Noticia
El pasado 15 de febrero se cerró el plazo para recibir las solicitudes para participar en el IV Desafío Aporta. En total, se han recibido 38 propuestas válidas en tiempo y forma, todas de gran calidad, cuyo objetivo es impulsar mejoras en la salud y el bienestar de los ciudadanos a través de la reutilización de datos ofrecidos por las administraciones públicas para su reutilización.
Las tecnologías disruptivas, claves para extraer el máximo valor de los datos
De acuerdo con las bases del concurso, en esta primera fase los participantes tenían que presentar ideas que identificasen nuevas oportunidades de captar, analizar y utilizar la inteligencia de los datos en el desarrollo de soluciones de todo tipo: estudios, aplicaciones móviles, servicios o sitios webs.
Todas las ideas buscan hacer frente a diversos retos relacionados con la salud y el bienestar, muchos de las cuales impactan directamente sobre nuestro sistema sanitario, como la mejora de la eficiencia de los servicios, la optimización de los recursos o el impulso de la transparencia. Algunas de las áreas abordadas por los participantes son la presión sobre el sistema sanitario, el diagnóstico de enfermedades, la salud mental, los hábitos de vida saludables, la calidad del aire o el impacto del cambio climático.
Muchos de los participantes han elegido apostar por las tecnologías disruptivas para hacer frente a estos retos. Entre las propuestas, nos encontramos con soluciones que aprovechan el poder de los algoritmos para cruzar datos y determinar hábitos saludables o modelos predictivos que nos permiten conocer la evolución de enfermedades o la situación del sistema sanitario. Algunas, incluso, utilizan técnicas de gamificación. También hay gran cantidad de soluciones dirigidas a acercar información de utilidad a los ciudadanos, a través de mapas o visualizaciones.
Asimismo, son diversos los colectivos concretos a los que se dirigen las soluciones: encontramos herramientas dirigidas a mejorar la calidad de vida de personas con discapacidad, mayores, niños, individuos que viven solos o que necesitan asistencia domiciliaria, etc.
Propuestas de toda España y con mayor presencia de mujeres
Equipos y particulares de toda España se han animado a participar en el Desafío. Contamos con representantes de 13 comunidades Autónomas: Madrid, Cataluña, País Vasco, Andalucía, Valencia, Canarias, Galicia, Aragón, Extremadura, Castilla y León, Castilla – La Mancha, La Rioja y Asturias.
El 25% de las propuestas han sido presentadas por particulares y el 75% por equipos multidisciplinares integrados por diversos miembros. La misma distribución la encontramos entre personas físicas (75%) y personas jurídicas (25%). En esta última categoría encontramos equipos procedentes de universidades, organismos ligados a la Administración Pública y distintas empresas.
Cabe destacar que en esta edición ha aumentado el número de mujeres participantes, demostrando el avance de nuestra sociedad en el ámbito de la igualdad. Hace dos ediciones, el 38% de las propuestas estaban presentadas por mujeres o por equipos con mujeres entre sus miembros. Ahora ese número aumenta hasta el 47,5%. Si bien es una mejora significativa, aun queda trabajo por hacer a la hora de impulsar las materias STEM entre las mujeres y niñas de nuestro país.
Comienza la deliberación del jurado
Una vez aceptadas las propuestas, es el momento de la valoración del jurado, integrado por expertos del ámbito de la innovación, los datos y la salud. La valoración estará basada en una serie de criterios detallados en las bases, como la calidad y claridad global de la idea propuesta, las fuentes de datos utilizadas o el impacto esperado de la idea propuesta en la mejora de la salud y el bienestar de los ciudadanos.
Las 10 propuestas con la mejor valoración pasarán a la fase II, y contarán con un plazo mínimo de dos meses para desarrollar el prototipo fruto de su idea. Las propuestas se presentarán antes el mismo jurado, que puntuará cada proyecto de manera individual. Los tres prototipos con mayor puntuación serán los ganadores y recibirán una dotación económica de 5.000, 4.000 y 3.000 euros, respectivamente.
¡Mucha suerte a todos los participantes!
Blog
Hoy 8 de marzo es el día que conmemoramos la lucha de las mujeres por lograr su plena participación en la sociedad, además de dar visibilidad a la desigualdad actual de género y reivindicar la acción global por una igualdad efectiva de derechos en todos los ámbitos.
Sin embargo, los datos parecen indicar que todavía nos queda camino por recorrer en este aspecto. El 70% de los 1.300 millones de personas que viven en condiciones de pobreza son mujeres. Las mujeres predominan en la producción mundial de alimentos (hasta el 80% en algunas zonas), pero poseen menos del 10% de la tierra. El 80% de las personas desplazadas por desastres y cambios relacionados con el clima en todo el mundo son mujeres y niñas. Y la situación para las mujeres no ha hecho más que empeorar debido a la pandemia, haciendo que la estimación del tiempo necesario para cerrar la brecha de género actual crezca ahora hasta más de 135 años.
La importancia de los datos en la lucha por la igualdad
Es por tanto un hecho que las mujeres se han quedado retrasadas en muchos de los indicadores de desarrollo sostenible, una desigualdad que además se está también replicando en el mundo digital – y que incluso se amplifica a través del cada vez más frecuente uso de algoritmos que carecen también de los datos de entrenamiento necesarios para ser representativos de la realidad de las mujeres. Pero también es un hecho que ni siquiera contamos con todos los datos necesarios para conocer con certeza cuál es la situación a la que nos enfrentamos con respecto a un gran número de indicadores clave.
Existe una escasez generalizada de datos de género que afecta a todos los sectores económicos y sociales. El Banco Mundial, la Unión Europea, la OECD, las Naciones Unidas, UNICEF, la ITU o el IMF – son cada vez más los organismos internacionales que están llevando a cabo sus esfuerzos particulares para recopilar sus propias bases de datos de género. No obstante, siguen faltando indicadores en múltiples aspectos clave, además de otras carencias importantes en cuanto a calidad de los datos actuales que frecuentemente están incompletos u obsoletos.
Esta carencia de datos es algo que puede resultar particularmente problemático cuando hablamos, por ejemplo, de temas tan sensibles como la violencia de género – un área en la que afortunadamente cada vez contamos con más datos a nivel global, e incluso algunos grandes ejemplos esperanzadores como la iniciativa de datos sobre feminicidios liderada por ILDA. Esto es un avance muy importante porque resulta todavía más difícil mejorar cuando ni siquiera sabemos cuál es la situación actual. Y es que los datos, y las políticas de gobernanza que creamos para gestionarlos, también pueden ser sexistas.
Los datos son herramientas que sirven para tomar mejores decisiones y elaborar mejores políticas. Nos permiten establecer objetivos y medir nuestros avances. Los datos se han convertido por tanto en una herramienta indispensable para crear un impacto social en las comunidades. Es por todo ello que la falta de datos sobre la vida de las mujeres y de las niñas es tan perjudicial.
Cómo abordar la brecha de género desde los datos
A la hora de buscar soluciones para este problema, y trabajar así por la equidad de género también a través de los datos, es crucial que involucremos a los protagonistas y que les demos voz. Así, a través de sus propias experiencias, podremos desarrollar procesos más inclusivos para la recopilación, el análisis y la publicación de datos. De este modo estaremos en una posición mucho mejor a la hora de utilizar los datos como una herramienta de inclusión para abordar la igualdad de género. El excelente manual del feminismo de datos escrito por Catherine D’Ignazio y Lauren Klein nos ofrece una serie de estrategias y principios que nos servirán de guía para poder conseguirlo:
- Examinar el poder – El feminismo de datos empieza por analizar cómo opera el poder en el mundo.
- Desafiar el poder – Debemos comprometernos a cuestionar las estructuras de poder cuando son desiguales y a trabajar por la equidad.
- Potenciar las emociones y la personificación – El feminismo de datos nos enseña a valorar múltiples formas de conocimiento, incluyendo los que provienen de las personas.
- Repensar los binarismos y las jerarquías – Debemos desafiar el binarismo de género, así como otros sistemas de cuantificación y clasificación que podrían dar lugar a distintas formas de marginación.
- Adoptar el pluralismo – El conocimiento más completo surge de sintetizar múltiples perspectivas, priorizando los saberes locales y las experiencias.
- Considerar el contexto – Los datos no son neutrales ni objetivos. Son productos de relaciones sociales desiguales, y entender ese contexto será esencial a la hora de realizar un análisis ético y preciso.
- Hacer visible el trabajo – El trabajo de la ciencia de datos es producto de la colaboración de muchas personas. Se debe hacer visible toda esa labor, para que pueda ser reconocida y valorada.
Nuestras opciones para contribuir a reducir la brecha de datos
Para poder avanzar en esta lucha por la igualdad necesitamos muchos más datos desagregados por género, que reflejen adecuadamente las inquietudes de las mujeres y las niñas, su diversidad y todos los aspectos de sus vidas. Todos podemos y debemos contribuir a llamar la atención sobre las desventajas que sufren las mujeres a través de los datos. Algunos consejos al respecto son:
- Comencemos por recopilar y publicar datos siempre desglosados por género.
- Utilicemos siempre a las mujeres como grupo de referencia en nuestros cálculos cuando estemos tratando desigualdades que les afectan directamente.
- Documentemos las decisiones que tomamos y nuestras metodologías a la hora de trabajar con los datos de género, incluyendo cualquier cambio nuestros enfoques a lo largo del tiempo y su justificación.
- Compartamos siempre los datos en bruto y de forma completa en un formato abierto y reutilizable. De este modo, aunque no hayamos puesto el foco en los retos que afrontan las mujeres, al menos otros podrán hacerlo usando los mismos datos.
Entre todos podemos conseguir que lo invisible se haga visible y que finalmente todas y cada una de las mujeres y niñas del mundo sean tenidas en cuenta. La situación es urgente y éste es el momento de hacer una apuesta decidida para cerrar la brecha de datos como herramienta necesaria a la hora de acabar con la brecha de género también.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hoy en día, nadie puede negar que los datos abiertos atesoran un gran poder económico. La propia Comisión Europea estima que la cifra de negocio de los datos abiertos en la EU27 podría alcanzar los 334.200 millones en 2025, impulsada por su uso en ámbitos ligados a tecnologías disruptivas como la inteligencia artificial, el machine learning o las tecnologías del lenguaje.
Pero junto a su impacto económico, los datos abiertos también tienen un importante valor para la sociedad: proporcionan información que permiten visibilizar la realidad social, impulsando la toma de soluciones informada en pro del beneficio común.
Son miles los campos donde la apertura de datos es fundamental, desde las crisis de refugiados hasta la inclusión de personas con discapacidad, pero en este artículo vamos a centrarnos en la lacra de la violencia de género.
¿Dónde puedo obtener datos sobre el tema?
A nivel mundial, organismos como la ONU, la Organización Mundial de la Salud o el Banco Mundial ofrecen recursos y estadísticas relacionados con la violencia contra la mujer.
En nuestro país, organismos locales, autonómicos y estatales publican conjuntos de datos relacionados. Para facilitar el acceso unificado a los mismos, la delegación del Gobierno contra la Violencia de Género cuenta con un portal estadístico que incluye en un único espacio datos que provienen de diversas fuentes como el Ministerio de Hacienda y Administraciones Públicas, el Consejo General del Poder Judicial o el Servicio Público de Empleo Estatal del Ministerio de Empleo y Seguridad Social. El usuario puede cruzar variables y crear tablas y gráficos que faciliten la visualización de la información, así como exportar los conjuntos de datos en formato CSV o Excel.
Proyectos para concienciar y visibilizar
Pero los datos por sí solos pueden ser complicados de entender. Necesitan de un contexto que los dote de significado y los transforme en información y conocimiento. Es aquí donde surgen distintos proyectos que buscan acercar los datos a la ciudadanía de forma sencilla.
Son muchas las asociaciones y organismos que aprovechan los datos publicados para crear visualizaciones e historias con datos que ayudan a concienciar sobre la violencia machista. Como ejemplo, la Iniciativa Barcelona Open Data desarrolla el proyecto “DatosXViolenciaXMujeres”. Se trata de un recorrido visual e interactivo sobre el impacto de la violencia de género en España y por Comunidades Autónomas durante el período 2008-2020, aunque se va actualizando periódicamente. Utilizando técnicas de data storytelling, se muestra la evolución de la violencia de género en el ámbito de la pareja, la respuesta judicial (órdenes dictadas y condenas firmes), los recursos públicos destinados, el impacto del COVID-19 en este ámbito y los delitos de violencia sexual. En cada gráfica se incluyen enlaces a la fuente original y a espacios dónde descargar los datos, para que puedan ser reutilizados en otros proyectos.
Otro ejemplo es “Datos contra el ruido”, desarrollado en el marco de GenderDataLab, plataforma de colaboración para el bien digital común que cuenta con el apoyo de distintas asociaciones, como Pyladies o Canodron, y el Ayuntamiento de Barcelona, entre otros. Esta asociación promueve la inclusión de la perspectiva de género en la recopilación de datos abiertos a través de distintos proyectos como el citado “Datos contra el ruido”, que visibiliza y hace comprensible la información que publica el sistema judicial y la policía sobre la violencia machistas. A través de datos y visualizaciones informa sobre las tipologías de delitos o su distribución geográfica a lo largo de nuestro país, entre otras cuestiones. Al igual que sucedía con “DatosXViolenciaXMujeres”, se incluye el enlace a la fuente original de los datos y a espacios de descarga.
Herramientas y soluciones para apoyar a las victimas
Pero además de visibilizar, los datos abiertos también nos pueden dar información sobre los recursos dedicados a ayudar a las víctimas, como veíamos en algunos de los proyectos anteriores. Poner esta información al alcance de las victimas de una forma rápida y sencilla es fundamental. Son de gran ayuda los mapas que muestran la situación de los centros de ayuda, como este del proyecto SOL.NET, con información sobre organizaciones que ofrecen servicios de apoyo y atención a víctimas de violencia de género en España. O este con los centros y servicios sociales de la Comunidad Valenciana dirigidos a colectivos desfavorecidos, entre los que se encuentras las víctimas de violencia de género, elaborado por la propia institución pública.
Esta información también se incorpora en aplicaciones dirigidas a víctimas, como Anticípate. Esta app no solo facilitar información y recursos a mujeres que se encuentre en situación vulnerable, sino que también cuenta con un botón de llamada de emergencia y posibilita el acceso a asesoramiento jurídico, psicológico o incluso sobre defensa personal, facilitando el apoyo de un criminólogo social.
En definitiva, nos encontramos ante un tema especialmente sensible, sobre el que es necesario seguir concienciando y luchando para poder ponerle fin. Una tarea en las que los datos abiertos pueden contribuir notablemente.
Si conoces algún otro ejemplo que muestre el poder de los datos abiertos en este campo, te animamos a compartirlo en la sección de comentarios o envíanos un email a dinamizacion@datos.gob.es.
Contenido elaborado por el equipo de datos.gob.es.
Noticia
15 personalidades del ámbito de la innovación, los datos y la salud serán los encargados de evaluar las propuestas recibidas a la IV edición del Desafío Aporta, la competición que busca premiar ideas y prototipos que impulsen mejoras en un sector concreto -en este caso la salud y el bienestar- a través del uso de datos abiertos.
Los nombres de los miembros del jurado se han conocido a través de una resolución publicada en la sede electrónica de Red.es. Entre ellos encontramos representantes de las Administraciones Públicas, organismos ligados a la economía digital y el ámbito de la universidad y las comunidades de datos. ¿Quieres saber quiénes son?
Organizaciones ligadas al avance digital
En el jurado participan una serie de representantes de organismos públicos a nivel nacional y autonómico focalizados en la digitalización y transformación digital de nuestro país.
-
Alberto Palomo Lozano, Chief Data Officer de la Oficina del Dato, dependiente de la Secretaría de Estado de Digitalización e Inteligencia Artificial del Ministerio de Asuntos Económicos y Transformación Digital (MINECO). Entre sus funciones está el impulso de la compartición, la gestión y el uso de los datos a lo largo de todos los sectores productivos.
-
Miguel Valle del Olmo, Subdirección General de Inteligencia Artificial y Tecnologías Habilitadoras Digitales de la Secretaría de Estado de Digitalización e Inteligencia Artificial (MINECO), encargada del diseño e implementación de la Estrategia Nacional de Inteligencia Artificial de España.
-
Santiago Graña Domínguez, Subdirector General de Planificación y Gobernanza de la Administración Digital del MINECO. Se trata del órgano encargado de impulsar el proceso de racionalización de las tecnologías de la información y de las comunicaciones en el ámbito de la Administración General del Estado y sus Organismos Públicos
-
Francisco Javier García Vieira, Director de Servicios Públicos Digitales de Red.es, entidad pública impulsora de la Agenda Digital en España. El área de servicio Públicos trabaja en tres ámbitos: en educación, con Educa en Digital y los Puestos Educativos en el Hogar; en sanidad, con proyectos de cronicidad en Andalucía y Extremadura y con toda una gama de desarrollos locales y provinciales a través de los Territorios Inteligentes.
-
María Fernández Rancaño, directora adjunta de Servicios Públicos Digitales de Red.es, unidad encargada del despliegue de programas de implantación tecnológica en los servicios públicos de la Administración.
-
Zaida Sampedro Préstamo, Subdirectora General de Servicios a Consejerías y Administración Digital de Madrid Digital, la Agencia para la Administración Digital de la Comunidad de Madrid.
Entidades del ámbito de la salud
Dado el carácter sectorial del Desafío, se ha invitado a formar parte del jurado a representantes de organismos ligados a la salud y el bienestar.
-
Carlos Gallego Pérez, Director del Área IA de la Fundacio Tic Salut Social del Departament de Salut, de la Generalitat de Catalunya. Este organismo impulsa el desarrollo y la utilización de las TIC en la salud y el bienestar social, funcionando como un observatorio de nuevas tendencias e innovación. Entre sus proyectos encontramos iniciativas para llevar al ámbito de la salud la Inteligencia Artificial y tecnologías emergentes como el 5G.
-
Carlos Luis Parra Calderón, Jefe de Sección de Innovación Tecnológica del Hospital Universitario Virgen del Rocío del Servicio Andaluz de Salud. Este centro cuenta con un área de I+D+i centrado en proyectos de Learning Health Systems, Tecnologías del Lenguaje o Big Data para la Gestión Sanitaria, entre otros.
-
Noemí Cívicos Villa, Directora General de Salud Digital y Sistemas de Información para el Sistema Nacional de Salud del Ministerio de Sanidad. Se trata de organismos que engloba las prestaciones y servicios sanitarios de España.
Asociaciones empresariales
El Desafío Aporta busca poner de manifiesto el poder de los datos como bases de modelos de negocio que impulsen la economía. Por ello, no podían faltar en el jurado los representantes de entidades empresariales.
-
Antonio Cimorra Lanchas, Director de Transformación Digital y Tecnologías Habilitadoras de Ametic (Asociación Multisectorial de Empresas de Tecnologías de la Información, Comunicaciones y Electrónica). Esta asociación representa a empresas de todos los tamaños ligadas con la industria tecnológica digital española.
-
Olga Quirós Bonet. Secretaria General de ASEDIE (Asociación Multisectorial de la Información). ASEDIE representa a empresas infomediarias que, desde distintos sectores, reutilizan información para crear productos y servicios de valor añadido.
-
Víctor María Calvo-Sotelo Ibáñez-Martín, Director General de DigitalES (Asociación Española para la Digitalización), que reúne a empresas presentes en toda la cadena de valor digital. DigitalEs forma parte del Consejo Consultivo para la Transformación Digital del Gobierno y es miembro de la junta directiva de CEOE.
Universidades y comunidades de datos
Los estudiantes y desarrolladores son, entre otros, dos de los públicos objetivos de esta competición, y por ello era importante también contar con la participación de comunidades de datos y universidades.
-
Emilio López Cano, Profesor Contratado Doctor de la Escuela Técnica Superior de Ingeniería Informática de la Universidad Rey Juan Carlos de Madrid. Emilio también es el presidente de R-Hispano, una comunidad de usuarios y desarrolladores cuyo objetivo es fomentar el avance del conocimiento y el uso del lenguaje de programación en R.
-
Fernando Díaz de María, Catedrático y responsable del Grupo de Procesado Multimedia de la Escuela Politécnica Superior de la Universidad Carlos III de Madrid. Esta entidad cuenta con una atractiva oferta formativa en datos, tanto en grados como en posgrados.
-
María Sánchez González, Profesora asociada del departamento de Periodismo de la Universidad de Málaga y co-organizadora de DataBeers Málaga, una iniciativa sin ánimo de lucro especializada en eventos dinámicos relacionados con el universo de los datos, entre ellos, los datos abiertos.
La Secretaría del Jurado, con voz y voto, recae en Sonia Castro García-Muñoz, Coordinadora de la Iniciativa Aporta en la Dirección de Servicios Públicos Digitales de Red.es.

Ampliada la fecha de cierre de las inscripciones al 15 de febrero
En la misma resolución, también se ha ampliado la fecha de cierre de presentación de propuestas al 15 de febrero de 2022 a las 13:00. Aquellos ciudadanos que deseen participar en el Desafío tienen que presentar antes de esa fecha una idea para una solución que impulse mejoras en el ámbito de la salud y el bienestar, utilizando al menos un conjunto de datos generado por las Administraciones Públicas, ya sean nacionales o internacionales.
Toda la información disponible está publicada, junto a las bases, en la sección Desafío Aporta.
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
Captura del vídeo que muestra la interacción con el dashboard de la caracterización de la demanda de empleo y la contratación registrada en España disponible al final de este artículo
2. Objetivos
El objetivo principal de este post es realizar una visualización interactiva partiendo de datos abiertos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre la evolución de la demanda de empleo en España a lo largo de los últimos años. A partir de estos datos se determina el perfil que representa la demanda de empleo en nuestro país, estudiando específicamente cómo afecta la brecha de género al colectivo y la incidencia de variables como la edad, la prestación por desempleo o la región.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se han seleccionado conjuntos de datos publicados por el Servicio Público de Empleo Estatal (SEPE), coordinado por el Ministerio de Trabajo y Economía Social, que recogen series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presentan los demandantes de empleo. Estos datasets se encuentran disponibles en datos.gob.es con las siguientes características:
- Demandantes de empleo por municipio: contiene el número de demandantes de empleo desagregado por municipio, edad y sexo, desde 2006 hasta 2020.
- Gasto de prestaciones por desempleo por Provincia: serie temporal desde 2010 hasta 2020 sobre el gasto en prestaciones por desempleo, desagregado por provincia y el tipo de prestación.
- Contratos registrados por el Servicio Público de Empleo Estatal (SEPE) por municipio: estos conjuntos de datos contienen el número de contratos registrados tanto a demandantes como a no demandantes de empleo, desagregados por municipio, sexo y tipo de contrato, desde 2006 hasta 2020.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
RStudio es un entorno de desarrollo open source integrado para el lenguaje de programación R, dedicado al análisis estadístico y la creación de gráficos.
RMarkdown permite la realización de informes integrando texto, código y resultados dinámicos en un único documento.
Para la creación de los gráficos interactivos se ha utilizado la herramienta Kibana.
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstasg y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch. Las principales ventajas de esta herramienta son:
- Presenta la información de manera visual a través de dashboards interactivos y personalizables mediante intervalos temporales, filtros facetados por rango, cobertura geoespacial, entre otros.
- Dispone de un catálogo de herramientas de desarrollo (Dev Tools) para interactuar con los datos almacenados en Elasticsearch.
- Cuenta con una versión gratuita para utilizar en tu propio ordenador y una versión enterprise que se desarrolla en un cloud propio de Elastic u otras infraestructuras en cloud como Amazon Web Service (AWS).
En la propia web de Elastic encontramos manuales de usuario para la descarga e instalación de la herramienta, o cómo crear gráficos o dashboards, entre otros. Además ofrece vídeos cortos en su canal de youtube y organiza webinars donde explican diversos aspectos relacionados con Elastic Stack.
Si quieres saber más sobre estas herramientas u otras que pueden ayudarte en el procesado de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Para la realización una visualización, es necesario preparar los datos de la forma adecuada realizando una serie de tareas que incluyen el preprocesado y el análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer la realidad de los datos a los que nos enfrentamos. El objetivo es identificar características de los datos y detectar las posibles anomalías o errores que pudieran afectar a la calidad de los resultados. Un tratamiento previo de los datos es esencial para que los análisis o las visualizaciones que se realicen posteriormente sean consistentes y efectivas.
Para favorecer el entendimiento de los lectores no especialistas en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo clik en \"Código\", no está diseñado para su eficiencia sino para su fácil comprensión, por lo que es posible que lectores más avanzados en este lenguaje de programación consideren una forma de codificar algunas funcionalidades de forma alternativa. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en cuenta en Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de RMarkdown. Una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
El paquete base de R, siempre disponible desde que abrimos la consola en RStudio, incorpora un amplio conjunto de funcionalidades para cargar datos de fuentes externas, llevar a cabo análisis estadísticos y obtener representaciones gráficas. No obstante, hay multitud de tareas para las que necesitamos recurrir a paquetes adicionales incorporando al entorno de trabajo las funciones y objetos definidos en ellas. Algunos de ellos ya están instalados en el sistema, pero otros será preciso descargarlos e instalarlos.
#Instalación de paquetes \r\n #El paquete dplyr presenta una colección de funciones para realizar de manera sencilla operaciones de manipulación de datos \r\n if (!requireNamespace(\"dplyr\", quietly = TRUE)) {install.packages(\"dplyr\")}\r\n #El paquete lubridate para el manejo de variables tipo fecha \r\n if (!requireNamespace(\"lubridate\", quietly = TRUE)) {install.packages(\"lubridate\")}\r\n#Carga de paquetes en el entorno de desarrollo \r\nlibrary (dplyr)\r\nlibrary (lubridate)\r\n4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros .CSV y .XLS. Debemos cargar en nuestro entorno de desarrollo todos los ficheros que nos interesan. El siguiente código muestra como ejemplo la carga de un único fichero .CSV en una tabla de datos para que la lectura de este post sea más comprensible.
Para agilizar el proceso de carga en el entorno de desarrollo, es necesario descargar en el directorio de trabajo los conjuntos de datos necesarios para esta visualización, que se encuentran disponibles en la cuenta de Github de datos.gob.es.
#Carga del datasets de demandantes de empleo por municipio de 2020. \r\n Demandantes_empleo_2020 <- \r\n read.csv(\"Conjuntos de datos/Demandantes de empleo por Municipio/Dtes_empleo_por_municipios_2020_csv.csv\",\r\n sep=\";\", skip = 1, header = T)\r\nUna vez que tenemos todos los conjuntos de datos cargados como tablas en el entorno de desarrollo, debemos unificarlos para así tener un único dataset que integre todos los años de la serie temporal, por cada una de las características relacionadas con los demandantes de empleo que se quiere analizar: número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados por el SEPE.
#Dataset de demandantes de empleo\r\nDatos_desempleo <- rbind(Demandantes_empleo_2006, Demandantes_empleo_2007, Demandantes_empleo_2008, Demandantes_empleo_2009, \r\n Demandantes_empleo_2010, Demandantes_empleo_2011,Demandantes_empleo_2012, Demandantes_empleo_2013,\r\n Demandantes_empleo_2014, Demandantes_empleo_2015, Demandantes_empleo_2016, Demandantes_empleo_2017, \r\n Demandantes_empleo_2018, Demandantes_empleo_2019, Demandantes_empleo_2020) \r\n#Dataset de gasto en prestaciones por desempleo\r\ngasto_desempleo <- rbind(gasto_2010, gasto_2011, gasto_2012, gasto_2013, gasto_2014, gasto_2015, gasto_2016, gasto_2017, gasto_2018, gasto_2019, gasto_2020)\r\n#Dataset de nuevos contratos a demandantes de empleo\r\nContratos <- rbind(Contratos_2006, Contratos_2007, Contratos_2008, Contratos_2009,Contratos_2010, Contratos_2011, Contratos_2012, Contratos_2013, \r\n Contratos_2014, Contratos_2015, Contratos_2016, Contratos_2017, Contratos_2018, Contratos_2019, Contratos_2020)b. Selección de variables
Una vez que tenemos las tablas con las tres series temporales (número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados), crearemos una nueva tabla que incluirá las variables que interesan de cada una de ellas.
En primer lugar, agregaremos por provincia las tablas de demandantes de empleo (“datos_desempleo”) y contratos nuevos contratos registrados (“contratos”) para facilitar la visualización y que coincidan con la desagregación por provincia de la tabla de gasto en prestaciones por desempleo (“gasto_desempleo”). En este paso, seleccionamos únicamente las variables que interesen de los tres conjuntos de datos.
#Realizamos un group by al dataset de \"datos_desempleo\", agruparemos las variables numéricas que nos interesen, en función de varias variables categóricas\r\nDtes_empleo_provincia <- Datos_desempleo %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(total.Dtes.Empleo = (sum(total.Dtes.Empleo)), Dtes.hombre.25 = (sum(Dtes.Empleo.hombre.edad...25)), \r\n Dtes.hombre.25.45 = (sum(Dtes.Empleo.hombre.edad.25..45)), Dtes.hombre.45 = (sum(Dtes.Empleo.hombre.edad...45)),\r\n Dtes.mujer.25 = (sum(Dtes.Empleo.mujer.edad...25)), Dtes.mujer.25.45 = (sum(Dtes.Empleo.mujer.edad.25..45)),\r\n Dtes.mujer.45 = (sum(Dtes.Empleo.mujer.edad...45)))\r\n#Realizamos un group by al dataset de \"contratos\", agruparemos las variables numericas que nos interesen en función de las varibles categóricas.\r\nContratos_provincia <- Contratos %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(Total.Contratos = (sum(Total.Contratos)),\r\n Contratos.iniciales.indefinidos.hombres = (sum(Contratos.iniciales.indefinidos.hombres)), \r\n Contratos.iniciales.temporales.hombres = (sum(Contratos.iniciales.temporales.hombres)), \r\n Contratos.iniciales.indefinidos.mujeres = (sum(Contratos.iniciales.indefinidos.mujeres)), \r\n Contratos.iniciales.temporales.mujeres = (sum(Contratos.iniciales.temporales.mujeres)))\r\n#Seleccionamos las variables que nos interesen del dataset de \"gasto_desempleo\"\r\ngasto_desempleo_nuevo <- gasto_desempleo %>% select(Código.mes, Comunidad.Autónoma, Provincia, Gasto.Total.Prestación, Gasto.Prestación.Contributiva)En segundo lugar, procedemos a unir las tres tablas en una que será con la que trabajemos a partir de este punto.
Caract_Dtes_empleo <- Reduce(merge, list(Dtes_empleo_provincia, gasto_desempleo_nuevo, Contratos_provincia))
c. Transformación de variables
Una vez tengamos la tabla con las variables de interés para el análisis y la visualización, debemos transformar algunas de ellas a otros tipos más adecuados para futuras agregaciones.
#Transformación de una variable fecha\r\nCaract_Dtes_empleo$Código.mes <- as.factor(Caract_Dtes_empleo$Código.mes)\r\nCaract_Dtes_empleo$Código.mes <- parse_date_time(Caract_Dtes_empleo$Código.mes(c(\"200601\", \"ym\")), truncated = 3)\r\n#Transformamos a variable numérica\r\nCaract_Dtes_empleo$Gasto.Total.Prestación <- as.numeric(Caract_Dtes_empleo$Gasto.Total.Prestación)\r\nCaract_Dtes_empleo$Gasto.Prestación.Contributiva <- as.numeric(Caract_Dtes_empleo$Gasto.Prestación.Contributiva)\r\n#Transformación a variable factor\r\nCaract_Dtes_empleo$Provincia <- as.factor(Caract_Dtes_empleo$Provincia)\r\nCaract_Dtes_empleo$Comunidad.Autónoma <- as.factor(Caract_Dtes_empleo$Comunidad.Autónoma)d. Análisis exploratorio
Veamos qué variables y estructura presenta el nuevo conjunto de datos.
str(Caract_Dtes_empleo)\r\nsummary(Caract_Dtes_empleo)La salida de esta porción de código se omite para facilitar la lectura. Las características principales que presenta el conjunto de datos son:
- El rango temporal abarca desde enero de 2010 hasta diciembre de 2020.
- El número de columnas (variables) es de 17.
- Presenta dos variables categóricas (“Provincia” y “Comunidad.Autónoma”), una variable tipo fecha (“Código.mes”) y el resto son variables numéricas.
e. Detección y tratamiento de datos perdidos
Seguidamente analizaremos si el dataset presenta valores perdidos (NAs). El tratamiento o la eliminación de los NAs es esencial, ya que si no es así no será posible procesar adecuadamente las variables numéricas.
any(is.na(Caract_Dtes_empleo)) \r\n#Como el resultado es \"TRUE\", eliminamos los datos perdidos del dataset, ya que no sabemos cual es la razón por la cual no se encuentran esos datos\r\nCaract_Dtes_empleo <- na.omit(Caract_Dtes_empleo)\r\nany(is.na(Caract_Dtes_empleo))4.3. Creación de nuevas variables
Para realizar la visualización, vamos a crear una nueva variable a partir de dos variables que se encuentran en la tabla de datos. Esta acción es muy común en el análisis de datos ya que en ocasiones interesa trabajar con datos calculados (por ejemplo, la suma o la media de diferentes variables) en lugar de los datos de origen. En este caso vamos a calcular el gasto medio en prestaciones por desempleo para cada demandante de empleo. Para ello utilizaremos las variables de gasto total por prestación (“Gasto.Total.Prestación”) y el total de demandantes de empleo (“total.Dtes.Empleo”).
Caract_Dtes_empleo$gasto_desempleado <-\r\n (1000 * (Caract_Dtes_empleo$Gasto.Total.Prestación/\r\n Caract_Dtes_empleo$total.Dtes.Empleo))4.4. Guardar el dataset
Una vez que tenemos la tabla con las variables que nos interesan para los análisis y las visualizaciones, la guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos. Es importante utilizar la codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta.
write.csv(Caract_Dtes_empleo,\r\n file=\"Caract_Dtes_empleo_UTF8.csv\",\r\n fileEncoding= \"UTF-8\")5. Creación de la visualización sobre la caracterización de la demanda de empleo en España usando Kibana
El desarrollo de esta visualización interactiva se ha realizado usando Kibana en nuestro entorno local. Tanto para la descarga del software, como para la instalación del mismo, hemos recurrido al tutorial realizado por la propia compañía, Elastic.
A continuación se adjunta un vídeo tutorial donde se muestra todo el proceso de realización de la visualización. En el vídeo podrás ver la creación de un cuadro de mando (dashboard) con diferentes indicadores interactivos mediante la generación de representaciones gráficas de diferentes tipos. Los pasos para obtener el dashboard son los siguientes:
- Cargamos los datos en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos en los archivos cargados, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
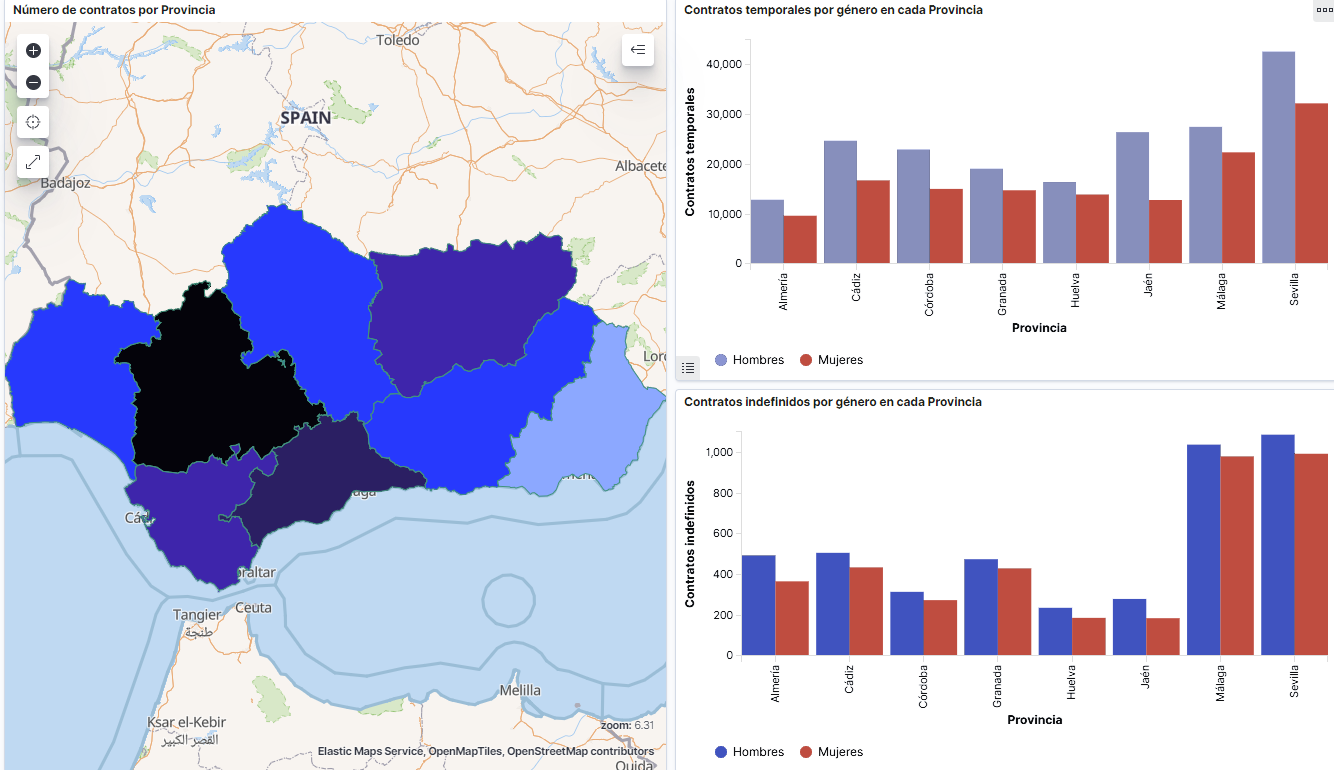
- Gráfico de líneas para representar la serie temporal sobre los demandantes de empleo en España desde 2006 hasta 2020.
- Gráfico de sectores de los demandantes de empleo desagregados por Provincia y Comunidad Autónoma.
- Mapa temático, mostrando el número de contratos nuevos registrados en cada Provincia del territorio. Para la creación de este visual es necesaria la descarga de un dataset de la georeferenciación de las Provincias publicado en el portal de datos abiertos Open Data Soft.
- Construcción del dashboard.
Seguidamente mostraremos un vídeo tutorial interactuando con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre el perfil de los demandantes de empleo en España en el periodo 2010 hasta 2020, se pueden obtener, entre otras, las siguientes conclusiones:
- Existen dos incrementos significativos en el número de demandantes de empleo. El primero aproximadamente en 2010, que coincide con la crisis económica. El segundo, mucho más pronunciado en 2020, que coincide con la crisis derivada de la pandemia.
- Se observa que existe una brecha de género en el colectivo de demandantes de empleo: el número de mujeres demandantes de empleo es mayor a lo largo de toda la serie temporal, principalmente en los grupos de edad de mayores de 25.
- A nivel regional, Andalucía, seguida de Cataluña y Comunidad Valenciana, son las Comunidades Autónomas con mayor número de demandantes de empleo. En contraste, Andalucía, es la Comunidad Autónoma con menor gasto por desempleo, mientras que Cataluña, es la que presenta mayor gasto por desempleo.
- Los contratos de tipo temporal son los prioritarios y las provincias que generan mayor número de contratos son Madrid y Barcelona, que coinciden con las provincias con mayor número de habitantes, mientras que en el lado opuesto, las provincias que menos número de contratos realizan son Soria, Ávila, Teruel o Cuenca, que coincide con las zonas más despobladas de España.
Esta visualización nos ha ayudado a sintetizar gran cantidad de información y darle sentido pudiendo obtener unas conclusiones y si fuera necesario tomar decisiones en función de los resultados. Esperemos que os haya gustado este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!
Aplicación
Infomedusa es una aplicación móvil que muestra a los usuarios información actualizada acerca de medusas en la costa. Además de la información sobre la presencia de estos invertebrados, incluye datos sobre su cantidad, variedad y peligrosidad, para poder evitar así las molestas picaduras.
Cuenta con un chat público en el que los usuarios pueden colaborar en la recopilación de información aportando las incidencias que observen en la playa en la que se encuentren.
La aplicación también ofrece información sobre la disponibilidad de servicios, incidencias en las playas, información sobre seguridad sanitaria respecto al COVID-19 en la costa o datos meteorológicos, como por ejemplo:
- Temperatura
- Dirección y velocidad del viento
- Estado del mar
- Radiación solar
- Estado del cielo
Noticia
La Sociedad Española de Documentación e Información Científica (SEDIC) dedica el número 7 de su revista Documentos de trabajo al data sharing, con el monográfico titulado "Data sharing: qué son y cómo se pueden compartir los datos de investigación. Manual de recomendación para gestores de la información".
Se trata de una guía elaborada por Andrea Sixto-Costoya, Rafael Aleixandre-Benavent, Antonio Vidal Infer, Rut Lucas Domínguez y Lourdes Castellón Cogollos; donde los autores analizan, desde una perspectiva amplía, diversos aspectos relacionados con los datos de investigación y su uso compartido.
En concreto, el manual recopila algunas de las principales iniciativas institucionales en el ámbito del data sharing a nivel mundial y en el contexto de la Unión Europea; describe las infraestructuras necesarias y analiza los aspectos más técnicos relacionados con formatos y protocolos; muestra las diferentes tecnologías disponibles, así como las características de los datos de investigación y de los planes de gestión de los datos; y reflexiona sobre el papel de las revistas científicas. El monográfico también recoge las principales ventajas y las perspectivas de futuro en el ámbito del data sharing.
En este post resumimos algunas de los aportes principales de este trabajo.
¿Qué es el “data sharing”?
El “data sharing” o el uso compartido de datos es la acción de compartir con el resto de la comunidad científica el material sin procesar (los datos brutos de la investigación) generado durante el curso de la investigación que sirve para extraer y validar resultados. Como se indica en el documento, actualmente el data sharing se engloba dentro de la filosofía de acceso abierto (open access), entendiéndose el compartir datos como una práctica que favorece que la ciencia sea más abierta y accesible. Desde esta perspectiva del acceso abierto, el data sharing promueve que los datos sin procesar puedan tener una “segunda vida” y se puedan utilizar más allá del fin para el que fueron generados en un principio. Estos usos pueden ir desde la reutilización de los datos para producir nuevos estudios, a servir como verificadores de resultados de investigación.
Para poder ser compartidos en todo su potencial los datos de investigación tienen que cumplir cuatro condiciones conocidas como Principios FAIR: Findable, Accessible, Interoperable, Reusable (Encontrables, Accesibles, Interoperables y Reutilizables).

Los Principios FAIR cuyo lema es “tan abiertos como sea posible, tan cerrados como sea necesario” no implican que todos los datos deban tener el mismo nivel de apertura; ni que todos los datos, de todas las disciplinas científicas sigan las mismas reglas. Lo que aportan estos principios es más bien un cambio de paradigma, que persigue el objetivo de que los datos estén abiertos por defecto, en vez de cerrados, como venía sucediendo hasta ahora.
Políticas sobre datos abiertos en el ámbito de la investigación científica
A nivel internacional, los autores destacan una serie de iniciativas institucionales implementadas en Australia, EEUU, América Latina y Canadá, indicando que éstas sirven como referencia para mostrar las tendencias de uso compartido de datos de investigación a nivel mundial. El Australian National Data Service; el Repositorio Nacional Digital de Ciencia, Tecnología e Innovación en Perú o el Canadian Institutes of Health Research, son algunas de las iniciativas más destacables.
En cuanto a la Unión Europea, su postura sobre el uso compartido de datos es clara: se defiende y se promueve, aunque no es un mandato obligatorio. Para el análisis de las iniciativas a nivel comunitario los autores han tomado como referencia las bases que estipula la Comisión para los proyectos Horizon 2020 (H2020), ya que es en ellos donde la UE engloba la mayoría de su actividad investigadora.
En la UE las directrices sobre el uso compartido de datos en investigación siguen la misma tendencia que sobre el acceso abierto en general, es decir, debe hacerse por sistema y por defecto, ya que no debería ser necesario pagar por la información financiada con fondos públicos cada vez que se accede o se utiliza la misma. En el caso de las publicaciones finales de los artículos, esto significa que debe hacerse siempre por alguna de las dos opciones disponibles, que son la vía verde o dorada, y solo en el caso de los estudios que implican patentes pueden guardarse el derecho de no publicar en abierto.
En cuanto a la situación por países del ámbito comunitario el monográfico, siguiendo el informe “An Analysis of Open Science Policies in Europe” publicado en 2019 por SPARC Europe y el Digital Curation Center (DCC) indica que 14 de 28 países tienen políticas vigentes relacionadas con los datos abiertos de investigación. Además, destaca la Directiva (UE) 2019/1024 del Parlamento Europeo y del Consejo de 20 de junio de 2019, relativa a los datos abiertos y la reutilización de la información del sector público, como una herramienta clave para promover el acceso abierto a los datos, no solo de investigación, sino también los datos generados por sectores empresariales o gubernamentales.
Finalmente en cuanto a España, sería el Plan Estatal de Investigación Científica y Tecnológica y de Innovación 2017-2020 donde se articula la política de datos abiertos en el ámbito de la investigación.
Los autores afirman que “el acercamiento de España con respecto al uso compartido de datos en ciencia es todavía tímido y algo ambiguo” sin embargo el camino estaría trazado de forma positiva. El Plan Estatal recoge claramente el objetivo de impulsar el acceso a datos de investigación, pero considera como optativo incluir un plan de gestión de los datos en los proyectos de I+D+i financiados con fondos públicos. Al mismo tiempo se señala que cuando los datos sean compartidos, se tendrá en cuenta para la evaluación curricular de los investigadores.
El siguiente cuadro recopila las iniciativas públicas internacionales identificadas en el manual.
| Poltíticas sobre datos abiertos: Internacional, UE y España | |
|---|---|
| Australia | |
| América Latina |
|
| Canadá | |
| Estados Unidos | |
| Unión Europea | |
| España | |
Tecnologías para compartir datos.
Las tecnologías para compartir datos incluyen toda la infraestructura digital necesaria para subir, almacenar, preservar, buscar y descargar datos de investigación. Dentro de las infraestructuras, los repositorios de datos y las plataformas de las editoriales son actualmente la máxima referencia en cuanto a datos de investigación compartidos. El informe analiza las características de ambos tipos de infraestructuras y ofrece ejemplos que sintetizamos a continuación:
| Repositorios de datos para la investigación científica | |
|---|---|
| Temáticos |
|
| Multidisciplinares | |
| Institucionales | |
| Buscadores | |
El papel de las revistas científicas en el uso compartidos de datos
Al igual que sucede con el acceso abierto a las publicaciones, los autores señalas que en los últimos años algunas revistas y editoriales han tomado conciencia y han desarrollado políticas y directrices sobre el uso compartido de datos que normalmente se plasman en las “Author guidelines”. Dentro de las revistas y de las editoriales que apuestan por el uso compartido de datos, se distinguen dos grupos: las que sugieren y las que obligan a su uso. Además existirían tres modalidades para indicar a los autores (bien por obligación, o por recomendación) como compartir sus datos:
- El primer nivel, que no implican ni obligación ni exigencia, permite al autor poner una indicación de que los datos pueden ser solicitados al autor o autores, normalmente indicando alguna forma de contacto, y éstos los facilitarán si lo consideran oportuno.
- El segundo nivel, que implica más apertura de los datos, es el que ofrece la posibilidad de que vayan adjuntos como material suplementario al artículo. En este caso, la revista puede optar porque este sea un requisito o no. En caso de que lo sea, los autores deben subir un adjunto donde se encuentren los datos brutos que sustentan los resultados del trabajo, lo que es muy positivo ya que se permite tanto la verificación como la reutilización. Esta modalidad hace que las revistas y las editoriales puedan ejercer de plataformas digitales en las que se almacenan los datos, ya que, junto con el pdf del artículo, estarían adjuntos los datos.
- El tercer nivel, es en el que los datos están más abiertos. La revista obliga o da la posibilidad de subir los datos a un repositorio de datos como los que se han visto en el apartado referente a repositorios. De esta forma, los datos estarían guardados con una modalidad que ofrece muchas más garantías tanto de preservación como de accesibilidad. Dependiendo de las revistas y de las editoriales a las que pertenecen, pueden variar sobre todo dos cuestiones. La primera es si se trata de una obligación o de una recomendación. La segunda, el tipo de instrucciones que se detallen, por ejemplo, si se da libertad al autor para que escoja el repositorio o si la revista ya tiene una lista cerrada de repositorios para elegir.
¿Por qué compartir datos de la investigación científica?
Los autores del manual siguen en este punto a la Red Española sobre Datos de Investigación en Abierto quien señala los principales puntos a favor de la práctica de compartir datos en el ámbito de la investigación y que pueden resumirse en los siguientes:
- Incrementa la transparencia y la credibilidad de los estudios
- Se puede comprobar la validez de los resultados.
- Permite replicar y verificar
- Fomenta la participación y la colaboración.
- Reduce costes y tiempo.
- Permite descubrimientos múltiples
- En el caso de investigaciones con animales, permite ahorrar el sufrimiento y la pérdida innecesaria de vidas.
- En el caso de las investigaciones con humanos ayudar a evitar duplicidades en estudios que, en ocasiones, son muy invasivos e incómodos para los sujetos que forman parte de la muestra.
- Incrementa la visibilidad.
Conclusiones
Los autores concluyen el monográfico señalando que es importante visibilizar y promover que el compartir datos es una práctica que puede y debe adaptarse a las necesidades y peculiaridades de los investigadores, grupos y disciplinas.
Las entidades financiadoras y las instituciones que se encargan de evaluar la ciencia tienen un papel fundamental en cuanto a la gestión de incentivos para favorecer esta práctica entre el personal investigador. En este sentido, es muy importante que se sigan desarrollando métricas que sirvan para la evaluación de las publicaciones y reutilización de datos y, sobre todo, incluir los datos abiertos en los indicadores de evaluación de la actividad científica. Resultaría más eficaz pedir a los investigadores que compartan sus datos si la petición viene acompañada tanto de este tipo de incentivos, como de ayuda material, económica y humana para hacerlo.
Finalmente, desde el punto de vista de los documentalistas y profesionales de la información, el data sharing constituye un terreno de trabajo que está en una coyuntura muy favorable y con un amplio potencial, que podría brindar oportunidades comparables a las que el acceso abierto brindó a las bibliotecas universitarias.
Noticia
Vivimos en un mundo conectado, donde todos llevamos encima un dispositivo móvil que nos permite capturar nuestro entorno y compartirlo con quien deseemos a través de redes sociales o distintas herramientas. Esto nos permite mantener el contacto con nuestros seres queridos aunque estemos a miles de kilómetros de distancia, pero… ¿Y si aprovecháramos también esta circunstancia para enriquecer las investigaciones científicas? Estaríamos hablando de lo que se conoce como ciencia ciudadana.
La ciencia ciudadana busca “involucrar al público general en actividades científicas y fomentar la contribución activa de los ciudadanos a la investigación a través de su esfuerzo intelectual, su conocimiento general, o sus herramientas y recursos”. Esta definición está extraída del Libro verde de la ciencia ciudadana, elaborado en el marco del proyecto europeo Socientize (7PM), y nos muestra algunas de las claves de la ciencia ciudadana. En concreto, la ciencia ciudadana es:
-
Participativa: Ciudadanos de todo tipo pueden colaborar de distintas maneras, a través de la recogida de información, o poniendo a disposición de la investigación su experiencia y conocimiento. Esta mezcla de perfiles genera una atmosfera perfecta para la innovación y los nuevos descubrimientos.
-
Voluntaria: Dado que la participación suele ser altruista, los proyectos de ciencia ciudadana necesitan estar alineados con las demandas e intereses de la sociedad. Por ello son habituales los proyectos que despierten la conciencia social de los ciudadanos (por ejemplo, aquellos relacionados con el ecologismo).
-
Eficiente: Gracias a los avances tecnológicos que mencionábamos al principio, se pueden capturar muestras del entorno con mayor ubicuidad e inmediatez. Además, se facilita la interconexión, y con ello la cooperación, de empresas, investigadores y sociedad civil. Todo ello repercute en una reducción de costes y unos resultados más ágiles.
-
Abierta: Los datos, metadatos y publicaciones que se generan durante la investigación se publican en formatos abiertos y accesibles. Este hecho hace que sea más sencillo reutilizar la información y repetir investigaciones para garantizar su veracidad y solidez.
En definitiva, con este tipo de iniciativas se busca generar una ciencia más democrática, que responda a los intereses de todos los implicados, pero sobre todo de los ciudadanos. Y que genere información que se pueda reutilizar en pro de la sociedad. Veámoslo con algunos ejemplos:
-
Mosquito Alert: Este proyecto busca luchar contra el mosquito tigre y el mosquito de la fiebre amarilla, especies transmisoras de enfermedades como el Zika, el Dengue o el Chikungunya. En este caso, la participación ciudadana consiste en enviar fotografías de insectos observados en el entorno y que son susceptibles de pertenecer a estas especies. Un equipo de profesionales analiza las imágenes para validar los hallazgos. Los datos generados permiten monitorizar y realizar predicciones sobre su comportamiento, lo cual ayuda a controlar su expansión. Toda esta información se comparten de manera abierta a través de GBIF España.
-
Apadrina una roca: Con el objetivo de favorecer la conservación del patrimonio geológico español, los participantes en este proyecto se comprometen a visitar, al menos una vez al año, el lugar de interés geológico que han apadrinado. Tendrán que avisar de cualquier actuación o amenaza que observe (anomalías, agresiones, expolio de minerales o fósiles…). La información ayudará a enriquecer el Inventario Español de Lugares de Interés Geológico.
-
RitmeNatura.cat: El proyecto consiste en seguir los cambios estacionales en las plantas y los animales: cuándo se produce la floración, si aparecen nuevos insectos, si hay cambios en la migración de las aves... El objetivo es controlar los efectos del cambio climático. Los resultados se pueden descargar en este enlace.
-
Identificación de asteroides cercanos a la tierra: Los participantes en el proyecto ayudaran a identificar asteroides utilizando imágenes astronómicas. El Minor Planet Center (organismo de la Unión Astronómica Internacional encargada de los cuerpos menores del Sistema Solar) evaluará los datos para mejorar las órbitas de dichos objetos y estimar de manera más precisa la probabilidad de un posible impacto con la Tierra. Puedes ver algunos de los resultados aquí.
-
Arturo: Un área donde la ciencia ciudadana puede aportar grandes ventajas es en el entrenamiento de inteligencias artificiales. Es el caso de Arturo, un algoritmo de aprendizaje automatico diseñado para determinar cuáles son las condiciones urbanísticas más óptimas. Para ello, los colaboradores deberán contestar a un cuestionario donde escogerán las imágenes que mejor se ajusta a su concepto de un entorno habitable. El objetivo es ayudar a técnicos y administraciones a generar entornos alineados con las necesidades de los ciudadanos. Los datos generados y el modelo utilizado se pueden descargar en el siguiente enlace.
Si estás interesado en conocer más proyectos de este tipo puedes visitar la web Ciencia Ciudadana en España cuyo objetivo es aumentar el conocimiento y visión sobre la ciencia ciudadana. En ella participan el Ministerio de Ciencia, Innovación y Universidades, la Fundación Española para la ciencia y la Tecnología y la Fundación Ibercivis. Un vistazo rápido a la sección de proyectos te permitirá conocer qué tipo de actividades se están llevando a cabo. Quizás encuentres alguna de tu interés...
Empresa reutilizadora
portalestadistico.com integra y difunde estadísticas oficiales de múltiples fuentes para cada uno de los territorios que conforman España. La difusión se realiza de forma interactiva a través de cuadros de mando y herramientas de análisis visual de datos, promoviendo así la reutilización de la información pública y haciendo que los datos multipliquen sus posibilidades.
En definitiva, ayudan a las administraciones locales a ser más eficientes y transparentes difundiendo en abierto datos inteligentes de sus territorios.
Noticia
Los datos abiertos, al igual que han contribuido en otros campos, como la sanidad, el turismo o el emprendimiento, pueden ser una herramienta muy útil para ayudar a conseguir la igualdad de género. Pero antes es necesario superar una serie de retos, entre los que destacan:
-
La existencia de una brecha de género en los datos: los datos desagregados por sexo permiten entender si existen desigualdades entre las personas de distinto género y tomar decisiones que puedan ayudar a reducir dichas desigualdades. Sin embargo, todavía hay importantes carencias en este tipo de datos.
-
La poca presencia de mujeres en el ecosistema de los datos abiertos: Al igual que pasa en otros sectores tecnológicos, la cantidad de mujeres que forma parte del ecosistema de los datos abiertos es menor que la de hombres. Esto hace que su visión y sus preocupaciones queden a veces fuera de la mesa de debate. Como ejemplo, The Feminist Open Government Initiative, creada para alentar a los gobiernos y la sociedad civil a defender los avances de género en un contexto de gobierno abierto, pero que está gestionado principalmente por integrantes del género masculino.
Para solucionar estos retos, se han creado diversos grupos de mujeres, como Open Heroine, integrado por más de 400 mujeres a nivel mundial que trabajan en los campos de gobierno abierto, datos abiertos y tecnología cívica. Se trata de un espacio virtual donde las mujeres pueden compartir sus experiencias y reflexionar sobre los desafíos que afrontan, así como impulsar una mayor presencia de mujeres en los grupos de debate sobre datos abiertos. Esta asociación fue la responsable de uno de los pre-eventos celebrado en el marco de la última Conferencia Internacional de Datos Abiertos. A través de un formato “do-a-thon” crearon grupos de trabajo para tratar de dar solución, a través del uso de los datos, a retos como la prevención de feminicidios o la brecha de género en los datos en la ciudad de Buenos Aires.
En España, también se está tratando de impulsar la presencia de las mujeres en estos campos, aunque de manera más general. Por ejemplo, el proyecto “Quiero ser ingeniera”, de la Universidad de Granada, busca impulsar la presencia femenina en las carreras relacionadas con las STEM (Ciencia, Tecnología, Ingeniería y Matemáticas). Para ello se realizan visitas a centros de Educación secundaria, y se celebra una Feria de la Ingeniería y un campus de verano. Hay que tener en cuenta que de acuerdo con los datos del Ministerio de Educación aunque las mujeres representan un 54% de la población universitaria española, solo suponen el 10% del alumnado en las carreras TIC.
Otro ejemplo es el espacio “Mujeres y datos abiertos”, de la Iniciativa Barcelona Open Data, donde se muestran visualizaciones fruto de 3 eventos organizados por esta organización para explorar fuentes de datos abiertos y solucionar retos sociales relacionados con las mujeres: Datos X Mujeres, Wiki-Data-Thon e Índice Pobreza mujeres y precariedad. Estas visualizaciones permiten ver las diferencias de género en ámbitos como los cuidados en el hogar o el callejero de grandes ciudades como Barcelona. Además impulsan la creación de soluciones digitales que permitan dar una respuesta a estas diferencias.
Las mujeres son el 50% de la sociedad y como tal deberían estar representadas en todos los ámbitos. Aunque su presencia es cada mayor en la comunidad de datos abiertos (como mostró el Encuentro Aporta), todavía queda trabajo por hacer: son necesario más datos de género y más espacios donde analizar y tratar de resolver los retos que las mujeres tienen por delante utilizando datos abiertos.