Blog
La demanda de profesionales con habilidades relacionadas con la analítica de datos no deja de crecer y ya se estima que la industria solo en España necesitaría más de 90.000 profesionales en datos e inteligencia artificial para impulsar la economía. Formar profesionales que puedan llenar este hueco es un gran reto que está haciendo incluso grandes compañías tecnológicas como Google, Amazon o Microsoft estén proponiendo programas de formación especializado que en paralelo a los que propone el sistema educativo reglado. Y en este contexto los datos abiertos tienen un papel muy relevante en la formación práctica de estos profesionales, ya que con frecuencia, los datos abiertos son la única posibilidad para realizar ejercicios reales y no solo simulados.
Además, aunque aún no existe un corpus de investigación sólido al respecto, algunos trabajos ya sugieren efectos positivos derivados del uso de datos abiertos como herramienta en el proceso de enseñanza-aprendizaje de cualquier materia y no solo de las relacionadas con la analítica de datos. Algunos países europeos han reconocido ya este potencial y han desarrollado proyectos piloto para determinar la mejor forma de introducir datos abiertos en el currículo escolar.
En este sentido, los datos abiertos se pueden utilizar como una herramienta para la educación y la formación de varias maneras. Por ejemplo, los datos abiertos se pueden utilizar para desarrollar nuevos materiales de enseñanza y aprendizaje, para crear proyectos basados en datos del mundo real para estudiantes o para apoyar la investigación sobre enfoques pedagógicos efectivos. Además, los datos abiertos se pueden utilizar para crear oportunidades de colaboración entre educadores, estudiantes e investigadores con el fin de compartir mejores prácticas y colaborar en soluciones a desafíos comunes.
Proyectos basados en datos del mundo real
Una aportación clave de los datos abiertos es su autenticidad, ya que son una representación de la enorme complejidad e incluso de los defectos del mundo real a diferencia de las construcciones artificiales o los ejemplos de libros de texto que se basan en supuestos muchos más simples.
Un ejemplo interesante en este sentido es el que documentó la Universidad Simon Fraser de Canadá en su Máster en Edición donde la mayor parte de sus alumnos proceden de programas universitarios no STEM y que por tanto tenían unas capacidades limitadas en el manejo de datos. El proyecto está disponible como recurso educativo abierto en la plataforma OER Commons y su objetivo es que los estudiantes comprendan que las métricas y la medición son herramientas estratégicas importantes para comprender el mundo que nos rodea.
Al trabajar con datos del mundo real, los estudiantes pueden desarrollar habilidades de construcción de relatos e investigación, y pueden aplicar habilidades analíticas y colaborativas en el uso de datos para resolver problemas del mundo real. El caso de estudio realizado con la primera edición en la que se utilizó este OER basado en datos abiertos está documentado en el libro “Open Data as Open Educational Resources - Case studies of emerging practice”. En él se muestra que la oportunidad de trabajar con datos pertenecientes a su campo de estudio resultó esencial para mantener a los estudiantes comprometidos con el proyecto. Sin embargo, lidiar con el desorden de los datos del "mundo real" fue lo que les permitió obtener un aprendizaje valioso y nuevas habilidades prácticas.
Desarrollo de nuevos materiales de aprendizaje
Los conjuntos de datos abiertos tienen un gran potencial para ser utilizados en el desarrollo de recursos educativos abiertos (REA) que son materiales de enseñanza, aprendizaje e investigación en soporte digital de carácter gratuito, pues son publicados con una licencia abierta (Creative Commons) que permite su uso, adaptación y redistribución para usos no comerciales de acuerdo con la definición de la UNESCO.
En este contexto, si bien los datos abiertos no siempre son REA, podemos decir que se convierten en REA cuando se usan en contextos pedagógicos. Los datos abiertos cuando se utilizan como recurso educativo facilitan que los estudiantes aprendan y experimenten trabajando con los mismos conjuntos de datos que utilizan investigadores, gobiernos y sociedad civil. Son un componente clave para que los estudiantes desarrollen habilidades de análisis, estadísticas, científicas y de pensamiento crítico.
Es difícil estimar la presencia actual de los datos abiertos como parte de los REA pero no resulta difícil encontrar ejemplos interesantes dentro de las principales plataformas de recursos educativos abiertos. En la plataforma Procomún podemos encontrar interesantes ejemplos como Aprender Geografía a través de la evolución de los paisajes agrarios de España que construye sobre la plataforma ArcGIS Online de la Universidad Complutense de Madrid un Webmap para el aprendizaje de los paisajes agrarios en España. El recurso educativo emplea ejemplos concretos de distintas comunidades autónomas empleando fotografías o imágenes fijas geolocalizadas y datos propios integrados con datos abiertos. De este modo los estudiantes trabajan los conceptos no a través de una mera descripción en texto sino con recursos interactivos que favorecen además la mejora de sus competencias digitales y espaciales
En la plataforma OER Commons encontramos por ejemplo el recurso “De los datos abiertos al compromiso cívico” que está dirigido a públicos a partir de enseñanza secundaria con el objetivo de enseñar a interpretar cómo se gasta el dinero público en un área regional, local, o barrio determinado. Para ello se apoya en los conocidos proyectos para analizar presupuestos públicos “¿Dónde van mis impuestos?”, disponibles en muchas zonas del mundo como fruto de las políticas de transparencia de los poderes públicos. Este recurso que podría ser portado a España con facilidad ya que contamos con numerosos proyectos ¿Donde van mis impuestos?, como el mantenido por Fundación Civio.
Habilidades relacionadas con datos
Cuando nos referimos a la formación y educación en habilidades relacionadas con los datos, en realidad nos estamos refiriendo a un área de gran amplitud que además es muy difícil dominar en todas sus facetas. De hecho, lo habitual es que los proyectos relacionados con datos se aborden en equipos donde cada miembro desempeña un rol especializado en alguna de estas áreas. Por ejemplo, es habitual diferenciar al menos la limpieza y preparación de datos, el modelado de datos y la visualización de datos como las principales actividades que se realizan en un proyecto de ciencia datos e inteligencia artificial.
En todos los casos el uso de datos abiertos está ampliamente adoptado como recurso central de los proyectos que se proponen para la adquisición de cualquiera de estas habilidades. La muy conocida comunidad de ciencia de datos Kaggle organiza competiciones basadas en conjuntos de datos abiertos aportados a la comunidad y que constituyen un recurso esencial para el aprendizaje basado en proyectos reales de quienes quieren adquirir habilidades relacionadas con los datos. Existen otras propuestas basadas en suscripciones como Dataquest o ProjectPro pero en todos los casos utilizan para los proyectos que proponen conjuntos de datos reales obtenidos de los múltiples repositorios de datos abiertos de carácter general o repositorios específicos de un área de conocimiento.
Los datos abiertos, al igual que en otras áreas, aún no han desarrollado todo su potencial como herramienta para la educación y la formación. Sin embargo como puede verse en el programa de la última edición de la OER Conference 2022, cada vez son más los ejemplos en los que los datos abiertos tienen un papel central en la enseñanza, las nuevas prácticas educativas y la creación de nuevos recursos educativos para todo tipo de materias, conceptos y habilidades.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
¿Estás interesado en el análisis de datos? Si la respuesta es sí, te interesará saber que UniversiDATA ha puesto en marcha un datathon para reconocer proyectos de tratamiento de datos abiertos basados en los datasets disponibles en su portal.
Con esta iniciativa se busca no solo premiar el talento, sino también promocionar los contenidos que ofertan y fomentar su uso, inspirando nuevos proyectos gracias a la difusión de casos de referencia. Además, se trata de una oportunidad para conocer a sus reutilizadores y entender mejor sus objetivos, retos y necesidades. Una información de valor que se utilizará para impulsar mejoras en la plataforma.
¿Quién puede participar?
La convocatoria está abierta a cualquier persona física mayor de edad con residencia fiscal en la Unión Europea. Pueden participar estudiantes, desarrolladores, investigadores o cualquier ciudadano interesado en el análisis de datos.
¿Cómo se desarrolla la competición?
La competición se estructura en dos fases:
Fase eliminatoria
Un jurado de expertos evaluará todas las solicitudes recibidas atendiendo a las descripciones de los proyectos realizadas por los participantes en el formulario de inscripción. Para ello se tendrán en cuenta 4 criterios detallados en las bases de la competición: impacto, calidad de la propuesta, usabilidad/presentación y reusabilidad.
Tras la evaluación, un máximo de 10 finalistas pasará a la siguiente fase.
Fase final
Los finalistas tendrán que presentar sus proyectos por videoconferencia ante los miembros del jurado.
Tras la presentación se darán a conocer a los tres ganadores.
¿Cuáles son los requisitos de los proyectos presentados?
Los trabajos presentados deberán cumplir tres obligaciones:
- Es necesario utilizar al menos un conjunto de datos publicado en el portal de datos abiertos UniversiDATA. Estos datasets podrá combinarse con datos secundarios de otras fuentes.
- El uso que se haga de los conjuntos de datos de UniversiDATA debe ser esencial para obtener los resultados del análisis.
- El análisis de los datos debe tener un objetivo o utilidad claro. No se admitirán tratamientos de datos genéricos.
Cabe destacar que se pueden presentar trabajos ya existentes, previamente presentado en otros contextos. Además, no existen limitaciones con respecto a la tecnología a utilizar para el análisis -cada usuario puede usar las herramientas que considere adecuadas- ni relativas al formato del resultado final del análisis. Es decir, se puede concursar con una App móvil, una aplicación web, un análisis de datos en Jupyter o R-Markdown, etc...
¿Cuáles son los premios?
Los tres ganadores recibirán un total de 3.500€, distribuidos de la siguiente manera:
- Primer premio: 2.000 €
- Segundo premio: 1.000 €
- Tercer premio: 500 €
El resto de finalistas recibirán un diploma de reconocimiento
¿Cómo puedo participar?
El plazo de inscripción ya está abierto. La manera más sencilla de participar es rellenar el formulario disponible al final del espacio web de la competición antes del 14 de octubre de 2022.
Antes de inscribirte te recomendamos revisar toda la información completa en las bases del concurso. Si tienes cualquier duda, puedes ponerte en contacto con los organizadores. Próximamente se habilitarán diversos canales para que los participantes puedan plantear dudas relativas no solo a los procedimientos de la competición, sino también a los conjuntos de datos de la plataforma.
Calendario de la competición
- Recepción de candidaturas: hasta el 14 de octubre de 2022
- Publicación de los 10 finalistas: 14 de noviembre de 2022
- Comunicación de los tres ganadores: 16 de diciembre de 2022
Descubre más sobre UniversiDATA
UniversiDATA nació a finales de 2020 con el objetivo de fomentar los datos abiertos en el sector de la educación superior en España de una forma armonizada. Se trata de una iniciativa público-privada que actualmente engloba a la Universidad Rey Juan Carlos, la Universidad Complutense de Madrid, la Universidad Autónoma de Madrid, la Universidad Carlos III de Madrid, la Universidad de Valladolid, la Universidad de Huelva y Dimetrical, The Analytics Lab, S.L.
En 2021 UniversiDATA se hizo con el Primer Premio del III Desafío Aporta por su proyecto UniversiDATA-Lab, un portal público para el análisis avanzado y automático de los datasets publicados por las universidades. Puedes conocer más sobre el proyecto en esta entrevista.
Empresa reutilizadora
Estudio Alfa es una empresa tecnológica dedicada a ofrecer servicios que favorezcan la imagen de empresas y marcas en Internet, incluyendo el desarrollo de apps. Para llevar a cabo estos servicios utilizan técnicas y estrategias que cumplen con estándares de usabilidad y favorecen el posicionamiento en buscadores web, facilitando así que las páginas de sus clientes reciban más visitantes y con ello potenciales clientes. Cuentan además con especial experiencia en sectores productivos y de turismo.
Blog
Las universidades españolas poseen numerosos datos de calidad que cuentan con un gran potencial económico y social. Por ello, hace ya un tiempo que venimos asistiendo a un movimiento de apertura de datos por parte de las universidades en nuestro país, con el objetivo de impulsar el uso y reutilización de la información que generan, así como mejorar su transparencia, entre otros .
Fruto de este movimiento de apertura, han ido surgiendo portales de datos abiertos ligados a universidades, muchos de los cuales se encuentran federados con datos.gob.es, como por ejemplo la Universidad de Cantabria, la Universidad de Extremadura o la Universidad Pablo de Olavide, aunque hay muchas más. Incluso han surgido iniciativas colaborativas como UniversiDATA, que busca fomentar los datos abiertos en el sector de la educación superior de una forma armonizada. UniversiDATA reúne actualmente a 6 universidades, pero su intención es continuar creciendo y actuar como un punto de acceso único donde las diferentes universidades adheridas a la iniciativa pueden compartir sus datos de una manera sencilla. También cabe destacar el papel del Ministerio de Universidades, que actualmente ofrece casi 1.000 datasets a través de datos.gob.es.
Entre los conjuntos de datos que comparten las universidades encontramos datos administrativos, sobre el perfil del alumnado o los distintos itinerarios académicos, aunque también cuentan con un papel relevante en la publicación de los datos de sus grupos de investigación.
Pero el papel de las universidades en el ecosistema de datos abiertos va mucho más allá de meros publicadores, sino que también tienen un rol destacado a la hora de impulsar la apertura de más datos y su reutilización.
Ejemplos de grupos de datos abiertos ligados a universidades
El campo de los datos en general, y el de los datos abiertos en particular, cuenta cada vez con más peso e importancia dentro del ámbito universitario, en materia lectiva pero también en el área de la divulgación. Como consecuencia, hoy en día encontramos diversos ejemplos de grupos, cátedras o profesionales ligados a la educación superior enfocados en el fomento del uso y reutilización de los datos académicos.
A continuación, analizamos algunos grupos de datos abiertos ligados al ámbito de la educación superior en nuestro país:
Cátedra de Transparencia y Datos Abiertos – Observatorio Valenciano de Datos Abiertos y Transparencia
¿Qué es y cuál es su objetivo?
Este organismo ha sido creado por la Generalitat Valenciana y la Universitat Politécnica de Valéncia, a través de su Escuela Superior de Ingeniería Informática y el Máster Universitario de Gestión de la Información, para realizar actividades relacionadas con la transparencia, la participación y el acceso de la ciudadanía a la información pública en el ámbito de la Comunidad Valenciana.
¿Qué funciones lleva a cabo?
La cátedra organiza y desarrolla una serie de actividades relacionadas con el ámbito de la transparencia y los datos abiertos que se pueden clasificar en tres categorías diferentes:
- Actividades de formación: la cátedra colabora en actividades docentes, como el Máster Oficial Universitario en Gestión de la Información; en la puesta en marcha de programas permanentes de formación dirigidos a funcionarios, entidades locales y asociaciones; o la creación de becas y premios para los mejores trabajos de grado en materia de transparencia para alumnos de la UPV.
- Actividades de divulgación técnica, tecnológica y artística: a través de talleres, conferencias y jornadas, se busca impulsar tanto la publicación como la reutilización de los datos abiertos. También desarrollan espacios de trabajo junto al personal técnico de la administración, programadores informáticos y gestores públicos.
- Actividades de investigación y desarrollo: desde la cátedra trabajan en distintas líneas de investigación, especialmente, en materia de datos abiertos procedentes de la web GVAOberta de la Generalitat. También promueven soluciones tecnológicas innovadoras en materia de transparencia, participación y acceso a la información pública.
Próximos pasos
Los datos abiertos conforman el eje central de todas las actividades que celebrarán a lo largo de este año, organizadas por la cátedra. El Datathon 2022 destaca como la actividad más cercana que están coordinando, pues ya se encuentra en marcha. En esta competición participan cuatro universidades públicas de la Comunidad Valenciana, además de las distintas cátedras de la Universitat Politécnica de Valéncia. Este desafío, que empezó el pasado 4 de marzo y se prolongará hasta el 30 de abril, tiene como objetivo que sus participantes resuelvan alguno de los tres retos propuestos (sobre producción y consumo responsable, aspectos medioambientales y cultura) haciendo uso de diferentes herramientas de aprendizaje automático, inteligencia artificial o ciencia de datos.
Además del Datathon, también tienen previsto celebrar una jornada internacional con la colaboración de Open Knowledge Foundation, una serie de talleres de verificación de noticias a través de los datos abiertos junto a Newtral, diversas jornadas de difusión y formación con varias federaciones de empresas, o un workshop sobre datos abiertos desde la perspectiva de género. Entre sus planes también se encuentra el crear un directorio de reutilizadores de la Comunidad Valenciana. Aunque se está trabajando en ellos, estos eventos todavía no cuentan a día de hoy con una agenda y calendario oficiales.
Cátedra Cajasiete de Big Data, Open Data y Blockchain, Universidad de La Laguna
¿Qué es y cuál es su objetivo?
La Universidad de La Laguna y Cajasiete crearon el año pasado la Cátedra Big Data, Open Data y Blockchain (Cátedra Cajasiete BOB), con el propósito de contribuir a la transformación digital y al desarrollo de una economía competitiva en las Islas Canarias, a través de la investigación, la formación y la divulgación en campos como Big Data, Open Data o Blockchain. Esta Cátedra cuenta en su Consejo Asesor con un conjunto de representantes de entidades públicas y privadas del archipiélago, que son actores clave a la hora de fomentar la transformación digital y el desarrollo de los modelos de negocio público-privado de Canarias.
¿Qué funciones lleva a cabo?
Uno de sus proyectos más destacados ha sido “Mapa BOB”, donde analizaron detalladamente la situación de las entidades canarias en materia de digitalización para tomar acciones concretas que ayuden a cumplir su misión. Tras este análisis, desde la cátedra se han centrado en diversas iniciativas con el objetivo de elevar el nivel de digitalización en el archipiélago, muchas de las cuales han estado centradas en los datos abiertos:
- Webinars BOB: han desarrollado seminarios online de temáticas concretas para conocer y difundir buenas prácticas en el ámbito de la tecnología y los datos.
- Encuentros de Administraciones Públicas: también han puesto en marcha espacios para que distintas AA.PP. canarias puedan compartir experiencias sobre temas concretos relacionados con datos. En la última edición presencial hubo una mesa de debate dedicada al análisis de datos abiertos.
- Proyectos: entre los proyectos que han llevado a cabo, destaca “Aplicación práctica de los datos abiertos: actualización y predicción”. Se trata de un Trabajo de Fin de Grado cuyo objetivo se basó en definir un indicador de calidad para, a partir de datos abiertos relacionados con COVID-19, realizar predicciones de la evolución de la incidencia acumulada.
- Cursos de formación: dentro del ámbito de los datos abiertos ha organizado diferentes formaciones como, por ejemplo:
- Curso sobre la plataforma CKAN destinado al Cabildo de Lanzarote.
- Masterclass de Open Data y Big Data destinada a estudiantes del ámbito de empresa de la Universidad de La Laguna.
- Cursos de Open Data destinados a Administraciones Públicas dentro de la iniciativa “Elementos para modernizar la Administración y mejorar la prestación de servicios públicos en el contexto actual” de la Universidad de La Laguna.
- Curso de Python, cuyo proyecto final consistía en analizar datos abiertos de turismo en la isla de Tenerife.
Próximos pasos
Actualmente la Cátedra BOB se encuentra colaborando en la iniciativa “DIGINNOVA”, un programa formativo para capacitar a personas desempleadas en materias de digitalización específicas para las necesidades de las islas. En lo que respecta a 2022, se han planificado diversas actividades de difusión, formación e investigación con las que esperan seguir creciendo y aportando valor, aunque por el momento ninguna de ellas se ha presentado oficialmente aún.
Hablando en data
¿Qué es y cuál es su objetivo?
Se trata de un canal de divulgación destinado a compartir información y conocimiento de interés con la comunidad de científicos de datos. En este espacio podemos encontrar entrevistas, repasar conceptos, noticias o eventos sobre Data Science e Inteligencia Artificial. En este caso no hablamos de un proyecto ligado a una universidad, sino a sus profesionales. Este canal ha sido creado por Abilio Romero Ramos e Iván Robles Agudo, dos científicos de datos con amplia experiencia en el sector que dedican parte de su tiempo profesional a impartir materias relacionadas con el ámbito de los datos en diferentes másteres de centros de educación superior como la Universidad Europea o la Universidad CEU San Pablo.
¿Qué funciones lleva a cabo?
El canal de YouTube de Hablando en Data se ha convertido en el eje central de su proyecto de divulgación. A través de él tratan de acercar y explicar de manera amena y sencilla diversos conceptos necesarios para aprovechar el valor que se esconde en los datos, sobre todo en aquellos que se encuentran disponibles al público.
Por otro lado, en su página web centralizan y recopilan multitud de contenido relacionado con la ciencia de datos. En ella podemos identificar algunas de las funciones que esta iniciativa lleva a cabo como, por ejemplo:
- Divulgación: cuentan con una sección dedicada a la difusión de blogs, webs y canales que cuentan con información de interés sobre esta temática.
- Formación: en su web podemos encontrar una sección dedicada a difundir materiales formativos de interés sobre ciencia de datos, bien sea a través de libros gratuitos, documentales o cursos en línea.
- Data science para la escuela: una iniciativa que trata de acercar los datos a toda la población, especialmente a los estudiantes. Aquí comparten recursos útiles y divertidos para ayudar a los más jóvenes a introducirse en el mundo de la ciencia de datos.
También es especialmente destacable la colaboración que esta iniciativa realiza con SoGoodData, una ONG que ayuda y apoya a proyectos sociales gracias a la combinación de información pública y aquella que comparten las empresas colaboradoras.
Próximos pasos
Los planes de futuro más próximos para esta iniciativa pasan por continuar divulgando conocimiento sobre ciencia de datos entre su comunidad y seguir aprovechando las posibilidades que este campo ofrece. Continuarán difundiendo el uso y la reutilización de datos públicos, no solo desde su canal de YouTube sino también desde los másteres en los que imparten clase y a través de iniciativas como SoGoodData.
Como hemos visto, las entidades universitarias y sus profesionales han adquirido un papel relevante en el sector de los datos abiertos de nuestro país, como publicadores, divulgadores y reutilizadores, aunque eso da para otro artículo. ¿Conoces alguna otra iniciativa de divulgación de datos abiertos en el ámbito universitario? Déjanos un comentario o escríbenos un correo a dinamizacion@datos.gob.es y cuéntanoslo. Estaremos encantados de leerte.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información que finalmente se resume en unas conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre el alumnado de la universidad española a lo largo de los últimos años. A partir de estos datos observaremos las características que presenta el alumnado de la universidad española y cuáles son los estudios más demandados.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio de Universidades, que recoge series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presenta el alumnado de la universidad española. Estos datos se encuentran disponibles en el catálogo de datos.gob.es y en el propio catálogo de datos del Ministerio de Universidades. Concretamente los datasets que usaremos son:
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de doctorado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de máster por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de grado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculaciones por cada una de las titulaciones impartidas por las universidades españolas que se encuentra publicado en la sección de Estadísticas de la página oficial del Ministerio de Universidades. El contenido de esta dataset abarca desde el curso 2015-2016 al 2020-2021, aunque para este último curso los datos con provisionales.
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación R desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Datawrapper.
Datawrapper es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en línea o exportarse como PNG, PDF o SVG. Esta herramienta es muy sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Preprocesamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Creación de tablas de trabajo
- Ajuste del nombre de algunas variables
- Agrupación de varias variables en una única con diferentes factores
- Transformación de variables
- Detección y tratamiento de datos ausentes (NAs)
- Creación de nuevas variables calculadas
- Resumen de las tablas transformadas
- Preparación de datos para su representación visual
- Almacenamiento de archivos con las tablas de datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
5. Visualización de datos
Una vez realizado el preprocesamiento de los datos, vamos con la visualización. Para la realización de esta visualización interactiva usamos la herramienta Datawrapper en su versión gratuita. Se trata de una herramienta muy sencilla con especial aplicación en el periodismo de datos que te animamos a utilizar. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que la tabla de datos que le proporcionemos este estructurada adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos la siguientes:
- ¿Cómo se está distribuyendo el número de hombres y mujeres entre los alumnos matriculados de grado, máster y doctorado a lo largo de los últimos cursos?
Si nos centramos en el último curso 2020-2021:
- ¿Cuáles son las ramas de enseñanza más demandadas en las universidades españolas? ¿Y las titulaciones?
- ¿Cuáles son las universidades con mayor número de matriculaciones y dónde se ubican?
- ¿En qué rangos de edad se encuentra el alumnado universitario de grado?
- ¿Cuál es la nacionalidad de los estudiantes de grado de las universidades españolas?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Distribución de las matriculaciones en las universidades españolas desde el curso 2015-2016 hasta 2020-2021, desagregado por sexo y nivel académico
Esta representación visual la hemos realizado teniendo en cuenta las matriculaciones de grado, master y Doctorado. Una vez que hemos subido la tabla de datos a Datawrapper (conjunto de datos \"Matriculaciones_NivelAcademico\"), hemos seleccionado el tipo de gráfico a realizar, en este caso un diagrama de barras apiladas (stacked bars) para poder reflejar por cada curso y sexo, las personas matriculadas en cada nivel académico. De esta forma podemos ver, además, el global de estudiantes matriculados por curso. A continuación, hemos seleccionado el tipo de variable a representar (Matriculaciones) y las variables de desagregación (Sexo y Curso). Una vez obtenido el gráfico, podemos modificar de forma muy sencilla la apariencia, modificando los colores, la descripción y la información que muestra cada eje, entre otras características.
Para responder a las siguientes preguntas, nos centraremos en el alumnado de grado y en el curso 2020-2021, no obstante, las siguientes representaciones visuales pueden ser replicadas para el alumnado de máster y doctorado, y para los diferentes cursos.
5.2. Mapa de las universidades españolas georreferenciadas, donde se muestra el número de matriculados que presentan cada una de ellas
Para la realización del mapa hemos utilizado un listado de las universidades españolas georreferenciadas publicado por el Portal de Datos Abiertos de Esri España. Una vez descargados los datos de las distintas áreas geográficas en formato GeoJSON, los transformamos en Excel, para poder realizar una unión entre el datasets de las universidades georreferenciadas y el dataset que presenta el número de matriculados por cada universidad que previamente hemos preprocesado. Para ello hemos utilizado la función BUSCARV() de Excel que nos permitirá localizar determinados elementos en un rango de celdas de una tabla.
Antes de subir el conjunto de datos a Datawrapper, debemos seleccionar la capa que muestra el mapa de España dividido en provincias que nos proporciona la propia herramienta. Concretamente, hemos seleccionado la opción \"Spain>>Provinces(2018)\". Seguidamente procedemos a incorporar el conjunto de datos \"Universidades\", antes generado, (este conjunto de datos se adjunta en la carpeta de conjuntos de datos de GitHub para esta visualización paso a paso), indicando que columnas contienen los valores de las variables Latitud y Longitud.
A partir de este punto, Datawrapper ha generado un mapa en el que se muestran las ubicaciones de cada una de las universidades. Ahora podemos modificar el mapa según nuestras preferencias y ajustes. En este caso, haremos que el tamaño de los puntos y el color dependa del número de matriculaciones que presente cada universidad. Además, para que estos datos se muestren, en la pestaña “Annotate”, en la sección “Tooltips”, debemos indicarle las variables o el texto que deseemos que aparezca.
5.3. Ranking de matriculaciones por titulación
Para esta representación gráfica utilizamos el objeto visual de Datawrapper tabla (Table) y el conjunto de datos \"Titulaciones_totales\" para mostrar el número de matriculaciones que presenta cada una de las titulaciones impartidas durante el curso 2020-2021. Dado que el número de titulaciones es muy extenso, la herramienta nos ofrece la posibilidad de incluir un buscador que permite filtrar los resultados.
5.4. Distribución de matriculaciones por rama de enseñanza
Para esta representación visual, hemos utilizado el conjunto de datos \"Matriculaciones_Rama_Grado\" y seleccionado gráficos de sectores (Pie Chart), donde hemos representado el número de matriculaciones según sexo en cada una de las ramas de enseñanza en las cuales se dividen las titulaciones impartidas por las universidades (Ciencias Sociales y Jurídicas, Ciencias de la Salud, Artes y Humanidades, Ingeniería y Arquitectura y Ciencias). Al igual que en el resto de gráficos, podemos modificar el color del gráfico, en este caso en función de la rama de enseñanza.
5.5. Matriculaciones de Grado por edad y nacionalidad
Para la realización de estas dos representaciones de datos visuales utilizamos diagramas de barras (Bar Chart), donde mostramos la distribución de matriculaciones en el primero, desagregada por sexo y nacionalidad, utilizaremos el conjunto de datos \"Matriculaciones_Grado_nacionalidad\" y en el segundo, desagregada por sexo y edad, utilizando el conjunto de datos \"Matriculaciones_Grado_edad\". Al igual que los visuales anteriores, la herramienta facilita de forma sencilla la modificación de las características que presentan los gráficos.
6. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implamentar se puede observar lo siguiente:
- El número de matriculaciones aumenta a lo largo de los cursos académicos independientemente del nivel académico (grado, máster o doctorado).
- El número de mujeres matriculadas es mayor que el de hombres en grado y máster, sin embargo es menor en el caso de las matriculaciones de doctorado, excepto en el curso 2019-2020.
- La mayor concentración de universidades la encontramos en la Comunidad de Madrid, seguido de la comunidad autónoma de Cataluña.
- La universidad que concentra mayor número de matriculaciones durante el curso 2020-2021 es la UNED (Universidad Nacional de Educación a Distancia) con 146.208 matriculaciones, seguida de la Universidad Complutense de Madrid con 57.308 matriculaciones y la Universidad de Sevilla con 52.156.
- La titulación más demandada el curso 2020-2021 es el Grado en Derecho con 82.552 alumnos a nivel nacional, seguido del Grado de Psicología con 75.738 alumnos y sin apenas diferencia, el Grado en Administración y Dirección de Empresas con 74.284 alumnos.
- La rama de enseñanza con mayor concentración de alumnos es Ciencias Sociales y Jurídicas, mientras que la menos demandada es la rama de Ciencias.
- Las nacionalidades que más representación tienen en la universidad española son de la región de la unión europea, seguido de los países de América Latina y Caribe, a expensas de la española.
- El rango de edad entre los 18 y 21 años es el más representado en el alumnado de las universidades españolas.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Entrevista
Publicar datos abiertos siguiendo las buenas prácticas del linked data (datos enlazados) permite impulsar su reutilización. Datos y metadatos se describen utilizando estándares RDF que permiten representar relaciones entre entidades, propiedades y valores. De esta forma los conjuntos de datos se interconectan entre sí, independientemente del repositorio digital donde se encuentren, lo que facilita su contextualización y explotación.
Si hay un campo donde este tipo de datos son especialmente valorados es el de la investigación. Por ello no es de extrañar que cada vez más universidades empiecen a utilizar esta tecnología. Es el caso de la Universidad de Extremadura (UEX), que cuenta con un portal de investigación que recopila de forma automática la producción científica ligada a la institución. Adolfo Lozano, Director de la Oficina de transparencia y datos abiertos de la Universidad de Extremadura y colaborador en la elaboración de la “Guía práctica para la publicación de datos enlazados en RDF", nos cuenta cómo han puesto en marcha este proyecto.
Entrevista completa:
1. El portal de investigación de la Universidad de Extremadura es una iniciativa pionera en nuestro país. ¿Cómo surgió el proyecto?
El portal de investigación de la Universidad de Extremadura se ha lanzado hace aproximadamente un año, y ha tenido una magnífica acogida entre los investigadores de la UEX y de entidades externas que buscan las líneas de trabajo de nuestros investigadores.
Pero la iniciativa del portal de datos abiertos de la UEX comenzó en 2015, aplicando el conocimiento de nuestro grupo de investigación Quercus de la Universidad de Extremadura sobre representación semántica, y con la experiencia que teníamos en el portal de datos abiertos del Ayuntamiento de Cáceres. El impulso mayor lo ha tenido hace unos 3 años cuando el Vicerrectorado de Transformación Digital creó la Oficina de Transparencia y Datos abiertos de la UEX.
Desde el principio, teníamos claro que queríamos un portal con datos de calidad, con el máximo nivel de reutilización, y donde se aplicasen los estándares internacionales. Aunque supuso un considerable esfuerzo publicar todos los datasets usando esquemas ontológicos, siempre representado los datos en RDF, y enlazando los recursos como práctica habitual, podemos decir que a medio plazo los beneficios de organizar así la información nos da un gran potencial para poder extraer y manejar la información para múltiples propósitos.
Queríamos un portal con datos de calidad, con el máximo nivel de reutilización, y donde se aplicasen los estándares internacionales. [...] supuso un considerable esfuerzo publicar todos los datasets usando esquemas ontológicos, siempre representado los datos en RDF, y enlazando los recursos.
2. Uno de los primeros pasos en un proyecto de este tipo es seleccionar vocabularios que permitan conceptualizar y establecer relaciones semánticas entre los datos ¿existía un buen punto de partida o fue necesario crear un vocabulario ex-profeso para este contexto? ¿la disponibilidad de vocabularios de referencia constituye un freno para el desarrollo de la interoperabilidad de datos?
Uno de los primeros pasos para seguir esquemas ontológicos en un portal de datos abiertos es identificar los términos más adecuados para representar las clases, atributos y relaciones que van a configurar los datasets. Y además es una práctica que continúa conforme que se van incorporando nuevos conjuntos de datos.
En nuestro caso, hemos intentado reutilizar vocabularios lo más extendidos posible como foaf, schema, dublin core y también algunos específicos como vibo o bibo. Pero en muchos casos hemos tenido que definir términos propios en nuestra ontología porque no existían esos componentes. En nuestra opinión, cuando el proyecto Hércules de la CRUE-TIC esté operativo y se hayan definido los esquemas ontológicos genéricos para las universidades, va a mejorar mucho la intereoperabilidad entre nuestros datos, y sobre todo animará a otras universidades a crear sus portales de datos abiertos con estos modelos.
Uno de los primeros pasos para seguir esquemas ontológicos en un portal de datos abiertos es identificar los términos más adecuados para representar las clases, atributos y relaciones que van a configurar los datasets.
3. ¿Cómo se abordó el desarrollo de esta iniciativa, qué dificultades os encontrasteis y qué perfiles son necesarios para llevar a cabo un proyecto de este tipo?
En nuestra opinión, si se quiere hacer un portal que sea útil a medio plazo, está claro que se requiere un esfuerzo inicial para organizar la información. Quizás lo más complicado al principio es recopilar los datos que están dispersos en diferentes servicios de la Universidad en múltiples formatos, comprender en qué consisten, buscar la mejor forma de representación, y luego coordinar la forma de poder acceder a ellos de forma periódica para las actualizaciones.
En nuestro caso, hemos desarrollado scripts específicos para distintos formatos de fuentes datos, de diferentes Servicios de la UEX (como el Servicio de Informática, el Servicio de Transferencia, o desde servidores externos de publicaciones) y que los transforman en representación RDF. En este sentido, es imprescindible contar con Ingenieros Informáticos, especializados en representación semántica y con amplios conocimientos de RDF y SPARQL. Pero además, desde luego, se debe involucrar a diferentes servicios de la Universidad para coordinar este mantenimiento de la información.
4. ¿Cómo valora el impacto de la iniciativa? ¿Puede contarnos algunos casos de éxito de reutilización de los conjuntos de datos proporcionados?
Por los logs de consultas, sobre todo al portal de investigación, vemos que muchos investigadores utilizan el portal como punto de recogida de datos que usan para elaborar sus currículums. Además, sabemos que las empresas que necesitan algún desarrollo concreto, utilizan el portal para obtener el perfil de nuestros investigadores.
Pero, por otro lado es habitual que algunos usuarios (de dentro y fuera de la UEX) nos pidan consultas específicas a los datos del portal. Y curiosamente, en muchos casos, son los propios servicios de la Universidad que nos suministran los datos los que nos piden listados o gráficos específicos donde se enlacen y crucen con otros datasets del portal.
Al tener los datos enlazados, un profesor de la UEX está enlazado con la asignatura que imparte, el área de conocimiento, el departamento, el centro, pero también con su grupo de investigación, con cada una de sus publicaciones, los proyectos en los que participa, las patentes, etc. Las publicaciones están enlazadas con revistas y estas a su vez con sus índices de impacto.
Por otro lado, las asignaturas, están enlazadas con las titulaciones donde se imparten, los centros, y disponemos también de los números de matriculados por asignaturas, e índices de calidad y satisfacción de usuarios. De esta forma, se pueden realizar consultas e informes complejos manejando en conjunto toda esta información.
Como casos de uso, por ejemplo, podemos mencionar que los documentos Word de las 140 comisiones de calidad de los títulos, se generan automáticamente (incluidos gráficos de evolución anual y listados) mediante consultas al portal opendata. Esto ha permitido ahorrar decenas de horas de trabajo en conjunto a los miembros de estas comisiones.
Otro ejemplo, que hemos terminado este año, ha sido la memoria anual de investigación que se ha generado también automáticamente mediante consultas SPARQL. Estamos hablando de más de 1.500 páginas donde se expone toda la producción científica y de transferencia de la UEX, agrupada por institutos de investigación, grupos, centros y departamentos.
Como casos de uso, por ejemplo, podemos mencionar que los documentos Word de las 140 comisiones de calidad de los títulos, se generan automáticamente (incluidos gráficos de evolución anual y listados) mediante consultas al portal opendata. Esto ha permitido ahorrar decenas de horas de trabajo en conjunto a los miembros de estas comisiones.
5. ¿Cuáles son los planes de futuro de la Universidad de Extremadura en materia de datos abiertos?
Queda mucho por hacer. Por ahora estamos abordando en primer lugar aquellos temas que hemos considerado que eran más útiles para la comunidad universitaria, como son la producción científica y de transferencia, y la información académica de la UEX. Pero en el futuro cercano queremos desarrollar conjuntos de datos y aplicaciones relacionados con temas económicos (como contratos públicos, evolución del gastos, mesas de contratación) y administrativos (como el plan de organización docente, organigrama de Servicios, composiciones de órganos de gobierno, etc) para mejorar la transparencia de la institución.
Entrevista
Google es una compañía con una fuerte apuesta por los datos abiertos. Ha lanzado el buscador Google Dataset Search, para localizar datos abiertos en repositorios existentes de todo el mundo, y también ofrece conjuntos de datos propios en formato abierto como parte de su iniciativa Google Research. Además, es reutilizador de datos abiertos en soluciones como Google Earth.
Entre sus áreas de trabajo está Google for Education, con soluciones diseñadas para profesores y alumnos. En datos.gob.es hemos entrevistado a Gonzalo Romero, director de Google for Education en España y miembro del jurado encargado de evaluar las propuestas recibidas en la III edición del Desafío Aporta. Gonzalo nos ha hablado sobre su experiencia, la influencia de los datos abiertos en el sector educativo y la importancia de la apertura de datos.
Entrevista completa:
1. ¿A qué retos se enfrenta el sector educativo en España y cómo pueden ayudar los datos abiertos y las tecnologías basadas en ellos a superarlos?
El año pasado debido a la pandemia, el sector de la educación se vio obligado a acelerar su proceso de digitalización para que la actividad se pudiese desarrollar con la máxima normalidad posible.
Los principales retos a los que se enfrenta el sector educativo en España son la tecnología y la digitalización puesto que este sector está menos digitalizado que la media. Se necesitan herramientas digitales seguras, sencillas y sostenibles para que el sistema educativo, desde profesores y alumnos hasta administrativos puedan operar fácilmente y sin problema alguno.
Los datos abiertos permiten localizar en cualquier momento determinada información de calidad entre miles de fuentes de manera rápida y sencilla. Estos repositorios crean un ecosistema de intercambio de datos fiable que impulsa a los editores a publicar datos para impulsar el aprendizaje de los alumnos y el desarrollo de soluciones tecnológicas.
2. ¿Qué datasets son los más demandados para poner en marcha soluciones educativas?
Cada región suele generar los suyos propios. El principal reto es cómo pueden crearse nuevos datasets en colaboración con las variables que les permitan crear modelos predictivos para anticiparse a los principales retos que enfrentan, tales como el abandono escolar, la personalización del aprendizaje o la orientación académica y profesional, entre otros.
3. ¿Cómo pueden iniciativas como los hackathons, desafíos o retos ayudar a impulsar la innovación basada en datos? ¿Cómo ha sido su experiencia en el III Desafío Aporta?
Es fundamental apostar por proyectos e iniciativas que desarrollen soluciones innovadoras para fomentar el uso de datos.
La tecnología ofrece herramientas que ayudan a buscar sinergias entre datos públicos y privados para desarrollar soluciones tecnológicas e impulsar diferentes habilidades entre los alumnos.
4. Además de como base para soluciones tecnológicas, los datos abiertos también tienen un rol importante como recurso educativo en sí, ya que pueden proporcionar conocimiento sobre múltiples áreas. ¿En qué medida este tipo de recursos favorece el pensamiento crítico de los estudiantes?
El uso de los datos abiertos en las aulas es una forma de impulsar y fomentar las capacidades educativas de los estudiantes. Para un buen uso de estos recursos es importante buscar y filtrar la información de acuerdo a las necesidades, así como mejorar la capacidad de analizar datos y argumentación de una manera razonada. Además, permite al estudiante desenvolverse en programas y herramientas tecnológicas.
Estas habilidades son útiles para el futuro no sólo académico sino laboral de los alumnos puesto que cada vez se demandan más profesionales que cuenten con habilidades relacionadas con capacidad analítica y de gestión de datos.
5. A través de su iniciativa de Google Research se llevan a cabo múltiples proyectos, algunos de ellos ligados a la apertura y reutilización de datos abiertos. ¿Por qué es importante que las compañías privadas también abran datos?
Entendemos las dificultades que pueden tener las compañías privadas si comparten datos puesto que compartir su información puede ser una ventaja para los competidores. Sin embargo, es esencial combinar datos del sector público y privado para impulsar el crecimiento del mercado de datos abiertos y que puedan dar lugar a nuevos análisis y estudios y el desarrollo de nuevos productos y servicios.
También es importante plantear la reutilización de datos teniendo en cuenta los nuevos retos que van surgiendo en la sociedad y facilitar el desarrollo de soluciones sin tener que partir desde cero.
6. ¿Cuáles son los planes de futuro de Google en relación con los datos abiertos?
Los datos confidenciales de las empresas tienen unos altos requisitos de supervivencia, en caso de que un proveedor tenga que cancelar los servicios en la nube debido a cambios en las políticas de un país o región, y creemos que no es posible asegurar los datos con una solución patentada. Sin embargo, sí contamos con herramientas de código y estándares abiertos que dan respuesta a las múltiples preocupaciones de los clientes.
Herramientas para analizar datos como son BigQuery o BigQuery Omni, permiten a los clientes hacer que sus propios datos sean más abiertos, tanto dentro como fuera de su organización. Así se puede aprovechar el potencial de esos datos de forma segura y eficiente en costes. Ya contamos con claros casos de uso de valor creados con nuestra tecnología de data e inteligencia artificial, y avalados por el CDTI, como es el caso del modelo de prevención de abandono escolar Student Success data . Instituciones educativas referentes ya lo utilizan a día y está en fase pilotaje en algunas consejerías de educación.
El objetivo de la compañía es seguir trabajando para construir una nube abierta de la mano de nuestros socios locales y las instituciones públicas en España y en toda Europa, creando un ecosistema europeo de datos digitales seguro de la mano de la mejor tecnología.
Noticia
¡Cómo pasa el tiempo! Parece que fue ayer cuando, por estas fechas, escribíamos nuestra carta a Papá Noel y a los Reyes Magos pidiéndoles nuestros más sinceros deseos. Un año más, la Navidad ya está aquí para recordarnos la magia de los reencuentros con nuestros seres queridos, pero también son días perfectos para disfrutar y descansar.
Para muchos, dentro de esa felicidad navideña se encuentra la pasión por la lectura. ¿Qué mejor época para disfrutar de un buen libro que estos días de invierno bajo el cobijo del calor del hogar? Novelas, comics, ensayos... pero también guías o libros teóricos que te puedan ayudar a ampliar conocimientos ligados a tu ámbito laboral. Por ello, como cada año, hemos preguntado a nuestros pajes -los colaboradores de datos.gob.es- las mejores recomendaciones sobre libros relacionados con los datos y la tecnología para ofrecerte algunas ideas que podrás incluir en tu carta este año, si te has portado bien.
Telling your Data Story: Data Storytelling for Data Management, Scott Taylor (The Data Whisperer)
¿De qué trata? El autor de este libro nos ofrece una práctica guía para explicar y hacernos comprender el valor estratégico de la gestión de datos dentro del ámbito empresarial.
¿A quién va dirigido? Está enfocado a profesionales en activo interesados en mejorar sus habilidades tanto a la hora de gestionar y llevar a cabo el plan de datos de una empresa, como de manejar herramientas para poder explicar con claridad sus actuaciones a terceros. También se encuentra entre su púbico objetivo los científicos de datos interesados en acercar esta disciplina al sector de la empresa.
Idioma: Inglés
The art of statistics: Learning from data, David Spiegelhalter
¿De qué trata? Este libro muestra a los lectores cómo derivar conocimiento a partir de datos en bruto y conceptos matemáticos. A través de ejemplos del mundo real, el autor nos cuenta cómo los datos y la estadística pueden ayudarnos a resolver diferentes problemas, como por ejemplo determinar el pasajero más afortunado del Titanic o si un asesino en serie podría haber sido capturado antes, entre otros.
¿A quién va dirigido? Si te apasiona el mundo de la estadística y los datos curiosos, este libro es para ti. Su lectura amena y llena de ejemplos extraídos del mundo que nos rodea hace de este libro una interesante idea para incluir en tu carta a los Reyes Magos este año.
Idioma: Inglés
Big Data. Conceptos, tecnologías y aplicaciones, David Ríos Insúa y David Gómez Ullate Oteiza
¿De qué trata?: Este nuevo libro del CSIC acerca a sus lectores al big data y sus aplicaciones en política, sanidad y ciberseguridad. Sus autores, David Ríos y David Gómez-Ullate describen la tecnología y los métodos usados por la ciencia de datos, explicando su potencial en diversos ámbitos.
¿A quién va dirigido?: Toda aquella persona con interés en ampliar sus conocimientos sobre la actualidad científica y tecnológica tendrá en este libro una opción más que interesante para hacerlo. Sus explicaciones sencillas y accesibles hacen de este manual un texto ameno y amigable para todo tipo de lectores.
Idioma: Español
Data Analytics with R: A Recipe book, Ryan Garnett
¿De qué trata? ¡Como si fuera un libro de recetas! Así plantea Ryan Garnet este libro dedicado a explicar de una forma amena y muy práctica a los lectores el análisis de datos que se centran en el lenguaje R.
¿A quién va dirigido? Este libro es una opción de gran interés tanto para programadores como para aficionados al análisis de datos que quieran descubrir más sobre R. Su estructura en forma de recetas para explicar este campo hace que sea sencillo de entender. Además, puedes descargarlo gratuitamente.
Idioma: Inglés
Datanomics, Paloma Llaneza
¿De qué trata?: Este libro nos revela con datos, informes y hechos comprobados lo que las empresas de tecnología hacen, realmente, con los datos personales que cedemos y cómo le sacan rentabilidad.
¿A quién va dirigido?: Se trata de un documento de gran interés para toda la ciudadanía. El hecho de que la información que contiene venga reforzada con informes de apoyo, hace más ligera y amena la lectura.
Idioma: Español
Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us about Who We Really Are, Seth Stephens-Davidowitz
¿De qué trata? ¿Sabías que los usuarios que navegamos en Internet exponemos un total de 8 billones de gigabytes de datos cada día? El autor nos muestra en este libro cómo los datos que ofrecemos sobre nuestras búsquedas revelan nuestros miedos, deseos y comportamientos, pero también los prejuicios conscientes e inconscientes.
¿A quién va dirigido? Este libro está dirigido a todas aquellas personas que buscan ampliar su conocimiento acerca de cómo nos expresamos en la era digital. Si te gustaría dar respuestas a cuestiones como si el lugar al que vamos a la escuela puede influir en nuestro éxito futuro, este libro es para ti.
Idioma: Inglés
Al igual que en años anteriores, esta lista es tan solo una pequeña selección que hemos elaborado en función de las recomendaciones que nos han sugerido algunos de los expertos que colaboran en datos.gob.es, así como parte de los miembros que conformamos este equipo. Sin duda, el mundo está lleno de libros sobre datos y tecnología realmente interesantes.
¿Conoces alguno más que no deberíamos olvidarnos en nuestra carta a los Reyes Magos? Déjanos un comentario o envíanos un correo electrónico a dinamizacion@datos.gob.es, ¡estaremos encantados de leerte!
Entrevista
Los datos abiertos no son solo cosa de las Administraciones públicas, cada vez más empresas también apuestan por ellos. Es el caso de Microsoft, quien ha proporcionado acceso a datos abiertos seleccionados en Azure pensados para el entrenamiento de modelos de Machine Learning. También colabora en el desarrollo de múltiples proyectos con el fin de impulsar el open data. En España, ha colaborado en el desarrollo de la plataforma HealthData 29, destinada a la publicación de datos en abierto para impulsar la investigación médica.
Hemos entrevistado a Belén Gancedo, Directora de Educación en Microsoft Ibérica y miembro del jurado en la III edición del Desafío Aporta, centrado en el valor de los datos para el sector educativo. Nos hemos reunido con ella para que nos hable de la importancia de la educación digital y de las soluciones innovadoras basadas en datos, así como de la importancia de los datos abiertos en el sector empresarial.
Entrevista completa:
1. ¿Qué retos del sector educativo, a los que urge dar respuesta, ha puesto de manifiesto la pandemia en España?
La tecnología se ha convertido en elemento imprescindible en la nueva forma de aprender y enseñar. Durante los últimos meses, marcados por la pandemia, hemos visto cómo se ha pasado en muy poco tiempo a un modelo de educación híbrido -presencial y en remoto-. Hemos visto ejemplos de centros que, en tiempo récord, en menos de 2 semanas, han tenido que acelerar los planes de digitalización que ya tenían en mente.
La tecnología ha pasado de ser un salvavidas temporal, que permitió dar clases en la peor etapa de la pandemia, a convertirse en una parte totalmente integrada de la metodología de enseñanza de muchos centros educativos. Según una encuesta reciente de YouGov encargada por Microsoft, el 71% de los educadores de Primaria y Secundaria señala que la tecnología les ha ayudado a mejorar su metodología y ha mejorado su capacidad de enseñar. Asimismo, el 82% del profesorado señala que, este último año, se ha acelerado el ritmo al que la tecnología ha impulsado la innovación en la enseñanza y el aprendizaje.
Antes de esta pandemia, de alguna forma, quienes veníamos dedicándonos a la educación, éramos quienes defendíamos la necesidad de transformar digitalmente el sector y los beneficios que la tecnología introducía en él. Sin embargo, lo vivido ha servido para que todo mundo sea consciente de los beneficios de la aplicación de la tecnología en el entorno educativo. En ese sentido ha habido un enorme avance. Nosotros hemos observado un gran incremento en el uso de nuestra herramienta Teams, que ya usan más de 200 millones de estudiantes, profesores y personal del sector educativo en todo el mundo.
Los mayores retos, pues, actualmente, son conseguir no sólo aprovechar los datos y la Inteligencia Artificial para proporcionar experiencias más personalizadas y operar con mayor agilidad sino también la integración de la tecnología con la pedagogía, lo que permitirá experiencias de aprendizaje más flexibles, atractivas e inclusivas. Los estudiantes son cada vez más diversos, y también lo son sus expectativas sobre el papel de la educación universitaria en su camino hacia el empleo.
Los mayores retos, pues, actualmente, son conseguir no sólo aprovechar los datos y la Inteligencia Artificial para proporcionar experiencias más personalizadas y operar con mayor agilidad sino también la integración de la tecnología con la pedagogía, lo que permitirá experiencias de aprendizaje más flexibles, atractivas e inclusivas
2. Cada vez hay más demanda de capacidades y competencias digitales relacionadas con los datos. En este sentido, se ha lanzado el Plan Nacional de Competencias Digitales, donde se incluye la digitalización de la educación y el desarrollo de las competencias digitales para el aprendizaje. ¿Qué cambios habría que hacer en los programas educativos de cara a impulsar la adquisición de conocimientos digitales por parte de los alumnos?
Sin duda, uno de los mayores retos a los que nos enfrentamos en la actualidad es la falta de capacitación y habilidades digitales. Según un estudio llevado a cabo por Microsoft y EY, el 57% de las compañías encuestadas esperan que la IA tenga un alto o muy alto impacto en las áreas de negocios que son “totalmente desconocidas para las compañías en la actualidad”.
Hay una clara oportunidad para que España lidere en Europa en talento digital, consolidándose como uno de los países más atractivos para atraer y retener este talento. Un reciente estudio de LinkedIn anticipa que en los próximos cinco años se crearán en España dos millones de puestos de trabajo relacionados con la tecnología, no sólo en la industria tecnológica, sino también, y sobre todo, en empresas de otros sectores de actividad que buscan incorporar el talento necesario para llevar a cabo su transformación. Sin embargo, hay un déficit de profesionales con habilidades y formación en competencias digitales. De acuerdo con los datos del Digital Economy and Society Index Report que publica anualmente la Comisión Europea, España se encuentra por debajo de la media europea en la mayoría de los indicadores que hacen referencia a las competencias digitales de los profesionales españoles.
Existe, por tanto, una demanda urgente de formar talento cualificado con capacidades digitales, gestión del dato, IA, machine learning… Los perfiles relacionados con la tecnología se encuentran entre los más difíciles de encontrar y, en un futuro próximo, los relacionados con la analítica de datos, la computación en la nube y el desarrollo de aplicaciones.
Para ello, es necesaria una adecuada formación, ya no solo en la forma de enseñar, sino también en el contenido curricular. Cualquier carrera, ya no solo las del ámbito STEM, necesitaría incluir materias relacionadas con la tecnología y la IA, que será la que defina el futuro. El uso de la IA llega a cualquier ámbito, no solo al tecnológico, por lo tanto, el alumnado de cualquier tipo de carrera -Derecho, Periodismo…- por poner algunos ejemplos de carreras no STEM, necesita formación cualificada en tecnología como la IA o la ciencia de datos, puesto que lo van a tener que aplicar en su futuro profesional.
Debemos apostar por las colaboraciones público-privadas e involucrar a la industria tecnológica, las administraciones públicas, la comunidad educativa, adecuando los contenidos curriculares de la Universidad a la realidad laboral- y las entidades del tercer sector, con el objetivo de impulsar la empleabilidad y el reciclaje profesional. De esta forma, se impulsará la capacitación de los profesionales en áreas como computación cuántica, Inteligencia Artificial, o analítica de datos y podremos aspirar al liderazgo digital.
En los próximos cinco años se crearán en España dos millones de puestos de trabajo relacionados con la tecnología, no sólo en la industria tecnológica, sino también, y sobre todo, en empresas de otros sectores de actividad que buscan incorporar el talento necesario para llevar a cabo su transformación.
3. Todavía hoy encontramos disparidad entre el número de hombre y mujeres que eligen ramas profesionales relacionadas con la tecnología. ¿Qué se necesita para impulsar el papel de la mujer en el ámbito tecnológico?
Según el Observatorio Nacional de Telecomunicaciones y Sociedad de la Información -ONTSI- (julio 2020), la brecha digital de género se ha reducido progresivamente en España, pasando de 8,1 a 1 punto, aunque las mujeres mantienen una posición desfavorable en competencias digitales y usos de Internet. En competencias avanzadas, como programación, la brecha en España es de 6,8 puntos, siendo la media de la UE de 8 puntos. El porcentaje de investigadoras en el sector de servicios TIC se reduce al 23,4%. Y en cuanto al porcentaje de graduados/as en STEM, España se sitúa en la posición 12 dentro de la UE, con una diferencia entre sexos de 17 puntos.
Sin duda, queda mucho camino por recorrer. Una de las principales barreras con las que se encuentran las mujeres en el sector de la tecnología y a la hora de emprender son los estereotipos y la tradición cultural. El entorno masculinizado de las carreras técnicas y los estereotipos sobre quienes se dedican a la tecnología las convierte en carreras poco atractivas para las mujeres.
La digitalización está dinamizando la economía y favoreciendo la competitividad empresarial, así como generando un incremento en la creación de empleo especializado. Quizá lo más interesante del impacto de la digitalización en el mercado laboral es que estos nuevos puestos de trabajo no se están creando sólo en la industria tecnológica, sino también en empresas de todos los sectores, que necesitan incorporar talento especializado y con habilidades digitales.
Por lo tanto, existe una demanda urgente de formar talento cualificado con capacidades digitales y este talento debe ser diverso. La mujer no puede quedar atrás. Es el momento de atajar la desigualdad de género, y alertar de esta enorme oportunidad a todos, con independencia de su género. Las carreras STEM son una opción ideal de futuro para cualquier persona, independientemente de su género.
Para favorecer la presencia femenina en el sector tecnológico, en pro de una era digital sin exclusión, en Microsoft hemos puesto en marcha diferentes iniciativas que buscan desterrar estereotipos y animar a las niñas y jóvenes a interesarse por la ciencia y la tecnología y hacerlas ver que ellas también pueden ser las protagonistas de la sociedad digital. Además de los Premios WONNOW que convocamos con CaixaBank, también participamos y colaboramos en muchas iniciativas, como los Premios Ada Byron junto a Universidad de Deusto, para ayudar a dar visibilidad al trabajo de mujeres en el ámbito STEM, para que sean referentes de las que están por venir.
La brecha digital de género se ha reducido progresivamente en España, pasando de 8,1 a 1 punto, aunque las mujeres mantienen una posición desfavorable en competencias digitales y usos de Internet. En competencias avanzadas, como programación, la brecha en España es de 6,8 puntos, siendo la media de la UE de 8 puntos
4. ¿Cómo pueden iniciativas como los hackathons, desafío o retos ayudar a impulsar la innovación basada en datos? ¿Cómo ha sido su experiencia en el III Desafío Aporta?
Este tipo de iniciativas son clave para ese cambio tan necesario. En Microsoft estamos constantemente organizando hackathons tanto a escala global, como regional y local, para innovar en distintas áreas prioritarias para la compañía como, por ejemplo, la educación.
Pero vamos más allá. También usamos estas herramientas en clase. Una de las apuestas de Microsoft son los proyectos Hacking STEM. Se trata de proyectos en los que se mezcla el concepto “maker” de aprender haciendo con la programación y la robótica, mediante el uso de materiales cotidianos. Además, están integrados por actividades que permiten a los docentes guiar a sus alumnos para construir y crear instrumentos científicos y herramientas basadas en proyectos para visualizar datos a través de la ciencia, la tecnología, la ingeniería y las matemáticas. Nuestros proyectos -tanto de Hacking STEM como de codificación y lenguaje computacional mediante el uso de herramientas gratuitas como Make Code- pretenden llevar la programación y la robótica a cualquier asignatura de forma transversal, y por qué no, aprender programación en una clase de latín o en una de biología.
Mi experiencia en el III Desafío Aporta ha sido fantástica porque me ha permitido conocer ideas y proyectos increíbles donde se hace realidad la utilidad de la cantidad de datos disponibles y se ponen al servicio de la mejora de la educación de todos. Ha habido muchísima participación y, además, con presentaciones muy cuidadas y trabajadas. La verdad es que me gustaría aprovechar esta oportunidad para dar las gracias a todos los que han participado y también dar la enhorabuena a los ganadores.
5. Hace un año Microsoft lanzó una campaña para impulsar la apertura de datos de cara a cerrar la brecha entre los países y empresas que tienen los datos necesarios para innovar y aquellos que no. ¿En qué ha consistido el proyecto? ¿Qué avances se han logrado?
La iniciativa global de Microsoft Open Data Campaign busca contribuir a cerrar la creciente “brecha de datos” entre el pequeño número de empresas tecnológicas que más se benefician de la economía de los datos en la actualidad y otras organizaciones que se ven obstaculizadas por la falta de acceso a ellos o por no tener capacidades para utilizar los que ya tienen.
Microsoft cree que se debe hacer más para ayudar a las organizaciones a compartir y colaborar en torno a los datos, de modo que las empresas y los gobiernos puedan utilizarlos para afrontar los retos que se les presentan, pues la capacidad de compartir datos conlleva enormes beneficios. Y no solo para el entorno empresarial, sino que también juegan un rol crítico a la hora de ayudarnos a entender y abordar grandes desafíos, como el cambio climático, o crisis sanitarias, como la pandemia COVID-19. Para aprovecharlos al máximo, es necesario desarrollar la capacidad de compartirlos de una forma segura y confiable, y permitir que puedan ser utilizados de manera efectiva.
Dentro de la iniciativa Open Data Campaign, Microsoft ha anunciado 5 grandes principios que guiarán cómo la propia compañía aborda la forma de compartir sus datos con otros:
- Abiertos – Trabajará para hacer que los datos relevantes sobre problemas sociales de gran envergadura se encuentren tan abiertos como sea posible.
- Utilizables– Invertirá en crear nuevas tecnologías y herramientas, mecanismos de gobernanza y políticas para que los datos puedan ser usados por todos.
- Impulsores – Microsoft ayudará a las organizaciones a generar valor a partir de sus datos y a desarrollar talento en IA para utilizarlos de manera efectiva.
- Seguros– Microsoft va a emplear controles de seguridad para garantizar que la colaboración en torno a datos sea segura a nivel operacional.
- Privados – Microsoft ayudará a las organizaciones a proteger la privacidad de los individuos en colaboraciones donde se compartan datos y que involucren información de identificación personal.
Seguimos avanzado en este sentido. El año pasado, Microsoft España, junto a Fundación 29, la Cátedra sobre la Privacidad y Transformación Digital Microsoft-Universitat de València y con el asesoramiento legal del despacho de abogados J&A Garrigues han creado la Guía “Health Data” que describe el marco técnico y legal para llevar a cabo la creación de un repositorio público de datos de los sistemas de Salud, y que estos puedan compartirse y utilizarse en entornos de investigación. Y LaLiga es una de las entidades que ha compartido, en junio de este año, sus datos anonimizados.
El Dato es el principio de todo. Y una de nuestras mayores responsabilidades como empresa de tecnología es ayudar a la conservación del ecosistema a gran escala, a nivel planetario. Para ello el mayor reto es consolidar no solo todos los datos disponibles, sino los algoritmos de inteligencia artificial que permitan acceder a ello y permitan tomar decisiones, crear modelos predictivos, escenarios con información actualizada desde múltiples fuentes. Por eso, Microsoft lanzó el concepto de Planetary Computer, basado en Open Data, para poner a disposición de científicos, biólogos, startups y empresas, de forma gratuita, más de 10 Petabytes de datos -y creciendo- de múltiples fuentes (biodiversidad, electrificación, forestación, biomasa, satélite), APIs, Entornos de Desarrollo y aplicaciones (modelo predictivo, etc.) para crear un mayor impacto para el planeta.
La iniciativa global de Microsoft Open Data Campaign busca contribuir a cerrar la creciente “brecha de datos” entre el pequeño número de empresas tecnológicas que más se benefician de la economía de los datos en la actualidad y otras organizaciones que se ven obstaculizadas por la falta de acceso a ellos o por no tener capacidades para utilizar los que ya tienen.
6. También ofrecen algunos conjuntos de datos en abierto a través de su iniciativa Azure Open Datasets. ¿Qué tipo de datos ofrecen? ¿Cómo los pueden utilizar los usuarios?
Esta iniciativa busca que las empresas mejoren la precisión de las predicciones de sus modelos de Machine Learning y reduzcan el tiempo de preparación de los datos, gracias a conjuntos de datos seleccionados de acceso público, listos para usar y a los que se puede acceder fácilmente desde los servicios de Azure.
Hay datos de todo tipo: salud y genómica, transporte, mano de obra y economía, población y seguridad, datos comunes… que se pueden utilizar de múltiples maneras. Y también es posible aportar datasets a la comunidad.
7. ¿Cuáles son los planes de futuro de Microsoft en relación con los datos abiertos?
Tras un año con la Opendata campaign, hemos tenido muchos aprendizajes y, en colaboración con nuestros partners, vamos a enfocarnos el próximo año a aspectos prácticos que hagan el proceso de la compartición de datos más sencilla. Acabamos de empezar a publicar materiales para que las organizaciones vean los aspectos prácticos de cómo empezar a compartir datos. Continuaremos identificando posibles colaboraciones para solventar retos sociales en temas de sostenibilidad, salud, equidad e inclusión. También queremos conectar a aquellos que están trabajando con datos o quieren explorar ese ámbito con las oportunidades que ofrecen las Certificaciones de Microsoft en Data e Inteligencia Artificial. Y, sobre todo, este tema requiere de un buen marco regulatorio y, para ello, es necesario que quienes definen las políticas se reúnan con la industria, la academia y la sociedad civil para desarrollar incentivos, infraestructuras y mecanismos que permitan compartir datos del sector público y privado -dentro y a través de fronteras organizacionales y nacionales,- siempre salvaguardando los derechos humanos, con el fin de hacer un uso efectivo de dichos datos en pro de la innovación.
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
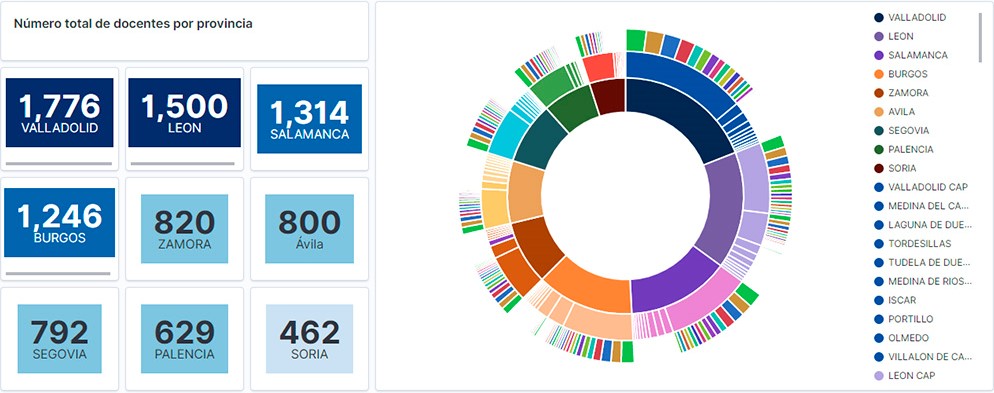
Visualización del personal docente de Castilla y León clasificados por Provincia, Localidad y Especialidad docente
2. Objetivos
El objetivo principal de este post es aprender a tratar un conjunto de datos desde su descarga hasta la creación de uno o varios gráficos interactivos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre los docentes y alumnos matriculados en los centros públicos de Castilla y León durante el año académico 2019-2020. A partir de estos datos se realizan análisis de varios indicadores que relacionan docentes, especialidades y alumnado matriculado en los centros de cada provincia o localidad de la comunidad autónoma.
3. Recursos
3.1. Conjuntos de datos
Para este estudio se han seleccionado conjuntos de datos de la temática Educación publicados por la Junta de Castilla y León, disponibles en el portal de datos abiertos datos.gob.es. Concretamente:
- Dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros, durante el curso académico 2019-2020. Este dataset se encuentra desagregado por especialidad del docente, centro educativo, localidad y provincia.
- Dataset de las matriculaciones de alumnos en centros educativos durante el curso académico 2019-2020. Este conjunto de datos se obtiene a través de una consulta que admite diferentes parámetros de configuración. Las instrucciones para realizarla se encuentran disponibles en el mismo punto de descarga del dataset. El conjunto de datos se encuentra desagregado por centro educativo, localidad y provincia.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado el lenguaje de programación Python (versión 3.7) y JupyterLab (versión 2.2), herramientas que encontrarás integradas en Anaconda, una de las plataformas más populares para instalar, actualizar o administrar software para trabajar con Data Science. Todas estas herramientas son abiertas y están disponibles de forma gratuita.
JupyterLab es una interfaz de usuario basada en web que proporciona un entorno de desarrollo interactivo donde el usuario puede trabajar con los denominados cuadernos Jupyter sobre los que podrás integrar y compartir fácilmente texto, código fuente y datos.
Para la creación de la visualización interactiva se ha usado la herramienta de Kibana (versión 7.10).
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Logstash, Beats y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres conocer más sobre estas herramientas u otras que pueden ayudarte en el tratamiento y la visualización de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son consistentes y confiables.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas! Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de Github. La forma de proporcionar el código es a través de un documento realizado sobre JupyterLab que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla.
4.1. Instalación y carga de librerías
Lo primero que debemos hacer es importar las librerías para el pre-procesamiento de los datos. Hay muchas librerías disponibles en Python pero una de las más populares y adecuada para trabajar con estos conjuntos de datos es Pandas. La librería Pandas es una librería muy popular para manipular y analizar conjuntos de datos.
import pandas as pd 4.2. Carga de datasets
En primer lugar descargamos los conjuntos de datos del catálogo de datos abiertos datos.gob.es y los cargamos en nuestro entorno de desarrollo como tablas para explorarlos y realizar algunas tareas básicas de limpieza y procesado de datos. Para la carga de los datos recurriremos a la función read_csv(), donde le indicaremos la url de descarga del dataset, el delimitador (\";\" en este caso) y, para que interprete correctamente los caracteres especiales como las letras con tildes o \"ñ\" presentes en las cadenas de texto del conjunto de datos, le añadimos el parámetro \"encoding\" que ajustamos al valor \"latin-1\".
#Cargamos el dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros url = \"https://datosabiertos.jcyl.es/web/jcyl/risp/es/educacion/plantillas-centros-educativos/1284922684978.csv\"docentes = pd.read_csv(url, delimiter=\";\", header=0, encoding=\"latin-1\")docentes.head(3)#Cargamos el dataset de los alumnos matriculados en los centros educativos públicos de Castilla y León alumnos = pd.read_csv(\"matriculaciones.csv\", delimiter=\",\", names=[\"Municipio\", \"Matriculaciones\"], encoding=\"latin-1\") alumnos.head(3)La columna \"Municipio\" de la tabla \"alumnos\" está compuesta por el código del municipio y el nombre del mismo. Debemos dividir esta columna en dos, para que su tratamiento sea más eficiente.
columnas_Municipios = alumnos[\"Municipio\"].str.split(\" \", n=1, expand = TRUE)alumnos[\"Codigo_Municipio\"] = columnas_Municipios[0]alumnos[\"Nombre_Munipicio\"] = columnas_Munipicio[1]alumnos.head(3)4.3. Creación de una nueva tabla
Una vez que tenemos ambas tablas con las variables de interés, creamos una nueva tabla resultado de su unión. La variables de unión serán: \"Localidad\" en la tabla de \"docentes\" y \"Nombre_Municipio\" en la de \"alumnos\".
docentes_alumnos = pd.merge(docentes, alumnos, left_on = \"Localidad\", right_on = \"Nombre_Municipio\")docentes_alumnos.head(3)4.4. Exploración del conjunto de datos
Una vez que disponemos de la tabla que nos interesa, debemos dedicar un tiempo a explorar los datos e interpretar cada variable. En estos casos es de enorme utilidad disponer del diccionario de datos que siempre debe acompañar a cada dataset descargado para conocer todos sus detalles, pero en esta ocasión no disponemos de esta esencial herramienta. Observando la tabla, además de interpretar las variables que lo integran (tipos de datos, unidades, rangos de valores), podemos detectar posibles errores como variables mal tipificadas o la presencia de valores perdidos (NAs) que pueden restar capacidad de análisis.
docentes_alumnos.info()En la salida de esta sección de código, podemos observar las principales características que presenta la tabla:
- Contiene un total de 4.512 registros
- Está compuesto de 13 variables, 5 variables numéricas (de tipo entero) y 8 variables de tipo categórico (tipo \"object\")
- No hay ausencia de valores.
Una vez que conocemos la estructura y contenido de la tabla, debemos rectificar errores, como es el caso de la transformación de algunas de las variables que no están tipificadas de manera adecuada, por ejemplo, la variable que alberga el código del centro (\"Código.centro\").
docentes_alumnos.Codigo_centro = data.Codigo_centro.astype(\"object\")docentes_alumnos.Codigo_cuerpo = data.Codigo_cuerpo.astype(\"object\")docentes_alumnos.Codigo_especialidad = data.Codigo_especialidad.astype(\"object\")Una vez que tenemos la tabla libre de errores, obtenemos una descripción de las variables numéricas, \"Plantilla\" y \"Matriculaciones\", que nos ayudará a conocer detalles importantes. En la salida del código que presentamos a continuación observamos la media, la desviación estándar, el número máximo y mínimo, entre otros descriptores estadísticos.
docentes_alumnos.describe()4.5. Guardar el dataset
Una vez que tenemos la tabla libre de errores y con las variables que nos interesa graficar, lo guardaremos en una carpeta de nuestra elección para usarla posteriormente en otras herramientas de análisis o visualización. Lo guardaremos en formato CSV codificada como UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta que usemos posteriormente.
df = pd.DataFrame(docentes_alumnos)filname = \"docentes_alumnos.csv\"df.to_csv(filename, index = FALSE, encoding = \"utf-8\")5. Creación de la visualización sobre los docentes de los centro educativos públicos de Castilla y León usando la herramienta Kibana
Para la realización de esta visualización hemos usado la herramienta Kibana en nuestro entorno local. Para realizarla es necesario tener instalado y en funcionamiento Elasticsearch y Kibana. La compañía Elastic nos pone a disposición toda la información sobre la descarga e instalación en este tutorial.
A continuación se adjuntan dos vídeo tutoriales, donde se muestra el proceso de realización de la visualización y la interacción con el dashboad generado.
En este primer vídeo, podrás ver la creación del cuadro de mando (dashboard) mediante la generación de diferentes representaciones gráficas, siguiendo los siguientes pasos:
- Cargamos la tabla de datos previamente procesados en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
- Gráfico de sectores donde mostrar la plantilla docente por provincia, localidad y especialidad.
- Métricas del número de docentes por provincia.
- Gráfico de barras, donde mostraremos el número de matriculaciones por provincia.
- Filtro por provincia, localidad y especialidad docente.
- Construcción del dashboard.
En este segundo vídeo, podrás observa la interacción con el cuadro de mando (dashboard) generado anteriormente.
6. Conclusiones
Observando la visualización de los datos sobre el número de docentes de los centros educativos públicos de Castilla y León, en el curso académico 2019-2020, se pueden obtener, entre otras, las siguientes conclusiones:
- La provincia de Valladolid es la que posee el mayor número de docentes e igualmente, el mayor número de alumnos matriculados. Mientras que Soria es la provincia con menor número de docentes y menor número de alumnos matriculados.
- Como era de esperar, las localidades que presentan mayor número de docentes son las capitales de provincia.
- En todas las provincias, la especialidad con mayor número de alumnos es Inglés, seguida de Lengua Castellana y Literatura y Matemáticas.
- Llama la atención, que la provincia de Zamora, aunque posee un número bajo de alumnos matriculados, está en quinta posición en el número de docentes.
Esta sencilla visualización nos ha ayudado a sintetizar una gran cantidad de información y a obtener una serie de conclusiones a golpe de vista, y si fuera necesario tomar decisiones en función de los resultados obtenidos. Esperamos que os haya resultado útil este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!