Evento
Solo unos meses después del éxito de su primera entrega, el Ayuntamiento de Madrid ha abierto la convocatoria de la segunda edición de los Premios a la Reutilización de Datos Abiertos. Se trata de una iniciativa que busca reconocer y promover proyectos innovadores que utilicen los conjuntos de datos publicados en el portal datos.madrid.es. Con una dotación total de 15.000 euros, estos premios consolidan el compromiso municipal con la cultura del dato, la transparencia y la creación de valor social y económico a partir de la información pública.
En este artículo te contamos algunas de las claves que debes tener en cuenta para participar.
Dos categorías de premios a considerar
La convocatoria establece dos categorías, cada una con varios premios:
1) Servicios web, aplicaciones y visualizaciones: premia proyectos que generen servicios, visualizaciones o aplicaciones web o para dispositivos móviles.
- Primer premio: 4.000 €
- Segundo premio: 3.000 €
- Tercer premio: 1.500 €
- Premio para estudiante: 1.500 €
2) Estudios, investigaciones e ideas: se centra en proyectos de investigación, análisis o descripción de ideas para crear servicios, estudios, visualizaciones, aplicaciones web o móviles. En esta categoría también pueden participar trabajos universitarios de fin de grado y de fin de máster (TFG-TFM).
- Primer premio: 2.500 €
- Segundo premio: 1.500 €
- Tercer premio: 1.000 €
En ambas categorías es necesario que se utilice al menos un conjunto de datos del portal municipal, pudiendo combinarse con fuentes públicas o privadas de cualquier ámbito territorial. Los proyectos pueden ser recientes o haber finalizado en los dos años previos al cierre de la convocatoria.
Los premios pueden declararse desiertos si no se alcanza la calidad mínima. En ese caso, los importes sobrantes se redistribuirán proporcionalmente entre el resto de premiados.
Requisitos para participar
La convocatoria está abierta a personas físicas y jurídicas autoras de los proyectos o iniciativas. El objetivo es que cualquier persona o entidad con interés en la reutilización de datos pueda presentar su propuesta, independientemente de su nivel técnico. Por ello, pueden participar tanto profesionales y empresas, personas investigadoras, periodistas y desarrolladores, como aficionados y amateurs interesados en el análisis y visualización de datos.
En el caso del premio para estudiante, solo podrán participar aquellas personas físicas matriculadas en cursos oficiales 2023/24, 2024/25 o 2025/26.
Por el contrario, quedan excluidos de todas las categorías:
- Proyectos ya premiados, subvencionados o contratados por el Ayuntamiento de Madrid.
- Proyectos que no utilicen ningún conjunto de datos del portal municipal.
Fases del proceso
En el portal municipal se detallan las fases de la convocatoria, que incluyen:
- Publicación de la convocatoria. El pasado 3 de marzo se publicaron las bases reguladoras en el Boletín Oficial del Ayuntamiento de Madrid.
- Presentación de candidaturas. El plazo para presentar las solicitudes abarca del 4 de marzo al 4 de mayo (ambos incluidos). Se pueden presentar online o presencialmente, como se explica más adelante.
-
Análisis y subsanación. Hasta el 3 de junio, se llevará a cabo la revisión de la documentación presentada. En caso necesario, se contactará con los solicitantes para la subsanación de errores.
-
Valoración y deliberación. Un jurado evaluará todos los proyectos admitidos, según los criterios establecidos en las bases de la convocatoria. Se tendrá en cuenta su utilidad, valor económico, valor social y contribución a la transparencia; su grado de innovación y creatividad; la variedad de conjuntos de datos utilizados del Portal de Datos Abiertos de Madrid; y su calidad técnica. Esta fase se extenderá hasta el 15 septiembre.
-
Resolución. En los meses de septiembre y octubre se llevará a cabo la propuesta de concesión y publicación oficial de la resolución.
-
Entrega de premios. Los galardones se entregarán en un acto público, estimado para el mes de noviembre.
La página oficial irá actualizando fechas y documentación a medida que avance el proceso.
Cómo se presentan las candidaturas
Como se mencionó anteriormente, las candidaturas se pueden presentar de manera telemática o presencial:
- En línea, a través de la sede electrónica del Ayuntamiento de Madrid. Para ello se requiere identificación y firma electrónica.
- Presencialmente, en las oficinas de asistencia en materia de registro del Ayuntamiento de Madrid, así como en los registros de otras administraciones públicas.
Las personas físicas podrán presentar la solicitud de ambas formas, mientras que las personas jurídicas solo podrán presentar la solicitud de forma telemática.
En ambos casos, las candidaturas deben incluir:
- Formulario oficial de solicitud, a descargar en la sede electrónica del Ayuntamiento de Madrid.
- Memoria del proyecto, en base a un modelo a descargar en la citada sede electrónica. Este documento incluirá el título, la autoría y una descripción detallada, así como la relación de conjuntos de datos utilizados, los objetivos, el público beneficiario, el impacto previsto, el grado de innovación y la tecnología empleada.
- Declaración responsable.
- Acuerdo de colaboración, en caso de presentarse como agrupación.
Inspírate con los proyectos ganadores de la primera edición
La segunda edición de los Premios a la Reutilización de Datos Abiertos llega precedida por el éxito de la convocatoria anterior. En 2025, el Ayuntamiento de Madrid celebró la primera edición de estos galardones, que reunió 65 candidaturas de gran calidad y diversidad. Entre ellas destacaron propuestas impulsadas por estudiantes universitarios, startups, equipos multidisciplinares y ciudadanía comprometida con el uso inteligente de los datos públicos.
Los proyectos premiados demostraron que los datos abiertos pueden convertirse en herramientas reales para mejorar la vida urbana, impulsar la transparencia y generar conocimiento útil para la ciudad. En este artículo te resumimos en qué consistían estos proyectos.
En resumen, los II Premios a la Reutilización de Datos Abiertos 2026 son una oportunidad para demostrar cómo los datos públicos pueden convertirse en innovación real. Una invitación a desarrollar proyectos que impulsen un Madrid más inteligente, transparente y participativo.
Aplicación
Esta visualización de datos interactiva busca poder consultar y comparar en detalle las partidas presupuestarias de 2025 por habitante y su desglose para las entidades locales de España, es decir los Ayuntamientos.
Son datos de presupuestos, las liquidaciones de la ejecución de los mismos se publicarán a finales de 2026.
Blog
La visualización de datos no es una disciplina reciente. Desde hace siglos, las personas han utilizado gráficos, mapas y esquemas para representar información compleja. Ejemplos clásicos como los mapas estadísticos del siglo XIX o los gráficos utilizados en la prensa muestran que la necesidad de “ver” los datos para entenderlos ha existido siempre.
Durante mucho tiempo, la creación de visualizaciones requería conocimientos especializados y acceso a herramientas profesionales, lo que limitaba su producción a perfiles muy concretos. Sin embargo, la revolución digital y tecnológica ha transformado profundamente este panorama. En la actualidad, cualquier persona con acceso a un ordenador y a datos puede crear visualizaciones. Las herramientas se han democratizado, muchas de ellas son gratuitas o de código abierto, y el trabajo de visualización se ha extendido más allá del diseño para integrarse en ámbitos como la estadística, la ciencia de datos, la investigación académica, la administración pública o la educación.
Hoy en día, la visualización de datos es una competencia transversal que permite a la ciudadanía explorar información pública, a las instituciones comunicar mejor sus políticas y a los reutilizadores generar nuevos servicios y conocimientos a partir de los datos abiertos. En este post presentamos algunas de las opciones más accesibles y utilizadas en visualización de datos.
Un ecosistema amplio y diverso de herramientas
El ecosistema de herramientas de visualización de datos es amplio y diverso, tanto en funcionalidades como en niveles de complejidad. Existen opciones pensadas para una primera exploración de los datos, otras orientadas al análisis en profundidad y algunas diseñadas para crear visualizaciones interactivas o narrativas digitales complejas.
Esta variedad permite adaptar la visualización a distintos contextos y objetivos: desde comprender un conjunto de datos de forma preliminar hasta publicar gráficos interactivos, paneles de control o mapas en la web.
La encuesta anual de la Data Visualization Society refleja esta diversidad y muestra cómo el uso de determinadas herramientas evoluciona con el tiempo, consolidando algunas opciones ampliamente conocidas y dando paso a nuevas soluciones que responden a necesidades emergentes. Estas son algunas de las herramientas que se mencionan en la encuesta, ordenadas según perfiles de uso.
Para la elaboración de este listado se ha tenido en cuenta los siguientes criterios:
- Grado de uso y madurez de la herramienta.
- Acceso libre, gratuito o con versiones abiertas.
- Utilidad para proyectos relacionados con datos públicos.
- Prioridad a herramientas abiertas o con versiones gratuitas.
Herramientas sencillas para empezar
Estas herramientas se caracterizan por contar con interfaces visuales, una curva de aprendizaje baja y la posibilidad de crear gráficos básicos de forma rápida. Son especialmente útiles para comenzar a explorar conjuntos de datos abiertos o para actividades de divulgación.
- Excel: es una de las herramientas más extendidas y conocidas. Permite realizar gráficos básicos y primeras exploraciones de datos de forma sencilla. Aunque no está diseñada específicamente para la visualización avanzada, sigue siendo una puerta de entrada habitual al trabajo con datos y su representación gráfica.
- Google Sheets: funciona como una alternativa gratuita y colaborativa a Excel. Su principal ventaja es la posibilidad de trabajar de forma compartida y publicar gráficos sencillos en línea, lo que facilita la difusión de visualizaciones básicas.
- Datawrapper: muy utilizada en comunicación pública y periodismo de datos. Permite crear gráficos claros, mapas y tablas interactivas sin necesidad de conocimientos técnicos. Es especialmente adecuada para explicar datos de forma comprensible a un público amplio.
- RAWGraphs: herramienta de software libre orientada a la exploración visual. Permite experimentar con tipos de gráficos menos habituales y descubrir nuevas formas de representar datos. Resulta especialmente útil en fases exploratorias.
- Canva: aunque su enfoque es más divulgativo que analítico, puede ser útil para crear piezas visuales sencillas que integren gráficos básicos con elementos de diseño. Es adecuada para la comunicación visual de resultados, no tanto para el análisis de datos.
Herramientas de análisis y exploración de datos
Este grupo de herramientas está orientado a perfiles que desean ir más allá de los gráficos básicos y realizar análisis más estructurados. Muchas de ellas son abiertas y están ampliamente consolidadas en el ámbito del análisis de datos.
- R: lenguaje de programación libre muy utilizado en estadística y análisis de datos. Dispone de un amplio ecosistema de paquetes que permiten trabajar con datos públicos de forma reproducible y transparente.
- Ggplot2: librería de visualización del lenguaje R. Es una de las herramientas más potentes para crear gráficos rigurosos y bien estructurados, tanto para análisis como para comunicación de resultados.
- Python (Matplotlib y Plotly): Python es uno de los lenguajes más utilizados en análisis de datos. Matplotlib permite crear gráficos estáticos personalizables, mientras que Plotly facilita la creación de visualizaciones interactivas. Juntas ofrecen un buen equilibrio entre potencia y flexibilidad.
- Apache Superset: plataforma de código abierto para análisis de datos y creación de paneles de control. Tiene un enfoque más institucional y escalable, lo que la hace adecuada para organizaciones que trabajan con grandes volúmenes de datos públicos.
Este bloque resulta especialmente relevante para reutilizadores de datos abiertos y perfiles técnicos intermedios que buscan combinar análisis y visualización de forma sistemática.
Herramientas para visualización interactiva y web
Estas herramientas permiten crear visualizaciones avanzadas para su publicación en entornos web. Aunque requieren mayores conocimientos técnicos, ofrecen una gran flexibilidad y posibilidades expresivas.
- D3.js: es uno de los referentes en visualización web. Se basa en estándares abiertos y permite un control total sobre la representación visual de los datos. Su flexibilidad es muy alta, aunque también lo es su complejidad.
En este ejercicio práctico puedes ver cómo se utiliza esta librería
- Vega y Vega-Lite: lenguajes declarativos para visualización que simplifican el uso de D3. Permiten definir gráficos de forma estructurada y reproducible, ofreciendo un buen equilibrio entre potencia y simplicidad.
- Observable: entorno interactivo muy ligado a D3 y Vega. Es especialmente útil para crear ejemplos educativos, prototipos y visualizaciones exploratorias que combinan código, texto y gráficos.
- Three.js y WebGL: tecnologías orientadas a visualizaciones avanzadas y en tres dimensiones. Su uso es más experimental y suele estar vinculado a proyectos de divulgación o investigación visual.
En este apartado conviene destacar que, aunque las barreras técnicas son mayores, estas herramientas permiten crear experiencias interactivas ricas que pueden resultar muy eficaces para comunicar datos públicos complejos.
Herramientas de cartografía y datos geoespaciales
La visualización geográfica es especialmente relevante en el ámbito de los datos abiertos, ya que una gran parte de la información pública tiene una dimensión territorial. En este campo, el software libre tiene un peso destacado y está muy alineado con el uso en administraciones públicas.
- QGIS: referente en software libre para sistemas de información geográfica (GIS). Es ampliamente utilizado en administraciones públicas y permite analizar y visualizar datos espaciales con gran detalle.
- ArcGIS: muy extendido en el ámbito institucional. Aunque no es software libre, su uso está muy consolidado y forma parte del ecosistema habitual de muchas organizaciones públicas.
- Mapbox: plataforma orientada a la creación de mapas web interactivos. Es muy utilizada en proyectos de visualización online y permite integrar datos geográficos en aplicaciones web.
- Leaflet: librería de código abierto muy popular para crear mapas interactivos en la web. Es ligera, flexible y ampliamente utilizada en proyectos de reutilización de datos abiertos geográficos.
Este conjunto de herramientas facilita la representación territorial de los datos y su reutilización en contextos locales, regionales o nacionales.
En conclusión, la elección de una herramienta de visualización depende en gran medida del objetivo que se persiga. No es lo mismo aprender y experimentar que analizar datos en profundidad o comunicar resultados a un público amplio. Por ello, resulta útil reflexionar previamente sobre el tipo de datos disponibles, el público al que se dirige la visualización y el mensaje que se quiere transmitir.
Apostar por herramientas accesibles y abiertas permite que más personas puedan explorar, interpretar y comunicar datos públicos. En este sentido, visualizar datos es también una forma de acercar la información a la ciudadanía y fomentar su reutilización.
Blog
Las visualizaciones de datos actúan como puentes entre la información compleja y la comprensión humana. Un gráfico bien diseñado puede comunicar en segundos datos que llevaría minutos o incluso horas descifrar en formato tabular. Más aún, las visualizaciones interactivas permiten a cada usuario explorar los datos desde su propia perspectiva, filtrando, comparando y descubriendo insights personalizados.
Para alcanzar estos fines existen múltiples herramientas, algunas de las cuales hemos abordado en ocasiones anteriores. Hoy nos acercamos a un nuevo ejemplo: la librería gratuita D3.js. En este post te explicamos cómo permite generar visualizaciones de datos útiles y atractivas junto con la herramienta de código abierto Observable.
¿Qué es D3?
D3.js (Data-Driven Documents) es una biblioteca de JavaScript que permite crear visualizaciones de datos personalizadas en navegadores web. A diferencia de herramientas que ofrecen gráficos predefinidos, D3.js proporciona los elementos fundamentales para construir prácticamente cualquier tipo de visualización imaginable.
La biblioteca es completamente gratuita y de código abierto, publicada bajo licencia BSD, lo que significa que cualquier persona u organización puede utilizarla, modificarla y distribuirla sin restricciones. Esta característica ha contribuido a su adopción generalizada: medios de comunicación internacionales como The New York Times, The Guardian, Financial Times y locales como El País o el ABC utilizan D3.js para crear visualizaciones periodísticas que ayudan a contar historias con datos.
D3.js funciona manipulando el DOM (Document Object Model) del navegador. En términos prácticos, esto significa que toma información (por ejemplo, un archivo CSV con datos de población) y la transforma en elementos visuales (círculos, barras, líneas) que el navegador puede mostrar. La potencia de D3.js reside en su flexibilidad: no impone una forma específica de visualizar datos, sino que proporciona las herramientas para crear exactamente lo que se necesita.
¿Qué es Observable?
Observable es una plataforma web para crear y compartir código, especialmente diseñada para trabajar con datos y visualizaciones. Aunque ofrece un servicio freemium con algunas funcionalidades gratuitas y otras de pago, mantiene una filosofía de código abierto que resulta particularmente relevante para el trabajo con datos públicos.
La característica distintiva de Observable es su formato de "cuadernos computacionales" (notebooks). Similar a herramientas como Jupyter Notebooks en Python, un cuaderno de Observable combina código, visualizaciones y texto explicativo en un mismo documento interactivo. Cada celda del cuaderno puede contener código JavaScript que se ejecuta inmediatamente, mostrando resultados al instante. Esto crea un entorno de experimentación ideal para explorar datos.
Puedes verlo en la práctica en este ejercicio de ciencia de datos que hemos publicado en datos.gob.es
Observable se integra naturalmente con D3.js y otras bibliotecas de visualización. De hecho, el creador de D3.js, es también uno de los fundadores de Observable, por lo que ambas herramientas trabajan conjuntamente de manera fluida. Los cuadernos de Observable pueden compartirse públicamente, permitiendo que otros usuarios vean tanto el código como los resultados, los bifurquen (fork) para crear sus propias versiones, o los integren en sus propios proyectos.
Ventajas de la herramienta para trabajar con todo tipo de datos
Tanto D3.js como Observable presentan características que pueden resultar útiles para trabajar con datos, entre ellos, con datos abiertos:
- Transparencia y reproducibilidad: al publicar una visualización creada con estas herramientas es posible compartir tanto el resultado final como todo el proceso de transformación de datos. Cualquier persona puede inspeccionar el código, verificar los cálculos y reproducir los resultados. Esta transparencia resulta fundamental cuando se trabaja con información pública, donde la confianza y la verificabilidad son esenciales.
- Sin costes de licencia: tanto D3.js como la versión gratuita de Observable permiten crear y publicar visualizaciones sin necesidad de adquirir licencias de software. Esto elimina barreras económicas para organizaciones, periodistas, investigadores o ciudadanos que desean trabajar con datos abiertos.
- Formatos web estándar: las visualizaciones creadas funcionan directamente en navegadores web sin necesidad de plugins o software adicional. Esto facilita su integración en sitios web institucionales, artículos periodísticos o informes digitales, haciéndolas accesibles desde cualquier dispositivo.
- Comunidad y recursos: existe una amplia comunidad de usuarios que comparten ejemplos, tutoriales y soluciones a problemas comunes. Observable, en particular, alberga miles de cuadernos públicos que sirven como ejemplos y plantillas reutilizables.
- Flexibilidad técnica: a diferencia de herramientas con opciones predefinidas, estas bibliotecas permiten crear visualizaciones completamente personalizadas que se adapten exactamente a las necesidades específicas de cada conjunto de datos o historia que se quiera contar.
Es importante señalar que estas herramientas requieren conocimientos de programación, específicamente de JavaScript. Para personas sin experiencia en programación, existe una curva de aprendizaje que puede resultar pronunciada inicialmente. Otras herramientas como hojas de cálculo o software de visualización con interfaces gráficas pueden ser más apropiadas para usuarios que buscan resultados rápidos sin necesidad de escribir código.
Para quienes buscan alternativas open source con una curva de aprendizaje suave, existen herramientas basadas en interfaz visual que no requieren programar. Por ejemplo, RawGraphs permite crear visualizaciones complejas simplemente arrastrando y soltando archivos, mientras que Datawrapper es una opción excelente y muy intuitiva para generar gráficos y mapas listos para publicar.
Además, existen numerosas alternativas tanto de código abierto como comerciales para visualizar datos: Python con bibliotecas como Matplotlib o Plotly, R con ggplot2, Tableau Public, Power BI, entre muchas otras. En la sección didáctica de ejercicios de visualización y ciencia de datos de datos.gob.es puedes encontrar ejemplos prácticos de uso de algunas de ellas.
En resumen, la elección de herramientas debe basarse siempre en una evaluación de requisitos específicos, recursos disponibles y objetivos del proyecto. Lo importante es que los datos abiertos se transformen en conocimiento accesible, y existen múltiples caminos para lograr este objetivo. D3.js y Observable ofrecen uno de estos caminos, particularmente adecuado para quienes buscan combinar flexibilidad técnica con principios de apertura y transparencia. Si conoces alguna otra herramienta o te gustaría que profundizáramos en otra temática, háznosla llegar a través de nuestras redes sociales o en el formulario de contacto.
Documentación
Introducción
Cada año se producen en España decenas de miles de accidentes, en los que miles de personas resultan heridas de diversa consideración, y que ocurren en circunstancias muy diversas, tanto de tipo de vía, como por el tipo de accidente.
Muchas de las estadísticas relacionadas con estos parámetros están recogidas en las bases de datos de la Dirección General de Tráfico (DGT) y algunas de ellas en el catálogo albergado en datos.gob.es.
En este ejercicio examinaremos el contenido de la base de datos de siniestralidad de la DGT para el año 2024 con el fin de realizar una serie de visualizaciones básicas que nos permitan ver de forma rápida e intuitiva cuáles son los hechos a destacar respecto a la incidencia de accidentes y sus consecuencias en ese año.
Para ello vamos a desarrollar código en Python que nos permita la lectura y cálculo de métricas básicas respecto al número total de víctimas, las particularidades de las infraestructuras así como las diferentes casuísticas de los accidentes. Y una vez tengamos disponibles esos datos, los visualizaremos utilizando la librería de Javascript D3.js, que nos permite tanto la representación de datos en su forma más tradicional como en diseños más contemporáneos, habituales en la prensa, favoreciendo así una narrativa fluída en estilo y coherente en contenido.
En el entorno de Python utilizaremos librerías de uso común y frecuente como son Numpy, para el cálculo básico - sumas, máximos y mínimos-, y Pandas, para estructurar los datos de forma intuitiva, facilitando tanto su organización como su transformación. Igualmente trabajaremos con Datetime, tanto para el formateo de los datos de entrada en tipos de fecha estándares dentro del mundo de la programación en Python, como para agregar los datos de forma fácil e intuitiva. De esta forma aprenderemos a abrir cualquier tipo de fichero de datos en formato .CSV, a estructurarlo de forma ordenada y a realizar transformaciones y operaciones básicas de forma sencilla.
En el entorno de Javascript desarrollaremos notebooks en D3.js gracias al uso de Observable, una iniciativa abierta y gratuita, para poder ejecutar código de Javascript directamente en un interfaz web, y sin tener que recurrir a servidores locales o complejas instalaciones. En diferentes notebooks crearemos visualizaciones clásicas -como las series temporales en ejes cartesianos o mapas- junto con otras propuestas tales como distribuciones de burbujas o elementos apilados por categorías.
En la Figura 1 se pueden ver las principales etapas de este ejercicio, desde la lectura de los datos dentro del fichero de la DGT, hasta las operaciones y las variables de salida en formato JSON, que nos servirán a su vez en un entorno Javascript para poder desarrollar las visualizaciones en D3.js.
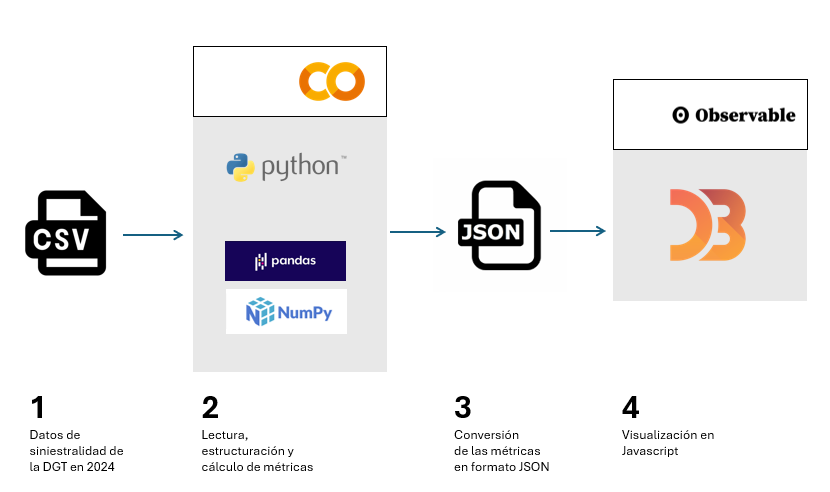
Figura 1. Pasos en los cuales se estructura este ejercicio, con punto de partida en la base de datos de la DGT, el procesado y manipulación de esos datos en Python, la creación de ficheros de salida en formato JSON y su uso en Javascript para visualizar los resultados.
El acceso al repositorio de Github, el notebook de Google Colab y los notebooks de Observable se pueden realizar a través de los siguientes enlaces:
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de GoogleColab
Accede a los notebooks de Observable
Proceso de Desarrollo
1. Lectura del fichero de datos
El primer paso será leer el fichero de la DGT que contiene todos los registros de accidentes del año 2024. Este paso nos permitirá identificar los campos de interés y sobre todo en qué formato se encuentran. Podremos identificar si se precisa de alguna transformación sobre todo en la información de la fecha, tal y como está estructurada en el fichero de origen.
Igualmente veremos cómo traducir los códigos de muchas de las categorías que nos ofrece la DGT, de modo que podamos hacer una interpretación real más allá de los números de categorías como tipo de accidente, tipo de vía o titularidad de la vía.
Una vez entendemos la estructura y contenido de los datos podemos empezar a operar con ellos.
2. Cálculo de métricas
La librería Pandas de Python nos permite operar con las diferentes columnas de datos y realizar cálculos básicos que serán suficientemente representativos para entender mínimamente la casuística de los accidentes en las carreteras españolas.
En este apartado se realizarán tres tipos de cálculos.
- El primero de ellos será el cálculo del número total de víctimas por hora del día para cada uno de los días de la semana. La base de datos de la DGT viene estructurada por día de la semana, de forma que utilizaremos también esa escala temporal para representar los datos en una serie. Cabe hacer notar que por víctima se considera toda aquella persona que ha fallecido o que sea diagnosticada como herida grave o leve.
- El segundo cálculo será la suma total de accidentes para diferentes categorías, tales como la titularidad de la vía, el tipo de accidente o el tipo de vía. Esto nos permitirá ver cuáles son las condiciones en las cuales los accidentes son más frecuentes.
- El tercer cálculo será el de número de accidentes por municipio. En este caso realizaremos el cálculo restringido a la provincia de Valencia como ejemplo, y que sería aplicable a cualquier provincia o municipio de nuestro interés. En este caso observaremos las diferencias entre los núcleos urbanos y no urbanos, así como aquellos municipios por los que pasan las principales vías de comunicación.
3. Diseño de las visualizaciones
Una vez hemos calculado las métricas de interés, desarrollaremos cinco ejercicios de visualización en D3.js. Para ello exportaremos en formato JSON el resultado de las métricas y crearemos notebooks en Observable. En concreto realizamos las siguientes visualizaciones:
- Serie temporal con el número total de víctimas en cada hora y día de la semana, con un menú desplegable interactivo para seleccionar el día de la semana de interés. A mayores de la curva que describe el número de víctimas dibujaremos sobre el fondo de la gráfica la incertidumbre de todos los días de la semana, de forma que la serie temporal diaria queda enmarcada en el contexto de toda la semana como referencia.
- Mapa de la provincia de Valencia con el número total de accidentes por municipio.
- Diagrama de burbujas, con las diferentes magnitudes de los diferentes tipos de accidentes con el número total de accidentes en cada caso escrita de forma detallada.
- Diagrama de puntos apilados, donde acumulamos círculos o cualquier otra forma geométrica para las diferentes titularidades de la vía y su número total de accidentes dentro del marco de cada titularidad.
- Diagrama de sierra, con la altura de cada montaña correspondiente al número de accidentes en cada tipo de vía en escala logarítmica.
Visualización de las métricas
El resultado de este ejercicio se podrá ver de forma gráfica y explícita en forma de visualizaciones realizadas para el formato web y accesibles desde una interfaz también web, tanto para su desarrollo como para su posterior publicación. Todo el conjunto de visualizaciones se encuentra en el repositorio de Datos.gob.es en Observable:
Accede a los notebooks de Observable
En la Figura 2 tenemos el resultado de la serie temporal del total de víctimas respecto a la hora del día para diferentes días de la semana. La serie temporal está enmarcada dentro de la incertidumbre del total de días de la semana, para dar una idea del margen de variabilidad que podemos tener dependiendo de la hora del día.
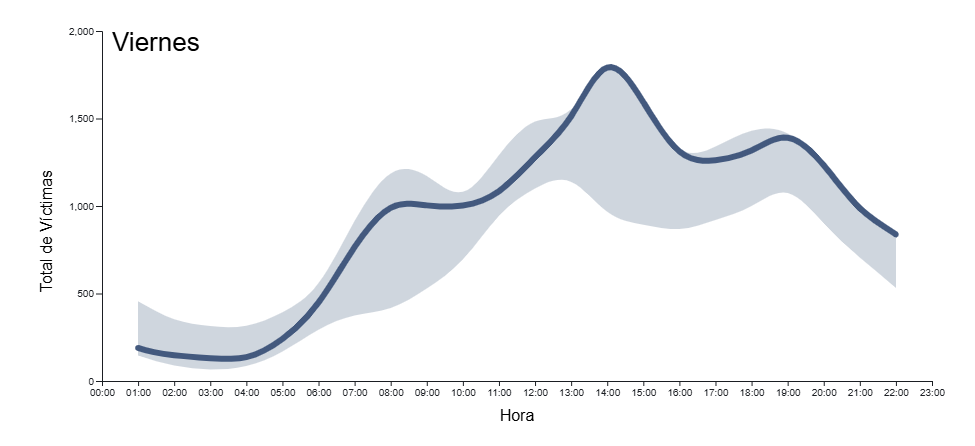
Figura 2. Serie temporal del total de víctimas en accidentes por hora del día para todos los días de la semana en 2024. En el fondo en color azul claro se indica la incertidumbre asociada a todos los días de la semana como contexto, con menú desplegable para seleccionar el día de la semana.
En la Figura 3 podemos observar el mapa de la provincia de Valencia con una intensidad de color proporcional al número de accidentes en cada municipio. Aquellos municipios en los cuales no se han registrado accidentes aparecen en color blanco. De forma intuitiva se puede adivinar el trazado de las principales carreteras que atraviesan la provincia, tanto la carretera hacia el este de la ciudad de Valencia en dirección Madrid como la carretera del interior hacia el sur de la ciudad en dirección a Alicante.
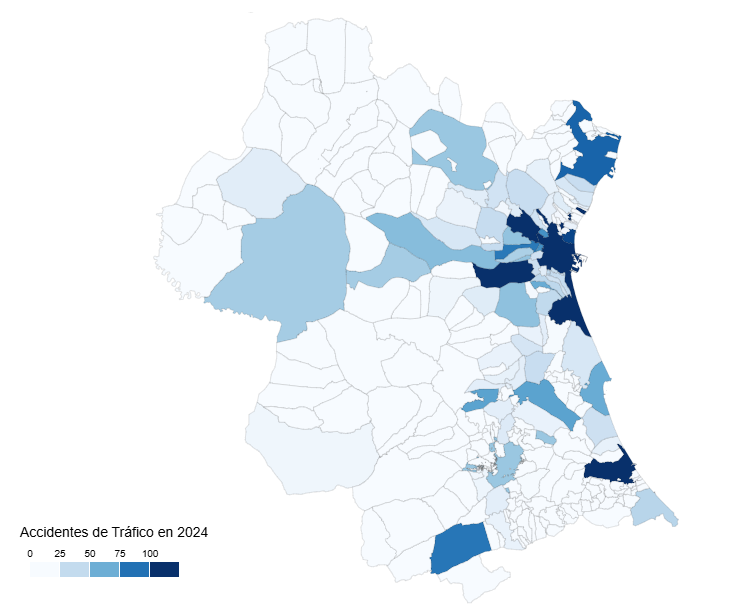
Figura 3. Mapa del número de accidentes por municipio en la provincia de Valencia en 2024.
En la Figura 4 vemos una forma geométrica, el círculo, asociada a los tipos de accidente, con el detalle del número de accidentes asociada a cada categoría. En este tipo de visualización emerge de forma natural aquellos accidentes más frecuentes en torno al centro del diagrama, mientras que aquellos minoritarios o residuales ocupan el perímetro del diagrama para dar igualmente una forma redonda al conjunto de formas.
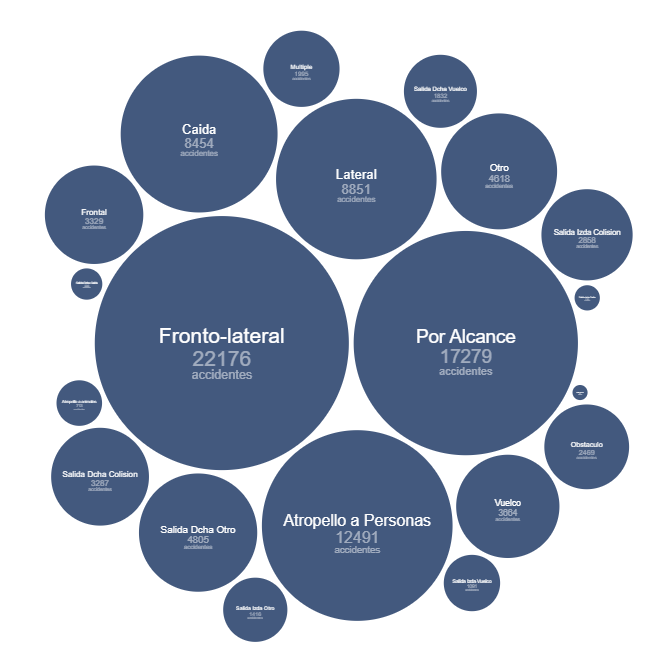
Figura 4. Diagrama de burbujas del número de accidentes por tipo de accidente en 2024.
En la Figura 5 se puede contemplar el tradicional diagrama de barras pero esta vez descompuesto en unidades más pequeñas, para afinar la cantidad de accidentes asociada a la titularidad de la vía donde han sucedido. Este tipo de diagramas permite discernir pequeñas diferencias entre magnitudes parecidas, preservando el mensaje general que obtenemos de un cálculo de estas características.
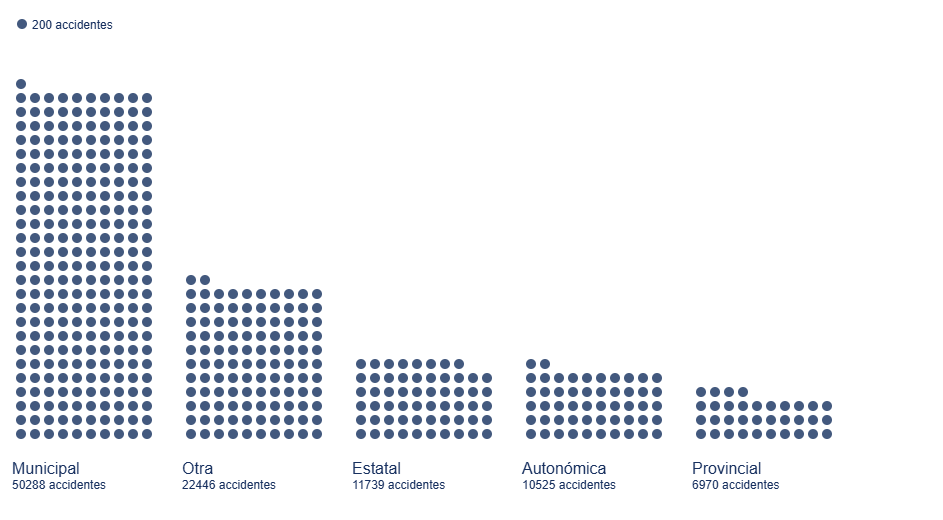
Figura 5. Diagrama de barras con discretización de puntos para el número de accidentes por titularidad de la vía en el 2024.
En la Figura 6 creamos una serie de formas geométricas que replican una cordillera o sierra donde los diferentes picos apuntan a la diferencia de número de accidentes por tipo de vía. Dada la diferencia en órdenes de magnitud establecemos una escala logarítmica, que permita comparar en el mismo diagrama diferentes casuísticas.
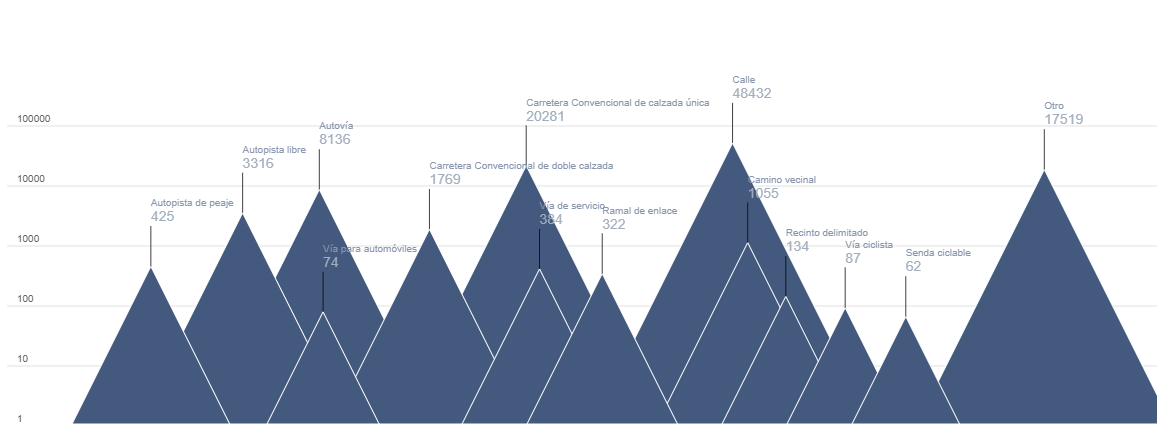
Figura 6. Diagrama en cordillera para los diferentes órdenes de magnitud del número de accidentes por tipo de vía en el 2024.
Lecciones aprendidas
A través de estos pasos aprenderemos toda una serie de habilidades transversales que nos permiten trabajar con aquellos conjunto de datos que se nos presentan en formato CSV en columnas, un formato muy popular para el cual podremos realizar tanto su análisis como su visualización. Estas lecciones son en concreto:
- Universalidad de lectura y estructuración de datos: el uso de herramientas como Python, con sus librerías Numpy y Pandas, permiten acceder a los datos en detalle y estructurarlos de forma ordenada e intuitiva con pocas líneas de código.
- Cálculos sencillos en Pandas: la propia librería de Python permite cálculos sencillos pero esenciales para la interpretación preliminar de resultados.
- Formato Datetime: a través de esta librería de Python podemos familiarizarnos con el estándar del formato de fecha, y así realizar todo tipo de transformaciones, filtros y selecciones que más nos interesen en cualquier intervalo temporal.
- Formato JSON: una vez que decidimos dar espacio a nuestras visualizaciones en la web, aprender la estructura y uso del formato JSON es de gran utilidad dado su amplio uso en todo tipo de aplicaciones y arquitecturas web.
- Espectro de posibilidades de D3.js: esta librería de Javascript nos permite explorar de lo más tradicional y conservador a lo más creativo gracias a sus principios basados en las formas más básicas, sin plantillas, templates o diagramas predefinidos.
Conclusiones y próximos pasos
Hemos aprendido a leer y a estructurar datos según los estándares de los formatos más utilizados en el mundo del análisis y visualización. Este ejercicio también sirve como módulo introductorio al mundo de D3.js, una herramienta muy versátil, vigente y popular dentro del mundo del storytelling y la visualización de datos a todos los niveles.
Para poder avanzar en este ejercicio se recomienda:
- Para los analistas y desarrolladores, se puede prescindir de la librería Pandas y estructurar los datos con objetos más elementales de Python como arrays y matrices, buscando qué funciones y qué operadores permiten realizar las mismas tareas que hace Pandas pero de una forma más fundamental, sobre todo si pensamos en entornos de producción para los cuales necesitamos el menor número de librerías posibles para aligerar la aplicación.
- Para los creadores de visualizaciones, la información sobre los municipios puede proyectarse igualmente sobre bases cartográficas ya existentes como OpenStreetMap y de esta forma vincular la incidencia de accidentes a características orográficas o infraestructuras ya reflejadas en esas bases cartográficas. Para las magnitudes de los números de accidentes se pueden explorar diagramas de tipo Treemap o diagramas de Voronoi y ver si transmiten el mismo mensaje que los que presentamos en este ejercicio.
Ámbitos de aplicación
Los pasos descritos en este ejercicio pueden pasar a formar parte de cualquier caja de herramientas de uso habitual para los siguientes perfiles:
- Analistas de datos: aquí se encuentran los pasos básicos para la descripción de un fichero de datos en formato CSV y los cálculos básicos a realizar tanto en el campo de la fecha como de operaciones entre variables de diferentes columnas. Estas herramientas pueden servir para introducirse en el mundo del análisis de datos y ayuda en esos primeros pasos a la hora de enfrentarse a un dataset.
- Científicos y personal investigador: la universalidad de las herramientas aquí descritas aplican a una gran variedad de origen de datos, como el que se experimenta en las ciencias experimentales y de observaciones o medidas de todo tipo. Estas herramientas permiten un análisis rápido a la vez que riguroso sin importar el campo de conocimiento en el que se trabaje.
- Desarrolladores web: la exportación de datos en formato JSON así como el código en Javascript que se ofrece en los notebooks de Observable son fácilmente integrables en todo tipo de entornos (Svelte, React, Angular, Vue) y permite la creación de visualizaciones en una web de forma sencilla e intuitiva.
- Periodistas: abarcar todo el proceso de vida de un fichero de datos, desde su lectura a su visualización, otorga al periodista o investigador independencia a la hora de evaluar e interpretar los datos por sí mismo sin depender de recursos técnicos ajenos. La creación del mapa por municipios abre la puerta a utilizar cualquier otro dato similar, como por ejemplo procesos electorales, con el mismo formato de salida para mostrar variabilidad geográfica respecto a cualquier tipo de magnitud.
- Diseñadores Gráficos: el manejo de herramientas de visualización con un amplio grado de libertad permite a los diseñadores cultivar toda su creatividad dentro del rigor y la exactitud que los datos necesitan.
Blog
La visualización de datos es una práctica fundamental para democratizar el acceso a la información pública. Sin embargo, crear gráficos efectivos va mucho más allá de elegir colores atractivos o utilizar las últimas herramientas tecnológicas. Como señala Alberto Cairo, experto en visualización de datos y docente de la academia del portal europeo de datos abiertos (data.europa.eu), “cada decisión de diseño debe ser deliberada: inevitablemente subjetiva, pero nunca arbitraria”. A través de una serie de tres webinar que puedes volver a ver aquí, el experto ofreció consejos innovadores para estar a la vanguardia de la visualización de datos.
Cuando trabajamos con visualización de datos, especialmente en el contexto de la información pública, es crucial desmontar algunos mitos arraigados en nuestra cultura profesional. Frases como "los datos hablan por sí mismos", "una imagen vale más que mil palabras" o "muestra, no cuentes" suenan bien, pero esconden una verdad incómoda: los gráficos no siempre comunican automáticamente.
La realidad es más compleja. Un/a profesional del diseño puede querer comunicar algo específico, pero los lectores pueden interpretar algo completamente diferente. ¿Cómo se puede superar la brecha entre intención y percepción en visualización de datos? En este post, ofrecemos algunas claves de la serie formativa.
Un marco estructurado para diseñar con propósito
En lugar de seguir "reglas" rígidas o aplicar plantillas predefinidas, en el curso se propone un marco de pensamiento basado en cinco componentes interrelacionados:
- Contenido: la naturaleza, origen y limitaciones de los datos
- Personas: la audiencia a la que nos dirigimos
- Intención: los propósitos que definimos
- Restricciones: las limitaciones que enfrentamos
- Resultados: cómo es recibido el gráfico
Este enfoque holístico nos obliga a preguntarnos constantemente: ¿qué necesitan realmente saber nuestros lectores? Por ejemplo, cuando comunicamos información sobre riesgos de huracanes o emergencias sanitarias, ¿es más importante mostrar trayectorias exactas o comunicar impactos potenciales? La respuesta correcta depende del contexto y, sobre todo, de las necesidades informativas de la ciudadanía.
El peligro de la agregación excesiva
Aún sin perder de vista el propósito es importante no caer en añadir demasiada información o presentar solo promedios. Imaginemos, por ejemplo, un conjunto de datos sobre seguridad ciudadana a nivel nacional: un promedio puede esconder que la mayoría de las localidades son muy seguras, mientras unas pocas con tasas extremadamente altas distorsionan el indicador nacional.
Como explica Claus O. Wilke en su libro "Fundamentals of Data Visualization", esta práctica puede ocultar patrones cruciales, valores atípicos y paradojas que son precisamente los más relevantes para la toma de decisiones. Para evitar este riesgo, en la formación se propone visualizar una gráfica como un sistema de capas que debemos construir cuidadosamente desde la base:
1. Codificación (Encoding)
- Es la base de todo: cómo traducimos datos en atributos visuales. Las investigaciones en percepción visual nos muestran que no todos los "canales visuales" son igual de efectivos. La jerarquía sería:
- Más efectivos: posición, longitud y altura
- Medianamente efectivos: ángulo, área y pendiente
- Menos efectivos: color, saturación y forma
¿Cómo ponemos esto en práctica? Pues, por ejemplo, para realizar comparaciones precisas, un gráfico de barras será casi siempre mejor opción que un gráfico circular. Sin embargo, como se matiza en los materiales formativos, "efectivo" no siempre significa "apropiado". Un gráfico circular puede ser perfecto cuando queremos expresar la idea de un "todo y sus partes", aunque las comparaciones precisas sean más difíciles.
2. Disposición (Arrangement)
El posicionamiento, orden y agrupación de los elementos afecta profundamente a la percepción. ¿Queremos que el lector compare entre categorías dentro de un grupo, o entre grupos? La respuesta determinará si organizamos nuestra visualización con barras agrupadas o apiladas, con paneles múltiples o en una única vista integrada.
3. Andamiaje (Scaffolding)
Los títulos, introducciones, anotaciones, escalas y leyendas son fundamentales. En datos.gob.es hemos visto cómo las visualizaciones interactivas pueden condensar información compleja, pero sin un andamiaje adecuado, la interactividad puede confundir más que aclarar.
El valor de una correcta escala
Uno de los aspectos técnicos más delicados —y a menudo más manipulables— de una visualización es la elección de la escala. Una simple modificación en el eje Y puede cambiar por completo la interpretación del lector: una tendencia suave puede parecer una crisis repentina, o un crecimiento sostenido puede pasar desapercibido.
Como se menciona en el segundo webinar de la serie, las escalas no son un detalle menor: son un componente narrativo. Decidir dónde empieza un eje, qué intervalos se usan o cómo se representan los periodos de tiempo implica hacer elecciones que afectan directamente la percepción de la realidad. Por ejemplo, si una gráfica de empleo comienza el eje Y en 90 % en lugar de 0 %, el descenso puede parecer dramático, aunque, en realidad, sea mínimo.
Por eso, las escalas deben ser honestas con los datos. Ser “honesto” no significa renunciar a decisiones de diseño, sino mostrar claramente qué decisiones se tomaron y por qué. Si existe una razón válida para empezar el eje Y en un valor distinto de cero, debe explicarse explícitamente en la gráfica o en su pie de texto. La transparencia debe prevalecer sobre el dramatismo.
La integridad visual no solo protege al lector de interpretaciones engañosas, sino que refuerza la credibilidad de quien comunica. En el ámbito de los datos públicos, esa honestidad no es opcional: es un compromiso ético con la verdad y con la confianza ciudadana.
Accesibilidad: visualizar para todos
Por otro lado, uno de los aspectos frecuentemente olvidado es la accesibilidad. Aproximadamente el 8 % de los hombres y el 0,5 % de las mujeres tienen algún tipo de daltonismo. Herramientas como Color Oracle permiten simular cómo se ven nuestras visualizaciones para personas con diferentes tipos de deficiencias en la percepción del color.
Además, en el webinar se mencionó el proyecto Chartability, una metodología para evaluar la accesibilidad de las visualizaciones de datos. En el sector público español, donde la accesibilidad web es un requisito legal, esto no es opcional: es una obligación democrática. Bajo esta premisa publicó la Federación Española de Municipios y Provincias publicó una Guía de Visualización de Datos para Entidades Locales.
Narrativa visual: cuando los datos cuentan historias
Una vez resueltas las cuestiones técnicas, podemos abordar el aspecto narrativo que cada día es más importante para comunicar correctamente. En este sentido, el curso plantea un método sencillo pero poderoso:
- Escribe una frase larga que resuma los puntos que quieres comunicar.
- Divide esa frase en componentes, aprovechando las pausas naturales.
- Transforma esos componentes en secciones de tu infografía.
Este enfoque narrativo es especialmente efectivo para proyectos como los que encontramos en data.europa.eu, donde se combinan visualizaciones con explicaciones contextuales para comunicar el valor de los conjuntos de datos de alto valor o en los ejercicios de visualización y ciencia de datos de datos de datos.gob.es.
El futuro de la visualización de datos también incluye aproximaciones más creativas y centradas en el usuario. Proyectos que incorporan elementos personalizados, que permiten a los lectores situarse en el centro de la información, o que utilizan técnicas narrativas para generar empatía, están redefiniendo lo que entendemos por "comunicación de datos".
Incluso emergen formas alternativas de "sensificación de datos": la fisicalización (crear objetos tridimensionales con datos) y la sonificación (traducir datos a sonido) abren nuevas posibilidades para hacer la información más tangible y accesible. La empresa española Tangible Data, de la que nos hacemos eco en datos.gob.es porque reutiliza conjuntos de datos abiertos, es prueba de ello.

Figura 1. Ejemplos de sensificación de datos. Fuente: https://data.europa.eu/sites/default/files/course/webinar-data-visualisation-episode-3-slides.pdf
A modo de conclusión, podemos resaltar que la integridad en el diseño no es un lujo: es un requisito ético. Cada gráfico que publicamos en plataformas oficiales influye en cómo los ciudadanos perciben la realidad y toman decisiones. Por eso, dominar herramientas técnicas como las bibliotecas y API de visualización, que se analizan en otros artículos del portal, es tan relevante.
La próxima vez que crees una visualización con datos abiertos, no te preguntes solo "¿qué herramienta uso?" o "¿qué gráfico se ve mejor?". Pregúntate: ¿qué necesita realmente saber mi audiencia? ¿Esta visualización respeta la integridad de los datos? ¿Es accesible para todos? Las respuestas a estas preguntas son las que transforman un gráfico bonito en una herramienta de comunicación verdaderamente efectiva.
Blog
Imagina que quieres saber cuántas terrazas hay en tu barrio, cómo evolucionan los niveles de polen del aire que respiras cada día o si el reciclaje en tu ciudad está funcionando bien. Toda esa información existe en las bases de datos de tu ayuntamiento, pero se encuentra entre hojas de cálculo y documentos técnicos que solo los expertos sabían interpretar.
Aquí es donde entran en juego las iniciativas de visualización de datos abiertos: transforman esos números aparentemente fríos en historias que cualquier persona puede entender de un vistazo. Un gráfico colorido que muestra la evolución del tráfico en tu calle, un mapa interactivo con las zonas verdes de tu ciudad, o una infografía que explica en qué se gasta el presupuesto municipal. Estas herramientas convierten la información pública en algo cercano, útil y, además, comprensible para toda la ciudadanía.
Además, las ventajas de este tipo de soluciones no son solo para la ciudadanía, sino que también benefician a la Administración que realiza el ejercicio, porque permite:
- Detectar y corregir errores en los datos.
- Incorporar nuevos conjuntos al portal.
- Disminuir el número de preguntas del ciudadano.
- Generar más confianza por parte de la sociedad.
Por tanto, visualizar datos abiertos permite acercar la Administración a la ciudadanía, facilita la toma de decisiones informadas, ayuda a las Administraciones Públicas a mejorar su oferta de datos abiertos y permite crear una sociedad más participativa donde todos podemos entender mejor cómo funciona el sector público. En este post, te presentamos algunos ejemplos de iniciativas de visualización de open data en portales de datos abiertos autonómicos y municipales.
Visualiza Madrid: acercando los datos a la ciudadanía
El portal de datos abiertos del Ayuntamiento de Madrid ha desarrollado la iniciativa "Visualiza Madrid", un proyecto que nace con el objetivo específico de hacer que los datos abiertos y su potencial lleguen a la ciudadanía en general, trascendiendo los perfiles técnicos especializados. Tal y como explicó Ascensión Hidalgo Bellota, Subdirectora general de Transparencia del Ayuntamiento de Madrid, durante el IV Encuentro Nacional de Datos Abiertos, “esta iniciativa responde a la necesidad de democratizar el acceso a la información pública”.
Actualmente, Visualiza Madrid cuenta con 29 visualizaciones que abarcan diferentes temáticas de interés ciudadano, desde información sobre terrazas de hostelería hasta gestión de residuos y análisis del tráfico urbano. Esta diversidad temática demuestra la versatilidad de las visualizaciones como herramienta para comunicar información de sectores muy diversos de la administración pública.
Además, la iniciativa ha recibido este año un reconocimiento externo a través de los premios Audaz 2025, una iniciativa del capítulo español de la Red Académica de Gobierno Abierto (RAGA España).
Castilla y León: análisis integral de datos regionales
La Junta de Castilla y León también ha desarrollado un portal especializado en análisis y visualizaciones que destaca por su enfoque integral hacia la presentación de datos autonómicos. Su plataforma de visualizaciones ofrece una aproximación sistemática al análisis de información regional, permitiendo a los usuarios explorar diferentes dimensiones de la realidad de Castilla y León a través de herramientas interactivas y dinámicas.
Esta iniciativa permite presentar información compleja de manera estructurada y comprensible, facilitando tanto el análisis académico como el uso ciudadano de los datos. La plataforma integra diferentes fuentes de información autonómica, creando un ecosistema coherente de visualizaciones que permite obtener una visión panorámica de diversos aspectos de la gestión regional. Entre las temáticas que ofrece podemos mencionar datos de turismo, del mercado laboral o de la ejecución de los presupuestos. Todas las visualizaciones están realizadas con conjuntos de datos abiertos del portal autonómico de Castilla y León.
El enfoque de Castilla y León demuestra cómo las visualizaciones pueden servir como herramienta de análisis territorial, proporcionando insights valiosos sobre dinámicas económicas, sociales y demográficas que resultan fundamentales para la planificación y evaluación de políticas públicas regionales.
Canarias: integración tecnológica con widgets interactivos
Por otro lado, el Gobierno de Canarias ha apostado por una estrategia innovadora mediante la implementación de widgets que permiten la integración de visualizaciones de datos abiertos del Instituto Canario de Estadística (ISTAC) en diferentes plataformas y contextos. Esta aproximación tecnológica representa un salto cualitativo en la distribución y reutilización de visualizaciones de datos públicos.
Los widgets desarrollados por Canarias facilitan que terceros puedan incorporar visualizaciones oficiales en sus propias aplicaciones, sitios web o análisis, ampliando exponencialmente el alcance y la utilidad de los datos abiertos canarios. Esta estrategia no solo multiplica los puntos de acceso a la información pública, sino que también fomenta la creación de un ecosistema colaborativo donde diferentes actores pueden beneficiarse y contribuir al valor de los datos abiertos.
La iniciativa canaria ilustra cómo la tecnología puede ser utilizada para crear soluciones escalables y flexibles que maximicen el impacto de las inversiones en visualización de datos abiertos, estableciendo un modelo replicable para otras administraciones que busquen amplificar el alcance de sus iniciativas de transparencia.
Lecciones aprendidas y mejores prácticas
A modo de ejemplo, los casos analizados revelan patrones comunes que pueden servir como guía para futuras iniciativas. La orientación hacia la ciudadanía general, más allá de usuarios técnicos especializados, emerge como un factor de oportunidad para el éxito de estas plataformas. Para mantener el interés y la relevancia de las visualizaciones es importante ofrecer diversidad temática y actualizar los datos regularmente.
La integración tecnológica y la interoperabilidad, como demuestra el caso de Canarias, abren nuevas posibilidades para maximizar el impacto de las inversiones públicas en visualización de datos. Asimismo, el reconocimiento externo y la participación en redes profesionales, como evidencia el caso de Madrid, contribuyen a la mejora continua y al intercambio de mejores prácticas entre administraciones.
En términos generales, las iniciativas de visualización de datos abiertos representan una oportunidad muy valiosa en la estrategia de transparencia y gobierno abierto de las administraciones públicas españolas. Los casos de Madrid, Castilla y León, así como de Canarias, son ejemplo de que existe un potencial enorme para transformar datos públicos en herramientas de empoderamiento ciudadano y mejora de la gestión pública.
El éxito de estas iniciativas radica en su capacidad para conectar la información gubernamental con las necesidades reales de la ciudadanía, creando puentes de comprensión que fortalecen la relación entre administración y sociedad. A medida que estas experiencias maduren y se consoliden, será fundamental mantener el foco en la usabilidad, la accesibilidad y la relevancia de las visualizaciones, asegurando que los datos abiertos cumplan verdaderamente su promesa de contribuir a una sociedad más informada, participativa y democrática.
La visualización de datos abiertos no es solo una cuestión técnica, sino una oportunidad estratégica para redefinir la comunicación pública y fortalecer los cimientos de una Administración verdaderamente abierta y transparente.
Blog
El Informe Europeo sobre Drogas proporciona una visión actual de la situación de las drogas en la región, analizando las principales tendencias y amenazas emergentes. Se trata de una publicación de gran valor, con un alto número de descargas, que se cita en múltiples medios de comunicación.
El informe se realiza de forma anual por la Agencia de la Unión Europea sobre Drogas (EUDA en sus siglas en inglés), nombre actual del antiguo Observatorio Europeo de las Drogas y las Toxicomanías. Este organismo recopila y analiza datos de los Estados miembros de la Unión Europea, junto con otros países asociados, como son Turquía y Noruega, para proporcionar una visión integral del consumo y oferta de drogas, los daños que producen y las intervenciones de reducción de daños. El informe contiene conjuntos completos de datos sobre estos temas desagregados a nivel nacional, e incluso, en algunos casos, a nivel de ciudad (como Barcelona o Palma de Mallorca).
Este estudio lleva realizándose desde 1993 y traduciéndose a más de 20 idiomas oficiales de la Unión Europea. No obstante, en los dos últimos años ha presentado una novedad: un cambio en los procesos internos para mejorar la visualización de los datos obtenidos. Un proceso que han explicado en el reciente webinar “El Informe Europeo sobre las Drogas: uso de un enfoque de datos abiertos para mejorar la visualización de datos”, organizado por el Portal de Datos Abiertos Europeo (data.europa.eu) el pasado 25 de junio. A continuación, se resume lo que contaron los representantes del Observatorio en esta cita.
La necesidad de un cambio
El Observatorio siempre ha trabajado con datos abiertos, pero el proceso presentaba ineficiencias. Hasta ahora el Informe Europeo sobre Drogas se había publicado siempre en formato PDF, poniendo el foco en conseguir un producto visualmente llamativo. El proceso interno previo a la publicación del informe consistía en varias etapas que involucraban a diversos equipos:
- Un equipo del Observatorio comprobaba el formato de los datos recibidos por parte del proveedor y, si era necesario, los adaptaba.
- Un equipo especializado en análisis de datos creaba visualizaciones a partir de los datos.
- Un equipo especializado en redacción redactaba el informe. El equipo que había creado las visualizaciones podía colaborar en esta fase.
- Un equipo interno validaba el contenido del reporte.
- El proveedor de los datos revisaba que el Observatorio había intepretado los datos correctamente.
A pesar del buen recibimiento del informe y su formato, en 2022 el Observatorio decidió cambiar completamente el formato de publicación por los siguientes motivos:
- Una vez iniciados los distintos pasos del proceso de publicación, los datos se formateban y dejaban de ser legibles por una máquina. Esto reducía la acessibilidad de los datos, por ejemplo, para lectores de pantalla, y limitaba su capacidad de reutilización.
- Si en los distintos pasos del proceso se detectaban errores, se corregían directamente sobre el formato que tenían los datos en este paso. Es decir, si en la fase de revisión se detectaba un error en un gráfico, se corregía directamente sobre dicho gráfico. Este procedimiento podía causar errores y opacar la trazabilidad de los datos, limitando la eficiencia: un mismo gráfico estático podía estar presente varias veces en el documento y cada mención se tenía que corregir individualmente.
- Al final del proceso se tenía que ajustar el formato de los datos de origen, por los cambios realizados en el procedimiento de publicación.
- Muchos de los usuarios que consultaban el informe lo hacían desde un dispositivo móvil, para el cual el formato del PDF no siempre era adecuado.
- Al no ser accesibles ni aptos para dispositivos moviles, los documentos en formato PDF no solían aparecer como primer resultado en los motores de búsqueda. Este punto es importante para el Observatorio, ya que muchos de los usuarios encuentran el informe a través de buscadores.
Era necesario un formato web responsive, que ajustara automáticamente el sitio web al tamaño y disposición de los dispositivos de sus usuarios. Con ello se buscaba:
- Una mejora de la accesibilidad.
- Un proceso de creación de visualizaciones más ágil.
- Un proceso de traducción más fácil.
- Un aumento de visitantes procedentes de motores de búsqueda.
- Un mayor modularidad.
El proceso detrás del nuevo informe
Con el fin de transformar por completo el formato de publicación del informe, se ha llevado a cabo un proceso de visualización diseñado ad hoc, resumido en la siguiente imagen:
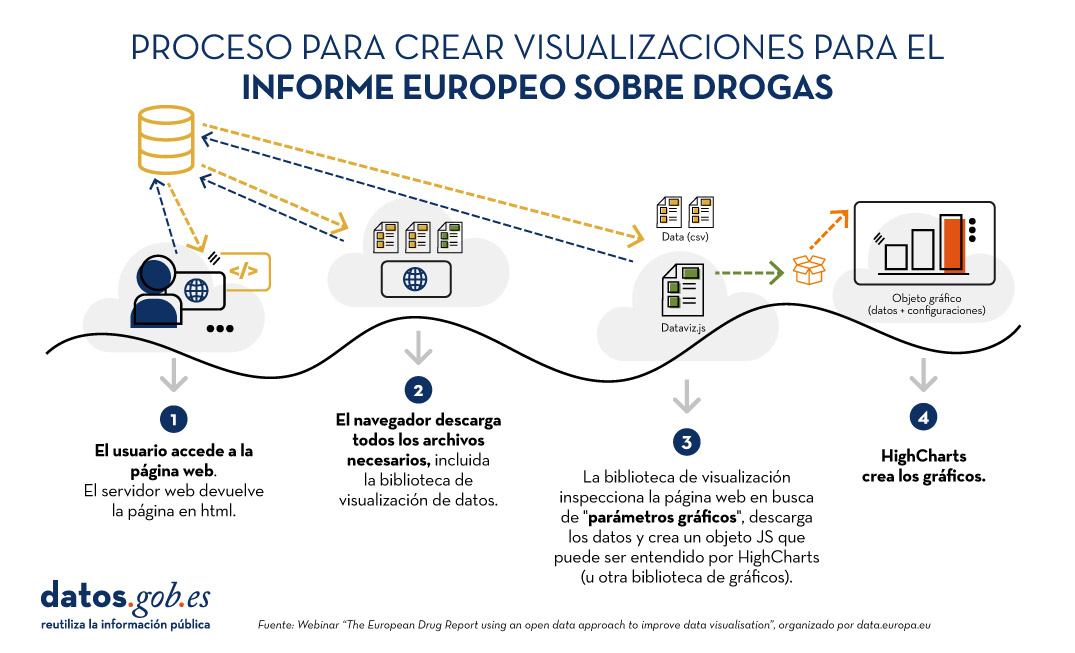
Figura 1. Proceso para crear visualizaciones para el Informe Europeo sobre Drogas. Fuente ES: Webinar “The European Drug Report using an open data approach to improve data visualisation”, organizado por data.europa.eu.
La principal novedad es que las visualizaciones se crean dinámicamente a partir de los datos fuente. De esta forma, si se modifica algo en dichos datos, automáticamente se cambia en todas las visualizaciones que se alimentan de ellos. Mediante el sistema de gestión de contenidos Drupal, en el que está basada gran parte de la web, los administradores pueden registrar cambios que automáticamente se reflejarán en el HTML y, por lo tanto, en las visualizaciones. Además, los administradores de la página disponen de un generador de visualizaciones que crea visualizaciones sin necesidad de tocar código, a partir de los datos e indicaciones -que equivalen a instrucciones sencillas como “ordenar de mayor a menor”, expresados mediante HTML-.
El mismo procedimiento dinámico de actualización se aplica al PDF que el usuario puede descargar. Si hay cambios en los datos, en las visualizaciones o se corrigen errores tipográficos, el PDF se genera nuevamente a través de un proceso de compilación que el Observatorio ha creado específicamente para esta tarea.
El informe después del cambio
Actualmente el informe se publica en versión HTML, con la posibilidad de descargar capítulos o el informe completo en formato PDF. Está estructurado por módulos temáticos y también permite la consulta de anexos.
Además, los datos siempre se publican en formato CSV y se indica en la misma página las condiciones de licencia de los datos (CC-BY-4.0). La referencia de la fuente de los datos siempre se pone a disposición del lector en la misma página en la que está una visualización.
Con este cambio de procedimiento y formato, se han conseguido beneficios para todos. Desde el punto de vista de los lectores, se ha mejorado la experiencia del usuario. Para la organización, se ha agilizado el proceso de publicación.
En cuanto a datos abiertos, este nuevo enfoque permite una mayor trazabilidad, ya que se puede consultar en cada momento los datos en su formato actual. Además, según los ponentes del Observatorio, este nuevo formato del informe, junto con el hecho de que los datos y visualizaciones siempre están actualizados, ha aumentado la accesibilidad de los datos para medios de comunicación.
Puedes acceder a los materiales del webinar aquí:
Documentación
1. Introducción
En la era de la información, la inteligencia artificial ha demostrado ser una herramienta invaluable para una variedad de aplicaciones. Una de las manifestaciones más increíbles de esta tecnología es GPT (Generative Pre-trained Transformer), desarrollado por OpenAI. GPT es un modelo de lenguaje natural que puede entender y generar texto, ofreciendo respuestas coherentes y contextualmente relevantes. Con la reciente introducción de Chat GPT-4, las capacidades de este modelo se han ampliado aún más, permitiendo una mayor personalización y adaptabilidad a diferentes temáticas.
En este post, te mostraremos cómo configurar y personalizar un asistente especializado en minerales críticos utilizando GPT-4 y fuentes de datos abiertas. Como ya mostramos en previas publicaciones, los minerales críticos son fundamentales para numerosas industrias, incluyendo la tecnología, la energía y la defensa, debido a sus propiedades únicas y su importancia estratégica. Sin embargo, la información sobre estos materiales puede ser compleja y dispersa, lo que hace que un asistente especializado sea particularmente útil.
El objetivo de este post es guiarte paso a paso desde la configuración inicial hasta la implementación de un asistente GPT que pueda ayudarte a resolver dudas y proporcionar información valiosa sobre minerales críticos en tu día a día. Además, exploraremos cómo personalizar aspectos del asistente, como el tono y el estilo de las respuestas, para que se adapte perfectamente a tus necesidades. Al final de este recorrido, tendrás una herramienta potente y personalizada que transformará la manera en que accedes y utilizas la información en abierto sobre minerales críticos.
Accede al repositorio del laboratorio de datos en Github
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
La transición hacia un futuro sostenible no solo implica cambios en las fuentes de energía, sino también en los recursos materiales que utilizamos. El éxito de sectores como baterías de almacenamiento de energía, aerogeneradores, paneles solares, electrolizadores, drones, robots, redes de transmisión de datos, dispositivos electrónicos o satélites espaciales, depende enormemente del acceso a las materias primas críticas para su desarrollo. Entendemos que un mineral es crítico cuando se cumplen los siguientes factores:
- Sus reservas mundiales son escasas
- No existen materiales alternativos que puedan ejercer su función (sus propiedades son únicas o muy singulares)
- Son materiales indispensables para sectores económicos clave de futuro, y/o su cadena de suministro es de elevado riesgo
Puedes aprender más sobre los minerales críticos en el post mencionado anteriormente.
3. Objetivo
Este ejercicio se centra en mostrar al lector cómo personalizar un modelo GPT especializado para un caso de uso concreto. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender cómo configurar y ajustar el modelo para resolver un problema real y relevante, como el asesoramiento experto en minerales críticos. Este enfoque práctico no solo mejora la comprensión de las técnicas de personalización de modelos de lenguaje, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
El asistente GPT especializado en minerales críticos estará diseñado para convertirse en una herramienta esencial para profesionales, investigadores y estudiantes. Su objetivo principal será facilitar el acceso a información precisa y actualizada sobre estos materiales, apoyar la toma de decisiones estratégicas y promover la educación en este campo. A continuación, se detallan los objetivos específicos que buscamos alcanzar con este asistente:
- Proporcionar información precisa y actualizada:
- El asistente debe ofrecer información detallada y precisa sobre diversos minerales críticos, incluyendo su composición, propiedades, usos industriales y disponibilidad.
- Mantenerse actualizado con las últimas investigaciones y tendencias del mercado en el ámbito de los minerales críticos.
- Asistir en la toma de decisiones:
- Proporcionar datos y análisis que puedan ayudar en la toma de decisiones estratégicas en la industria y la investigación sobre minerales críticos.
- Ofrecer comparativas y evaluaciones de diferentes minerales en función de su rendimiento, coste y disponibilidad.
- Promover la educación y la concienciación en torno a esta temática:
- Actuar como una herramienta educativa para estudiantes, investigadores y profesionales, ayudando a mejorar su conocimiento sobre los minerales críticos.
- Aumentar la conciencia sobre la importancia de estos materiales y los desafíos relacionados con su suministro y sostenibilidad.
4. Recursos
Para configurar y personalizar nuestro asistente GPT especializado en minerales críticos, es esencial disponer de una serie de recursos que faciliten la implementación y aseguren la precisión y relevancia de las respuestas del modelo. En este apartado, detallaremos los recursos necesarios que incluyen tanto las herramientas tecnológicas como las fuentes de información que serán integradas en la base de conocimiento del asistente.
Herramientas y Tecnologías
Las herramientas y tecnologías clave para desarrollar este ejercicio son:
- Cuenta de OpenAI: necesaria para acceder a la plataforma y utilizar el modelo GPT-4. En este post, utilizaremos la suscripción Plus de ChatGPT para mostrarte cómo crear y publicar un GPT personalizado. No obstante, puedes desarrollar este ejercicio de forma similar utilizando una cuenta gratuita de OpenAI y realizando el mismo conjunto de instrucciones a través de una conversación de ChatGPT estándar.
- Microsoft Excel: hemos diseñado este ejercicio de forma que cualquier persona sin conocimientos técnicos pueda desarrollarlo de principio a fin. Únicamente nos apoyaremos en herramientas ofimáticas como Microsoft Excel para realizar algunas adecuaciones de los datos descargados.
De forma complementaria, utilizaremos otro conjunto de herramientas que nos permitirán automatizar algunas acciones sin ser estrictamente necesaria su utilización:
- Google Colab: es un entorno de Python Notebooks que se ejecuta en la nube, permitiendo a los usuarios escribir y ejecutar código Python directamente en el navegador. Google Colab es especialmente útil para el aprendizaje automático, el análisis de datos y la experimentación con modelos de lenguaje, ofreciendo acceso gratuito a potentes recursos de computación y facilitando la colaboración y el intercambio de proyectos.
- Markmap: es una herramienta que visualiza mapas mentales de Markdown en tiempo real. Los usuarios escriben ideas en Markdown y la herramienta las renderiza como un mapa mental interactivo en el navegador. Markmap es útil para la planificación de proyectos, la toma de notas y la organización de información compleja visualmente. Facilita la comprensión y el intercambio de ideas en equipos y presentaciones.
Fuentes de Información
- Raw Materials Information System (RMIS): sistema de información sobre materias primas mantenido por el Joint Research Center de la Unión Europea. Proporciona datos detallados y actualizados sobre la disponibilidad, producción y consumo de materias primas en Europa.
- Catálogo de informes y datos de la Agencia Internacional de la Energía (IEA en sus siglas en inglés): ofrece un amplio catálogo de informes y datos relacionados con la energía, incluyendo estadísticas sobre producción, consumo y reservas de minerales energéticos y críticos.
- Base de datos de minerales del Instituto Geológico y Minero Español (BDMIN): contiene información detallada sobre los minerales y depósitos minerales en España, útil para obtener datos específicos sobre la producción y reservas de minerales críticos en el país.
Con estos recursos, estarás bien equipado para desarrollar un asistente GPT especializado que pueda proporcionar respuestas precisas y relevantes sobre minerales críticos, facilitando la toma de decisiones informadas en este campo.
5. Desarrollo del ejercicio
5.1. Construcción de la base de conocimiento
Para que nuestro asistente GPT especializado en minerales críticos sea verdaderamente útil y preciso, es esencial construir una base de conocimiento sólida y estructurada. Esta base de conocimiento será el conjunto de datos e información que el asistente utilizará para responder a las consultas. La calidad y relevancia de esta información determinarán la eficacia del asistente en proporcionar respuestas precisas y útiles.
Búsqueda de Fuentes de Datos
Comenzamos con la recopilación de fuentes de información que nutrirán nuestra base de conocimiento. No todas las fuentes de información son igualmente fiables. Es fundamental evaluar la calidad de las fuentes identificadas, asegurando que:
- La información esté actualizada: la relevancia de los datos puede cambiar con rapidez, especialmente en campos dinámicos como el de los minerales críticos.
- La fuente sea confiable y reconocida: es necesario utilizar fuentes de instituciones reconocidas y respetadas en el ámbito académico y profesional.
- Los datos sean completos y accesibles: es crucial que los datos sean detallados y que estén accesibles para su integración en nuestro asistente.
En nuestro caso, desarrollamos una búsqueda online en diferentes plataformas y repositorios de información tratando de seleccionar información perteneciente a diversas entidades reconocidas:
- Centros de investigación y universidades:
- Publican estudios y reportes detallados sobre la investigación y desarrollo de minerales críticos.
- Ejemplo: RMIS del Joint Research Center de la Unión Europea.
- Instituciones gubernamentales y organismos internacionales:
- Estas entidades suelen proporcionar datos exhaustivos y actualizados sobre la disponibilidad y el uso de minerales críticos.
- Ejemplo: Agencia Internacional de la Energía (IEA).
- Bases de datos especializadas:
- Contienen datos técnicos y específicos sobre depósitos y producción de minerales críticos.
- Ejemplo: Base de datos de Minerales del Instituto Geológico y Minero español (BDMIN).
Selección y preparación de la información
Nos centraremos ahora en la selección y preparación de la información existente en estas fuentes para asegurar que nuestro asistente GPT pueda acceder a datos precisos y útiles.
RMIS del Joint Research Center de la Unión Europea:
- Información seleccionada:
Seleccionamos el informe “Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU – A foresight study”. Se trata de un análisis de la cadena de suministro y la demanda de minerales en tecnologías y sectores estratégicos de la UE. Presenta un estudio detallado de las cadenas de suministro de materias primas críticas y pronostica la demanda de minerales hasta 2050.
- Preparación necesaria:
El formato del documento, PDF, permite la ingesta directa de la información por parte de nuestro asistente. No obstante, como se observa en la Figura 1, existe una tabla especialmente relevante en sus páginas 238-240 donde se analiza, para cada mineral, su riesgo de suministro, tipología (estratégico, crítico o no crítico) y las tecnologías clave que lo emplean. Decidimos, por ello, extraer esta tabla a un formato estructurado (CSV), de tal forma que dispongamos de dos piezas de información que pasarán a formar parte de nuestra base de conocimiento.

Figura 1: Tabla de minerales contenida en el PDF de JRC
Para extraer de forma programática los datos contenidos en esta tabla y transformarlos en un formato más fácilmente procesable, como CSV (comma separated values o valores separados por comas), utilizaremos un script de Python que podemos utilizar a través de la plataforma Google Colab (Figura 2).

Figura 2: Script Python para la extracción de datos del PDF de JRC desarrollado en plataforma Google Colab.
A modo de resumen, este script:
- Se apoya en la librería de código abierto PyPDF2, capaz de interpretar información contenida en ficheros PDF.
- Primero, extrae en formato texto (cadena de caracteres) el contenido de las páginas del PDF donde se encuentra la tabla de minerales eliminando todo el contenido que no se corresponde con la propia tabla.
- Posteriormente, recorre, línea a línea, la cadena de caracteres convirtiendo los valores en columnas de una tabla de datos. Sabremos que un mineral es utilizado en una tecnología clave si en la columna correspondiente de dicho mineral encontramos un número 1 (en caso contrario contendrá un 0).
- Por último, exporta dicha tabla a un fichero CSV para su posterior utilización.
Agencia Internacional de la Energía (IEA):
- Información seleccionada:
Seleccionamos el informe “Global Critical Minerals Outlook 2024”. Este proporciona una visión general de los desarrollos industriales en 2023 y principios de 2024, y ofrece perspectivas a medio y largo plazo para la demanda y oferta de minerales clave para la transición energética. También evalúa los riesgos para la fiabilidad, sostenibilidad y diversidad de las cadenas de suministro de minerales críticos.
- Preparación necesaria:
El formato del documento, PDF, nos permite la ingesta directa de la información por parte de nuestro asistente virtual. No realizaremos en este caso ninguna adecuación de la información seleccionada.
Base de Datos de Minerales del Instituto Geológico y Minero Español (BDMIN)
- Información seleccionada:
En este caso, utilizamos el formulario para seleccionar los datos existentes en esta base de datos en cuanto a indicios y yacimientos del ámbito de la metalogenia, en particular seleccionamos aquellos con contenido de Litio.

Figura 3: Selección de conjunto de datos en BDMIN.
- Preparación necesaria:
Observamos cómo la herramienta web nos permite la visualización online y también la exportación de estos datos en varios formatos. Seleccionamos, por tanto, todos los datos a exportar y haciendo clic en esta opción, descargamos un fichero Excel con la información deseada.

Figura 4: Herramienta de visualización y descarga en BDMIN

Figura 5: Datos descargados BDMIN.
Todos los archivos que componen nuestra base de conocimiento se encuentran GitHub del proyecto, de tal forma que aquel lector que lo desee pueda saltarse la fase de descarga y preparación de la información.
5.2. Configuración y personalización del GPT para minerales críticos
Cuando hablamos de "crear un GPT," en realidad nos estamos refiriendo a la configuración y personalización de un modelo de lenguaje basado en GPT (Generative Pre-trained Transformer) para adaptarlo a un caso de uso específico. En este contexto, no estamos creando el modelo desde cero, sino ajustando cómo el modelo preexistente (como GPT-4 de OpenAI) interactúa y responde dentro de un dominio específico, en este caso, sobre minerales críticos.
En primer lugar, accedemos a la aplicación a través de nuestro navegador y, en caso de no tener una cuenta, seguimos el proceso de registro y login en la plataforma ChatGPT. Como indicamos con anterioridad, para realizar la creación de un GPT paso a paso será necesario disponer de una cuenta Plus. No obstante, aquellos lectores que no dispongan de dicha cuenta, podrán trabajar con una cuenta gratuita interactuando con ChatGPT a través de una conversación estándar.
Figura 6: Página de inicio de sesión y registro de ChatGPT.
Una vez iniciada la sesión, seleccionamos la opción "Explorar GPT", y posteriormente hacemos clic en "Crear" para comenzar el proceso de creación de nuestro GPT.

Figura 7: Creación de nuevo GPT.
En pantalla se nos mostrará la pantalla dividida de creación de un nuevo GPT: a la izquierda podremos conversar con el sistema para indicarle las características que debe tener nuestro GPT, mientras que a la izquierda podremos interactuar con nuestro GPT para validar que su comportamiento es el adecuado según vayamos avanzando en el proceso de configuración.

Figura 8: Pantalla de creación de nuevo GPT.
En el GitHub de este proyecto, podemos encontrar todos los prompts o instrucciones que utilizaremos para configurar y personalizar nuestro GPT y que deberemos introducir de forma secuencial en la pestaña "Crear", situada en la pestaña izquierda de nuestras pantallas, para completar los pasos que se detallan a continuación.
Los pasos que vamos a seguir para la creación del GPT son:
- En primer lugar, le indicaremos el objetivo y las consideraciones básicas a nuestro GPT para que pueda entender su modo de empleo.
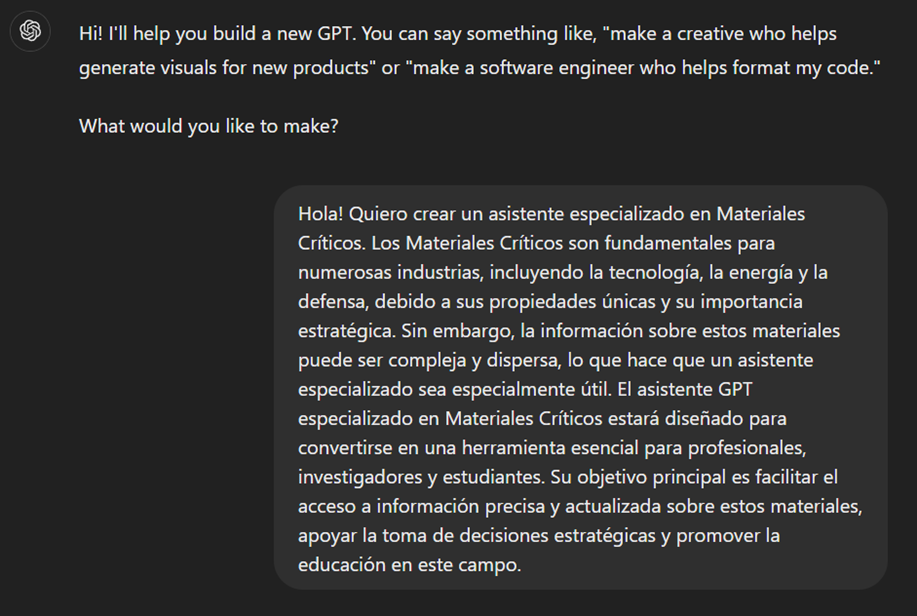
Figura 9: Instrucciones básicas de nuevo GPT.
2. Posteriormente crearemos un nombre y una imagen que representen a nuestro GPT y lo hagan fácilmente identificable. En nuestro caso, lo denominaremos MateriaGuru.

Figura 10: Selección de nombre para nuevo GPT.

Figura 11: Creación de imagen para GPT.
3. A continuación, construiremos la base de conocimiento a partir de la información anteriormente seleccionada y preparada para nutrir los conocimientos de nuestro GPT.


Figura 12: Carga de información a la base de conocimiento de nuevo GPT.
4. Ahora, podemos personalizar aspectos conversacionales como su tono, el nivel de complejidad técnica de sus repuesta o si esperamos respuestas escuetas o elaboradas.
5. Por último, desde la pestaña "Configurar", podemos indicar los iniciadores de conversación deseados para que los usuarios que interactúen con nuestro GPT tengan algunas ideas para empezar la conversación de forma predefinida.

Figura 13: Pestaña Configurar GPT.
En la Figura 13 podemos también observar el resultado definitivo de nuestro entrenamiento, donde aparecen elementos clave como su imagen, nombre, instrucciones, iniciadores de conversación o documentos que forma parte de su base de conocimiento.
5.3. Validación y publicación de GPT
Antes de dar por bueno a nuestro nuevo asistente basado en GPT, procederemos a realizar una breve validación de su correcta configuración y aprendizaje respecto a la temática en torno a la que le hemos entrenado. Para ello, preparamos una batería de preguntas que le realizaremos para comprobar que responde de forma adecuada ante un escenario real de utilización.
| # | Pregunta | Respuesta |
|---|---|---|
| 1 | ¿Qué minerales críticos han experimentado una caída significativa en los precios en 2023? | Los precios de los minerales para baterías vieron particularmente grandes caídas con los precios del litio cayendo un 75% y los precios del cobalto níquel y grafito cayendo entre un 30% y un 45%. |
| 2 | ¿Qué porcentaje de la capacidad solar fotovoltaica (PV) mundial fue añadido por China en 2023? | China representó el 62% del aumento en la capacidad solar fotovoltaica global en 2023. |
| 3 | ¿Cuál es el escenario que proyecta que las ventas de autos eléctricos (EV) alcanzarán el 65% en 2030? | El escenario de emisiones netas cero (NZE) para 2050 proyecta que las ventas de autos eléctricos alcanzarán el 65% en 2030. |
| 4 | ¿Cuál fue el crecimiento de la demanda de litio en 2023? | La demanda de litio aumentó en un 30% en 2023. |
| 5 | ¿Qué país fue el mayor mercado de autos eléctricos en 2023? | China fue el mayor mercado de autos eléctricos en 2023 con 8.1 millones de ventas de autos eléctricos representando el 60% del total global. |
| 6 | ¿Cuál es el principal riesgo asociado con la concentración de mercado en la cadena de suministro de grafito para baterías? | Más del 90% del grafito de grado batería y el 77% de las tierras raras refinadas en 2030 se originan en China lo que representa un riesgo significativo para la concentración del mercado. |
| 7 | ¿Qué proporción de la capacidad mundial de producción de celdas de batería estaba en China en 2023? | China poseía el 85% de la capacidad de producción de celdas de batería en 2023. |
| 8 | ¿Cuánto aumentó la inversión en minería de minerales críticos en 2023? | La inversión en minería de minerales críticos creció un 10% en 2023. |
| 9 | ¿Qué porcentaje de la capacidad de almacenamiento de baterías en 2023 estaba compuesto por baterías de fosfato de hierro y litio (LFP)? | En 2023, las baterías LFP constituían aproximadamente el 80% del mercado total de almacenamiento de baterías. |
| 10 | ¿Cuál es el pronóstico para la demanda de cobre en un escenario de emisiones netas cero (NZE) para 2040? | En el escenario de emisiones netas cero (NZE) para 2040 se espera que la demanda de cobre tenga el mayor aumento en términos de volumen de producción. |
Figura 14: Tabla con batería de preguntas para la validación de nuestro GPT.
Valiéndonos de la parte de previsualización, situada a la derecha de nuestras pantallas, lanzamos la batería de preguntas y validamos que las respuestas se corresponden con aquellas esperadas.

Figura 15: Validación de respuestas GPT.
Por último, hacemos clic en el botón "Crear" para finalizar el proceso. Podremos seleccionar entre diferentes alternativas para restringir su utilización por parte de otros usuarios.

Figura 16: Publicación de nuestro GPT.
6. Escenarios de uso
En este apartado mostramos varios escenarios en los que podremos sacar partido a MateriaGuru en nuestro día a día. En el GitHub del proyecto podremos encontrar los prompts utilizados para replicar cada uno de ellos.
6.1. Consulta de información de minerales críticos
El escenario más típico de utilización de este tipo de GPTs es la asistencia para resolución de dudas relacionadas con la temática en cuestión, en este caso, los minerales críticos. A modo de ejemplo, hemos preparado una batería de cuestiones que el lector podrá plantear al GPT creado para comprender en mayor detalle la relevancia y situación actual de un material crítico como es el grafito a partir de los informes provistos a nuestro GPT.

Figura 17: Resolución de dudas de minerales críticos.
También podemos plantearle preguntas concretas sobre la información tabulada provista respecto a los yacimientos e indicios existentes en el territorio español.
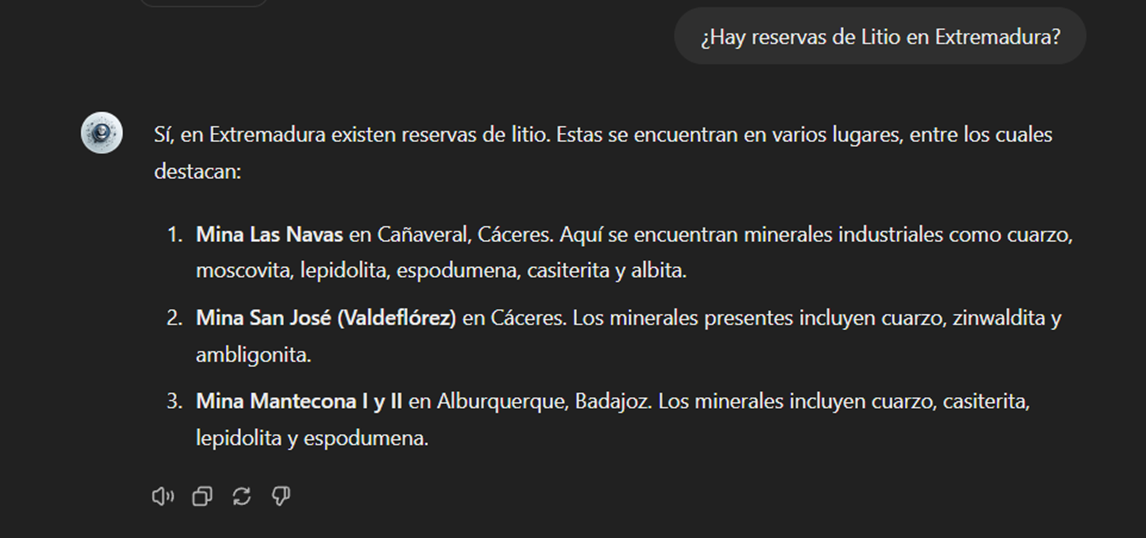
Figura 18: Reservas de litio en Extremadura.
6.2. Representación de visualizaciones de datos cuantitativos
Otro escenario común, es la necesidad de consultar información cuantitativa y realizar representaciones visuales para su mejor entendimiento. En este escenario, podemos observar cómo MateriaGuru es capaz de generar una visualización interactiva de la producción de grafito en toneladas de los principales países productores.

Figura 19: Generación de visualización interactiva con nuestro GPT.
6.3. Generación de mapas mentales para facilitar la comprensión
Por último, en línea con la búsqueda de alternativas para un mejor acceso y comprensión del conocimiento existente en nuestro GPT, plantearemos a MateriaGuru la construcción de un mapa mental que nos permita entender de una forma visual conceptos clave de los minerales críticos. Para ello, utilizamos la notación abierta Markmap (Markdown Mindmap), que nos permite definir mapas mentales utilizando notación markdown.

Figura 20: Generación de mapas mentales desde nuetro GPT.
Deberemos copiar el código generado e introducirlo en un visualizador de markmap para poder generar el mapa mental deseado. Facilitamos aquí una versión de este código generada por MateriaGuru.

Figura 21: Visualización de mapas mentales.
7. Resultados y conclusiones
En el ejercicio de construcción de un asistente experto utilizando GPT-4, hemos logrado crear un modelo especializado en minerales críticos. Este asistente proporciona información detallada y actualizada sobre minerales críticos, apoyando la toma de decisiones estratégicas y promoviendo la educación en este campo. Primero recopilamos información de fuentes confiables como el RMIS, la Agencia Internacional de la Energía (IEA), y el Instituto Geológico y Minero Español (BDMIN). Posteriormente, procesamos y estructuramos los datos adecuadamente para su integración en el modelo. Las validaciones demostraron que el asistente responde de manera precisa a preguntas relevantes del dominio, facilitando el acceso a su información.
De esta forma, el desarrollo del asistente especializado en minerales críticos ha demostrado ser una solución efectiva para centralizar y facilitar el acceso a información compleja y dispersa.
La utilización de herramientas como Google Colab y Markmap ha permitido una mejor organización y visualización de los datos, aumentando la eficiencia en la gestión del conocimiento. Este enfoque no solo mejora la comprensión y el uso de la información sobre minerales críticos, sino que también prepara a los usuarios para aplicar estos conocimientos en contextos reales.
La experiencia práctica adquirida en este ejercicio es directamente aplicable a otros proyectos que requieran la personalización de modelos de lenguaje para casos de uso específicos.
8. ¿Quieres realizar el ejercicio?
Si quieres replicar este ejercicio, accede a este repositorio donde encontrarás más información (las prompt utilizadas, el código generado por MateriaGuru, etc.)
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En el vasto panorama tecnológico, pocas herramientas han marcado una huella tan profunda como Google Maps. Desde sus inicios, esta aplicación se convirtió en el estándar de búsqueda y navegación de puntos de interés en mapas. Pero, ¿qué sucede cuando buscamos opciones más allá de la omnipresente aplicación de mapas? En este post repasamos posibles alternativas a la conocida aplicación de Google.
Introducción
A principios de 2005, el blog oficial de Google publicó una breve nota de prensa en la que presentaron su última creación: Google Maps. Para hacernos a la idea que cómo era el año 2005, tecnológicamente hablando, basta con mirar los terminales móviles más rompedores aquel año:

Créditos de las imágenes: Cinco móviles que marcaron el año 2005
Algunos todavía recordamos cómo era la experiencia (o ausencia de experiencia) de ejecutar apps en estos terminales. Pues bien, en ese año se lanza la primera versión de Google Maps que nos permitía buscar restaurantes, hoteles y otros elementos cerca de nuestra ubicación, así como averiguar la ruta más óptima para ir del punto A al punto B sobre una versión digital de un mapa de nuestra ciudad. Además, ese mismo año, también se lanza Google Earth, que supuso un verdadero hito tecnológico al facilitar el acceso para casi todos los ciudadanos del mundo a imagen satelital.
Desde entonces, el ecosistema digital de mapas y navegación de Google, con su interfaz intuitiva y las innovadoras funciones de realidad aumentada, ha sido un faro que guía a millones de usuarios en sus viajes diarios.
Pero, ¿y si buscamos algo diferente? ¿Qué alternativas existen para aquellos que desean explorar nuevos horizontes? Acompáñanos en este viaje en el que nos aventuramos en el fascinante mundo de sus competidores. Desde opciones más especializadas hasta aquellas que priorizan la privacidad, descubriremos juntos las diversas rutas que podemos tomar en el vasto paisaje de la navegación digital.
Alternativas a Google Maps
Casi seguro que algunos de vosotros, lectores, habéis visto o utilizado alguna de las alternativas a Google Maps de código abierto, aunque a lo mejor no lo sabes. Por citar solo algunas de las alternativas más conocidas:
1. OpenStreetMap (OSM): OpenStreetMap es un proyecto colaborativo que crea un mapa del mundo editable por la comunidad. Ofrece datos geoespaciales abiertos y libres que pueden ser utilizados para diversas aplicaciones, desde navegación hasta análisis urbanos.
2. uMap: uMap es una herramienta online que permite a los usuarios crear mapas personalizados con capas de OpenStreetMap. Es fácil de usar y ofrece opciones de personalización, lo que la convierte en una opción popular para la creación rápida de mapas interactivos.
3. GraphHopper: GraphHopper es una solución para la creación de rutas de código abierto que utiliza datos de OpenStreetMap. Destaca por su capacidad para calcular rutas eficientes para vehículos, bicicletas y peatones, y puede ser utilizado como parte de aplicaciones personalizadas.
4. Leaflet: Leaflet es una librería de código abierto en JavaScript para mapas interactivos compatibles con dispositivos móviles. Es probablemente la librería más extendida por su bajo peso en KB y porque incluye todas las funciones de cartografía que la mayoría de los desarrolladores puedan necesitar.
5. Overture Maps: Mientras que las cuatro soluciones anteriores ya están ampliamente establecidas en el mercado, Overture Maps es un nuevo player. Se trata de un proyecto colaborativo para crear mapas abiertos interoperables.
De todas ellas, vamos a centrarnos en OpenStreetMap (OSM) y Overture Maps.
Open Street Maps: una herramienta colaborativa y abierta
De las citadas soluciones anteriores, probablemente, la más extendida y conocida sea Open Street Maps.
OpenStreetMap (OSM) destaca como una de las mejores alternativas a Google Maps de código abierto por varias razones:
-
En primer lugar, la característica fundamental de OpenStreetMap radica en su naturaleza colaborativa y abierta, donde una comunidad global contribuye a la creación y actualización constante de datos geoespaciales.
-
Además, OpenStreetMap proporciona datos libres y accesibles que pueden ser utilizados de manera flexible en una amplia gama de aplicaciones y proyectos. Citando literalmente su web, se puede leer: OpenStreetMap es datos abiertos: eres libre de usarlo para cualquier propósito siempre y cuando acredites a OpenStreetMap y a sus colaboradores. Si modificas o construyes sobre los datos de ciertas maneras, puedes distribuir el resultado solo bajo la misma licencia. Consulta la página de Derechos de Autor y Licencia para obtener más detalles.
-
La capacidad para personalizar mapas y la flexibilidad de integración de OpenStreetMap son también características muy destacadas. Los desarrolladores pueden adaptar fácilmente los mapas a las necesidades específicas de sus aplicaciones, aprovechando la API de OpenStreetMap. Esta es la clave del desarrollo de un ecosistema de aplicaciones alrededor de OSM cómo uMap, Leaflet o GraphHopper, entre otras muchas.
Overture Maps. Un competidor singular
Quizás, uno de los proyectos más prometedores que haya aparecido recientemente en la escena tecnológica mundial sea Overture Maps. Como indican (el pasado julio de este año) desde su fundación (OMF Overture Maps Foundation), se ha liberado el lanzamiento de su primer conjunto de datos abiertos, marcando un hito significativo en el esfuerzo colaborativo para crear productos de mapas abiertos interoperables. La primera versión Overture incluye cuatro capas de datos únicas:
-
Lugares de Interés (POIs)
-
Edificaciones
-
Red de Transporte
-
Límites Administrativos

Ejemplo de cobertura de lugares públicos en todo el mundo identificados en el dataset inicial del proyecto. La primera versión del paquete de datos de overture maps contiene, entre otros, 59 millones de registros de puntos de interés, 780 millones de edificios, redes de transporte y límites administrativos nacionales y regionales en todo el mundo.
Estas capas, que fusionan diversas fuentes de datos de mapas abiertos, se han validado y contrastado a través de controles de calidad y se lanzan bajo el esquema de datos de Overture Maps, hecho público en junio de 2023. En concreto, la capa de Lugares de Interés incluye datos sobre más de 59 millones de lugares en todo el mundo. Este conjunto de datos se presenta como un elemento fundamental para la navegación, la búsqueda local y para diversas aplicaciones basadas en la ubicación. Las otras tres capas incluyen información detallada sobre edificaciones (con más de 780 millones de huellas de edificaciones en todo el mundo), una red de transporte global derivada del proyecto OpenStreetMap y límites administrativos a nivel mundial con nombres regionales traducidos a más de 40 idiomas.
Uno de los datos más significativos de este anuncio quizás sea el de los colaboradores que se han unido para realizar este proyecto. La colaboración de Overture, fundada en diciembre de 2022 por Amazon Web Services (AWS), Meta, Microsoft y TomTom, ahora cuenta con más de una docena de empresas tecnológicas y del sector geoespacial, incluyendo nuevos miembros como Esri, Cyient, InfraMappa, Nomoko, Precisely, PTV Group, SafeGraph, Sanborn y Sparkgeo. La premisa central de esta colaboración es la necesidad de compartir datos de mapas como un activo común para respaldar futuras aplicaciones.
Como buen proyecto de código abierto, la fundación Overture ha puesto a disposición de la comunidad de desarrollo un repositorio de Github donde poder contribuir al proyecto.
En definitiva, los mapas digitales, sus correspondientes capas de datos geoespaciales, las capacidades de navegación y foto-geolocalización son activos vitales y estratégicos para las organizaciones sociales y tecnológicas alrededor del mundo. Ahora, cuando queda muy poco para el 20 aniversario del nacimiento de Google Maps, existen buenas alternativas de código abierto y los grandes actores del panorama tecnológico internacional se unen para generar aún activos espaciales de mayor valor. ¿Quién ganará esta nueva carrera? No lo sabemos, pero seguiremos muy de cerca las noticias de actualidad sobre este tema.