Noticia
The concept of High-Value data (High-Value datasets) was introduced by the European Parliament and the Council of the European Union 4 years ago, in Directive (EU) 2019/1024. In it, they were defined as a series of datasets with a high potential to generate "benefits for society, the environment and the economy". Therefore, member states were to push for their openness for free, in machine-readable formats, via APIs, in the form of bulk download and comprehensively described by metadata.
Initially, the directive proposed in its annex six thematic categories to be considered as high value: geospatial, earth observation and environmental, meteorological, statistical, business records and transport network data. These categories were subsequently detailed in an implementing regulation published in December 2022. In addition, to facilitate their openness, a document with guidelines on how to use DCAT-AP for publication was published in June 2023.
New categories of data to be considered of high value
These initial categories were always open to extension. In this sense, the European Commission has just published the report "Identification of data themes for the extensions of public sector High-Value Datasets" which includes seven new categories to be considered as high-value data
-
Climate loss: This refers to data related to approaches and actions needed to avoid, minimize and address damages associated with climate change. Examples of datasets in this category are economic and non-economic losses from extreme weather events or slow-onset changes such as sea level rise or desertification. It also includes data related to early warning systems for natural disasters, the impact of mitigation measures, or research data on the attribution of extreme events to climate change.
-
Energy: This category includes comprehensive statistics on the production, transport, trade and final consumption of primary and secondary energy sources, both renewable and non-renewable. Examples of data sets to consider are price and consumption indicators or information on energy security.
-
Finance: This is information on the situation of private companies and public administrations, which can be used to assess business performance or economic sustainability, as well as to define spending and investment strategies. It includes datasets on company registers, financial statements, mergers and acquisitions, as well as annual financial reports.
-
Government and public administration: This theme includes data that public services and companies collect to inform and improve the governance and administration of a specific territorial unit, be it a state, a region or a municipality. It includes data relating to government (e.g. minutes of meetings), citizens (census or registration in public services) and government infrastructures. These data are then reused to inform policy development, deliver public services, optimize resources and budget allocation, and provide actionable and transparent information to citizens and businesses.
-
Health: This concept identifies data sets covering the physical and mental well-being of the population, referring to both objective and subjective aspects of people's health. It also includes key indicators on the functioning of health care systems and occupational safety. Examples include data relating to Covid-19, health equity or the list of services provided by health centers.
-
Justice and legal affairs: Identifies datasets to strengthen the responsiveness, accountability and interoperability of EU justice systems, covering areas such as the application of justice, the legal system or public security, i.e. that which ensures the protection of citizens. The data sets on justice and legal matters include documentation of national or international jurisprudence, decisions of courts and prosecutors general, as well as legal acts and their content.
-
Linguistic data: Refers to written or spoken expressions that are at the basis of artificial intelligence, natural language processing and the development of related services. The Commission provides a fairly broad definition of this category of data, all of which are grouped under the term "multimodal linguistic data". They may include repositories of text collections, corpora of spoken languages, audio resources, or video recordings.

To make this selection, the authors of the report conducted desk research as well as consultations with public administrations, data experts and private companies through a series of workshops and surveys. In addition to this assessment, the study team mapped and analyzed the regulatory ecosystem around each category, as well as policy initiatives related to their harmonization and sharing, especially in relation to the creation of European Common Data Spaces.
Potential for SMEs and digital platforms
In addition to defining these categories, the study also provides a high-level estimate of the impact of the new categories on small and medium-sized companies, as well as on large digital platforms. One of the conclusions of the study is that the cost-benefit ratio of data openness is similar across all new topics, with those relating to the categories "Finance" and "Government and public administration" standing out in particular.
Based on the publicly available datasets, an estimate was also made of the current degree of maturity of the data belonging to the new categories, according to their territorial coverage and their degree of openness (taking into account whether they were open in machine-readable formats, with adequate metadata, etc.). To maximize the overall cost-benefit ratio, the study suggests selecting a different approach for each thematic category: based on their level of maturity, it is recommended to indicate a higher or lower number of mandatory criteria for publication, thus ensuring to avoid overlaps between new topics and existing high-value data.
You can read the full study at this link.
Blog
The European Open Science Cloud (EOSC) is a European Union initiative that aims to promote open science through the creation of an open, collaborative and sustainabledigital research infrastructure. EOSC's main objective is to provide European researchers with easier access to the data, tools and resources they need to conduct quality research.
EOSC on the European Research and Data Agenda
EOSC is part of the 20 actions of the European Research Area (ERA) agenda 2022-2024 and is recognised as the European data space for science, research and innovation, to be integrated with other sectoral data spaces defined in the European data strategy. Among the expected benefits of the platform are the following:
- An improvement in the confidence, quality and productivity of European science.
- The development of new innovative products and services.
- Improving the impact of research in tackling major societal challenges.
The EOSC platform
EOSC is in fact an ongoing process that sets out a roadmap in which all European states participate, based on the central idea that research data is a public good that should be available to all researchers, regardless of their location or affiliation. This model aims to ensure that scientific results comply with the FAIR (Findable, Accessible, Interoperable, Reusable) Principles to facilitate reuse, as in any other data space.
However, the most visible part of EOSC is its platform that gives access to millions of resources contributed by hundreds of content providers. This platform is designed to facilitate the search, discovery and interoperability of data and other content such as training resources, security, analysis, tools, etc. To this end, the key elements of the architecture envisaged in EOSC include two main components:
- EOSC Core: which provides all the basic elements needed to discover, share, access and reuse resources - authentication, metadata management, metrics, persistent identifiers, etc.
- EOSC Exchange: to ensure that common and thematic services for data management and exploitation are available to the scientific community.
In addition, the ESOC Interoperability Framework (EOSC-IF)is a set of policies and guidelines that enable interoperability between different resources and services and facilitate their subsequent combination.
The platform is currently available in 24 languages and is continuously updated to add new data and services. Over the next seven years, a joint investment by the EU partners of at least EUR 1 billion is foreseen for its further development.
Participation in EOSC
The evolution of EOSC is being guided by a tripartite coordinating body consisting of the European Commission itself, the participating countries represented on the EOSC Steering Board and the research community represented through the EOSC Association. In addition, in order to be part of the ESCO community, you only have to follow a series of minimum rules of participation:
- The whole EOSC concept is based on the general principle of openness.
- Existing EOSC resources must comply with the FAIR principles.
- Services must comply with the EOSC architecture and interoperability guidelines.
- EOSC follows the principles of ethical behaviour and integrity in research.
- EOSC users are also expected to contribute to EOSC.
- Users must comply with the terms and conditions associated with the data they use.
- EOSC users always cite the sources of the resources they use in their work.
- Participation in EOSC is subject to applicable policies and legislation.
EOSC in Spain
The Consejo Superior de Investigaciones Científicas (CSIC) of Spain was one of the 4 founding members of the association and is currently a commissioned member of the association, in charge of coordination at national level.
CSIC has been working for years on its open access repository DIGITAL.CSIC as a step towards its future integration into EOSC. Within its work in open science we can highlight for example the adoption of the Current Research Information System (CRIS), information systems designed to help research institutions to collect, organise and manage data on their research activity: researchers, projects, publications, patents, collaborations, funding, etc.
CRIS are already important tools in helping institutions track and manage their scientific output, promoting transparency and open access to research. But they can also play an important role as sources of information feeding into the EOSC, as data collected in CRIS can also be easily shared and used through the EOSC.
The road to open science
Collaboration between CRIS and ESCO has the potential to significantly improve the accessibility and re-use of research data, but there are also other transitional actions that can be taken on the road to producing increasingly open science:
- Ensure the quality of metadata to facilitate open data exchange.
- Disseminate the FAIR principles among the research community.
- Promote and develop common standards to facilitate interoperability.
- Encourage the use of open repositories.
- Contribute by sharing resources with the rest of the community.
This will help to boost open science, increasing the efficiency, transparency and replicability of research.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Noticia
Under the Spanish Presidency of the Council of the European Union, the Government of Spain has led the Gaia-X Summit 2023, held in Alicante on November 9 and 10. The event aimed to review the latest advances of Gaia-X in promoting data sovereignty in Europe. As presented on datos.gob.es, Gaia-X is a European private sector initiative for the creation of a federated, open, interoperable, and reversible data infrastructure, fostering digital sovereignty and data availability.
The summit has also served as a space for the exchange of ideas among the leading voices in the European data spaces community, culminating in the presentation of a statement to boost strategic autonomy in cloud computing, data, and artificial intelligence—considered crucial for EU competitiveness. The document, promoted by the State Secretariat for Digitization and Artificial Intelligence, constitutes a joint call for a "more coherent and coordinated" response in the development of programs and projects, both at the European and member state levels, related to data and sector technologies.
To achieve this, the statement advocates for interoperability supported by a robust cloud services infrastructure and the development of high-quality data-based artificial intelligence with a robust governance framework in compliance with European regulatory frameworks. Specifically, it highlights the possibilities offered by Deep Neural Networks, where success relies on three main factors: algorithms, computing capacity, and access to large amounts of data. In this regard, the document emphasizes the need to invest in the latter factor, promoting a neural network paradigm based on high-quality, well-parameterized data in shared infrastructures, not only saving valuable time for researchers but also mitigating environmental degradation by reducing computing needs beyond the brute force paradigm.
For this reason, another aspect addressed in the document is the stimulation of access to data sources from different complementary domains. This would enable a "flexible, dynamic, and highly scalable" data economy to optimize processes, innovate, and/or create new business models.
The call is optimistic about existing European initiatives and programs, starting with the Gaia-X project itself. Other projects highlighted include IPCEI-CIS or the Simpl European project. It also emphasizes the need for "broader and more effective coordination to drive industrial projects, advance the standardization of cloud and reliable data tags, ensuring high levels of cybersecurity, data protection, algorithmic transparency, and portability."
The statement underscores the importance of achieving a single data market that includes data exchange processes under a common governance framework. It values the innovative set of digital and data legislation, such as the Data Act, with the goal of promoting data availability across the Union. The statement is open to new members seeking to advance the promotion of a flexible, dynamic, and highly scalable data economy.
You can read the full document here: The Trinity of Trusted Cloud Data and AI as a Gateway to EU's Competitiveness
Blog
On September 8, the webinar \"Geospatial Trends 2023: Opportunities for data.europa.eu\" was held, organized by the Data Europa Academy and focused on emerging trends in the geospatial field. Specifically, the online conference addressed the concept of GeoAI (Geospatial Artificial Intelligence), which involves the application of artificial intelligence (AI) combined with geospatial data.
Next, we will analyze the most cutting-edge technological developments of 2023 in this field, based on the knowledge provided by the experts participating in the aforementioned webinar.
What is GeoAI?
The term GeoAI, as defined by Kyoung-Sook Kim, co-chair of the GeoAI Working Group of the Open Geospatial Consortium (OGC), refers to \"a set of methods or automated entities that use geospatial data to perceive, construct (automate), and optimize spaces in which humans, as well as everything else, can safely and efficiently carry out their geographically referenced activities.\"
GeoAI allows us to create unprecedented opportunities, such as:
- Extracting geospatial data enriched with deep learning: Automating the extraction, classification, and detection of information from data such as images, videos, point clouds, and text.
- Conducting predictive analysis with machine learning: Facilitating the creation of more accurate prediction models, pattern detection, and automation of spatial algorithms.
- Improving the quality, uniformity, and accuracy of data: Streamlining manual data generation workflows through automation to enhance efficiency and reduce costs.
- Accelerating the time to gain situational knowledge: Assisting in responding more rapidly to environmental needs and making more proactive, data-driven decisions in real-time.
- Incorporating location intelligence into decision-making: Offering new possibilities in decision-making based on data from the current state of the area that needs governance or planning.
Although this technology gained prominence in 2023, it was already discussed in the 2022 geospatial trends report, where it was indicated that integrating artificial intelligence into spatial data represents a great opportunity in the world of open data and the geospatial sector.
Use Cases of GeoAI
During the Geospatial Trends 2023 conference, companies in the GIS sector, Con terra and 52ºNorth, shared practical examples highlighting the use of GeoAI in various geospatial applications.
Examples presented by Con terra included:
- KINoPro: A research project using GeoAI to predict the activity of the \"black arches\" moth and its impact on German forests.
- Anomaly detection in cell towers: Using a neural network to detect causes of anomalies in towers that can affect the location in emergency calls.
- Automated analysis of construction areas: Aiming to detect building areas for industrial zones using OpenData and satellite imagery.

On the other hand, 52ºNorth presented use cases such as MariData, which seeks to reduce emissions from maritime transport by using GeoAI to calculate optimal routes, considering ship position, environmental data, and maritime traffic regulations. They also presented KI:STE, which applies artificial intelligence technologies in environmental sciences for various projects, including classifying Sentinel-2 images into (un)protected areas.
These projects highlight the importance of GeoAI in various applications, from predicting environmental events to optimizing maritime transport routes. They all emphasize that this technology is a crucial tool for addressing complex problems in the geospatial community.
GeoAI not only represents a significant opportunity for the spatial sector but also tests the importance of having open data that adheres to FAIR principles (Findable, Accessible, Interoperable, Reusable). These principles are essential for GeoAI projects as they ensure transparent, efficient, and ethical access to information. By adhering to FAIR principles, datasets become more accessible to researchers and developers, fostering collaboration and continuous improvement of models. Additionally, transparency and the ability to reuse open data contribute to building trust in results obtained through GeoAI projects.
Reference
| Reference video | https://www.youtube.com/watch?v=YYiMQOQpk8A |
Blog
The active participation of young people in civic and political life is one of the keys to strengthening democracy in Europe. Analyzing and understanding the voice of young people provides insight into their attitudes and opinions, something that helps to foresee future trends in society with sufficient room for maneuver to address their needs and concerns towards a more prosperous and comfortable future for all.
In the mission to gain a clearer perspective on how they participate in Europe, open data has become a valuable tool. In this post, we will explore how young people in Europe actively engage in society and politics through relevant European Union (EU) open data published on the European open data portal.
Youth commitment in the European elections
The European Union has as one of its objectives to promote the active participation of young people in democracy and society. Their participation in elections and civic activities enriches European democracy. Young people bring diverse ideas and perspectives, which contributes to decision-making and ensures that policies are tailored to their needs and challenges. In addition, their participation contributes to a political system that reflects the interests of all citizens, which in turn fosters an inclusive and peaceful society.
In the last European Parliament elections, the highest turnout in the last 20 years was achieved, with more than 50% of the European population voting, as corroborated by the EU's Eurobarometer post-election survey. This increase in turnout was largely due to an increase in youth participation.
The data show that the younger generation (under 25) increased their electoral participation by 14% to 42%, while the participation of 25-39 year olds increased by 12% to 47%, compared between the 2014 and 2019 European elections. This growth in youth participation raises a question: what motivated young people to participate more? According to the 2021 Eurobarometer Youth Survey, a sense of duty as a citizen (32%) and a willingness to take responsibility for the future (32%) were the main factors motivating young people to vote in the European elections.

Why do young people want to participate in the EU?
In addition to voting in elections, there are other ways in which young people demonstrate that they are an active part of citizenship. The Youth Survey 2021 reveals interesting data about their interest in politics and civic life.
In general, politics is a topic that interests them. The majority of participants in the Youth Survey 2021 claimed to discuss politics with friends or family (85%). In addition, many said they understand how their country's national government works (58%). However, most young people feel they have little influence on important decisions, laws, and policies that affect them. Young people feel they have more say in their local government (47%), than in the national government (40%) or at the EU level (30%).
The next step, after understanding the policy, is action. Young people believe that certain political and civic activities are more effective than others in getting their voice to decision-makers. In order, voting in elections (41%), participating in protests or street demonstrations (33%) and participating in petitions (30%) were considered the three most effective activities by respondents. Many young people had voted in their last local, national or European elections (46%) and had created or signed a petition (42%).
However, the survey reveals an interesting divergence between young people's perceptions and their actions. On some occasions, youth get involved in activities even though they are not what they consider to be the most effective, as in the case of online signature petitions. On the other hand, they do not always participate in activities that they perceive to be effective, such as street protests or contact with politicians.

The youth impulse for European democracy
Young people want the issues they see as priorities to be on the political agenda of the next European elections. A more recent special Eurobarometer on democracy in action in 2023 revealed that young people aged 15-24 are the age group most satisfied with the functioning of democracy in the EU (61%, compared to the EU average of 54%).
Climate change is a particularly prominent concern among young people, with 40% of respondents aged 15-24 considering this issue a priority, compared to 31% of the general EU population.
To encourage youth participation in the European political agenda, initiatives have been developed that use open data to bring politics closer to citizens. Examples such as TrackmyEU and Democracy Game seek to engage young people in politics and enable them to access information on EU policies and participate in debates and civic activities.
In general, open data provides valuable insights into many realities, for example, that affecting youth and their interaction in society and politics. This analysis enables governments and public administrations to make informed decisions on issues affecting this social group. Young Europeans are interested in politics, actively participate in elections and get involved in youth organizations; they are concerned about issues such as inequality and climate change. Open data is also used in initiatives that promote the participation of young people in political and civic life, further strengthening European democracy.
In an increasingly digital and data-driven society, access to open data is essential to understand the concerns and interests of youth and their participation in civic and political decision-making. As a part of an active and engaged citizenry, youth have an important role to play in Europe's future, and open data is an essential tool to support their participation.
Content based on the post from the European open data portal Understanding youth engagement in Europe through open data.
Blog
IATE, which stands for Interactive Terminology for Europe, is a dynamic database designed to support the multilingual drafting of European Union texts. It aims to provide relevant, reliable and easily accessible data with a distinctive added value compared to other sources of lexical information such as electronic archives, translation memories or the Internet.
This tool is of interest to EU institutions that have been using it since 2004 and to anyone, such as language professionals or academics, public administrations, companies or the general public. This project, launched in 1999 by the Translation Center, is available to any organization or individual who needs to draft, translate or interpret a text on the EU.
Origin and usability of the platform
IATE was created in 2004 by merging different EU terminology databases.The original Eurodicautom, TIS, Euterpe, Euroterms and CDCTERM databases were imported into IATE. This process resulted in a large number of duplicate entries, with the consequence that many concepts are covered by several entries instead of just one. To solve this problem, a cleaning working group was formed and since 2015 has been responsible for organizing analyses and data cleaning initiatives to consolidate duplicate entries into a single entry. This explains why statistics on the number of entries and terms show a downward trend, as more content is deleted and updated than is created.
In addition to being able to perform queries, there is the possibility to download your datasets together with the IATExtract extraction tool that allows you to generate filtered exports.
This inter-institutional terminology base was initially designed to manage and standardize the terminology of EU agencies. Subsequently, however, it also began to be used as a support tool in the multilingual drafting of EU texts, and has now become a complex and dynamic terminology management system. Although its main purpose is to facilitate the work of translators working for the EU, it is also of great use to the general public.
IATE has been available to the public since 2007 and brings together the terminology resources of all EU translation services. The Translation Center manages the technical aspects of the project on behalf of the partners involved: European Parliament (EP), Council of the European Union (Consilium), European Commission (COM), Court of Justice (CJEU), European Central Bank (ECB), European Court of Auditors (ECA), European Economic and Social Committee (EESC/CoR), European Committee of the Regions (EESC/CoR), European Investment Bank (EIB) and the Translation Centre for the Bodies of the European Union (CoT).
The IATE data structure is based on a concept-oriented approach, which means that each entry corresponds to a concept (terms are grouped by their meaning), and each concept should ideally be covered by a single entry. Each IATE entry is divided into three levels:
-
Language Independent Level (LIL)
-
Language Level (LL)
-
Term Level (TL) For more information, see Section 3 ('Structure Overview') below.
Reference source for professionals and useful for the general public
IATE reflects the needs of translators in the European Union, so that any field that has appeared or may appear in the texts of the publications of the EU environment, its agencies and bodies can be covered. The financial crisis, the environment, fisheries and migration are areas that have been worked on intensively in recent years. To achieve the best result, IATE uses the EuroVoc thesaurus as a classification system for thematic fields.
As we have already pointed out, this database can be used by anyone who is looking for the right term about the European Union. IATE allows exploration in fields other than that of the term consulted and filtering of the domains in all EuroVoc fields and descriptors. The technologies used mean that the results obtained are highly accurate and are displayed as an enriched list that also includes a clear distinction between exact and fuzzy matches of the term.
The public version of IATE includes the official languages of the European Union, as defined in Regulation No. 1 of 1958. In addition, a systematic feed is carried out through proactive projects: if it is known that a certain topic is to be covered in EU texts, files relating to this topic are created or improved so that, when the texts arrive, the translators already have the required terminology in IATE.
How to use IATE
To search in IATE, simply type in a keyword or part of a collection name. You can define further filters for your search, such as institution, type or date of creation. Once the search has been performed, a collection and at least one display language are selected.
To download subsets of IATE data you need to be registered, a completely free option that allows you to store some user preferences in addition to downloading. Downloading is also a simple process and can be done in csv or tbx format.
The IATE download file, whose information can also be accessed in other ways, contains the following fields:
-
Language independent level:
-
Token number: the unique identifier of each concept.
-
Subject field: the concepts are linked to fields of knowledge in which they are used. The conceptual structure is organized around twenty-one thematic fields with various subfields. It should be noted that concepts can be linked to more than one thematic field.
-
Language level:
-
Language code: each language has its own ISO code.
-
Term level
-
Term: concept of the token.
-
Type of term. They can be: terms, abbreviation, phrase, formula or short formula.
-
Reliability code. IATE uses four codes to indicate the reliability of terms: untested, minimal, reliable or very reliable.
-
Evaluation. When several terms are stored in a language, specific evaluations can be assigned as follows: preferable, admissible, discarded, obsolete and proposed.
A continuously updated terminology database
The IATE database is a document in constant growth, open to public participation, so that anyone can contribute to its growth by proposing new terminologies to be added to existing files, or to create new files: you can send your proposal to iate@cdt.europa.eu, or use the 'Comments' link that appears at the bottom right of the file of the term you are looking for. You can provide as much relevant information as you wish to justify the reliability of the proposed term, or suggest a new term for inclusion. A terminologist of the language in question will study each citizen's proposal and evaluate its inclusion in the IATE.
In August 2023, IATE announced the availability of version 2.30.0 of this data system, adding new fields to its platform and improving functions, such as the export of enriched files to optimize data filtering. As we have seen, this EU inter-institutional terminology database will continue to evolve continuously to meet the needs of EU translators and IATE users in general.
Another important aspect is that this database is used for the development of computer-assisted translation (CAT) tools, which helps to ensure the quality of the translation work of the EU translation services. The results of translators' terminology work are stored in IATE and translators, in turn, use this database for interactive searches and to feed domain- or document-specific terminology databases for use in their CAT tools.
IATE, with more than 7 million terms in over 700,000 entries, is a reference in the field of terminology and is considered the largest multilingual terminology database in the world. More than 55 million queries are made to IATE each year from more than 200 countries, which is a testament to its usefulness.
Noticia
El Instituto de Estadística y Cartografía de Andalucía (IECA), in collaboration with the Andalusian Agency for International Development Cooperation (AACID), has incorporated new indicators at the municipal level into its Sustainable Development Indicators System for Andalusia for the Agenda 2030. This effort aims to integrate statistical and geographical information while enhancing the efficiency of the Andalusian public administration and the information services provided to society.
Thanks to these efforts, Andalusia has been selected as one of the participating regions in the European project "REGIONS 2030: Monitoring the SDGs in EU regions," along with nine other regions in the European Union. All of these regions share a strong commitment to the analysis and fulfillment of the Sustainable Development Goals (SDGs), recognizing the importance of this work in decision-making and sustainable regional development.
The "REGIONS 2030" project, funded by the European Parliament and developed by the Joint Research Centre (JRC) of the European Commission in collaboration with the Directorate-General for Regional and Urban Policy (DG REGIO) and EUROSTAT, aims to fill data gaps in monitoring the SDGs in EU regions.

Image 1: "REGIONS 2030" Project: Monitoring the SDGs in EU regions.
Source: Andalusian Institute of Statistics and Cartography (IECA)
The new indicators incorporated are essential for measuring the progress of the SDGs
The Andalusian Institute of Statistics and Cartography, in collaboration with AACID, has created a set of indicators that allow for evaluating the advancement of the Sustainable Development Goals at the regional level, available on their website. All the new municipal-level indicators are identified with the Joint Research Centre (municipal) for Andalusia, and they address 9 of the 17 Sustainable Development Goals.
The methodology used for most of the indicators is based on georeferenced information from the Andalusian Institute of Statistics and Cartography, using publications on the Spatial Distribution of the Population in Andalusia and the Characterization and Distribution of Built Space in Andalusia as reference points.
One of the indicators provides information on Goal 1: No Poverty and measures the risks of poverty by assessing the percentage of people residing at an address where none of their members are affiliated with Social Security. This indicator reveals more unfavorable conditions in urban municipalities compared to rural ones, consistent with previous studies that identify cities as having more acute poverty situations than rural areas.
Similarly, the per capita Built-up Area indicator for Goal 11: Sustainable Cities and Communities has been calculated using cadastral data and geospatial processes in geographic information systems.
Visualization and query of the new municipal indicators
Allow for obtaining information at the municipal level about the value and variation of the indicators compared to the previous year, both for the entire Andalusia region and different degrees of urbanization.

Image 2: Data visualization of the indicator.
Source: Andalusian Institute of Statistics and Cartography (IECA)
Moreover, the applied filter enables an analysis of the temporal and geographical evolution of the indicators in each of the considered areas, providing a temporal and territorial perspective.
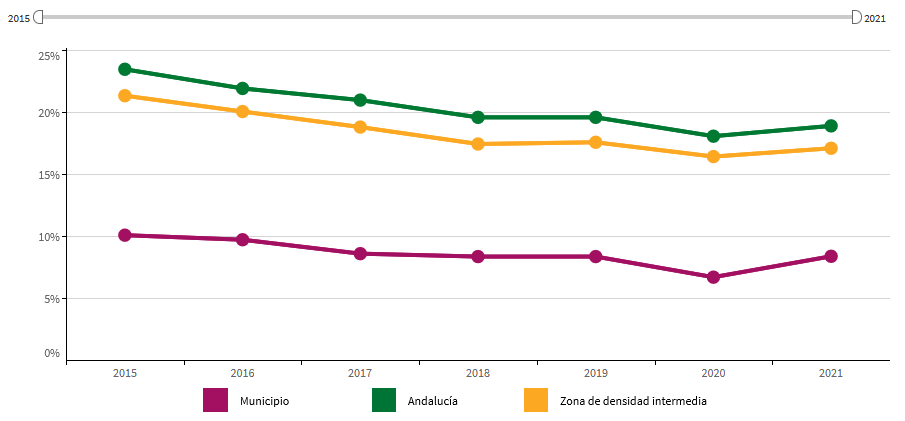
Image 3: Visualization of the indicator's evolution by area.
Source: Andalusian Institute of Statistics and Cartography (IECA)
These results are presented through an interactive map at the municipal level, displaying the distribution of the indicator in the territory.
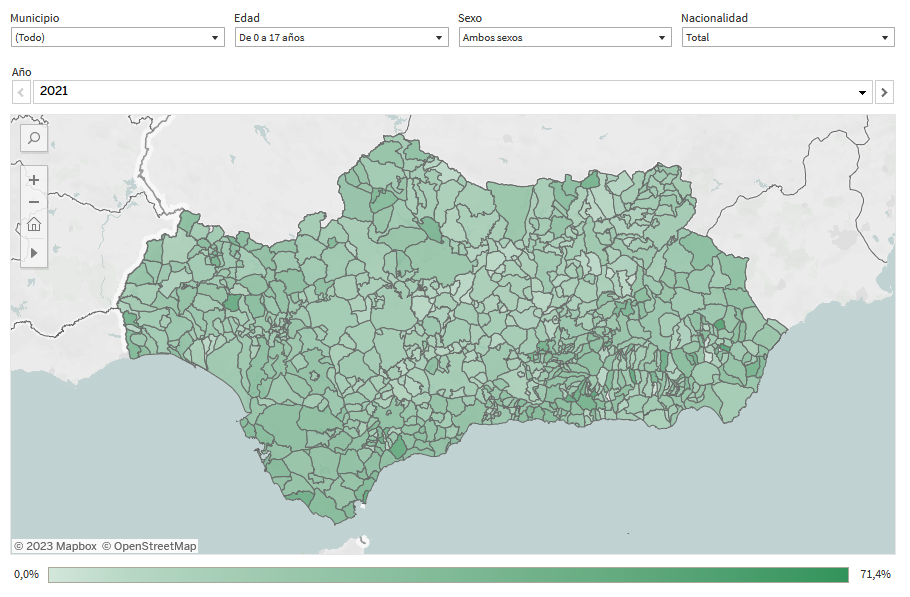
Image 4: Interactive map of the indicator.
Source: Andalusian Institute of Statistics and Cartography (IECA)
The data for the indicators are also available in downloadable structured formats (XLS, CSV, and JSON). Methodological information regarding the calculations for each indicator is provided as well.
The inclusion of Andalusia in the "REGIONS 2030" project
Has integrated all of this work with the existing Sustainable Development Indicators System for Andalusia for the Agenda 2030, which has been calculated and published by the IECA to date. This collective effort among different regions will serve to establish a methodology and select the most relevant regional indicators in Europe (NUTS2 European level) so that this methodology can be applied to all European regions in the future.
The "REGIONS 2030" project, after completing its initial work in Andalusia, has disseminated its results in the article "Monitoring the SDGs in Andalusia region, Spain," published by the European Commission in July 2023, and in an event held at the Three Cultures Foundation of the Mediterranean on September 27, under the title 'SDG Localisation and Monitoring Framework for 2030 Agenda Governance: Milestones & Challenges in Andalusia.' In this event, each selected region presented their results and discussed the needs, deficiencies, or lessons learned in generating their reports.
The "REGIONS 2030" project will conclude in December 2023 with the presentation and publication of a final report. This report will consolidate the ten regional reports generated during the monitoring of the Sustainable Development Goals at the regional level in Europe, contributing to their effective monitoring as part of the proper implementation of the Agenda 2030.
Blog
The INSPIRE (Infrastructure for Spatial Information in Europe) Directive sets out the general rules for the establishment of an Infrastructure for Spatial Information in the European Community based on the Infrastructures of the Member States. Adopted by the European Parliament and the Council on 14 March 2007 (Directive 2007/2/EC), it entered into force on 25 April 2007.
INSPIRE makes it easier to find, share and use spatial data from different countries. The information is available through an online portal where it can be found broken down into different formats and topics of interest.
To ensure that these data are compatible and interoperable in a Community and cross-border context, the Directive requires the adoption of common Implementing Rules specific to the following areas:
- Metadata
- Data sets
- Network services
- Data sharing and services
- Spatial data services
- Monitoring and reporting
The technical implementation of these standards is done through Technical Guidelines, technical documents based on international standards and norms.
Inspire and semantic interoperability
These rules are considered Commission decisions or regulations and are therefore binding in each EU country. The transposition of this Directive into Spanish law is developed through Law 14/2010 of 5 July, which refers to the infrastructures and geographic information services of Spain (LISIGE) and the IDEE portal, both of which are the result of the implementation of the INSPIRE Directive in Spain.
Semantic interoperability plays a decisive role in INSPIRE. Thanks to this, there is a common language in spatial data, as the integration of knowledge is only possible when a homogenisation or common understanding of the concepts that constitute a domain or area of knowledge is achieved. Thus, in INSPIRE, semantic interoperability is responsible for ensuring that the content of the information exchanged is understood in the same way by any system.
Therefore, in the implementation of spatial data models in INSPIRE, in GML exchange format, we can find codelists that are an important part of the INSPIRE data specifications and contribute substantially to interoperability.
In general, a codelist (or code list) contains several terms whose definitions are universally accepted and understood. Code lists promote data interoperability and constitute a shared vocabulary for a community. They can even be multilingual.
INSPIRE code lists are commonly managed and maintained in the central Federated INSPIRE Registry (ROR) which provides search capabilities, so that both end-users and client applications can easily access code list values for reference.
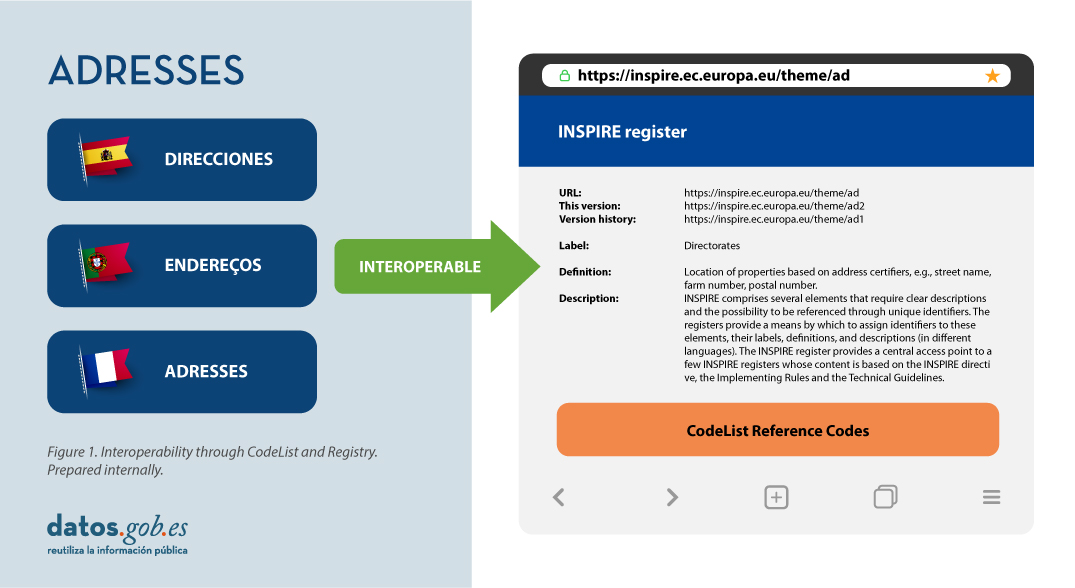
Registers are necessary because:
- They provide the codes defined in the Technical Guidelines, Regulations and Technical Specifications necessary to implement the Directive.
- They allow unambiguous references of the elements.
- Provides unique and persistent identifiers for resources.
- Enable consistent management and version control of different elements
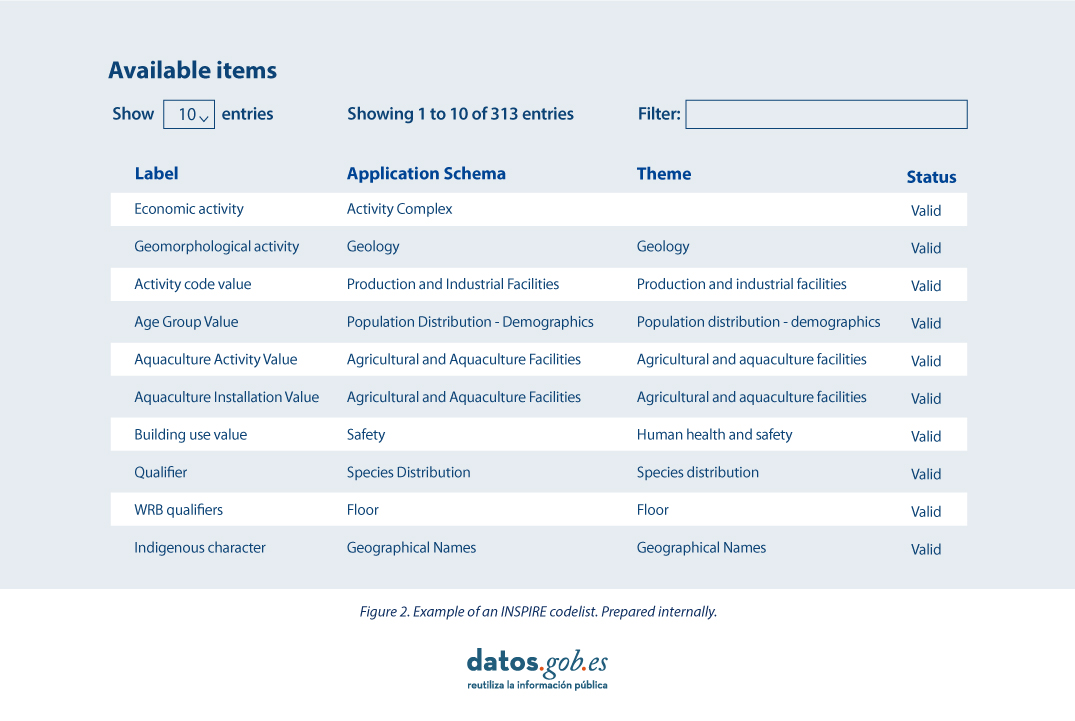
The code lists used in INSPIRE are maintained at:
- The Inspire Central Federated Registry (ROR).
- The register of code lists of a member state,
- The list registry of a recognised external third party that maintains a domain-specific code list.
To add a new code list, you will need to set up your own registry or work with the administration of one of the existing registries to publish your code list. This can be quite a complicated process, but a new tool helps us in this task.
Re3gistry is a reusable open-source solution, released under EUPL, that allows companies and organisations to manage and share \"reference codes\" through persistent URIs, ensuring that concepts are unambiguously referenced in any domain and facilitating the management of these resources graphically throughout their lifecycle.
Funded by ELISE, ISA2 is a solution recognised by the Europeans in the Interoperability Framework as a supporting tool.
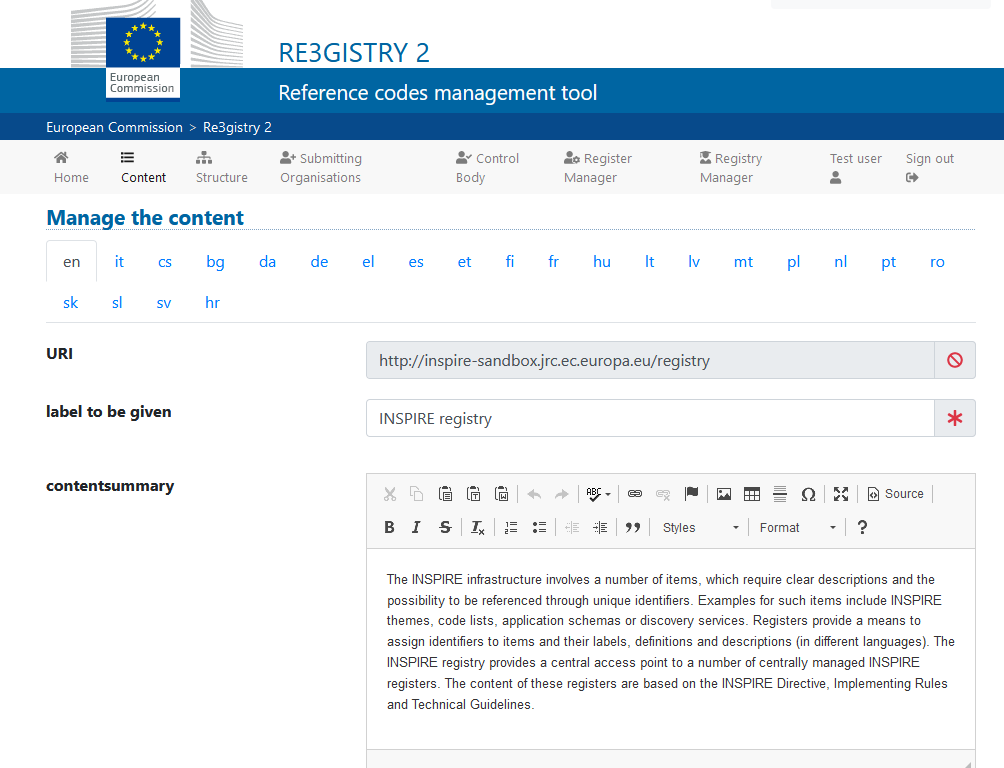
Illustration 3: Image of the Re3gister interface
Re3gistry is available for both Windows and Linux and offers an easy-to-use Web Interface for adding, editing, and managing records and reference codes. In addition, it allows the management of the complete lifecycle of reference codes (based on ISO 19135: 2005 Integrated procedures for the registration of reference codes)
The editing interface also provides a flag to allow the system to expose the reference code in the format that allows its integration with RoR, so that it can eventually be imported into the INSPIRE registry federation. For this integration, Reg3gistry makes an export in a format based on the following specifications:
- The W3C Data Catalogue (DCAT) vocabulary used to model the entity registry (dcat:Catalog).
- The W3C Simple Knowledge Organisation System (SKOS) which is used to model the entity registry (skos:ConceptScheme) and the element (skos:Concept).
Other notable features of Re3gistry
- Highly flexible and customisable data models
- Multi-language content support
- Support for version control
- RESTful API with content negotiation (including OpenAPI 3 descriptor)
- Free-text search
- Supported formats: HTML, ISO 19135 XML, JSON
- Service formats can be easily added or customised (default formats): JSON and ISO 19135 XML
- Multiple authentication options
- Externally governed elements referenced through URIs
- INSPIRE record federation format support (option to automatically create RoR format)
- Easy data export and re-indexing (SOLR)
- Guides for users, administrators, and developers
- RSS feed
Ultimately, Re3gistry provides a central access point where reference code labels and descriptions are easily accessible to both humans and machines, while fostering semantic interoperability between organisations by enabling:
- Avoid common mistakes such as misspellings, entering synonyms or filling in online forms.
- Facilitate the internationalisation of user interfaces by providing multilingual labels.
- Ensure semantic interoperability in the exchange of data between systems and applications.
- Tracking changes over time through a well-documented version control system.
- Increase the value of reference codes if they are widely reused and referenced.
More about Re3gistry:




References
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Content prepared by Mayte Toscano, Senior Consultant in Technologies linked to the data economy.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
A data space is a development framework that enables the creation of a complete ecosystem by providing an organisational, regulatory, technical and governance structure with the objective of facilitating the reliable and secure exchange of different data assets for the common benefit of all actors involved and ensuring compliance with all applicable laws and regulations. Data spaces are also a key element of the European Union's new data strategy and an essential building block in realising the goal of the European single data market.
As part of this strategy, the EU is currently exploring the creation of several data space pilots in a number of strategic sectors and domains: health, industry, agriculture, finance, mobility, Green Pact, energy, public administration and skills. These data spaces offer great potential to help organisations improve decision-making, increase innovation, develop new products, services and business models, reduce costs and avoid duplication of efforts. However, creating a successful data space is not a trivial activity and requires first carefully analysing the use cases and then facing major business, legal, operational, functional, technological and governance challenges.
This is why, as a support measure, the Data Spaces Support Centre (DSSC) has also been created to provide guidance, tools and resources to organisations interested in creating or participating in new data spaces. One of the first resources developed by the DSSC was the Data Spaces Starter Kit, the final version of which has recently been published and which provides a basic initial guide to understanding the basic elements of a data space and how to deal with the different challenges that arise when building them. We review below some of the main guidelines and recommendations offered by this starter kit.
The value of data spaces and their business models
Data spaces can be a real alternative to current unidirectional platforms, generating business models based on network effects that respond to both the supply and demand of data. Among the different business model patterns existing in data spaces, we can find:
- Cost sharing: all participants save time and money by sharing data for a common purpose, such as the smart network of connected SCSN providers.
- Joint innovation: innovation is only possible if data is shared as none of the participants have the complete data individually, e.g., the Eona-X platform for mobility, transport and tourism.
- Combined forces: different actors join forces to prevent a single actor from dominating a certain space, as in the EuPro Gigant manufacturing data network.
- Shared market: actors with common interests share data with each other in order to benefit each other, such as the Catena-X automotive network.
- Greater common good: when the public and private sectors share data for a social purpose, as for example in the mobility data space developed in Spain through the Mobility Working Group of the Gaia-X Hub.
The legal aspects
The legal side of data spaces can be a major challenge as they necessarily move between multiple legal frameworks and regulations, both national and European. To address this challenge, the Data Spaces Support Centre proposes the elaboration of a reference framework composed of three main instruments:
- The cross-cutting legal frameworks that will apply to all data spaces, such as contract law, data protection, intellectual property, competition or cybersecurity laws.
- The organisational aspects to consider when establishing models and mechanisms for data governance in each specific case.
- The contractual dimension to be taken into account when exchanging data and the agreements and terms of use to be established to make this possible.
Operational activities
The design of operational activities should address the arrangements that enable the organisational functioning of the data space, such as guidelines for onboarding new participants, decision-making and conflict resolution.
In addition, consideration should also be given to business operations, such as process streamlining and automation, marketing tasks and awareness-raising activities, which are also important components of operational activities.
Functionality of data spaces
Data spaces shall share a number of basic components (or building blocks) that will provide the minimum functionality expected of them, including at least the following elements:
- Interoperability: data models and formats, data exchange interfaces and origin and traceability.
- Trust: identity management, access and usage control and secure data exchanges.
- Data value: metadata and location protocols, data usage accounting, publishing and commercial services.
- Governance: cooperation and service level agreements and continuity models.
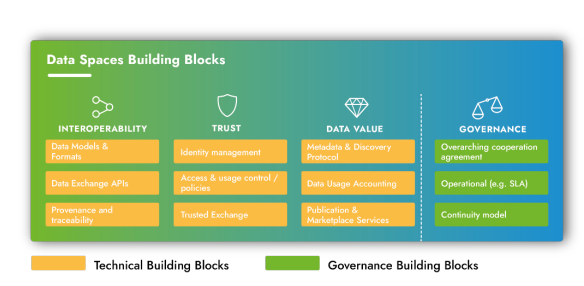
While these components can be expected to be common to all data spaces and provide similar functionality, each individual data space can make its own design choices in implementing and realising them.
Technological aspects
Data spaces are designed to be technology agnostic, i.e., defined solely in terms of functionality and with freedom in the choice of specific technologies for implementation. In this scenario it will be important to establish clear references in terms of:
- A formal basis of de facto standards to be followed.
- Specifications to serve as a reference for the different implementations.
- Open source implementations of the basic components carried out by other actors.
Governance of data spaces
Designing, implementing and maintaining a data space requires multiple organisations to collaborate together across different functions. This requires these entities to build a common vision of the key aspects of such collaboration through a governance framework.
This will require a joint design exercise through which stakeholders formalise a set of agreements defining key strategic and operational aspects, such as legal issues, description of the network of participants, code of conduct, terms and conditions of use, data space incorporation and membership agreements, and governance model.
In the near future the DSSC support centre will identify the core components of each of the dimensions described above and provide additional guidance for each of them through the development of a common blueprint for data spaces. So, if you are considering participating in any of the data spaces initiatives that are being launched, but are not quite sure where to start, then this basic starter kit will certainly be a valuable resource in understanding the basic concepts - along with the glossary that explains all the related terminology. Also, don't forget to subscribe to the support centre's newsletter to keep up to date with all the latest news, documentation and support services on offer.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
We live in the era of data, a lever of digital transformation and a strategic asset for innovation and the development of new technologies and services. Data, beyond the skills it brings to the generator and/or owner of the same, also has the peculiarity of being a non-rival asset. This means that it can be reused without detriment to the owner of the original rights, which makes it a resource with a high degree of scalability in its sharing and exploitation.
This possibility of non-rival sharing, in addition to opening potential new lines of business for the original owners, also carries a huge latent value for the development of new business models. And although sharing is not new, it is still very limited to niche contexts of sector specialisation, mediated either by trust between parties (usually forged in advance), or tedious and disciplined contractual conditions. This is why the innovative concept of data space has emerged, which in its most simplified sense is nothing more than the modelling of the general conditions under which to deploy a voluntary, sovereign and secure sharing of data. Once modelled, the prescription of considerations and methodologies (technological, organisational and operational) allows to make such sharing tangible based on peer-to-peer interactions, which together shape federated ecosystems of data sets and services.
Therefore, and given the distributed nature of data spaces (they are not a monolithic computer system, nor a centralised platform), an optimal way to approach their construction is through the creation and deployment of use cases.
The Data Office has created this infographic of a 'Model of use case development within data spaces', with the objective of synthetically defining the phases of this iterative journey, which progressively shapes a data space. This model also serves as a general framework for other technical and methodological deliverables to come, such as the 'Use Case Feasibility Assessment Guide', or the 'Use Case Design Guide', elements with which to facilitate the implementation of practical (and scalable by design) data sharing experiences, a sine qua non condition to articulate the longed-for European single data market.
The challenge of building a data space
To make the process of developing a data space more accessible, we could assimilate the definition and construction of a use case as a construction project, in which from an initial business problem (needs or challenges, desires, or problems to be solved) a goal is reached in which value is added to the business, providing a solution to those initial needs. This infographic offers a synthesis of that journey.

These are the phases of the model:
PHASE 1: Definition of the business problem. In this phase a group of potential participants detects an opportunity around the sharing of their data (hitherto siloed) and its corresponding exploitation. This opportunity can be new products or services (innovation), efficiency improvements, or the resolution of a business problem. In other words, there is a business objective that the group can solve jointly, by sharing data.
PHASE 2: Data-driven modelling. In this phase, those elements that serve to structure and organise the data for strategic decision-making based on its exploitation will be identified. It involves defining a model that possibly uses multidisciplinary tools to achieve business results. This is the part traditionally associated with data science tasks.
PHASE 3: Consensus on requirements specification. Here, the actors sponsoring the use case must establish the relationship model to have during this collaborative project around the data. Such a formula must: (i) define and establish the rules of engagement, (ii) define a common set of policies and governance model, and (iii) define a trust model that acts as the root of the relationship.
PHASES 4 and 5: Use case mapping. As in a construction project, the blueprint is the means of expressing the ideas of those who have defined and agreed the use case, and should explicitly capture the solutions proposed for each part of the use case development. This plan is unique for each use case, and phase 5 corresponds to its construction. However, it is not created from scratch, but there are multiple references that allow the use of previously identified materials and techniques. For example, models, methodologies, artefacts, templates, technological components or solutions as a service. Thus, just as an architect designing a building can reuse recognised standards, in the world of data spaces there are also models on which to paint the components and processes of a use case. The analysis and synthesis of these references is phase 4.
PHASE 6: Technology selection, parameterisation and/or development. The technology enables the deployment of the transformation and exploitation of the data, favouring the entire life cycle, from its collection to its valorisation. In this phase, the infrastructure that supports the use case is implemented, understood as the collection of tools, platforms, applications and/or pieces of software necessary for the operation of the application.
PHASE 7: Integration, testing and deployment. Like any technological construction process, the use case will go through the phases of integration, testing and deployment. The integration work and the functional, usability, exploratory and acceptance tests, etc. will help us to achieve the desired configuration for the operational deployment of the use case. In the case of wanting to incorporate a use case into a pre-existing data space, the integration would seek to fit within its structure, which means modelling the requirements of the use case within the processes and building blocks of the data space.
PHASE 8: Operational data space. The end point of this journey is the operational use case, which will employ digital services deployed on top of the data space structure, and whose architecture supports different resources and functionalities federated by design. This implies that the value creation lifecycle would have been efficiently articulated based on the shared data, and business returns are achieved according to the original approach. However, this does not prevent the data space from continuing to evolve a posteriori, as its vocation is to grow either with the entry of new challenges, or actors to existing use cases. In fact, the scalability of the model is one of its unique strengths.
In essence, the data shared through a federated and interoperable ecosystem is the input that feeds a layer of services that will generate value and solve the original needs and challenges posed, in a journey that goes from the definition of a business problem to its resolution.