





From theory to practice: creating a RAG-based conversational agent.


Fecha del documento: 06-02-2025

Introduction
In previous content, we have explored in depth the exciting world of Large Language Models (LLM) and, in particular, the Retrieval Augmented Generation (RAG) techniques that are revolutionising the way we interact with conversational agents. This exercise marks a milestone in our series, as we will not only explain the concepts, but also guide you step-by-step in building your own RAG-powered conversational agent. For this, we will use a Google Colabnotebook.
Access the data lab repository on Github.
Execute the data pre-processing code on Google Colab.
Through this notebook, we will build a chat that uses RAG to improve its responses, starting from scratch. The notebook will guide the user through the whole process:
- Installation of dependencies.
- Setting up the environment.
- Integration of a source of information in the form of a post.
- Incorporation of this source into the chat knowledge base using RAG techniques.
- Finally, we can see how the model's response changes before and after providing the post and asking a specific question about its content.
Tools used
Before starting, it is necessary to introduce and explain which tools we have used and why we have chosen them. For the construction of this RAG application we have used 3 pieces of technology or tools: Google Colab, OpenAI y LangChain. Both Google Colab and OpenAI are old acquaintances and we have used them several times in previous content. Therefore, in this section, we pay special attention to explaining what LangChain is, as it is a new tool that we have not used in previous posts.
- Google Colab. As usual in our exercises, when computing resources are needed, as well as a user-friendly programming environment, we use Google Colab, as far as possible. Google Colab guarantees that any user who wants to reproduce the exercise can do so without complications derived from the configuration of the particular environments of each programmer. It should be noted that adapting this exercise inspired by previous resources available in LangChain to the Google Colab environment has been a challenge.
- OpenAI. As a provider of the Chat GPT large language model (LLM), OpenAI offers a variety of powerful language models, such as GPT-4, GPT-4o, GPT-4o mini, etc. that are used to process and generate natural language text. In this case, the OpenAI language model is used in the answer generation area, where the user's question and the retrieved documents are combined to produce an accurate answer.
- LangChain. It is an open source framework (set of libraries) designed to facilitate the development of large-scale language model (LLM) based applications. This framework is especially useful for integrating and managing complex flows that combine multiple components, such as language models, vector databases, and information retrieval tools, among others.
LangChain is widely used in the development of applications such as:
- Question and answer systems (QA systems).
- Virtual assistants with specific knowledge.
- Customised text generation systems.
- Data analysis tools based on natural language.
Key features of LangChain
- Modularity and flexibility. LangChain is designed with a modular architecture that allows developers to connect different tools and services. This includes language models (such as OpenAI, Hugging Face, or local LLM) and vector databases (such as Pinecone, ChromaDB or Weaviate). The List of chat models that can be interacted with through Langchain is extensive.
- Support for AGR (Generation Augmented Retrieval) techniques. Langhain facilitates the implementation of RAG techniques by enabling the direct integration of information retrieval and text generation models. This improves the accuracy of responses by enabling LLMs to work with up-to-date and specific knowledge.
- Optimising the handling of prompts. Langhain helps to design and manage complex prompts efficiently. It allows to dynamically build a relevant context that works with the model, optimising the use of tokens and ensuring that responses are accurate and useful.
- Tokens represent the basic units that an AI model uses to process text. A token can be a whole word, a part of a word or a punctuation mark. In the sentence "Hello world!" there are, for example, four different tokens: "Hello", "Hello", "World", "! Text processing requires more computational resources as the number of tokens increases. Free versions of AI models, including the one we use in this exercise, set limits on the number of tokens that can be processed.
- Integrate multiple data sources. The framework can connect to various data sources, such as databases, APIs or user uploaded documents. This makes it ideal for building applications that need access to large volumes of structured or unstructured information.
- Interoperability with multiple LLMs. LangChain is agnostic (can be adapted to various language model providers) with respect to the language model provider, which means that you can use OpenAI, Cohere, Anthropic or even locally hosted language models.
To conclude this section, it is worth noting the open source nature of Langhain, which facilitates collaboration and innovation in the development of applications based on language models. In addition, LangChain gives us incredible flexibility because it allows developers to easily integrate different LLMs, vectorisers and even final web interfaces into their applications.
Step-by-step exploration of the exercise: introduction to the Repository
The Github repository that we will use contains all the resources needed to build our RAG application. Inside, you will find:
- README: this file provides an overview of the project, instructions for use and additional resources.
- Jupyter Notebook: the example has been developed using a Jupyter Notebook format that we have already used in the past to code practical exercises combining a text document with code snippets executable in Google Colab. Here is the detailed implementation of the application, including data loading and processing, integration with language models such as GPT-44, configuration of information retrieval systems and generation of responses based on the retrieved data.
Notebook: preparing the Environment
Before starting, it is advisable to have the following requirements.
- Basic knowledge of Python and Natural Language Processing (NLP): although the notebook is self-explanatory, a basic understanding of these concepts will facilitate learning.
- Access to Google Colab: the notebook runs in this environment, which provides the necessary infrastructure.
- Accounts active in OpenAI and LangChain with valid API keys. These services are free and essential for running the notebook. Once you register with these services, you will need to generate an API Key to interact with the services. You will need to have this key handy so that you can paste it when executing the corresponding code snippet. If you need help to get these keys, any conversational assistant such as chatGPT or Google Gemini can help you step-by-step to get the keys. If you need visual guidance on youtube you will find thousands of tutorials.
- OpenAI API: https://openai.com/api/
- Lanchain API: https://www.langchain.com/
Exploring the Notebook: block by block
The notebook is divided into several blocks, each dedicated to a specific stage of the development of our RAG application. In the following, we will describe each block in detail, including the code used and its explanation.
Note to user. In the following, we are going to reproduce blocks of the code present in the Colab notebook. For clarity we have divided the code into self-contained units and formatted the code to highlight the syntax of the Python programming language. In addition, the outputs provided by the Notebook have been formatted and highlighted in JSON format to make them more readable. Note that this Notebook invokes language model APIs and therefore the model response changes with each run. This means that the outputs (the answers) presented in this post may not be exactly the same as what the user receives when running the Notebook in Colab.
Block 1: Installation and initial configuration
|
import os |
It is very important that you run these two lines at the beginning of the exercise and then do not run it again until you close and exit Google Colab.
|
%%capture |
|
!pip install langchain --quiet |
|
import getpass os.environ["LANGCHAIN_TRACING_V2"] = "true" |
When you run this snippet, a small dialogue box will appear below the snippet. There you must paste your Langchain API Key.
|
!pip install -qU langchain-openai |
|
import getpass |
When you run this snippet, a small dialogue box will appear below the snippet. There you must paste your OpenAI API Key.
In this first block, we have installed the necessary libraries for our project. Some of the most relevant are:
- openai: To interact with the OpenAI API and access models such as GPT-4.
- langchain: A framework that simplifies LLM application development.
- langchain-text-splitters: To break up long texts into smaller fragments that can be processed by language models.
- langchain-community: A collection of additional tools and components for LangChain.
- langchain-openai: To integrate LangChain with the OpenAI API.
- langgraph: To visualise the workflow of our RAG application.
- In addition to installing the libraries, we also set up the API keys for OpenAI and LangChain, using the getpass.getpass() function to enter them securely.
Block 2: Initialising the interaction with the LLM
Next, we start the first programmatic interaction (we pass our first prompt) with the language model. To check that everything works, we ask you to translate a simple sentence.
|
import getpass import os ] |
If everything went well we will get an output like this:
|
{ |
This block is a basic introduction to using an LLM for a simple task: translation. The OpenAI API key is configured and a gpt-4o-mini language model is instantiated using ChatOpenAI.
Two messages are defined:
- SystemMessage: Instruction to the model for translating from English into Italian.
- HumanMessage: The text to be translated ("hi!").
Finally, the model is invoked with llm.invoke(messages) to get the translation.
Block 3: Creating Embeddings
To understand the concept of Embeddings applied to the context of natural language processing, we recommend reading this post.
|
import getpass pip install -qU langchain-core from langchain_core.vectorstores import InMemoryVectorStore |
When you run this snippet, a small dialogue box will appear below the snippet. There you must paste your OpenAI API Key.
This block focuses on the creation of embeddings (vector representations of text) that capture their semantic meaning. We use the OpenAIEmbeddings class to access OpenAI's text-embedding-3-large model, which generates high-quality embeddings .
The embeddings will be stored in an InMemoryVectorStore, an in-memory data structure that allows efficient searches based on semantic similarity.
Block 4: Implementing RAG
|
#RAG import bs4 from langchain_community.document_loaders import WebBaseLoader # Manten únicamente el título del post, los encabezados y el contenido del HTML bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content")) loader = WebBaseLoader( web_paths=("https://datos.gob.es/es/blog/slm-llm-rag-y-fine-tuning-pilares-de-la-ia-...",) ) docs = loader.load() assert len(docs) == 1 print(f"Total characters: {len(docs.page_content)}") from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, add_start_index=True, ) all_splits = text_splitter.split_documents(docs) print(f"Split blog post into {len(all_splits)} sub-documents.") document_ids = vector_store.add_documents(documents=all_splits) print(document_ids[:3]) |
This block is the heart of the RAG implementation. Start loading the content of a post, using WebBaseLoader and the URL of the post on SLM, LLM, RAG and Fine-tuning..
To prepare our Generation Augmented Retrieval (GAR) system, we start by processing the text of the post using segmentation techniques. This initial step is crucial, as we break down the content into smaller fragments that are complete in meaning. We use LangChain tools to perform this segmentation, assigning each fragment a unique identifier (id). This prior preparation allows us to subsequently perform efficient and accurate searches when the system needs to retrieve relevant information to answer queries.
The bs4.SoupStrainer is used to extract only the relevant sections of the HTML. The text of the post is split into smaller fragments with RecursiveCharacterTextSplitter, ensuring overlap between fragments to maintain context. These fragments are added to the vector_store created in the previous block, generating embeddings for each one.
We see that the result of one of the fragments informs us that it has split the document into 21 sub-documents.
|
Split blog post into 21 sub-documents. |
Documents have their own identifier. For example, the first 3 are identified as:.
|
["409f1bcb-1710-49b0-80f8-e45b7ca51a96", "e242f16c-71fd-4e7b-8b28-ece6b1e37a1c", "9478b11c-61ab-4dac-9903-f8485c4770c6"] |
Block 5: Defining the Prompt and visualising the workflow
|
from langchain import hub prompt = hub.pull("rlm/rag-prompt") example_messages = prompt.invoke( {"context": "(context goes here)", "question": "(question goes here)"} ).to_messages() assert len(example_messages) == 1 print(example_messages.content) from langchain_core.documents import Document from typing_extensions import List, TypedDict class State(TypedDict): question: str context: List[Document] answer: str def retrieve(state: State): retrieved_docs = vector_store.similarity_search(state["question"]) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} from langgraph.graph import START, StateGraph graph_builder = StateGraph(State).add_sequence([retrieve, generate]) graph_builder.add_edge(START, "retrieve") graph = graph_builder.compile() from IPython.display import Image, display display(Image(graph.get_graph().draw_mermaid_png())) result = graph.invoke({"question": "What is Task Decomposition?"}) print(f"Context: {result["context"]}\n\n") print(f"Answer: {result["answer"]}") for step in graph.stream( {"question": "¿Cual es el futuro de la IA Generativa?"}, stream_mode="updates" ): print(f"{step}\n\n----------------\n") |
This block defines the prompt to be used to interact with the LLM. A predefined LangChain Hub prompt (rlm/rag-prompt) is used which is designed for RAG tasks.
Two functions are defined:
- retrieve: search the vector_store for snippets most similar to the user's question.
- generate: generates a response using the LLM, taking into account the context provided by the retrieved fragments.
langgraph is used to visualise the RAG workflow.
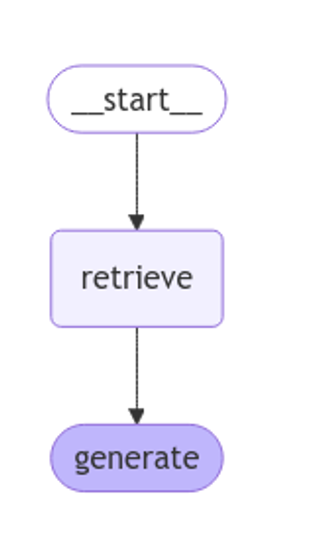
Figure 1: RAG workflow. Own elaboration.
Finally, the system is tested with two questions: one in English ("What is Task Decomposition?") and one in Spanish ("¿Cual es el futuro de la AI Generativa?").
The first question, "What is Task Decomposition?", is in English and is a generic question, unrelated to our content post. Therefore, although the system searches in its knowledge base previously created with the vectorisation of the document (post), it does not find any relation between the question and this context.
This text may vary with each execution
|
Answer: There is no explicit mention of the concept of "Task Decomposition" in the context provided. Therefore, I have no information on what Task Decomposition is. |
|
Answer: Task Decomposition is a process that decomposes a complex task into smaller, more manageable sub-tasks. This allows each subtask to be addressed independently, facilitating their resolution and improving overall efficiency. Although the context provided does not explicitly define Task Decomposition, this concept is common in AI and task optimisation. |
Answer: Task Decomposition is a process that decomposes a complex task into smaller, more manageable sub-tasks. This allows each subtask to be addressed independently, facilitating their resolution and improving overall efficiency. Although the context provided does not explicitly define Task Decomposition, this concept is common in AI and task optimisation.
|
{ |
As you can see in the response, the system retrieves 4 documents (in the diagram above, this corresponds to the "Retrieve" stage) with their corresponding "id" (identifiers), for example, the first document "id":. "53962c40-c08b-4547-a74a-26f63cced7e8" which corresponds to a fragment of the original post "title":. "SLM, LLM, RAG and Fine-tuning: Pillars of Modern Generative AI | datos.gob.es".
With these 4 fragments the system considers that it has enough relevant information to provide (in the diagram above, the "generate" stage) a satisfactory answer to the question.
|
{ |
Bloque 6: personalizando el prompt
|
from langchain_core.prompts import PromptTemplate template = """Use the following pieces of context to answer the question at the end. If you don"t know the answer, just say that you don"t know, don"t try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template) |
This block customises the prompt to make answers more concise and add a polite sentence at the end. PromptTemplate is used to create a new prompt with the desired instructions.
Block 7: Adding metadata and refining your search
|
total_documents = len(all_splits) third = total_documents // 3 for i, document in enumerate(all_splits): if i < third: document.metadata["section"] = "beginning" elif i < 2 * third: document.metadata["section"] = "middle" else: document.metadata["section"] = "end" all_splits.metadata from langchain_core.vectorstores import InMemoryVectorStore vector_store = InMemoryVectorStore(embeddings) _ = vector_store.add_documents(all_splits) from typing import Literal from typing_extensions import Annotated class Search(TypedDict): """Search query.""" query: Annotated[str, ..., "Search query to run."] section: Annotated( Literal["beginning", "middle", "end"], ..., "Section to query.", ] class State(TypedDict): question: str query: Search context: List[Document] answer: str def analyze_query(state: State): structured_llm = llm.with_structured_output(Search) query = structured_llm.invoke(state["question"]) return {"query": query} def retrieve(state: State): query = state["query"] retrieved_docs = vector_store.similarity_search( query["query"], filter=lambda doc: doc.metadata.get("section") == query["section"], ) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate]) graph_builder.add_edge(START, "analyze_query") graph = graph_builder.compile() display(Image(graph.get_graph().draw_mermaid_png())) for step in graph.stream( {"question": "¿Cual es el furturo de la IA Generativa en palabras del autor?"}, stream_mode="updates", ): print(f"{step}\n\n----------------\n") |
In this block, metadata is added to the post fragments, dividing them into three sections: "beginning", "middle" and "end". This allows for more refined searches, limiting the search to a specific section of the post.
A new analyze_query function is introduced that uses the LLM to determine the section of the post most relevant to the user's question. The RAG workflow is updated to include this new step.
Finally, the system is tested with a question in Spanish ("What is the future of Generative AI in the author's words?"), observing how the system uses the information in the "end" section of the post to generate a more accurate answer.
Let's look at the result:

Figure 2: RAG workflow. Own elaboration.
|
{ ---------------- { |
|
{ |
Conclusions
Through this notebook tour of Google Colab, we have experienced first-hand the construction of a conversational agent with RAG. We have learned to:
- Install the necessary libraries.
- Configure the development environment.
- Upload and process data.
- Create embeddings and store them in a vector_store.
- Implement the RAG recovery and generation stages.
- Customise the prompt to get more specific answers.
- Add metadata to refine the search.
This practical exercise provides you with the tools and knowledge you need to start exploring the potential of RAG and develop your own applications.
Dare to experiment with different information sources, language models and prompts to create increasingly sophisticated conversational agents!
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.













