Blog
IATE, acrónimo en inglés de Interactive Terminology for Europe (Terminología Interactiva para Europa), es una base de datos dinámica diseñada para respaldar la redacción multilingüe de textos de la Unión Europea. Su objetivo es proporcionar datos relevantes, confiables y de fácil acceso con un valor añadido distintivo en comparación con otras fuentes de información léxica como pueden ser archivos electrónicos, memorias de traducción o internet.
Esta herramienta es de interés para las instituciones de la UE que la utilizan desde 2004 y para cualquier persona, como profesionales de la lengua o del mundo académico, administraciones públicas, empresas o público en general Este proyecto, puesto en marcha en 1999 por el Centro de Traducción, está disponible para cualquier organización o persona que necesite redactar, traducir o interpretar un texto sobre la UE.
Origen y usabilidad de la plataforma
IATE se creó en 2004 mediante la fusión de diferentes bases de datos terminológicas de la UE. Para su creación se importaron a IATE las bases de datos originales de Eurodicautom, TIS, Euterpe, Euroterms y CDCTERM. Este proceso originó una gran cantidad de entradas duplicadas, lo que tiene como consecuencia que muchos conceptos estén cubiertos por varias entradas en lugar de una sola. Para solucionar este problema, se constituyó un grupo de trabajo de limpieza que desde 2015 se encarga de organizar análisis e iniciativas de limpieza de datos para consolidar entradas duplicadas en una sola entrada. Esto explica por qué las estadísticas sobre el número de entradas y términos muestran una tendencia a la baja, ya que se eliminan y actualizan más contenidos de los que se crean.
Además de poder realizar consultas, existe la posibilidad de descargar sus ficheros de datos junto con la herramienta de extracción IATExtract que permite generar exportaciones filtradas.
Esta base terminológica interinstitucional fue inicialmente diseñada para gestionar y normalizar la terminología de las agencias de la UE. No obstante, posteriormente, también se empezó a utilizar como herramienta de apoyo en la redacción multilingüe de los textos de la UE, hasta llegar a convertirse en la actualidad en un sistema complejo y dinámico de gestión terminológica. Aunque su principal objetivo es facilitar la labor de los traductores que trabajan para la UE, también es de gran utilidadl para el público en general. .
IATE lleva a disposición del público desde 2007, y reúne los recursos terminológicos de todos los servicios de traducción de la UE. El Centro de Traducción gestiona los aspectos técnicos del proyecto en nombre de los socios que participan en él: el Parlamento Europeo (EP), el Consejo de la Unión Europea (Consilium), la Comisión Europea (COM), el Tribunal de Justicia (CJUE), el Banco Central Europeo (ECB), el Tribunal de Cuentas Europeo (ECA), el Comité Económico y Social Europeo (EESC/CoR), el Comité Europeo de las Regiones (EESC/CoR), el Banco Europeo de Inversiones (EIB) y el Centro de Traducción de los Órganos de la Unión Europea (CdT).
La estructura de datos de IATE se basa en un enfoque orientado a conceptos, lo que significa que cada entrada corresponde a un concepto (los términos se agrupan por su significado), y cada concepto idealmente debería estar cubierto por una sola entrada. Cada entrada de IATE se divide en tres niveles:
-
Nivel independiente del idioma (LIL)
-
Nivel de idioma (LL)
-
Nivel de término (TL) Para obtener más información, consulte la Sección 3 ('Visión general de la estructura') a continuación.
Fuente de referencia para profesionales y útil para el público en general
En IATE se reflejan las necesidades de los traductores de la Unión Europea, por lo que puede cubrirse cualquier ámbito que haya aparecido o pueda aparecer en los textos de las publicaciones del entorno de la UE, sus agencias y organismos. La crisis financiera, el medio ambiente, la pesca y la migración son ámbitos en los que se ha trabajado de forma intensa durante los últimos años. Para conseguir el mejor resultado, IATE utiliza el tesauro EuroVoc como sistema de clasificación de campos temáticos.
Como ya hemos señalado, esta base de datos puede ser utilizada por cualquier persona que esté buscando el término adecuado sobre la Unión Europea. IATE permite explorar en campos diferentes al del término consultado y filtrar los dominios en todos los ámbitos y descriptores de EuroVoc. Las tecnologías utilizadas hacen que los resultados obtenidos tengan una gran precisión, mostrándose como una lista enriquecida que incluye además una clara distinción entre las coincidencias exactas y difusas del término.
La versión pública de IATE incluye las lenguas oficiales de la Unión Europea, que se definen en el Reglamento n.º 1 de 1958. . Además, se efectúa una alimentación sistemática a través de proyectos anticipativos: si se sabe que va a tratarse en textos de la UE un tema determinado, se crean o mejoran las fichas que guardan relación con ese tema para que, cuando lleguen los textos, los traductores dispongan ya en IATE de la terminología precisada.
Cómo utilizar IATE
Para realizar una búsqueda en IATE simplemente se debe escribir una palabra clave o parte del nombre de una colección. Se pueden definir más filtros para su búsqueda, como institución, tipo o fecha de creación. Una vez que se ha realizado la búsqueda, se selecciona una colección y al menos una lengua de visualización.
Para descargar subconjuntos de datos de IATE es necesario estar registrado, una opción totalmente gratuita que permite además de la descarga, almacenar algunas preferencias de usuario. La descarga es también un proceso sencillo y se puede realizar en formato csv o tbx.
El archivo de descarga de IATE, a cuya información se puede también acceder de otras formas, contiene los siguientes campos:
-
Nivel independiente de la lengua:
-
Número de ficha: el identificador único de cada concepto.
-
Campo temático: los conceptos están vinculados a ámbitos de conocimiento en los que se utilizan. La estructura conceptual se organiza en torno a veintiún campos temáticos con diversos subcampos. Hay que señalar que los conceptos pueden estar vinculados a más de un campo temático.
-
Nivel de la lengua:
-
Código de la lengua: cada idioma tiene su propio código ISO.
-
Nivel del término
-
Término: concepto de la ficha.
-
Tipo de término. Pueden ser: términos, abreviatura, frase, fórmula o fórmula corta.
-
Código de fiabilidad. IATE utiliza cuatro códigos para indicar la fiabilidad de los términos: sin comprobar, mínima, fiable o muy fiable.
-
Evaluación. Cuando se almacenan varios términos en una lengua, se pueden asignar evaluaciones específicas del siguiente modo: preferible, admisible, desechado, obsoleto y propuesto.
Una base de datos terminológica en continua actualización
La base de datos IATE es un documento en permanente crecimiento, abierto a la participación ciudadana, de forma que cualquier persona puede contribuir a su crecimiento proponiendo nuevas terminologías para añadir a fichas existentes, o para crear fichas nuevas: puede enviar su propuesta a iate@cdt.europa.eu, o bien utilizar el enlace ‘Observaciones’ que aparece en la parte inferior derecha de la ficha del término buscado. Se puede facilitar cuanta información pertinente se desee para justificar la fiabilidad del término propuesto, o plantear un nuevo término a incluir. Un terminólogo de la lengua en cuestión estudiará cada propuesta ciudadana y valorará su incorporación al IATE.
En agosto de 2023, la IATE anunciaba la disponibilidad de la versión 2.30.0 de este sistema de datos, añadiendo nuevos campos en su plataforma y la mejora de funciones, como la exportación de archivos enriquecidos para optimizar el filtrado de datos. Como hemos visto, esta base de datos terminológica interinstitucional de la UE seguirá evolucionando de manera continua para satisfacer las necesidades de los traductores de la UE y los usuarios de IATE en general.
Otro aspecto importante es que esta base de datos sirve para el desarrollo de herramientas de traducción asistida por ordenador (TAO), lo que contribuye a garantizar la calidad de los trabajos de traducción de los servicios de traducción de la UE. Los resultados de la labor de terminología de los traductores se almacenan en IATE y éstos, a su vez, utilizan esta base de datos para realizar búsquedas interactivas y para alimentar bases de datos terminológicas específicas para un ámbito o documento que utilizan en sus herramientas TAO.
IATE, con más de 7 millones de términos en más de 700.000 entradas, es una referencia en el ámbito de la terminología y está considerada como la mayor base de datos terminológica multilingüe del mundo. Cada año se realizan en IATE más de 55 millones de consultas desde más de 200 países, lo que da buena cuenta de su utilidad.
Blog
Detrás de un asistente virtual de voz, la recomendación de una película en una plataforma de streaming o el desarrollo de algunas vacunas contra el covid-19 existen modelos de machine learning. Esta rama de la inteligencia artificial permite que los sistemas aprendan y mejoren su funcionamiento.
El machine learning (ML) o aprendizaje automático es uno de los campos que impulsa el avance tecnológico del presente y sus aplicaciones crecen cada día. Como ejemplos de soluciones desarrolladas con machine learning podemos mencionar DALL-E, el conjunto de modelos del lenguaje en español MarIA o incluso Chat GPT-3, herramienta de IA generativa que es capaz de crear contenido de todo tipo, como, por ejemplo, código para programar visualizaciones con datos del catálogo datos.gob.es.
Todas estas soluciones funcionan gracias a grandes repositorios de datos que hacen posible el aprendizaje de los sistemas. Entre estos, los datos abiertos juegan un papel fundamental para el desarrollo de la inteligencia artificial ya que pueden servir de entrenamiento para los modelos de aprendizaje automático.
Bajo esta premisa, sumado al esfuerzo permanente de las administraciones por la apertura de datos, existen organizaciones no gubernamentales y asociaciones que contribuyen desarrollando aplicaciones que usan técnicas de machine learning dirigidas a mejorar la vida de la ciudadanía. Destacamos tres de ellas:
ML Commons impulsa un sistema de aprendizaje automático mejor para todos
Esta iniciativa pretende mejorar el impacto positivo del aprendizaje automático en la sociedad y acelerar la innovación ofreciendo herramientas como conjuntos de datos, mejores prácticas y algoritmos abiertos. Entre sus miembros fundadores se encuentran empresas como Google, Microsoft, DELL, Intel AI, Facebook AI, entre otras.
Según ML Commons, en torno al 80% de las investigaciones realizadas en el ámbito del machine learning se basan en datos abiertos. Por lo tanto, los datos abiertos son vitales para acelerar la innovación en esta materia. Sin embargo, hoy en día, “la mayoría de los ficheros de datos públicos disponibles son pequeños, estáticos, tienen restricciones legales y no son redistribuibles”, tal y como asegura David Kanter, director de ML Commons.
En esta línea, las tecnologías innovadoras de ML necesitan grandes conjuntos de datos con licencias que permitan su reutilización, que puedan ser redistribuibles y que estén en continua mejora. Por ello, la misión de ML Commons es contribuir a mitigar esa brecha y para así impulsar la innovación en machine learning.
El principal objetivo de esta organización es crear una comunidad de datos abiertos para el desarrollo de aplicaciones machine learning. Su estrategia se basa en tres pilares:
En primer lugar, crear y mantener conjuntos de datos abiertos completos. Entre otros: The People’s Speech, con más de 30.000 horas de discurso en inglés para entrenar modelos de procesamiento del lenguaje natural (PLN), Multilingual Spoken Words, con más de 23 millones de expresiones en 50 idiomas diferentes o Dollar Street, con más de 38.000 imágenes de hogares de todo el mundo en situaciones socioeconómicas variadas. El segundo pilar consiste en impulsar buenas prácticas que faciliten la estandarización. Ejemplo de ello es el proyecto MLCube que propone estandarizar el proceso de contenedores para modelos ML para facilitar su uso compartido. Y, por último, realizar benchmarking en grupos de estudios para definir puntos de referencia para la comunidad desarrolladora e investigadora.
Aprovechar las ventajas y formar parte de la comunidad ML Commons es gratuito para las instituciones académicas y las empresas pequeñas (menos de diez trabajadores).
Datacommons sintetiza diferentes fuentes de datos abiertos en un único portal
Datacommons busca potenciar los flujos democráticos de datos dentro de la economía cooperativa y solidaria y tiene como objetivo principal ofrecer datos depurados, normalizados e interoperables.
La variedad de formato e información que ofrecen los portales públicos de datos abiertos puede llegar a ser un obstáculo para la investigación. El objetivo de Datacommons es compilar datos abiertos en una web enciclopédica que ordena todos los dataset mediante nodos. De esta manera, el usuario puede acceder a la fuente que más le interesa.
Esta plataforma, que fue diseñada con fines educativos y de investigación periodística, funciona como herramienta de referencia para navegar entre distintas fuentes de datos. El equipo de colaboradores trabaja para mantener la información actualizada e interactúa con la comunidad a través de su e-mail (support@datacommons.org) o foro de GitHub.
Papers with Code: el repositorio de materiales en abierto para alimentar modelos machine learning
Se trata de un portal que ofrece código, informes, datos, métodos y tablas de evaluación en formato abierto y gratuito. Todo el contenido de la web está bajo licencia CC-BY-SA, es decir, permite copiar, distribuir, exhibir y modificar la obra incluso con fines comerciales compartiendo las contribuciones realizadas con la misma licencia original.
Cualquier usuario puede contribuir aportando contenido e, incluso, participar en el canal de Slack de la comunidad que está moderado por responsables que protegen la política de inclusión definida por la plataforma.
A día de hoy, Papers with Code aloja 7806 conjuntos de datos que se pueden filtrar según formato (gráfico, texto, imagen, tabular etc.), tarea (detección de objeto, consultas, clasificación de imágenes etc.) o idioma. El equipo que mantiene Papers with Code pertenece al instituto de investigación de Meta.
El objetivo de ML Commons, Data Commons y Papers with Code es mantener y hacer crecer comunidades de datos abiertos que contribuyan al desarrollo de tecnologías innovadoras. Entre ellas, la inteligencia artificial (machine learning, deep learning etc.) con todas las posibilidades que su desarrollo puede llegar a ofrecer a la sociedad.
Como parte de este proceso, las tres organizaciones desarrollan un papel fundamental: ofrecen repositorios de datos en formato estándar y redistribuible para entrenar modelos machine learning. Son recursos útiles para realizar ejercicios académicos, impulsar la investigación y, al fin y al cabo, facilitar la innovación de tecnologías que cada día están más presentes en nuestra sociedad.
Empresa reutilizadora
KSNET (Knowledge Sharing Network S.L) es una empresa dedicada a la transferencia de conocimiento que tiene por objetivo mejorar los programas y las políticas con un impacto tanto social como económico. Por eso acompañan a sus clientes en todo el proceso de creación de estos programas, desde la fase de diagnóstico, diseño e implementación hasta la evaluación de los resultados e impacto conseguido, aportando también una visión de futuro a partir de propuestas de mejora.
Blog
Las librerías de programación hacen referencia a los conjuntos de archivos de código que han sido creados para desarrollar software de manera sencilla. Gracias a ellas, los desarrolladores pueden evitar la duplicidad de código y minimizar errores con mayor agilidad y menor coste. Existen multitud de librerías, enfocadas en distintas actividades. Hace unas semanas vimos algunos ejemplos de librerías para la creación de visualizaciones, y en esta ocasión nos vamos a centrar en librerías de utilidad para tareas de aprendizaje automático (Machine Learning).
Estas librerías son altamente prácticas a la hora de implementar flujos de Machine Learning. Esta disciplina, perteneciente al campo de la Inteligencia Artificial, utiliza algoritmos que ofrecen, por ejemplo, la capacidad de identificar patrones de datos masivos o la capacidad de ayudar a elaborar análisis predictivos.
A continuación, te mostramos algunas de las librerías de análisis de datos y Machine Learning más populares que existen en la actualidad para los principales lenguajes de programación, como Python o R:
Librerías para Python
NumPy
- Descripción:
Esta librería de Python está especializada en el cálculo matemático y en el análisis de grandes volúmenes de datos. Permite trabajar con arrays que permiten representar colecciones de datos de un mismo tipo en varias dimensiones, además de funciones muy eficientes para su manipulación.
- Materiales de apoyo:
Aquí encontramos la Guía para principiantes, con conceptos básicos y tutoriales, la Guía del usuario, con información sobre las características generales, o la Guía del colaborador, para contribuir al mantenimiento y desarrollo del código o en la redacción de documentación técnica. NumPy también cuenta con una Guía de referencia que detalla funciones, módulos y objetos incluidos en esta librería, así como una serie de tutoriales para aprender a utilizarla de forma sencilla.
Pandas
- Descripción:
Se trata de una de las librerías más utilizadas para el tratamiento de datos en Python. Esta herramienta de análisis y manipulación de datos se caracteriza, entre otros aspectos, por definir nuevas funcionalidades de datos basadas en los arrays de la librería NumPy. Permite leer y escribir fácilmente ficheros en formato CSV, Excel y especificar consultas a bases de datos SQL.
- Materiales de apoyo:
Su web cuenta con diferentes documentos como la Guía del usuario, con información básica detallada y explicaciones útiles, la Guía del desarrollador, que detalla los pasos a seguir ante la identificación de errores o sugerencia de mejoras en las funcionalidades, así como la Guía de referencia, con descripción detallada de su API. Además, ofrece una serie de tutoriales aportados por la comunidad y referencias sobre operaciones equivalentes en otros softwares y lenguajes como SAS, SQL o R.
Scikit-learn
- Descripción:
Scikit-Learn es una librería que implementa una gran cantidad de algoritmos de Machine Learning para tareas de clasificación, regresión, clustering y reducción de dimensionalidad. Además, es compatible con otras librerías de Python como NumPy, SciPy y Matplotlib (Matpotlib es una librería de visualización de datos y como tal está incluida en el artículo anterior).
- Materiales de apoyo:
Esta librería cuenta con diferentes documentos de ayuda como un Manual de instalación, una Guía del Usuario o un Glosario de términos comunes y elementos de su API. Además, ofrece una sección con diferentes ejemplos que ilustran las características de la librería, así como otras secciones de interés con tutoriales, preguntas frecuentes o acceso a su GitHub.
Scipy
- Descripción:
Esta librería presenta una colección de algoritmos matemáticos y funciones construidas sobre la extensión de NumPy. Incluye módulos de extensión para Python sobre estadística, optimización, integración, álgebra lineal o procesamiento de imágenes, entre otros.
- Materiales de apoyo:
Al igual que los ejemplos anteriores, esta librería también cuenta con materiales como Guías de instalación, Guías para usuarios, para desarrolladores o un documento con descripciones detalladas sobre su API. Además, ofrece información sobre act, una herramienta para ejecutar acciones de GitHub de forma local.
Librerías para R
mlr
- Descripción:
Esta librería ofrece componentes fundamentales para desarrollar tareas de aprendizaje automático, entre otros, preprocesamiento, pipelining, selección de características, visualización e implementación de técnicas supervisadas y no supervisadas utilizando un amplio abanico de algoritmos.
- Materiales de apoyo:
En su web cuenta con múltiples recursos para usuarios y desarrolladores, entre los que destaca un tutorial de referencia que presenta un extenso recorrido que abarca los aspectos básicos sobre tareas, predicciones o preprocesamiento de datos hasta la implementación de proyectos complejos utilizando funciones avanzadas.
Además, cuenta con un apartado que redirige a GitHub en el que ofrece charlas, vídeos y talleres de interés sobre el funcionamiento y los usos de esta librería.
Tidyverse
- Descripción:
Esta librería ofrece una colección de paquetes de R diseñados para la ciencia de datos que aporta funcionalidades muy útiles para importar, transformar, visualizar, modelar y comunicar información a partir de datos. Todos ellos comparten una misma filosofía de diseño, gramática y estructuras de datos subyacentes. Los principales paquetes que lo componen son: dplyr, ggplot2, forcats, tibble, readr, stringr, tidyr y purrr.
- Materiales de apoyo:
Tidyverse cuenta con un blog en el que podrás encontrar posts sobre programación, paquetes o trucos y técnicas para trabajar con esta librería. Además, cuenta con una sección que recomienda libros y workshops para aprender a utilizar esta librería de una manera más sencilla y amena.
Caret
- Descripción:
Esta popular librería contiene una interfaz que unifica bajo un único marco de trabajo cientos de funciones para entrenar clasificadores y regresores, facilitando en gran medida todas las etapas de preprocesado, entrenamiento, optimización y validación de modelos predictivos.
- Materiales de apoyo:
La web del proyecto contine exhaustiva información que facilita al usuario abordar tareas mencionadas. También se puede encontrar referencias en CRAN y el proyecto está alojado en GitHub. Algunos recursos de interés para el manejo de esta librería se pueden encontrar a través de libros como Applied Predictive Modeling, artículos, seminarios o tutoriales, entre otros.
Librerías para abordar tareas de Big Data
TensorFlow
- Descripción:
Además de Python y R, esta librería también es compatible con otros lenguajes como JavaScript, C++ o Julia. TensorFlow ofrece la posibilidad de compilar y entrenar modelos de ML utilizando APIs. La API más destacada es Keras, que permite construir y entrenar modelos de aprendizaje profundo (Deep Learning).
- Materiales de apoyo:
En su web se pueden encontrar recursos como modelos y conjuntos de datos previamente establecidos y desarrollados, herramientas, bibliotecas y extensiones, programas de certificación, conocimientos sobre aprendizaje automático o recursos y herramientas para integrar las prácticas de IA responsable. Puedes acceder a su página de GitHub aquí.
Dmlc XGBoost
- Descripción:
Librería de "Gradient Boosting" (GBM, GBRT, GBDT) escalable, portátil y distribuida es compatible con los lenguajes de programación C++, Python, R, Java, Scala, Perl y Julia. Esta librería permite resolver muchos problemas de ciencia de datos de una manera rápida y precisa y se puede integrar con Flink, Spark y otros sistemas de flujo de datos en la nube para abordar tareas Big Data.
- Materiales de apoyo:
En su web cuenta con un blog con temáticas relacionadas como actualizaciones de algoritmos o integraciones, además de una sección de documentación que cuenta con guías de instalación, tutoriales, preguntas frecuentes, foro de usuarios o paquetes para los distintos lenguajes de programación. Puedes acceder a su página de GitHub a través de este enlace.
H20
- Descripción:
Esta librería combina los principales algoritmos de Machine Learning y aprendizaje estadístico con Big Data, además de ser capaz de trabajar con millones de registros. H20 está escrita en Java, y sigue el paradigma Key/Value para almacenar datos y Map/Reduce para implementar algoritmos. Gracias a su API, se puede acceder desde R, Python o Scala.
- Materiales de apoyo:
Cuenta con una serie de vídeos en forma de tutorial para enseñar y facilitar su uso a los usuarios. En su página de GitHub podrás encontrar recursos adicionales como blogs, proyectos, recursos, trabajos de investigación, cursos o libros sobre H20.
En este artículo hemos ofrecido una muestra de algunas de las librerías más populares que ofrecen funcionalidades versátiles para abordar tareas típicas de ciencia de datos y aprendizaje automático, aunque hay muchas otras. Este tipo de librerías está en constante evolución gracias a la posibilidad que ofrece a sus usuarios de participar en su mejora a través de acciones como la contribución a la escritura de código, la generación de nueva documentación o el reporte de errores. Todo ello permite enriquecer y perfeccionar sus resultados continuamente.
Si sabes de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Entrevista
La asociación AMETIC representa a empresas de todos los tamaños ligadas con la industria tecnológica digital española, un sector clave para el PIB nacional. Entre otras cuestiones, AMETIC busca impulsar un entorno favorable para el crecimiento de las empresas del sector, potenciando el talento digital y la creación y consolidación de nuevas empresas.
En datos.gob.es hemos hablado con Antonio Cimorra, Director de Transformación Digital y Tecnologías Habilitadoras de AMETIC, para reflexionar sobre el papel de los datos abiertos en la innovación y como base de nuevos productos, servicios e incluso modelos de negocio.
Entrevista completa:
1. ¿Cómo ayudan los datos abiertos a impulsar la transformación digital? ¿Qué tecnologías disruptivas son las más beneficiadas por la apertura de datos?
Los datos abiertos constituyen uno de los pilares de la economía del dato, que está llamada a ser la base de nuestro desarrollo presente y futuro y de la transformación digital de nuestra sociedad. Todas las industrias, administraciones publicas y la propia ciudadanía no hemos hecho más que comenzar a descubrir y utilizar el enorme potencial y utilidad que la utilización de los datos aporta a la mejora de la competitividad de las empresas, a la eficiencia y mejora de los servicios de las Administraciones Públicas y a las relaciones sociales y la calidad de vida de las personas.
2. Una de las áreas en las que trabajan desde AMETIC es la Inteligencia Artificial y el Big Data, entre cuyos objetivos está promover la creación de plataformas públicas de compartición de datos abiertos. ¿Podría explicarnos qué acciones llevan o han llevado a cabo para ello?
En AMETIC contamos con una Comisión de Inteligencia Artificial y Big Data en la que participan las principales empresas proveedoras de esta tecnología. Desde este ámbito, trabajamos en la definición de iniciativas y propuestas que contribuyen difundir su conocimiento entre los potenciales usuarios, con las consiguientes ventajas que supone su incorporación en los sectores público y privado. Son destacados ejemplos de las acciones en este ámbito la reciente presentación del Observatorio de Inteligencia Artificial de AMETIC, así como el AMETIC Artificial Intelligence Summit que en 2022 celebrará su quinta edición que pondrá foco en mostrar cómo la Inteligencia Artificial puede contribuir al cumplimiento de los Objetivos de Desarrollo Sostenible y a los Planes de Transformación a ejecutar con Fondos Europeos
3. Los datos abiertos pueden servir de base para desarrollar servicios y soluciones que den lugar a nuevas empresas. ¿Podría contarnos algún ejemplo de caso de uso llevado a cabo por sus asociados?
Los datos abiertos y muy particularmente la reutilización de la información del sector público son la base de desarrollo de un sinfín de aplicaciones e iniciativas emprendedoras tanto en empresas consolidadas de nuestro sector tecnológico como en otros muchos casos de pequeñas empresas o startups que encuentran en esta fuente de información el motor de desarrollo de nuevos negocios y acercamiento al mercado.
4. ¿Qué tipos de datos son los más demandados por las empresas a las que representan?
En la actualidad, todos los datos de actividad industrial y social cuentan con una importante demanda por las empresas, atendiendo a su gran valor en el desarrollo de proyectos y soluciones que vienen demostrando su interés y extensión en todos los ámbitos y tipología de organizaciones y usuarios en general.
5. También es fundamental contar con iniciativas de compartición de datos como GAIA-X, constituida sobre los valores de soberanía digital y disponibilidad de los datos. ¿Cómo han recibido las empresas la creación de un hub nacional?
El sector tecnológico ha recibido la creación del hub nacional de GAIA-X muy positivamente, entendiendo que nuestra aportación desde España a este proyecto europeo será de enorme valor para nuestras empresas de muy distintos ámbitos de actividad. Espacios de compartición de datos en sectores como el turismo, la sanidad, la movilidad, la industria, por poner algunos ejemplos, cuentan con empresas y experiencias españolas que son ejemplo y referencia a nivel europeo y mundial.
6. En este momento hay una gran demanda de profesionales relacionados con la captación, análisis y visualización de datos. Sin embargo, la oferta de profesionales, aunque va creciendo, continúa siendo limitada. ¿Qué habría que hacer para impulsar la capacitación en habilidades relacionadas con los datos y la digitalización?
La oferta de profesionales tecnológicos es uno de los mayores problemas para el desarrollo de nuestra industria local y para la transformación digital de la sociedad. Es una dificultad que podemos calificar como histórica, y que lejos de ir a menos, cada día es mayor en número de puestos y perfiles a cubrir. Es un problema a nivel mundial que evidencia que no existe una formula única o sencilla para solucionarlo, pero si podemos mencionar la importancia de que todos los agentes sociales y profesionales desarrollemos acciones conjuntas y en colaboración que permitan la capacitación digital de nuestra población desde edades tempranas y de ciclos y programas formativos y de grado especializados que se caractericen por su proximidad con lo que serán las carreras profesionales para lo que es necesario contar con la participación del sector empresarial
7. Durante los últimos años, has formado parte del jurado de las distintas ediciones del Desafío Aporta. ¿Cómo cree que contribuyen este tipo de acciones a impulsar negocios basados en datos?
El Desafío Aporta ha sido un ejemplo de apoyo y estímulo para la definición de muchos proyectos en torno a los datos abiertos y para el desarrollo de una industria propia que en estos últimos años ha venido creciendo de forma muy significativa con la puesta a disposición de datos de muy distintos colectivos, en muchos casos por parte de las Administraciones Públicas, y su posterior reutilización e incorporación a aplicaciones y soluciones de interés para muy distintos usuarios.
Los datos abiertos constituyen uno de los pilares de la economía del dato, que está llamada a ser la base de nuestro desarrollo presente y futuro y de la transformación digital de nuestra sociedad.
8. ¿Cuáles son las próximas acciones que van a llevar a cabo en AMETIC ligadas a la economía del dato?
Entre las acciones más destacadas de AMETIC en relación con la economía del dato cabría citar nuestra reciente incorporación al hub nacional de GAIA-X para el que hemos sido elegidos miembros de su junta directiva, y en donde representaremos e incorporaremos la visión y las aportaciones de la industria tecnológica digital en todos los espacios de datos que se constituyan, sirviendo de canal de participación de las empresas tecnológicas que desarrollan su actividad en nuestro país y que tienen que conformar la base de los proyectos y casos de uso que integrar en la red europea GAIA-X en colaboración con otros hubs nacionales.
Noticia
El verano ya está a la vuelta de la esquina y con él las merecidas vacaciones. Sin duda, esta época del año nos brinda tiempo para descansar, reencontrarnos con la familia y pasar ratos agradables con nuestros amigos.
Sin embargo, también resulta una magnífica oportunidad para aprovechar y mejorar nuestro conocimiento sobre datos y tecnología a través de los cursos que diferentes universidades ponen a nuestra disposición durante estas fechas. Ya seas estudiante o profesional en activo, este tipo de cursos pueden contribuir a aumentar tu formación, y ayudarte a adquirir ventajas competitivas dentro del mercado laboral.
A continuación, te mostramos varios ejemplos de cursos de verano de universidades españolas sobre estas temáticas. También hemos incluido alguna formación online, disponible todo el año, y que puede ser un excelente producto para aprender también en la época estival.
Cursos relacionados con los datos abiertos
Iniciamos nuestra recopilación con el curso de ‘Big & Open Data. Análisis y programación con R y Python’ impartido por la Universidad Complutense de Madrid. Se celebrará de manera presencial en la Fundación General UCM del 5 al 23 de julio, de lunes a viernes en horario de 9 a 14 horas. Este curso está dirigido a estudiantes universitarios, docentes, investigadores y profesionales que deseen ampliar y perfeccionar sus conocimientos sobre esta materia.
Análisis y visualización de datos
Si te interesa aprender el lenguaje R, la Universidad de Santiago de Compostela organiza dos cursos relacionados con esta materia, en el marco de su ‘Universidade de Verán’. El primero de ellos es ‘Introducción en sistemas de información geográfica y cartográfica con el Entorno R’, que se celebrará del 6 al 9 de julio en la Facultad de Geografía e Historia de Santiago de Compostela. Puedes consultar toda la información y el plan de estudios a través de este enlace.
El segundo es ‘Visualización y análisis de datos con R’, que tendrá lugar del 13 al 23 de julio en la Facultad de Matemáticas de la USC. En este caso, la universidad ofrece la posibilidad al alumnado de asistir en dos turnos (mañana y tarde). Como puedes comprobar en su programa, la estadística se erige como uno de los aspectos clave de esta formación.
Si tu campo son las ciencias sociales y quieres aprender a manejar los datos correctamente, el curso de la Universidad de Internacional de Andalucía (UNIA) ‘Técnicas de análisis de datos en Humanidades y Ciencias Sociales’ buscas aproximarse al uso de las nuevas técnicas estadísticas y espaciales en la investigación en estos campos. Se impartirá del 23 al 26 de agosto en modalidad presencial.
Big Data
El Big Data se coloca, cada día más, como uno de los elementos que más contribuyen al aceleramiento de la transformación digital. Si te interesa este campo, puedes optar por el curso ‘Big Data Geolocalizado: Herramientas para la captura, análisis y visualización’ que impartirá la Universidad Complutense de Madrid del 5 al 23 de julio en horario de 9 a 14 horas, de manera presencial en la Fundación General UCM.
Otra opción es el curso de ‘Big Data: fundamentos tecnológicos y aplicaciones prácticas’ organizado por la Universidad de Alicante que se celebrará del 19 al 23 de julio de manera online.
Inteligencia artificial
El Gobierno ha puesto en marcha recientemente el curso online ‘Elementos de IA’ en español con el objetivo de impulsar y perfeccionar la formación de la ciudadanía en inteligencia artificial. La Secretaría de Estado de Digitalización e Inteligencia Artificial será quien ponga en marcha este proyecto junto a la colaboración de la UNED, que se encargará de proporcionar el soporte técnico y académico de esta formación. Elementos de IA es un proyecto educativo masivo y abierto (MOOC) que tiene como objetivo acercar a los ciudadanos conocimientos y habilidades sobre Inteligencia Artificial y sus distintas aplicaciones. Puedes descubrir toda la información sobre este curso aquí. Y si quieres comenzar ya la formación, puedes inscribirte a través de este enlace. El curso es gratuito.
Otra formación interesante relacionada con este ámbito es el curso de ‘Introducción práctica a la inteligencia artificial y al deep learning’ que organiza la Universidad Internacional de Andalucía (UNIA). Se impartirá de manera presencial en la sede Antonio Machado de Baeza entre los días 17 y 20 de agosto de 2021. Entre sus objetivos, destaca el ofrecer a los alumnos una visión general de los modelos de procesamiento de datos basados en técnicas de inteligencia artificial y aprendizaje profundo, entre otros.
Estos son solo algunos ejemplos de cursos que actualmente tienen matrícula abierta, aunque hay muchos más ya que la oferta es amplia y variada. Además, hay que recordar que el inicio del verano aún no se ha producido y que en las próximas semanas podrían aparecer nuevos cursos relacionados con los datos. Si conoces alguno más que sea de interés, no dudes en dejarnos un comentario aquí debajo o escribirnos a contacto@datos.gob.es
Evento
La actual situación sanitaria ha cambiado la forma de celebrar los grandes eventos, pasando en su mayoría de ser presenciales a celebrarse de manera online. Sin embargo, poco a poco se va retomando la presencialidad, volviendo al formato offline e incluso combinando ambas experiencias.
En este artículo vamos a descubrir algunos eventos relacionados con el mundo de la tecnología y los datos, tanto privados como públicos, que se celebrarán en las próximas semanas y que no deberías perderte. ¡Acompáñanos a descubrirlos!
OpenExpo Virtual Experience 2021
8 al 10 de junio de 2021 – Online
OpenExpo Europe se han posicionado en los últimos años como una de las principales ventanas de divulgación en innovación tecnológica, transformación digital y open source en Europa. Su principal objetivo es difundir entre los profesionales del sector tecnológico las últimas tendencias, herramientas y servicios en innovación y tecnología, además de ayudarles a aumentar su red de contactos.
La iniciativa OpenExpo Virtual Experience surgió el pasado año, tras el éxito cosechado con la divulgación de contenidos en formato online sobre ciberseguridad, blockchain, IA, realidad Virtual, IoT o big data, entre otros temas.
En este evento, los asistentes podrán disfrutar de más de 50 actividades de la mano de profesionales expertos en tecnología e innovación: ponencias, casos de éxito, entrevistas, debates, talleres, sesiones de preguntas y respuestas, reuniones 1to1, etc. Algunas de las temáticas que se tratarán son el Govtech y la apuesta de la administración pública por la innovación, el software libre educativo o Gaia-X, uno de los grandes proyectos de la comisión europea en materia de datos.
Advanced Factories
8 al 10 de junio de 2021 – Barcelona
La Ciudad Condal será la encargada de acoger la cumbre anual Advanced Factories, en la que se reúnen las empresas más punteras de la industria 4.0. Algunos de los puntos centrales de este encuentro de talla mundial serán: automatización industrial, sensores, eficiencia energética, inteligencia artificial, blockchain, machine learning o big data.
Esta cumbre acogerá por cuarto año consecutivo el Industry 4.0 Congress bajo el lema “We are the future of automation”, que comenzará con una ponencia sobre el papel de los datos en la trasformación de este sector.
Mobile World Congress (MWC) 2021
28 junio al 01 de julio de 2021 – Barcelona
Este gran evento tecnológico fue suspendido en 2020, pero en 2021 resurge en una nueva cita con grandes garantías de seguridad sanitaria. Como novedad, este año el MWC contará con diversas actividades virtuales que complementarán la edición presencial del evento. “Connected Impact” es el lema elegido, que sitúa la pandemia del COVID-19 como el principal elemento de influencia en las tendencias tecnológicas de este año.
Como viene siendo habitual, participarán grandes profesionales del sector y ponentes destacados. Entre ellos se encuentra Carme Artigas, Secretaria de Estado de Digitalización e Inteligencia Artificial, que participará con una ponencia sobre los datos en la era de la inteligencia.
Al igual que otros años, como parte del MWC, se celebrará el evento interno para startups 4YFN (4 Years From Now). Su objetivo es apoyar el contacto entre nuevas empresas e inversores, facilitando el acceso a una red internacional de contactos y diferentes oportunidades comerciales. Entre las empresas participantes podemos encontrar muchas centradas en el mundo de los datos y su reutilización. Red.es selecciona empresas y startups españolas para que participen en los diferentes espacios de representación que se organizan.
South Summit
5 al 7 de octubre de 2021 – Online
De cara al otoño llegará South Summit, un escaparate a modo de concurso para dar más visibilidad a proyectos disruptivos que buscan conseguir nuevos clientes, financiación o asociaciones estratégicas. Contará con inversores y empresas líderes en innovación, tanto de España como del sur de Europa y Latinoamérica, sin importar la industria, el país de procedencia o la etapa de desarrollo del proyecto.
Este año la organización ha decidido declinar la celebración de forma presencial, por lo que las presentaciones de los proyectos se realizarán de manera virtual.
IoT Solutions World Congress
5 al 7 de octubre de 2021 – Barcelona
Este es, sin duda, uno de los eventos más destacado sobre IoT a nivel internacional. Debido a la creciente demanda del sector, se estima una participación de más de 8.000 visitantes, en un evento que congregará a expertos de la industria para analizar cómo el Internet de las Cosas está transformado la producción, el transporte, la logística, los servicios públicos o sectores como el sanitario y el energético.
Algunas de las ponencias que se presentarán son “Aprovechamiento de EdgeX Foundry como marco de datos abierto y de confianza para la supervisión de contadores inteligentes”, “Uso de móviles, IoT y análisis de datos para adoptar un enfoque localizado del problema mundial de los residuos” o “Ciudades, infraestructuras y obras más inteligentes con datos de series temporales”.
Semantic Web for E-Government
24 de octubre - online
Este evento online se focalizará en una revisión de la web semántica y su importancia a la hora de lograr la interoperabilidad e integración entre los distintos niveles organizativos de las administraciones públicas. En él se presentarán dos iniciativas actuales de gobierno electrónico y datos abiertos:
- El Portal Europeo de Datos, una plataforma para integrar y evaluar los datos enlazados del gobierno abierto de Europa. Se abordarán las múltiples aplicaciones de los estándares de la web semántica en el Portal Europeo de Datos, como DCAT, SKOS, SHACL y DQV. También se prestará especial atención a la medición y publicación de información de calidad.
- Ciudades Abiertas: buenas prácticas para la armonización de datos con las administraciones públicas locales. Se explicará cómo se está desarrollando un conjunto de vocabularios para apoyar un suministro homogéneo de datos abiertos en el marco de Ciudades Abiertas, un proyecto de colaboración con cuatro ciudades españolas (Zaragoza, A Coruña, Madrid y Santiago de Compostela).
Smart City Expo World Congress
16 al 18 de noviembre de 2021 – Barcelona
Desde hace ya varios años, Smart City Expo World Congress (SCEWC) se ha convertido en un encuentro de referencia que mezcla la innovación tecnológica con el campo de las Smart Cities. Reúne expertos, empresas y emprendedores con el objetivo crear sinergias e impulsar nuevos proyectos.
En este 2021 el congreso cumple su décimo aniversario y sus organizadores volverán a apostar por celebrar el evento de manera presencial, combinado con una plataforma digital que ofrecerá multitud de oportunidades a sus asistentes.
Este evento suele ser el marco elegido por Open Data Barcelona para mostrar los trabajos finalistas de su World Data Viz Challenge, aunque la edición de 2021 todavía no ha sido anunciada.
EU Open Data Days
23 al 25 de noviembre 2021 - Online
Este año también asistiremos a la primera edición de las Jornadas de Datos Abiertos de la Unión Europea, organizadas por la Oficina de Publicaciones de la Unión Europea y que cuentan con la colaboración de la Iniciativa Aporta. El evento será virtual y estará dividido en dos actividades:
- EU Dataviz 2021 (23-24 de noviembre). Un programa de conferencias centradas en datos abiertos y visualizaciones. Actualmente están definiendo la agenda que compartiremos con vosotros próximamente.
- EU Datathon 2021 (25 de noviembre). Durante los meses previos, se desarrollará una competición que busca impulsar la creación de productos basado en datos abiertos, como aplicaciones móviles o web, que ofrezcan una respuesta a diferentes desafíos relacionados con las prioridades de la UE. El plazo para presentar propuestas acaba el 11 de junio. El 25 de noviembre se celebrará la final en el marco de estas jornadas.
Esta es tan solo una selección de los principales eventos tecnológicos que están por llegar. ¿Conoces alguno más que te gustaría destacar? Entonces no dudes en escribirnos un comentario o hacernos llegar tu propuesta a través de nuestro correo electrónico contacto@datos.gob.es
Blog
El impulso de la digitalización en la actividad industrial constituye uno de los ejes principales para abordar la transformación que pretende impulsar la Agenda España Digital 2025. A este respecto, son varias las iniciativas que ya se han puesto en marcha desde las instituciones públicas, entre las que destacan el programa Industria Conectada 4.0, a través del cual se pretende fomentar un marco de actuación conjunta y coordinada del sector público y privado en este ámbito.
Al margen de los debates acerca de lo que supone la Industria 4.0 y los desafíos que plantea, entre los principales requerimientos que se han identificado para evaluar la madurez y viabilidad de este tipo de proyectos se encuentra el relativo a la existencia de “una estrategia de recopilación, análisis y uso de datos relevantes, fomentando la implantación de tecnologías que lo faciliten, orientada a la toma de decisiones y a la satisfacción del cliente”, así como el uso de tecnologías que “permitan obtener modelos predictivos y prescriptivos, por ejemplo, Big Data e Inteligencia Artificial”. Precisamente, la Estrategia Española de I+D+I Artificial otorga una singular relevancia al uso masivo de datos que, en definitiva, precisa de su disponibilidad en condiciones adecuadas, tanto desde una perspectiva cuantitativa como cualitativa. En el caso de la Industria 4.0 esta exigencia se convierte en estratégica, en particular si se tiene en cuenta que casi la mitad del gasto tecnológico de las empresas está vinculado a la gestión de datos.
Aunque una parte relevante de los datos serán los que se generen en el desarrollo de su propia actividad por parte de las empresas, no puede obviarse que la reutilización de datos de terceros adquiere una singular importancia por el valor añadido que aporta, sobre todo por lo que se refiere a la información proporcionada por las entidades del sector público. En todo caso, los sectores concretos donde se desarrolle la actividad industrial determinarán qué tipo de datos resulten de especial utilidad. En este sentido, la industria alimentaria puede tener mayor interés en conocer con la mayor precisión posible no sólo la predicción meteorológica sino también datos históricos relacionados con el clima y, de este modo, planificar adecuadamente tanto su producción como, asimismo, la gestión de su personal, las actividades logísticas e, incluso, inversiones futuras. O, siguiendo con otro ejemplo, desde la industria farmacéutica y la vinculada al suministro de material sanitario se podrían adoptar decisiones más eficaces y eficientes si se pudiera acceder en condiciones adecuadas a información actualizada proveniente de los sistemas de salud autonómicos lo que, en última instancia redundaría no sólo en su propio beneficio sino, adicionalmente, en la mejor satisfacción de los propios intereses públicos.
Más allá de las particularidades de cada uno de los sectores sobre los que se proyecte la concreta actividad empresarial, con carácter general las entidades del sector público disponen de bancos de datos relevantes cuya efectiva apertura a fin de permitir su reutilización de manera automatizada sería de gran interés a la hora de facilitar la transformación digital de la actividad industrial. En concreto, la disponibilidad de información socio-económica puede aportar un indiscutible valor añadido, de manera que la adopción de las decisiones sobre la propia actividad de las empresas pueda estar basada en datos generados por los servicios de estadística pública, en parámetros que tengan relevancia desde la perspectiva de la actividad económica —caso, por ejemplo, de los tributos o los niveles de renta— o, incluso, en la planificación de la propia actividad de las entidades públicas con implicaciones patrimoniales, como sucede en el ámbito de las subvenciones o la contratación. Por otro lado, son numerosos los registros públicos con información estructurada cuya apertura aportaría un importante valor añadido desde la perspectiva industrial, tal y como sucede con aquellos que proporcionen información relevante sobre la población o la apertura de establecimientos que desarrollen actividades económicas que incidan directa o indirectamente sobre las condiciones en las que se desarrolla la actividad industrial, ya sea por lo que respecta a las condiciones de producción o sobre el mercado en el que se distribuyan sus productos. Adicionalmente, la accesibilidad de la información ambiental, urbanística y, en general, sobre la ordenación territorial supondría un indiscutible en el contexto de la transformación digital de la actividad industrial, ya que permitiría integrar variables esenciales para los tratamientos de datos que precisan este tipo de empresas.
Ahora bien, la disponibilidad de datos de terceros en los proyectos vinculados a la Industria 4.0 no puede limitarse únicamente al sector público, ya que resulta de especial trascendencia poder contar con datos proporcionados por sujetos privados. En concreto, existen ciertos sectores de actividad en los que su accesibilidad con fines de reutilización por parte de las empresas industriales presentaría una singular relevancia, tal y como sucede con el ámbito de las telecomunicaciones, la energía o, entre otros, las entidades financieras. Sin embargo, a diferencia de lo que sucede con los datos generados en el ámbito del sector público, no existe una regulación que obligue a que los sujetos privados ofrezcan información a terceros generada en el desarrollo de su propia actividad en formatos abiertos y reutilizables.
Es más, puede concurrir en ocasiones un interés legítimo por parte de tales entidades para evitar que otros sujetos accedan a los datos que tienen en su poder caso, por ejemplo, de que eventuales derechos de propiedad intelectual o industrial se vean afectados, existan obligaciones contractuales que cumplir o, simplemente, razones comerciales aconsejen evitar que información relevante esté disponible a empresas competidoras. Sin embargo, salvo la tímida regulación europea dirigida a facilitar la libre circulación de datos que no tengan carácter personal, no existe un marco normativo específico que resulte de aplicación para el sector privado por lo que, en última instancia, la posibilidad de reutilización de información relevante para proyectos relacionados con la Industria 4.0 estaría limitada a los acuerdos que puedan alcanzarse de manera voluntaria.
Así pues, el decidido impulso de la Industria 4.0 requiere la existencia de un adecuado ecosistema por lo que respecta a la accesibilidad de los datos generados por otras entidades que, en definitiva, no se pueden limitar única y exclusivamente al sector público. No se trata simplemente de adoptar una perspectiva de incrementar la eficiencia desde la perspectiva de los costes sino, más bien, de optimizar todos los procesos; lo que también afecta a ciertos aspectos sociales de creciente importancia como la eficiencia energética, el respeto al medio ambiente o la mejora en las condiciones laborales. Y es precisamente en relación a estos desafíos donde el papel que ha de jugar la Administración Pública resulta crucial, no sólo ofreciendo datos relevantes para su reutilización por parte de las empresas industriales sino, sobre todo, impulsando la consolidación de un modelo de producción tecnológica y socialmente avanzando a partir de los parámetros de la Industria 4.0, lo que requiere dinamizar igualmente unas condiciones jurídicas adecuadas que garanticen la accesibilidad de información generada por entidades privadas en ciertos sectores estratégicos.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Vivimos en una era en la que la formación se ha vuelto un elemento imprescindible, tanto para ingresar y progresar en un mercado laboral cada vez más competitivo, como a la hora de formar parte de proyectos de investigación que puedan llegar a conseguir grandes mejoras en nuestra vida.
Se acerca el verano y con él nos llega una oferta formativa renovada que no descansa en absoluto en la época estival, sino todo lo contrario. Cada año, aumenta el número de cursos relacionados con la ciencia de datos, la analítica o los datos abiertos. El actual mercado laboral demanda y requiere profesionales especializados en este abanico de campos tecnológicos, tal y como refleja la CE en su Estrategia Europea de Datos, donde se destaca que la UE proporcionará financiación “para ampliar la reserva de talento digital a alrededor de 250.000 personas que sean capaces de implantar las últimas tecnologías en empresas de toda la UE”.
En este sentido, las posibilidades que ofrecen las nuevas tecnologías para realizar cualquier tipo de formación online, desde tu propio hogar con las máximas garantías, ayudan a que más profesionales apuesten por este tipo de cursos cada año.
Desde datos.gob.es hemos seleccionado una serie de cursos online, tanto gratuitos como de pago, relacionados con datos que pueden ser de tu interés:
- Comenzamos con el Curso de Aprendizaje automático y ciencia de datos impartido por la Universitat Politécnica de Valencia destaca por ofrecer a sus futuros alumnos el aprendizaje necesario para extraer conocimiento técnico a partir de los datos. Con un programa de 5 semanas de duración, en este curso podrás introducirte al lenguaje R y aprender, entre otras cosas, diferentes técnicas de preprocesamiento y visualización de datos.
- El curso de Métodos Modernos en el Análisis de Datos (Modern Methods in Data Analytics) es otra de las opciones si lo que buscas es ampliar tu formación sobre datos y aprender inglés al mismo tiempo. La Universidad de Utrecht comenzará a impartir este curso totalmente online a partir del 31 de agosto, totalmente centrado en el estudio de modelos lineares y análisis de datos longitudinal, entre otros campos.
- Otro de los cursos en inglés que dará comienzo el próximo 16 de junio es una formación de 9 semanas de duración enfocada a Data Analytics y que está impartido por la Ironhack International School. Se trata de un curso recomendable para quienes quieran aprender a cargar, limpiar, explorar y extraer información de una amplia gama de datasets, así como a utilizar Python, SQL y Tableau, entre otros aspectos.
- A continuación te descubrimos el curso de Digitalización Empresarial y Big Data: Datos, Información y Conocimiento en Mercados Altamente Competitivos, impartido por la FGUMA (Fundación General de la Universidad de Málaga). Su duración es de 25 horas y su fecha límite de matriculación es el 15 de junio. Si eres un profesional relacionado con la gestión empresarial y/o el emprendimiento, este curso seguro que resulta de tu interés.
- R para ciencia de Datos, es otro de los cursos que ofrece la FGUMA. Su principal objetivo es mostrar una visión introductoria al lenguaje de programación R para tareas de análisis de datos, incluyendo la realización de informes y visualizaciones avanzadas, presentando técnicas propias del aprendizaje computacional como un valor extra. Al igual que el curso anterior, el plazo límite de matrícula para esta formación es el 15 de junio.
- Por su parte, Google Cloud ofrece una ruta de aprendizaje totalmente online y gratuita destinada a profesionales de datos que buscan perfeccionar el diseño, compliación, análisis y optimización de soluciones de macrodatos. Seguro que este Programa especializado: Data Engineering, Big Data, and Machine Learning on GCP encaja dentro de la formación que tenías planeada.
Además, de estos cursos puntuales, cabe destacar la existencia de plataformas de formación online que ofrecen cursos relacionados con las nuevas tecnologías de manera continua. Estos cursos se conocen como MOOC y son una alternativa a la formación tradicional, en áreas como Machine Learning, Analítica del Dato, Business Intelligence o Deep Learning, unos conocimientos cada vez más demandados por las empresas.
Esta es tan solo una selección de los muchos cursos que existen como oferta formativa relacionada con datos. Sin embargo, nos encantaría contar con tu colaboración haciéndonos llegar, a través de los comentarios, otros cursos de interés en el campo de los datos y que puedan completar esta lista en el futuro.
Blog
Personas, gobiernos, economía, infraestructuras, medio ambiente… todos estos elementos confluyen en nuestras ciudades y hacen que para poder ser más eficientes éstas tengan que sacar el máximo potencial del flujo de datos constante que fluye a través de sus calles. Análisis de eficiencia de los servicios, seguimiento de la inversión, mejora del transporte público, participación y colaboración con los ciudadanos, reducción de los residuos o prevención de desastres naturales son sólo algunos de los múltiples ejemplos de innovación en las ciudades dirigidas por datos que nos muestran cómo los gobiernos locales están consiguiendo mejorar los servicios y la calidad de vida de sus ciudadanos gracias a la apertura y mejor explotación de sus datos.
Desde encontrar una plaza de aparcamiento a descubrir nuevos lugares de ocio o simplemente movernos por la ciudad. Las aplicaciones que nos facilitan el día a día ya forman parte del paisaje habitual de las ciudades. Al mismo tiempo, los datos están también transformando las ciudades poco a poco delante de nuestros propios ojos y nos ofrecen una visión alternativa de las mismas a través de la definición de nuevos barrios virtuales en función de la huella que vamos dejando con nuestras acciones y nuestros datos.
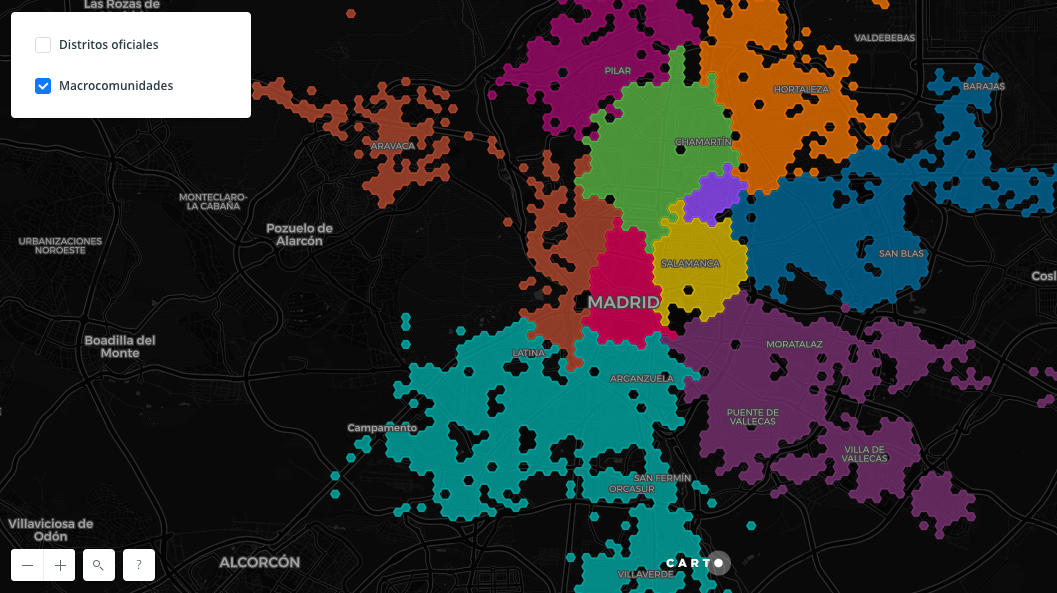
Ciudades hiperconectadas, dirigidas por los datos, gestionadas por inteligencia artificial y habitadas por un mayor número de robots que de humanos ya no serán una exclusiva de las películas y series de ciencia ficción, sino proyectos reales en mitad del desierto y con planes ya definidos que han sido puestos en marcha en busca de la diversificación y con el objetivo de transformar y renovar economías demasiado dependientes del viejo petróleo irónicamente gracias al supuesto nuevo petróleo de los datos. Volviendo por un momento al presente, encontramos también ya ejemplos de cómo esa transformación a través de los datos es real y está sucediendo en casos tan tangibles como la prevención de crímenes y disminución de la violencia en las favelas de Rio de Janeiro.
Pero no todas las expectativas son tan optimistas, ya que la visión transformadora que tienen algunas empresas tecnológicas para nuestros barrios genera también serias dudas fundadas, no sólo sobre cómo se gestionarán nuestros datos más personales y quiénes serán realmente los que tendrán acceso y control sobre ellos, sino también sobre el supuesto poder transformador de los propios datos.
Por el momento lo único que parece estar totalmente claro es que el papel de los datos en la transformación de las ciudades y ciudadanos del futuro inmediato será clave y deberemos encontrar nuestro propio camino a medias entre las visiones más optimistas y las más pesimistas para definir entre todos qué entendemos como el nuevo paradigma de las Smart Cities, pero siempre con el foco puesto en el elemento humano y no únicamente en los aspectos puramente tecnológicos y con la participación y la co-creación como elementos clave.