Aplicación
ContratosMenores.es es una web que brinda información sobre los contratos menores realizados en España desde enero de 2022. A través de esta aplicación se pueden localizar los contratos según su clasificación en el Vocabulario Común de la Contratación Pública (CPV), siguiendo el árbol jerárquico de los Órganos de Contratación públicos, con una búsqueda de texto libre, o a partir de diferentes rankings, por ejemplo, de contratos más caros, adjudicatarias más frecuentes y otros.
En la ficha de cada organismo y de cada adjudicataria se detallan sus relaciones destacadas con otras entidades, las categorías más frecuentes de sus contratos, empresas similares, duración de los contratos, importe, y muchos datos más.
En el caso de las empresas adjudicatarias se dibuja un mapa con la ubicación de los contratos que han recibido.
La web es totalmente gratuita, no requiere registro, y se actualiza diariamente, comenzando con más de un millón de contratos menores registrados.
Blog
La Federación Española de Municipios y Provincias (FEMP) aprobó a finales de 2023 dos ordenanzas tipo que abordan el progreso en dos áreas clave: la transparencia y el gobierno del dato. Ambos documentos no solo mejorarán la calidad de los procesos, sino que facilitarán el acceso, gestión y la reutilización de los datos. En este post, analizaremos la segunda ordenanza elaborada en el seno de la Red de Entidades por la Transparencia y Participación Ciudadana de la FEMP en su búsqueda de definir modelos de referencia comunes. En concreto, la ordenanza relativa al gobierno del dato.
La utilidad y buen hacer de la Ordenanza Tipo del Gobierno del Dato en la Entidad Local ha sido resaltada por la Asociación Multisectorial de la Información (ASEDIE), quien le otorgó el premio en la categoría ‘Impulsando el conocimiento del dato’ en su 15º Conferencia Internacional ASEDIE.
Bajo esta premisa, el documento aborda todos los elementos relacionados con la obtención, gestión y explotación de los datos para plantearlos como un bien común, es decir, garantizando su apertura, accesibilidad y reutilización. Este es un objetivo relevante para las administraciones locales, ya que gracias a ello pueden mejorar su funcionamiento, los servicios que presta y la toma de decisiones. El gobierno del dato es el marco que guía y garantizar este proceso y esta ordenanza plantea un marco normativo flexible que las diferentes administraciones puedan adaptar según sus necesidades concretas.
¿Qué es el gobierno del dato?
El Gobierno del Dato aborda de forma integral todos los aspectos relacionados con la obtención, gestión y explotación de los datos, así como su apertura y reutilización por toda la sociedad de forma igualitaria. Por tanto, podemos definirlo como una función organizativa responsable de rendir cuentas sobre el uso eficaz, eficiente y aceptable de los datos por parte de la organización, necesaria para acometer la estrategia de negocio. Así lo describen las especificaciones UNE 0077:2023 de Gobierno del Dato y UNE 78:2023 de Gestión del Dato, que recogen procesos estandarizados para guiar a las organizaciones en el establecimiento de mecanismos aprobados y validados que den soporte organizacional a los aspectos relacionados con la apertura y publicación de datos, para su posterior uso por la ciudadanía y otras instituciones.
¿Cómo se desarrolló la Ordenanza de Gobierno del Dato de la FEMP?
Para desarrollar la Ordenanza Tipo de Gobierno del Dato en la Entidad Local, se constituyó en 2022 un grupo de trabajo multidisciplinar que contaba con trabajadores de las AAPP, empresas privadas, representantes del sector infomediario, la Oficina del Dato, universidades, etc. Este equipo planteó dos objetivos principales que marcarían el contenido del documento:
- Elaborar guías para ayuntamientos y otras AAPP donde se defina la estrategia a seguir para poner en marcha un proyecto de datos abiertos.
- Crear un modelo de referencia de conjuntos de datos común a todas las AAPP para facilitar la reutilización de la información.
Teniendo en cuenta estos dos retos, a principios de 2023 el grupo de trabajo de la FEMP empezó a establecer aspectos, estructura, contenidos y plan de trabajo. Durante los meses posteriores, se llevaron a cabo trabajos de redacción, elaboración y consenso de un borrador único.
Además, se organizó un proceso participativo en la plataforma Idea Zaragoza para nutrir el documento con las aportaciones de expertos de todo el país y socios de las FEMP.
El resultado de todo el trabajo se sustentó en la Carta Internacional de Datos Abiertos (Open Data Charter-ODC), las recomendaciones emanadas de la Oficina del Dato del Gobierno de España y la normativa europea y nacional existente sobre esta materia.
Aspectos novedosos y estructura de la Ordenanza de Gobierno del Dato
La Ordenanza Tipo de Gobierno del Dato de la FEMP es acorde al contexto en el que se ha presentado; es decir, reconoce aspectos relevantes del momento actual que estamos viviendo. Alguna de las características a destacar del documento es la premisa de garantizar y potenciar los derechos de las personas tanto físicas como jurídicas y respetar el Reglamento General de Protección de Datos. El reglamento hace especial hincapié en la proporcionalidad de la anonimización para garantizar la privacidad de las personas.
Otro aspecto novedoso de la norma es que aporta la visión de los datos de alto valor definidos por la Comisión Europea desde la perspectiva de la administración local. Además, la Ordenanza Tipo reconoce un régimen único para el acceso y reutilización de la información pública, acorde a la Ley 19/2013, de 9 de diciembre, de transparencia, acceso a la información pública y buen gobierno, y la Ley 37/2007, sobre reutilización de la información del sector público.
Más allá de garantizar el marco jurídico y normativo, la Ordenanza de la FEMP también aborda los datos asociados a la inteligencia artificial, sinergia tecnológica puntera que cada día ofrece grandes soluciones innovadoras. Para que una inteligencia artificial funcione correctamente, es necesario contar con datos de calidad que ayuden a su entrenamiento. En relación con este punto, la ordenanza define unos requisitos de calidad (Artículo 18) y métricas para su evaluación que se adaptan a cada contexto específico y que abordan cuestiones como la exactitud, portabilidad o confidencialidad, entre otras. El documento establece garantías para que el uso de los datos se lleve a cabo respetando los derechos de las personas.
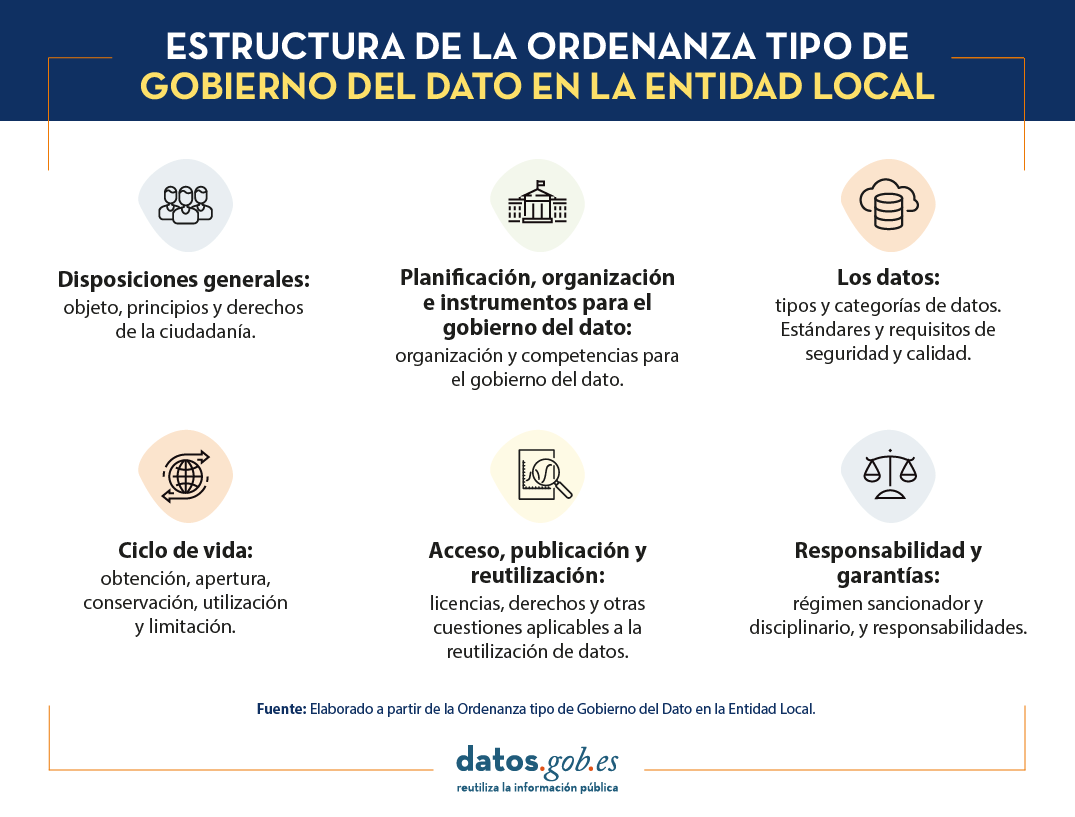
Todos estos aspectos novedosos forman parte de la Ordenanza Tipo de Gobierno del Dato para Entidades Locales de la FEMP que se organiza en la siguiente estructura:
- Disposiciones generales: Este primer apartado presenta el dato como principal activo digital de las Administraciones Públicas como activo estratégico, y del objeto, principios y derecho de la ciudadanía.
- Planificación, organización e instrumentos para el gobierno del dato: En este punto se define la organización y competencias para el gobierno del dato. Además, se destaca la importancia de mantener un inventario de conjuntos de datos y fuentes de información (Artículo 9).
- Los datos: Este capítulo reconoce los requisitos de publicación y los estándares de seguridad, la importancia del uso de vocabularios de referencia, y las categorías de conjuntos de datos cuya apertura debe ser priorizada, en concreto, las 80 tipologías referidas por la FEMP como más relevantes.
- Ciclo de vida: En este apartado se destaca, por un lado, la obtención, apertura, conservación y utilización de los datos; y, por otro, los límites, supresión y destrucción de los datos cuando se precise de la realización de estas actuaciones. cuando se precise de la realización de estas actuaciones.
- Acceso, publicación y reutilización: El quinto capítulo aborda cuestiones relativas a la explotación de los datos como es el uso de licencias específicas, los derechos exclusivos, el pago por reutilización o la solicitud previa para acceder a determinados conjuntos de datos
- Responsabilidad y garantías: El último punto describe el régimen sancionador y el disciplinario, y las responsabilidades civil y penal del reutilizador.
En definitiva, la publicación de la Ordenanza sobre Gobierno del Dato en Entidades Locales dota a las administraciones locales de una regulación flexible y define estructuras administrativas que buscan la mejora de la gestión, la reutilización y el impulso de una sociedad basada en el dato.
Puedes acceder al documento completo aquí: Ordenanza tipo de Gobierno del Dato en la Entidad Local.
Noticia
El Centre de documentació i biblioteca del Institut Català d'Arqueologia Clàssica (ICAC) cuenta con el repositorio Open Science ICAC. Esta página web se configura como un espacio donde la ciencia se comparte de forma accesible e inclusiva. El espacio introduce recomendaciones y asesora sobre el proceso de la publicación de contenidos. También, sobre cómo poner a disposición los datos generados durante el proceso de investigación, de forma que sirvan a futuros trabajos de investigación.
La página web, además de ser un repositorio de textos de investigación científica, también es un lugar en el que encontrar herramientas y trucos a la hora de abordar el proceso de gestión de datos de investigación en cada una de sus fases: antes, durante y en el momento de la publicación.
- Antes de comenzar: recomienda crear un plan de gestión de datos para garantizar que la propuesta de investigación sea lo más sólida posible. El Plan de Gestión de Datos (PGD) es un documento metodológico que describe el ciclo de vida de los datos recogidos, generados y procesados durante un proyecto de investigación, una tesis doctoral, etc.
- Durante el proceso de investigación: en este punto señala la necesidad de unificar la nomenclatura de los documentos a generar antes de empezar a recopilar archivos o datos, para evitar una acumulación de contenido desorganizado que conducirá a datos extraviados o perdidos. Además, en este apartado se ofrece información sobre la estructura de directorios, nombres de carpetas y nombres de archivos, la creación de un archivo txt (README) que describa las nomenclaturas o el uso de nombres cortos y descriptivos como nombre del proyecto/acrónimo, fecha de creación del archivo, número de muestra o número de la versión. En la página web se pueden encontrar también recomendaciones sobre cómo estructurar cada uno de estos campos para que sean reutilizables y fácilmente buscables.
- Publicación de los datos de investigación: además de los propios resultados de la investigación en forma de tesis, tesina, paper... recomienda la publicación de los datos que se hayan ido generando con el propio proceso investigador. El propio ICAC señala que los datos de investigación siguen siendo valiosos una vez finalizado el proyecto de investigación para el que se generaron, y que compartir los datos puede abrir nuevas vías de investigación sin que los futuros investigadores tengan que recrear y recopilar datos idénticos. Por último, señala cómo, cuándo y qué tener en cuenta a la hora de publicar los datos de investigación.
Los contenidos gráficos para la mejora de la calidad de datos abiertos
Recientemente, el ICAC ha dado un paso más para incentivar unas buenas prácticas en el uso de datos abiertos. Para ello ha elaborado una serie de contenidos gráficos basándose en la “Guía práctica para la mejora de la calidad de datos abiertos”, elaborada por datos.gob.es. En concreto, el ente cultural ha elaborado cuatro infografías, en catalán e inglés, de fácil comprensión sobre buenas prácticas con datos abiertos en el trabajo con bases de datos y hojas de cálculo, textos y docs y formato CSV.
Todas las infografías surgidas de la adaptación de la guía están a disposición del público general y también del personal investigador del centro en Recercat, el repositorio de investigación de Cataluña. Próximamente también estará dentro de la web de Ciencia Abierta del Institut Català d'Arqueologia Clàssica (ICAC), Open Science ICAC.
Las infografías elaboradas por el ICAC repasan diversos aspectos. Las primeras, recogen las recomendaciones generales para garantizar la calidad de los datos abiertos, como el uso de codificación de caracteres estandarizados, tales como el UTF-8, o nombrar las columnas de forma correcta, utilizando solo letras en minúscula y evitando los espacios, siendo estos sustituidos por guiones. Entre las recomendaciones para generar datos de calidad, también recogen cómo mostrar la presencia de datos nulos o la carencia de datos o cómo gestionar la duplicidad de datos, de manera que se centralice la recogida de datos y su procesamiento en un único sistema de forma que, en caso de haber duplicidad, se puedan detectar de forma sencilla y puedan ser eliminados.
Las segundas abordan cómo establecer el formato de las cifras numéricas y de otros datos como las fechas, de manera que sigan el sistema estandarizado ISO, así como utilizar los puntos como decimales. En el caso de la información geográfica, tal y como recomienda la Guía, sus materiales también recogen la necesidad de reservar dos columnas para insertar la longitud y la latitud de los puntos geográficos utilizados.
La tercera temática de estas infografías se centra en la elaboración de buenas bases de datos u hojas de cálculo, de forma que sean fácilmente reutilizables y no generen problemas a la hora de trabajar con ellas. Entre las recomendaciones que destacan se encuentra la consistencia a la hora de generar nombres o códigos para cada ítem incluido en la recogida de datos, así como elaborar una guía de ayuda para las celdas que se encuentran codificadas, de manera que sean inteligibles para quienes necesiten reutilizarlas.
En el apartado de textos y documentos dentro de estas bases de datos, las infografías que ha elaborado el Institut Català d'Arqueologia Clàssica recogen algunas de las recomendaciones más importantes para crear textos y asegurarse de su conservación de la mejor forma posible. Entre ellas, señala la necesidad de guardar materiales adjuntos en los documentos de texto como pueden ser imágenes u hojas de cálculo de forma separada al documento de texto. De esta manera, se asegura que el documento conserva su calidad original, como la resolución de una imagen, por ejemplo.
Por último, la cuarta infografía que se ha puesto a disposición recoge las recomendaciones más importantes a la hora de trabajar con formato CSV (comma separated value) como crear un documento CSV para cada tabla y, en caso de trabajar con un documento con varias hojas de cálculo, ponerlas a disposición de forma independiente. También señala en este caso que cada fila en el documento CSV tiene el mismo número de columnas para que sean fácilmente trabajables y reutilizables, sin necesidad de realizar una limpieza posterior.
Como se mencionaba anteriormente, todas las infografías siguen las recomendaciones ya recogidas en la Guía práctica para la mejora de la calidad de datos abiertos.
La guía para la mejora de la calidad de datos abiertos
La “Guía práctica para la mejora de la calidad de datos abiertos” es un documento elaborado por datos.gob.es dentro de la Iniciativa Aporta y publicado en septiembre de 2022. El documento proporciona un compendio de directrices para actuar sobre cada una de las características que definen la calidad, impulsando su mejora. A su vez, esta guía toma como referente la guía para la calidad de datos de data.europe.eu, publicada en 2021 por la Oficina de Publicaciones de la Unión Europea y la completa para que tanto publicadores como reutilizadores de datos puedan seguir pautas que garanticen la calidad de los datos abiertos.

En resumen, la guía pretende ser un marco de referencia para todas las personas involucradas tanto en la generación como en la utilización de datos abiertos para que tengan un punto de partida que garantice la idoneidad de los datos tanto en su puesta a disposición como a la hora de evaluar si un conjunto de datos posee calidad suficiente para su reutilización en estudios, aplicaciones, servicios u otros.
Blog
La tecnología digital y los algoritmos han revolucionado la forma en que vivimos, trabajamos y nos comunicamos. Si bien prometen eficiencia, precisión y conveniencia, estas tecnologías pueden exacerbar los prejuicios y las desigualdades sociales y crear nuevas formas de exclusión. Así, la invisibilización y la discriminación, que siempre han existido, cobran nuevas formas en la era de los algoritmos.
La falta de interés y de datos lleva a la invisibilización algorítmica, motivando que existan dos tipos de abandono algorítmico. El primero de ellos ocurre entre las personas desatendidas en el mundo, que incluye a los millones que no tienen un teléfono inteligente ni una cuenta bancaria y que, por ende, se encuentran al margen de la economía de plataformas y, para los algoritmos, no existen. El segundo tipo de abandono algorítimico incluye a individuos o grupos que son víctimas del fracaso del sistema algorítmico, como sucedió con SyRI (Systeem Risico Indicatie) en Países Bajos que señaló injustamente a unas 20.000 familias de origen socioeconómico bajo de cometer fraude fiscal, llevando a muchas a la ruina en 2021. El algoritmo, que fue declarado ilegal por un tribunal de La Haya meses más tarde, se aplicó en los barrios más pobres del país y bloqueó la posibilidad de muchas familias con más de una nacionalidad de percibir los beneficios sociales a los que tenían derecho por su condición socioeconómica.
Más allá del ejemplo en el sistema público neerlandés, la invisibilización y la discriminación también pueden originarse en el sector privado. Un ejemplo es el algoritmo de ofertas de trabajo de Amazon que mostró un sesgo contra las mujeres al aprender de datos históricos –es decir, datos incompletos al no incluir un universo amplio y representativo—, lo que llevó a Amazon a abandonar el proyecto. Otro ejemplo Apple Card, una tarjeta de crédito respaldada por Goldman Sachs, que también fue señalada cuando se descubrió que su algoritmo ofrecía límites de crédito más favorables a los hombres que a las mujeres.
En general, la invisibilidad y la discriminación algorítmica, en cualquier ámbito, puede derivar en un acceso desigual a los recursos y en una exacerbación de la exclusión social y económica.
Tomar decisiones basadas en algoritmos
Los datos y los algoritmos son componentes interconectados en el ámbito de la informática y el procesamiento de la información. Los datos sirven de base, pero pueden ser desestructurados, con excesiva variabilidad e incompletos. Los algoritmos son instrucciones o procedimientos diseñados para procesar y estructurar estos datos y extraer información, patrones o resultados significativos.
La calidad y relevancia de los datos impacta directamente en la efectividad de los algoritmos, ya que estos dependen de las entradas de datos para generar resultados. De ahí, el principio “basura entra basura sale”, que resume la idea de que, si entran datos de mala calidad, sesgados o inexactos en un sistema o proceso, el resultado también será de mala calidad o impreciso. Por su lado, los algoritmos bien diseñados pueden mejorar el valor de los datos al revelar relaciones ocultas o hacer predicciones.
Esta relación simbiótica subraya el papel fundamental que desempeñan tanto los datos como los algoritmos a la hora de impulsar los avances tecnológicos, permitir la toma de decisiones informadas y favorecer innovaciones.
La toma de decisiones algorítmica se refiere al proceso de utilizar conjuntos predefinidos de instrucciones o reglas para analizar datos y emitir predicciones que ayuden a decidir. Cada vez más, se aplica a decisiones que tienen que ver con el bienestar social y la oferta de servicios y productos comerciales a través de plataformas. Es ahí donde se puede encontrar la invisibilidad o la discriminación algorítmica.
Cada vez con más frecuencia, los sistemas de bienestar utilizan datos y algoritmos para ayudar en la toma de decisiones sobre asuntos como quién debe recibir asistencia y de qué tipo o quién presenta riesgos. Estos algoritmos consideran diferentes factores como ingresos, tamaño de la familia o de la vivienda, gastos, factores de riesgo, edad, sexo o género, que pueden incluir sesgos y omisiones.
Por eso el Relator Especial sobre la extrema pobreza y los derechos humanos, Philip Alston, advertía en un informe ante la Asamblea General de Naciones Unidas que la adopción sin cautelas de estos puede llevar a un bienestar social distópico. En dicho estado de bienestar distópico, los algoritmos se utilizan para reducir presupuestos, disminuir el número de personas beneficiarias, eliminar servicios, introducir formas exigentes e intrusivas de condicionalidad, modificar comportamientos, imponer sanciones y “revertir la noción de que el Estado debe rendir cuentas”.
Invisibilidad y discriminación algorítmicas: Dos conceptos opuestos
Aunque los datos y los algoritmos tienen mucho en común, la invisibilidad y la discriminación algorítmicas son dos conceptos opuestos. La invisibilidad algorítmica se refiere a lagunas en conjuntos de datos u omisiones en los algoritmos, que resultan en desatenciones en la aplicación de beneficios o servicios. Por el contrario, la discriminación algorítmica habla de puntos críticos que resaltan comunidades específicas o características sesgadas en conjuntos de datos, generando injusticia.
Es decir, la invisibilización algorítmica ocurre cuando individuos o grupos están ausentes en los conjuntos de datos, lo que hace imposible abordar sus necesidades. Por ejemplo, integrar en la toma de decisiones social datos sobre mujeres con discapacidad puede ser vital para la inclusión. A nivel mundial, las mujeres son más vulnerables a la invisibilización algorítmica que los hombres, ya que tienen menos acceso a la tecnología digital y dejan menos trazas digitales.
Los sistemas algorítmicos opacos que incorporan estereotipos pueden aumentar la invisibilización y la discriminación al ocultar, o bien apuntar, a personas o poblaciones vulnerables. Un sistema algorítmico opaco es aquel no permite el acceso a su funcionamiento.
Por otro lado, agregar o desagregar datos sin estudiar las consecuencias cuidadosamente puede resultar en omisiones u errores. Esto ilustra el doble filo de la contabilidad; es decir, la ambivalencia de la tecnología que cuantifica y cuenta, y que puede servir para mejorar la vida de las personas, pero también para perjudicarlas.
La discriminación puede surgir cuando las decisiones algorítmicas se basan en datos históricos, que normalmente incorporan asimetrías, estereotipos e injusticias, porque en el pasado existieron más desigualdades. El efecto de “basura entra basura sale” se produce si los datos están sesgados, como suele pasar con el contenido en línea. Asimismo, las bases de datos con sesgos o incompletas pueden ser incentivos de la discriminación algorítmica. Pueden aparecer sesgos de selección cuando los datos de reconocimiento facial, por ejemplo, se basan en rasgos de hombres blancos, mientras que las usuarias son mujeres de piel oscura, o en contenido en línea generado por una minoría de agentes, lo que dificulta la generalización.
Como se ve, abordar la invisibilidad y la discriminación algorítmica es un reto de primera magnitud que solo se podrá resolver con la concienciación y la colaboración de instituciones, organizaciones de campaña, empresas, e investigación.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Blog
La UNESCO (Organización de las Naciones Unidas para la Educación, la Ciencia y la Cultura) es un organismo de las Naciones Unidas cuyo objeto es el de contribuir a la paz y a la seguridad en el mundo mediante la educación, la ciencia, la cultura y las comunicaciones. Para cumplir con su objetivo esta organización suele establecer guías y recomendaciones como la que ha publicado este 5 de Julio del 2023 titulado ‘Open data for AI: what now?’
Tras la pandemia del COVID-19 la UNESCO destaca una serie de lecciones aprendidas:
- Deben desarrollarse marcos normativos y modelos de gobernanza de datos, respaldados por infraestructuras, recursos humanos y capacidades institucionales suficientes para abordar los retos relacionados con los datos abiertos, con el fin de estar mejor preparados para las pandemias y otros retos mundiales.
- Es necesario especificar más la relación entre los datos abiertos y la IA, incluyendo qué características de los datos abiertos son necesarias para que sean "AI-Ready".
- Debe establecerse una política de gestión, colaboración e intercambio de datos para la investigación, así como para las instituciones gubernamentales que posean o procesen datos relacionados con la salud, al tiempo que se debe garantizar la privacidad de los datos mediante la anonimización.
- Los funcionarios públicos que manejan datos que son o pueden llegar a ser de utilidad para las pandemias pueden necesitar formación para reconocer la importancia de dichos datos, así como el imperativo de compartirlos.
- Deben recopilarse y recogerse tantos datos de alta calidad como sea posible. Los datos tienen que proceder de una variedad de fuentes creíbles, que, sin embargo, también deben ser éticas, es decir, no deben incluir conjuntos de datos con sesgos y contenido perjudicial, y tienen que recopilarse únicamente con consentimiento y no de forma invasiva para la privacidad. Además, las pandemias suelen ser procesos que evolucionan rápidamente, por lo que la actualización continua de los datos es esencial.
- Estas características de los datos son especialmente obligatorias para mejorar en el futuro las inadecuadas herramientas de diagnóstico y predicción de la IA. Es necesario realizar un esfuerzo para convertir los datos pertinentes en un formato legible por máquina, lo que implica la conservación de los datos recopilados, es decir, su limpieza y etiquetado.
- Debe abrirse una amplia gama de datos relacionados con las pandemias, adhiriéndose a los principios FAIR.
- El público objetivo de los datos abiertos relacionados con la pandemia incluye la investigación y el mundo académico, los responsables de la toma de decisiones en los gobiernos, el sector privado para el desarrollo de productos relevantes, pero también el público, todos los cuales deben ser informados sobre los datos disponibles.
- Las iniciativas de datos abiertos relacionadas con pandemias deberían institucionalizarse en lugar de formarse ad hoc, y por tanto deberían ponerse en marcha para la preparación ante futuras pandemias. Estas iniciativas también deberían ser integradoras y reunir a distintos tipos de productores y usuarios de datos.
- Asimismo, debería regularse el uso beneficioso de los datos relacionados con pandemias para las técnicas de aprendizaje automático de IA con el objetivo de evitar el uso indebido para el desarrollo de pandemias artificiales, es decir, armas biológicas, con la ayuda de sistemas de IA.
La UNESCO se basa en estas lecciones aprendidas para establecer unas Recomendaciones sobre la Ciencia Abierta facilitando el intercambio de datos, mejorando la reproducibilidad y la transparencia, promoviendo la interoperabilidad de los datos y las normas, apoyando la preservación de los datos y el acceso a largo plazo.
A medida que reconocemos cada vez más el papel de la Inteligencia Artificial (IA), la disponibilidad y el acceso a los datos son más cruciales que nunca, por ello la UNESCO lleva a cabo investigaciones en el ámbito de la IA para proporcionar conocimientos y soluciones prácticas que fomenten la transformación digital y construyan sociedades del conocimiento inclusivas.
Los datos abiertos son el principal objetivo de estas recomendaciones, ya que se consideran un requisito previo para la elaboración de planes, la toma de decisiones y las intervenciones con conocimiento de causa. Por ello, el informe afirma que los Estados miembros deben compartir los datos y la información, garantizando la transparencia y la rendición de cuentas, así como las oportunidades para que cualquiera pueda hacer uso de los datos.
La UNESCO ofrece una guía en la que pretende dar a conocer el valor de los datos abiertos y especifican los pasos concretos que los Estados miembros pueden dar para abrir sus datos. Son pasos prácticos, pero de alto nivel sobre cómo abrir datos, basándose en las directrices existentes. Se distinguen tres fases: preparación, apertura de los datos y seguimiento para su reutilización y sostenibilidad, y se presentan cuatro pasos para cada fase.
Es importante señalar que varios de los pasos pueden realizarse simultáneamente, es decir, no necesariamente de forma consecutiva.

Paso 1: Preparación
- Elaborar una política de gestión y puesta en común de datos: Una política de gestión y puesta en común de datos es un requisito importante previo a la apertura de los datos, ya que dicha política define el compromiso de los gobiernos de compartir los datos. El Instituto de Datos Abiertos sugiere los siguientes elementos de una política de datos abiertos:
- Una definición de datos abiertos, una declaración general de principios, un esquema de los tipos de datos y referencias a cualquier legislación, política u otra orientación pertinente.
- Se anima a los gobiernos a adherirse al principio "tan abierto como sea posible, tan cerrado como sea necesario". Si los datos no pueden abrirse por motivos legales, de privacidad o de otro tipo, por ejemplo, datos personales o sensibles, debe explicarse claramente.
Además, los gobiernos también deberían animar a los investigadores y al sector privado de sus países a desarrollar políticas de gestión e intercambio de datos que se adhieran a los mismos principios.
- Reunir y recopilar datos de alta calidad: Los datos existentes deben recopilarse y almacenarse en el mismo repositorio, por ejemplo, de varios departamentos gubernamentales donde pueden haber estado almacenados en silos. Los datos deben ser precisos y no estar desfasados. Además, los datos deben ser exhaustivos y no deben, por ejemplo, descuidar a las minorías o la economía informal. Los datos sobre las personas deben desglosarse cuando sea pertinente, incluso por ingresos, sexo, edad, raza, origen étnico, situación migratoria, discapacidad y ubicación geográfica.
- Desarrollar capacidades de datos abiertos: Estas capacidades se dirigen a dos grupos:
- Para los funcionarios públicos, incluye la comprensión de los beneficios de los datos abiertos potenciando y propiciando el trabajo que conlleva la apertura de los datos.
- Para los usuarios potenciales, incluye la demostración de las oportunidades de los datos abiertos, como su reutilización, y cómo tomar decisiones informadas.
- Preparar los datos para la IA: Si los datos no van a ser utilizados únicamente por humanos, sino que también pueden alimentar sistemas de IA, deben cumplir algunos criterios más para estar preparados para la IA.
- El primer paso en este sentido es preparar los datos en un formato legible por máquinas.
- Algunos formatos favorecen más que otros la legibilidad por parte de los sistemas de inteligencia artificial.
- Los datos también deben limpiarse y etiquetarse, lo que a menudo lleva mucho tiempo y, por tanto, es costoso.
- El éxito de un sistema de IA depende de la calidad de los datos de entrenamiento, incluida su coherencia y pertinencia. La cantidad necesaria de datos de entrenamiento es difícil de conocer de antemano y debe controlarse mediante comprobaciones de rendimiento. Los datos deben abarcar todos los escenarios para los que se ha creado el sistema de IA.
Paso 2: Abrir los datos
- Seleccionar los conjuntos de datos que se van a abrir: El primer paso para abrir los datos es decidir qué conjuntos de datos se van a abrir. Los criterios a favor de la apertura son:
- Si ha habido solicitudes previas de apertura de estos datos
- Si otros gobiernos han abierto estos datos y si ello ha dado lugar a usos beneficiosos de los datos.
La apertura de los datos no debe violar las leyes nacionales, como las leyes de privacidad de datos.
- Abrir los conjuntos de datos legalmente: Antes de abrir los conjuntos de datos, el gobierno correspondiente tiene que especificar exactamente en qué condiciones, en su caso, se pueden utilizar los datos. A la hora de publicar los datos, los gobiernos podrán optar por la licencia que mejor se adapte a sus objetivos, como son por ejemplo las licencias Creative Commons y Open. Para dar soporte a la selección de licencia la comisión europea pone a disposición JLA - Compatibility Checker, una herramienta que da apoyo para esta decisión
- Abrir los conjuntos de datos técnicamente: La forma más habitual de abrir los datos es publicarlos en formato electrónico para su descarga en un sitio web, además se debe contar con APIs para el consumo de estos datos, ya sea el del propio Gobierno o el de un tercero.
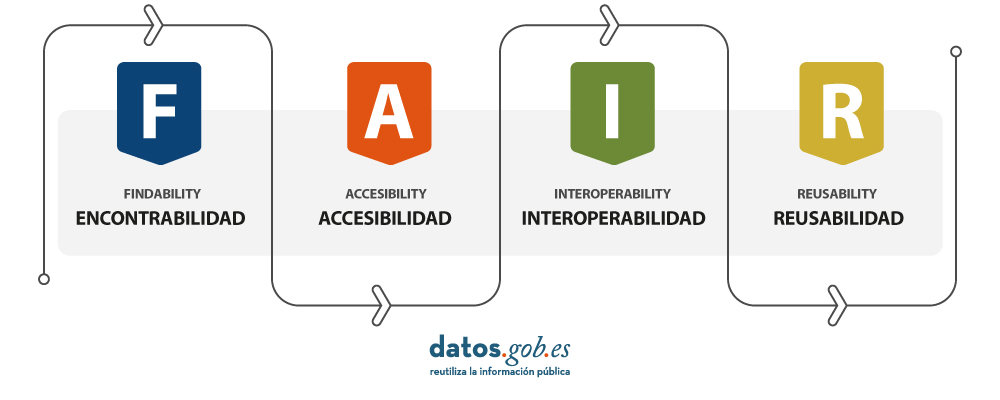
Los datos deben presentarse en un formato que permita su localización, accesibilidad, interoperabilidad y reutilización, cumpliendo así los principios FAIR.
Además, los datos también podrían publicarse en un archivo o repositorio de datos, que debería ser, según la Recomendación de la UNESCO, apoyado y mantenido por una institución académica, una sociedad académica, una agencia gubernamental u otra organización sin ánimo de lucro bien establecida y dedicada al bien común que permita el acceso abierto, la distribución sin restricciones, la interoperabilidad y la preservación y el archivo digital a largo plazo.
- Crear una cultura impulsada por los datos abiertos: La experiencia ha demostrado que, además de la apertura legal y técnica de los datos, hay que lograr al menos dos cosas más para alcanzar una cultura de datos abiertos:
- A menudo los departamentos gubernamentales no están acostumbrados a compartir datos y ha sido necesario crear una mentalidad y educarles en esta finalidad.
- Además, los datos deben convertirse, si es posible, en la base exclusiva para la toma de decisiones; en otras palabras, las decisiones deben estar basadas en los datos.
- Además se requieren cambios culturales por parte de todo el personal implicado, fomentando la divulgación proactiva de datos, lo que puede asegurar que los datos estén disponibles incluso antes de que se soliciten.
Paso 3: Seguimiento de la reutilización y la sostenibilidad
- Apoyar la participación ciudadana: Una vez abiertos los datos, deben ser descubiertos por los usuarios potenciales. Para ello hay que desarrollar una estrategia de promoción, que puede comprender anunciar la apertura de los datos en comunidades de datos abiertos y los canales de medios sociales pertinentes.
Otra actividad importante es la consulta y el compromiso tempranos con los usuarios potenciales, a los que, además de informar sobre los datos abiertos, se debe animar a utilizarlos y reutilizarlos y a seguir participando.
- Apoyar el compromiso internacional: Las asociaciones internacionales aumentarían aún más los beneficios de los datos abiertos, por ejemplo, mediante la colaboración sur-sur y norte-sur. Especialmente importantes son las asociaciones que apoyan y crean capacidades para la reutilización de los datos, ya sea mediante el uso de IA o sin ella.
- Apoyar la participación beneficiosa de la IA: Los datos abiertos ofrecen muchas oportunidades a los sistemas de IA. Para aprovechar todo el potencial de los datos, es necesario potenciar que los desarrolladores hagan uso de ellos y desarrollen sistemas de IA en consecuencia. Al mismo tiempo, hay que evitar el abuso de los datos abiertos para aplicaciones de IA irresponsables y perjudiciales. Una práctica recomendada es mantener un registro público de qué datos han utilizado los sistemas de IA y cómo lo han hecho.
- Mantener datos de alta calidad: Muchos datos quedan obsoletos rápidamente. Por lo tanto, los conjuntos de datos deben actualizarse con regularidad. El paso "Mantener datos de alta calidad" convierte esta directriz en un bucle, ya que enlaza con el paso "Reunir y recopilar datos de alta calidad".
Conclusiones
Estas directrices sirven como una llamada a la acción por parte de la UNESCO sobre la ética de la inteligencia artificial. Los datos abiertos son un requisito previo y necesario para el seguimiento y la consecución del desarrollo sostenible.
Debido a la magnitud de las tareas, los gobiernos no sólo deben adoptar la apertura de los datos, sino también crear condiciones favorables para una participación beneficiosa de la IA que cree nuevos conocimientos a partir de los datos abiertos, para una toma de decisiones basada en pruebas.
Si los Estados Miembros de la UNESCO siguen estas directrices y abren sus datos de manera sostenible, crean capacidades, así como una cultura impulsada por los datos abiertos, podremos conseguir un mundo en el que los datos no sólo sean más éticos, sino que las aplicaciones sobre estos datos sean más certeras y beneficiosas para la humanidad.
Referencias
https://www.unesco.org/en/articles/open-data-ai-what-now
Autor : Ziesche, Soenke , ISBN : 978-92-3-100600-5
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En la etapa protagonizada por la inteligencia artificial que estamos comenzando, los datos abiertos se han convertido por derecho propio en un activo cada vez más valioso no sólo como soporte a la transparencia, sino también para el progreso de la innovación y el desarrollo tecnológico en general.
La apertura de datos ha traído enormes beneficios al brindar acceso público a conjuntos de datos que habilitan el impulso de iniciativas de transparencia gubernamental, que estimulan investigaciones científicas y que promueven la innovación en sectores tan variados como la salud, la educación, la agricultura, o la lucha contra el cambio climático.
Sin embargo, a medida que aumenta la disponibilidad de datos, también lo hace la preocupación por la privacidad ya que la exposición y tratamiento indebido de datos personales puede poner en peligro la privacidad de las personas. ¿Qué herramientas tenemos para mantener el equilibrio entre el acceso abierto a la información y la protección de los datos personales para garantizar la privacidad de las personas en un futuro que ya es digital?
Anonimización y pseudonimización
Para abordar estas preocupaciones, se han desarrollado técnicas como la anonimización y pseudonimización que con frecuencia se confunden. La anonimización se refiere al proceso por el que se modifica un conjunto de datos para que no exista una probabilidad razonable de que pueda identificarse a una persona física en el mismo. Es importante destacar que, en este caso, después del tratamiento, el conjunto de datos anonimizado ya no estaría bajo el ámbito de aplicación del Reglamento General de Protección de Datos (RGPD). En este informe de datos.gob.es se analizan tres enfoques generales para la anonimización de datos: aleatorización, generalización y seudonimización.
Por su parte, la pseudonimización es el proceso de reemplazar atributos identificables con pseudónimos o identificadores ficticios de forma que los datos no puedan atribuirse a la persona física sin utilizar información adicional. El tratamiento de pseudonimización genera dos nuevos conjuntos de datos: el que contiene la información pseudonimizada y el que contiene la información adicional que permite revertir la anonimización. El conjunto de datos pseudonimizados y la información adicional vinculada con dicho conjunto de datos sí están bajo el ámbito de aplicación del Reglamento General de Protección de Datos (RGPD). Además, se requiere que dicha información adicional esté independizada y sujeta a medidas técnicas y organizativas destinadas a garantizar que los datos personales no se atribuyan a una persona física.
Consentimiento
Otro aspecto clave para garantizar la privacidad es el cada vez más presente consentimiento “inequívoco” de los interesados por el que las personas manifiestan ser conscientes y estar de acuerdo con cómo se tratarán sus datos antes de que estos se compartan o utilicen. Es necesario que las organizaciones y las entidades que recopilan datos proporcionen políticas de privacidad claras y comprensibles pero cada vez más se pone de manifiesto la necesidad de una mayor educación en materia de tratamiento de datos que ayude a las personas a comprender mejor sus derechos y que garantice decisiones más informadas.
En respuesta a la creciente necesidad de gestionar adecuadamente estos consentimientos, han surgido soluciones tecnológicas que buscan simplificar y mejorar el proceso para los usuarios. Estas soluciones conocidas como plataformas de gestión de los consentimientos (CMP, por sus siglas en inglés), nacieron originalmente en el ámbito del sector salud y permiten a las organizaciones recopilar, almacenar y rastrear los consentimientos de los usuarios de una manera más eficiente y transparente. Estas herramientas ofrecen interfaces amigables y visualmente atractivas que facilitan la comprensión de qué datos se están recopilando y con qué propósito. Pero, sobre todo, estas plataformas proporcionan a los usuarios la posibilidad de modificar o retirar su consentimiento en cualquier momento, otorgándoles un mayor control sobre sus datos personales.
Entrenamientos de inteligencia artificial
El entrenamiento de modelos de inteligencia artificial (IA) se perfila como uno de los campos más desafiantes en materia de gestión de la privacidad por la multitud de dimensiones que es necesario tener en cuenta. A medida que la IA continúa evolucionando y se integra más profundamente en nuestra vida cotidiana, la necesidad de entrenar modelos con grandes cantidades de datos aumenta, como han puesto de manifiesto los vertiginosos avances en materia de IA generativa del último año. Sin embargo, esta práctica a menudo se enfrenta a profundos dilemas éticos y de privacidad ya que los datos de mayor valor en algunos escenarios no son en absoluto abiertos.
Los avances en tecnologías como el aprendizaje federado, que permite entrenar algoritmos de IA a través de una arquitectura descentralizada formada por múltiples dispositivos los cuales contienen sus propios datos locales y privados, son parte de la solución a este desafío. De este modo, no se intercambian datos de forma explícita, algo que es clave en aplicaciones de salud, defensa o farmacia.
Asimismo, están ganando tracción técnicas como la privacidad diferencial que permite garantizar, mediante la incorporación de ruido aleatorio, aplicando funciones matemáticas a la información original, que en el resultado del proceso de análisis de los datos a los que se ha aplicado esta técnica no hay pérdida en la utilidad de los resultados obtenidos.
Web3
Pero si algún avance promete revolucionar nuestra interacción en internet, otorgando mayor control y propiedad a los usuarios sobre sus datos, este sería la web3 ya que, en este nuevo paradigma, la gestión de la privacidad es inherente a su propio diseño. Con la integración de tecnologías como la cadena de bloques (blockchain), los contratos inteligentes (smart contracts) y las organizaciones autónomas descentralizadas, la web3 busca proporcionar a los individuos un control total sobre su identidad y todos sus datos, eliminando intermediarios y potencialmente reduciendo puntos de vulnerabilidad a la privacidad.
A diferencia de las plataformas centralizadas actuales, donde los datos de los usuarios a menudo son “propiedad” o están controlados por empresas privadas, la web 3.0 aspira a que cada persona sea dueña y gestora de su propia información. No obstante, esta descentralización también plantea desafíos por lo que es esencial que, mientras se despliega esta nueva era de la web, se desarrollen herramientas y protocolos robustos que garanticen tanto la libertad como la privacidad de los usuarios en el entorno digital.
La privacidad en la era de los datos abiertos, la inteligencia artificial y la web3 obliga, sin duda, a trabajar con equilibrios delicados que a menudo son inestables. Por ello, un nuevo conjunto de soluciones tecnológicas, fruto de la colaboración entre gobiernos, empresas y ciudadanos, será esencial para mantener este equilibrio y garantizar que, mientras disfrutamos de los beneficios de un mundo cada vez más digital, también seamos capaces de proteger los derechos fundamentales de las personas.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
La aplicación UNA Women ofrece un dashboard personalizado con opciones formativas para mujeres jóvenes según sus circunstancias socioeconómicas.
El objetivo principal del proyecto es contribuir a reducir la brecha laboral de género. Para ello, la empresa ITER IDEA ha utilizado más de 6 millones de líneas de datos procesados de distintas fuentes, como data.europa.eu, Eurostat, Censis, Istat (Instituto nacional de estadística de Italia) o NUMBEO.
A nivel experiencia de usuaria, la aplicación plantea en primer lugar un formulario para conocer datos clave sobre la persona que busca información: edad, formación o sector profesional, presupuesto para formación etc. Una vez ha recogido los datos, la app ofrece un mapa interactivo con todas aquellas opciones formativas en Europa. Cada ciudad cuenta con un panel que muestra datos de interés sobre estudios, coste de vida en la ciudad, etc.
Blog
La serie “Stories of use cases”, organizada por el portal de datos abiertos europeo (data.europe.eu), es un conjunto de eventos online sobre el uso de los datos abiertos para contribuir a la consecución de objetivos comunes de la Unión Europea como la consolidación de la democracia, el impulso de la economía, la lucha contra el cambio climático o la transformación digital. La serie consta de cuatro eventos y todas las grabaciones están disponibles en el canal de Youtube del portal europeo de datos abiertos. También están publicadas las presentaciones que se utilizaron para exponer cada caso.
En un post anterior de datos.gob.es, explicamos las aplicaciones que se presentaron en dos de los eventos de la serie, en concreto, sobre economía y democracia. Ahora, nos centramos en los casos de uso relacionados con clima y tecnología, así como los conjuntos de datos abiertos que se emplearon para su desarrollo.
Los datos abiertos han permitido el desarrollo de aplicaciones que ofrecen información y servicios variados. En materia de clima, algunos ejemplos logran identificar la trazabilidad del proceso de gestión de residuos o visualizar datos relevantes sobre agricultura ecológica. Mientras que la aplicación de los datos abiertos en el ámbito tecnológico facilita la gestión de procesos. ¡Descubre los ejemplos destacados por el portal de datos abiertos europeo!
Datos abiertos para cumplir con el European Green Deal
El European Green Deal es una estrategia de la Comisión Europea que tiene como objetivo lograr la neutralidad climática en Europa para el año 2050 y fomentar el crecimiento económico sostenible. Para alcanzar este objetivo, la Comisión Europea está trabajando en varias líneas de acción, como la reducción de emisiones de gases de efecto invernadero, la transición hacia una economía circular y la mejora de la eficiencia energética. Bajo esta meta común y empleando conjuntos de datos abiertos, se han desarrollado las tres aplicaciones que se presentan en uno de los webinars de la serie sobre casos de uso de datos.europe.eu: Eviron mate, Geofluxus y MyBioEuBuddy.
-
Eviron mate: Es un proyecto educativo que tiene como objetivo concienciar a los jóvenes sobre el cambio climático y los datos relacionados con él. Para lograr este objetivo, Eviron mate utiliza datos abiertos de Eurostat, el programa Copernicus y data.europa.eu.
- Geofluxus: Es una iniciativa que realiza un seguimiento de los residuos desde su punto de origen hasta su destino final, para fomentar la reutilización de materiales y reducir la cantidad de residuos. Su principal objetivo es extender la vida útil de los materiales y ofrecer herramientas a las empresas para tomar mejores decisiones con sus desechos. Para ello, Geofluxus utiliza datos abiertos de Eurostat y de diferentes portales de datos abiertos nacionales.
- MyBioEuBuddy es un proyecto que ofrece información y visualizaciones sobre la agricultura sostenible en Europa, utilizando datos abiertos de Eurostat y de diferentes portales de datos abiertos regionales.
El papel de los datos abiertos en la transformación digital
Además de contribuir a la lucha contra el cambio climático permitiendo monitorizar procesos relacionados con el medio ambiente, los datos abiertos pueden ofrecer resultados interesantes en otros ámbitos que también operan en la era digital. La combinación del uso de datos abiertos con tecnologías innovadoras ofrece un resultado muy valioso, por ejemplo, en procesamiento de lenguaje natural, inteligencia artificial o realidad aumentada, entre otras.
Otro de los seminarios online de la serie sobre casos de uso presentado por el European Data Portal se adentró en este tema: el impulso de la transformación digital en Europa mediante datos abiertos. Durante el evento, se presentaron tres aplicaciones que combinan tecnología puntera y datos abiertos: Big Data Test Infrastructure, Lobium y 100 europeans.
- "Big Data Test Infrastructure (BDTI)": Es una herramienta de la Comisión Europea que cuenta con una plataforma en la nube para facilitar el análisis de datos abiertos para las administraciones del sector público, brindando una solución gratuita y lista para usar. BDTI ofrece herramientas de código abierto que fomentan la reutilización de datos del sector público. Desde cualquier administración pública, se puede solicitar el servicio de asesoramiento gratuito rellenando este formulario. El BDTI ya ha ayudado a algunas entidades del sector público a optimizar procesos de contratación, obtener información sobre movilidad para rediseñar servicios o apoyar a los médicos extrayendo conocimiento de artículos.
- Lobium: Web que ayuda a los gerentes de asuntos públicos a abordar las complejidades de sus tareas. Su objetivo es proporcionar herramientas para la administración de campañas, informes internos, medición de KPI y paneles de control de asuntos gubernamentales. En definitiva, su solución permite aprovechar las ventajas de las herramientas digitales para mejorar y optimizar las gestiones públicas.
- 100 europeans: Es una aplicación que visualiza estadísticas europeas de manera sencilla, dividiendo la población europea en 100 personas. Mediante una navegación de scrolling presenta visualizaciones de datos con cifras sobre los hábitos saludables y de consumo en Europa.
Las seis aplicaciones son ejemplos de cómo los datos abiertos pueden servir para desarrollar soluciones de interés para la sociedad. Descubre más casos de uso creados con datos abiertos en este artículo que hemos publicado en datos.gob.es.

Conoce más sobre estas aplicaciones en sus seminarios -> Grabaciones aquí
Blog
Los datos abiertos son una herramienta útil para tomar decisiones informadas que incentiven el éxito de un proceso y mejorar su eficacia. Desde una visión sectorial, los datos abiertos aportan información relevante sobre el sector legal, el educativo o el de la salud. Todos ellos, junto a otros muchos ámbitos, emplean fuentes abiertas para medir el cumplimiento de una mejora o desarrollar herramientas que faciliten el trabajo a los profesionales.
Los beneficios del uso de los datos abiertos son amplios y su variedad va de la mano de la innovación tecnológica: cada día surgen más oportunidades para emplear datos abiertos en el desarrollo de soluciones innovadoras. Ejemplo de ello puede ser el desarrollo urbanístico alineado con los valores de sostenibilidad que defiende la Organización de las Naciones Unidas (ONU).
Las ciudades ocupan el 3% de la superficie terrestre; sin embargo, emiten el 70% de las emisiones de carbono y consumen más del 60% de los recursos de todo el mundo, según la ONU. En 2023, más de la mitad de la población mundial vive en ciudades y se prevé que esta cifra siga creciendo. En 2030 se estima que más de 5.000 millones de personas vivirían en ciudades, es decir, más del 60% de la población de todo el mundo.
A pesar de la tendencia, las infraestructuras y los barrios no cumplen con las condiciones adecuadas de desarrollo sostenible y el objetivo es “Lograr que las ciudades y los asentamientos humanos sean inclusivos, seguros y sostenibles”, tal y como se reconoce en el ODS número 11. La planificación y gestión adecuada de los recursos urbanos son cuestiones de peso a la hora de crear y mantener comunidades basadas en la sostenibilidad. En este contexto, los datos abiertos juegan un importante papel para medir el cumplimiento de este ODS y así alcanzar la meta de ciudades sostenibles.
En definitiva, los datos abiertos se constituyen como una herramienta fundamental para el fortalecimiento y progreso del desarrollo sostenible de las ciudades.
En esta infografía, hemos recogido casos de uso que emplean conjuntos de datos abiertos para monitorizar y/o mejorar la eficiencia energética, el transporte y la movilidad urbana, la calidad del aire y el nivel de ruido. Cuestiones que contribuyen al buen funcionamiento de los centros urbanos.
Haz clic en la infografía para verla en tamaño real

Aplicación
Se trata de una aplicación colaborativa desarrollada para la captura y el envío de datos de cobertura de acceso a internet dentro de la Comunidad de Aragón. La ciudadanía puede participar y aportar información para ayudar a conocer la calidad de acceso a internet en sus municipios. Su principal objetivo es el de conocer la calidad en el acceso a internet en Aragón.
En definitiva, esta app obtiene y ofrece los datos de cobertura a internet de todos los municipios de Aragón a través de un trabajo de campo inicial unido a los datos aportados de forma anónima por los usuarios. Su finalidad es la de procesar los datos obtenidos y ofrecerlos abiertamente y de forma pública a través de un mapa. Para ello utiliza los sistemas y servicios cartográficos del Gobierno de Aragón los del Instituto Geográfico de Aragón.