Blog
Data has become the great transforming power of society. Beyond the more mercantilist view, its capacity to generate knowledge, drive innovation and empower individuals and communities is undeniable. Indeed, it is a resource with which to address, from an innovative perspective, major environmental, social and health challenges, enabling collaboration between actors, driving innovation and improving accountability.
Following European guidelines such as the European Data Strategy, the challenge now is to promote the circulation of data for the benefit of all, by pooling data in key sectors with the creation of common and interoperabledata spaces. A data space is an ecosystem where the voluntary sharing of its participants' data takes place within an environment of sovereignty, trust and security, established through integrated governance, organisational, regulatory and technical mechanisms. Data spaces are key to the development of the data economy, enabling access, exchange and legitimate re-use, positioning data as a non-rivalrous resource, whose utility grows as its use becomes more widespread, in a clear example of the network effect.
What are the Coordinated Support Actions (CSA)?
In order to foster the development of data spaces, the European Commission's Digital Europe Programme (DIGITAL) is funding a series of Coordinated Support Actions (CSA) to foster their development. Most of these actions have a funding of around one million euros per project and a duration of approximately one year, with an expected completion date in the fourth quarter of 2023. Their results should contribute to the objectives of the DIGITAL programme, which aims to bridge the gap between research and deployment of digital technologies, and to facilitate the transfer of research results to the market, to the benefit of European citizens and businesses, especially small and medium-sized ones.
Each concrete action focuses on a particular sector of economic activity seeking, based on a mapping of the data landscape of each sector concerned, to contact and connect relevant stakeholders, seeking to collaboratively develop a shared strategic roadmap. This shared roadmap ultimately aims to eventually build up the corresponding sectoral data spacesin subsequent phases. During the process, clear objectives and key results are defined to inspire, support and motivate all stakeholders to contribute and use high quality sectoral data as a basis for innovation and value generation.
In order to carry out this roadmap, a comprehensive inventory of existing platforms that already share relevant data has been drawn up. In addition, each CSA project has focused, through different working groups and stakeholder workshops, on developing recommendations on governance models for data spaces and digital business models for their sector. The aim is to identify key success factors and outline how a data space can create value and benefits not only for the sector in question but also for other sectors with which it is interlinked. In addition, plans to address the technical and organisational challenges that drive the use of interoperability standards are made in the different projects in close collaboration with the Data Spatial Support Centre (DSSC) in order to align with the European Technological Framework for Data Spaces.
Where can I find up-to-date information on CSAs?
Concrete information on the state of play of the different coordination and support actions can be found on their websites through the following links:
 |
DATES (Tourism) |
 |
Tourism Data Space (Tourism) |
 |
DS4SKills (Skills) |
 |
PrepDSpace4Mobility (Mobility) |
 |
AgriDataSpace (Agri-food) |
 |
Great (Environmental) |
 |
DataSp4ce (Industrial) |
 |
DS4SSCC (Smarts Cities) |
The outcome of these coordinated support actions will provide the information and the basis for the correct execution of the projects for the development and implementation (\"deployments\") of the Common European Data Spaces, which will be supported by different European programmes. This will catalyse the creation of a single data market, based on reliable and quality data, which will enable the digitisation of industries' value chains. Moreover, its effective development will support the European Union's objectives of achieving a green transition and a digital transformation, and of strengthening its resilience and strategic autonomy.
Blog
As tradition dictates, the end of the year is a good time to reflect on our goals and objectives for the new phase that begins after the chimes. In data, the start of a new year also provides opportunities to chart an interoperable and digital future that will enable the development of a robust data economy robust data economy, a scenario that benefits researchers, public administrations and private companies alike, as well as having a positive impact on the citizen as the end customer of many data-driven operations, optimising and reducing processing times. To this end, there is the European Data Strategy strategy, which aims to unlock the potential of data through, among others, the Data Act (Data Act), which contains a set of measures related to fair access to and use of data fair access to and use of data ensuring also that the data handled is of high quality, properly secured, etc.
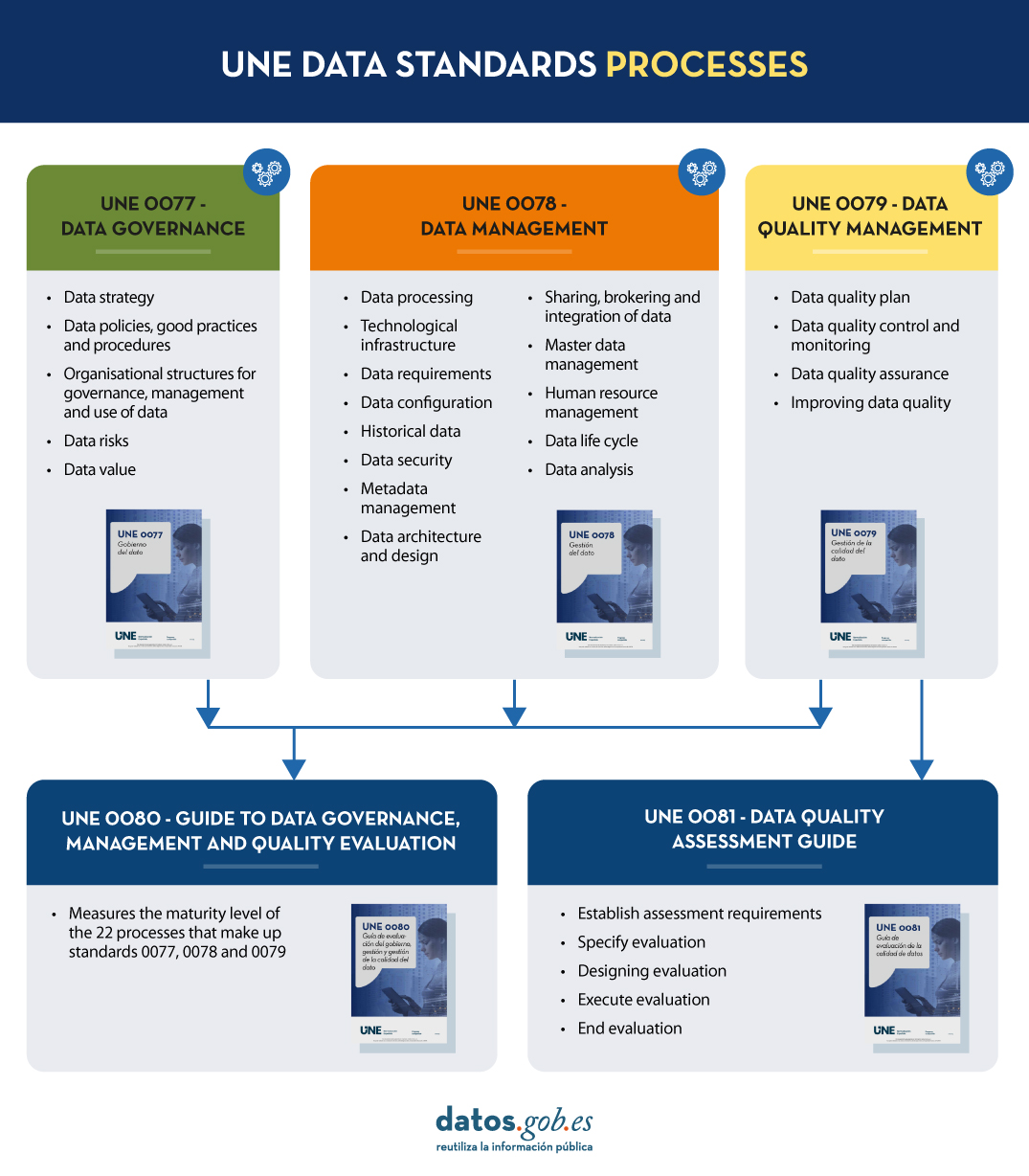
As a solution to this need, in the last year the uNE data specifications which are normative and informative resources for implementing common data governance, management and quality processes. These specifications, supported by the Data Officethese specifications, supported by the Data Office, establish standards for well-governed data (UNE 0077), managed (UNE 0078) and with adequate levels of quality (UNE 0079), thus allowing for sustainable growth in the organisation during the implementation of the different processes. In addition to these three specifications, the UNE 0080 specification defines a maturity assessment guide and process to measure the degree of implementation of data governance, management and quality processes. For its part, the UNE 0081 also establishes a process of evaluation of the data asset itself, i.e. of the data sets, regardless of their nature or typology; in short, its content is closely related to UNE 0079 because it sets out data quality characteristics. Adopting all of them can provide multiple benefits. In this post, we look at what they are and what the process would be like for each specification.
So, with an eye to the future, we set a New Year's resolution: the application of the UNE data specifications to an organisation.
What are the benefits of your application and how can I access them?
In today's era, where data governance and efficient data management have become a fundamental pillar of organisational success, the implementation of the uNE data specifications specifications emerge as a guiding light towards excellence, leading the way forward. These specifications describe rigorous standardised processes that offer organisations the possibility to build a robust and reliable structure for the management of their data and information throughout its lifecycle.
By adopting the UNE specifications, you not only ensure data quality and security, but also provide a solid and adequate basis for informed decision-making by enriching organisational processes with good data practices. Therefore, any organisation that chooses to embrace these regulations in the new year will be moving closer to innovation, efficiency and trust in data governance and management; as well as preparing to meet the challenges and opportunities that the digital future holds digital future. The application of UNE specifications is not only a commitment to quality, but a strategic investment that paves the way for sustainable success in an increasingly competitive and dynamic business environment because:
- Maximising value contribution to business strategy
- Minimises risks in data processing
- Optimise tasks by avoiding unnecessary work
- It establishes homogeneous frameworks for reference and certification
- Facilitates information sharing with trust and sovereignty
The content of the guides can be downloaded free of charge from the AENOR portal via the links below. Registration is required for downloading. The discount on the total price is applied at the time of checkout.
- SPECIFICATION UNE 0077:2023
- SPECIFICATION UNE 0078:2023
- SPECIFICATION UNE 0079:2023
- SPECIFICATION UNE 0080:2023
- SPECIFICATION UNE 0081:2023
From datos.gob.es we have echoed the content of the same and we have prepared different didactic resources such as this infographic or this explanatory video.
How do they apply to an organisation?
Once the decision has been taken to address the implementation of these specifications, a crucial question arises: what is the most effective way to do this? The answer to this question will depend on the initial situation (marked by an initial maturity assessment), the type of organisation and the resources available at the time of establishing the master plan or implementation plan. Nevertheless, at datos.gob.es, we have published a series of contents prepared by experts in technologies linked to the data economy datos.gob.es, we have published a series of contents elaborated by experts in technologies linked to the data economy that will accompany you in the process.
Before starting, it is important to know the different processes that make up each of the UNE data specifications. This image shows what they are.
Once the basics are understood, the series of contents 'Application of the UNE data specifications' deals with a practical exercise, broken down into three posts, on a specific use case: the application of these specifications to open data. As an example, a need is defined for the fictitious Vistabella Town Council: to make progress in the open publication of information on public transport and cultural events.
- In the first post of the series, the importance of using the UNE 0077 data using the UNE 0077 Data Governance Specification to establish approved mechanisms to support the openness and publication of open data. Through this first content, an overview of the processes necessary to align the organisational strategy in such a way as to achieve maximum transparency and quality of public services through the reuse of information is provided.
- The second article in the series takes a closer look at the uNE 0079 data quality management standard and its application in the context of open data and its application in the context of open data. This content underlines that the quality of open data goes beyond the FAIR principles fAIR principles principles and stresses the importance of assessing quality using objective criteria. Through the practical exercise, we explore how Vistabella Town Council approaches the UNE processes to improve the quality of open data as part of its strategy to enhance the publication of data on public transport and cultural events.
- Finally, the uNE 0078 standard on data management is explained in a third article presenting the Data Sharing, Intermediation and Integration (CIIDat) process for the publication of open data, combined with specific templates.
Together, these three articles provide a guide for any organisation to move successfully towards open publication of key information, ensuring consistency and quality of data. By following these steps, organisations will be prepared to comply with regulatory standards with all the benefits that this entails.
Finally, embracing the New Year's resolution to implement the UNE data specifications represents a strategic and visionary commitment for any organisation, which will also be aligned with the European Data Strategy and the European roadmap that aims to shape a world-leading digital future.
Blog
The regulatory approach in the European Union has taken a major turn since the first regulation on the reuse of public sector information was promoted in 2003. Specifically, as a consequence of the European Data Strategy approved in 2020, the regulatory approach is being expanded from at least two points of view:
-
on the one hand, governance models are being promoted that take into account the need to integrate, from the design and by default, respect for other legally relevant rights and interests, such as the protection of personal data, intellectual property or commercial secrecy, as has happened in particular through the Data Governance Regulation;
-
on the other hand, extending the subjective scope of the rules to go beyond the public sector, so that obligations specifically aimed at private entities are also beginning to be contemplated, as shown by the approval in November 2023 of the Regulation on harmonized rules for fair access to and use of data (known as the Data Act).
In this new approach, data spaces take on a singular role, both in terms of the importance of the sectors they deal with (health, mobility, environment, energy...) and, above all, because of the important role they are called upon to play in facilitating the availability of large amounts of data, specifically in overcoming the technical and legal obstacles that hinder their sharing. In this regard, in Spain we already have a legal provision in this regard, which has materialized with the creation of a specific section in the Public Sector Procurement Platform.
The Strategy itself envisages the creation of "a common European data space for public administrations, in order to improve transparency and accountability of public spending and the quality of spending, fight corruption at both national and EU level, and address compliance needs, as well as support the effective implementation of EU legislation and encourage innovative applications". At the same time, however, it is recognized that "data concerning public procurement are disseminated through various systems in the Member States, are available in different formats and are not user-friendly", concluding the need, in many cases, to "improve the quality of the data".
Why a data space in the field of public procurement?
Within the activity carried out by public entities, public procurement stands out, whose relevance in the economy of the EU as a whole reaches almost 14% of GDP, so it is a strategic pole to boost a more innovative, competitive and efficient economy. However, as expressly recognized in the Commission's Communication Public Procurement: A Data Space to improve public spending, boost data-driven policy making and improve access to tenders for SMEs published in March 2023, although there is a large amount of data on public procurement, however "at the moment its usefulness for taxpayers, public decision-makers and public purchasers is scarce".
The regulation on public procurement approved in 2014 incorporated a strong commitment to the use of electronic media in the dissemination of information related to the call for tenders and the awarding of procedures, although this regulation suffers from some important limitations:
-
refers only to contracts that exceed certain minimum thresholds set at European level, which limits the measure to 20% of public procurement in the EU, so that it is up to the States themselves to promote their own transparency measures for the rest of the cases;
-
does not affect the contractual execution phase, so that it does not apply to such relevant issues as the price finally paid, the execution periods actually consumed or, among other issues, possible breaches by the contractor and, if applicable, the measures adopted by the public entities in this respect;
-
although it refers to the use of electronic media when complying with the obligation of transparency, it does not, however, contemplate the need for it to be articulated on the basis of open formats that allow the automated reuse of the information.
Certainly, since the adoption of the 2014 regulation, significant progress has been made in facilitating the standardization of the data collection process, notably by imposing the use of electronic forms for the above-mentioned thresholds as of October 25, 2023. However, a more ambitious approach was needed to "fully leverage the power of procurement data". To this end, this new initiative envisages not only measures aimed at decisively increasing the quantity and quality of data available, but also the creation of an EU-wide platform to address the current dispersion, as well as the combination with a set of tools based on advanced technologies, notably artificial intelligence.
The advantages of this approach are obvious from several points of view:
-
on the one hand, it could provide public entities with more accurate information for planning and decision-making;
-
on the other hand, it would also facilitate the control and supervision functions of the competent authorities and society in general;
-
and, above all, it would give a decisive boost to the effective access of companies and, in particular, of SMEs to information on current or future procedures in which they could compete.
What are the main challenges to be faced from a legal point of view?
The Communication on the European Public Procurement Data Space is an important initiative of great interest in that it outlines the way forward, setting out the potential benefits of its implementation, emphasizing the possibilities offered by such an ambitious approach and identifying the main conditions that would make it feasible. All this is based on the analysis of relevant use cases, the identification of the key players in this process and the establishment of a precise timetable with a time horizon up to 2025.
The promotion of a specific European data space in the field of public procurement is undoubtedly an initiative that could potentially have an enormous impact both on the contractual activity of public entities and also on companies and, in general, on society as a whole. But for this to be possible, major challenges would also have to be addressed from a legal perspective:
Firstly, there are currently no plans to extend the publication obligation to contracts below the thresholds set at European level, which would mean that most tenders would remain outside the scope of the area. This limitation poses an additional consequence, as it means leaving it up to the Member States to establish additional active publication obligations on the basis of which to collect and, if necessary, integrate the data, which could pose a major difficulty in ensuring the integration of multiple and heterogeneous data sources, particularly from the perspective of interoperability. In this respect, the Commission intends to create a harmonized set of data which, if they were to be mandatory for all public entities at European level, would not only allow data to be collected by electronic means, but also to be translated into a common language that facilitates their automated processing.
Secondly, although the Communication urges States to "endeavor to collect data at both the pre-award and post-award stages", it nevertheless makes contract completion notices voluntary. If they were mandatory, it would be possible to "achieve a much more detailed understanding of the entire public procurement cycle", as well as to encourage corrective action in legally questionable situations, both as regards the legal position of the companies that were not awarded the contracts and of the authorities responsible for carrying out audit functions.
Another of the main challenges for the optimal functioning of the European data space is the reliability of the data published, since errors can often slip in when filling in the forms or, even, this task can be perceived as a routine activity that is sometimes carried out without paying due attention to its execution, as has been demonstrated by administrative practice in relation to the CPVs. Although it must be recognized that there are currently advanced tools that could help to correct this type of dysfunction, the truth is that it is essential to go beyond the mere digitization of management processes and make a firm commitment to automated processing models that are based on data and not on documents, as is still common in many areas of the public sector. Based on these premises, it would be possible to move forward decisively from the interoperability requirements referred to above and implement the analytical tools based on emerging technologies referred to in the Communication.
The necessary adaptation of European public procurement regulations
Given the relevance of the objectives proposed and the enormous difficulty involved in the challenges indicated above, it seems justified that such an ambitious initiative with such a significant potential impact should be articulated on the basis of a solid regulatory foundation. It is essential to go beyond recommendations, establishing clear and precise legal obligations for the Member States and, in general, for public entities, when managing and disseminating information on their contractual activity, as has been proposed, for example, in the health data space.
In short, almost ten years after the approval of the package of directives on public procurement, perhaps the time has come to update them with a more ambitious approach that, based on the requirements and possibilities of technological innovation, will allow us to really make the most of the huge amount of data generated in this area. Moreover, why not configure public procurement data as high-value data under the regulation on open data and reuse of public sector information?
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec). The contents and points of view reflected in this publication are the sole responsibility of its author.
Application
Kohesio is a comprehensive knowledge database that provides easy and transparent access to up-to-date information on projects and beneficiaries co-financed by the EU cohesion policy during the 2014-2020 programming period.
This application is based on W3C semantic web open standards and open source tools. Its database currently contains more than 1.5 million projects and approximately 500 000 beneficiaries.
The EU Directorate-General for Regional and Urban Policy is responsible for gradually enriching Kohesio with new projects and beneficiaries for the programming period 2021-2027, in close cooperation with EU Member States and program authorities.
All datasets are available in CSV/XLSX and RDF format (see "Services" page).
EU Member States and program authorities publish lists of operations and related beneficiaries under their reporting and communication obligations Regulation (EU) No. 1303/2013, Annex XII[, and Regulation (EU) 2021/1060, Article 49].
Kohesio aggregates and standardizes the data in these lists of operations. All data published in the lists are the responsibility of the respective managing authorities.
Open data sources such as:
Noticia
The concept of High-Value data (High-Value datasets) was introduced by the European Parliament and the Council of the European Union 4 years ago, in Directive (EU) 2019/1024. In it, they were defined as a series of datasets with a high potential to generate "benefits for society, the environment and the economy". Therefore, member states were to push for their openness for free, in machine-readable formats, via APIs, in the form of bulk download and comprehensively described by metadata.
Initially, the directive proposed in its annex six thematic categories to be considered as high value: geospatial, earth observation and environmental, meteorological, statistical, business records and transport network data. These categories were subsequently detailed in an implementing regulation published in December 2022. In addition, to facilitate their openness, a document with guidelines on how to use DCAT-AP for publication was published in June 2023.
New categories of data to be considered of high value
These initial categories were always open to extension. In this sense, the European Commission has just published the report "Identification of data themes for the extensions of public sector High-Value Datasets" which includes seven new categories to be considered as high-value data
-
Climate loss: This refers to data related to approaches and actions needed to avoid, minimize and address damages associated with climate change. Examples of datasets in this category are economic and non-economic losses from extreme weather events or slow-onset changes such as sea level rise or desertification. It also includes data related to early warning systems for natural disasters, the impact of mitigation measures, or research data on the attribution of extreme events to climate change.
-
Energy: This category includes comprehensive statistics on the production, transport, trade and final consumption of primary and secondary energy sources, both renewable and non-renewable. Examples of data sets to consider are price and consumption indicators or information on energy security.
-
Finance: This is information on the situation of private companies and public administrations, which can be used to assess business performance or economic sustainability, as well as to define spending and investment strategies. It includes datasets on company registers, financial statements, mergers and acquisitions, as well as annual financial reports.
-
Government and public administration: This theme includes data that public services and companies collect to inform and improve the governance and administration of a specific territorial unit, be it a state, a region or a municipality. It includes data relating to government (e.g. minutes of meetings), citizens (census or registration in public services) and government infrastructures. These data are then reused to inform policy development, deliver public services, optimize resources and budget allocation, and provide actionable and transparent information to citizens and businesses.
-
Health: This concept identifies data sets covering the physical and mental well-being of the population, referring to both objective and subjective aspects of people's health. It also includes key indicators on the functioning of health care systems and occupational safety. Examples include data relating to Covid-19, health equity or the list of services provided by health centers.
-
Justice and legal affairs: Identifies datasets to strengthen the responsiveness, accountability and interoperability of EU justice systems, covering areas such as the application of justice, the legal system or public security, i.e. that which ensures the protection of citizens. The data sets on justice and legal matters include documentation of national or international jurisprudence, decisions of courts and prosecutors general, as well as legal acts and their content.
-
Linguistic data: Refers to written or spoken expressions that are at the basis of artificial intelligence, natural language processing and the development of related services. The Commission provides a fairly broad definition of this category of data, all of which are grouped under the term "multimodal linguistic data". They may include repositories of text collections, corpora of spoken languages, audio resources, or video recordings.

To make this selection, the authors of the report conducted desk research as well as consultations with public administrations, data experts and private companies through a series of workshops and surveys. In addition to this assessment, the study team mapped and analyzed the regulatory ecosystem around each category, as well as policy initiatives related to their harmonization and sharing, especially in relation to the creation of European Common Data Spaces.
Potential for SMEs and digital platforms
In addition to defining these categories, the study also provides a high-level estimate of the impact of the new categories on small and medium-sized companies, as well as on large digital platforms. One of the conclusions of the study is that the cost-benefit ratio of data openness is similar across all new topics, with those relating to the categories "Finance" and "Government and public administration" standing out in particular.
Based on the publicly available datasets, an estimate was also made of the current degree of maturity of the data belonging to the new categories, according to their territorial coverage and their degree of openness (taking into account whether they were open in machine-readable formats, with adequate metadata, etc.). To maximize the overall cost-benefit ratio, the study suggests selecting a different approach for each thematic category: based on their level of maturity, it is recommended to indicate a higher or lower number of mandatory criteria for publication, thus ensuring to avoid overlaps between new topics and existing high-value data.
You can read the full study at this link.
Blog
The European Open Science Cloud (EOSC) is a European Union initiative that aims to promote open science through the creation of an open, collaborative and sustainabledigital research infrastructure. EOSC's main objective is to provide European researchers with easier access to the data, tools and resources they need to conduct quality research.
EOSC on the European Research and Data Agenda
EOSC is part of the 20 actions of the European Research Area (ERA) agenda 2022-2024 and is recognised as the European data space for science, research and innovation, to be integrated with other sectoral data spaces defined in the European data strategy. Among the expected benefits of the platform are the following:
- An improvement in the confidence, quality and productivity of European science.
- The development of new innovative products and services.
- Improving the impact of research in tackling major societal challenges.
The EOSC platform
EOSC is in fact an ongoing process that sets out a roadmap in which all European states participate, based on the central idea that research data is a public good that should be available to all researchers, regardless of their location or affiliation. This model aims to ensure that scientific results comply with the FAIR (Findable, Accessible, Interoperable, Reusable) Principles to facilitate reuse, as in any other data space.
However, the most visible part of EOSC is its platform that gives access to millions of resources contributed by hundreds of content providers. This platform is designed to facilitate the search, discovery and interoperability of data and other content such as training resources, security, analysis, tools, etc. To this end, the key elements of the architecture envisaged in EOSC include two main components:
- EOSC Core: which provides all the basic elements needed to discover, share, access and reuse resources - authentication, metadata management, metrics, persistent identifiers, etc.
- EOSC Exchange: to ensure that common and thematic services for data management and exploitation are available to the scientific community.
In addition, the ESOC Interoperability Framework (EOSC-IF)is a set of policies and guidelines that enable interoperability between different resources and services and facilitate their subsequent combination.
The platform is currently available in 24 languages and is continuously updated to add new data and services. Over the next seven years, a joint investment by the EU partners of at least EUR 1 billion is foreseen for its further development.
Participation in EOSC
The evolution of EOSC is being guided by a tripartite coordinating body consisting of the European Commission itself, the participating countries represented on the EOSC Steering Board and the research community represented through the EOSC Association. In addition, in order to be part of the ESCO community, you only have to follow a series of minimum rules of participation:
- The whole EOSC concept is based on the general principle of openness.
- Existing EOSC resources must comply with the FAIR principles.
- Services must comply with the EOSC architecture and interoperability guidelines.
- EOSC follows the principles of ethical behaviour and integrity in research.
- EOSC users are also expected to contribute to EOSC.
- Users must comply with the terms and conditions associated with the data they use.
- EOSC users always cite the sources of the resources they use in their work.
- Participation in EOSC is subject to applicable policies and legislation.
EOSC in Spain
The Consejo Superior de Investigaciones Científicas (CSIC) of Spain was one of the 4 founding members of the association and is currently a commissioned member of the association, in charge of coordination at national level.
CSIC has been working for years on its open access repository DIGITAL.CSIC as a step towards its future integration into EOSC. Within its work in open science we can highlight for example the adoption of the Current Research Information System (CRIS), information systems designed to help research institutions to collect, organise and manage data on their research activity: researchers, projects, publications, patents, collaborations, funding, etc.
CRIS are already important tools in helping institutions track and manage their scientific output, promoting transparency and open access to research. But they can also play an important role as sources of information feeding into the EOSC, as data collected in CRIS can also be easily shared and used through the EOSC.
The road to open science
Collaboration between CRIS and ESCO has the potential to significantly improve the accessibility and re-use of research data, but there are also other transitional actions that can be taken on the road to producing increasingly open science:
- Ensure the quality of metadata to facilitate open data exchange.
- Disseminate the FAIR principles among the research community.
- Promote and develop common standards to facilitate interoperability.
- Encourage the use of open repositories.
- Contribute by sharing resources with the rest of the community.
This will help to boost open science, increasing the efficiency, transparency and replicability of research.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Noticia
Under the Spanish Presidency of the Council of the European Union, the Government of Spain has led the Gaia-X Summit 2023, held in Alicante on November 9 and 10. The event aimed to review the latest advances of Gaia-X in promoting data sovereignty in Europe. As presented on datos.gob.es, Gaia-X is a European private sector initiative for the creation of a federated, open, interoperable, and reversible data infrastructure, fostering digital sovereignty and data availability.
The summit has also served as a space for the exchange of ideas among the leading voices in the European data spaces community, culminating in the presentation of a statement to boost strategic autonomy in cloud computing, data, and artificial intelligence—considered crucial for EU competitiveness. The document, promoted by the State Secretariat for Digitization and Artificial Intelligence, constitutes a joint call for a "more coherent and coordinated" response in the development of programs and projects, both at the European and member state levels, related to data and sector technologies.
To achieve this, the statement advocates for interoperability supported by a robust cloud services infrastructure and the development of high-quality data-based artificial intelligence with a robust governance framework in compliance with European regulatory frameworks. Specifically, it highlights the possibilities offered by Deep Neural Networks, where success relies on three main factors: algorithms, computing capacity, and access to large amounts of data. In this regard, the document emphasizes the need to invest in the latter factor, promoting a neural network paradigm based on high-quality, well-parameterized data in shared infrastructures, not only saving valuable time for researchers but also mitigating environmental degradation by reducing computing needs beyond the brute force paradigm.
For this reason, another aspect addressed in the document is the stimulation of access to data sources from different complementary domains. This would enable a "flexible, dynamic, and highly scalable" data economy to optimize processes, innovate, and/or create new business models.
The call is optimistic about existing European initiatives and programs, starting with the Gaia-X project itself. Other projects highlighted include IPCEI-CIS or the Simpl European project. It also emphasizes the need for "broader and more effective coordination to drive industrial projects, advance the standardization of cloud and reliable data tags, ensuring high levels of cybersecurity, data protection, algorithmic transparency, and portability."
The statement underscores the importance of achieving a single data market that includes data exchange processes under a common governance framework. It values the innovative set of digital and data legislation, such as the Data Act, with the goal of promoting data availability across the Union. The statement is open to new members seeking to advance the promotion of a flexible, dynamic, and highly scalable data economy.
You can read the full document here: The Trinity of Trusted Cloud Data and AI as a Gateway to EU's Competitiveness
Blog
On September 8, the webinar \"Geospatial Trends 2023: Opportunities for data.europa.eu\" was held, organized by the Data Europa Academy and focused on emerging trends in the geospatial field. Specifically, the online conference addressed the concept of GeoAI (Geospatial Artificial Intelligence), which involves the application of artificial intelligence (AI) combined with geospatial data.
Next, we will analyze the most cutting-edge technological developments of 2023 in this field, based on the knowledge provided by the experts participating in the aforementioned webinar.
What is GeoAI?
The term GeoAI, as defined by Kyoung-Sook Kim, co-chair of the GeoAI Working Group of the Open Geospatial Consortium (OGC), refers to \"a set of methods or automated entities that use geospatial data to perceive, construct (automate), and optimize spaces in which humans, as well as everything else, can safely and efficiently carry out their geographically referenced activities.\"
GeoAI allows us to create unprecedented opportunities, such as:
- Extracting geospatial data enriched with deep learning: Automating the extraction, classification, and detection of information from data such as images, videos, point clouds, and text.
- Conducting predictive analysis with machine learning: Facilitating the creation of more accurate prediction models, pattern detection, and automation of spatial algorithms.
- Improving the quality, uniformity, and accuracy of data: Streamlining manual data generation workflows through automation to enhance efficiency and reduce costs.
- Accelerating the time to gain situational knowledge: Assisting in responding more rapidly to environmental needs and making more proactive, data-driven decisions in real-time.
- Incorporating location intelligence into decision-making: Offering new possibilities in decision-making based on data from the current state of the area that needs governance or planning.
Although this technology gained prominence in 2023, it was already discussed in the 2022 geospatial trends report, where it was indicated that integrating artificial intelligence into spatial data represents a great opportunity in the world of open data and the geospatial sector.
Use Cases of GeoAI
During the Geospatial Trends 2023 conference, companies in the GIS sector, Con terra and 52ºNorth, shared practical examples highlighting the use of GeoAI in various geospatial applications.
Examples presented by Con terra included:
- KINoPro: A research project using GeoAI to predict the activity of the \"black arches\" moth and its impact on German forests.
- Anomaly detection in cell towers: Using a neural network to detect causes of anomalies in towers that can affect the location in emergency calls.
- Automated analysis of construction areas: Aiming to detect building areas for industrial zones using OpenData and satellite imagery.

On the other hand, 52ºNorth presented use cases such as MariData, which seeks to reduce emissions from maritime transport by using GeoAI to calculate optimal routes, considering ship position, environmental data, and maritime traffic regulations. They also presented KI:STE, which applies artificial intelligence technologies in environmental sciences for various projects, including classifying Sentinel-2 images into (un)protected areas.
These projects highlight the importance of GeoAI in various applications, from predicting environmental events to optimizing maritime transport routes. They all emphasize that this technology is a crucial tool for addressing complex problems in the geospatial community.
GeoAI not only represents a significant opportunity for the spatial sector but also tests the importance of having open data that adheres to FAIR principles (Findable, Accessible, Interoperable, Reusable). These principles are essential for GeoAI projects as they ensure transparent, efficient, and ethical access to information. By adhering to FAIR principles, datasets become more accessible to researchers and developers, fostering collaboration and continuous improvement of models. Additionally, transparency and the ability to reuse open data contribute to building trust in results obtained through GeoAI projects.
Reference
| Reference video | https://www.youtube.com/watch?v=YYiMQOQpk8A |
Blog
The active participation of young people in civic and political life is one of the keys to strengthening democracy in Europe. Analyzing and understanding the voice of young people provides insight into their attitudes and opinions, something that helps to foresee future trends in society with sufficient room for maneuver to address their needs and concerns towards a more prosperous and comfortable future for all.
In the mission to gain a clearer perspective on how they participate in Europe, open data has become a valuable tool. In this post, we will explore how young people in Europe actively engage in society and politics through relevant European Union (EU) open data published on the European open data portal.
Youth commitment in the European elections
The European Union has as one of its objectives to promote the active participation of young people in democracy and society. Their participation in elections and civic activities enriches European democracy. Young people bring diverse ideas and perspectives, which contributes to decision-making and ensures that policies are tailored to their needs and challenges. In addition, their participation contributes to a political system that reflects the interests of all citizens, which in turn fosters an inclusive and peaceful society.
In the last European Parliament elections, the highest turnout in the last 20 years was achieved, with more than 50% of the European population voting, as corroborated by the EU's Eurobarometer post-election survey. This increase in turnout was largely due to an increase in youth participation.
The data show that the younger generation (under 25) increased their electoral participation by 14% to 42%, while the participation of 25-39 year olds increased by 12% to 47%, compared between the 2014 and 2019 European elections. This growth in youth participation raises a question: what motivated young people to participate more? According to the 2021 Eurobarometer Youth Survey, a sense of duty as a citizen (32%) and a willingness to take responsibility for the future (32%) were the main factors motivating young people to vote in the European elections.

Why do young people want to participate in the EU?
In addition to voting in elections, there are other ways in which young people demonstrate that they are an active part of citizenship. The Youth Survey 2021 reveals interesting data about their interest in politics and civic life.
In general, politics is a topic that interests them. The majority of participants in the Youth Survey 2021 claimed to discuss politics with friends or family (85%). In addition, many said they understand how their country's national government works (58%). However, most young people feel they have little influence on important decisions, laws, and policies that affect them. Young people feel they have more say in their local government (47%), than in the national government (40%) or at the EU level (30%).
The next step, after understanding the policy, is action. Young people believe that certain political and civic activities are more effective than others in getting their voice to decision-makers. In order, voting in elections (41%), participating in protests or street demonstrations (33%) and participating in petitions (30%) were considered the three most effective activities by respondents. Many young people had voted in their last local, national or European elections (46%) and had created or signed a petition (42%).
However, the survey reveals an interesting divergence between young people's perceptions and their actions. On some occasions, youth get involved in activities even though they are not what they consider to be the most effective, as in the case of online signature petitions. On the other hand, they do not always participate in activities that they perceive to be effective, such as street protests or contact with politicians.

The youth impulse for European democracy
Young people want the issues they see as priorities to be on the political agenda of the next European elections. A more recent special Eurobarometer on democracy in action in 2023 revealed that young people aged 15-24 are the age group most satisfied with the functioning of democracy in the EU (61%, compared to the EU average of 54%).
Climate change is a particularly prominent concern among young people, with 40% of respondents aged 15-24 considering this issue a priority, compared to 31% of the general EU population.
To encourage youth participation in the European political agenda, initiatives have been developed that use open data to bring politics closer to citizens. Examples such as TrackmyEU and Democracy Game seek to engage young people in politics and enable them to access information on EU policies and participate in debates and civic activities.
In general, open data provides valuable insights into many realities, for example, that affecting youth and their interaction in society and politics. This analysis enables governments and public administrations to make informed decisions on issues affecting this social group. Young Europeans are interested in politics, actively participate in elections and get involved in youth organizations; they are concerned about issues such as inequality and climate change. Open data is also used in initiatives that promote the participation of young people in political and civic life, further strengthening European democracy.
In an increasingly digital and data-driven society, access to open data is essential to understand the concerns and interests of youth and their participation in civic and political decision-making. As a part of an active and engaged citizenry, youth have an important role to play in Europe's future, and open data is an essential tool to support their participation.
Content based on the post from the European open data portal Understanding youth engagement in Europe through open data.
Blog
IATE, which stands for Interactive Terminology for Europe, is a dynamic database designed to support the multilingual drafting of European Union texts. It aims to provide relevant, reliable and easily accessible data with a distinctive added value compared to other sources of lexical information such as electronic archives, translation memories or the Internet.
This tool is of interest to EU institutions that have been using it since 2004 and to anyone, such as language professionals or academics, public administrations, companies or the general public. This project, launched in 1999 by the Translation Center, is available to any organization or individual who needs to draft, translate or interpret a text on the EU.
Origin and usability of the platform
IATE was created in 2004 by merging different EU terminology databases.The original Eurodicautom, TIS, Euterpe, Euroterms and CDCTERM databases were imported into IATE. This process resulted in a large number of duplicate entries, with the consequence that many concepts are covered by several entries instead of just one. To solve this problem, a cleaning working group was formed and since 2015 has been responsible for organizing analyses and data cleaning initiatives to consolidate duplicate entries into a single entry. This explains why statistics on the number of entries and terms show a downward trend, as more content is deleted and updated than is created.
In addition to being able to perform queries, there is the possibility to download your datasets together with the IATExtract extraction tool that allows you to generate filtered exports.
This inter-institutional terminology base was initially designed to manage and standardize the terminology of EU agencies. Subsequently, however, it also began to be used as a support tool in the multilingual drafting of EU texts, and has now become a complex and dynamic terminology management system. Although its main purpose is to facilitate the work of translators working for the EU, it is also of great use to the general public.
IATE has been available to the public since 2007 and brings together the terminology resources of all EU translation services. The Translation Center manages the technical aspects of the project on behalf of the partners involved: European Parliament (EP), Council of the European Union (Consilium), European Commission (COM), Court of Justice (CJEU), European Central Bank (ECB), European Court of Auditors (ECA), European Economic and Social Committee (EESC/CoR), European Committee of the Regions (EESC/CoR), European Investment Bank (EIB) and the Translation Centre for the Bodies of the European Union (CoT).
The IATE data structure is based on a concept-oriented approach, which means that each entry corresponds to a concept (terms are grouped by their meaning), and each concept should ideally be covered by a single entry. Each IATE entry is divided into three levels:
-
Language Independent Level (LIL)
-
Language Level (LL)
-
Term Level (TL) For more information, see Section 3 ('Structure Overview') below.
Reference source for professionals and useful for the general public
IATE reflects the needs of translators in the European Union, so that any field that has appeared or may appear in the texts of the publications of the EU environment, its agencies and bodies can be covered. The financial crisis, the environment, fisheries and migration are areas that have been worked on intensively in recent years. To achieve the best result, IATE uses the EuroVoc thesaurus as a classification system for thematic fields.
As we have already pointed out, this database can be used by anyone who is looking for the right term about the European Union. IATE allows exploration in fields other than that of the term consulted and filtering of the domains in all EuroVoc fields and descriptors. The technologies used mean that the results obtained are highly accurate and are displayed as an enriched list that also includes a clear distinction between exact and fuzzy matches of the term.
The public version of IATE includes the official languages of the European Union, as defined in Regulation No. 1 of 1958. In addition, a systematic feed is carried out through proactive projects: if it is known that a certain topic is to be covered in EU texts, files relating to this topic are created or improved so that, when the texts arrive, the translators already have the required terminology in IATE.
How to use IATE
To search in IATE, simply type in a keyword or part of a collection name. You can define further filters for your search, such as institution, type or date of creation. Once the search has been performed, a collection and at least one display language are selected.
To download subsets of IATE data you need to be registered, a completely free option that allows you to store some user preferences in addition to downloading. Downloading is also a simple process and can be done in csv or tbx format.
The IATE download file, whose information can also be accessed in other ways, contains the following fields:
-
Language independent level:
-
Token number: the unique identifier of each concept.
-
Subject field: the concepts are linked to fields of knowledge in which they are used. The conceptual structure is organized around twenty-one thematic fields with various subfields. It should be noted that concepts can be linked to more than one thematic field.
-
Language level:
-
Language code: each language has its own ISO code.
-
Term level
-
Term: concept of the token.
-
Type of term. They can be: terms, abbreviation, phrase, formula or short formula.
-
Reliability code. IATE uses four codes to indicate the reliability of terms: untested, minimal, reliable or very reliable.
-
Evaluation. When several terms are stored in a language, specific evaluations can be assigned as follows: preferable, admissible, discarded, obsolete and proposed.
A continuously updated terminology database
The IATE database is a document in constant growth, open to public participation, so that anyone can contribute to its growth by proposing new terminologies to be added to existing files, or to create new files: you can send your proposal to iate@cdt.europa.eu, or use the 'Comments' link that appears at the bottom right of the file of the term you are looking for. You can provide as much relevant information as you wish to justify the reliability of the proposed term, or suggest a new term for inclusion. A terminologist of the language in question will study each citizen's proposal and evaluate its inclusion in the IATE.
In August 2023, IATE announced the availability of version 2.30.0 of this data system, adding new fields to its platform and improving functions, such as the export of enriched files to optimize data filtering. As we have seen, this EU inter-institutional terminology database will continue to evolve continuously to meet the needs of EU translators and IATE users in general.
Another important aspect is that this database is used for the development of computer-assisted translation (CAT) tools, which helps to ensure the quality of the translation work of the EU translation services. The results of translators' terminology work are stored in IATE and translators, in turn, use this database for interactive searches and to feed domain- or document-specific terminology databases for use in their CAT tools.
IATE, with more than 7 million terms in over 700,000 entries, is a reference in the field of terminology and is considered the largest multilingual terminology database in the world. More than 55 million queries are made to IATE each year from more than 200 countries, which is a testament to its usefulness.