Aplicación
Menosdeluz.com es una web que permite a los usuarios encontrar información sobre el mercado eléctrico. Ofrece información sobre el precio de la luz de cada día y cada hora, evolución del precio del tope de gas y sobre energía solara. En la web, se alojan también tres comparadores de tarifas de luz que leyendo una factura busca en segundos la mejor tarifa de luz comercial para el usuario. La aplicación permite también realizar un análisis de potencia para ayudar al usuario a identificar la posibilidad de ahorrar ajustando la potencia a su uso diario. El uso de las aplicaciones de menosdeluz.com es gratuito.
Aplicación
Play4CYL es una aplicación web desarrollada por Daniel Heras y Carlos Montero para el VI Concurso de Datos Abiertos de Castilla y León. Esta iniciativa recibió el ‘Premio estudiantes’ (dotado con 1.500€) en la categoría ‘Productos y Servicios’, que reconoce aquellos proyectos que proporcionan estudios, servicios, sitios web o aplicaciones para dispositivos móviles que utilizan la información del Portal de Datos Abiertos de la Junta de Castilla y León para su desarrollo.
Se trata de una aplicación web que presenta un mapa interactivo para localizar zonas recreativas en espacios naturales, así como árboles singulares y miradores de la comunidad autónoma. Además, presenta otras secciones con información acerca de la población total y los juegos tradicionales típicos de cada zona.
Blog
A medida que una mayor parte de nuestras vidas cotidianas se desarrolla online, y al mismo tiempo que la importancia y el valor de los datos personales aumenta en nuestra sociedad, las normas que protegen el derecho universal y fundamental a la privacidad, la seguridad y a la intimidad – respaldadas por marcos como la Declaración Universal de los Derechos Humanos o la Declaración Europea de Derechos Digitales – resultan cada vez de mayor importancia.
Hoy en día, nos enfrentamos también a una serie de nuevos retos en relación con nuestra privacidad y nuestros datos personales. Según el último informe de la Fundación Lloyd's Register, al menos tres de cada cuatro usuarios de internet están preocupados porque su información personal pueda ser robada o utilizada de algún modo sin su permiso. Por todo lo anterior, cada vez resulta también más urgente el poder garantizar que las personas estén en condiciones de conocer y controlar sus datos personales en todo momento.
Hoy en día, la balanza se inclina claramente hacia las grandes plataformas que son las que cuentan con los recursos necesarios para recopilar, comerciar y tomar decisiones basadas en nuestros datos personales – mientras que los individuos solo pueden aspirar a obtener cierto control sobre lo que ocurre con sus datos, generalmente previo gran esfuerzo.
Por ese motivo surgen iniciativas como MyData Global, una organización sin ánimo de lucro que lleva ya varios años promoviendo un enfoque de la gestión de datos personales centrado en el ser humano y abogando por garantizar el derecho de las personas a participar activamente en la economía del dato. El objetivo es restablecer el equilibrio y avanzar hacia una visión de los datos centrada en las personas para construir una sociedad digital más justa, sostenible y próspera cuyos pilares serían:
-
Establecer relaciones de confianza y seguridad entre las personas y las organizaciones.
-
Conseguir la autonomía en materia de datos, no sólo mediante la protección legal, sino también con medidas para compartir y distribuir el poder de los datos.
-
Maximizar los beneficios colectivos de los datos personales, compartiéndolos equitativamente entre las organizaciones, los individuos y la sociedad.
Y para poder introducir los cambios necesarios que den lugar a este nuevo enfoque más humano de los datos personales se han elaborado los siguientes principios:
1 – Control de los datos centrado en las personas
Son las personas las que deben tener el poder de decisión en la gestión de todo lo concerniente a su vida personal. Para ello deben disponer de los medios prácticos necesarios que les permitan comprender y controlar eficazmente quién tiene acceso a sus datos y cómo se utilizan y comparten.
La privacidad, la seguridad y el uso mínimo de datos deben ser prácticas habituales en el diseño de aplicaciones y las condiciones de uso de los datos personales deben ser negociadas de forma justa entre particulares y organizaciones.
2 – Las personas como punto central de integración
El valor de los datos personales crece exponencialmente con su diversidad, a la vez que crece también la potencial amenaza hacia la privacidad. Esta aparente contradicción podría resolverse si colocamos a las personas como eje central en cualquier intercambio de datos, centrándonos siempre en sus propias necesidades por encima de cualquier otra motivación.
Todo uso de los datos personales debe girar en torno al individuo a través de una profunda personalización de las herramientas y los servicios.
3 – Autonomía individual
En una sociedad impulsada por los datos, los individuos no deberían ser vistos únicamente como clientes o usuarios de servicios y aplicaciones. Deben ser considerados agentes libres y autónomos, capaces de establecer y perseguir sus propios objetivos.
Las personas deben poder gestionar con seguridad sus datos personales de la manera que prefieran, contando siempre con las herramientas, habilidades y asistencia necesarias.
4 – Portabilidad, acceso y reutilización
Permitir que las personas puedan obtener y reutilizar sus datos personales para sus propios fines y en diferentes servicios es la clave para pasar de los silos de datos aislados a los datos como recursos reutilizables.
La portabilidad de datos no debe ser un mero derecho legal, sino combinarse con medios prácticos para que las personas puedan trasladar eficazmente los datos a otros servicios o en sus dispositivos personales de forma segura y sencilla.
5 – Transparencia y responsabilidad
Las organizaciones que utilizan los datos de una persona deben ser transparentes en el uso que hacen de ellos y la finalidad que persiguen. Al mismo tiempo, deben asumir su responsabilidad sobre la gestión que hacen de esos datos, incluido cualquier incidente de seguridad.
Se deben crear canales fáciles de usar y seguros para que las personas puedan conocer y controlar lo que ocurre con sus datos en todo momento, y poder así también cuestionar las decisiones basadas únicamente en algoritmos.
6 – Interoperabilidad
Es necesario minimizar la fricción en el flujo de datos desde las fuentes de origen a los servicios que los utilizan. Para ello hay que incorporar los efectos positivos de los ecosistemas abiertos e interoperables, incluyendo protocolos, aplicaciones e infraestructura. Esto se logrará a través de la aplicación de normas y prácticas comunes y estándares técnicos.
La comunidad de MyData lleva ya años aplicando estos principios en su trabajo para conseguir difundir una visión más humana de la gestión, tratamiento y uso de los datos centrada en las personas, como está haciendo por ejemplo en la actualidad a través de su papel en el Data Spaces Support Centre, un proyecto de referencia que está llamado a definir el futuro uso y gobierno responsable de los datos en la Unión Europea.
Y para quien quiera profundizar más en el uso de los datos centrado en las personas, tendremos en breve una nueva edición de MyData Conference, que este año se centrará en mostrar casos prácticos en los que la recopilación, el procesamiento y el análisis de los datos personales sirven principalmente a las necesidades y experiencias de los seres humanos.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La crisis humanitaria que se originó tras el terremoto de Haití en 2010 fue el punto de partida de una iniciativa voluntaria para crear mapas que identificaran el nivel de daño y vulnerabilidad por zonas, y así, poder coordinar los equipos de emergencia. Desde entonces, el proyecto de mapeo colaborativo conocido como Hot OSM (OpenStreetMap) realiza una labor clave en situaciones de crisis y desastres naturales.
Ahora, la organización ha evolucionado hasta convertirse en una red global de voluntarios que aportan sus habilidades de creación de mapas en línea para ayudar en situaciones de crisis por todo el mundo. La iniciativa es un ejemplo de colaboración en torno a los datos para resolver problemas de la sociedad, tema que desarrollamos en este informe de datos.gob.es.
Hot OSM trabaja para acelerar la colaboración con organizaciones humanitarias y gubernamentales en torno a los datos, así como con comunidades locales y voluntarios de todo el mundo, para proporcionar mapas precisos y detallados de áreas afectadas por desastres naturales o crisis humanitarias. Estos mapas se utilizan para ayudar a coordinar la respuesta de emergencia, identificar necesidades y planificar la recuperación.
En su trabajo, Hot OSM prioriza la colaboración y el empoderamiento de las comunidades locales. La organización trabaja para garantizar que las personas que viven en las áreas afectadas tengan voz y poder en el proceso de mapeo. Esto significa que Hot OSM trabaja en estrecha colaboración con las comunidades locales para asegurarse de que se mapeen áreas importantes para ellos. De esta manera, se tienen en cuenta las necesidades de las comunidades a la hora de planificar respuesta de emergencia y la recuperación.
Labor didáctica de Hot OSM
Además de su trabajo en situaciones de crisis, Hot OSM dedica esfuerzos a la promoción del acceso a datos geoespaciales abiertos y libres, y trabaja en colaboración con otras organizaciones para construir herramientas y tecnologías que permitan a las comunidades de todo el mundo aprovechar el poder del mapeo colaborativo.
A través de su plataforma en línea, Hot OSM proporciona acceso gratuito a una amplia gama de herramientas y recursos para ayudar a los voluntarios a aprender y participar en la creación de mapas colaborativos. La organización también ofrece capacitación para aquellos interesados en contribuir a su trabajo.
Un ejemplo de proyecto de HOT es el trabajo que la organización realizó en el contexto del ébola en África Occidental. En 2014, un brote de ébola afectó a varios países de África Occidental, incluidos Sierra Leona, Liberia y Guinea. La falta de mapas precisos y detallados en estas áreas dificultó la coordinación de la respuesta de emergencia.
En respuesta a esta necesidad, HOT inició un proyecto de mapeo colaborativo que involucró a más de 3.000 voluntarios en todo el mundo. Los voluntarios utilizaron herramientas en línea para mapear áreas afectadas por el ébola, incluidas carreteras, pueblos y centros de tratamiento.
Este mapeo permitió a los trabajadores humanitarios coordinar mejor la respuesta de emergencia, identificar áreas de alto riesgo y priorizar la asignación de recursos. Además, el proyecto también ayudó a las comunidades locales a comprender mejor la situación y a participar en la respuesta de emergencia.
Este caso en África Occidental es solo un ejemplo del trabajo que HOT realiza en todo el mundo para ayudar en situaciones de crisis humanitarias. La organización ha trabajado en una variedad de contextos, incluidos terremotos, inundaciones y conflictos armados, y ha ayudado a proporcionar mapas precisos y detallados para la respuesta de emergencia en cada uno de estos contextos.
Por otro lado, la plataforma también está involucrada en zonas en las que no hay cobertura de mapas, como en muchos países africanos. En estas zonas los proyectos de ayuda humanitaria muchas veces tienen un gran reto en las primeras fases, ya que es muy difícil cuantificar qué población vive en una zona y donde está emplazada. Poder tener la ubicación esas personas y que muestre vías de acceso las “pone en el mapa” y permite que puedan llegar a acceder a los recursos.
En el artículo The evolution of humanitarian mapping within the OpenStreetMap community de Nature, podemos ver gráficamente algunos de los logros de la plataforma.
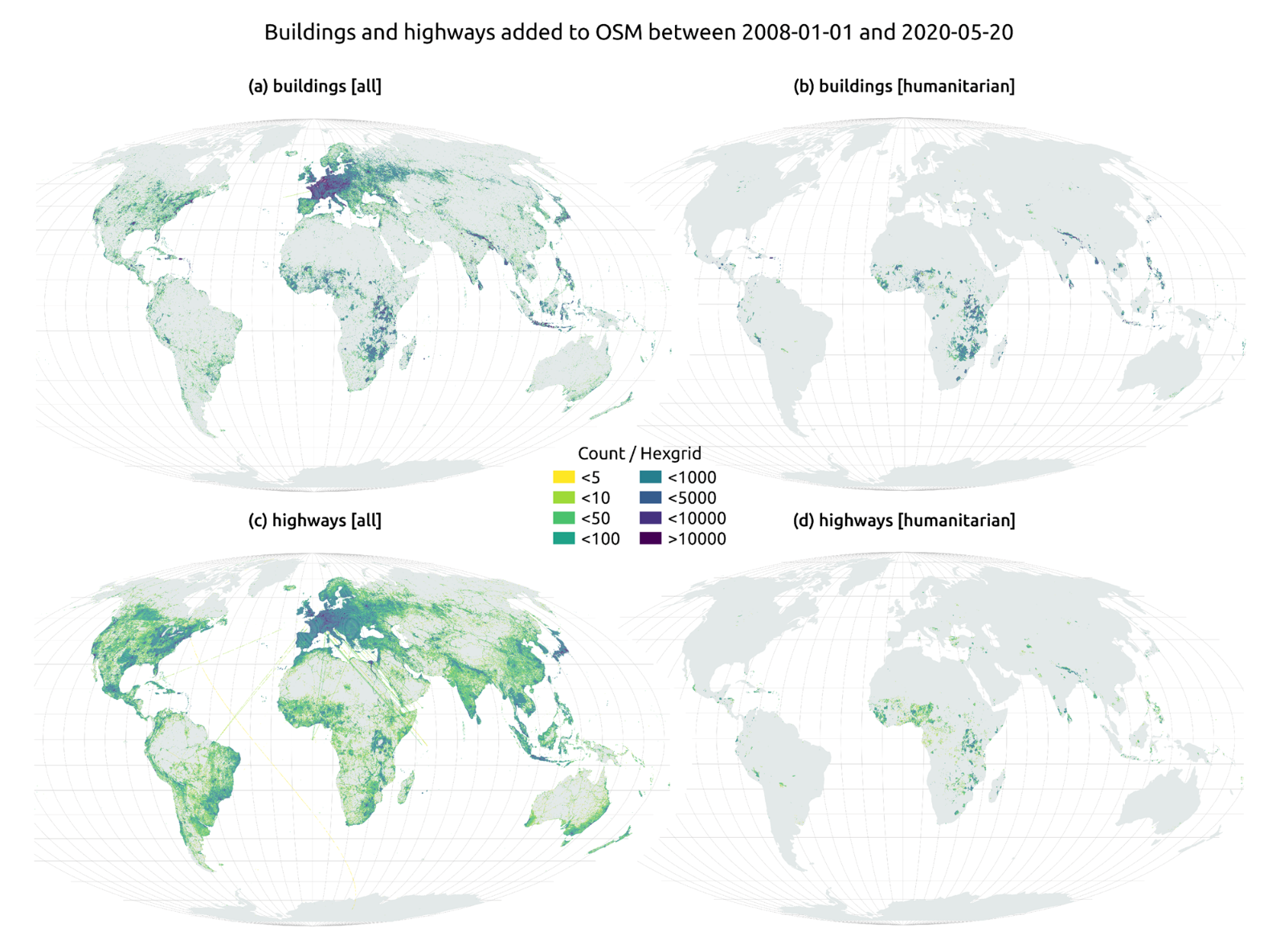
Como colaborar
Empezar a colaborar con Hot OSM es fácil, basta con ir a la página https://tasks.hotosm.org/explore y ver los proyectos abiertos que necesitan colaboración.
Esta pantalla nos permite una gran cantidad de opciones a la hora de buscar los proyectos, seleccionado por nivel de dificultad, organización, ubicación o intereses entre otros.
Para participar, basta con pulsar el botón Registrese.
Dar un nombre y un e-mail y en la siguiente pantalla:

Nos preguntará si tenemos creada una cuenta en Open Street Maps o queremos crear una.
Si queremos ver más en detalle el proceso, esta página nos lo pone muy fácil.
Una vez creado el usuario, en la página aprender encontramos ayuda de cómo participar en el proyecto.
Es importante destacar que las contribuciones de los voluntarios se revisan y validan y existe un segundo nivel de voluntarios, los validadores, que dan por bueno el trabajo de los principiantes. Durante el desarrollo de la herramienta, el equipo de HOT ha cuidado mucho que sea una aplicación sencilla de utilizar para no limitar su uso a personas con conocimientos informáticos.
Además, organizaciones como Cruz Roja o Naciones unidas organizan regularmente mapatones con el objetivo de reunir grupos de personas para proyectos específicos o enseñar a nuevos voluntarios el uso de la herramienta. Estas reuniones sirven, sobre todo, para quitar el miedo de los nuevos usuarios a “romper algo” y para que puedan ver cómo su labor de voluntariado sirve para cosas concretas y ayuda a otras personas.
Otra de las grandes fortalezas del proyecto es que está basado en software libre y permite la reutilización del mismo. En el repositorio Github del proyecto MissingMaps podemos encontrar el código y si queremos crear una comunidad basada en el software, la organización Missing Maps nos facilita el proceso y dará visibilidad a nuestro grupo.
En definitiva, Hot OSM es un proyecto de ciencia ciudadana y altruismo de datos que contribuye a aportar beneficios a la sociedad mediante la elaboración de mapas colaborativos muy útiles en situaciones de emergencia. Este tipo de iniciativas están alineadas con el concepto europeo de gobernanza de datos que busca impulsar el altruismo para facilitar voluntariamente el uso de los datos para el bien común.
Contenido elaborado por Santiago Mota, senior data scientist.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La ‘Estrategia europea de datos’ de la Comisión Europea establece que es clave la creación de un mercado único de datos compartidos. En dicha estrategia, la Comisión se ha marcado como uno de sus principales objetivos el impulso de una economía del dato acorde a los valores europeos de autodeterminación en la compartición de datos (soberanía), confidencialidad, transparencia, seguridad y competencia justa.
Los espacios de datos comunes a nivel europeo son un recurso fundamental en la estrategia de datos porque actúan como habilitadores del impulso de la economía del dato. De hecho, poner en común los datos europeos de sectores clave, fomentar la circulación de los datos y crear espacios de datos colectivos e interoperables son acciones que contribuyen al beneficio de la sociedad.
Aunque los entornos de compartición de datos existen desde hace tiempo, se plantea la creación de espacios de datos que garanticen los valores y principios de la UE. Desarrollar iniciativas legislativas que los habiliten no solo es un reto tecnológico, sino también de coordinación entre los participantes, de gobernanza, de adopción de estándares y de interoperabilidad.
Para abordar un desafío de tal magnitud, la Comisión tiene previsto invertir cerca de 8.000 millones de euros hasta 2027 en el despliegue de la transformación digital europea. Como parte del proyecto se incluye el fomento de infraestructuras, herramientas, arquitecturas y mecanismos para compartir datos. Para que triunfe esta estrategia es necesario que, desde el cumplimiento de los valores europeos, se plantee un paradigma de espacio de datos que tenga calado en la industria. Este paradigma de espacio de datos actuará como un estándar tecnológico de facto y permitirá que avance la concienciación social sobre las posibilidades del dato, algo que posibilitará el retorno económico de las inversiones requeridas para crearlo.
Con el fin de hacer realidad el paradigma de espacios de datos, desde la convergencia de las actuales iniciativas, la Comisión Europea ha apostado por el desarrollo del proyecto Simpl.
¿En qué consiste exactamente Simpl?
Simpl es un proyecto financiado por el programa Digital Europe de la Comisión Europea, dotado con 150 millones de euros y con un plazo de ejecución de tres años. Su objetivo es poner a disposición de la sociedad un software (middleware) para la construcción de ecosistemas de datos y servicios de infraestructuras en la nube que soporten los valores europeos de soberanía el dato, privacidad y mercado justo.
El proyecto Simpl consiste en la entrega de 3 productos:
- Simpl-Open: Middleware propiamente dicho. Se trata de una solución de software para crear ecosistemas de servicios de datos (compartición de datos y aplicaciones) y servicios de infraestructura en la nube (IaaS, PaaS, SaaS, etc). Este software debe incluir agentes que habiliten la conexión al espacio de datos, servicios operacionales y servicios de intermediación (catálogo, vocabulario, registro de actividad, etc). El resultado deberá entregarse bajo licencia de fuentes abiertas y se intentará construir una comunidad open source que garantice su evolución.
- Simpl-Labs: Infraestructura para crear entornos de trabajo de pruebas (test bed) para que los usuarios interesados pueden probar la última versión del software en la modalidad de autoservicio. Este entorno está pensado principalmente para promotores de espacios de datos que quieran hacer las oportunas pruebas técnicas antes de un despliegue.
- Simpl-Live: Despliegues de Simpl-open en entornos de producción que se corresponderán a espacios sectoriales contemplados en el programa Digital Europe. En concreto, se plantea el despliegue de espacios de datos gestionados por la propia Comisión Europea (Salud, Procurement, Lenguaje).
El proyecto tiene una orientación práctica y busca obtener resultados a la mayor brevedad. Por lo que se pretende que, además de suministrar el software, el contratista preste un servicio de laboratorio para que los usuarios puedan realizar pruebas. La empresa que desarrolle Simpl también deberá adaptar el software para el despliegue de espacios de datos comunes europeos previstos en el programa Digital Europe.
La asociación Gaia-X está considerada como la más próxima en sus objetivos al proyecto Simpl, así que el resultado del proyecto deberá esforzarse en la reutilización de los componentes que Gaia-X ponga a su disposición.
Por su parte, el centro Data Space Support Center, en el que participan las principales iniciativas europeas de creación de marcos tecnológicos y estándares para la construcción de espacios de datos, deberá definir los requisitos del middleware mediante especificaciones, modelos arquitectónicos y selección de estándares.
Los trabajos preparatorios de Simpl finalizaron en mayo de 2022, fijando el alcance y los requerimientos técnicos del proyecto que han sido objeto de detalle en el proceso contractual actualmente abierto. La licitación se puso en marcha el pasado 24 de febrero de 2023. Toda la información está disponible en TED eTendering, incluida la manera de formular preguntas sobre el proceso de licitación. El plazo para la presentación de solicitudes finaliza el 24 de abril de 2023 a las 17: 00 (hora de Bruselas).
Simpl espera disponer de una plataforma viable mínima publicada a principios de 2024. Paralelamente, y lo antes posible, el entorno abierto de pruebas (Simpl-Labs) se pondrá a disposición de las partes interesadas en experimentar. A continuación, se procederá a integrar progresivamente diferentes casos de uso, ayudándolos a ajustar Simpl a las necesidades específicas, considerando prioritarios los casos financiados de otro modo en el marco del programa de trabajo Europa DIGITAL.
Como conclusión, cabe remarcar que Simpl es la apuesta de la Comisión Europea para el despliegue e interoperabilidad de las diferentes iniciativas de espacios de datos sectoriales, garantizándose su concordancia con las especificaciones y requisitos emanados del Data Space Support Center y, por tanto, con el proceso de convergencia de las diferentes iniciativas europeas de construcción de espacios de datos (Gaia-X, IDSA, Fiware, BDVA).
Noticia
El próximo 2 de marzo, tendrá lugar la presentación del proyecto ‘Datos abiertos y mujeres’, impulsado por el Observatorio Valenciano de Datos Abiertos y Transparencia, fruto de la colaboración entre la Conselleria de Participació, Transparencia, Cooperación y Calidad Democrática de la Generalitat y la Universidad Politécnica de València.
El evento que ha sido organizado por la profesora de la Universidad de Sevilla, Lorena R. Romero-Domínguez y la técnica audiovisual de la Universidad Politécnica de Valencia, Lucía García Robledo, con el apoyo de Antonia Ferrer Sapena, directora del Observatorio, y Eloína Coll Aliaga, directora de la Càtedra de Governança de la Ciutat de València, se llevará a cabo en el Salón de actos de Rectorado en la Universitat Politècnica de València.
Desde un inicio, el objetivo de este proyecto ha sido poner el foco en el rol que distintas mujeres del sector profesional desempeñan en el contexto de los datos y, en especial, de los datos abiertos. Así, mediante una serie de entrevistas, las profesionales seleccionadas comparten el transcurso de su trayectoria, explican cómo han crecido profesionalmente en el mundo de los datos y, también, cómo han abordado algunos de los proyectos más significativos de sus carreras a este respecto.
Las entrevistas, que fueron grabadas meses atrás, están disponibles para su visionado desde el canal de Youtube del Observatorio, donde podemos ver cómo cada una de las profesionales interpeladas reflexiona sobre los retos más importantes que afronta el sector, prestando especial atención a la inclusión de la perspectiva de género en los datos.
Presentación del proyecto y mesa redonda con algunas de las protagonistas
En la sesión de presentación del próximo 2 de marzo, se contará con Andrés Gomis, Director General de Transparencia, Atención a la Ciudadanía y Buen Gobierno de la Conselleria de Participación, Transparencia, Cooperación y Calidad Democrática de la Generalitat Valenciana y Elisa Valía, Tenienta Alcalde Participación, Derechos e Innovación de la Democracia. Concejala de Transparéncia y Gobierno Abierto del Ajuntament de València.
Además, también tendrá lugar una mesa de redonda sobre los datos con perspectiva de género que estará moderada por Carmen Montalbá, profesora de la Universitat de València, y en la que participarán las siguientes profesionales cuyas entrevistas forman parte del proyecto:
- Lorena R. Romero, profesora de la Universidad de Sevilla y autora del proyecto.
- Ana Tudela, Cofundadora de Datadista y miembro de la Oxford Climate Journalism Network.
- Silvia Rueda, Directora Territorial en la Conselleria de Innovación, Universidades, Ciencia y Sociedad Digital.
Junto a las ponentes anteriores que estarán presentes en la mesa redonda, el proyecto ‘Datos abiertos y mujeres’ recoge también las entrevistas de Lourdes Muñoz Santamaría, Fundadora y Directora de la Iniciativa Barcelona Open Data; Laura Castro, Diseñadora de visualización de datos en Affective Advisory; Zynnia del Villar, Directora de Investigación de Ciencias de Datos en Data-Pop Alliance; Thais Ruiz de Alda, Fundadora y CEO de Digital Fems. Tech Advisor&Consultant Digital Business; Sonia Castro-García Muñoz, Coordinadora de datos.gob.es (Red.es); Ana Tudela, Cofundadora de Datadista y Eva Méndez Rodríguez, Profesora Titular y Vicerrectora Adjunta de Política Científica de la Universidad Carlos III.
En definitiva, ‘Datos abiertos y mujeres’ es un proyecto que surge de la necesidad de incentivar un debate sobre la incorporación de la perspectiva de género a los datos, una práctica prioritaria para establecer políticas públicas que sean eficientes para combatir las desigualdades que se plantean entre hombres y mujeres.
Precisamente por esta razón, en las entrevistas, se ofrece una gran diversidad de visiones sobre el papel de los datos en los distintos campos profesionales, entre los que destacan, el periodismo de datos, el ámbito científico-tecnológico, el administrativo o las organizaciones internacionales, entre otros.
Por último, las personas interesadas en asistir presencialmente a la presentación del proyecto deberán inscribirse previamente en este formulario y, una vez confirmada su asistencia, acudir al Salón de actos de Rectorado UPV, en el edificio 3ª.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones utilizando el lenguaje visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio del laboratorio de datos de Github perteneciente a datos.gob.es.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es mostrar cómo realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos utilizado un dataset proporcionado por el Ministerio de Justicia que contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico, que cruzaremos con los datos que publica la Jefatura Central de Tráfico que contienen el detalle sobre el parque de vehículos matriculados en España.
A partir de este cruce de datos analizaremos y podremos observar las ratios de resultados toxicológicos positivos en relación con el parque de vehículos matriculados.
Cabe destacar que el Ministerio de Justicia pone a disposición de los ciudadanos diversos cuadros de mando donde visualizar los datos sobre los resultados toxicológicos realizados en accidentes de tráfico. La diferencia radica en que este ejercicio práctico hace hincapié en la parte didáctica, mostraremos cómo procesar los datos y cómo diseñar y construir las visualizaciones.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se ha utilizado un conjunto de datos proporcionado por el Ministerio de Justicia, el cual contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico. Este conjunto de datos se encuentra en el siguiente repositorio de Github:
También se han utilizado los conjuntos de datos del parque de vehículos matriculados en España. Estos conjuntos de datos son publicados por parte de la Jefatura Central de Tráfico, organismo dependiente del Ministerio del Interior. Se encuentran disponibles en la siguiente página del catálogo de datos de datos.gob.es:
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Tratamiento o preparación de los datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab. Link al notebook de Google Colab
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es la generación de las tablas de datos preprocesados que usaremos para generar las visualizaciones. Para ello ajustaremos las variables, realizaremos el cruce de datos entre ambos conjuntos y filtraremos o agruparemos según sea conveniente.
Los pasos que se siguen en este preprocesamiento de los datos son los siguientes:
- Importación de librerías
- Carga de archivos de datos a utilizar
- Detención y tratamiento de datos ausentes (NAs)
- Modificación y ajuste de las variables
- Generación de tablas con datos preprocesados para las visualizaciones
- Almacenamiento de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Generación de las visualizaciones
Una vez hemos realizado el preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente, para ello hemos realizado los pasos anteriores para la preparación de los datos.
El punto de partida es el planteamiento de una serie de preguntas que la visualización nos ayudará a resolver. Proponemos las siguientes:
-
¿Cómo está distribuido el parque de vehículos en España por comunidades autónomas?
-
¿Qué tipo de vehículo está implicado en mayor y en menor medida en accidentes de tráfico con resultados toxicológicos positivos?
-
¿Dónde se producen más hallazgos toxicológicos en víctimas mortales de accidentes de tráfico?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Parque de vehículos matriculados por CCAA y por típo de vehículo
Esta representación visual se ha realizado teniendo en cuenta el número de vehículos matriculados en las distintas comunidades autónomas, desglosando el total por tipo de vehículo. Los datos, correspondientes a la media de los registros mes a mes de los años 2020 y 2021, están almacenados en la tabla “parque_vehiculos.csv” generada en el preprocesamiento de los datos de partida.
Mediante un mapa coroplético podemos visualizar qué CCAAs son las que poseen un mayor parque de vehículos. El mapa se complementa con un gráfico de anillo que aporta información de los porcentajes sobre el total por cada CCAA.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los mapas coropléticos o de coropletas muestran los valores de una variable sobre un mapa pintando las áreas de cada región afectada de un color determinado. Son utilizados cuando se quieren encontrar patrones geográficos en los datos que están categorizados por zonas o regiones.
Los gráficos de anillo, englobados en los gráficos de sectores, utilizan una representación circular que muestra cómo se distribuyen proporcionalmente los datos.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de vehículo.
Ver la visualización en pantalla completa
5.2. Ratio resultados toxicológicos positivos para los distintos tipos de vehículos
Esta representación visual se ha realizado teniendo en cuanta las ratios de los resultados toxicológicos positivos por número de vehículos a nivel nacional. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_vehiculos.csv”
Mediante un gráfico de barras apiladas, podemos evaluar los ratios de los resultados toxicológicos positivos por número de vehículos para las distintas sustancias y los distintos tipos de vehículos.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los gráficos de barras se utilizan cuando se quiere comparar el valor total de la suma de los segmentos que forman cada una de las barras. Al mismo tiempo, ofrecen información sobre cómo son de grandes estos segmentos.
Cuando las barras apiladas suman un 100%, es decir, que cada barra segmenteada ocupa la altura de la representación, el gráfico se puede considerar un gráfico que permite representar partes de un total.
La tabla aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
5.3. Ratio resultados toxicológicos positivos para las CCAAs
Esta representación visual se ha realizado teniendo en cuenta las ratios de los resultados toxicológicos positivos por el parque de vehículos de cada CCAA. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_ccaa.csv”.
Hay que remarcar que no tiene por qué coincidir la CCAA de matriculación del vehículo con la CCAA donde se ha registrado el accidente, no obstante, ya que este es un ejercicio didáctico y se presupone que en la mayoría de los casos coinciden, se ha decido partir de la base de que ambos coinciden.
Mediante un mapa coroplético podemos visualizar que CCAAs son las que poseen las mayores ratios. A la información aportada en la primera visualización sobre este tipo de gráficos, hay que añadir lo siguiente.
Según se define en la “Guía de visualización de datos para Entidades Locales” uno de los requisitos de los mapas coropléticos o de coropletas es utilizar una medida o dato numérico, un dato categórico para el territorio y un dato geográfico de polígono.
La tabla y el gráfico de barras aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña despegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
6. Conclusiones del estudio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
El parque de vehículos de las Comunidades Autónomas de Andalucía, Cataluña y Madrid corresponde a cerca del 50% del total del país.
-
Las ratios de resultados toxicológicos positivos más altas se presentan en las motocicletas, siendo del orden de tres veces superior a la siguiente ratio, los turismos, para la mayoría de las sustancias.
-
Las ratios de resultados toxicológicos positivos más bajas se presentan en los camiones.
-
Los vehículos de dos ruedas (motocicletas y ciclomotores) presentan ratios en \"cannabis\" superiores a los obtenidos en \"cocaina\", mientras que los vehículos de cuatro ruedas (turismos, furgonetas y camiones) presentan ratios en \"cocaina\" superiores a los obtenidos en \"cannabis\".
-
La comunidad autónoma donde mayor es la ratio para el total de sustancias es La Rioja.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por tipo de vehículo y tipo de sustancia. Te animamos a lo que lo hagas para sacar conclusiones más específicas sobre la información concreta en la que estés más interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Noticia
La igualdad efectiva entre hombres y mujeres es una meta común a alcanzar como sociedad. Así lo recoge la Organización de las Naciones Unidas (ONU), que contempla "Lograr la igualdad de género y empoderar a todas las mujeres y niñas" como uno de los Objetivos de Desarrollo Sostenible a alcanzar en 2030.
Para ello, es fundamental disponer de datos de calidad que nos muestren la realidad y las situaciones de riesgo y vulnerabilidad a las que se enfrentan las mujeres. Solo así se podrán diseñar políticas efectivas más equitativas e informadas, en materias como la violencia contra la mujer o la lucha por romper los techos de cristal. Esto ha llevado a que cada vez más organismos abran datos relacionados con la desigualdad de género. Sin embargo, de acuerdo con la propia ONU, menos de la mitad de los datos necesarios para supervisar dicho objetivo están actualmente disponibles.
¿Qué datos son necesarios?
Para conocer la situación real de las mujeres y las niñas en el mundo es necesario incluir sistemáticamente un análisis de género en todas las etapas de la producción de estadísticas. Esto implica desde utilizar conceptos sensibles al género hasta ampliar las fuentes de información para poder evidenciar fenómenos que en la actualidad no se están midiendo.
Cuando se habla de datos de género no solo se hace referencia a los datos desglosados por sexo. También es necesario que los datos se basen en conceptos y definiciones que reflejen adecuadamente la diversidad de mujeres y hombres, captando todos los aspectos de sus vidas y especialmente aquellas áreas que más susceptibles de presentar desigualdades. Además, los métodos de recogida de datos deben tener en cuenta los estereotipos y los factores sociales y culturales que pueden inducir un sesgo de género en los datos.
Recursos para incorporar la perspectiva de género en los datos
Desde datos.gob.es ya hemos abordado esta cuestión en otros contenidos, aportando algunas primeras pistas sobre la creación de conjuntos de datos con perspectiva de género, pero cada vez son más los organismos que se implican en esta materia, elaborando materiales que pueden ayudar a paliar esta cuestión.
La División de Estadística de la ONU elaboró el informe “Integrating a Gender Perspective into Statistics” con el fin de proporcionar la información metodológica y analítica necesaria para mejorar la disponibilidad, la calidad y el uso de las estadísticas de género. El informe se centra en 10 temas: educación; trabajo; pobreza; medio ambiente; seguridad alimentaria; poder y toma de decisiones; población, hogares y familias; salud; migración, desplazados y refugiados; y violencia contra la mujer. Para cada tema se detallan las cuestiones de género a abordar, los datos necesarios para ello, fuentes de datos a considerar y cuestiones conceptuales y de medición específicas. El informe también aborda de manera transversal cómo generar encuestas, realizar el análisis de los datos o generar visualizaciones adecuadas.
Las Agencias de la ONU también trabajan en esta materia desde sus diversas áreas de acción. Por ejemplo, desde Unicef también han desarrollado guías de interés como “Gender statistics and administrative data systems”, que recopila recursos como marcos conceptuales y estratégicos, herramientas prácticas y casos de uso, entre otros.
Otro ejemplo es el Banco Mundial. Este organismo cuenta con un portal de datos con perspectiva de género, donde ofrece indicadores y estadísticas sobre diversos aspectos como salud, educación, violencia o empleo. Los datos pueden descargarse en CSV o Excel, aunque también se muestran a través de narraciones y visualizaciones, que facilitan su comprensión. Además, se puede acceder a ellos a través de una API. Este portal también incluye una sección donde se recopilan herramientas y directrices para mejorar la recogida de datos, el uso y la difusión de las estadísticas de género. Estos materiales están enfocados en sectores concretos, como el agroalimentario o el trabajo doméstico. También tiene una sección de cursos, donde podemos encontrar, entre otros, formaciones para comunicar y utilizar las estadísticas de género.
Iniciativas en España
Si nos centramos en nuestro país, también encontramos iniciativas muy interesantes. Ya hemos hablado en otras ocasiones de GenderDataLab.org, un repositorio de datos abiertos con perspectiva de género. En su web también incluyen guías sobre cómo generar y compartir estos conjuntos de datos. Si quieres saber más sobre este proyecto, te invitamos a ver esta entrevista con Thais Ruiz de Alda, fundadora y CEO de Digital Fems, una de las entidades detrás de esta iniciativa.
Además, cada vez más organismos están poniendo en práctica mecanismos para publicar conjuntos de datos con perspectiva de género. El Gobierno de Canarias ha creado la herramienta web "Canarias con perspectiva" con el fin de aunar distintas fuentes estadísticas y ofrecer un cuadro de mando con datos desagregados por sexo, que se actualizan de forma continua. Otro proyecto a destacar es la web "Mujeres y Hombres en Canarias", fruto de una operación estadística diseñada por el Instituto Canario de Estadística (ISTAC) en colaboración con el Instituto Canario de Igualdad. En ella se recopila información proveniente de distintas operaciones estadísticas y se analiza desde una perspectiva de género.
Desde la Generalitat de Catalunya también han incluido esta cuestión en su Plan de Gobierno. En el informe "Prioritisation of open data relating to gender inequality for the Government of Catalonia" recopilan bibliografía y experiencias locales e internacionales que pueden servir de inspiración tanto para la publicación como para el uso de este tipo de conjuntos de datos. El informe también propone una serie de indicadores a tener en cuenta y detalla algunos datasets cuya apertura es necesaria.
Estos son solo algunos ejemplos que muestran el compromiso de asociaciones civiles y organismos públicos por esta materia. Un campo en el que hay que seguir trabajando para contar con los datos necesarios para poder evaluar la situación real de la mujer en el mundo y diseñar así soluciones políticas que permitan un mundo más justo para todos.
Blog
El pasado 24 de febrero Europa se adentraba en un escenario que ni siquiera los datos hubiesen podido predecir: Rusia invadía Ucrania, desatando la primera guerra en suelo europeo de lo que llevamos de siglo XXI.
Casi cinco meses después, a fecha del 26 de septiembre, Naciones Unidas hacía públicas sus cifras oficiales: 4.889 fallecidos y 6.263 heridos. Según los datos oficiales de la ONU, mes tras mes, la realidad de los damnificados ucranianos que arrojaban los datos quedaba de la siguiente forma:
| Fecha | Fallecidos | Heridos |
|---|---|---|
| 24-28 febrero | 336 | 461 |
| Marzo | 3028 | 2384 |
| Abril | 660 | 1253 |
| Mayo | 453 | 1012 |
| Junio | 361 | 1029 |
| 1-3 julio | 51 | 124 |
Los datos extraídos por la misión que el Alto Comisionado de las Naciones Unidas para los Derechos Humanos realiza en Ucrania desde que en 2014 Rusia invadiese Crimea cifran en más de 7 millones de personas, el total de civiles desplazados como consecuencia del conflicto.
Sin embargo, al igual que sucede en otros ámbitos, los datos sirven no solo para elaborar soluciones, sino también para conocer en profundidad aspectos de la realidad que de otra forma no sería posible. En el caso de la guerra de Ucrania es precisamente la captación, monitorización y análisis de datos sobre el territorio lo que permite que organismos como Naciones Unidas puedan sacar sus propias conclusiones.
Con el objetivo de visibilizar cómo los datos pueden utilizarse para conseguir la paz, a continuación analizaremos cuál es el papel que estos desempeñan en relación con las siguientes labores:
Predicción
En este ámbito, los datos se utilizan para tratar de adelantarse a situaciones y planificar una respuesta adecuada al riesgo previsto. Así, si antes del estallido de la guerra se utilizaban los datos para evaluar el riesgo de un futuro conflicto, ahora se emplean para establecer un control y prever la escalada del mismo.
Por ejemplo, las imágenes satélite que arrojan aplicaciones tipo Google Maps han permitido monitorizar el avance de las tropas rusas. Igualmente, visualizadores como Subnational Surge Tracker identifican los picos de violencia registrados en distintos niveles administrativos: estados, provincias o municipios.
Información
Tan importante es conocer los datos para prevenir la violencia, como utilizar los mismos para limitar la desinformación y comunicar los hechos de forma objetiva, veraz y acorde a las cifras oficiales. Para conseguirlo, han comenzado a utilizarse aplicaciones de fact cheking, capaces de responder con datos oficiales a las noticias falsas.
Entre ellas destaca Newsguard, una entidad de verificación que ha elaborado un rastreador que reúne todos los sitios web que comparten desinformación sobre el conflicto, poniendo especial énfasis en las narrativas falsas más populares que circulan por la red. Incluso, cataloga este tipo de contenido en función del idioma en el que se promueve.
Daños materiales
Los datos también se pueden utilizar para localizar los daños materiales y rastrear la aparición de otros nuevos. A lo largo de estos meses, la ofensiva rusa ha dañado la red de infraestructura pública ucraniana, dejando inutilizadas carreteras, puentes, suministros de agua y electricidad e, incluso, hospitales.
Conocer a través de los datos esta realidad es muy útil de cara a organizar una respuesta dirigida a la reconstrucción de estas zonas y al envío de asistencia humanitaria para los civiles que se han quedado desprovistos de servicios.
En este sentido, destacamos los siguientes casos de uso:
- El algoritmo de aprendizaje automático del Programa de las Naciones Unidas para el Desarrollo (PNUD) ha sido desarrollado y mejorado para identificar y clasificar la infraestructura dañada por la guerra.
- De forma paralela, la organización HALO Trust utiliza minería de medios sociales capaz de captar información de las redes sociales, imágenes vía satélite e, incluso, datos geográficos que ayudan a identificar áreas con "restos explosivos". Gracias a este hallazgo las organizaciones desplegadas por el terreno ucraniano, pueden moverse con mayor seguridad para organizar una respuesta humanitaria coordinada.
- La información lumínica captada por los satélites de la NASA sirve también para construir una base de datos que ayude a identificar cuáles son las áreas de conflicto activo en Ucrania. Así, al igual que en los ejemplos anteriores, estos datos sirven para realizar un seguimiento y poder enviar ayuda a los puntos donde esta sea más necesaria.
Violación y abuso de derechos humanos
Lamentablemente, en este tipo de conflictos, la violación de los derechos humanos de la población civil está a la orden del día. De hecho, según la experiencia sobre el terreno y la información recopilada por el Alto Comisionado de las Naciones Unidas para los Derechos Humanos, se han documentado violaciones de este tipo durante todo el periodo de guerra en Ucrania.
Así y con el objetivo de comprender qué está sucediendo con los civiles ucranianos, los funcionarios de vigilancia y derechos humanos recopilan datos, información pública y relatos en primera persona de la guerra en Ucrania. Con todo ello, desarrollan un mapa-mosaico que facilita la toma de decisiones y la búsqueda de soluciones justas para la población.
Otro trabajo muy interesante y desarrollado con datos abiertos es el realizado por Conflict Observatory. Gracias a la colaboración de analistas y desarrolladores, y al empleo de información geoespacial e inteligencia artificial, han podido descubrirse y mapearse crímenes de guerra que de otro modo podrían quedar más invisibilizados.
Movimientos migratorios
Desde el estallido de la guerra el pasado mes de febrero, han escapado de la guerra y, por ende, de su propio país, más de 7 millones de ucranianos. Al igual que en los casos anteriores, los datos sobre los flujos migratorios se pueden utilizar para reforzar los esfuerzos humanitarios que demandan los refugiados y los desplazados internos.
Algunas de las iniciativas en las que los datos abiertos contribuyen son las siguientes:
La Matriz de Seguimiento de Desplazamiento es un proyecto desarrollado por la Organización Internacional para las Migraciones y cuya finalidad ha sido obtener datos sobre los flujos migratorios dentro de Ucrania. Gracias a la información facilitada por aproximadamente 2.000 encuestados a través de entrevistas telefónicas, se creó una base de datos que se ha ido utilizando para garantizar una distribución de las acciones humanitarias eficaz en función de las necesidades de cada zona del país.
Respuesta humanitaria
De forma similar al análisis realizado para controlar los movimientos migratorios, los datos recopilados sobre el conflicto también sirven para diseñar acciones de respuesta humanitaria y realizar un seguimiento de la ayuda proporcionada.
En esta línea, uno de los agentes más activos durante los últimos meses ha sido el Fondo de Población de las Naciones Unidas que creó un conjunto de datos que recoge proyecciones actualizadas por género, edad y región ucraniana. Es decir, gracias a este mapeo actualizado de la población ucraniana es mucho más sencillo pensar en cuáles son las necesidades que tiene cada zona en términos de suministros médicos, alimentos o, incluso, apoyo de salud mental.
Otras de las iniciativas que también está prestando apoyo en este ámbito es el Explorador de Datos de Ucrania, un proyecto desarrollado sobre código abierto en la plataforma Intercambio de Datos Humanitarios (HDX) que proporciona información obtenida de forma colaborativa sobre refugiados, víctimas y necesidades de financiación para los esfuerzos humanitarios.
Por último, los datos recopilados y, posteriormente analizados por Premise, visibilizan aquellas zonas que presentan déficit de alimentos y combustible. Monitorizar esta información es realmente útil de cara a localizar las zonas del país con menos recursos para las personas que han migrado internamente y, a su vez, para señalar a las organizaciones humanitarias cuáles son las áreas donde se está demandando más asistencia.
La innovación y el desarrollo de herramientas capaces de recopilar datos y extraer conclusiones sobre los mismos es, sin duda, un gran paso que ayuda a reducir el impacto de los conflictos armados. Gracias a este tipo de previsiones y análisis de datos es posible responder de forma rápida y coordinada a las necesidades de la sociedad civil que se encuentra en las zonas más afectadas, sin dejar de lado tampoco a los refugiados que se desplazan a miles de kilómetros de sus casas.
Estamos ante una crisis humanitaria que ha generado más de 12,6 millones de movimientos transfronterizos. En concreto, nuestro país ha atendido a más de 145.600 personas desde el inicio de la invasión y se han concedido más de 142.190 solicitudes de protección temporal, el 35% de ellas a menores. Tales cifras convierten a España en el quinto Estado Miembro con mayor número de resoluciones favorables de protección temporal. Asimismo, más de 63.500 personas desplazadas han sido dadas de alta en el Sistema Nacional de Salud y con el inicio del curso académico, hay 30. 919 estudiantes ucranianos desplazados escolarizados, de los que 28.060 son menores.
Contenido elaborado por el equipo de datos.gob.es.
Empresa reutilizadora
Estudio Alfa es una empresa tecnológica dedicada a ofrecer servicios que favorezcan la imagen de empresas y marcas en Internet, incluyendo el desarrollo de apps. Para llevar a cabo estos servicios utilizan técnicas y estrategias que cumplen con estándares de usabilidad y favorecen el posicionamiento en buscadores web, facilitando así que las páginas de sus clientes reciban más visitantes y con ello potenciales clientes. Cuentan además con especial experiencia en sectores productivos y de turismo.