





Unity Catalog: Potenciando la colaboración en el ecosistema Data e IA mediante código abierto


Fecha del documento: 11-07-2025

La compartición de datos o data sharing se ha convertido en un pilar imprescindible para el avance de la analítica y el intercambio de conocimiento, tanto en el ámbito privado como en el público. Las organizaciones de cualquier tamaño y sector –empresas, administraciones públicas, instituciones de investigación, comunidades de desarrolladores o individuos– encuentran un fuerte valor en la capacidad de compartir información de forma segura, fiable y eficiente. Este intercambio no se limita a datos en crudo o datasets estructurados; también se extiende a productos de datos más avanzados, tales como modelos de machine learning entrenados, dashboards analíticos, resultados de experimentos científicos y otros artefactos complejos que generan un gran impacto a través de su reutilización.
En este contexto, la importancia de la gobernanza de estos recursos cobra un papel crítico. No es suficiente con disponer de un método para mover ficheros de un sitio a otro; es necesario garantizar aspectos clave como el control de acceso (quién puede leer o modificar cierto recurso), la trazabilidad y la auditoría (saber quién ha accedido, cuándo y con qué finalidad) o el cumplimiento de regulaciones o estándares, especialmente en entornos empresariales y gubernamentales.
Con el fin de unificar estos requisitos, Unity Catalog surge como un almacén de metadatos (metastore) de próxima generación, pensado para centralizar y simplificar la gobernanza de datos y recursos de datos. Originalmente, Unity Catalog formaba parte de los servicios ofrecidos por la plataforma Databricks, pero el proyecto ha dado un salto a la comunidad de código abierto para convertirse en un estándar de referencia. Esto implica que ahora es posible utilizarlo, modificarlo y, en definitiva, contribuir a su evolución desde un entorno libre y colaborativo. Con ello, se espera que más organizaciones adopten sus modelos de catálogo y compartición, impulsando la reutilización de datos y la creación de flujos analíticos e innovaciones tecnológicas.

Fuente: https://docs.unitycatalog.io/
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Objetivos
En este ejercicio, aprenderemos a configurar Unity Catalog, una herramienta que nos ayuda a organizar y compartir datos en la nube de manera segura. Aunque utilizaremos algo de código, explicaremos cada paso para que incluso personas con poca experiencia en programación puedan seguirlo a través de un laboratorio práctico.
Trabajaremos con un escenario realista donde gestionaremos datos sobre transporte público en diferentes ciudades. Crearemos catálogos de datos, configuraremos una base de datos y aprenderemos a interactuar con la información usando herramientas como Docker, Apache Spark y MLflow.
Nivel de dificultad: Intermedio.

Figura 1. Esquema Unity Catalog
Recursos Necesarios
En esta sección explicaremos los requisitos previos y recursos necesarios para poder desarrollar este laboratorio. El laboratorio está pensado para desarrollarse en un ordenador personal estándar (Windows, MacOS, Linux).
Adicionalmente utilizaremos las siguientes herramientas y entornos de trabajo:
- Docker Desktop: Docker es una herramienta que nos permite ejecutar aplicaciones en un entorno aislado llamado contenedor. Un contenedor es como una "caja" que contiene todo lo necesario para que una aplicación funcione correctamente, sin importar el sistema operativo que estés usando.
- Visual Studio Code: Nuestro entorno de trabajo será un Notebook Python que ejecutaremos y manipularemos a través del editor de código ampliamente utilizado Visual Studio Code (VS Code).
- Unity Catalog: Es una herramienta de gobernanza de datos que permite organizar y controlar el acceso a recursos como tablas, volúmenes de datos, funciones o modelos de machine learning. A lo largo del laboratorio, utilizaremos su versión open source, que puede desplegarse localmente, para aprender a gestionar catálogos de datos con control de permisos, trazabilidad y estructura jerárquica. Unity Catalog actúa como un metastore centralizado, facilitando la colaboración y la reutilización de datos de forma segura.
- Amazon Web Services: AWS será el proveedor cloud que utilizaremos para alojar ciertos datos del laboratorio, en concreto los datos en crudo (como archivos JSON) que gestionaremos mediante volúmenes de datos. Aprovecharemos su servicio Amazon S3 para almacenar estos archivos y configuraremos las credenciales y permisos necesarios para que Unity Catalog pueda interactuar con ellos de forma controlada.
Desarrollo del ejercicio
A lo largo del ejercicio, los participantes desplegarán la aplicación, comprenderán su arquitectura e irán construyendo un catálogo de datos paso a paso, aplicando buenas prácticas de organización, control de acceso y trazabilidad.
Despliegue y primeros pasos
-
Clonamos el repositorio de Unity Catalog y lo levantamos con Docker.
-
Exploramos su arquitectura: un backend accesible por API y CLI, y una interfaz gráfica intuitiva.
- Navegamos por los recursos que gestiona Unity Catalog: catálogos, esquemas, tablas, volúmenes, funciones y modelos.
Figura 2. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo levantar la aplicación, sus componentes principales, y cómo empezar a interactuar con ella desde distintos puntos: web, API y CLI.
Organización de recursos
-
Configuramos una base de datos MySQL externa como repositorio de metadatos.
-
Creamos catálogos para representar distintas ciudades y esquemas para distintos servicios públicos.

Figura 3. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo estructurar el gobierno de datos a distintos niveles (ciudad, servicio, dataset) y cómo gestionar los metadatos de forma centralizada y persistente.
Construcción de datos y uso real
-
Creamos tablas estructuradas para representar rutas, autobuses o paradas.
-
Cargamos datos reales en estas tablas usando PySpark.Habilitamos un bucket en AWS S3 como almacenamiento de datos en crudo (volúmenes).
- Subimos ficheros JSON con eventos de telemetría y los gobernamos desde Unity Catalog.
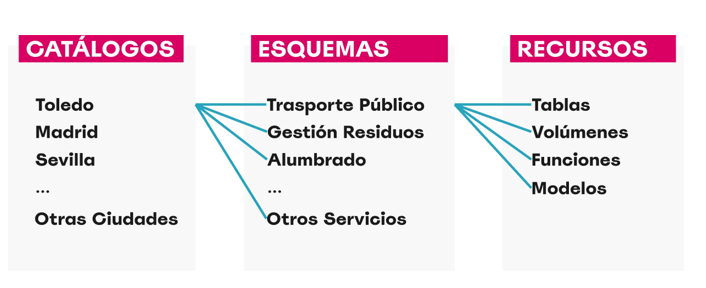
Figura 4. Esquema
¿Qué aprenderemos aquí?
Cómo convivir con distintos tipos de datos (estructurados y no estructurados), y cómo integrarlos con fuentes externas (como AWS S3).
Funciones reutilizables y modelos de IA
-
Registramos funciones personalizadas (como el cálculo de distancias) reutilizables desde el catálogo.
-
Creamos y registramos modelos de machine learning con MLflow.
- Ejecutamos predicciones desde Unity Catalog como si fueran cualquier otro recurso del ecosistema.
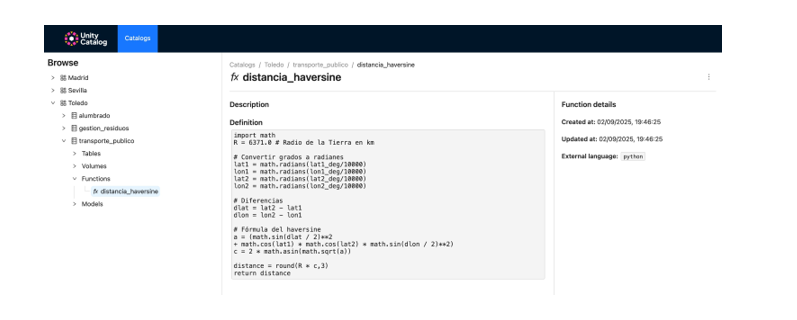
Figura 5. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo ampliar el gobierno de datos a funciones y modelos, y cómo facilitar su reutilización y trazabilidad en entornos colaborativos.
Resultados y conclusiones
Como resultado de este laboratorio práctico, vamos a poner conocer la herramienta Unity Catalog como plataforma abierta para la gobernanza de datos y recursos de datos como modelos de machine learning. Exploraremos, además, el contexto de un caso de uso concreto y con un ecosistema de herramientas similar al que podemos encontrar en una organización real, sus capacidades, su modo de despliegue y su uso.
Mediante este ejercicio configuraremos y utilizaremos Unity Catalog para organizar datos de transporte público. En concreto, podrás:
- Aprender a instalar herramientas como Docker o Spark.
- Crear catálogos, esquemas y tablas en Unity Catalog.
- Cargar datos y almacenarlos en un bucket de Amazon S3.
- Implementar un modelo de machine learning con MLflow.
Veremos, en los próximos años, si este tipo de herramientas alcanzan el nivel de estandarización necesario para transformar la forma en que se administran y comparten los recursos de datos en múltiples sectores.
¡Te animamos a realizar más ejercicios de ciencia de datos! Accede al repositorio aquí
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.













