Publication date
24/09/2021
Update date
20/06/2024

Description
Life happens in real time and much of our life, today, takes place in the digital world. Data, our data, is the representation of how we live hybrid experiences between the physical and the virtual. If we want to know what is happening around us, we must analyze the data in real time. In this post, we explain how.
Introduction
Let's imagine the following situation: we enter our favorite online store, we search for a product we want and we get a message on the screen saying that the price of the product shown is from a week ago and we have no information about the current price of the product. Someone in charge of the data processes of that online store could say that this is the expected behavior since the price database uploads from the central system to the e-commerce are weekly. Fortunately, this online experience is unthinkable today in an e-commerce, but far from what you might think, it is a common situation in many other processes of companies and organizations. It has happened to all of us that being registered in a database of a business, when we go to a store different from our usual one, opps, it turns out that we are not listed as customers. Again, this is because the data processing (in this case the customer database) is centralized and the loads to peripheral systems (after-sales service, distributors, commercial channel) are done in batch mode. This, in practice, means that data updates can take days or even weeks.
In the example above, batch mode thinking about data can unknowingly ruin the experience of a customer or user. Batch thinking can have serious consequences such as: the loss of a customer, the worsening of the brand image or the loss of the best employees.
Benefits of using real-time data
There are situations in which data is simply either real-time or it is not. A very recognizable example is the case of transactions, banking or otherwise. We cannot imagine that payment in a store does not occur in real time (although sometimes the payment terminals are out of coverage and this causes annoying situations in physical stores). Nor can (or should) it happens that when passing through a toll booth on a highway, the barrier does not open in time (although we have probably all experienced some bizarre situation in this context).
However, in many processes and situations it can be a matter of debate and discussion whether to implement a real-time data strategy or simply follow conventional approaches, trying to have a time lag in (data) analysis and response times as low as possible. Below, we list some of the most important benefits of implementing real-time data strategies:
- Immediate reaction to an error. Errors happen and with data it is no different. If we have a real-time monitoring and alerting system, we will react before it is too late to an error.
- Drastic improvement in the quality of service. As we have mentioned, not having the right information at the time it is needed can ruin the experience of our service and with it the loss of customers or potential customers. If our service fails, we must know about it immediately to be able to fix it and solve it. This is what makes the difference between organizations that have adapted to digital transformation and those that have not.
- Increasing sales. Not having the data in real time, can make you lose a lot of money and profitability. Let's imagine the following example, which we will see in more detail in the practical section. If we have a business in which the service we provide depends on a limited capacity (a chain of restaurants, hotels or a parking lot, for example) it is in our interest to have our occupancy data in real time, since this means that we can sell our available service capacity more dynamically.
The technological part of real time
For years, data analysis was originally conceived in batch mode. Historical data loads, every so often, in processes that are executed only under certain conditions. The reason is that there is a certain technological complexity behind the possibility of capturing and consuming data at the very moment it is generated. Traditional data warehouses, (relational) databases, for example, have certain limitations for working with fast transactions and for executing operations on data in real time. There is a huge amount of documentation on this subject and on how technological solutions have been incorporating technology to overcome these barriers. It is not the purpose of this post to go into the technical details of the technologies to achieve the goal of capturing and analyzing data in real time. However, we will comment that there are two clear paradigms for building real-time solutions that need not be mutually exclusive.
- Solutions based on classic mechanisms and flows of data capture, storage (persistence) and exposure to specific consumption channels (such as a web page or an API).
- Solutions based on event-driven availability mechanisms, in which data is generated and published regardless of who and how it will be consumed.
A practical example
As we usually do in this type of posts, we try to illustrate the topic of the post with a practical example with which the reader can interact. In this case, we are going to use an open dataset from the datos.gob.es catalog. In particular, we are going to use a dataset containing information on the occupancy of public parking spaces in the city center of Malaga. The dataset is available at this link and can be explored in depth through this link. The data is accessible through this API. In the description of the dataset it is indicated that the update frequency is every 2 minutes. As mentioned above, this is a good example in which having the data available in real time[1] has important advantages for both the service provider and the users of the service. Not many years ago it was difficult to think of having this information in real time and we were satisfied with aggregated information at the end of the week or month on the evolution of the occupancy of parking spaces.
From the data set we have built an interactive app where the user can observe in real time the occupancy level through graphic displays. The reader has at his disposal the code of the example to reproduce it at any time.
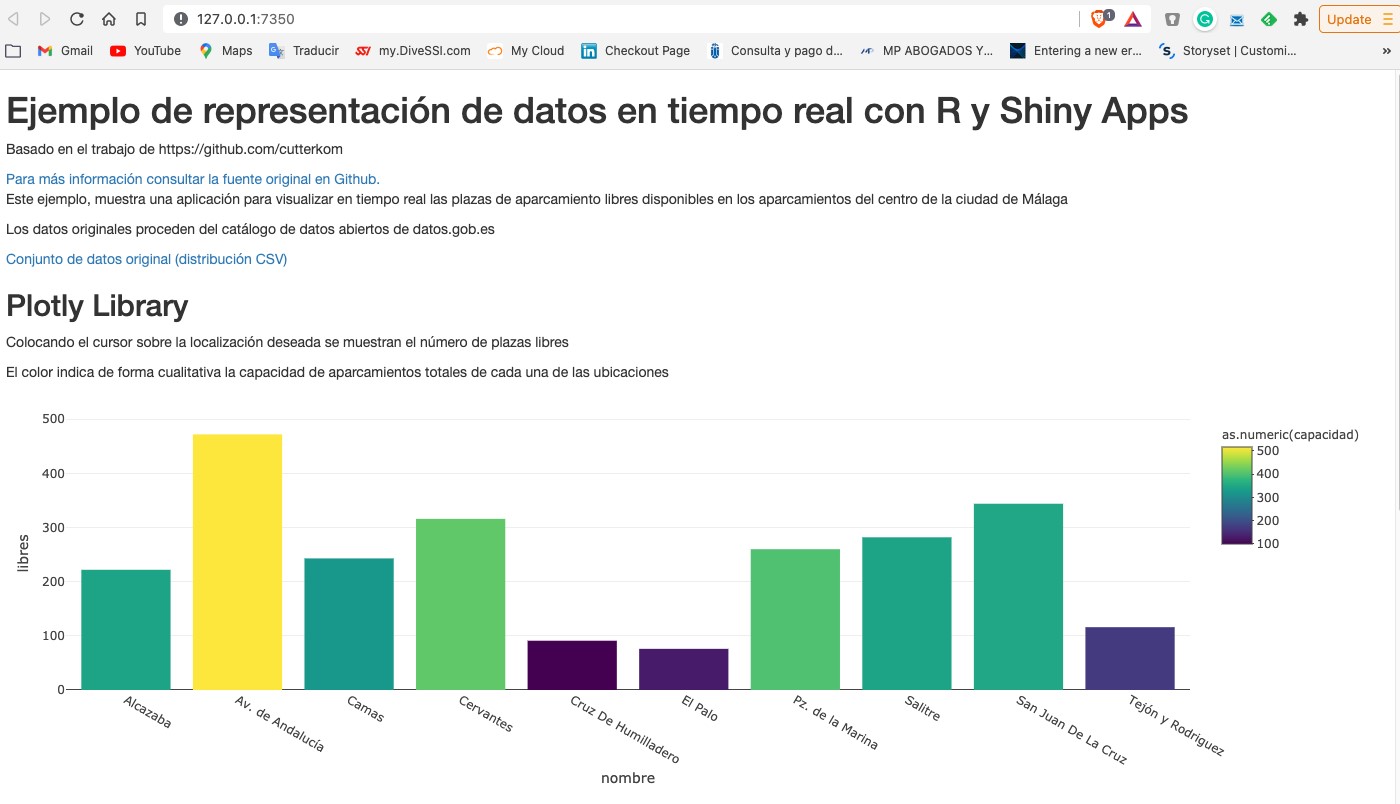
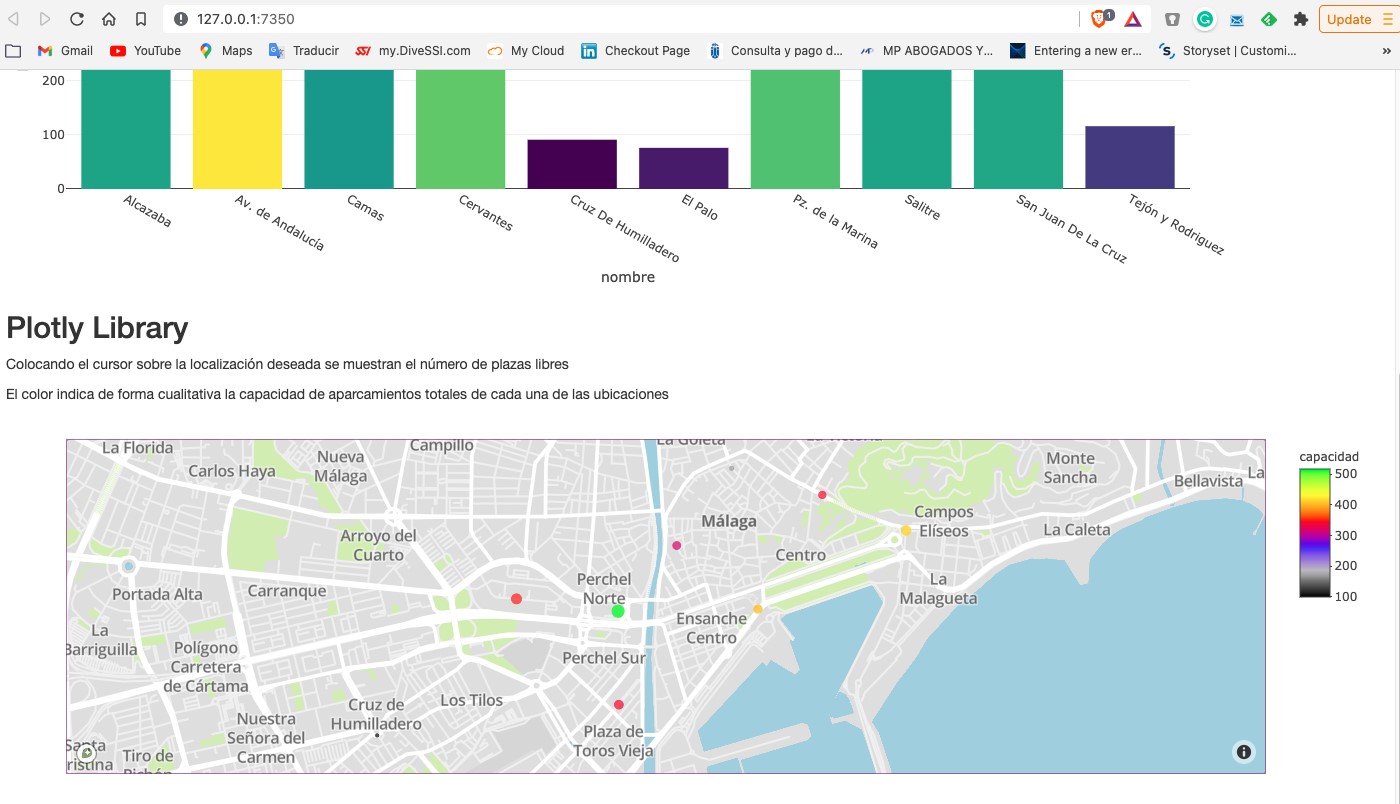
In this example, we have seen how, from the moment the occupancy sensors communicate their status (free or occupied) until we consume the data in a web application, this same data has gone through several systems and even had to be converted to a text file to expose it to the public. A much more efficient system would be to publish the data in an event broker that can be subscribed to with real-time technologies. In any case, through this API we are able to capture this data in real time and represent it in a web application ready for consumption and all this with less than 150 lines of code. Would you like to try it?
In conclusion, the importance of real-time data is now fundamental to most processes, not just space management or online commerce. As the volume of real-time data increases, we need to shift our thinking from a batch perspective to a real-time first mindset. That is, let's think directly that data must be available for real-time consumption from the moment it is generated, trying to minimize the number of operations we do with it before we can consume it.
[1] The term real time can be ambiguous in certain cases. In the context of this post, we can consider real time to be the characteristic data update time that is relevant to the particular domain we are working in. For example, in this use case an update rate of 2 min is sufficient and can be considered real time. If we were analysing a use case of stock quotes the concept of real time would be in the order of seconds.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Comments