectors, where trust is an essential condition for sharing data.
New opportunities for data pooling: public sector, companies and data reuse
The regulatory simplification and confidence-building introduced by the Digital Omnibus is not an end in itself. Its true value lies in the concrete opportunities that data pooling opens up for different actors in the data ecosystem, especially for the public sector, companies and information reusers.
In the case of public administrations, data pooling offers particularly relevant potential. It allows data from different sources and administrative levels to be combined to improve the design and evaluation of public policies, move towards evidence-based decision-making and offer more effective and personalised services to citizens. At the same time, it facilitates the breaking down of information silos, the reuse of already available data and the reduction of duplications, with the consequent savings in costs and efforts.
In addition, data pooling reinforces collaboration between the public sector, the research field and the private sector, always under secure and transparent frameworks. In this context, it does not compete with open data, but complements it, making it possible to connect datasets that are currently published in a fragmented way and enabling more advanced analyses that expand their social and economic value.
From a business point of view, the Digital Omnibus introduces a significant novelty by expanding the focus beyond traditional SMEs. The so-called small mid-caps, mid-cap companies that also suffer the impact of bureaucracy, are now benefiting from regulatory simplification. This significantly increases the base of organizations capable of participating in data pooling schemes and expands the volume and diversity of data available in strategic sectors such as industry, automotive or chemicals.
The economic impact of this new scenario is also relevant. The European Commission estimates significant savings in administrative and operational costs, both for companies and public administrations. But beyond the numbers, these savings represent freed up capacity to innovate, invest in new digital services, and develop more advanced AI models, fueled by data that can now be shared more securely.
In short, data pooling is consolidated as a key lever to move from the punctual sharing of data to the systematic generation of value, laying the foundations for a more collaborative, efficient and competitive data economy in Europe.
Conclusion: Cooperate to compete
The proposal of data pooling in the Digital Omnibus marks a before and after in the way we understand the ownership of information. Europe has understood that, in the global data economy, sovereignty is not defended by closing borders, but by creating secure environments where collaboration is the simplest and most profitable option.
Data pooling is at the heart of this transformation. By cutting red tape, simplifying notifications, and protecting trade secrets, the Omnibus is taking the stones out of the way so that businesses and citizens can enjoy the benefits of a true Data Union.
In short, it is a question of moving from an economy of isolated silos to one of connected networks. Because, in the world of data, sharing is not losing control, it is gaining scale.
Content created by Dr. Fernando Gualo, Professor at UCLM and Government and Data Quality Consultant. The content and views expressed in this publication are the sole responsibility of the author.
Blog
The idea of conceiving artificial intelligence (AI) as a service for immediate consumption or utility, under the premise that it is enough to "buy an application and start using it", is gaining more and more ground. However, getting on board with AI isn't like buying conventional software and getting it up and running instantly. Unlike other information technologies, AI will hardly be able to be used with the philosophy of plug and play. There is a set of essential tasks that users of these systems should undertake, not only for security and legal compliance reasons, but above all to obtain efficient and reliable results.
The Artificial Intelligence Regulation (RIA)[1]
The RIA defines frameworks that should be taken into account by providers[2] and those responsible for deploying[3] AI. This is a very complex rule whose orientation is twofold. Firstly, in an approach that we could define as high-level, the regulation establishes a set of red lines that can never be crossed. The European Union approaches AI from a human-centred and human-serving approach. Therefore, any development must first and foremost ensure that fundamental rights are not violated or that no harm is caused to the safety and integrity of people. In addition, no AI that could generate systemic risks to democracy and the rule of law will be admitted. For these objectives to materialize, the RIA deploys a set of processes through a product-oriented approach. This makes it possible to classify AI systems according to their level of risk, -low, medium, high- as well as general-purpose AI models[4]. And also, to establish, based on this categorization, the obligations that each participating subject must comply with to guarantee the objectives of the standard.
Given the extraordinary complexity of the European regulation, we would like to share in this article some common principles that can be deduced from reading it and could inspire good practices on the part of public and private organisations. Our approach is not so much on defining a roadmap for a given information system as on highlighting some elements that we believe can be useful in ensuring that the deployment and use of this technology are safe and efficient, regardless of the level of risk of each AI-based information system.
Define a clear purpose
The deployment of an AI system is highly dependent on the purpose pursued by the organization. It is not about jumping on the bandwagon of a fashion. It is true that the available public information seems to show that the integration of this type of technology is an important part of the digital transformation processes of companies and the Administration, providing greater efficiency and capabilities. However, it cannot become a fad to install any of the Large Language Models (LLMs). Prior reflection is needed that takes into account what the needs of the organization are and defines what type of AI will contribute to the improvement of our capabilities. Not adopting this strategy could put our bank at risk, not only from the point of view of its operation and results, but also from a legal perspective. For example, introducing an LLM or chatbot into a high-decision-making risk environment could result in reputational impacts or liability. Inserting this LLM in a medical environment, or using a chatbot in a sensitive context with an unprepared population or in critical care processes, could end up generating risk situations with unforeseeable consequences for people.
Do no evil
The principle of non-malefficiency is a key element and should decisively inspire our practice in the world of AI. For this reason, the RIA establishes a series of practices expressly prohibited to protect the fundamental rights and security of people. These prohibitions focus on preventing manipulations, discrimination, and misuse of AI systems that can cause significant harm.
Categories of Prohibited Practices
1. Manipulation and control of behavior. Through the use of subliminal or manipulative techniques that alter the behavior of individuals or groups, preventing informed decision-making and causing considerable damage.
2. Exploiting vulnerabilities. Derived from age, disability or social/economic situation to substantially modify behavior and cause harm.
3. Social Scoring. AI that evaluates people based on their social behavior or personal characteristics, generating ratings with effects for citizens that result in unjustified or disproportionate treatment.
4. Criminal risk assessment based on profiles. AI used to predict the likelihood of committing crimes solely through profiling or personal characteristics. Although its use for criminal investigation is admitted when the crime has actually been committed and there are facts to be analyzed.
5. Facial recognition and biometric databases. Systems for the expansion of facial recognition databases through the non-selective extraction of facial images from the Internet or closed circuit television.
6. Inference of emotions in sensitive environments. Designing or using AI to infer emotions at work or in schools, except for medical or safety reasons.
7. Sensitive biometric categorization. Develop or use AI that classifies individuals based on biometric data to infer race, political opinions, religion, sexual orientation, etc.
8. Remote biometric identification in public spaces. Use of "real-time" remote biometric identification systems in public spaces for police purposes, with very limited exceptions (search for victims, prevention of serious threats, location of suspects of serious crimes).
Apart from the expressly prohibited conduct, it is important to bear in mind that the principle of non-maleficence implies that we cannot use an AI system with the clear intention of causing harm, with the awareness that this could happen or, in any case, when the purpose we pursue is contrary to law.
Ensure proper data governance
The concept of data governance is found in Article 10 of the RIA and applies to high-risk systems. However, it contains a set of principles that are highly cost-effective when deploying a system at any level. High-risk AI systems that use data must be developed with training, validation, and testing suites that meet quality criteria. To this end, certain governance practices are defined to ensure:
- Proper design.
- That the collection and origin of the data, and in the case of personal data the purpose pursued, are adequate and legitimate.
- Preparation processes such as annotation, labeling, debugging, updating, enrichment, and aggregation are adopted.
- That the system is designed with use cases whose information is consistent with what the data is supposed to measure and represent.
- Ensure data quality by ensuring the availability, quantity, and adequacy of the necessary datasets.
- Detect and review biases that may affect the health and safety of people, rights or generate discrimination, especially when data outputs influence the input information of future operations. Measures should be taken to prevent and correct these biases.
- Identify and resolve gaps or deficiencies in data that impede RIA compliance, and we would add legislation.
- The datasets used should be relevant, representative, complete and with statistical properties appropriate for their intended use and should consider the geographical, contextual or functional characteristics necessary for the system, as well as ensure its diversity. In addition, they shall be error-free and complete in view of their intended purpose.
AI is a technology that is highly dependent on the data that powers it. From this point of view, not having data governance can not only affect the operation of these tools, but could also generate liability for the user.
In the not too distant future, the obligation for high-risk systems to obtain a CE marking issued by a notified body (i.e., designated by a member state of the European Union) will provide conditions of reliability to the market. However, for the rest of the lower-risk systems, the obligation of transparency applies. This does not at all imply that the design of this AI should not take these principles into account as far as possible. Therefore, before making a contract, it would be reasonable to verify the available pre-contractual information both in relation to the characteristics of the system and its reliability and with respect to the conditions and recommendations for deployment and use.
Another issue concerns our own organization. If we do not have the appropriate regulatory, organizational, technical and quality compliance measures that ensure the reliability of our own data, we will hardly be able to use AI tools that feed on it. In the context of the RIA, the user of a system may also incur liability. It is perfectly possible that a product of this nature has been properly developed by the supplier and that in terms of reproducibility the supplier can guarantee that under the right conditions the system works properly. What developers and vendors cannot solve are the inconsistencies in the datasets that the user-client integrates into the platform. It is not your responsibility if the customer failed to properly deploy a General Data Protection Regulation compliance framework or is using the system for an unlawful purpose. Nor will it be their responsibility for the client to maintain outdated or unreliable data sets that, when introduced into the tool, generate risks or contribute to inappropriate or discriminatory decision-making.
Consequently, the recommendation is clear: before implementing an AI-based system, we must ensure that data governance and compliance with current legislation are adequately guaranteed.
Ensuring Safety
AI is a particularly sensitive technology that presents specific security risks, such as the corruption of data sets. There is no need to look for fancy examples. Like any information system, AI requires organizations to deploy and use them securely. Consequently, the deployment of AI in any environment requires the prior development of a risk analysis that allows identifying which are the organizational and technical measures that guarantee a safe use of the tool.
Train your staff
Unlike the GDPR, in which this issue is implicit, the RIA expressly establishes the duty to train as an obligation. Article 4 of the RIA is so precise that it is worthwhile to reproduce it in its entirety:
Providers and those responsible for deploying AI systems shall take measures to ensure that, to the greatest extent possible, their staff and others responsible on their behalf for the operation and use of AI systems have a sufficient level of AI literacy, taking into account their technical knowledge; their experience, education and training, as well as the intended context of use of AI systems and the individuals or groups of people in whom those systems are to be used.
This is certainly a critical factor. People who use artificial intelligence must have been given adequate training that allows them to understand the nature of the system and be able to make informed decisions. One of the core principles of European legislation and approach is that of human supervision. Therefore, regardless of the guarantees offered by a given market product, the organization that uses it will always be responsible for the consequences. And this will happen both in the case where the last decision is attributed to a person, and when in highly automated processes those responsible for its management are not able to identify an incident by making appropriate decisions with human supervision.
Guilt in vigilando
The massive introduction of LLMs poses the risk of incurring the so-called culpa in vigilando: a legal principle that refers to the responsibility assumed by a person for not having exercised due vigilance over another, when that lack of control results in damage or harm. If your organization has introduced any of these marketplace products that integrate functions such as reporting, evaluating alphanumeric information, and even assisting you in email management, it will be critical that you ensure compliance with the recommendations outlined above. It is particularly advisable to define very precisely the purposes for which the tool is implemented, the roles and responsibilities of each user, and to document their decisions and to train staff appropriately.
Unfortunately, the model of introduction of LLMs into the market has itself generated a systemic and serious risk for organizations. Most tools have opted for a marketing strategy that is no different from the one used by social networks in their day. That is, they allow open and free access to anyone. It is obvious that with this they achieve two results: reuse the information provided to them by monetizing the product and generate a culture of use that facilitates the adoption and commercialization of the tool.
Let's imagine a hypothesis, of course, that is far-fetched. A resident intern (MIR) has discovered that several of these tools have been developed and, in fact, are used in another country for differential diagnosis. Our MIR is very worried about having to wake up the head of medical duty in the hospital every 15 minutes. So, diligently, he hires a tool, which has not been planned for that use in Spain, and makes decisions based on the proposal of differential diagnosis of an LLM without yet having the capabilities that enable it for human supervision. Obviously, there is a significant risk of ending up causing harm to a patient.
Situations such as the one described force us to consider how organizations that do not use AI but are aware of the risk that their employees use them without their knowledge or consent should act. In this regard, a preventive strategy should be adopted based on the issuance of very precise circulars and instructions regarding the prohibition of their use. On the other hand, there is a hybrid risk situation. The LLM has been contracted by the organization and is used by the employee for purposes other than those intended. In this case, the safety-training duo acquires a strategic value.
Training and the acquisition of culture about artificial intelligence are probably an essential requirement for society as a whole. Otherwise, the systemic problems and risks that in the past affected the deployment of the Internet will happen again and who knows if with an intensity that is difficult to govern.
Content prepared by Ricard Martínez, Director of the Chair of Privacy and Digital Transformation. Professor, Department of Constitutional Law, Universitat de València. The contents and points of view reflected in this publication are the sole responsibility of its author.
NOTES:
[1] Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised standards in the field of artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 available in https://eur-lex.europa.eu/legal-content/ES/TXT/?uri=OJ%3AL_202401689
[2] The RIA defines 'provider' as a natural or legal person, public authority, body or agency that develops an AI system or a general-purpose AI model or for which an AI system or a general-purpose AI model is developed and places it on the market or puts the AI system into service under its own name or brand; for a fee or free of charge.
[3] The RIA defines "deployment controller" as a natural or legal person, or public authority, body, office or agency that uses an AI system under its own authority, except where its use is part of a personal activity of a non-professional nature.
[4] The RIA defines a 'general-purpose AI model' as an AI model, also one trained on a large volume of data using large-scale self-monitoring, which has a considerable degree of generality and is capable of competently performing a wide variety of different tasks, regardless of how the model is introduced to the market. and that it can be integrated into various downstream systems or applications, except for AI models that are used for research, development, or prototyping activities prior to their introduction to the market.
Blog
Energy is the engine of our society, a vital resource that powers our lives and the global economy. However, the traditional energy model faces monumental challenges: growing demand, climate urgency, and the prevailing need for a transition to cleaner and more sustainable sources. In this panorama of profound transformation, a silent but powerful actor emerges: data. Not only is "having data" important, but also the ability to govern it properly to transform the energy sector.
In this new energy paradigm, data has become a strategic resource as essential as energy itself. The key is not only in generating and distributing electricity, but in understanding, anticipating and optimizing its use in real time. And to do this, it is necessary to capture the digital pulse of the energy system through millions of measurement and observation points.
So, before addressing how this data is governed, it's worth understanding where it comes from, what kind of information it generates, and how it's quietly transforming how the power grid works.
The digital heartbeat of the network: data from smart meters and sensors
Imagine an electric grid that not only distributes power, but also "listens," "learns," and "reacts." This is the promise of smart grids, a system that goes far beyond the cables and transformers we see. Asmart grid is an electricity distribution system that uses digital technology to improve grid efficiency, sustainability, and security. At the heart of this revolution are smart meters and a vast network of sensors.
Smart meters, also known as Advanced Metering Infrastructure (AMI), are devices that record electricity consumption digitally, often at very short intervals of time (e.g. every 15 minutes or per hour), and transmit this data to power companies via various communication technologies, such as cellular networks, WiFi, PLC (Power Line Communication) or radio frequency (RF). This data is not limited to the total amount of energy consumed, but offers a detailed breakdown of consumption patterns, voltage levels, power quality, and even fault detection.
But network intelligence doesn't just lie with the meters. A myriad of sensors distributed throughout the electrical infrastructure monitor critical variables in real time: from transformer temperature and equipment status to environmental conditions and power flow at different points on the grid. These sensors act as the "eyes and ears" of the system, providing a granular and dynamic view of network performance.
The magic happens in the flow of this data. The information from the meters and sensors travels bidirectionally: from the point of consumption or generation to the management platforms of the electricity company and vice versa. This constant communication allows utilities to:
- Check-in accurately
- Implement demand response programs
- Optimize power distribution
- Predict and prevent disruptions
- Efficiently integrate renewable energy sources that are intermittent by their nature
Data governance: the backbone of a connected network
The mere collection of data, however abundant, does not guarantee its value. In fact, without proper management, this heterogeneity of sources can become an insurmountable barrier to the integration and useful analysis of information. This is where data governance comes into play.
Data governance in the context of smart grids involves establishing a robust set of principles, processes, roles, and technologies to ensure that the data generated is reliable, accessible, useful, and secure. It's the "rule of the game" that defines how data is captured, stored, maintained, used, protected, and deleted throughout its entire lifecycle.
Why is this so crucial?
- Interoperability: A smart grid is not a monolithic system, but a constellation of devices, platforms, and actors (generators, distributors, consumers, prosumer, regulators). For all these elements to "speak the same language", interoperability is essential. Data governance sets standards for nomenclature, formats, encoding, and synchronization, allowing information to flow frictionlessly between disparate systems. Without it, we risk creating fragmented and costly information silos.
- Quality: Artificial intelligence algorithms and machine learning, so vital to smart grids, are only as good as the data they are fed with. Data governance ensures the accuracy, completeness, and consistency of data (and future information and knowledge) by defining business rules, cleaning up duplicates, and managing data errors. Poor quality data can lead to wrong decisions, operational inefficiencies, and unreliable results.
- Security: The interconnection of millions of devices in a smart network exponentially expands the attack surface for cybercriminals. A breach of data security could have catastrophic consequences, from massive power outages to breaches of user privacy. Data governance is the shield that implements robust access controls, encryption protocols, and usage audits, safeguarding the integrity and confidentiality of critical information. Adhering to consolidated security frameworks such as ENS, ISO/IEC 27000, NIST, IEC 62443, and NERC CIP is critical.
Ultimately, effective data governance turns data into critical infrastructure, as important as cables and substations, for decision-making, resource optimization, and intelligent automation.
Data in action: optimising, anticipating and facilitating the energy transition
Governing data is not an end in itself, but the means to unlock vast potential for efficiency and sustainability in the energy sector.
1. Optimisation of consumption and operational efficiency
Exact, complete, consistent, current, credible and real-time data enables multiple advantages in energy management:
- Consumption at the user level: smart meters empower citizens and businesses by providing them with detailed information about their own consumption. This allows them to identify patterns, adjust their habits, and ultimately reduce their energy bills.
- Demand management: Utilities can use data to implement demand response (DR) programs. These programs incentivize consumers to reduce or shift their electricity consumption during periods of high demand or high prices, thereby balancing the load on the grid and avoiding costly investments in new infrastructure.
- Reduced inefficiencies: The availability of accurate and well-integrated data allows utilities to automate tasks, avoid redundant processes, and reduce unplanned downtime in their systems. For example, a generation plant can adjust its production in real-time based on the analysis of performance and demand data.
- Energy monitoring and emission control: real-time monitoring of energy, water or polluting gas emissions reveals hidden inefficiencies and savings opportunities. Smart dashboards, powered by governed data, enable industrial plants and cities to reduce their costs and advance their environmental sustainability goals.
2. Demand anticipation and grid resilience
Smart grids can also foresee the future of energy consumption:
- Demand forecasting: By using advanced artificial intelligence and machine learning algorithms (such as time series analysis or neural networks), historical consumption data, combined with external factors such as weather, holidays, or special events, allow utilities to forecast demand with astonishing accuracy. This anticipation is vital to optimize resource allocation, avoid overloads, and ensure network stability.
- Predictive maintenance: By combining historical maintenance data with real-time information from sensors on critical equipment, companies can anticipate machine failures before they occur, proactively schedule maintenance, and avoid costly unexpected outages.
3. Facilitating the energy transition
Data governance is an indispensable catalyst for the integration of renewable energy and decarbonization:
- Integration of renewables: sources such as solar and wind energy are intermittent by nature. Real-time data on generation, weather conditions, and grid status are critical to managing this variability, balancing the load, and maximizing the injection of clean energy into the grid.
- Distributed Energy Resources (RED) Management: The proliferation of rooftop solar panels, storage batteries, and electric vehicles (which can charge and discharge energy to the grid) requires sophisticated data management. Data governance ensures the interoperability needed to coordinate these resources efficiently, transforming them into "virtual power plants" that can support grid stability.
- Boosting the circular economy: thanks to the full traceability of a product's life cycle, from design to recycling, data makes it possible to identify opportunities for reuse, recovery of materials and sustainable design. This is crucial to comply with new circular economy regulations and the Digital Product Passport (DPP).
- Digital twins: For a virtual replica of a physical process or system to work, it needs to be powered by accurate and consistent data. Data governance ensures synchronization between the physical and virtual worlds, enabling reliable simulations to optimize the design of new production lines or the arrangement of elements in a factory.
Tangible benefits for citizens, businesses and administrations
Investment in data governance in smart grids generates significant value for all actors in society:
For citizens
- Savings on electricity bills: by having access to real-time consumption data and flexible tariffs (for example, with lower prices in off-peak hours), citizens can adjust their habits and reduce their energy costs.
- Empowerment and control: citizens go from being mere consumers to "prosumers", with the ability to generate their own energy (for example, with solar panels) and even inject the surplus into the grid, being compensated for it. This encourages participation and greater control over their energy consumption.
- Better quality of life: A more resilient and efficient grid means fewer power interruptions and greater reliability, which translates into a better quality of life and uninterrupted essential services.
- Promoting sustainability: By participating in demand response programs and adopting more efficient consumption behaviors, citizens contribute directly to the reduction of the country's carbon footprint and energy transition.
For companies
- Optimization of operations and cost reduction: companies can predict demand, adjust production and perform predictive maintenance of their machinery, reducing losses due to failures and optimizing the use of energy and material resources.
- New business models: The availability of data creates opportunities for the development of new services and products. This includes platforms for energy exchange, intelligent energy management systems for buildings and homes, or the optimization of charging infrastructures for electric vehicles.
- Loss reduction: Intelligent data management allows utilities to minimize losses in power transmission and distribution, prevent overloads, and isolate faults faster and more efficiently.
- Improved traceability: in regulated sectors such as food, automotive or pharmaceuticals, the complete traceability of the product from the raw material to the end customer is not only an added value, but a regulatory obligation. Data governance ensures that this traceability is verifiable and meets standards.
- Regulatory compliance: Robust data management enables companies to comply with increasingly stringent regulations on sustainability, energy efficiency, and emissions, as well as data privacy regulations (such as GDPR).
For Public Administrations
- Smart energy policymaking: Aggregated and anonymised data from the smart grid provides public administrations with valuable information to design more effective energy policies, set ambitious decarbonisation targets and strategically plan the country's energy future.
- Infrastructure planning: with a clear view of consumption patterns and future needs, governments can more efficiently plan grid upgrades and expansions, as well as the integration of distributed energy resources such as smart microgrids.
- Boosting urban resilience: the ability to manage and coordinate locally distributed energy resources, such as in micro-grids, improves the resilience of cities to extreme events or failures in the main grid.
- Promotion of technological and data sovereignty: by encouraging the publication of this data in open data portals together with the creation of national and sectoral data spaces, Administrations ensure that the value generated by data stays in the country and in local companies, boosting innovation and competitiveness at an international level.
Challenges and best practices in smart grid data governance
Despite the immense benefits, implementing effective data governance initiatives in the energy sector presents significant challenges:
- Heterogeneity and complexity of data integration: Data comes from a multitude of disparate sources (meters, sensors, SCADA, ERP, MES, maintenance systems, etc.). Integrating and harmonizing this information is a considerable technical and organizational challenge.
- Privacy and compliance: Energy consumption data can reveal highly sensitive patterns of behavior. Ensuring user privacy and complying with regulations such as the GDPR is a constant challenge that requires strong ethical and legal frameworks.
- Cybersecurity: The massive interconnection of devices and systems expands the attack surface, making smart grids attractive targets for sophisticated cyberattacks. Integrating legacy systems with new technologies can also create vulnerabilities.
- Data quality: Without robust processes, information can be inconsistent, incomplete, or inaccurate, leading to erroneous decisions.
- Lack of universal standards: The absence of uniform cybersecurity practices and regulations across different regions can reduce the effectiveness of security measures.
- Resistance to change and lack of data culture: The implementation of new data governance policies and processes can encounter internal resistance, and a lack of understanding about the importance of data often hampers efforts.
- Role and resource allocation: Clearly defining who is responsible for which aspect of the data and securing adequate financial and human resources is critical to success.
- Scalability: As the volume and variety of data grows exponentially, the governance structure must be able to scale efficiently to avoid bottlenecks and compliance issues.
To overcome these challenges, the adoption of the following best practices is essential:
- Establish a strong governance framework: define clear principles, policies, processes and roles from the outset, with the support of public administrations and senior management. This can be solved with the implementation of the processes of UNE 0077 to 0080, which includes the definition of data governance, management and quality processes, as well as the definition of organizational structures.
- Ensure data quality: Implement data quality assessment methodologies and processes, such as data asset classification and cataloguing, quality control (validation, duplicate cleanup), and data lifecycle management. All this can be based on the implementation of a quality model following UNE 0081.
- Prioritize cybersecurity and privacy: Implement robust security frameworks (ENS, ISO 27000, NIST, IEC 62443, NERC CIP), secure IoT devices, use advanced threat detection tools (including AI), and build resilient systems with network segmentation and redundancy. Ensure compliance with data privacy regulations (such as GDPR).
- Promote interoperability through standards: adopt open standards for communication and data exchange between systems, such as OPC UA or ISA-95.
- Invest in technology and automation: Use data governance tools that enable automatic data discovery and classification, application of data protection rules, automation of metadata management, and cataloguing of data. Automating routine tasks improves efficiency and reduces errors.
- Collaboration and Information Sharing: Encourage the exchange of threat and best practice information among utilities, government agencies, and other industry stakeholders. In this regard, it is worth highlighting the more than 900 datasets published in the datos.gob.es catalogue on the subject of Energy, as well as the creation of "Data Spaces" (such as the National Data Space for Energy or Industry in Spain) facilitates the secure and efficient sharing of data between organisations, boosting innovation and sectoral competitiveness.
- Continuous monitoring and improvement: data governance is a continuous process. KPIs should be established to monitor progress, evaluate performance, and make improvements based on feedback and regulatory or strategic changes.
Conclusions: a connected and sustainable future
Energy and data are linked in the future. Smart grids are the manifestation of this symbiosis, and data governance is the key to unlocking its potential. By transforming data from simple records into strategic assets and critical infrastructure, we can move towards a more efficient, sustainable and resilient energy model.
Collaboration between companies, citizens and administrations, driven by initiatives such as the National Industry Data Space in Spain, is essential to build this future. This space not only seeks to improve industrial efficiency, but also to reinforce the country's technological and data sovereignty, ensuring that the value generated by data benefits our own companies, regions and sectors. By investing in strong data governance initiatives and building shared data ecosystems, we are investing in an industry that is more connected, smarter and ready for tomorrow's energy and climate challenges.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The content and the point of view reflected in this publication are the sole responsibility of its author.
Blog
Today's industry is facing one of the biggest challenges in its recent history. Market demands, pressure to meet climate targets, consumer demand for transparency and technological acceleration are converging in a profound transformation of the production model. This transformation is not only aimed at greater competitiveness, but also at more resilient, flexible, efficient and sustainable production.
In this context, industrial digitisation - driven by technologies such as the Internet of Things (IoT), artificial intelligence, edge computing, or cyber-physical systems - is generating massive amounts of operational, environmental and logistical data. However, the mere existence of this data does not in itself guarantee value. The key is to govern it properly, i.e. to establish principles, processes, roles and technologies that ensure that this data is reliable, accessible, useful and secure. In other words, that the data is fit to be harnessed to improve industrial processes.
This is why industrial data governance is positioned as a strategic factor. It is not just a matter of ‘having data’, but of turning it into a critical infrastructure for decision-making, resource optimisation, intelligent automation and ecological transition. Without data governance, there is no Industry 4.0. And without Industry 4.0, the challenges of sustainability, energy efficiency or full traceability are intractable.
In this article we explore why data governance is essential in industry, what concrete benefits it brings to production processes and how initiatives such as the National Industry Data Space can accelerate this transformation.
We then analyse its impact at different levels, from the most relevant use cases to the collaborative frameworks that are emerging in Spain.
Why is data governance key in industry?
Industrial data comes from a multitude of distributed sources: IoT sensors, SCADA systems, automated assembly lines, maintenance platforms, ERP or Manufacturing Execution Systems (MES), among others. This heterogeneity, if not properly managed, can become a barrier to the integration and useful analysis of information.
Data governance overcomes these barriers by establishing the rules of the game for data capture, storage, quality, interoperability, use, protection and disposal. This enables not only operational efficiency but also long-term sustainability. How?
- Reducing operational inefficiencies: by having accurate, up-to-date and well-integrated data between systems, tasks can be automated, rework avoided, and unplanned downtime reduced. For example, a plant can adjust the speed of its production lines in real time based on the analysis of performance and demand data.
- Improving sustainability: robust data management can identify patterns of energy consumption, materials or emissions. With this information, processes can be redesigned to be more sustainable, eco-design can be applied and the environmental footprint can be reduced. Data, in this case, acts as a compass towards decarbonisation.
- Ensuring regulatory compliance and traceability: from ISO 9001 to the new circular economy regulations or the Digital Product Passport, industries must demonstrate compliance. This is only possible with reliable, traceable and auditable data.
- Facilitating interoperability between systems: data governance acts as the ‘glue’ that binds together the different technological silos of an organisation: quality, production, logistics, maintenance, purchasing, etc. The standardisation and semantic alignment of data allows for more agile flows and better informed decisions.
- Boosting the circular economy: thanks to the full traceability of a product's life cycle, from design to recycling, it is possible to identify opportunities for reuse, material recovery and sustainable design. This is supported by data that follows the product throughout its life.
What should data governance look like in the industrial environment?
A data governance model adapted to this context should include:
▸Specific roles: it is necessary to have a defined team, where everyone's responsibility and tasks are clear. Some of the roles that cannot be missing are:
- Data owners: responsible for the use of the data in their area (production, quality, maintenance...).
- Data stewards: ensure the consistency, completeness and accuracy of the information.
- Data governance team: coordinates the strategy, defines common policies and evaluates compliance.
▸Structured processes: Like the roles, it is necessary to define the various phases and operations to be carried out. These include the following:
- Classification and cataloguing of data assets (by type, criticality, use).
- Data quality control: definition of validation rules, cleaning of duplicates, exception management.
- Data life cycle: from its creation on the machine to its archiving or destruction.
- Access and security: privilege management, usage audits, traceability.
▸Organisational policies: to ensure interoperability and data quality it is necessary to have standards, norms and guidelines to guide users. Some examples are:
- Standards for nomenclature, formats, encoding and synchronisation.
- Standards for interoperability between systems (e.g. use of standards such as OPC UA or ISA-95).
- Guidelines for ethical and legally compliant use (such as Data Regulation, GDPR or environmental legislation).
This approach makes industrial data an asset managed with the same rigour as any physical infrastructure.
Industrial use cases enabled by data governance
The benefits of data governance in industry are realised in multiple practical applications. Some of the most representative use cases are:
1.Predictive maintenance
One of the great classics of Industry 4.0. By combining historical maintenance data with real-time sensors, organisations can anticipate machine failures and avoid unexpected downtime. But this is only possible if the data is governed: if its capture frequency, format, responsible parties, quality and availability have been defined.
2. Complete product traceability
From raw material to end customer, every event in the value chain is recorded and accessible. This is vital for sectors such as food, automotive or pharmaceuticals, where traceability is both an added value and a regulatory obligation. Data governance ensures that this traceability is not lost, is verifiable and meets the required interoperability standards.
3. Digital twins and process simulation
For a digital twin - a virtual replica of a physical process or system - to work, it needs to be fed with accurate, up-to-date and consistent data. Data governance ensures synchronisation between the physical and virtual worlds, and allows the generation of reliable simulation scenarios, from the design of a new production line to the optimisation of the factory layout, i.e. of the different elements within the plant.
4. Energy monitoring and emission control
Real-time monitoring of energy, water or gas consumption can reveal hidden inefficiencies and opportunities for savings. Through intelligent dashboards and KPIs defined on governed data, industrial plants can reduce their costs and advance their environmental sustainability goals.
5. Automation and intelligent quality control
Machine vision systems and machine learning algorithms trained with production data allow to detect defects in real time, adjust parameters automatically and improve final quality. Without good data quality (accuracy, completeness, consistency), these algorithms can fail or generate unreliable results.
The National Industry Data Space: key to collaboration and competitiveness
For industrial data governance to transcend the scope of each company and become a real lever for sectoral transformation, it is necessary to have infrastructures that facilitate the secure, reliable and efficient sharing of data between organisations. The National Data Space for Industry, framed within the Plan for the Promotion of Sectoral Data Spaces promoted by the Ministry for Digital Transformation and the Civil Service, is in this line.
This space aims to create an environment of trust where companies, associations, technology centres and administrations can share and reuse industrial data in an interoperable manner, in accordance with ethical, legal and technical principles. Through this framework, the aim is to enable new forms of collaboration, accelerate innovation and reinforce the strategic autonomy of the national productive fabric.
The industrial sector in Spain is enormously diverse, with an ecosystem made up of large corporations, SMEs, suppliers, subcontractors, clusters and R&D centres. This diversity can become a strength if it is articulated through a common data infrastructure that facilitates the integration and exchange of information in an orderly and secure manner. Moreover, these industrial data can be complemented with open data published by public bodies, such as those available in the National Catalogue of Open Data, thus extending the value and possibilities of reuse for the sector as a whole.
The strengths of this common infrastructure allow:
- Detect synergies along the value chain, such as industrial recycling opportunities between different sectors (e.g. plastic waste from one chemical industry as raw material in another).
- Reducing entry barriers to digitisation, especially for SMEs that do not have the resources to deploy advanced data analytics solutions, but could access shared services or data within the space.
- Encourage open innovation models where companies share data in a controlled way for the joint development of solutions based on artificial intelligence or predictive maintenance.
- Promote sectoral aggregate indicators, such as shared carbon footprints, energy efficiency levels or industrial circularity indices, which allow the country as a whole to make more coordinated progress towards sustainability and competitiveness objectives.
The creation of the National Industrial Data Space can be a true lever for modernization for the Spanish industrial fabric:
- Increased international competitiveness, by facilitating compliance with European market requirements, such as the Data Regulation, the Digital Product Passport, and sustainability standards.
- Regulatory agility and improved traceability, allowing industries to respond quickly to audits, certifications, or regulatory changes.
- Proactive capacity, thanks to the joint analysis of production, consumption, or market data that allows for the prediction of disruptions in supply chains or the demand for critical resources.
- Creation of new business models, based on the provision of products as a service, the reuse of materials, or the shared leasing of industrial capacities.
The deployment of this national data space not only seeks to improve the efficiency of industrial processes. It also aims to strengthen the country's technological and data sovereignty, enabling a model where the value generated by data remains within the companies, regions, and sectors themselves. In this sense, the National Industrial Data Space aligns with European initiatives such as GAIA-X and Manufacturing-X, but with an approach adapted to the context and needs of the Spanish industrial ecosystem.
Conclusions
Data governance is a fundamental pillar for the industry to move toward more efficient, sustainable, and resilient models. Having large volumes of information is not enough: it must be managed properly to generate real value.
The benefits are clear: operational optimization, improved traceability, a boost to the circular economy, and support for technologies such as artificial intelligence and digital twins. But the real leap forward comes when data is no longer managed in isolation and becomes part of a shared ecosystem.
The National Industrial Data Space offers this framework for collaboration and trust, facilitating innovation, competitiveness, and technological sovereignty. Investing in its development means investing in a more connected, intelligent industry that is prepared for the challenges of the future.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The content and point of view reflected in this publication are the sole responsibility of its author.
Blog
Over the last decade, the amount of data that organisations generate and need to manage has grown exponentially. With the rise of the cloud, Internet of Things (IoT), edge computing and artificial intelligence (AI), enterprises face the challenge of integrating and governing data from multiple sources and environments. In this context, two key approaches to data management have emerged that seek to solve the problems associated with data centralisation: Data Mesh y Data Fabric. Although these concepts complement each other, each offers a different approach to solving the data challenges of modern organisations.
Why is a data lake not enough?
Many companies have implemented data lakes or centralised data warehouses with dedicated teams as a strategy to drive company data analytics. However, this approach often creates problems as the company scales up, for example:
- Centralised data equipment becomes a bottleneck. These teams cannot respond quickly enough to the variety and volume of questions that arise from different areas of the business.
- Centralisation creates a dependency that limits the autonomy of domain teams, who know their data needs best.
This is where the Data Meshapproach comes in.
Data Mesh: a decentralised, domain-driven approach
Data Mesh breaks the centralisation of data and distributes it across specific domains, allowing each business team (or domain team) to manage and control the data it knows and uses most. This approach is based on four basic principles:
- Domain ownership: instead of a central data computer having all the control, each computer is responsible for the data it generates. That is, if you are the sales team, you manage the sales data; if you are the marketing team, you manage the marketing data. Nobody knows this data better than the team that uses it on a daily basis.
- Data as a product: this idea reminds us that data is not only for the use of the domain that generates it, but can be useful for the entire enterprise. So each team should think of its data as a "product" that other teams can also use. This implies that the data must be accessible, reliable and easy to find, almost as if it were a public API.
- Self-service platform: decentralisation does not mean that every team has to reinvent the wheel. To prevent each domain team from specialising in complex data tools, the Data Mesh is supported by a self-service infrastructure that facilitates the creation, deployment and maintenance of data products. This platform should allow domain teams to consume and generate data without relying on high technical expertise.
- Federated governance: although data is distributed, there are still common rules for all. In a Data Mesh, governance is "federated", i.e. each device follows globally defined interoperability standards. This ensures that all data is secure, high quality and compliant.
These principles make Data Mesh an ideal architecture for organisations seeking greater agility and team autonomy without losing sight of quality and compliance. Despite decentralisation, Data Mesh does not create data silos because it encourages collaboration and standardised data sharing between teams, ensuring common access and governance across the organisation.
Data Fabric: architecture for secure and efficient access to distributed data
While the Data Mesh focuses on organising and owning data around domains, the Data Fabric is an architecture that allows connecting and exposing an organisation''s data, regardless of its location. Unlike approaches based on data centralisation, such as the data lake, the Data Fabric acts as a unified layer, providing seamless access to data distributed across multiple systems without the need to physically move it to a single repository.
In general terms, the Data Fabric is based on three fundamental aspects:
- Access to data: in a modern enterprise, data is scattered across multiple locations, such as data lakes, data warehouses, relational databases and numerous SaaS (Software as-a-Service) applications. Instead of consolidating all this data in one place, the Data Fabric employs a virtualisation layer that allows it to be accessed directly from its original sources. This approach minimises data duplication and enables real-time access, thus facilitating agile decision-making. In cases where an application requires low latencies, the Data Fabric also has robust integration tools, such as ETL (extract, transform and load), to move and transform data when necessary.
- Data lifecycle management: the Data Fabric not only facilitates access, but also ensures proper management throughout the entire data lifecycle. This includes critical aspects such as governance, privacy and compliance. The architecture of the Data Fabric relies on active metadata that automates the application of security and access policies, ensuring that only users with the appropriate permissions access the corresponding information. It also offers advanced traceability (lineage) functionalities, which allow tracking the origin of data, knowing its transformations and assessing its quality, which is essential in environments regulated under regulations such as the General Data Protection Regulation (GDPR).
- Data exposure: after connecting the data and applying the governance and security policies, the next step of the Data Fabric is to make that data available to end users. Through enterprise catalogues, data is organised and presented in a way that is accessible to analysts, data scientists and developers, who can locate and use it efficiently.
In short, the Data Fabric does not replace data lakes or data warehouses, but facilitates the integration and management of the organisation''s existing data. It aims to create a secure and flexible environment that enables the controlled flow of data and a unified view, without the need to physically move it, thus driving more agile and informed decision-making.
Data Mesh vs. Data Fabric. Competitors or allies?
While Data Mesh and Data Fabric have some objectives in common, each solves different problems and, in fact, benefits can be found in applying mechanisms from both approaches in a complementary manner. The following table shows a comparison of the two approaches:
| APEARANCE | DATA MESH | DATA FABRIC |
|---|---|---|
| Approach | Organisational and structural, domain-oriented. | Technical, focusing on data integration. |
| Purpose | Decentralise ownership and responsibility for data to domain teams. | Create a unified data access layer distributed across multiple environments. |
| Data management | Each domain manages its own data and defines quality standards. | Data is integrated through services and APIs, allowing a unified view without physically moving data. |
| Governance | Federated, with rules established by each domain, maintaining common standards. | Centralised at platform level, with automation of access and security policies through active metadata. |
Figure 1. Comparative table of Data Mesh VS. Data Fabric. Source: Own elaboration.
Conclusion
Both Data Mesh and Data Fabric are designed to solve the challenges of data management in modern enterprises. Data Mesh brings an organisational approach that empowers domain teams, while Data Fabric enables flexible and accessible integration of distributed data without the need to physically move it. The choice between the two, or a combination of the two, will depend on the specific needs of each organisation, although it is important to consider the investment in infrastructure, training and possible organisational changes that these approaches require. For small to medium-sized companies, a traditional data warehouse can be a practical and cost-effective alternative, especially if their data volumes and organisational complexity are manageable. However, given the growth of data ecosystems in organisations, both models represent a move towards a more agile, secure and useful data environment, facilitating data management that is better aligned with strategic objectives in an environment.
Definitions
- Data Lake: it is a storage repository that allows large volumes of data to be stored in their original format, whether structured, semi-structured or unstructured. Its flexible structure allows raw data to be stored and used for advanced analytics and machine learning.
- Data Warehouse: it is a structured data storage system that organises, processes and optimises data for analysis and reporting. It is designed for quick queries and analysis of historical data, following a predefined scheme for easy access to information.
References
- Dehghani, Zhamak. Data Mesh Principles and Logical Architecture. https://martinfowler.com/articles/data-mesh-principles.html.
- Dehghani, Zhamak. Data Mesh: Delivering Data-Driven Value at Scale. O''Reilly Media. Book detailing the implementation and fundamental principles of Data Mesh in organisations.
- Data Mesh Architecture. Website about Data Mesh and data architectures. https://www.datamesh-architecture.com/
- IBM Data Fabric. IBM Topics. https://www.ibm.com/topics/data-fabric
- IBM Technology. Data Fabric. Unifying Data Across Hybrid and Multicloud Environments. YouTube. https://www.youtube.com/watch?v=0Zzn4eVbqfk&t=4s&ab_channel=IBMTechnology
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
In an increasingly data-driven world, all organisations, both private companies and public bodies, are looking to leverage their information to make better decisions, improve the efficiency of their processes and meet their strategic objectives. However, creating an effective data strategy is a challenge that should not be underestimated.
Often, organisations in all sectors fall into common mistakes that can compromise the success of their strategies from the outset. From ignoring the importance of data governance to not aligning strategic objectives with the real needs of the institution, these failures can result in inefficiencies, non-compliance with regulations and even loss of trust by citizens, employees or users.
In this article, we will explore the most common mistakes in creating a data strategy, with the aim of helping both public and private entities to avoid them. Our goal is to provide you with the tools to build a solid foundation to maximise the value of data for the benefit of your mission and objectives.

Figure 1. Tips for designing a data governance strategy. Source: own elaboration.
The following are some of the most common mistakes in developing a data strategy, justifying their impact and the extent to which they can affect an organisation:
Lack of linkage to organisational objectives and failure to identify key areas
For data strategy to be effective in any type of organisation, it is essential that it is aligned with its strategic objectives. These objectives include key areas such as revenue growth, service improvement, cost optimisation and customer/citizen experience. In addition, prioritising initiatives is essential to identify the areas of the organisation that will benefit most from the data strategy. This approach not only allows maximising the return on data investment, but also ensures that initiatives are clearly connected to desired outcomes, reducing potential gaps between data efforts and strategic objectives.
Failure to define clear short- and medium-term objectives
Defining specific and achievable goals in the early stages of a data strategy is very important to set a clear direction and demonstrate its value from the outset. This boosts the motivation of the teams involved and builds trust between leaders and stakeholders. Prioritising short-term objectives, such as implementing a dashboard of key indicators or improving the quality of a specific set of critical data, delivers tangible results quickly and justifies the investment in the data strategy. These initial achievements not only consolidate management support, but also strengthen the commitment of the teams.
Similarly, medium-term objectives are essential to build on initial progress and prepare the ground for more ambitious projects. For example, the automation of reporting processes or the implementation of predictive models for key areas can be intermediate goals that demonstrate the positive impact of the strategy on the organisation. These achievements allow us to measure progress, evaluate the success of the strategy and ensure that it is aligned with the organisation's strategic priorities.
Setting a combination of short- and medium-term goals ensures that the data strategy remains relevant over time and continues to generate value. This approach helps the organisation to move forward in a structured way, strengthening its position both vis-à-vis its competitors and in fulfilling its mission in the case of public bodies.
Failure to conduct a maturity assessment beforehand to define the strategy as narrowly as possible.
Before designing a data strategy, it is crucial to conduct a pre-assessment to understand the current state of the organisation in terms of data and to realistically and effectively scope it. This step not only prevents efforts from being dispersed, but also ensures that the strategy is aligned with the real needs of the organisation, thus maximising its impact. Without prior assessment, it is easy to fall into the error of taking on initiatives that are too broad or poorly connected to strategic priorities .
Therefore, conducting this pre-assessment is not only a technical exercise, but a strategic tool to ensure that resources and efforts are well targeted from the outset. With a clear diagnosis, the data strategy becomes a solid roadmap, capable of generating tangible results from the earliest stages. It should be recalled that the UNE 0080:2023, which focuses on the assessment of the maturity of data governance and management, provides a structured framework for this initial assessment. This standard allows for an objective analysis of the organisation's processes, technologies and capabilities around data..
Failure to carry out data governance initiatives
The definition of a sound strategy is fundamental to the success of data governance initiatives. It is essential to have an area or unit responsible for data governance, such as a data office or a centre of excellence, where clear guidelines are established and the necessary actions are coordinated to achieve the committed strategic objectives. These initiatives must be aligned with the organisation's priorities, ensuring that the data is secure, usable for its intended purpose and compliant with applicable laws and regulations.
A robust data governance framework is key to ensuring consistency and quality of data, strengthening confidence in reporting and analysis that generates both internal and external value. In addition, an appropriate approach reduces risks such as non-compliance, promoting effective use of data and protecting the organisation's reputation.
It is therefore important to design these initiatives with a holistic approach, prioritising collaboration between different areas and aligning them with the overall data strategy. For more information on how to structure an effective data governance system, see this series of articles: From data strategy to data governance system - Part 1.
Focusing exclusively on technology
Many organisations have the mistaken view that acquiring sophisticated tools and platforms will be the ultimate solution to their data problems. However, technology is only one part of the ecosystem. Without the right processes, governance framework and, of course, people, even the best technology will fail. This is problematic because it can lead to huge investments with no clear return, as well as frustration among teams when they do not get the expected results.
Failure to involve all stakeholders and define roles and responsibilities
A sound data strategy needs to bring together all relevant actors, whether in a public administration or in a private company. Each area, department or unit has a unique vision of how data can be useful to achieve objectives, improve services or make more informed decisions. Therefore, involving all stakeholders from the outset not only enriches the strategy, but also ensures that they are aligned with the real needs of the organisation.
Likewise, defining clear roles and responsibilities is key to avoid confusion and duplication. Knowing who is responsible for the data, who manages it and who uses it ensures a more efficient workflow and fosters collaboration between teams. In both the public and private spheres, this approach helps to maximise the impact of the data strategy, ensuring that efforts are coordinated and focused towards a common goal.
Failure to establish clear metrics of success
Establishing key performance indicators (KPIs) is essential to assess whether initiatives are generating value. KPIs help demonstrate the results of the data strategy, reinforcing leadership support and encouraging willingness to invest in the future. By measuring the impact of actions, organisations can guarantee the sustainability and continuous development of their strategy, ensuring that it is aligned with strategic objectives and delivers tangible benefits.
Failure to place data quality at the centre
A sound data strategy must be built on a foundation of reliable and high quality data. Ignoring this aspect can lead to wrong decisions, inefficient processes and loss of trust in data by teams. Data quality is not just a technical aspect, but a strategic enabler: it ensures that the information used is complete, consistent, valid and timely.
Integrating data quality from the outset involves defining clear metrics, establishing validation and cleansing processes, and assigning responsibilities for their maintenance. Furthermore, by placing data quality at the heart of the strategy, organisations can unlock the true potential of data, ensuring that it accurately supports business objectives and reinforces user confidence. Without quality, the strategy loses momentum and becomes a wasted opportunity.
Failure to manage cultural change and resistance to change
The transition to a data-driven organisation requires not only tools and processes, but also a clear focus on change management to engage employees. Promoting an open mind towards new practices is key to ensuring the adoption and success of the strategy. By prioritising communication, training and team engagement, organisations can facilitate this cultural change, ensuring that all levels work in alignment with strategic objectives and maximising the impact of the data strategy.
Not planning for scalability
It is critical for organisations to consider how their data strategy can scale as the volume of information grows. Designing a strategy ready to handle this growth ensures that systems can support the increase in data without the need for future restructuring, optimising resources and avoiding additional costs. By planning for scalability, organisations can ensure long-term sustainable operational efficiency and maximise the value of their data as their needs evolve.
Lack of continuous updating and review of the strategy
Data and organisational needs are constantly evolving, so it is important to regularly review and adapt the strategy to keep it relevant and effective. A flexible and up-to-date data strategy allows you to respond nimbly to new opportunities and challenges, ensuring that you continue to deliver value as market or organisational priorities change. This proactive approach ensures that the strategy remains aligned with strategic objectives and reinforces its long-term positive impact.
In conclusion, it is important to highlight that the success of a data strategy lies in its ability to align with the strategic objectives of the organisation, setting clear goals and encouraging the participation of all areas involved. A good data governance system, accompanied by metrics to measure its impact, is the basis for ensuring that the strategy generates value and is sustainable over time.
In addition, addressing issues such as data quality, cultural change and scalability from the outset is essential to maximise its effectiveness. Focusing exclusively on technology or neglecting these elements can limit results and jeopardise the organisation's ability to adapt to new opportunities and challenges. Finally, continuously reviewing and updating the strategy ensures its relevance and reinforces its positive impact.
To learn more about how to structure an effective data strategy and its connection with a solid data governance system, we recommend exploring the articles published in datos.gob.es: From Data Strategy to Data Governance System - Part 1 and Part 2.. These resources complement the concepts presented in this article and offer practical insights for implementation in any type of organisation.
Content elaborated by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The content and the point of view reflected in this publication are the sole responsibility of its author.
Noticia
On 28 November, the 2nd Forum for the Government and the Autonomous Communities to meet around data was held in Seville, organised by the State Secretariat for Digitalisation and Artificial Intelligence (SEDIA), in collaboration with the Andalusian Institute of Statistics and Cartography (IECA) and the Digital Agency of Andalusia (ADA). Almost all the autonomous communities participated, reflecting their commitment to data as a strategic driver of digital transformation.
The programme addressed key issues, such as the lessons learned in the implementation of data governance, the impact of its ethical use, and the potential of public-private collaboration in the deployment of sectoral data spaces, with emphasis on the Plan for the Promotion of Sectoral Data Spaces recently presented by the Ministry for Digital Transformation on 21 November.
Here is a summary of the key points of the meeting.
A space to exchange experiences, success stories and lessons learned.
The event brought together more than 70 experts from units of the General State Administration and 15 autonomous communities and the Autonomous City of Melilla, which are active in the use and management of data in their organisations. El objetivo era poner en común las experiencias en este ámbito y compartir los casos de éxito y los aprendizajes derivados de la implantación de iniciativas de gobierno del dato, promoviendo la colaboración entre administraciones para mejorar la competitividad y la eficiencia digital futura.
The forum was opened by the Regional Minister of Presidency, Interior, Social Dialogue and Administrative Simplification of the Andalusian Regional Government, and the Director General of Data of the Ministry for Digital Transformation and Public Administration, and was closed by the Director of IECA.
The day was structured around three round tables with 15 speakers. The attendees were also able to answer various questions related to the subject matter of each of these roundtables, in order to ascertain their perceptions in this regard. This format facilitated a fruitful and enriching exchange of ideas that allowed attendees to explore key issues.
- Table 1 "Experiences of implementing Data Governance: Lessons learnt. The first round table focused on different experiences in data governance. The speakers shared the challenges faced and the practical lessons learned, with the aim of serving as an example and point of reflection for similar initiatives that participants might undertake in the future. The importance of support at the highest level and the use of existing frameworks, such as UNE specifications or the DAMA methodology, was stressed. The need to focus not only on technology, but also to respond to cultural and organisational changes, and to establish processes and structures that will last over time was also emphasised.
- Table 2 "Data with purpose: Success stories of ethical and reliable use of data". The second roundtable focused on presenting concrete results obtained through the ethical and reliable use of data. The speakers shared their backgrounds and achievements, illustrating the wide possibilities that a well governed and managed data can generate in terms of citizen service and improvement of public administration. The work to be done on the quantity and quality of datawas highlighted, without losing focus on the future goal, which is to solve today's problems through sustainable projects.
- Table 3 "Data spaces from the perspective of public-private collaboration and the enhancement of public data". The third and final roundtable explored the paradigm of data spaces. Special emphasis was placed on public-private partnerships and how to enhance the value of public data. A highlight of this session was the presentation by the Directorate General for Data of the Plan for the Promotion of Sectoral Data Spaces. This plan seeks to deploy data spaces across the different productive sectors, underlining the fundamental value that quality public data can have in their effective implementation.
Overall, these roundtables not only provided a platform for the exchange of knowledge and experiences, but also laid the groundwork for future collaborations and innovative projects in the field of data management and governance in the Spanish public administration.
Attendees were very appreciative of the wide variety of roles involved, giving different views on something as complex as data governance, which includes many different approaches and competencies. The general perception is that shared experiences help others to try to circumvent the barriers that others have previously had to overcome and to reach the final goal faster, which is to provide better service and implement better public policies for citizens through a data-driven government.
Conclusions of the Forum
Some of the conclusions reached were:
- It is necessary to focus on data quality. Without quality data, well governed and managed, it will be difficult to achieve valuable solutions, for example in the field of artificial intelligence.
- Invest in data governance by ensuring sustainable projects. Data governance is not just about technology, but about business and services. It requires considerable effort on the part of organisations to create data that reflect reality and are truly useful for decision-making, breaking down silos and implementing citizen-oriented services. To this end, it is recommended to build on existing conceptual frameworks, oriented towards processes and organisational structures that are sustainable over time.
- The Autonomous Communities can help the deployment of the Plan for the Promotion of Data Spaces from a public-private partnership perspective and benefit from its actions.
- We need to influence the data culture in organisations. The objective is to incorporate data governance into the different business areas, supporting organisational objectives, ensuring that the data culture permeates the organisation and is perceived as something transversal that contributes value to the different sectors as well as to the administration and society as a whole.
Upcoming performances
After the success of the first edition, held in Navarre in 2023, the forum has been consolidated as a reference space for the exchange of experiences and good practices in data management, essential for those seeking to lead the future of data management in public administrations.
Theday concluded with a proposal for continuity, highlighting the need to create a community of knowledge exchange between editions. Furthermore, the Principality of Asturias has applied to host the third edition of the forum, to be held in 2025, which demonstrates the growing interest in further consolidating this space for inter-institutional cooperation on data.
Entrevista
This episode focuses on data governance and why it is important to have standards, policies and processes in place to ensure that data is correct, reliable, secure and useful. For this purpose, we analyze the Model Ordinance on Data Governance of the Spanish Federation of Municipalities and Provinces, known as the FEMP, and its application in a public body such as the City Council of Zaragoza. This will be done by the following guests:
- Roberto Magro Pedroviejo, coordinator of the Open Data Working Group of the Network of Local Entities for Transparency and Citizen Participation of the Spanish Federation of Municipalities and Provinces and civil servant of the Alcobendas City Council.
- María Jesús Fernández Ruiz, head of the Technical Office of Transparency and Open Government of Zaragoza City Council.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. What is data governance?
Roberto Magro Pedroviejo: We, in the field of Public Administrations, define data governance as an organisational and technical mechanism that comprehensively addresses issues related to the use of data in our organisation. It covers the entire data lifecycle, i.e. from creation to archiving or even, if necessary, purging and destruction. Its purpose is that data is of quality and available to all those who need it: sometimes it will be only the organisation itself internally, but many other times it will be the general public, re-users, the university environment, etc. Data governance must facilitate the right of access to data. In short, data governance makes it possible to respond to the objective of managing our administration effectively and efficiently and achieving greater interoperability between all administrations.
2. Why is this concept important for a municipality?
María Jesús Fernández Ruiz: Because we have found that, within organisations, both public and private, data collection and management is often carried out without following homogeneous criteria, standards or appropriate techniques. This translates into a difficult and costly situation, which is exacerbated when we try to develop a data space or develop data-related services. Therefore, we need an umbrella that obliges us to manage data, as Roberto has said, effectively and efficiently, following homogeneous standards and criteria, which facilitates interoperability.
3. To meet this challenge, it is necessary to establish a set of guidelines to help local administrations set up a legal framework. For this reason, the FEMP Model Ordinance on Data Governance has been created. What was the process of developing this reference document like?
Roberto Magro Pedroviejo: Within the Open Data Network Group that was created back in 2017, one of the people we have counted on and who has contributed a lot of ideas has been María Jesús, from Zaragoza City Council. We were leaving COVID, just in March 2021, and I remember perfectly the meeting we had in a room lent to us by the Madrid City Council in the Cibeles Palace. María Jesús was in Zaragoza and joined the meeting by videoconference. On that day, seeing what things and what work we could tackle within this multidisciplinary group, María Jesús proposed creating a model ordinance. The FEMP and the Network already had experience in creating model ordinances to try to improve, and above all help, municipalities and local entities or councils to create regulations.
We started working as a multidisciplinary team, led by José Félix Muñoz Soro, from the University of Zaragoza, who is the person who has coordinated the regulatory text that we have published. And a few months later, in January 2022 to be precise, we held a meeting. We met in person at the Zaragoza City Council and there we began to establish the basis for the model ordinance, what type of articles it should have, what type of structure it should have, etc. And we got together a multidisciplinary team, as we said, which included experts in data governance and jurists from the University of Zaragoza, staff from the Polytechnic University of Madrid, colleagues from the Polytechnic University of Valencia, professionals from the local public sphere and journalists who are experts in open data.
The first draft was published in May/June 2022. In addition, it was made available for public consultation through Zaragoza City Council's Citizen Participation platform. We contacted around 100 national experts and received around 30 contributions of improvements, most of which were included, and which allowed us to have the final text by the end of last year, which was passed to the legal department of the FEMP to validate it. The regulations were published in February 2024 and are now available on the Network's website for free download.
I would like to take this opportunity to thank the excellent work done by all the people involved in the team who, from their respective points of view, have worked selflessly to create this knowledge and share it with all the Spanish public administrations.
4. What are the expected benefits of the ordinance?
María Jesús Fernández Ruiz: For me, one of the main objectives of the ordinance, and I think it is a great instrument, is that it takes the whole life cycle of the data. It covers from the moment the data is generated, how the data is managed, how the data is provided, how the documentation associated with the data must be stored, how the historical data must be stored, etc. The most important thing is that it establishes criteria for managing the data while respecting its entire life cycle.
The ordinance also establishes some principles, which are not many, but which are very important and which set the tone, which speak, for example, of effective data governance and describe the importance of establishing processes when generating the data, managing the data, providing the data, etc.
Another very important principle, which has been mentioned by Roberto, is the ethical treatment of data. In other words, the importance of collecting data traceability, of seeing where the data is moving and of respecting the rights of natural and legal persons.
Another very important principle that generates a lot of noise in the institutions is that data must be managed from the design phase, the management of data by default. Often, when we start working on data with openness criteria, we are already in the middle or near the end of the data lifecycle. We have to design data management from the beginning, from the source. This saves us a lot of resources, both human and financial.
Another important issue for us and one that we advocate within the ordinance is that administration has to be data-oriented. It has to be an administration that is going to design its policies based on evidence. An administration that will consider data as a strategic asset and will therefore provide the necessary resources.
And another issue, which we often discuss with Roberto, is the importance of data culture. When we work on and publish data, data that is interoperable, that is easy to reuse, that is understood, etc., we cannot stop there, but we must talk about the data culture, which is also included in the ordinance. It is important that we disseminate what is data, what is quality data, how to access data, how to use data. In other words, every time we publish a dataset, we must consider actions related to data culture.
5. Zaragoza City Council has been a pioneer in the application of this ordinance. What has this implementation process been like and what challenges are you facing?
María Jesús Fernández Ruiz: This challenge has been very interesting and has also helped us to improve. It was very fast at the beginning and already in June we were going to present the ordinance to the city government. There is a process where the different parties make private votes on the ordinance and say "this point I like", "this point seems more interesting", "this one should be modified", etc. Our surprise is that we have had more than 50 private votes on the ordinance, after having gone through the public consultation process and having appeared in all the media, which was also enriching, and we have had to respond to these votes. The truth is that it has helped us to improve and, at the moment, we are waiting for it to go to government.
When they tell me how do you feel, María Jesús? The answer is well, we are making progress, because thanks to this ordinance, which is pending approval by the Zaragoza City Council government, we have already issued a series of contracts. One that is extremely important for us: to draw up an inventory of data and information sources in our institution, which we believe is the basic instrument for managing data, knowing what data we have, where they originate, what traceability they have, etc. Therefore, we have not stopped. Thanks to this framework that has not yet been approved, we have been able to make progress on the basis of contracts or something that is basic in an institution: the definition of the professionals who have to participate in data management.
6. You mentioned the need to develop an inventory of datasets and information sources, what kind of datasets are we talking about and what descriptive information should be included for each?
Roberto Magro Pedroviejo: There is a core, let's say a central core, with a series of datasets that we recommend in the ordinance itself, referring to other work done in the open data group, which is to recommend 80 datasets that we could publish in Spanish public administrations. The focus is also on high-value datasets, those that can most benefit municipal management or can benefit by providing social and economic value to the general public and to the business community and reusers. Any administration that wants to start working on the issue of datasets and wonders where to start publishing or managing data has to focus, in my view, on three key areas in a city:
- The personal data, i.e. our beloved census: who are the people living in our city, their ages, gender, postal addresses, etc.
- The urban and territorial data, that is, where these people live, what the territorial delimitation of the municipality is, etc. Everything that has to do with these sets of data related to streets, roads, even sewerage, public roads or lighting, needs to be inventoried, to know where these data are and to have them, as we have already said, updated, structured, accessible, etc.
- And finally, everything that has to do with how the city is managed, of course, with the tax and budget area.
That is: the personal sphere, the territorial sphere and the taxation sphere. That is what we recommend to start with. And in the end, this inventory of datasets describes what they are, where they are, how they are and will be the first basis on which to start building data governance.
María Jesús Fernández Ruiz: Another issue that is also very fundamental, which is included in the ordinance, is to define the master datasets. Just a little anecdote. When creating a spatial data space, the street map, the base cartography and the portal holder are basic. When we got together to work, a technical commission was set up and we considered these to be master datasets for Zaragoza City Council. The quality of the data is determined by a concept in the ordinance, which is respecting the sovereignty of the data: whoever creates the data is the sovereign of the data and is responsible for the quality of the data. Sovereignty must be respected and that determines quality.
We then discovered that, in Zaragoza City Council, we had five different portal identifiers. To improve this situation, we define a descriptive unique identifier which we declare as master data. In this way, all municipal entities will use the same identifier, the same street map, the same cartography, etc. and this will make all services related to the city interoperable.
7. What additional improvements do you think could be included in future revisions of the ordinance?
Roberto Magro Pedroviejo: The ordinance itself, being a regulatory instrument, is adapted to current Spanish and European regulations. In other words, we will have to be very vigilant -we are already - to everything that is being published on artificial intelligence, data spaces and open data. The ordinance will have to be adapted because it is a regulatory framework to comply with current legislation, but if that regulatory framework changes, we will make the appropriate modifications for compliance.
I would also like to highlight two things. There have been more town councils and a university, specifically the Town Council of San Feliu de Llobregat and the University of La Laguna, interested in the ordinance. We have received more requests to know a little more about the ordinance, but the bravest have been the Zaragoza City Council, who were the ones who proposed it and are the ones who are suffering the process of publication and final approval. From this experience that Zaragoza City Council itself is gaining, we will surely all learn, about how to tackle it in each of the administrations, because we copy each other and we can go faster. I believe that, little by little, once Zaragoza publishes the ordinance, other city councils and other institutions will join in. Firstly, because it helps to organise the inside of the house. Now that we are in a process of digital transformation that is not fast, but rather a long process, this type of ordinance will help us, above all, to organise the data we have in the administration. Data and the management of data governance will help us to improve public management within the organisation itself, but above all in terms of the services provided to citizens.
And the last thing I wanted to emphasise, which is also very important, is that, if the data is not of high quality, is not updated and is not metadata-driven, we will do little or nothing in the administration from the point of view of artificial intelligence, because artificial intelligence will be based on the data we have and if it is not correct or updated, the results and predictions that AI can make will be of no use to us in the public administration.
María Jesús Fernández Ruiz: What Roberto has just said about artificial intelligence and quality data is very important. And I would like to add two things that we are learning in implementing this ordinance. Firstly, the need to define processes, i.e. efficient data management has to be based on processes. And another thing that I think we should talk about, and we will talk about within the FEMP, is the importance of defining the roles of the different professionals involved in data management. We are talking about data manager, data provider, technology provider, etc. If I had the ordinance now, I would talk about that definition of the roles that have to be involved in efficient data management. That is, processes and professionals.
Interview clips
Clip 1. What is data governance?
Clip 2. What is the FEMP Model Ordinance on Data Governance?