Noticia
Un síntoma que refleja la madurez de un ecosistema de datos abiertos es la posibilidad de encontrar conjuntos de datos y casos de uso relativos a diferentes sectores de actividad. Así lo considera el propio Portal de Datos Abiertos Europeo en su índice de madurez. La clasificación de los datos y de sus usos por categorías temáticas impulsa la reutilización, ya que permite a los usuarios localizar y acceder a estos de forma más específica. Además, permite detectar necesidades en áreas concretas, identificar sectores prioritarios y estimar más fácilmente el impacto.
En España encontramos distintos repositorios temáticos, como UniversiData, en el caso de la educación superior, o TURESPAÑA, para el sector turístico. Sin embargo, el hecho de que las competencias de determinadas materias estén distribuidas por las Comunidades Autónomas o Ayuntamientos complica la localización de datos de una misma temática.
Datos.gob.es reúne los datos abiertos de todos los organismos públicos españoles que hayan llevado a cabo un proceso de federación con el portal. Por ello en nuestro catálogo puedes encontrar conjuntos de datos de distintos publicadores segmentados por 22 categorías temáticas, las consideradas por la Norma Técnica de Interoperabilidad.

Número de conjuntos de datos por categoría a fecha de junio 2021
Pero además de mostrar los conjuntos de datos divididos por temática también es importante mostrar datasets destacados, casos de uso, guías y demás recursos de ayuda por sector, de tal forma que los usuarios puedan acceder más fácilmente a los contenidos relacionados con sus áreas de interés. Por ello, en datos.gob.es hemos puesto en marcha una serie de apartados web centrados en distintos sectores de actividad, con contenidos específicos para cada área.
4 sectoriales que se irán ampliando a otras áreas de interés
Actualmente en datos.gob.es puedes encontrar 4 sectoriales: Medio ambiente, Cultura y ocio, Educación y Transporte. Estos sectores se han destacado por diferentes motivos estratégicos:
- Medio ambiente: Los datos de medio ambiente son fundamentales para conocer cómo cambia nuestro entorno y poder así luchar contra el cambio climático, la contaminación y la deforestación. La propia Comisión Europea considera los datos de medio ambiente datos de alto valor en la Directiva 2019/1024. En datos.gob.es puedes localizar datos de calidad del aire, predicción meteorológica, escasez de agua, etc. Todos ellos fundamentales para impulsar soluciones que logren un mundo más sostenible.
- Transporte: En la Directiva 2019/1024 también se destaca la importancia de los datos de transporte. Muchas veces en tiempo real, estos datos facilitan la toma de decisiones encaminadas a la gestión eficiente del servicio y la mejora de la experiencia de los viajeros. Los datos de transporte son de los más utilizados para crear servicios y aplicaciones (por ejemplo, aquellas que informan del estado de tráfico, los horarios de los autobuses, etc.). A esta categoría pertenecen datasets como las incidencias de tráfico en tiempo real o los precios de los carburantes.
- Educación: Con la llegada de la COVID-19, muchos alumnos tuvieron que seguir sus estudios desde sus hogares, a través de soluciones digitales que no siempre estaban preparadas. En los últimos meses, a través de iniciativas como el Desafío Aporta, se ha hecho un esfuerzo para impulsar la creación de soluciones que incorporen datos abiertos con el fin de mejorar la eficiencia del ámbito educativo, impulsar mejoras -como la personalización de la educación- y lograr un acceso más universal al conocimiento. Algunos de los datasets de educación que podemos encontrar en el catálogo son las titulaciones impartidas por las universidades españolas, o encuestas sobre el gasto de los hogares en educación.
- Cultura y ocio: Los datos de cultura y ocio son una categoría de gran importancia a la hora de reutilizarse para desarrollar, por ejemplo, contenidos educativos y de aprendizaje. Los datos culturales pueden ayudar a generar nuevo conocimiento que nos ayude a conocer nuestro pasado, presente y futuro. Algunos ejemplos de conjuntos de datos son la ubicación de monumentos o los listados de obras de arte.
Estructura de cada sector
Cada página de sector cuenta con una estructura homogénea, que facilita la localización de contenidos disponibles igualmente en otras secciones.
Empieza con un destacado donde se aprecian algunos ejemplos de conjuntos de datos destacados pertenecientes a esta categoría, y un enlace para acceder a todos los datasets de esta temática en el catálogo.
Continua con noticias relacionadas con los datos y el sector en cuestión, que pueden abarcar desde eventos o información sobre iniciativas concretas (como Procomún en el ámbito de los datos educativos o el Pacto Verde en medio ambiente) hasta las últimas novedades a nivel estratégico y operativo.
Por último, encontramos tres secciones relacionadas con los casos de uso: innovación, empresas reutilizadoras y aplicaciones. En la primera se cuenta, a través de artículos, ejemplos de usos novedosos, muchas veces ligados a tecnologías disruptivas como la Inteligencia Artificial. En las dos últimas, hallamos fichas concretas de empresas y aplicaciones que utilizan datos abiertos de dicha categoría para generar un beneficio para la sociedad o la economía.
Sección de destacados en la home
Además de la creación de páginas sectoriales, en el último año, datos.gob.es también ha incorporado una sección de datasets destacados. El objetivo es dar una mayor visibilidad a aquellos conjuntos de datos que cumplen una serie de características: han sido los últimos en actualizarse, se encuentran en formato CSV o se puede acceder a ellos vía API o servicios web.

¿Qué otros sectoriales te gustaría destacar?
En los planes de datos.gob.es está el continuar aumentado el número de sectores a destacar. Por ello, te invitamos a dejar en comentarios cualquier propuesta que consideres adecuada.
Blog
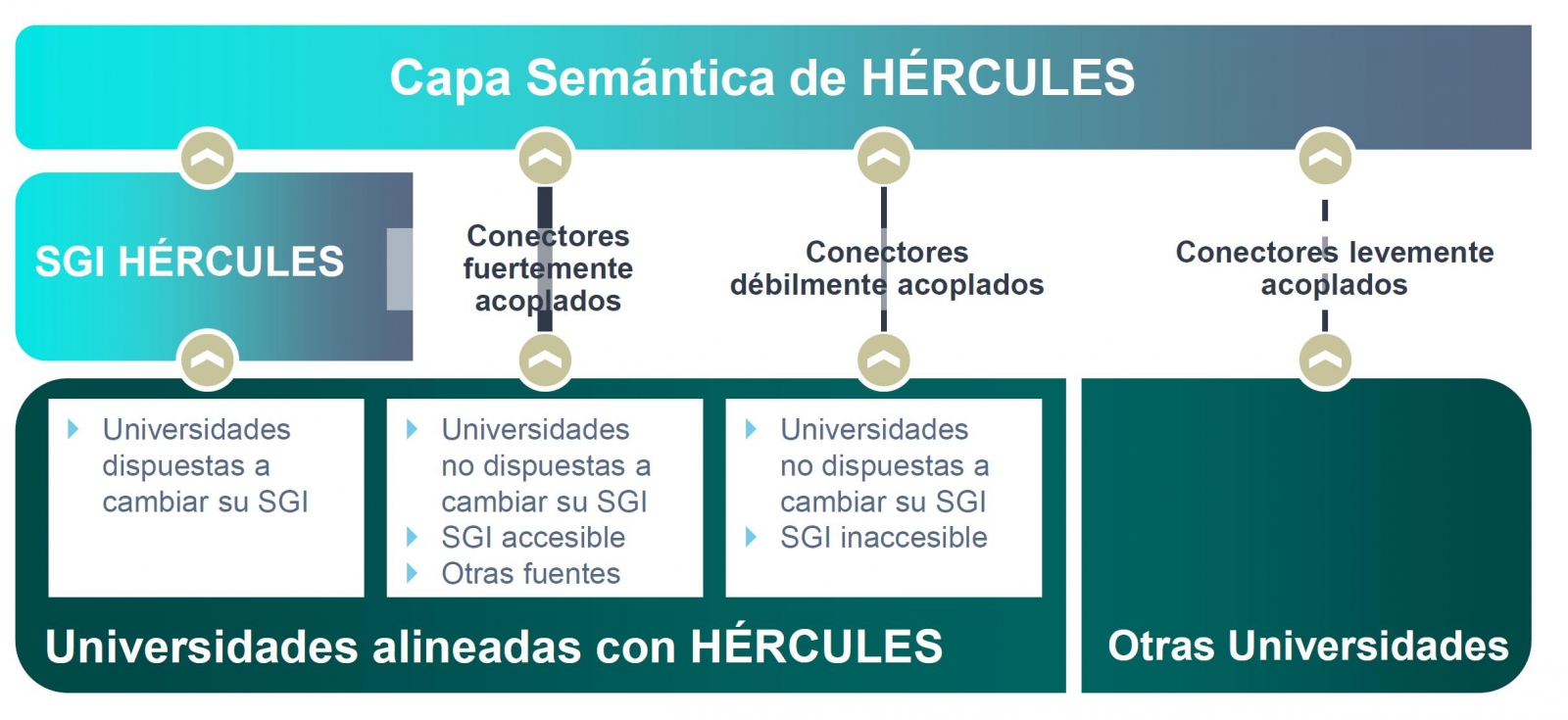
La iniciativa Hércules se inicia en noviembre de 2017, mediante un convenio entre la Universidad de Murcia y el Ministerio de Economía, Industria y Competitividad, con el objetivo de desarrollar un Sistema de Gestión de Investigación (SGI) basado en datos abiertos semánticos que ofrezca una visión global de los datos de investigación del Sistema Universitario Español (SUE), para mejorar la gestión, el análisis y las posibles sinergias entre universidades y el gran público.
Esta iniciativa es complementaria a UniversiDATA, donde varias universidades españolas colaboran para fomentar los datos abiertos en el sector de la educación superior mediante la publicación de conjuntos de datos a través de criterios estandarizados y comunes. En concreto se define un Núcleo Común con 42 especificaciones de datasets, de los cuales se han publicado 12 para la versión 1.0. Hércules, en cambio es una iniciativa específica del ámbito de investigación, estructurada en torno a tres pilares:
- Prototipo innovador de SGI
- Grafo unificado de conocimiento (ASIO) 1],
- Enriquecimiento de datos y análisis semántico (EDMA)
El objetivo final es la publicación de un grafo unificado de conocimiento donde queden integrados todos los datos de investigación que deseen hacer públicos las universidades participantes. Hércules prevé la integración de universidades a diferentes niveles, dependiendo de su disposición a reemplazar su SGI por el SGI de Hércules. En el caso de SGIs externos, el grado de accesibilidad que ofrezcan también tendrá implicación en el volumen de datos que puedan compartir a través del grafo unificado.
Organigrama general de la iniciativa Hércules
Dentro de la iniciativa Hércules, se integra el Proyecto ASIO (Arquitectura Semántica e Infraestructura Ontológica). El propósito de este sub-proyecto es definir una Red de Ontologías para la Gestión de la Investigación (Infraestructura Ontológica). Una ontología es una definición formal que describe con fidelidad y alta granularidad un dominio de discusión concreto. En este caso, el dominio de la investigación, que puede ser extrapolable a otras universidades españolas e internacionales (de momento el piloto se está desarrollando con la Universidad de Murcia). Es decir, se trata de crear un vocabulario de datos común.
Adicionalmente, a través del módulo de Arquitectura Semántica de Datos se ha desarrollado una plataforma eficiente para almacenar, gestionar y publicar datos de investigación del SUE, basándose en ontologías, con la capacidad de sincronizar instancias instaladas en diferentes universidades, así como la ejecución de consultas federadas distribuidas sobre aspectos clave de producción científica, líneas de investigación, búsqueda de sinergias, etc.
Como solución a este reto de innovación se han propuesto dos líneas complementarias, una centralizada (sincronización en escritura) y otra descentralizada (sincronización en consulta). En las próximas secciones se explica en detalle la arquitectura de la solución descentralizada.
Domain Driven Design
El modelo de datos sigue el enfoque Domain Driven Design, modelando entidades y vocabulario común, que pueda ser comprendido tanto por desarrolladores como expertos del dominio. Este modelo es independiente de la base de datos, del interfaz de usuario y del entorno de desarrollo, obteniendo una arquitectura de software limpia que permite adaptarse a los cambios del modelo.
Para ello se hace uso de Shape Expressions (ShEx), un lenguaje para validar y describir conjuntos de datos RDF, con sintaxis legible por humanos. A partir de estas expresiones se genera el modelo de dominio automáticamente y permite orquestar un proceso de integración continua (CI), tal y como se describe en la siguiente figura.
Proceso de integración continua mediante Domain Driven Design
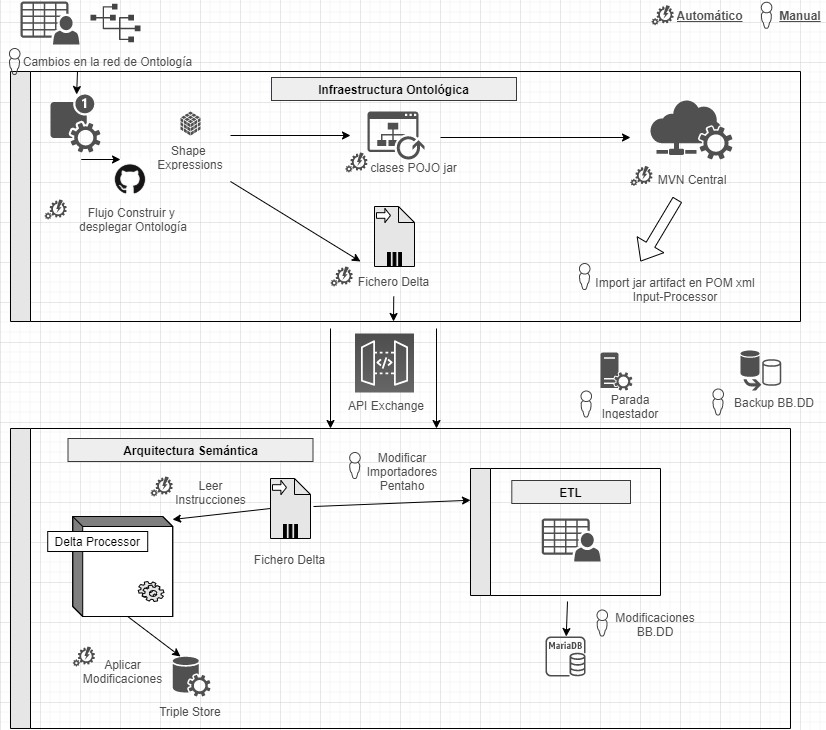
Mediante un sistema basado en de control de versiones como elemento central, se ofrece la posibilidad de que los expertos de dominio construyan y visualicen las ontologías multilingües. Estas a su vez se apoyan en ontologías tanto del ámbito de la investigación: VIVO, EuroCRIS/CERIF o Research Object, como ontologías de propósito general para la etiquetación de metadatos: Prov-O, DCAT, etc.
Linked Data Platform
El servidor de datos enlazados es el núcleo de la arquitectura, encargándose de renderizar la información sobre todas las entidades. Para ello recoge peticiones HTTP del exterior y las redirecciona a los servicios correspondientes, aplicando negociación de contenidos, la cual ofrece la mejor representación de un recurso basado en las preferencias del navegador para los distintos tipos de medios, idiomas, caracteres y codificación.
Todos los recursos se publican siguiendo un esquema de URIs persistentes diseñado a medida. Cada entidad representada mediante una URI (investigador, proyecto, universidad, etc) dispone de una serie de acciones para consultar y actualizar sus datos, siguiendo los patrones propuestos por Linked Data Platform (LDP) y el modelo de 5 estrellas.
Este sistema garantiza además el cumplimiento con los principios FAIR (Findable, Accesible, Interoperable, Reusable) y publica automáticamente los resultados de aplicar dichas métricas sobre el repositorio de datos.
Publicación de datos abiertos
El sistema de procesamiento de datos se encarga de la conversión, integración y validación de datos de terceras partes, así como la detección de duplicados, equivalencias y relaciones entre entidades. Los datos surgen de varias fuentes, principalmente el SGI unificado de Hércules, pero también de SGIs alternativos, o de otras fuentes que ofrecen datos en formato FECYT/CVN (Curriculum Vitae Normalizado), EuroCRIS/CERIF y otros posibles.
El sistema de importación convierte todas estas fuentes a formato RDF y los registra en un repositorio de propósito específico para datos enlazados, denominado Triple Store, por su capacidad para almacenar tripletas de tipo sujeto-predicado-objeto.
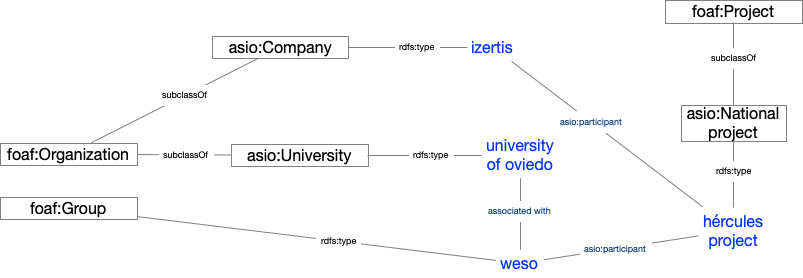
Una vez importados, se organizan formando un grafo de conocimiento, fácilmente accesible, permitiendo realizar inferencias y búsquedas avanzadas potenciadas por las relaciones entre conceptos.
Ejemplo de grafo de conocimiento describiendo el proyecto ASIO
Resultados y conclusiones
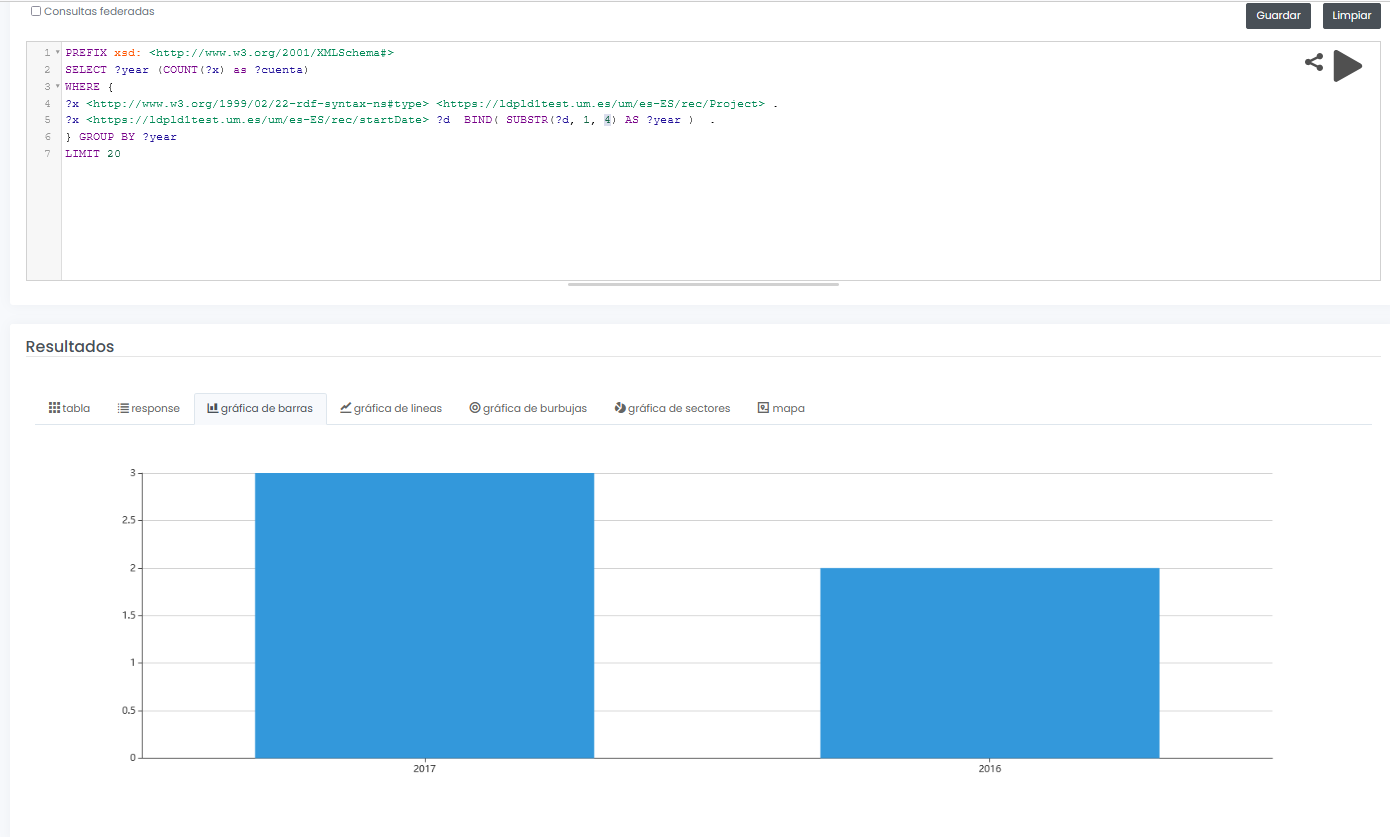
El sistema final no sólo permite ofrecer un interfaz gráfico para consulta interactiva y visual de datos de investigación, sino que además permite diseñar consultas SPARQL, como la que se muestra a continuación, incluso con la posibilidad de ejecutar la consulta de forma federada sobre todos los nodos de la red Hércules, y mostrar resultados de forma dinámica en diferentes tipos de gráficos y mapas.
En este ejemplo, se muestra una consulta (con datos limitados de prueba) de todos proyectos de investigación disponibles agrupados gráficamente por año:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
En definitiva, ASIO ofrece un marco común de publicación de datos abiertos enlazados, ofrecido como código libre y fácilmente adaptable a otros dominios. Para dicha adaptación, bastaría con diseñar un modelo de dominio específico, incluyendo la ontología y los procesos de importación y validación comentados en este artículo.
Actualmente el proyecto, en sus dos variantes (centralizada y descentralizada), se encuentra en proceso de puesta en pre-producción dentro de la infraestructura de la Universidad de Murcia, y en breve será accesible públicamente.
[1 Los grafos son una forma de representación del conocimiento que permiten relacionar conceptos a través de la integración de conjuntos de datos, utilizando técnicas de web semántica. De esta forma se puede conocer mejor el contexto de los datos, lo que facilita el descubrimiento de nuevo conocimiento.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Entrevista
Durante 2020 el sector de la educación se ha visto expuesto a grandes cambios debido a la pandemia mundial. Los hogares se transformaron en aulas, lo que supuso un reto para todos los implicados en el ecosistema educativo. La Fundación COTEC, una organización privada sin ánimo de lucro encargada de promover la innovación para el desarrollo económico y social, siguió muy de cerca esta situación. Ya en el mes de abril, publicaron el primer informe “COVID 19 Y EDUCACIÓN I: problemas, respuestas y escenarios”, donde se analizaban los retos educativos derivados de la emergencia sanitaria y se proponían diversos escenarios de actuación. Al que le siguieron luego “Covid-19 y Educación II: escuela en casa y desigualdad” y “Covid-19 y Educación II: escuela en casa y desigualdad”.
Hemos hablado con Ainara Zubillaga, Directora de Educación y Formación de la Fundación COTEC y coautora del informe, para analizar la situación del I+D español en general y que nos cuente cuál es la situación actual y la evolución que se espera que experimente nuestro sistema educativo en los próximos años gracias a la tecnología y los datos.
Entrevista completa
1. En marzo de 2020 los colegios cerraron prácticamente de un día para otro. ¿Qué retos sacó a relucir esta situación?
El cierre de las escuelas visibilizó las costuras del sistema educativo. No emergieron problemas que no existieran, pero sí puso la lupa en los déficits estructurales que ya existían, igual que ha acelerado tendencias que estaban llamando a la puerta.
El impacto del cierre de los centros educativos ha sido doble: educativo y social. Desde la perspectiva educativa ha puesto de manifiesto la sobrecarga que tiene nuestro currículum, un volumen de contenidos que no son capaces de ser abordados en condiciones normales, lo que complicó aún más el desarrollo en un escenario de educación en remoto. La digitalización ha sido el gran reto al que se han enfrentado los centros y el profesorado: desde falta de recursos (plataformas, aplicaciones, digitalización de materiales, etc.), hasta una escasa formación del profesorado que se ha visto obligado a migrar su actividad docente diaria a un formato y un canal que muchos desconocían cómo funciona y cómo aprovecharlo didácticamente.
Y desde la perspectiva social, el cierre de escuelas ha visibilizado la brecha educativa, que se ha mostrado al gran público a través de la brecha digital. No se reduce únicamente a ella, pero sí es lo que ha permitido a todos ver los problemas de equidad y de segregación educativa más allá de las aulas. Los datos son claros: es fundamentalmente el nivel socioeconómico, la variable que incide en las tres brecha digitales -de acceso, de uso y de centro-, por encima de comparativas con otros países o entre Comunidades Autónomas.
2. Al revisar las políticas educativas de las distintas CC.AA., ¿qué aspectos podrían ayudar a paliar las diferentes brechas detectadas y evitar además disparidades entre territorios?
La más evidente parece toda acción vinculada con la reducción de la brecha digital, pero en su sentido más amplio, es decir, no hablamos solo de dotación de dispositivos y garantía de conectividad, sino también de competencia digital y de aprovechamiento didáctico de las tecnologías.
Y el otro gran aspecto, sin duda, son todos los programas de refuerzo y apoyo escolar. Los primeros datos que empezamos a tener sobre el impacto del cierre de escuelas en términos de pérdida de aprendizaje, muestran claramente que hay una incidencia significativamente mayor sobre los alumnos más vulnerables. Las brechas que ya existían, por tanto, se están agrandando, y es necesario invertir la tendencia.
3. ¿En qué sentido pueden los datos abiertos impulsar mejoras en el sector educativo que ayuden a superar estos retos?
Los datos son un elemento fundamental para la transparencia y evaluación del funcionamiento del sistema educativo y de sus políticas. Sólo la evidencia sobre el grado de impacto y funcionamiento de las políticas públicas puede ayudarnos tanto a enfocar correctamente las inversiones, como a reforzar aquello que no funcione.
Por otro lado, los datos abiertos permiten a las diferentes Consejerías compartir información, compartir buenas prácticas, y, en definitiva, hacer más eficiente la administración pública y ponerla al servicio del ciudadano. El estudio COVID-19 Y EDUCACIÓN III: la respuesta de las Administraciones, que lanzamos desde Cotec el pasado diciembre, refleja entre sus conclusiones que es necesario un sistema de información más accesible, transparente, directo y coordinado que permita compartir, replicar y transmitir buenas prácticas dentro de la Administración educativa.
Los datos son un elemento fundamental para la transparencia y evaluación del funcionamiento del sistema educativo y de sus políticas, que permiten compartir información y buenas prácticas para hacer más eficiente la administración pública.
4. Forma parte del jurado del Desafío Aporta 2020, que este año se ha centrado en buscar soluciones basadas en datos que ayuden a solucionar retos del sistema educativo. ¿Nos puedes contar algo de las soluciones presentadas?
Las propuestas que se han presentado al concurso son un ejemplo de esas tendencias que se han acelerado y que comentaba anteriormente. Son claros ejemplos, en su mayoría, de soluciones orientadas a la personalización del aprendizaje, que sin duda es una de las líneas de desarrollo de la digitalización en educación, y así está recogida además en el programa Educa en Digital del propio Ministerio de Educación.
La personalización del proceso de aprendizaje es un ejemplo claro del valor añadido que aporta la tecnología a la educación: no sólo permite ajustar qué se enseña y cómo al alumno y sus necesidades, sino que, además, libera al docente de funciones rutinarias de seguimiento, permitiéndole enfocar en una atención más personalizada, especialmente en aquellos alumnos que precisan un mayor apoyo.
5. Acaban de poner en marcha el proyecto La escuela, lo primero, ¿qué nos puede contar de él?
"La escuela, lo primero" es un proyecto de innovación cuyo objetivo es ofrecer a la Administración, centros educativos, personal docente, y otras instituciones, las herramientas necesarias para afrontar los desafíos a los que se enfrenta el sistema educativo, los diferentes escenarios y situaciones – presenciales y a distancia – derivados de la pandemia de la Covid-19.
Arrancamos en julio, con la primera edición de los laboratorios de innovación docente, y hemos contado con la participación de más de 200 profesores de toda España, que han generado más de treinta propuestas, todas ellas soluciones innovadoras que incluyen juegos, guías, decálogos o recursos virtuales, válidas para ser aplicadas en cualquier centro escolar.
Las propuestas prácticas abordan, entre otros retos, la transferencia de metodologías activas al entorno virtual, la organización de tiempos y espacios de forma flexible, el fomento del trabajo colaborativo en remoto, impulsar la autonomía del alumno, reforzar las necesidades educativas especiales o fomentar la convivencia.
"La escuela, lo primero" es un proyecto de innovación que ofrece herramientas para afrontar los desafíos a los que se enfrenta el sistema educativo.
6. ¿Qué otros proyectos relacionados con el ámbito educativo han puesto en marcha o tienen pensado desarrollar?
Seguimos con nuestro trabajo de análisis y diseño de soluciones y propuestas orientadas a dar respuesta a todos los retos que han surgido por la pandemia. Los laboratorios docentes de "La escuela, lo primero" no sólo continúan, sino que se van a completar con otros de seguimiento que nos permita evaluar la implementación de las soluciones propuestas: qué ha funcionado y qué no, cómo ha evolucionado este curso tan peculiar, qué nuevos retos han surgido… y todo ello dirigido a poder definir las líneas de esa escuela que queremos construir.
Y desde la dimensión más vinculada con las políticas públicas, estamos trabajando en la elaboración de un Plan de Digitalización, que esperemos dé orientaciones tanto a la Administración como a los centros, en este proceso que en ocasiones no está siendo enfocado de la manera más adecuada.
7. La Fundación COTEC elabora cada año un informe sobre la situación del I+D en España. El informe de este año muestra que la I+D ha ganado peso en la estructura productiva por segundo año consecutivo, ¿Qué hacemos bien en España? ¿Qué queda por hacer?
Si miramos el país como conjunto, los datos nos dicen que no somos un país especialmente innovador (ocupamos posiciones medias en los rankings internacionales, que no se corresponden con las posiciones que tenemos como potencia económica o científica).
Ahora bien, si nuestro punto de vista baja de la escala país a la escala individual, de lo institucional a lo personal, la perspectiva cambia. Tanto en el sector público como en el sector privado proliferan, cada vez más, las iniciativas innovadoras, impulsadas por una fuerte creatividad y entusiasmo individual. Y a ello se une que muchas de ellas se están desarrollando en entornos y por cauces al margen de la estructura clásica del sistema de ciencia, tecnología y universidad. Por tanto, creo que somos buenos a título individual, en proyectos que actúan de catalizadores, pero que, al carecer de un sistema debidamente definido, articulado, conectado y coordinado, perdemos fuerza en el cambio colectivo.
Y en educación ocurre algo similar: tenemos una brecha entre una vocación innovadora de una gran parte del profesorado, reflejada en esa multitud de proyectos y experiencias piloto, y el desempeño innovador de las escuelas y el conjunto del sistema. Y eso ralentiza la transformación del sistema educativo en su conjunto.
Tanto en el sector público como en el sector privado proliferan, cada vez más, las iniciativas innovadoras, impulsadas por una fuerte creatividad y entusiasmo individual.
8. El informe COTEC de este año también resalta que España presenta una tasa superior a la media europea en graduados STEM, pero con una brecha de género mucho más amplia ¿qué podemos hacer para revertir esta situación?
Parece evidente que hay una brecha entre la tecnología y la mujer (y recalco la tecnología porque por ejemplo no se produce en el ámbito sanitario, que también es otra área STEM, científica, pero que sí cuenta con una presencia femenina significativa). Creo que ese distanciamiento viene generado por el discurso subyacente a la tecnología, que está enfocado en el dispositivo (el qué), no en el proceso (el para qué). Nos falta vincular de manera clara la finalidad de las tecnologías, contextualizarlas, dotarlas de un mayor sentido y enfoque social, y creo que así minimizaríamos la distancia que la población en general y las mujeres en participar tienen hacia la tecnología. Permitiría abordar al problema desde otra perspectiva: no se trata de acercar la mujer a la tecnología, sino de acercar la tecnología a la mujer.
Noticia
El pasado mes de octubre, desde la Iniciativa Aporta, junto con la Secretaría de Estado de Digitalización e Inteligencia Artificial y Red.es, se lanzó la tercera edición del Desafío Aporta. Bajo el lema “El valor del dato en la educación digital” se buscaba premiar ideas y prototipos que fueran capaces de identificar nuevas oportunidades de captar, analizar y utilizar la inteligencia de los datos en el desarrollo de soluciones en el ámbito educativo.
Dentro de las propuestas presentadas en la Fase I, se pueden encontrar candidaturas de diversa índole. Han participado desde particulares, hasta equipos del ámbito académico universitario, instituciones educativas y empresas privadas, que han ideado plataformas web, aplicaciones móviles y soluciones interactivas con la analítica de datos y las técnicas de machine learning como protagonistas.
Un jurado de reconocido prestigio ha sido el encargado de evaluar las propuestas presentadas en base a una serie de criterios públicos. Las 10 soluciones seleccionadas como finalistas son:

EducaWood
- Equipo: Jimena Andrade, Guillermo Vega, Miguel Bote, Juan Ignacio Asensio, Irene Ruano, Felipe Bravo y Cristóbal Ordóñez.
¿En qué consiste?
EducaWood es un portal web socio-semántico que permite explorar la información forestal de una zona del territorio español y enriquecerla con anotaciones de árboles. El profesorado puede proponer actividades de aprendizaje medioambiental contextualizadas a su entorno. Los estudiantes realizan dichas actividades en visitas al campo mediante anotaciones de árboles (localización e identificación de especies, medidas, microhábitats, fotos, etc.) a través de sus dispositivos móviles. Además, EducaWood permite realizar visitas virtuales al campo y realizar actividades remotas con la información forestal disponible y con las anotaciones generadas por la comunidad, posibilitando así su uso por colectivos vulnerables y en escenarios Covid.
EducaWood utiliza fuentes como el Mapa Forestal Español, el Inventario Forestal Nacional o GeoNames, las cuales han sido integradas y republicadas como datos abiertos enlazados. Las anotaciones que se generan con las actividades de los estudiantes se publicarán también como datos abiertos enlazados, contribuyendo así al beneficio comunitario.
Educación en Datos. Innovación y Derechos Humanos.
- Equipo: María Concepción Catalán, Asociación Innovación y Derechos Humanos (ihr.world).
¿En qué consiste?
Esta propuesta plantea un portal web de educación en datos para estudiantes y docentes centrado en los Objetivos de Desarrollo Sostenible (ODS). Su principal objetivo es proponer a sus usuarios diferentes retos a resolver mediante el uso de datos, como por ejemplo ‘¿A qué se dedicaban las mujeres en España en 1920?’ o ‘¿Cuánta energía se necesita para mantener una granja de 200 cerdos?’.
Esta iniciativa utiliza datos de diversas fuentes como la ONU, el Banco Mundial, Our World in Data, la Unión Europea y cada uno de sus países. En el caso de España utiliza datos de datos.gob.es y el INE, entre otros.
UniversiDATA-Lab
- Equipo: Universidad Rey Juan Carlos, Universidad Complutense de Madrid, Universidad Autónoma de Madrid, Universidad Carlos III de Madrid y DIMETRICAL The Analytics Lab S.L.
¿En qué consiste?
UniversiDATA-Lab es un portal público y abierto cuya función es alojar un catálogo de análisis avanzados y automáticos de los conjuntos de datos publicados en el portal UniversiDATA, y que es fruto del trabajo colaborativo de las universidades. Surge como evolución natural de la sección "laboratorio" actual de UniversiDATA, abriendo el alcance de los análisis potenciales a todos los datasets/universidades presentes y futuros, con el fin de mejorar los aspectos analizados y estimular que las universidades sean laboratorios de ciudadanía, aportando un valor diferencial a la sociedad.
Todos los conjuntos de datos que las universidades están publicando o van a publicar en UniversiDATA son potencialmente utilizables para llevar a cabo análisis en profundidad, siempre considerando el respeto a la protección de datos personales. Las fuentes concretas de los análisis se publicarán en GitHub para favorecer la colaboración de otros usuarios para aportar mejoras.
LocalizARTE
- Equipo: Pablo García, Adolfo Ruiz, Miguel Luis Bote, Guillermo Vega, Sergio Serrano, Eduardo Gómez, Yannis Dimitriadis, Alejandra Martínez y Juan Ignacio Asensio.
¿En qué consiste?
Esta aplicación web persigue el aprendizaje de historia del arte a través de diferentes entornos educativos. Permite al alumnado visualizar y realizar tareas geoetiquetadas sobre un mapa. El profesorado puede proponer nuevas tareas, que son agregadas al repositorio público, además de seleccionar las tareas que puedan resultar más interesantes para su alumnado y visualizar las que realicen. Por otro lado, en el futuro se desarrollará una versión móvil de LocalizARTE en la que para realizar las tareas será necesario que el usuario se encuentre próximo al lugar donde estén geoetiquetadas.
Los datos abiertos que se utilizan en la primera versión de LocalizARTE provienen de la relación de monumentos históricos de Castilla y León, DBpedia, Wikidata, Casual Learn SPARQL y OpenStreetMap.
Estudio Datos PISA y datos.gob.es
- Equipo: Antonio Benito, Iván Robles y Beatriz Martínez.
¿En qué consiste?
Este proyecto se basa en la creación de un cuadro de mando que permite ver la información del informe PISA, realizado por la OCDE, u otras evaluaciones educativas junto con datos proporcionados por datos.gob.es de ámbito socioeconómico, demográfico, educativo o científico. El objetivo es detectar qué aspectos favorecen el incremento del rendimiento académico utilizando un modelo de machine learning, de tal forma que se pueda llevar a cabo una toma de decisiones eficaz. La idea es que los propios centros de estudio puedan adaptar sus prácticas y currículos educativos hacia las necesidades de aprendizaje del alumnado para garantizar un mayor éxito.
Esta aplicación utiliza diversos datos abiertos del INE, del Ministerio de Educación y Formación Profesional o de PISA España.
Big Data en Educación Secundaria… y lo secundario en Educación
- Equipo: Carmen Navarro, Colegio Nazaret Oporto.
¿En qué consiste?
Esta propuesta persigue dos objetivos: por un lado, mejorar la formación del alumnado de secundaria en competencias digitales, como el control de sus perfiles digitales en internet o el uso de datos abiertos para sus trabajos y proyectos. Por otro, la utilización de los datos generados por el alumnado en una plataforma e-learning del centro tipo Moodle para determinar patrones y métricas que permitan personalizar el aprendizaje. Todo ello alineado con los ODS y la Agenda 20-30.
Para su desarrollo se utilizan datos de la OMS y del datatón “Big Data en la lucha contra la obesidad”, donde diversos alumnos y alumnas propusieron medidas para mitigar la obesidad mundial en base al estudio de datos públicos.
DataLAB: el laboratorio de datos en la Educación
- Equipo: iteNlearning, Ernesto Ferrández Bru.
¿En qué consiste?
Los datos obtenidos con técnicas de Inteligencia Artificial empiristas como big data o machine learning ofrecen correlaciones, no causas. iteNleanring basa su tecnología en modelos científicos con evidencia, además de en datos (procedentes de fuentes como el INE o el Instituto Vasco de Estadística - Eustat). Estos datos son curados con el fin de asistir a los docentes en la toma de decisiones, una vez que DataLAB identifica las necesidades específicas de cada estudiante.
DataLAB Matemáticas es un instrumento educativo profesional que, partiendo de modelos neuropsicológicos y cognitivos, mide el nivel de neurodesarrollo de los procesos cognitivos específicos desarrollados por cada estudiante. Con ello genera un cuadro de mando educativo que, a partir de datos, nos informa de las necesidades específicas de cada persona (alta capacidad, discalculia...) con el objetivo de que puedan ser potenciadas y/o reforzadas, permitiendo una educación basada en evidencias.
El valor del podcast en la educación digital
- Equipo: Adrián Pradilla Pórtoles y Débora Núñez Morales.
¿En qué consiste?
2020 ha sido el año en que los podcasts han despegado como nuevo formato digital para el consumo de diferentes ámbitos de información. Esta idea busca aprovechar el auge de esta herramienta para utilizarla en el ámbito educativo y que el alumnado pueda aprender de una forma más amena y diferente.
La propuesta recoge los temarios oficiales de educación secundaria o universitaria, así como de oposiciones, que se pueden obtener de fuentes de datos abiertas y webs oficiales. A través de tecnologías de procesamiento del lenguaje natural, esos temarios se asocian con audios ya existentes del profesorado sobre historia, inglés, filosofía, etc. en plataformas como iVoox o Spotify, dando como resultado un listado de podcast por curso y materia.
Entre las fuentes de datos utilizadas para esta propuesta se incluyen la Oferta Pública de Empleo de Castilla La Mancha o las competencias educativas en diferentes etapas.
Proyecto MIPs
- Equipo: Aday Melián Carrillo, Daydream Software.
¿En qué consiste?
Un MIP (Marked Information Picture) es un nuevo soporte interactivo de información, que consiste en una serie de capas interactivas sobre imágenes estáticas que facilitan la retención de información y la identificación de elementos.
Este proyecto consiste en un servicio para la creación de MIPs de forma rápida y sencilla, dibujando manualmente regiones de interés sobre cualquier imagen importada a través de la web. Los MIPs creados serán accesible desde cualquier dispositivo y tienen múltiples aplicaciones como recurso docente, personal y profesional.
Además de la creación manual, los autores han implementado en Python un conversor de datos GeoJSON a MIP de forma automática. Como primer paso, han desarrollado un MIP de provincias españolas a partir de esta base de datos pública.
FRISCHLUFT
- Equipo: Harut Alepoglian y Benito Cuezva, Asociación Cultural Colegio Alemán, Zaragoza.
¿En qué consiste?
El proyecto Frischluft (Aire Fresco) es una solución hardware y software para la medición de parámetros ambientales en el colegio. Con ello se pretende mejorar el confort térmico de las aulas y aumentar la protección del alumnado a través de una ventilación inteligente, a la vez que se consolida un proyecto tractor que impulse la transformación digital del colegio.
Esta propuesta utiliza fuentes de datos del Ayuntamiento de Zaragoza sobre niveles de CO2 en el entorno urbano de la ciudad y repositorios de datos internacionales para la medición de emisiones globales, que se comparan a través de técnicas estadísticas y modelos de machine learning.
Próximos pasos
Todas estas ideas han sido capaces de plasmar cómo utilizar de manera óptima la inteligencia de los datos para desarrollar soluciones reales en el sector de la educación. Ahora, los finalistas cuentan con 3 meses para desarrollar un prototipo. Los tres prototipos que obtengan la mejor valoración del jurado, según los criterios de evaluación establecidos, serán premiados con 4.000, 3.000 y 2.000 euros respectivamente.
¡Mucha suerte a todos los participantes!

Blog
Cuando pensamos en datos abiertos nuestra primera intuición suele estar dirigida hacia los datos generados por los organismos del sector público en el ejercicio de sus funciones y que son puestos a disposición de los ciudadanos y empresas para su reutilización, esto es, en datos abiertos del sector público o datos públicos abiertos. Y es normal, porque la información del sector público representa una fuente extraordinaria de datos y el uso inteligente de estos datos, incluido su tratamiento a través de aplicaciones de inteligencia artificial, tiene un gran potencial transformador en todos los sectores de la economía, tal como reconoce la directiva europea relativa a los datos abiertos y la reutilización de la información del sector público
Una de las novedades más interesantes que introdujo la directiva fue la definición inicial aunque ampliable de 6 categorías temáticas de conjuntos de datos de alto valor, cuya reutilización está asociada a considerables beneficios para la sociedad, el medio ambiente y la economía. Estas seis áreas, Geoespacial, Observación de la Tierra y medio ambiente, Meteorología, Estadística, Sociedades y propiedad de sociedades y Movilidad, son las que en 2019 se consideraron con un mayor potencial para la creación de servicios de valor añadido y aplicaciones basadas en tales conjuntos de datos. Sin embargo, desde la óptica de un 2021 en el que va a cumplirse prácticamente un año de crisis sanitaria global, parece claro que en esta lista se echan de menos dos áreas clave con un gran potencial impacto para la sociedad como son la salud y la educación.
De hecho, encontramos que por una parte los centros educativos están exentos explícitamente de algunas obligaciones en la directiva y por otra que los datos del sector salud apenas si son mencionados. La directiva, por tanto, no aporta un desarrollo de estas dos áreas que las circunstancias sobrevenidas con la pandemia de covid-19 han puesto en la primera línea de las prioridades de la sociedad.
La disponibilidad de los datos de salud y educación
A pesar de que los sistemas de salud, tanto públicos como privados, generan y custodian en las historias clínicas de las personas una enorme cantidad de datos de gran valor, la disponibilidad de estos datos es muy escasa debido a la muy elevada complejidad de su tratamiento de forma segura. Normalmente los conjuntos de datos relativos a la salud solo están a disposición de la entidad que los genera, a pesar del gran valor que su liberación podría tener para el avance de la investigación científica.
Algo equivalente podría decirse de los datos que se generan en la interacción de los estudiantes con las plataformas educativas, que en general tampoco están disponibles como datos abiertos. Al igual que en el sector salud estos conjuntos de datos habitualmente solo están a disposición de sus propietarios, para quienes constituyen un valioso activo para la mejora de las plataformas, lo cual solo es una pequeña parte de su valor potencial para la sociedad.
La directiva establece que los datos de alto valor deberían publicarse en formatos abiertos que puede utilizar, reutilizar y compartir libremente cualquier persona con cualquier fin. Además, con el objetivo de garantizar su máxima repercusión y facilitar la reutilización, los conjuntos de datos de alto valor deberían ponerse a disposición para su reutilización con muy pocas restricciones legales y sin coste alguno.
Los datos de salud son altamente sensibles para la privacidad de las personas, por lo que siempre es necesario tener presente el delicado compromiso entre el respeto a la privacidad y la necesidad de apoyar el avance en la investigación científica. Probablemente la consideración de los datos de salud y educación como datos abiertos de alto valor debiera mantener algunas restricciones particulares por la naturaleza y sensibilidad propia de estos datos y potenciar figuras como la donación de datos con fines de investigación por parte de los pacientes o el intercambio con el mismo fin entre investigadores. En este sentido la regulación sobre protección de datos de 2018 introdujo la posibilidad de reutilizar datos con fines de investigación siempre que se adopten las oportunas medidas de seudonimización y el resto de garantías previstas legalmente.
La importancia de la colaboración público-privada
La educación y la salud son dos áreas en los que el sector privado o la colaboración del sector público y privado está realizando interesantes avances para convertir parte del potencial de los datos abiertos en beneficios para la sociedad. La publicación de datos abiertos no es patrimonio exclusivo del sector público y existe una larga tradición de colaboración entre la iniciativa privada y el sector público, en gran medida canalizado a través de las universidades. Veamos algunos ejemplos:
- Existen un buen número de iniciativas como la pionera The UCI Machine Learning Repository fundada en 1987 como un repositorio de conjuntos de datos que utiliza la comunidad de inteligencia artificial para el análisis empírico de algoritmos de aprendizaje automático. Este repositorio ha sido citado en más de 1000 ocasiones, el número más alto de citas obtenido en el dominio de las ciencias de la computación. En este y otros repositorios gestionados también por universidades o fundaciones con donaciones de empresas privadas podemos encontrar también conjuntos de datos abiertos liberados por empresas o en los que éstas han colaborado activamente para su creación o desarrollo.
- También las grandes empresas tecnológicas, sin duda inspiradas por estas iniciativas, mantienen buscadores o repositorios de datos abiertos como el buscador de conjuntos de datos de Google, el registro de datos abiertos de AWS, o los conjuntos de datos de Microsoft Azure, donde los conjuntos de datos relacionados con la salud o la educación son cada vez más habituales.
- En cuanto a datos que pueden contribuir a mejorar educación por ejemplo, The Open University publica OULAD (OpenUniversity Learning Analytics Dataset), un conjunto de datos abiertos de analítica del aprendizaje que contiene datos sobre cursos, estudiantes y sus interacciones con el entorno de aprendizaje virtual para siete cursos. Sin embargo, existen muy pocos conjuntos de datos homologables cuya utilización de forma conjunta en proyectos sin duda permitirían desarrollar mayores avances en áreas como la detección del riesgo de abandono por parte de los estudiantes.
- En lo que se refiere al sector salud, merece la pena destacar el caso de la plataforma española HealthData 29, desarrollada por Fundación 29, que tiene como objetivo crear la infraestructura necesaria para que sea posible publicar de forma segura conjuntos de datos abiertos de salud para que estén disponibles para la comunidad con fines de investigación. Como parte de esta infraestructura Fundacion 29 ha publicado el Health Data Playbook que es una guía para la creación dentro del marco técnico y legal vigente de un repositorio público de datos procedentes de los sistemas de salud, de manera que puedan ser utilizados en la investigación médica. En la elaboración de esta guía han colaborado Microsoft como socio tecnológico y Garrigues como socio jurídico y está destinada a las organizaciones que investigan en salud.
Por el momento la plataforma sólo tiene disponible el conjunto de datos Covid Data Save Lives (COVIDDSL) publicado por el Grupo Hospitalario Universitario HM Hospitales, compuesto por datos clínicos de las interacciones registradas en el proceso de tratamiento del covid-19. Sin embargo, se trata de un excelente ejemplo del potencial que podemos estar desaprovechando en el mundo entero por no haber recogido y publicado de forma sistematizada y a escala global una mayor y mejor cantidad de datos de los pacientes diagnosticados de covid-19. La creación de modelos predictivos de la evolución de la enfermedad en los pacientes, el desarrollo de modelos epidemiológicos sobre la propagación del virus o la extracción de conocimiento sobre el comportamiento del virus para el desarrollo de vacunas son sólo algunos de los casos de uso que se verían beneficiados por una mayor disponibilidad de estos datos.
La educación y la salud son dos de las grandes preocupaciones de todas las sociedades desarrolladas del mundo porque están estrechamente relacionadas con el bienestar de sus ciudadanos. Pero quizá nunca hemos sido tan conscientes de ello como en el último año y esto representa una extraordinaria oportunidad para impulsar iniciativas que contribuyan a liberar una mayor cantidad de datos abiertos de salud y educación. Ya sea como datos de alto valor o con cualquier otra figura estos conjuntos de datos son clave para que podamos reaccionar mejor ante futuras situaciones de crisis sanitaria pero también para ayudarnos a superar las secuelas de la actual.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El mundo de la tecnología y los datos está en evolución constante. Estar a la última de las novedades y tendencias puede ser una tarea complicada. Por ello, son importantes los espacios de diálogo donde compartir conocimientos, dudas y recomendaciones.
¿Qué son las comunidades?
Las comunidades son canales abiertos a través de los cuales diferentes personas interesadas en una misma temática o tecnología se reúnen de forma física o virtual para aportar, preguntar, discutir y resolver temas relacionados con dicha tecnología. Comúnmente se crean a través de una plataforma en línea, aunque existen comunidades que organizan reuniones y eventos de manera periódica donde comparten experiencias, establecen objetivos y afianzan los lazos creados a través de la pantalla.
¿Cómo funcionan?
Muchas comunidades de desarrolladores utilizan plataformas de código abierto conocidas como GitHub o Stack Overflow, a través de las que almacenan y administran su código, además de compartir y debatir sobre temas relacionados.
Respecto a cómo se organizan, no todas las comunidades disponen de un organigrama como tal, algunas sí, pero no existe un parámetro que rija la organización de las comunidades de manera general. Sin embargo, sí pueden existir roles definidos en función de las habilidades y conocimientos de cada uno de sus miembros.
Las comunidades de desarrolladores como reutilizadores de datos
Existe un gran significativo número de comunidades que acercan los conocimientos sobre datos y sus tecnologías asociadas a diferentes grupos de usuarios. Algunas de ellas, están integradas por desarrolladores, que se reúnen para ampliar sus capacidades a través de webinars, concursos o proyectos. En ocasiones, estás actividades ayudan a impulsar la innovación y la transformación en el mundo de la tecnología y los datos, y pueden servir de escaparate para promover el uso de los datos abiertos.
A continuación, recogemos tres ejemplos de comunidades de desarrolladores relacionadas con los datos que pueden ser de tu interés si quieres ampliar tu conocimiento en este campo:
Hackathon Lovers
Desde su creación en 2013, esta comunidad de desarrolladores, diseñadores y emprendedores amantes de los hackathones, organizan encuentros para probar nuevas plataformas, APIs, productos, hardware, etc. Entre sus principales objetivos se encuentra el crear nuevos proyectos y aprender, a la vez que los usuarios se divierten y afianzan lazos con otros profesionales.
Las temáticas que abordan en sus eventos son variadas. En el hackathon #SerchathonSalud, se centraron en impulsar la formación e investigación en el campo de la salud a partir de las búsquedas bibliográficas en 3 bases de datos (PubMed, Embase, Cochrane). En otros eventos, se han focalizado en el uso de APIs concretas. Es el caso de #OpenApiHackathon, un evento de desarrollo sobre Open Banking y #hackaTrips, un hackathon para buscar ideas sobre turismo sostenible.
¿A través de qué canales puedes seguir sus novedades?
Hackathon Lovers está presente en las principales redes sociales como son Twitter y Facebook, además de YouTube, Github, Flickr y cuenta con un blog propio.
Comunidad R Hispano
Se creó en noviembre de 2011, en el seno de las III Jornadas de Usuarios de R celebradas en la Escuela de Organización Industrial en Madrid. Organizada a través de grupos locales de usuarios, su principal objetivo es el de fomentar el avance del conocimiento y el uso del lenguaje de programación en R, además del desarrollo de la profesión en todas sus vertientes, especialmente la investigadora, docente y empresarial.
Uno de sus principales campos es el de la formación de R y tecnologías asociadas a sus usuarios, en las que los datos abiertos tienen cabida. Respecto a las actividades que realizan, se encuentran eventos como:
- Congresos anuales: hasta ahora se han realizado once ediciones basadas en charlas y talleres con los asistentes con el software R como protagonista.
- Iniciativas locales: aunque la asociación es el principal promotor de los congresos anuales, el sentimiento de comunidad se forja gracias a grupos locales como los de Madrid, patrocinado por RConsortium, Canarias, que comunica aspectos como datos públicos y geográficos o Sevilla, que durante sus últimos hackatones han desarrollado varios paquetes vinculados a datos abiertos.
- Colaboración con grupos e iniciativas centradas en datos: como la UNED, Grupo de Periodismo de Datos, Grupo Machine Learning Spain o empresas como Kabel o Kernel Analytics.
- Colaboración con instituciones académicas españolas: como EOI, Universidad Francisco de Vitoria, ESIC, o K-School, entre otras.
- Relación con instituciones internacionales: como RConsortium o RStudio.
- Creación de paquetes centrado en datos en España: participación en ROpenSpain, una iniciativa para entusiastas de R y datos abiertos encaminada a crear paquetes de R de máxima calidad para la reutilización de datos españoles de interés general.
¿A través de qué canales puedes seguir sus novedades?
Esta comunidad está formada por más de 500 socios. El principal canal de comunicación para entrar en contacto con sus usuarios es Twitter, aunque sus grupos locales poseen cuentas propias, como es el caso de Málaga, Canarias o Valencia, entre otros.
R- Ladies Madrid
R-Ladies Madrid es una rama local de R-Ladies Global -un proyecto financiado por el R Consortium-Linux Foundation- que nace en 2016. Se trata de una comunidad open source desarrollada por mujeres que se apoyan y ayudan a crecer dentro del sector R.
La actividad principal de esta comunidad reside en la celebración de encuentros mensuales o meet ups donde ponentes mujeres comparten conocimientos y proyectos en los que trabajan, o enseñan funcionalidades relacionadas con R. Entre sus miembros encontramos desde profesionales que tienen R como herramienta principal de trabajo hasta aficionadas que buscan aprender y mejorar sus capacidades.
R-Ladies Madrid es muy activa dentro de la comunidad software y apoya diferentes iniciativas tecnológicas, desde la creación de grupos de trabajo open source hasta su participación en diferentes eventos tecnológicos. En algunos de sus grupos de trabajo utilizan datos abiertos, procedentes de fuentes como el BOE o Open Data NASA. Además, también han ayudado a montar un grupo de trabajo con datos sobre Covid-19. En años anteriores han organizado hackatones de género donde todos los equipos participantes estaban constituidos por un 50% mujeres y se proponía trabajar con datos de organizaciones sin ánimo de lucro.
¿A través de qué canales puedes seguir sus novedades?
R – Ladies Madrid está presente en Twitter, además de tener un grupo de Meetup.
Esta ha sido una primera aproximación, pero existen más comunidades de desarrolladores relacionadas con el mundo de los datos en nuestro país. Estas son fundamentales no solo para acercar los conocimientos teóricos y técnicos a los usuarios, sino también para impulsar la reutilización de los datos públicos a través de diversos proyectos como los que hemos visto. ¿Conoces alguna otra organización con fines similares? No dudes en escribirnos a dinamizacion@datos.gob.es o dejarnos toda la información en los comentarios.
Documentación
La pandemia originada el pasado año ha supuesto un cambio significativo en la forma que teníamos de ver el mundo y relacionarnos con este. En lo que al sector educativo se refiere, alumnos y docentes de todos los niveles se han visto obligados a tener que cambiar la metodología de enseñanza y aprendizaje presencial por un sistema telemático.
En este contexto, desde el marco de la Iniciativa Aporta se ha desarrollado el estudio “Tecnología educativa basada en datos para mejorar el aprendizaje en el aula y en el hogar”, realizado por José Luis Marín. Este informe ofrece diversas claves para reflexionar acerca de los nuevos retos y desafíos que plantea esta situación y que se pueden convertir en oportunidades si conseguimos introducir cambios que fomenten la mejora del proceso de enseñanza-aprendizaje más allá de solamente sustituir las clases presenciales por formación en línea.
La importancia de los datos para mejorar el sector educativo
A través de una tecnología educativa innovadora basada en datos e inteligencia artificial se pueden abordar algunos de los desafíos a los que se enfrenta el sistema educativo. Para este informe se han seleccionado 4 de estos retos:
- Supervisión no presencial de pruebas de evaluación: monitorización y vigilancia de pruebas evaluativas a través de recursos telemáticos.
- Identificación de problemas de comportamiento o atención: alerta a los docentes sobre actividades y conductas que indiquen problemas de atención, motivación o comportamiento.
- Programas formativos personalizados y más atractivos: adaptación de las rutas y el ritmo de aprendizaje de los alumnos.
- Mejora del rendimiento en exámenes estandarizados: uso de plataformas de aprendizaje en línea para mejorar resultados en pruebas estandarizadas, para reforzar el dominio de un tema en particular y para conseguir una evaluación más justa e igualitaria.
Para abordar cada uno de estos cuatro retos, se propone una sencilla estructura dividida en tres apartados:
- Descripción del problema, que nos permite poner el desafío en contexto.
- Análisis de algunos de los enfoques basados en el uso de datos e inteligencia artificial que se utilizan para ofrecer una solución tecnológica al reto en cuestión.
- Ejemplos de soluciones o experiencias relevantes o altamente innovadoras.
El informe también destaca la enorme complejidad que entraña este tipo de cuestiones, por lo que deben abordarse con cautela para evitar consecuencias negativas sobre los individuos, como pueden ser problemas de ciberseguridad, invasión de la privacidad o riesgo de exclusión de algunos colectivos, entre otros. Para ello, el documento finaliza con una serie de conclusiones que convergen en la idea de que el mejor camino para generar mejores resultados para todos los estudiantes, aliviando desigualdades, es combinar excelentes docentes y excelente tecnología que aumente sus capacidades. En este proceso los datos abiertos pueden jugar un papel aún más relevante para mejorar el estado del arte en tecnología educativa y asegurar un acceso más generalizado a determinadas innovaciones que en gran medida están basadas en tecnologías de aprendizaje automático o inteligencia artificial.
En este vídeo, su autor nos cuenta más sobre el informe:
Aplicación
Este portal recopila de forma automática la producción científica y de transferencia de los investigadores de la Universidad de Extremadura, agrupados por Institutos y Grupos de investigación. Recoge periódicamente datos de varios Servicios de la Universidad de Extremadura y de fuentes externas de publicaciones (Scopus, ORCID y Dialnet). Todos los datos (en RDF) se pueden descargar desde el catálogo de datos del portal de datos abiertos del Servicio de Informática. El portal se caracteriza por representar la información en open linked data, con el máximo nivel de reutilización de 5 estrellas, recomendado por el W3C.
Blog
Los datos abiertos son un recurso cada vez más utilizado para la formación de estudiantes de diferentes etapas del sistema educativo y para la formación continua de profesionales de todos los sectores. Y es que ya existen pocas dudas acerca de la creciente importancia que están adquiriendo todas las habilidades relacionadas con el análisis de datos y su tratamiento en relación con casi cualquier disciplina del conocimiento. Del mismo modo las habilidades relacionadas con la visualización y la construcción de relatos sobre la base de las conclusiones extraídas de cualquier análisis o modelado de datos son cada vez más necesarias para complementar y extender las siempre necesarias habilidades para comunicar y presentar resultados de cualquier tipo de trabajo.
En todo el proceso de formación de profesionales relacionados con la ciencia de datos y la inteligencia artificial, los datos abiertos constituyen un valioso recurso para adquirir experiencia práctica con las técnicas y herramientas habituales en la profesión. Sin embargo, también comienzan a apreciarse los efectos que tiene el uso de datos, habitualmente abiertos, sobre el aprendizaje de otras materias, en la adquisición de otro tipo de habilidades e incluso en la motivación de los estudiantes hacia el aprendizaje.
Ya en 2013 en una investigación que realizó una comparación cuantitativa detallada de diferentes enfoques educativos adoptados por 39 escuelas en Nueva York se demostró que el uso de datos para guiar el programa educativo era una de las cinco políticas principales que tenía efecto sobre la mejora del desempeño académico.
Aunque el uso de datos abiertos en el aula no se ha estudiado de forma amplia, por el momento las pocas investigaciones realizadas sugieren de entrada que existe una falta de conocimiento de los datos abiertos entre los educadores. Si bien no tenemos un conocimiento consolidado sobre el efecto del uso de los datos abiertos en contextos educativos ya que no son actualmente un recurso educativo generalizado, si parece existir un conjunto de educadores ‘early adopters‘ que hacen un uso sustancial de datos abiertos en sus programas de enseñanza.
La investigación “The use of open data as a material for learning” del Institute of Educational Technology se basa en el análisis cualitativo de la experiencia de un conjunto de estos educadores pioneros para extraer una serie de conclusiones sobre el valor que aporta el uso de datos abiertos en la enseñanza.
Uno de los puntos de partida es que los datos abiertos no parecen ofrecer metodologías educativas o pedagógicas completamente nuevas, sino que su uso complementa conceptos de enseñanza y aprendizaje existentes como el aprendizaje basado en investigación o en proyectos o la personalización del aprendizaje. Destacan dos conclusiones al respecto:
-
Los conjuntos de datos abiertos que se utilizan como parte de los proyectos de aprendizaje en cualquier materia normalmente son relevantes para el alumno, bien porque describen cuestiones de su entorno geográfico o social, o bien porque tienen relaciones con cuestiones relativas a la actualidad o a sus propias aficiones. La investigación pone de manifiesto que el mero uso de estos conjuntos de datos que despiertan la curiosidad del estudiante durante el aprendizaje de cualquier concepto tiene efectos positivos sobre la motivación de los estudiantes para profundizar en la materia y apreciar su utilidad.
-
El uso de conjuntos de datos abiertos ofrece la posibilidad de proponer actividades más avanzadas sin aumentar la dificultad del programa formativo. En la investigación se citan ejemplos que van desde el uso de datos abiertos para apoyar la formación en estadística de alumnos de bachillerato hasta el uso de bases de datos científicas abiertas en el área de la genómica para apoyar la enseñanza de conceptos de bioinformática. De este modo los alumnos pueden adquirir conocimientos y habilidades más avanzados que de otro modo probablemente sólo se habrían producido en el ámbito de la actividad profesional o que habrían sido descartadas por no disponer de tiempo suficiente en el programa. Este efecto, sobre todo en los niveles educativos superiores, además contribuiría a cerrar la brecha entre el sistema educativo y la práctica profesional.
Aunque aún no se ha estudiado su efecto, los concursos de datos abiertos son otro vehículo para canalizar la formación práctica de los estudiantes y para crear nuevos recursos educativos. Cada vez es más frecuente que desde universidades o escuelas de enseñanza secundaria se incentive como actividad dentro de algunas asignaturas la formación de equipos que participen en concursos de datos abiertos regionales o nacionales. Algunos concursos, como el concurso de datos abiertos de Castilla y León, incluso tienen una categoría especial con su correspondiente premio que está reservado para la participación de estudiantes.
En la misma línea, el Ayuntamiento de Barcelona lleva cuatro años organizando el Reto Barcelona Dades Obertes, que tiene como finalidad acercar los beneficios de los datos abiertos y promover su uso en los centros educativos de la ciudad. El reto mezcla la competición entre escuelas, que tienen que desarrollar un proyecto basado en datos, con un Plan de Formación específico sobre datos abiertos para el profesorado, para que puedan orientar a sus alumnos.
El hecho que no haya un uso más generalizado de conjuntos de datos abiertos en los programas educativos se puede atribuir a factores como la falta de formación del profesorado o a la dificultad para adaptar los datos existentes. La mayoría de los conjuntos de datos abiertos proceden de entornos profesionales como la investigación científica o la administración de los servicios públicos y es posible que los alumnos y los educadores no tengan la alfabetización o los recursos necesarios para aprovecharlos a pesar de que están surgiendo herramientas que simplifican algunas de las complejidades de trabajar con datos abiertos. En este sentido, una mayor relación y trabajo conjunto entre los educadores y los alumnos y los productores de conjuntos de datos también podría fomentar el despliegue de un mayor número de programas de aprendizaje.
Por ello son interesantes iniciativas como UDIT (Use Open Research Data In Teaching) iniciada en 2017 con el objetivo de fomentar y ayudar a los profesores de educación superior a incorporar datos de investigación abiertos y otros conceptos de la ciencia abierta a su docencia para mejorar el proceso de aprendizaje.
En la Carta Internacional de Datos Abiertos ya se reconoce la importancia de involucrase “con escuelas e instituciones de educación superior para respaldar una mayor investigación de datos abiertos y para incorporar la alfabetización de los datos en los programas educativos”. Y es que el valor de los datos abiertos en el proceso de aprendizaje no está aún lo suficientemente estudiado. Sirva como ejemplo que en el discurso habitual de la comunidad de datos abiertos se destaca siempre el potencial valor económico y social de la reutilización, pero no tanto el potencial de su uso en educación.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
2020 llega a su fin y en este año tan atípico nos va a tocar vivir unas Navidades diferentes, más tranquilas y con nuestro núcleo más cercano. ¿Qué mejor para disfrutar de esos momentos de calma que formarte y mejorar tus conocimientos sobre datos y nuevas tecnologías?
Tanto si estás buscando una lectura que te haga mejorar tu perfil profesional a la que dedicar tu tiempo libre en estas fechas tan especiales, como si quieres ofrecer a tus seres más queridos un regalo didáctico e interesante, desde datos.gob.es queremos proponerte algunas recomendaciones de libros sobre datos y tecnologías disruptivas que esperamos sean de tu interés. Hemos seleccionado libros en castellano e inglés, para que también puedas poner en práctica tu conocimiento de este idioma.
¡Toma nota porque todavía estás a tiempo de incluir alguno en tu carta a los Reyes Magos!
INTELIGENCIA ARTIFICIAL, naturalmente. Nuria Oliver, ONTSI, red.es (2020)
¿De qué trata?: Este libro es el primero de la nueva colección que publica el ONTSI llamada “Pensamiento para la sociedad digital”. Sus páginas ofrecen un breve recorrido por la historia de la inteligencia artificial, describiendo su impacto en la actualidad y abordando los retos que presenta desde diversos puntos de vista.
¿A quién va dirigido?: Esta dirigido especialmente a tomadores de decisiones, profesionales del sector público y privado, profesores y estudiantes universitarios, organizaciones del tercer sector, investigadores y medios de comunicación, pero también es una buena opción para lectores que quieran introducirse y acercarse al complejo mundo de la inteligencia artificial.
Artificial Intelligence: A Modern Approach, Stuart Russell
¿De qué trata?: Interesante manual que introduce al lector en el campo de la Inteligencia Artificial a través de una estructura ordenada y una redacción comprensible.
¿A quién va dirigido?: Este libro de texto es una buena opción para utilizar como documentación y referencia en diferentes cursos y estudios en Inteligencia Artificial a diferentes niveles. Para aquellos que quieran convertirse en expertos en la materia.
Situating Open Data: Global Trends in Local Contexts, Danny Lämmerhirt, Ana Brandusescu, Natalia Domagala – African Minds (Octubre 2020)
¿De qué trata?: Este libro proporciona varios relatos empíricos sobre las prácticas de datos abiertos, la implementación local de iniciativas globales y el desarrollo de nuevos ecosistemas de open data.
¿A quién va dirigido?: Será de gran interés para los investigadores y defensores de los datos abiertos y para quienes están en las administraciones gubernamentales o las asesoran en el diseño y la implementación de iniciativas efectivas de open data. Puedes descargar su versión en PDF a través de este enlace.
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition (Springer Series in Statistics), Trevor Hustle, Jerome Friedman. – Springer (Mayo 2017)
¿De qué trata?: Este libro describe diversos conceptos estadísticos en una variedad de campos como la medicina, la biología, las finanzas y el marketing en un marco conceptual común. Si bien el enfoque es estadístico, el énfasis está en las definiciones más que en las matemáticas.
¿A quién va dirigido?: Es un recurso valioso para los estadísticos y cualquier persona interesada en la minería de datos en la ciencia o la industria. También puedes descargar su versión digital aquí.
Europa frente a EEUU y China: Prevenir el declive en la era de la inteligencia artificial, Luis Moreno, Andrés Pedreño – Kdp (2020)
¿De qué trata?: Este interesante libro aborda los motivos del retraso europeo respecto a la potencia que sí tienen EEUU y China, y sus consecuencias, pero sobre todo propone soluciones a la problemática que se expone en la obra.
¿A quién va dirigido?: Se trata de una reflexión para aquellos interesados en pensar acerca del cambio que Europa necesitaría, en palabras de su autor, “alejada cada vez más de la revolución que impone el nuevo paradigma tecnológico”.
¿De qué trata?: Este libro hace una llamada de atención acerca de la problemática que puede desencadenar el mal uso de los algoritmos y propone algunas ideas para no caer en errores.
¿A quién va dirigido?: En estas páginas no aparecen conceptos demasiado técnicos, ni hay fórmulas ni explicaciones complejas, aunque sí se tratan problemas densos que necesitan la atención del autor.
Data Feminism (Strong Ideas), Catherine D’Ignazio, Lauren F. Klein. MIT Press (2020)
¿De qué trata?: Estas páginas abordan una nueva forma de pensar sobre la ciencia de datos y su ética basada en las ideas del pensamiento feminista.
¿A quién va dirigido?: A todos/as aquellos/as que tienen interés en reflexionar sobre los sesgos integrados en los algoritmos de las herramientas digitales que utilizamos en todos los ámbitos de la vida.
Open Cities | Open Data: Collaborative Cities in the Information, Scott Hawken, Hoon Han, Chris Pettit – Palgrave Macmillan, Singapore (2020)
¿De qué trata?: Este libro explica la importancia de abrir los datos en las ciudades a través de una variedad de perspectivas críticas, y presenta estrategias, herramientas y casos de uso que facilitan tanto dicha apertura como su reutilización.
¿A quién va dirigido?: Perfecto para aquellos integrados en la cadena de valor del dato en las ciudades y quienes tienen que elaborar estrategias de open data en el marco de una ciudad inteligente, pero también para los ciudadanos preocupados por la privacidad y que quieran saber qué sucede -y qué puede suceder- con los datos que generan las ciudades.
Aunque nos encantaría incluirlos a todos en esta lista, son muchos los libros interesantes sobre datos y tecnología que llenan las estanterías de cientos de librerías y tiendas online. Si tienes alguna recomendación extra que nos quieres hacer, no dudes en dejarnos tu título favorito en comentarios. Los miembros que formamos el equipo de datos.gob.es estaremos encantados de leer vuestras recomendaciones esta Navidad.