Entrevista
In the last fifteen years we have seen how public administrations have gone from publishing their first open datasets to working with much more complex concepts. Interoperability, standards, data spaces or digital sovereignty are some of the trendy concepts. And, in parallel, the web has also changed. That open, decentralized, and interoperable space that inspired the first open data initiatives has evolved into a much more complex ecosystem, where technologies, new standards, and at the same time important challenges such as information silos to digital ethics and technological concentration coexist.
To talk about all this, today we are fortunate to have two voices that have not only observed this evolution, but have been direct protagonists of it at an international level:
- Josema Alonso, with more than twenty-five years of experience working on the open web, data and digital rights, has worked at the World Wide Web Foundation, the Open Government Partnership and the World Economic Forum, among others.
- Carlos Iglesias, an expert in web standards, open data and open government, has advised administrations around the world on more than twenty projects. He has been actively involved in communities such as W3C, the Web Foundation and the Open Knowledge Foundation.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. At what point do you think we are now and what has changed with respect to that first stage of open data?
Carlos Iglesias: Well, I think what has changed is that we understand that today that initial battle cry of "we want the data now" is not enough. It was a first phase that at the time was very useful and necessary because we had to break with that trend of having data locked up, not sharing data. Let's say that the urgency at that time was simply to change the paradigm and that is why the battle cry was what it was. I have been involved, like Josema, in studying and analyzing all those open data portals and initiatives that arose from this movement. And I have seen that many of them began to grow without any kind of strategy. In fact, several fell by the wayside or did not have a clear vision of what they wanted to do. Simple practice I believe came to the conclusion that the publication of data alone was not enough. And from there I think that they have been proposing, a little with the maturity of the movement, that more things have to be done, and today we talk more about data governance, about opening data with a specific purpose, about the importance of metadata, models. In other words, it is no longer simply having data for the sake of having it, but there is one more vision of data as one of the most valuable elements today, probably, and also as a necessary infrastructure for many things to work today. Just as infrastructures such as road or public transport networks or energy were key in their day. Right now we are at the moment of the great explosion of artificial intelligence. A series of issues converge that have made this explode and the change is immense, despite the fact that we are only talking about perhaps a little more than ten or fifteen years since that first movement of "we want the data now". I think that right now the panorama is completely different.
Josema Alonso: Yes, it is true that we had that idea of "you publish that someone will come and do something with it". And what that did is that people began to become aware. But I, personally, could not have imagined that a few years later we would have even had a directive at European level on the publication of open data. It was something, to be honest, that we received with great pleasure. And then it will begin to be implemented in all member states. That moved consciences a little and moved practices, especially within the administration. There was a lot of fear of "let's see if I put something in there that is problematic, that is of poor quality, that I will be criticized for it", etc. But it began to generate a culture of data and the usefulness of very important data. And as Carlos also commented in recent years, I think that no one doubts this anymore. The investments that are being made, for example, at European level and in Member States, including in our country, in Spain, in the promotion and development of data spaces, are hundreds of millions of euros. Nobody has that kind of doubt anymore and now the focus is more on how to do it well, on how to get everyone to interoperate. That is, when a European data space is created for a specific sector, such as agriculture or health, all countries and organisations can share data in the best possible way, so that they can be exchanged through common models and that they are done within trusted environments.
2. In this context, why have standards become so essential?
Josema Alonso: I think it's because of everything we've learned over the years. We have learned that it is necessary for people to be able to have a certain freedom when it comes to developing their own systems. The architecture of the website itself, for example, is how it works, it does not have a central control or anything, but each participant within the website manages things in their own way. But there are clear rules of how those things then have to interact with each other, otherwise it wouldn't work, otherwise we wouldn't be able to load a web page in different browsers or on different mobile phones. So, what we are seeing lately is that there is an increasing attempt to figure out how to reach that type of consensus in a mutual benefit. For example, part of my current work for the European Commission is in the Semantic Interoperability Community, where we manage the creation of uniform models that are used across Europe, definitions of basic standard vocabularies that are used in all systems. In recent years it has also been instrumentalized in a way that supports, let's say, that consensus through regulations that have been issued, for example, at the European level. In recent years we have seen the regulation of data, the regulation of data governance and the regulation of artificial intelligence, things that also try to put a certain order and barriers. It's not that everyone goes through the middle of the mountain, because if not, in the end we won't get anywhere, but we're all going to try to do it by consensus, but we're all going to try to drive within the same road to reach the same destination together. And I think that, from the part of the public administrations, apart from regulating, it is very interesting that they are very transparent in the way it is done. It is the way in which we can all come to see that what is built is built in a certain way, the data models that are transparent, everyone can see them participate in their development. And this is where we are seeing some shortcomings in algorithmic and artificial intelligence systems, where we do not know very well the data they use or where it is hosted. And this is where perhaps we should have a little more influence in the future. But I think that as long as this duality is achieved, of generating consensus and providing a context in which people feel safe developing it, we will continue to move in the right direction.
Carlos Iglesias: If we look at the principles that made the website work in its day, there is also a lot of focus on the community part and leaving an open platform that is developed in the open, with open standards in which everyone could join. The participation of everyone was sought to enrich that ecosystem. And I think that with the data we should think that this is the way to go. In fact, it's kind of also a bit like the concept that I think is behind data spaces. In the end, it is not easy to do something like that. It's very ambitious and we don't see an invention like the web every day.
3. From your perspective, what are the real risks of data getting trapped in opaque infrastructures or models? More importantly, what can we do to prevent it?
Carlos Iglesias: Years ago we saw that there was an attempt to quantify the amount of data that was generated daily. I think that now no one even tries it, because it is on a completely different scale, and on that scale there is only one way to work, which is by automating things. And when we talk about automation, in the end what you need are standards, interoperability, trust mechanisms, etc. If we look ten or fifteen years ago, which were the companies that had the highest share price worldwide, they were companies such as Ford or General Electric. If you look at the top ten worldwide, today there are companies that we all know and use every day, such as Meta, which is the parent company of Facebook, Instagram, WhatsApp and others, or Alphabet, which is the parent company of Google. In other words, in fact, I think I'm a little hesitant right now, but probably of the ten largest listed companies in the world, all are dedicated to data. We are talking about a gigantic ecosystem and, in order for this to really work and remain an open ecosystem from which everyone can benefit, the key is standardization.
Josema Alonso: I agree with everything Carlos said and we have to focus on not getting trapped. And above all, from the public administrations there is an essential role to play. I mentioned before about regulation, which sometimes people don't like very much because the regulatory map is starting to be extremely complicated. The European Commission, through an omnibus decree, is trying to alleviate this regulatory complexity and, as an example, in the data regulation itself, which obliges companies that have data to facilitate data portability to their users. It seems to me that it is something essential. We're going to see a lot of changes in that. There are three things that always come to mind; permanent training is needed. This changes every day at an astonishing speed. The volumes of data that are now managed are huge. As Carlos said before, a few days ago I was talking to a person who manages the infrastructure of one of the largest streaming platforms globally and he told me that they are receiving requests for data generated by artificial intelligence in such a large volume in just one week as the entire catalog they have available. So the administration needs to have permanent training on these issues of all kinds, both at the forefront of technology as we have just mentioned, and what we talked about before, how to improve interoperability, how to create better data models, etc. Another is the common infrastructure in Europe, such as the future European digital wallet, which would be the equivalent of the national citizen folder. A super simple example we are dealing with is the birth certificate. It is very complicated to try to integrate the systems of twenty-seven different countries, which in turn have regional governments and which in turn have local governments. So, the more we invest in common infrastructure, both at the semantic level and at the level of the infrastructure itself, the cloud, etc., I think the better we will do. And then the last one, which is the need for distributed but coordinated governance. Each one is governed by certain laws at local, national or European level. It is good that we begin to have more and more coordination in the higher layers and that those higher layers permeate to the lower layers and the systems are increasingly easier to integrate and understand each other. Data spaces are one of the major investments at the European level, where I believe this is beginning to be achieved. So, to summarize three things that are very practical to do: permanent training, investing in common infrastructure and that governance continues to be distributed, but increasingly coordinated.
Blog
At the crossroads of the 21st century, cities are facing challenges of enormous magnitude. Explosive population growth, rapid urbanization and pressure on natural resources are generating unprecedented demand for innovative solutions to build and manage more efficient, sustainable and livable urban environments.
Added to these challenges is the impact of climate change on cities. As the world experiences alterations in weather patterns, cities must adapt and transform to ensure long-term sustainability and resilience.
One of the most direct manifestations of climate change in the urban environment is the increase in temperatures. The urban heat island effect, aggravated by the concentration of buildings and asphalt surfaces that absorb and retain heat, is intensified by the global increase in temperature. Not only does this affect quality of life by increasing cooling costs and energy demand, but it can also lead to serious public health problems, such as heat stroke and the aggravation of respiratory and cardiovascular diseases.
The change in precipitation patterns is another of the critical effects of climate change affecting cities. Heavy rainfall episodes and more frequent and severe storms can lead to urban flooding, especially in areas with insufficient or outdated drainage infrastructure. This situation causes significant structural damage, and also disrupts daily life, affects the local economy and increases public health risks due to the spread of waterborne diseases.
In the face of these challenges, urban planning and design must evolve. Cities are adopting sustainable urban planning strategies that include the creation of green infrastructure, such as parks and green roofs, capable of mitigating the heat island effect and improving water absorption during episodes of heavy rainfall. In addition, the integration of efficient public transport systems and the promotion of non-motorised mobility are essential to reduce carbon emissions.
The challenges described also influence building regulations and building codes. New buildings must meet higher standards of energy efficiency, resistance to extreme weather conditions and reduced environmental impact. This involves the use of sustainable materials and construction techniques that not only reduce greenhouse gas emissions, but also offer safety and durability in the face of extreme weather events.
In this context, urban digital twins have established themselves as one of the key tools to support planning, management and decision-making in cities. Its potential is wide and transversal: from the simulation of urban growth scenarios to the analysis of climate risks, the evaluation of regulatory impacts or the optimization of public services. However, beyond technological discourse and 3D visualizations, the real viability of an urban digital twin depends on a fundamental data governance issue: the availability, quality, and consistent use of standardized open data.
What do we mean by urban digital twin?
An urban digital twin is not simply a three-dimensional model of the city or an advanced visualization platform. It is a structured and dynamic digital representation of the urban environment, which integrates:
-
The geometry and semantics of the city (buildings, infrastructures, plots, public spaces).
-
Geospatial reference data (cadastre, planning, networks, environment).
-
Temporal and contextual information, which allows the evolution of the territory to be analysed and scenarios to be simulated.
-
In certain cases, updatable data streams from sensors, municipal information systems or other operational sources.
From a standards perspective, an urban digital twin can be understood as an ecosystem of interoperable data and services, where different models, scales and domains (urban planning, building, mobility, environment, energy) are connected in a coherent way. Its value lies not so much in the specific technology used as in its ability to align heterogeneous data under common, reusable and governable models.
In addition, the integration of real-time data into digital twins allows for more efficient city management in emergency situations. From natural disaster management to coordinating mass events, digital twins provide decision-makers with a real-time view of the urban situation, facilitating a rapid and coordinated response.
In order to contextualize the role of standards and facilitate the understanding of the inner workings of an urban digital twin, Figure 1 presents a conceptual diagram of the network of interfaces, data models, and processes that underpin it. The diagram illustrates how different sources of urban information – geospatial reference data, 3D city models, regulatory information and, in certain cases, dynamic flows – are integrated through standardised data structures and interoperable services.
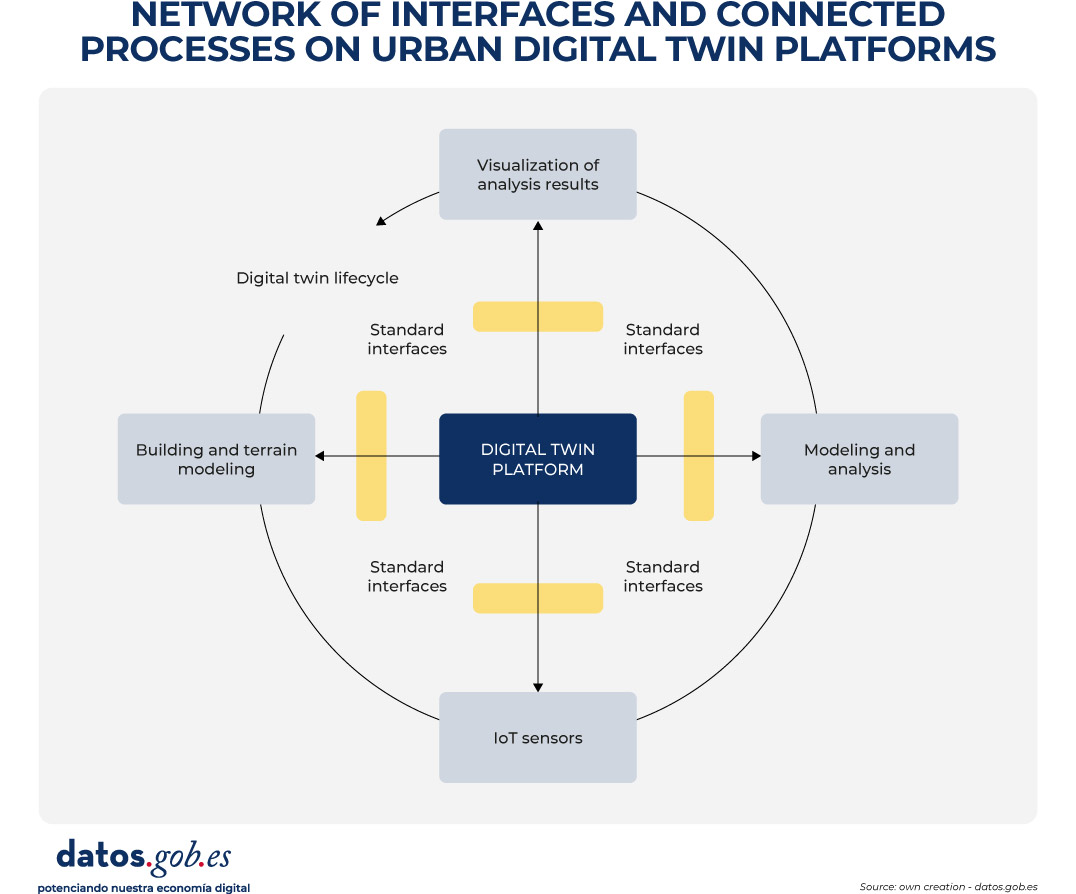
Figure 1. Conceptual diagram of the network of interfaces and connected processes in urban digital twin platforms. Source: own elaboration – datos.gob.es.
In these environments, CityGML and CityJSON act as urban information models that allow the city to be digitally described in a structured and understandable way. In practice, they function as "common languages" to represent buildings, infrastructures and public spaces, not only from the point of view of their shape (geometry), but also from the point of view of their meaning (e.g. whether an object is a residential building, a public road or a green area). As a result, these models form the basis on which urban analyses and the simulation of different scenarios are based.
In order for these three-dimensional models to be visualized in an agile way in web browsers and digital applications, especially when dealing with large volumes of information, 3D Tiles can be incorporated. This standard allows urban models to be divided into manageable fragments, facilitating their progressive loading and interactive exploration, even on devices with limited capacities.
The access, exchange and reuse of all this information is usually articulated through OGC APIs, which can be understood as standardised interfaces that allow different applications to consult and combine urban data in a consistent way. These interfaces make it possible, for example, for an urban planning platform, a climate analysis tool or a citizen viewer to access the same data without the need to duplicate or transform it in a specific way.
In this way, the diagram reflects the flow of data from the original sources to the final applications, showing how the use of open standards allows for a clear separation of data, services, and use cases. This separation is key to ensuring interoperability between systems, the scalability of digital solutions and the sustainability of the urban digital twin over time, aspects that are addressed transversally in the rest of the document.
Real example: Urban regeneration project in Barcelona
An example of the impact of urban digital twins on urban construction and management can be found in the urban regeneration project of the Plaza de las Glòries Catalanes, in Barcelona (Spain). This project aimed to transform one of the city's most iconic urban areas into a more accessible, greener and sustainable public space.

Figure 2. General view. Image by the joint venture Fuses Viader + Perea + Mansilla + Desvigne.
By using digital twins from the initial phases of the project, the design and planning teams were able to create detailed digital models that represented not only the geometry of existing buildings and infrastructure, but also the complex interactions between different urban elements, such as traffic, public transport and pedestrian areas.
These models not only facilitated the visualization and communication of the proposed design among all stakeholders, but also allowed different scenarios to be simulated and their impact on mobility, air quality, and walkability to be assessed. As a result, more informed decisions could be made, contributing decisively to the overall success of the urban regeneration initiative.
The critical role of open data in urban digital twins
In the context of urban digital twins, open data should not be understood as an optional complement or as a one-off action of transparency, but as the structural basis on which sustainable, interoperable and reusable digital urban systems are built over time. An urban digital twin can only fulfil its function as a planning, analysis and decision-support tool if the data that feeds it is available, well defined and governed according to common principles.
When a digital twin develops without a clear open data strategy, it tends to become a closed system and dependent on specific technology solutions or vendors. In these scenarios, updating information is costly and complex, reuse in new contexts is limited, and the twin quickly loses its strategic value, becoming obsolete in the face of the real evolution of the city it intends to represent. This lack of openness also hinders integration with other systems and reduces the ability to adapt to new regulatory, social or environmental needs.
One of the main contributions of urban digital twins is their ability to base public decisions on traceable and verifiable data. When supported by accessible and understandable open data, these systems allow us to understand not only the outcome of a decision, but also the data, models and assumptions that support it, integrating geospatial information, urban models, regulations and, in certain cases, dynamic data. This traceability is key to accountability, the evaluation of public policies and the generation of trust at both the institutional and citizen levels. Conversely, in the absence of open data, the analyses and simulations that support urban decisions become opaque, making it difficult to explain how and why a certain conclusion has been reached and weakening confidence in the use of advanced technologies for urban management.
Urban digital twins also require the collaboration of multiple actors – administrations, companies, universities and citizens – and the integration of data from different administrative levels and sectoral domains. Without an approach based on standardized open data, this collaboration is hampered by technical and organizational barriers: each actor tends to use different formats, models, and interfaces, which increases integration costs and slows down the creation of reuse ecosystems around the digital twin.
Another significant risk associated with the absence of open data is the increase in technological dependence and the consolidation of information silos. Digital twins built on non-standardized or restricted access data are often tied to proprietary solutions, making it difficult to evolve, migrate, or integrate with other systems. From the perspective of data governance, this situation compromises the sovereignty of urban information and limits the ability of administrations to maintain control over strategic digital assets.
Conversely, when urban data is published as standardised open data, the digital twin can evolve as a public data infrastructure, shared, reusable and extensible over time. This implies not only that the data is available for consultation or visualization, but that it follows common information models, with explicit semantics, coherent geometry and well-defined access mechanisms that facilitate its integration into different systems and applications.
This approach allows the urban digital twin to act as a common database on which multiple use cases can be built —urban planning, license management, environmental assessment, climate risk analysis, mobility, or citizen participation—without duplicating efforts or creating inconsistencies. The systematic reuse of information not only optimises resources, but also guarantees coherence between the different public policies that have an impact on the territory.
From a strategic perspective, urban digital twins based on standardised open data also make it possible to align local policies with the European principles of interoperability, reuse and data sovereignty. The use of open standards and common information models facilitates the integration of digital twins into wider initiatives, such as sectoral data spaces or digitalisation and sustainability strategies promoted at European level. In this way, cities do not develop isolated solutions, but digital infrastructures coherent with higher regulatory and strategic frameworks, reinforcing the role of the digital twin as a transversal, transparent and sustainable tool for urban management.
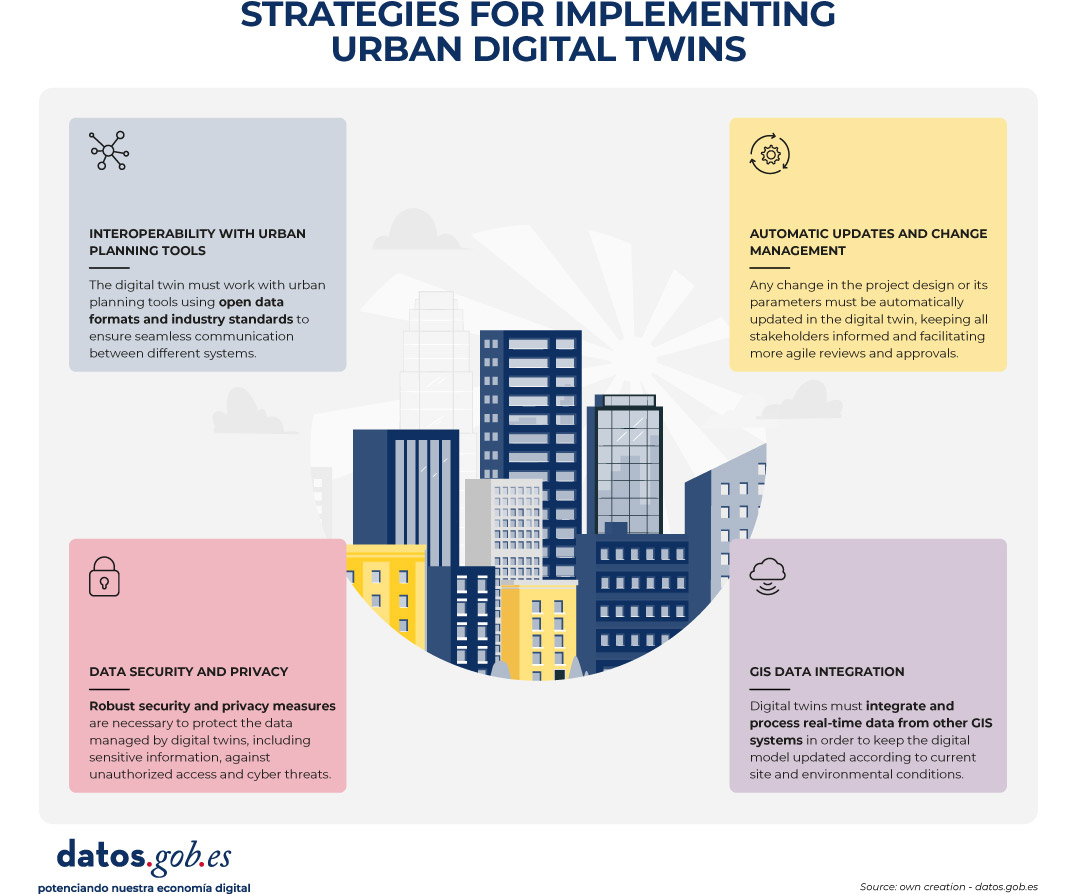
Figure 3. Strategies to implement urban digital twins. Source: own elaboration – datos.gob.es.
Conclusion
Urban digital twins represent a strategic opportunity to transform the way cities plan, manage and make decisions about their territory. However, their true value lies not in the technological sophistication of the platforms or the quality of the visualizations, but in the robustness of the data approach on which they are built.
Urban digital twins can only be consolidated as useful and sustainable tools when they are supported by standardised, well-governed open data designed from the ground up for interoperability and reuse. In the absence of these principles, digital twins risk becoming closed, difficult to maintain, poorly reusable solutions that are disconnected from the actual processes of urban governance.
The use of common information models, open standards and interoperable access mechanisms allows the digital twin to evolve as a public data infrastructure, capable of serving multiple public policies and adapting to social, environmental and regulatory changes affecting the city. This approach reinforces transparency, improves institutional coordination, and facilitates decision-making based on verifiable evidence.
In short, betting on urban digital twins based on standardised open data is not only a technical decision, but also a public policy decision in terms of data governance. It is this vision that will enable digital twins to contribute effectively to addressing major urban challenges and generating lasting public value for citizens.
Documentación
The future new version of the Technical Standard for Interoperability of Public Sector Information Resources (NTI-RISP) incorporates DCAT-AP-ES as a reference model for the description of data sets and services. This is a key step towards greater interoperability, quality and alignment with European data standards.
This guide aims to help you migrate to this new model. It is aimed at technical managers and managers of public data catalogs who, without advanced experience in semantics or metadata models, need to update their RDF catalog to ensure its compliance with DCAT-AP-ES. In addition, the guidelines in the document are also applicable for migration from other RDF-based metadata models, such as local profiles, DCAT, DCAT-AP or sectoral adaptations, as the fundamental principles and verifications are common.
Why migrate to DCAT-AP-ES?
Since 2013, the Technical Standard for the Interoperability of Public Sector Information Resources has been the regulatory framework in Spain for the management and openness of public data. In line with the European and Spanish objectives of promoting the data economy, the standard has been updated in order to promote the large-scale exchange of information in distributed and federated environments.
This update, which at the time of publication of the guide is in the administrative process, incorporates a new metadata model aligned with the most recent European standards: DCAT-AP-ES. These standards facilitate the homogeneous description of the reusable data sets and information resources made available to the public. DCAT-AP-ES adopts the guidelines of the European metadata exchange scheme DCAT-AP (Data Catalog Vocabulary – Aplication Profile), thus promoting interoperability between national and European catalogues.
The advantages of adopting DCAT-AP-ES can be summarised as follows:
- Semantic and technical interoperability: ensures that different catalogs can understand each other automatically.
- Regulatory alignment: it responds to the new requirements provided for in the NTI-RISP and aligns the catalogue with Directive (EU) 2019/1024 on open data and the re-use of public sector information and Implementing Regulation (EU) 2023/138 establishing a list of specific High Value Datasets or HVD), facilitating the publication of HVDs and associated data services.
- Improved ability to find resources: Makes it easier to find, locate, and reuse datasets using standardized, comprehensive metadata.
- Reduction of incidents in the federation: minimizes errors and conflicts by integrating catalogs from different Administrations, guaranteeing consistency and quality in interoperability processes.
What has changed in DCAT-AP-ES?
DCAT-AP-ES expands and orders the previous model to make it more interoperable, more legally accurate and more useful for the maintenance and technical reuse of data catalogues.
The main changes are:
- In the catalog: It is now possible to link catalogs to each other, record who created them, add a supplementary statement of rights to the license, or describe each entry using records.
- In datasets: New properties are added to comply with regulations on high-value sets, support communication, document provenance and relationships between resources, manage versions, and describe spatial/temporal resolution or website. Likewise, the responsibility of the license is redefined, moving its declaration to the most appropriate level.
- For distributions: Expanded options to indicate planned availability, legislation, usage policy, integrity, packaged formats, direct download URL, own license, and lifecycle status.
A practical and gradual approach
Many catalogs already meet the requirements set out in the 2013 version of NTI-RISP. In these cases, the migration to DCAT-AP-ES requires a reduced adjustment, although the guide also contemplates more complex scenarios, following a progressive and adaptable approach.
The document distinguishes between the minimum compliance required and some extensions that improve quality and interoperability.
It is recommended to follow an iterative strategy: starting from the minimum core to ensure operational continuity and, subsequently, planning the phased incorporation of additional elements, such as data services, contact, applicable legislation, categorization of HVDs and contextual metadata. This approach reduces risks, distributes the effort of adaptation, and favors an orderly transition.
Once the first adjustments have been made, the catalogue can be federated with both the National Catalogue, hosted in datos.gob.es, and the Official European Data Catalogue, progressively increasing the quality and interoperability of the metadata.
The guide is a technical support material that facilitates a basic transition, in accordance with the minimum interoperability requirements. In addition, it complements other reference resources, such as the DCAT-AP-ES Application Profile Model and Implementation Technical Guide, the implementation examples (Migration from NIT-RISP to DCAT-AP-ES and Migration from NTI-RISP to DCAT-AP-ES HHD), and the complementary conventions to the DCAT-AP-ES model that define additional rules to address practical needs.
Blog
Context and need for an update
Data is a key resource in the digital transformation of public administrations. Ensuring its access, interoperability and reuse is fundamental to improve transparency, foster innovation and enable the development of efficient public services centered on citizens.
In this context, the Technical Standard for Interoperability for the Reuse of information Resources (NTI-RISP) is the regulatory framework in Spain for the management and opening of public data since 2013. The standard sets common conditions on selection, identification, description, format, terms of use and provision of documents and information resources produced or held by the public sector, relating to numerous areas of interest such as social, economic, legal, tourism, business, education information, etc., fully complying with the provisions of Law 37/2007, of November 16.
In recent months, the text has been undergoing modernization in line with the European and Spanish objective of boosting the data economy, promoting its large-scale exchange within distributed and federated environments, guaranteeing adequate cybersecurity conditions and respecting European principles and values.
The new standard, currently in the processing stage, refers to a new metadata model aligned with the latest versions of European standards, which facilitate the description of datasets and reusable information resources made publicly available.
This new metadata model, called DCAT-AP-ES, adopts the guidelines of the European metadata exchange schema DCAT-AP (Data Catalog Vocabulary – Application Profile) with some additional restrictions and adjustments. DCAT-AP-ES is aligned with the European standards DCAT-AP 2.1.1 and the extension DCAT-AP-HVD 2.2.0, which incorporates the requirements for High-Value Datasets (HVD) defined by the European Commission.
What is DCAT-AP and how is it applied in Spain?
DCAT-AP is an application profile based on the DCAT vocabulary from the W3C, designed to improve the interoperability of public sector open data catalogues in Europe. Its goal is to provide a common metadata model that facilitates the exchange, aggregation and federation of catalogues from different countries and organizations (interoperability).
DCAT-AP-ES, as the Spanish application profile of DCAT-AP, is designed to adapt to the particulars of the national context, ensuring efficient management of open data at the national, regional and local levels.
DCAT-AP-ES is established as the standard to be considered in the new version of the NTI-RISP, which in turn is framed within the National Interoperability Framework (ENI), regulated by Royal Decree 4/2010, which sets the conditions for the reuse of public sector information in Spain.
Main news in DCAT-AP-ES
The new version of DCAT-AP-ES introduces significant improvements that facilitate interoperability and data management in the digital ecosystem. Among others:
Alignment with DCAT-AP
- Greater compatibility with European open data catalogues by aligning NTI-RISP with the EU standard DCAT-AP.
- Inclusion of advanced properties to improve the description of datasets and data services, to ensure the possibilities indicated below.
Incorporation of metadata for the description of High-Value Datasets (HVD)
- Facilitates compliance with European regulation on high-value data.
- Enables detailed description of data in key sectors such as geospatial, meteorology, earth observation and environment, statistics, mobility and business.
Improvements in the description of data services
- Inclusion of specific metadata to describe APIs and data access services.
- Possibility to express a dataset in different contexts (e.g. geospatial, with a map server, or statistical, with a data API).
Support for provenance and data quality
- Incorporation of new properties to manage lifecycle, versioning and origin.
- Implementation of validation and quality control mechanisms using SHACL, ensuring consistency and structure of metadata in catalogues.
Use of controlled vocabularies and best practices
- Adaptation of standardized vocabularies for licenses, data formats, languages and themes.
- Greater clarity in data classification to facilitate discovery.
Data governance and improved agent management
- Specification of agent roles (creator, publisher) and contact points.
- Enhanced metadata to represent resource provenance.
Validation of conformity and metadata quality
- Guides to help validate metadata that comply with DCAT-AP-ES.
- Validation of DCAT-AP-ES graphs against SHACL templates.
Key benefits of the update
The adoption of DCAT-AP-ES represents a qualitative leap in the management and reuse of open data in Spain. Among its benefits are:
✅ Facilitates the federation of catalogues and the discovery of data.
✅ Improves interoperability with the European open data ecosystem.
✅ Complies with European open data regulations.
✅ Increases metadata quality through validation mechanisms.
✅ Ensures that data are FAIR (Findable, Accessible, Interoperable, Reusable).
Implementation and next steps
When will it come into force?
The new application profile DCAT-AP-ES will be progressively implemented in Spain's open data catalogues. Its application will be mandatory once the modification text of the standard comes into force which, as mentioned earlier, is currently undergoing administrative processing but is already compatible with the datos.gob.es data federator.
Are there supporting materials and resources for implementing DCAT-AP-ES?
The management team of the datos.gob.es platform has developed the DCAT-AP-ES Technical guide and model, available in the datos.gob.es repository.
This repository will be enriched as new needs of users applying the standard are identified. Likewise, help guides and educational resources will be developed to facilitate its adoption by publishing organizations. All the news and resources produced in the context of the application profile will be announced and referenced punctually on datos.gob.es.
Where to find more information?
The updated documentation, guides and resources will be accessible on datos.gob.es and in the associated code repository. At present the following are available:
- DCAT-AP-ES Technical guide and model
- DCAT-AP-ES Conventions
- DCAT-AP-ES Implementation examples
- DCAT-AP-ES Frequently Asked Questions
- DCAT-AP-ES Metadata validation
- DCAT-AP explanatory video: Spanish / English
- datos.gob.es
Learn more in this video:
And this infographic (click to access the interactive and accessible version):

Blog
Citizen participation in the collection of scientific data promotes a more democratic science, by involving society in R+D+i processes and reinforcing accountability. In this sense, there are a variety of citizen science initiatives launched by entities such as CSIC, CENEAM or CREAF, among others. In addition, there are currently numerous citizen science platform platforms that help anyone find, join and contribute to a wide variety of initiatives around the world, such as SciStarter.
Some references in national and European legislation
Different regulations, both at national and European level, highlight the importance of promoting citizen science projects as a fundamental component of open science. For example, Organic Law 2/2023, of 22 March, on the University System, establishes that universities will promote citizen science as a key instrument for generating shared knowledge and responding to social challenges, seeking not only to strengthen the link between science and society, but also to contribute to a more equitable, inclusive and sustainable territorial development.
On the other hand, Law 14/2011, of 1 June, on Science, Technology and Innovation, promotes "the participation of citizens in the scientific and technical process through, among other mechanisms, the definition of research agendas, the observation, collection and processing of data, the evaluation of impact in the selection of projects and the monitoring of results, and other processes of citizen participation."
At the European level, Regulation (EU) 2021/695 establishing the Framework Programme for Research and Innovation "Horizon Europe", indicates the opportunity to develop projects co-designed with citizens, endorsing citizen science as a research mechanism and a means of disseminating results.
Citizen science initiatives and data management plans
The first step in defining a citizen science initiative is usually to establish a research question that requires data collection that can be addressed with the collaboration of citizens. Then, an accessible protocol is designed for participants to collect or analyze data in a simple and reliable way (it could even be a gamified process). Training materials must be prepared and a means of participation (application, web or even paper) must be developed. It also plans how to communicate progress and results to citizens, encouraging their participation.
As it is an intensive activity in data collection, it is interesting that citizen science projects have a data management plan that defines the life cycle of data in research projects, that is, how data is created, organized, shared, reused and preserved in citizen science initiatives. However, most citizen science initiatives do not have such a plan: this recent research article found that only 38% of the citizen science projects consulted had a data management plan.

Figure 1. Data life cycle in citizen science projects Source: own elaboration – datos.gob.es.
On the other hand, data from citizen science only reach their full potential when they comply with the FAIR principles and are published in open access. In order to help have this data management plan that makes data from citizen science initiatives FAIR, it is necessary to have specific standards for citizen science such as PPSR Core.
Open Data for Citizen Science with the PPSR Core Standard
The publication of open data should be considered from the early stages of a citizen science project, incorporating the PPSR Core standard as a key piece. As we mentioned earlier, when research questions are formulated, in a citizen science initiative, a data management plan must be proposed that indicates what data to collect, in what format and with what metadata, as well as the needs for cleaning and quality assurance from the data collected by citizens. in addition to a publication schedule.
Then, it must be standardized with PPSR (Public Participation in Scientific Research) Core. PPSR Core is a set of data and metadata standards, specially designed to encourage citizen participation in scientific research processes. It has a three-layer architecture based on a Common Data Model (CDM). This CDM helps to organize in a coherent and connected way the information about citizen science projects, the related datasets and the observations that are part of them, in such a way that the CDM facilitates interoperability between citizen science platforms and scientific disciplines. This common model is structured in three main layers that allow the key elements of a citizen science project to be described in a structured and reusable way. The first is the Project Metadata Model (PMM), which collects the general information of the project, such as its objective, participating audience, location, duration, responsible persons, sources of funding or relevant links. Second, the Dataset Metadata Model (DMM) documents each dataset generated, detailing what type of information is collected, by what method, in what period, under what license and under what conditions of access. Finally, the Observation Data Model (ODM) focuses on each individual observation made by citizen science initiative participants, including the date and location of the observation and the result. It is interesting to note that this PPSR-Core layer model allows specific extensions to be added according to the scientific field, based on existing vocabularies such as Darwin Core (biodiversity) or ISO 19156 (sensor measurements). (ODM) focuses on each individual observation made by participants of the citizen science initiative, including the date and place of the observation and the outcome. It is interesting to note that this PPSR-Core layer model allows specific extensions to be added according to the scientific field, based on existing vocabularies such as Darwin Core (biodiversity) or ISO 19156 (sensor measurements).
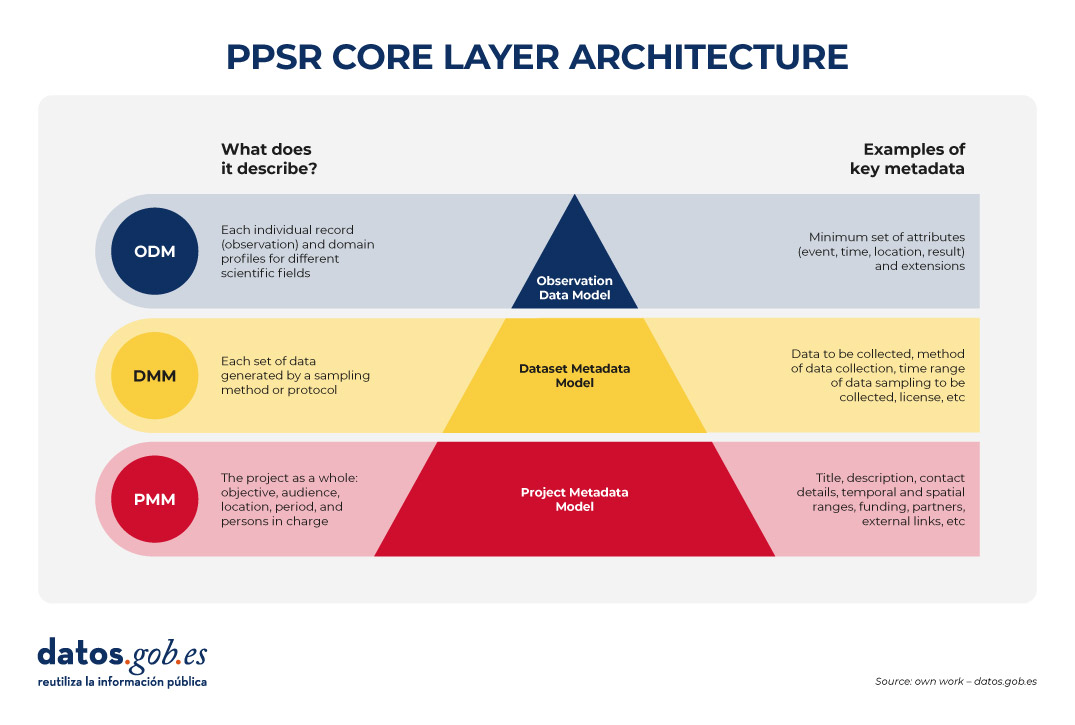
Figure 2. PPSR CORE layering architecture. Source: own elaboration – datos.gob.es.
This separation allows a citizen science initiative to automatically federate the project file (PMM) with platforms such as SciStarter, share a dataset (DMM) with a institutional repository of open scientific data, such as those added in FECYT's RECOLECTA and, at the same time, send verified observations (ODMs) to a platform such as GBIF without redefining each field.
In addition, the use of PPSR Core provides a number of advantages for the management of the data of a citizen science initiative:
- Greater interoperability: platforms such as SciStarter already exchange metadata using PMM, so duplication of information is avoided.
- Multidisciplinary aggregation: ODM profiles allow datasets from different domains (e.g. air quality and health) to be united around common attributes, which is crucial for multidisciplinary studies.
- Alignment with FAIR principles: The required fields of the DMM are useful for citizen science datasets to comply with the FAIR principles.
It should be noted that PPSR Core allows you to add context to datasets obtained in citizen science initiatives. It is a good practice to translate the content of the PMM into language understandable by citizens, as well as to obtain a data dictionary from the DMM (description of each field and unit) and the mechanisms for transforming each record from the MDG. Finally, initiatives to improve PPSR Core can be highlighted, for example, through a DCAT profile for citizen science.
Conclusions
Planning the publication of open data from the beginning of a citizen science project is key to ensuring the quality and interoperability of the data generated, facilitating its reuse and maximizing the scientific and social impact of the project. To this end, PPSR Core offers a level-based standard (PMM, DMM, ODM) that connects the data generated by citizen science with various platforms, promoting that this data complies with the FAIR principles and considering, in an integrated way, various scientific disciplines. With PPSR Core , every citizen observation is easily converted into open data on which the scientific community can continue to build knowledge for the benefit of society.

Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Data is the engine of innovation, and its transformative potential is reflected in all areas, especially in health. From faster diagnoses to personalized treatments to more effective public policies, the intelligent use of health information has the power to change lives in profound and meaningful ways.
But, for this data to unfold its full value and become a real force for progress, it is essential that it "speaks the same language". That is, they must be well organized, easy to find, and can be shared securely and consistently across systems, countries, and practitioners.
This is where HealthDCAT-AP comes into play, a new European specification that, although it sounds technical, has a lot to do with our well-being as citizens. HealthDCAT-AP is designed to describe health data—from aggregated statistics to anonymized clinical records—in a homogeneous, clear, and reusable way, through metadata. In short, it does not act on the clinical data itself, but rather makes it easier for them to be located and better understood thanks to a standardized description.HealthDCAT-AP is exclusively concerned with metadata, i.e., how datasets are described and organized in catalogs, unlike HL7, FHIR, and DICOM, which structure the exchange of clinical information and images. CDA, which describes the architecture of documents; and SNOMED CT, LOINC, and ICD-10, which standardize the semantics of diagnoses, procedures, and observations to ensure that data have the same meaning in any context.
This article explores how HealthDCAT-AP, in the context of the European Health Data Space (EHDS) and the National Health Data Space (ENDS), brings value primarily to those who reuse data—such as researchers, innovators, or policymakers—and ultimately benefits citizens through the advances they generate.
What is HealthDCAT-AP and how does it relate to DCAT-AP?
Imagine a huge library full of health books, but without any system to organize them. Searching for specific information would be a chaotic task. Something similar happens with health data: if it is not well described, locating and reusing it is practically impossible.
HealthDCAT-AP was born to solve this challenge. It is a European technical specification that allows for a clear and uniform description of health datasets within data catalogues, making it easier to search, access, understand and reuse them. In other words, it makes the description of health data speak the same language across Europe, which is key to improving health care, research and policy.
This technical specification is based on DCAT-AP, the general specification used to describe catalogues of public sector datasets in Europe. While DCAT-AP provides a common structure for all types of data, HealthDCAT-AP is your specialized health extension, adapting and extending that model to cover the particularities of clinical, epidemiological, or biomedical data.
HealthDCAT-AP was developed within the framework of the European EHDS2 (European Health Data Space 2) pilot project and continues to evolve thanks to the support of projects such as HealthData@EU Pilot, which are working on the deployment of the future European health data infrastructure. The specification is under active development and its most recent version, along with documentation and examples, can be publicly consulted in its official GitHub repository.
HealthDCAT-AP is also designed to apply the FAIR principles: that data is Findable, Accessible, Interoperable and Reusable. This means that although health data may be complex or sensitive, its description (metadata) is clear, standardized, and useful. Any professional or institution – whether in Spain or in another European country – can know what data exists, how to access it and under what conditions. This fosters trust, transparency, and responsible use of health data. HealthDCAT-AP is also a cornerstone of EHDS and therefore ENDS. Its adoption will allow hospitals, research centres or administrations to share information consistently and securely across Europe. Thus, collaboration between countries is promoted and the value of data is maximized for the benefit of all citizens.
To facilitate its use and adoption, from Europe, under the initiatives mentioned above, tools such as the HealthDCAT-AP editor and validator have been created, which allow any organization to generate descriptions of datasets through metadata that are compatible without the need for advanced technical knowledge. This removes barriers and encourages more entities to participate in this networked health data ecosystem.
How does HealthDCAT-AP contribute to the public value of health data?
Although HealthDCAT-AP is a technical specification focused on the description of health datasets, its adoption has practical implications that go beyond the technological realm. By offering a common and structured way of documenting what data exists, how it can be used and under what conditions, it helps different actors – from hospitals and administrations to research centres or startups – to better access, combine and reuse the available information, enabling the so-called secondary use of the same, beyond its primary healthcare use.
- Faster diagnoses and personalized treatments: When data is well-organized and accessible to those who need it, advances in medical research accelerate. This makes it possible to develop artificial intelligence tools that detect diseases earlier, identify patterns in large populations and adapt treatments to the profile of each patient. It is the basis of personalized medicine, which improves results and reduces risks.
- Better access to knowledge about what data exists: HealthDCAT-AP makes it easier for researchers, healthcare managers or authorities to locate useful datasets, thanks to its standardized description. This can facilitate, for example, the analysis of health inequalities or resource planning in crisis situations.
- Greater transparency and traceability: The use of metadata allows us to know who is responsible for each set of data, for what purpose it can be used and under what conditions. This strengthens trust in the data reuse ecosystem.
- More efficient healthcare services: Standardizing metadata improves information flows between sites, regions, and systems. This reduces bureaucracy, avoids duplication, optimizes the use of resources, and frees up time and money that can be reinvested in improving direct patient care.
- More innovation and new solutions for the citizen: by facilitating access to larger datasets, HealthDCAT-AP promotes the development of new patient-centric digital tools: self-care apps, remote monitoring systems, service comparators, etc. Many of these solutions are born outside the health system – in universities, startups or associations – but directly benefit citizens.
- A connected Europe around health: By sharing a common way of describing data, HealthDCAT-AP makes it possible for a dataset created in Spain to be understood and used in Germany or Finland, and vice versa. This promotes international collaboration, strengthens European cohesion and ensures that citizens benefit from scientific advances regardless of their country.
And what role does Spain play in all this?
Spain is not only aligned with the future of health data in Europe: it is actively participating in its construction. Thanks to a solid legal foundation, a largely digitized healthcare system, accumulated experience in the secure sharing of health information within the Spanish National Health System (SNS), and a long history of open data—through initiatives such as datos.gob.es—our country is in a privileged position to contribute to and benefit from the European Health Data Space (EHDS).
Over the years, Spain has developed legal frameworks and technical capacities that anticipate many of the requirements of the EHDS Regulation. The widespread digitalization of healthcare and the experience in using data in a secure and responsible way allow us to move towards an interoperable, ethical and common good-oriented model.
In this context, the National Health Data Space project represents a decisive step forward. This initiative aims to become the national reference platform for the analysis and exploitation of health data for secondary use, conceived as a catalyst for research and innovation in health, a benchmark in the application of disruptive solutions, and a gateway to different data sources. All of this is carried out under strict conditions of anonymization, security, transparency, and protection of rights, ensuring that the data is only used for legitimate purposes and in full compliance with current regulations.
Spain's familiarity with standards such as DCAT-AP facilitates the deployment of HealthDCAT-AP. Platforms such as datos.gob.es, which already act as a reference point for the publication of open data, will be key in its deployment and dissemination.
Conclusions
HealthDCAT-AP may sound technical, but it is actually a specification that can have an impact on our daily lives. By helping to better describe health data, it makes it easier for that information to be used in a useful, safe, and responsible manner.
This specification allows the description of data sets to speak the same language across Europe. This makes it easier to find, share with the right people, and reuse for purposes that benefit us all: faster diagnoses, more personalized treatments, better public health decisions, and new digital tools that improve our quality of life.
Spain, thanks to its experience in open data and its digitized healthcare system, is actively participating in this transformation through a joint effort between professionals, institutions, companies, researchers, etc., and also citizens. Because when data is understood and managed well, it can make a difference. It can save time, resources, and even lives.
HealthDCAT-AP is not just a technical specification: it is a step forward towards more connected, transparent, and people-centered healthcare. A specification designed to maximize the secondary use of health information, so that all of us as citizens can benefit from it.
Content created by Dr. Fernando Gualo, Professor at UCLM and Government and Data Quality Consultant. The content and views expressed in this publication are the sole responsibility of the author.
Noticia
The UNE 0087 standard defines for the first time in Spain the key principles and requirements for creating and operating in data spaces
On 17 July, the UNE 0087 Specification "Definition and Characterisation of Data Spaces" was officially published, the first Spanish standard to establish a common framework for these digital environments.
This milestone has been possible thanks to the collaboration of the Data Space Reference Centre (CRED) with the Spanish Association for Standardisation (UNE). This regulation, which was approved on June 20, 2025, defines three key pillars in adherence to data spaces: interoperability, governance and value creation, with the aim of offering legal certainty, trust and a common technical language in the data economy.
For its creation, three working groups have been formed with more than 50 participants from both public and private entities who have contributed their knowledge to define the principles and key characteristics of these collaborative systems. These working groups have been coordinated as follows:
- WG1: Definition of Data Spaces and Maturity Model.
- WG2: Technical and Semantic Interoperability.
- WG3: Legal and organisational interoperability.
The publication of this regulation is, therefore, a reference document for the creation of secure and reliable data spaces, applicable in all productive sectors and which serves as a basis for future guide documents.
In this way, to offer guidelines that facilitate the implementation and development of data spaces, the UNE 0087:2025 specification was created to create an inclusive framework of reference that guides organizations so that they can take advantage of all the information in an environment of regulatory compliance and digital sovereignty. The publication of this regulation has a number of benefits:
- Accelerate the deployment of data spaces across all sectors of the economy.
- Supporting sustainability and scaling/growth of data-sharing ecosystems.
- Promoting public/private collaboration, ensuring convergence with Europe.
- Move towards technological autonomy and data sovereignty in ecosystems.
- Promote the discovery of new innovative business opportunities by fostering collaboration and the creation of strategic alliances.
Within the specification, data spaces are defined, their key characteristics of interoperability, governance and value generation are established and the benefits of their adhesion are determined. The specification is published here and it is important to add that, although there is a download cost, it is free of charge, thanks to the sponsorship of the General Directorate of Data.
With this tool, Spain takes a firm step in the consolidation of cohesive, secure data spaces aligned with the European framework, facilitating the implementation of cross-cutting projects in different sectors.
Blog
As tradition dictates, the end of the year is a good time to reflect on our goals and objectives for the new phase that begins after the chimes. In data, the start of a new year also provides opportunities to chart an interoperable and digital future that will enable the development of a robust data economy robust data economy, a scenario that benefits researchers, public administrations and private companies alike, as well as having a positive impact on the citizen as the end customer of many data-driven operations, optimising and reducing processing times. To this end, there is the European Data Strategy strategy, which aims to unlock the potential of data through, among others, the Data Act (Data Act), which contains a set of measures related to fair access to and use of data fair access to and use of data ensuring also that the data handled is of high quality, properly secured, etc.
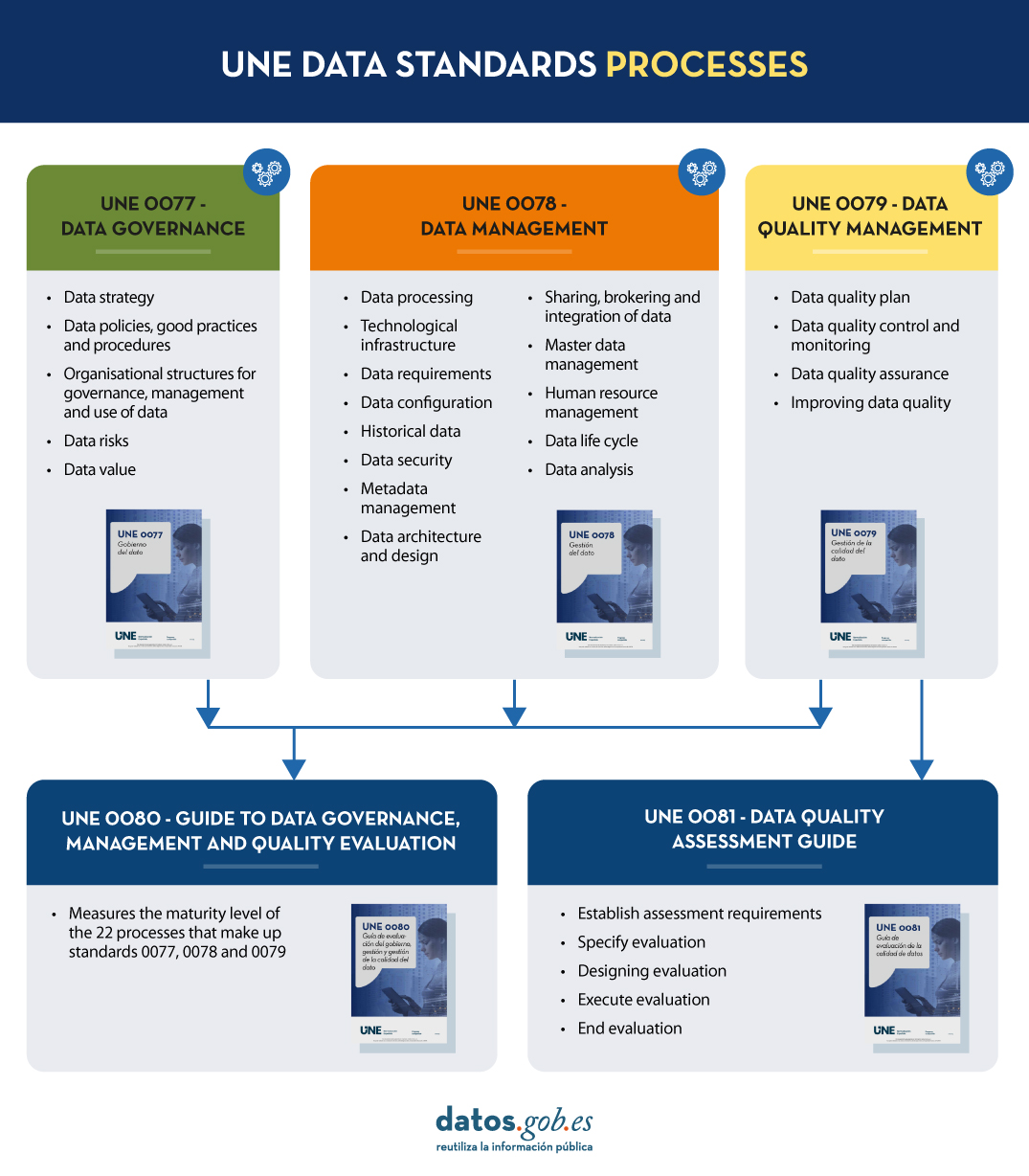
As a solution to this need, in the last year the uNE data specifications which are normative and informative resources for implementing common data governance, management and quality processes. These specifications, supported by the Data Officethese specifications, supported by the Data Office, establish standards for well-governed data (UNE 0077), managed (UNE 0078) and with adequate levels of quality (UNE 0079), thus allowing for sustainable growth in the organisation during the implementation of the different processes. In addition to these three specifications, the UNE 0080 specification defines a maturity assessment guide and process to measure the degree of implementation of data governance, management and quality processes. For its part, the UNE 0081 also establishes a process of evaluation of the data asset itself, i.e. of the data sets, regardless of their nature or typology; in short, its content is closely related to UNE 0079 because it sets out data quality characteristics. Adopting all of them can provide multiple benefits. In this post, we look at what they are and what the process would be like for each specification.
So, with an eye to the future, we set a New Year's resolution: the application of the UNE data specifications to an organisation.
What are the benefits of your application and how can I access them?
In today's era, where data governance and efficient data management have become a fundamental pillar of organisational success, the implementation of the uNE data specifications specifications emerge as a guiding light towards excellence, leading the way forward. These specifications describe rigorous standardised processes that offer organisations the possibility to build a robust and reliable structure for the management of their data and information throughout its lifecycle.
By adopting the UNE specifications, you not only ensure data quality and security, but also provide a solid and adequate basis for informed decision-making by enriching organisational processes with good data practices. Therefore, any organisation that chooses to embrace these regulations in the new year will be moving closer to innovation, efficiency and trust in data governance and management; as well as preparing to meet the challenges and opportunities that the digital future holds digital future. The application of UNE specifications is not only a commitment to quality, but a strategic investment that paves the way for sustainable success in an increasingly competitive and dynamic business environment because:
- Maximising value contribution to business strategy
- Minimises risks in data processing
- Optimise tasks by avoiding unnecessary work
- It establishes homogeneous frameworks for reference and certification
- Facilitates information sharing with trust and sovereignty
The content of the guides can be downloaded free of charge from the AENOR portal via the links below. Registration is required for downloading. The discount on the total price is applied at the time of checkout.
- SPECIFICATION UNE 0077:2023
- SPECIFICATION UNE 0078:2023
- SPECIFICATION UNE 0079:2023
- SPECIFICATION UNE 0080:2023
- SPECIFICATION UNE 0081:2023
From datos.gob.es we have echoed the content of the same and we have prepared different didactic resources such as this infographic or this explanatory video.
How do they apply to an organisation?
Once the decision has been taken to address the implementation of these specifications, a crucial question arises: what is the most effective way to do this? The answer to this question will depend on the initial situation (marked by an initial maturity assessment), the type of organisation and the resources available at the time of establishing the master plan or implementation plan. Nevertheless, at datos.gob.es, we have published a series of contents prepared by experts in technologies linked to the data economy datos.gob.es, we have published a series of contents elaborated by experts in technologies linked to the data economy that will accompany you in the process.
Before starting, it is important to know the different processes that make up each of the UNE data specifications. This image shows what they are.
Once the basics are understood, the series of contents 'Application of the UNE data specifications' deals with a practical exercise, broken down into three posts, on a specific use case: the application of these specifications to open data. As an example, a need is defined for the fictitious Vistabella Town Council: to make progress in the open publication of information on public transport and cultural events.
- In the first post of the series, the importance of using the UNE 0077 data using the UNE 0077 Data Governance Specification to establish approved mechanisms to support the openness and publication of open data. Through this first content, an overview of the processes necessary to align the organisational strategy in such a way as to achieve maximum transparency and quality of public services through the reuse of information is provided.
- The second article in the series takes a closer look at the uNE 0079 data quality management standard and its application in the context of open data and its application in the context of open data. This content underlines that the quality of open data goes beyond the FAIR principles fAIR principles principles and stresses the importance of assessing quality using objective criteria. Through the practical exercise, we explore how Vistabella Town Council approaches the UNE processes to improve the quality of open data as part of its strategy to enhance the publication of data on public transport and cultural events.
- Finally, the uNE 0078 standard on data management is explained in a third article presenting the Data Sharing, Intermediation and Integration (CIIDat) process for the publication of open data, combined with specific templates.
Together, these three articles provide a guide for any organisation to move successfully towards open publication of key information, ensuring consistency and quality of data. By following these steps, organisations will be prepared to comply with regulatory standards with all the benefits that this entails.
Finally, embracing the New Year's resolution to implement the UNE data specifications represents a strategic and visionary commitment for any organisation, which will also be aligned with the European Data Strategy and the European roadmap that aims to shape a world-leading digital future.
Blog
The new UNE 0081 Data Quality Assessment specification, focused on data as a product (datasets or databases), complements the UNE 0079 Data Quality Management specification, which we analyse in this article, and focuses on data quality management processes. Both standards 0079 and 0081 complement each other and address data quality holistically:
- The UNE 0079 standard refers to the processes, the activities that the organisation must carry out to guarantee the appropriate levels of quality of its data to satisfy the strategy that the organisation has set itself.
- On the other hand, UNE 0081 defines a data quality model, based on ISO/IEC 25012 and ISO/IEC 25024, which details the quality characteristics that data can have, as well as some applicable metrics. It also defines the process to be followed to assess the quality of a particular dataset, based on ISO/IEC 25040. Finally, the specification details how to interpret the results obtained from the evaluation, showing concrete examples of application.
How can an organisation make use of this specification to assess the quality level of its data?
To answer this question, we will use the example of the Vistabella Town Council, previously used in previous articles. The municipality has a number of data sets, the quality of which it wants to evaluate in order to improve them and provide a better service to citizens. The institution is aware that it works with many types of data (transactional, master, reference, etc.), so the first thing it does is to first identify the data sets that provide value and for which not having adequate levels of quality may have repercussions on the day-to-day work. Some criteria to follow when selecting these sets can be: data that provide value to the citizen, data resulting from a data integration process or master view of the data, critical data because they are used in several processes/procedures, etc.
The next step will be to determine at which point(s) in the lifecycle of the municipality's operational processes these data quality checks will be performed.
This is where the UNE 0081 specification comes into play. The evaluation is done on the basis of the "business rules" that define the requirements, data requirements or validations that the data must meet in order to provide value to the organisation. Some examples are shown below:
- Citizens' ID cards will have to comply with the specific syntax for this purpose (8 numbers and one letter).
- Any existing date in the system shall follow the notation DD-MM-YYYYYY.
- Records of documentation dated after the current date will not be accepted.
- Traceability of who has made a change to a dataset and when.
In order to systematically and comprehensively identify the business rules that data has to comply with at each stage of its lifecycle, the municipality uses a methodology based on BR4DQ.
The municipality then reviews all the data quality characteristics included in the specification, prioritises them, and determines a first set of data quality characteristics to be taken into account for the evaluation. For this purpose, and in this first stage, the municipality decided to stick exclusively to the 5 inherent characteristics of ISO 25012 defined within the specification. These are: accuracy, completeness, consistency, credibility and timeliness.
Similarly, for each of these first characteristics that have been agreed to be addressed, possible properties are identified. To this end, the municipality finally decided to work with the following quality model, which includes the following characteristics and properties:
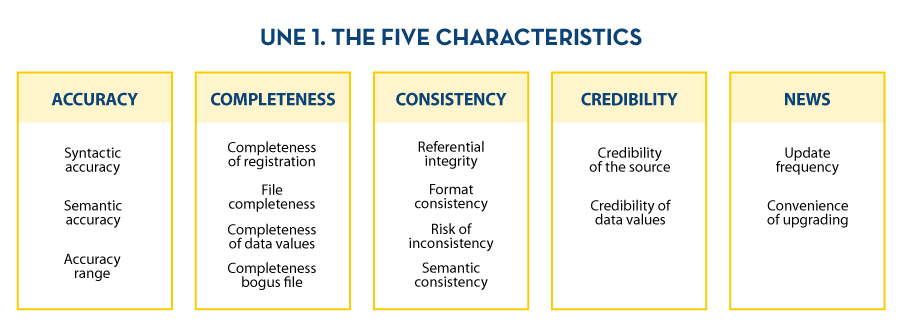
At this point, the municipality has identified the dataset to be assessed, as well as the business rules that apply to it, and which aspects of quality it will focus on (data quality model). Next, it is necessary to carry out data quality measurement through the validation of business rules. Values for the different metrics are obtained and computed in a bottom-up approach to determine the level of data quality of the repository
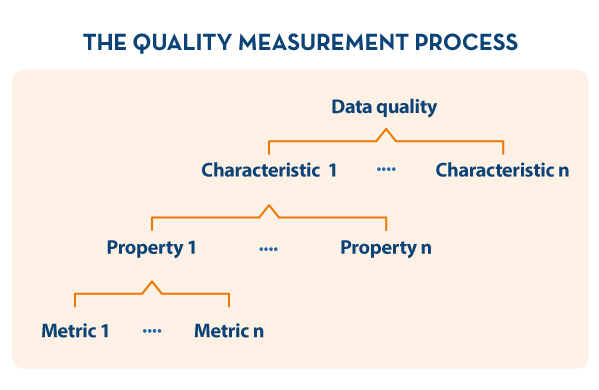
Definition of the evaluation process
In order to carry out the assessment in an appropriate way, it is decided to make use of the quality assessment process based on ISO 25024, indicated in the UNE 0081 specification (see below).
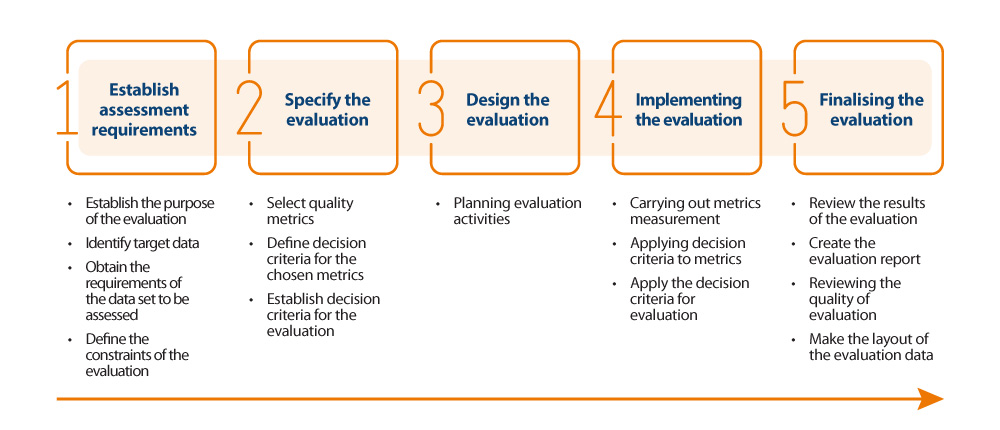
Implementation of the evaluation process
The following is a summary of the most noteworthy aspects carried out by the City Council during stage 4 of the evaluation process:
- Validation of the degree of compliance with each business rule by property: Having all the business rules classified by property, the degree of compliance with each of them is validated, thus obtaining a series of values for each of the metrics. This is run on each of the data sets to be evaluated.
As an example, for the syntactic accuracy property, two metrics are obtained:
- Number of records that comply with the syntactic correctness business rules: 826254
- Number of records that must comply with the syntactic correctness business rules: 850639
- Quantification of the value of the property: From these metrics, the value of the property is quantified and determined using the measurement function specified in the UNE 0081 specification. For the specific case of syntactic accuracy, it is determined that a record density of 97.1% complies with all syntactic accuracy rules.
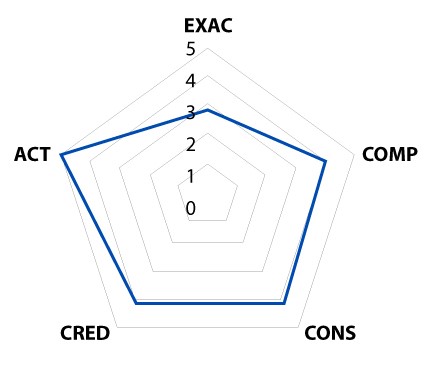
- Calculation of the characteristic value: This is done by making use of the results of each of the data quality metrics associated with a property. To calculate it, and as specified in the UNE 0081 specification, it is decided to follow a weighted sum in which each property has the same weight. In the case of Accuracy, Syntactic Accuracy values are available: 97.1, Semantic accuracy: 95, and Accuracy range: 92.9. Computing these 3 scores, a value of 95 out of 100 was obtained for this characteristic.
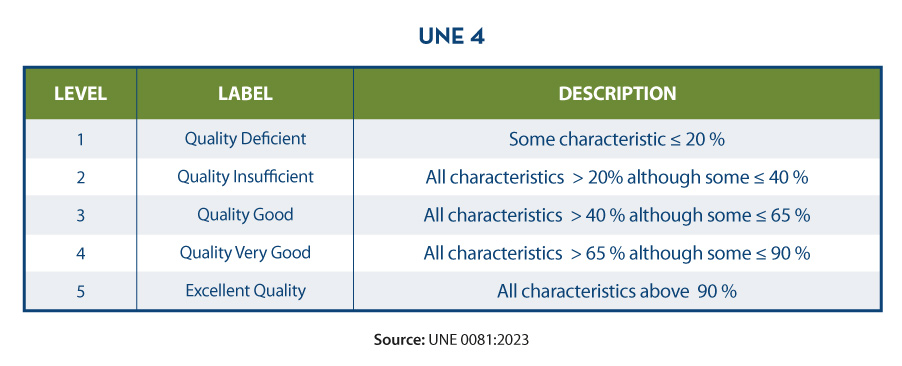
- Shift from quantitative to qualitative value: In order to provide a final quality result, it is decided to use another weighted sum; in this case, all dimensions have the same weight. Based on the above aggregated results of the above characteristics: Accuracy: 95, Completeness: 87, Consistency: 90, Credibility: 88, News: 93, a quality level of 90 out of 100 is determined for the repository. Finally, it is necessary to move from this quantitative value of 0 to 100 to a qualitative value. In this particular example, using the percentage-based quality level function, it is concluded that the quality level of the repository, for the analysed property, is 4, or "Very Good".
Results visualisation
Finally, once the evaluation of all the characteristics has been carried out, the municipality builds a series of data quality control dashboards with different levels of aggregation (characteristic, property, dataset and table/view) based on the results of the evaluation, so that the level of quality can be quickly consulted. For this purpose, results at different levels of aggregation are shown as an example.
As can be seen throughout the application example, there is a direct relationship between the application of this UNE 0081 specification, with certain parts of the 0078 specification, specifically with the data requirements management process, and with the UNE 0079specification, at least with the data planning and quality control processes. As a result of the evaluation, recommendations for quality improvement (corrective actions) will be established, which will have a direct impact on the established data processes, all in accordance with Deming's PDCA continuous improvement circle.
Once the example has been completed, and as an added value, it should be noted that it is possible to certify the level of data quality of organisational repositories. This will require a certification body to provide this data quality service, as well as an ISO 17025 accredited laboratory with the power to issue data quality assessment reports.
The content of this guide can be downloaded freely and free of charge from the AENOR portal through the link below by accessing the purchase section. Access to this family of UNE data specifications is sponsored by the Secretary of State for Digitalization and Artificial Intelligence, Directorate General for Data. Although the download requires prior registration, a 100% discount on the total price is applied at the time of finalizing the purchase. After finalizing the purchase, the selected standard or standards can be accessed from the customer area in “my products” section.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant.The content and the point of view reflected in this publication are the sole responsibility of its author.
Noticia
The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.

The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.