Blog
The European High-Value Datasets (HVD) regulation, established by Implementing Regulation (EU) 2023/138, consolidates the role of APIs as an essential infrastructure for the reuse of public information, making their availability a legal obligation and not just a good technological practice.
Since 9 June 2024, public bodies in all Member States are required to publish datasets classified as HVDs free of charge, in machine-readable formats and accessible via APIs. The six categories regulated are: geospatial data, Earth observation, environment, statistics, business information and mobility.
This framework is not merely declarative. Member States must report to the European Commission compliance status every two years, including persistent links to APIs that give access to such data. The situation in Spain in terms of transparency, open data and Systematic API Provisioning can be consulted in the indicators published by the Open Data Maturity Report.
In practice, this means that APIs are the bridge between the norm and reality. The regulation not only says what data must be opened, but also requires it to be done in such a way that it can be automatically integrated into applications, studies or digital services. Therefore, reviewing the public APIs available in Spain is a concrete way to understand how this framework is being applied on a day-to-day basis.
Inventory of public APIs in Spain
INE — API JSON (Tempus3)
The National Institute of Statistics offers a API REST that Exposes the entire database Tempus3 broadcast format JSON, which includes official statistical series on demography, economy, labour market, industry, services, prices, living conditions and other socio-economic indicators.
To make calls, the structure must follow the pattern https://servicios.ine.es/wstempus/js/{language}/{function}/{input}. The tip=AM parameter allows you to get metadata along with the data, and tv filters by specific variables. For example, to obtain the population figures by province, simply consult the corresponding operation (IOE 30243) and filter by the desired geographical variable.
No authentication or API key required: any well-formed GET request returns data directly.
Example in Python — get the resident population series with metadata:
import requests
url = ("https://servicios.ine.es/wstempus/js/ES/"
"DATOS_TABLA/t20/e245/p08/l0/01002.px?tip=AM")
response = requests.get(url)
data = response.json()
for serie in data[:3]: # primeras 3 series
name = series["Name"]
last = series["Date"][-1]
print(f"{name}: {last['Value']:,.0f} ({last['PeriodName']})")
TOTAL AGES, TOTAL, Both sexes: 39,852,651 (1998)
TOTAL AGES, TOTAL, Males: 19,488,465 (1998)
TOTAL EDADES, TOTAL, Mujeres: 20,364,186 (1998)AEMET — OpenData API REST
The State Meteorological Agency exposes its data through a REST API, documented with Swagger UI (an open-source tool that generates interactive documentation), observed meteorological data and official predictions, including temperature, precipitation, wind, alerts and adverse phenomena.
Unlike the INE, AEMET requires a Free API key, which is obtained by providing an email address in the portal opendata.aemet.es. A API key works as A type of "password" or identifier: it is used to allow the agency to know who is using the service, control the volume of requests and ensure proper use of the infrastructure.
A relevant technical aspect is that AEMET implements a two-call model: the first request returns a JSON with a temporary URL in the data field, and a second request to that URL retrieves the actual dataset. The rate limit is 50 requests per minute.
Example in Python — daily weather data (double call):
import requests
API_KEY = "tu_api_key_aqui"
headers = {"api_key": API_KEY}
#1st call: Get temporary data URLs
url = ("https://opendata.aemet.es/opendata/api/"
"Values/Climatological/Daily/Data/"
"fechaini/2025-01-01T00:00:00UTC/"
"fechafin/2025-01-10T23:59:59UTC/"
"allseasons")
resp1 = requests.get(url, headers=headers).json()
#2nd call: Download the actual dataset
datos = requests.get(resp1["datos"], headers=headers).json()
for estacion in datos[:3]:
print(f"{station['name']}: "
f"Tmax={station.get('tmax','N/A')}°C, "
f"Prec={estacion.get('prec','N/A')}mm")
CITFAGRO_88_GAITERO: Tmax=8.8°C, Prev=0.0mm
ABANILLA: Tmax=14,8°C, Prec=0,0mm
LA RODA DE ANDALUCÍA: Tmax=15.7°C, Prec=0.2mmCNIG / IDEE — Servicios OGC y OGC API Features
The National Center for Geographic Information It publishes official geospatial data – base mapping, digital terrain models, river networks, administrative boundaries and other topographic elements – through interoperable services. These have evolved from WMS/WFS to the OGC API (Features, Maps and Processes), implemented with open software such as pygeoapi.
The main advantage of OGC API Features over WFS is the response format: instead of GML (heavy and complex), the data is served in GeoJSON and HTML, native formats of the web ecosystem. This allows them to be consumed directly from libraries such as Leaflet, OpenLayers or GDAL. Available datasets include Cartociudad addresses, hydrography, transport networks and geographical gazetteer.
Example in Python — query geographic features via OGC API:
import requests
# OGC API Features - Basic Geographical Gazetteer of Spain
base = "https://api-features.idee.es/collections"
collection = "falls" # Waterfalls
url = f"{base}/{collection}/items?limit=5&f=json"
resp = requests.get(url).json()
for feat in resp["features"]:
props = feat["properties"]
coords = feat["geometry"]["coordinates"]
print(f"{props['number']}: ({coords[0]:.4f}, {coords[1]:.4f})")
None: (-6.2132, 42.8982)
Cascada del Cervienzo: (-6.2572, 42.9763)
El Xaral Waterfall: (-6.3815, 42.9881)
Rexiu Waterfall: (-7.2256, 42.5743)
Santalla Waterfall: (-7.2543, 42.6510)MITECO — Open Data Portal (CKAN)
The Ministry for the Ecological Transition maintains a CKAN-based portal that exposes three access layers: the CKAN Action API for metadata and dataset search, the Datastore API (OpenAPI) for live queries on tabular resources, and RDF/JSON-LD endpoints compliant with DCAT-AP and GeoDCAT-AP. In its catalogue you can find data on air quality, emissions and climate change, water (state of masses and hydrological planning), biodiversity and protected areas, waste, energy and environmental assessment.
Featured datasets include Natura 2000 Network protected areas, bodies of water, and greenhouse gas emissions projections.
Example in Python — search for datasets:
import requests
BASE = "https://catalogo.datosabiertos.miteco.gob.es/ catalog"
# Search for datasets containing 'natura 2000'
busqueda = requests.get(
f"{BASE}/api/3/action/package_search",
params={"q": "natura 2000", "rows": 3},
).json()
for ds in busqueda["result"]["results"]:
print(f"{ds['title']} ({ds['num_resources']} resources)")
Protected Areas of the Natura 2000 Network (13 resources)
Database of Natura 2000 Network Protected Areas of Spain (CNTRYES) (1 resources)
Protected Areas of the Natura 2000 Network - API - High Value Data (1 resources)Technical comparison
| Organisim | Protocol | Format | Authentication | Rate limit | HVD |
|---|---|---|---|---|---|
| INE | REST | JSON | None | Undeclared | Yes (statistic) |
| AEMET | REST | JSON | API key (free) | 50 reg/min | Yes (environment) |
| CNIG/IDEA | OGC API/WFS | GeoJSON/GML | None | Undeclared | Yes (geoespatial) |
| MITECO | CKAN/REST | JSON/RDF | None | Undeclared | Yes (environment) |
Figure 1. Comparative table of the APIs from various public agencies discussed in this post. Source: Compiled by the author – datos.gob.es.
The availability of public APIs isn't just a matter of technical convenience. From a data perspective, these interfaces enable three critical capabilities:
- Pipeline automation: the periodic ingestion of public data can be orchestrated with standard tools (Airflow, Prefect, cron) without manual intervention or file downloads.
- Reproducibility: API URLs act as static references to authoritative sources, facilitating auditing and traceability in analytics projects.
- Interoperability: the use of open standards (REST, OGC API, DCAT-AP) allows heterogeneous sources to be crossed without depending on proprietary formats.
The public API ecosystem in Spain has different levels of development depending on the body and the sectoral scope. While entities such as the INE and AEMET have consolidated and well-documented interfaces, in other cases access is articulated through CKAN portals or traditional OGC services. The regulation regarding High Value Datasets (HVDs) is driving the progressive adoption of REST standards, although the degree of implementation evolves at different rates. For data professionals, these APIs are already a fully operational source that is increasingly common to integrate into data architectures in engineering and analytical environments.ás habitual en entornos analíticos y de ingeniería.
Content produced by Juan Benavente, a senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.
Documentación
The future new version of the Technical Standard for Interoperability of Public Sector Information Resources (NTI-RISP) incorporates DCAT-AP-ES as a reference model for the description of data sets and services. This is a key step towards greater interoperability, quality and alignment with European data standards.
This guide aims to help you migrate to this new model. It is aimed at technical managers and managers of public data catalogs who, without advanced experience in semantics or metadata models, need to update their RDF catalog to ensure its compliance with DCAT-AP-ES. In addition, the guidelines in the document are also applicable for migration from other RDF-based metadata models, such as local profiles, DCAT, DCAT-AP or sectoral adaptations, as the fundamental principles and verifications are common.
Why migrate to DCAT-AP-ES?
Since 2013, the Technical Standard for the Interoperability of Public Sector Information Resources has been the regulatory framework in Spain for the management and openness of public data. In line with the European and Spanish objectives of promoting the data economy, the standard has been updated in order to promote the large-scale exchange of information in distributed and federated environments.
This update, which at the time of publication of the guide is in the administrative process, incorporates a new metadata model aligned with the most recent European standards: DCAT-AP-ES. These standards facilitate the homogeneous description of the reusable data sets and information resources made available to the public. DCAT-AP-ES adopts the guidelines of the European metadata exchange scheme DCAT-AP (Data Catalog Vocabulary – Aplication Profile), thus promoting interoperability between national and European catalogues.
The advantages of adopting DCAT-AP-ES can be summarised as follows:
- Semantic and technical interoperability: ensures that different catalogs can understand each other automatically.
- Regulatory alignment: it responds to the new requirements provided for in the NTI-RISP and aligns the catalogue with Directive (EU) 2019/1024 on open data and the re-use of public sector information and Implementing Regulation (EU) 2023/138 establishing a list of specific High Value Datasets or HVD), facilitating the publication of HVDs and associated data services.
- Improved ability to find resources: Makes it easier to find, locate, and reuse datasets using standardized, comprehensive metadata.
- Reduction of incidents in the federation: minimizes errors and conflicts by integrating catalogs from different Administrations, guaranteeing consistency and quality in interoperability processes.
What has changed in DCAT-AP-ES?
DCAT-AP-ES expands and orders the previous model to make it more interoperable, more legally accurate and more useful for the maintenance and technical reuse of data catalogues.
The main changes are:
- In the catalog: It is now possible to link catalogs to each other, record who created them, add a supplementary statement of rights to the license, or describe each entry using records.
- In datasets: New properties are added to comply with regulations on high-value sets, support communication, document provenance and relationships between resources, manage versions, and describe spatial/temporal resolution or website. Likewise, the responsibility of the license is redefined, moving its declaration to the most appropriate level.
- For distributions: Expanded options to indicate planned availability, legislation, usage policy, integrity, packaged formats, direct download URL, own license, and lifecycle status.
A practical and gradual approach
Many catalogs already meet the requirements set out in the 2013 version of NTI-RISP. In these cases, the migration to DCAT-AP-ES requires a reduced adjustment, although the guide also contemplates more complex scenarios, following a progressive and adaptable approach.
The document distinguishes between the minimum compliance required and some extensions that improve quality and interoperability.
It is recommended to follow an iterative strategy: starting from the minimum core to ensure operational continuity and, subsequently, planning the phased incorporation of additional elements, such as data services, contact, applicable legislation, categorization of HVDs and contextual metadata. This approach reduces risks, distributes the effort of adaptation, and favors an orderly transition.
Once the first adjustments have been made, the catalogue can be federated with both the National Catalogue, hosted in datos.gob.es, and the Official European Data Catalogue, progressively increasing the quality and interoperability of the metadata.
The guide is a technical support material that facilitates a basic transition, in accordance with the minimum interoperability requirements. In addition, it complements other reference resources, such as the DCAT-AP-ES Application Profile Model and Implementation Technical Guide, the implementation examples (Migration from NIT-RISP to DCAT-AP-ES and Migration from NTI-RISP to DCAT-AP-ES HHD), and the complementary conventions to the DCAT-AP-ES model that define additional rules to address practical needs.
Blog
Context and need for an update
Data is a key resource in the digital transformation of public administrations. Ensuring its access, interoperability and reuse is fundamental to improve transparency, foster innovation and enable the development of efficient public services centered on citizens.
In this context, the Technical Standard for Interoperability for the Reuse of information Resources (NTI-RISP) is the regulatory framework in Spain for the management and opening of public data since 2013. The standard sets common conditions on selection, identification, description, format, terms of use and provision of documents and information resources produced or held by the public sector, relating to numerous areas of interest such as social, economic, legal, tourism, business, education information, etc., fully complying with the provisions of Law 37/2007, of November 16.
In recent months, the text has been undergoing modernization in line with the European and Spanish objective of boosting the data economy, promoting its large-scale exchange within distributed and federated environments, guaranteeing adequate cybersecurity conditions and respecting European principles and values.
The new standard, currently in the processing stage, refers to a new metadata model aligned with the latest versions of European standards, which facilitate the description of datasets and reusable information resources made publicly available.
This new metadata model, called DCAT-AP-ES, adopts the guidelines of the European metadata exchange schema DCAT-AP (Data Catalog Vocabulary – Application Profile) with some additional restrictions and adjustments. DCAT-AP-ES is aligned with the European standards DCAT-AP 2.1.1 and the extension DCAT-AP-HVD 2.2.0, which incorporates the requirements for High-Value Datasets (HVD) defined by the European Commission.
What is DCAT-AP and how is it applied in Spain?
DCAT-AP is an application profile based on the DCAT vocabulary from the W3C, designed to improve the interoperability of public sector open data catalogues in Europe. Its goal is to provide a common metadata model that facilitates the exchange, aggregation and federation of catalogues from different countries and organizations (interoperability).
DCAT-AP-ES, as the Spanish application profile of DCAT-AP, is designed to adapt to the particulars of the national context, ensuring efficient management of open data at the national, regional and local levels.
DCAT-AP-ES is established as the standard to be considered in the new version of the NTI-RISP, which in turn is framed within the National Interoperability Framework (ENI), regulated by Royal Decree 4/2010, which sets the conditions for the reuse of public sector information in Spain.
Main news in DCAT-AP-ES
The new version of DCAT-AP-ES introduces significant improvements that facilitate interoperability and data management in the digital ecosystem. Among others:
Alignment with DCAT-AP
- Greater compatibility with European open data catalogues by aligning NTI-RISP with the EU standard DCAT-AP.
- Inclusion of advanced properties to improve the description of datasets and data services, to ensure the possibilities indicated below.
Incorporation of metadata for the description of High-Value Datasets (HVD)
- Facilitates compliance with European regulation on high-value data.
- Enables detailed description of data in key sectors such as geospatial, meteorology, earth observation and environment, statistics, mobility and business.
Improvements in the description of data services
- Inclusion of specific metadata to describe APIs and data access services.
- Possibility to express a dataset in different contexts (e.g. geospatial, with a map server, or statistical, with a data API).
Support for provenance and data quality
- Incorporation of new properties to manage lifecycle, versioning and origin.
- Implementation of validation and quality control mechanisms using SHACL, ensuring consistency and structure of metadata in catalogues.
Use of controlled vocabularies and best practices
- Adaptation of standardized vocabularies for licenses, data formats, languages and themes.
- Greater clarity in data classification to facilitate discovery.
Data governance and improved agent management
- Specification of agent roles (creator, publisher) and contact points.
- Enhanced metadata to represent resource provenance.
Validation of conformity and metadata quality
- Guides to help validate metadata that comply with DCAT-AP-ES.
- Validation of DCAT-AP-ES graphs against SHACL templates.
Key benefits of the update
The adoption of DCAT-AP-ES represents a qualitative leap in the management and reuse of open data in Spain. Among its benefits are:
✅ Facilitates the federation of catalogues and the discovery of data.
✅ Improves interoperability with the European open data ecosystem.
✅ Complies with European open data regulations.
✅ Increases metadata quality through validation mechanisms.
✅ Ensures that data are FAIR (Findable, Accessible, Interoperable, Reusable).
Implementation and next steps
When will it come into force?
The new application profile DCAT-AP-ES will be progressively implemented in Spain's open data catalogues. Its application will be mandatory once the modification text of the standard comes into force which, as mentioned earlier, is currently undergoing administrative processing but is already compatible with the datos.gob.es data federator.
Are there supporting materials and resources for implementing DCAT-AP-ES?
The management team of the datos.gob.es platform has developed the DCAT-AP-ES Technical guide and model, available in the datos.gob.es repository.
This repository will be enriched as new needs of users applying the standard are identified. Likewise, help guides and educational resources will be developed to facilitate its adoption by publishing organizations. All the news and resources produced in the context of the application profile will be announced and referenced punctually on datos.gob.es.
Where to find more information?
The updated documentation, guides and resources will be accessible on datos.gob.es and in the associated code repository. At present the following are available:
- DCAT-AP-ES Technical guide and model
- DCAT-AP-ES Conventions
- DCAT-AP-ES Implementation examples
- DCAT-AP-ES Frequently Asked Questions
- DCAT-AP-ES Metadata validation
- DCAT-AP explanatory video: Spanish / English
- datos.gob.es
Learn more in this video:
And this infographic (click to access the interactive and accessible version):

Blog
The European Green Deal (Green Deal) is the European Union's (EU) sustainable growth strategy, designed to drive a green transition that transforms Europe into a just and prosperous society with a modern and competitive economy. Within this strategy, initiatives such as Target 55 (Fit for 55), which aims to reduce EU emissions by at least 55% by 2030, stand out, and the Nature Restoration Regulation(, which sets binding targets to restore ecosystems, habitats and species.
The European Data Strategy positions the EU as a leader in data-driven economies, promoting fundamental values such as privacy and sustainability. This strategy envisages the creation of data spaces sectoral spaces to encourage the availability and sharing of data, promoting its re-use for the benefit of society and various sectors, including the environment.
This article looks at how environmental data spaces, driven by the European Data Strategy, play a key role in achieving the goals of the European Green Pact by fostering the innovative and collaborative use of data.
Green Pact data space from the European Data Strategy
In this context, the EU is promoting the Green Deal Data Space, designed to support the objectives of the Green Deal through the use of data. This data space will allow sharing data and using its full potential to address key environmental challenges in several areas: preservation of biodiversity, sustainable water management, the fight against climate change and the efficient use of natural resources, among others.
In this regard, the European Data Strategy highlights two initiatives:
- On the one hand, the GreenData4all initiative which carries out an update of the INSPIRE directive to enable greater exchange of environmental geospatial data between the public and private sectors, and their effective re-use, including open access to the general public.
- On the other hand, the Destination Earth project proposes the creation of a digital twin of the Earth, using, among others, satellite data, which will allow the simulation of scenarios related to climate change, the management of natural resources and the prevention of natural disasters.
Preparatory actions for the development of the Green Pact data space
As part of its strategy for funding preparatory actions for the development of data spaces, the EU is funding the GREAT project (The Green Deal Data Space Foundation and its Community of Practice). This project focuses on laying the foundations for the development of the Green Deal data space through three strategic use cases: climate change mitigation and adaptation, zero pollution and biodiversity. A key aspect of GREAT is the identification and definition of a prioritised set of high-value environmental data (minimum but scalable set). This approach directly connects this project to the concept of high-value data defined in the European Open Data Directive (i.e. data whose re-use generates not only a positive economic impact, but also social and environmental benefits).. The high-value data defined in the Implementing Regulation include data related to Earth observation and the environment, including data obtained from satellites, ground sensors and in situ data.. These packages cover issues such as air quality, climate, emissions, biodiversity, noise, waste and water, all of which are related to the European Green Pact.
Differentiating aspects of the Green Pact data space
At this point, three differentiating aspects of the Green Pact data space can be highlighted.
- Firstly, its clearly multi-sectoral nature requires consideration of data from a wide variety of domains, each with their own specific regulatory frameworks and models.
- Secondly, its development is deeply linked to the territory, which implies the need to adopt a bottom-up approach (bottom-up) starting from concrete and local scenarios.
- Finally, it includes high-value data, which highlights the importance of active involvement of public administrations, as well as the collaboration of the private and third sectors to ensure its success and sustainability.
Therefore, the potential of environmental data will be significantly increased through European data spaces that are multi-sectoral, territorialised and with strong public sector involvement.
Development of environmental data spaces in HORIZON programme
In order to develop environmental data spaces taking into account the above considerations of both the European Data Strategy and the preparatory actions under the Horizon Europe (HORIZON) programme, the EU is funding four projects:
- Urban Data Spaces for Green dEal (USAGE).. This project develops solutions to ensure that environmental data at the local level is useful for mitigating the effects of climate change. This includes the development of mechanisms to enable cities to generate data that meets the FAIR principles (Findable, Accessible, Interoperable, Reusable) enabling its use for environmentally informed decision-making.
- All Data for Green Deal (AD4GD).. This project aims to propose a set of mechanisms to ensure that biodiversity, water quality and air quality data comply with the FAIR principles. They consider data from a variety of sources (satellite remote sensing, observation networks in situ, IoT-connected sensors, citizen science or socio-economic data).
- F.A.I.R. information cube (FAIRiCUBE). The purpose of this project is to create a platform that enables the reuse of biodiversity and climate data through the use of machine learning techniques. The aim is to enable public institutions that currently do not have easy access to these resources to improve their environmental policies and evidence-based decision-making (e.g. for the adaptation of cities to climate change).
- Biodiversity Building Blocks for Policy (B-Cubed).. This project aims to transform biodiversity monitoring into an agile process that generates more interoperable data. Biodiversity data from different sources, such as citizen science, museums, herbaria or research, are considered; as well as their consumption through business intelligence models, such as OLAP cubes, for informed decision-making in the generation of adequate public policies to counteract the global biodiversity crisis.
Environmental data spaces and research data
Finally, one source of data that can play a crucial role in achieving the objectives of the European Green Pact is scientific data emanating from research results. In this context, the European Union's European Open Science Cloud (EOSC) initiativeis an essential tool. EOSC is an open, federated digital infrastructure designed to provide the European scientific community with access to high quality scientific data and services, i.e. a true research data space. This initiative aims to facilitate interoperability and data exchange in all fields of research by promoting the adoption of FAIR principles, and its federation with the Green Pact data space is therefore essential.
Conclusions
Environmental data is key to meeting the objectives of the European Green Pact. To encourage the availability and sharing of this data, promoting its re-use, the EU is developing a series of environmental data space projects. Once in place, these data spaces will facilitate more efficient and sustainable management of natural resources, through active collaboration between all stakeholders (both public and private), driving Europe's ecological transition.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Entrevista
In this episode we will delve into the importance of three related categories of high-value datasets. These are Earth observation and environmental data, geospatial data and mobility data. To tell us about them, we have interviewed two experts in the field:
- Paloma Abad Power, deputy director of the National Centre for Geographic Information (CNIG).
- Rafael Martínez Cebolla, geographer of the Government of Aragón.
With them we have explored how these high-value datasets are transforming our environment, contributing to sustainable development and technological innovation.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. What are high-value datasets and why are their important?
Paloma Abad Power: According to the regulation, high-value datasets are those that ensure highest socio-economic potential and, for this, they must be easy to find, i.e. they must be accessible, interoperable and usable. And what does this mean? That means that the datasets must have their descriptions, i.e. the online metadata, which report the statistics and their properties, and which can be easily downloaded or used.
In many cases, these data are often reference data, i.e. data that serve to generate other types of data, such as thematic data, or can generate added value.
Rafael Martínez Cebolla: They could be defined as those datasets that represent phenomena that are useful for decision making, for any public policy or for any action that a natural or legal person may undertake.
In this sense, there are already some directives, which are not so recent, such as the Water Framework Directive or the INSPIRE Directive, which motivated this need to provide shared data under standards that drive the sustainable development of our society.
2. These high-value data are defined by a European Directive and an Implementing Regulation which dictated six categories of high-value datasets. On this occasion we will focus on three of them: Earth observation and environmental data, geospatial data and mobility data. What do these three categories of data have in common and what specific datasets do they cover?
Paloma Abad Power: In my opinion, these data have in common the geographical component, i.e. they are data located on the ground and therefore serve to solve problems of different nature and linked to society.
Thus, for example, we have, with national coverage, the National Aerial Orthophotography Plan (PNOA), which are the aerial images, the System of Land Occupation Information (SIOSE), cadastral parcels, boundary lines, geographical names, roads, postal addresses, protected sites - which can be both environmental and also castles, i.e. historical heritage- etc. And these categories cover almost all the themes defined by the annexes of the INSPIRE directive.
Rafael Martínez Cebolla: It is necessary to know what is pure geographic information, with a direct geographic reference, as opposed to other types of phenomena that have indirect geographic references. In today's world, 90% of information can be located, either directly or indirectly. Today more than ever, geographic tagging is mandatory for any corporation that wants to implement a certain activity, be it social, cultural, environmental or economic: the implementation of renewable energies, where I am going to eat today, etc. These high-value datasets enhance these geographical references, especially of an indirect nature, which help us to make a decision.
3. Which agencies publish these high-value datasets? In other words, where could a user locate datasets in these categories?
Paloma Abad Power: It is necessary to highlight the role of the National Cartographic System, which is an action model in which the organisations of the NSA (National State Administration) and the autonomous communities participate. It is coordinating the co-production of many unique products, funded by these organisations.
These products are published through interoperable web services. They are published, in this case, by the National Center for Geographic Information (CNIG), which is also responsible for much of the metadata for these products.
They could be located through the Catalogues of the IDEE (Spatial Data Infrastructure of Spain) or the Official Catalogue of INSPIRE Data and Services, which is also included in datos.gob.es and the European Data Portal.
And who can publish? All bodies that have a legal mandate for a product classified under the Regulation. Examples: all the mapping bodies of the Autonomous Communities, the General Directorate of Cadastre, Historical Heritage, the National Statistics Institute, the Geological and Mining Institute (IGME), the Hydrographic Institute of the Navy, the Ministry of Agriculture, Fisheries and Food (MAPA), the Ministry for Ecological Transition and the Demographic Challenge, etc. There are a multitude of organisations and many of them, as I have mentioned, participate in the National Cartographic System, provide the data and generate a single service for the citizen.
Rafael Martínez Cebolla: The National Cartographic System defines very well the degree of competences assumed by the administrations. In other words, the public administration at all levels provides official data, assisted by private enterprise, sometimes through public procurement.
The General State Administration goes up to scales of 1:25,000 in the case of the National Geographic Institute (IGN) and then the distribution of competencies for the rest of the scales is for the autonomous or local administrations. In addition, there are a number of actors, such as hydrographic confederations, state departments or the Cadastre, which have under their competences the legal obligation to generate these datasets.
For me it is an example of how it should be distributed, although it is true that it is then necessary to coordinate very well, through collegiate bodies, so that the cartographic production is well integrated.
Paloma Abad Power: There are also collaborative projects, such as, for example, a citizen map, technically known as an X, Y, Z map, which consists of capturing the mapping of all organisations at national and local level. That is, from small scales 1:1,000,000 or 1:50,000,000 to very large scales, such as 1:1000, to provide the citizen with a single multi-scale map that can be served through interoperable and standardised web services.
4. Do you have any other examples of direct application of this type of data?
Rafael Martínez Cebolla: A clear example was seen with the pandemic, with the mobility data published by the National Institute of Statistics. These were very useful data for the administration, for decision making, and from which we have to learn much more for the management of future pandemics and crises, including economic crises. We need to learn and develop our early warning systems.
I believe that this is the line of work: data that is useful for the general public. That is why I say that mobility has been a clear example, because it was the citizen himself who was informing the administration about how he was moving.
Paloma Abad Power: I am going to contribute some data. For example, according to statistics from the National Cartographic System services, the most demanded data are aerial images and digital terrain models. In 2022 there were 8 million requests and in 2023 there were 19 million requests for orthoimages alone.
Rafael Martínez Cebolla: I would like to add that this increase is also because things are being done well. On the one hand, discovery systems are improved. My general feeling is that there are many successful example projects, both from the administration itself and from companies that need this basic information to generate their products.
There was an application that was generated very quickly with de-escalation - you went to a website and it told you how far you could walk through your municipality - because people wanted to get out and walk. This example arises from spatial data that have moved out of the public administration. I believe that this is the importance of successful examples, which come from people who see a compelling need.
5. And how do you incentivise such re-use?
Rafael Martínez Cebolla: I have countless examples. Incentivisation also involves promotion and marketing, something that has sometimes failed us in the public administration. You stick to certain competences and it seems that just putting it on a website is enough. And that is not all.
We are incentivising re-use in two ways. On the one hand, internally, within the administration itself, teaching them that geographic information is useful for planning and evaluating public policies. And I give you the example of the Public Health Atlas of the Government of Aragon, awarded by an Iberian society of epidemiology the year before the pandemic. It was useful for them to know what the health of the Aragonese was like and what preventive measures they had to take.
As for the external incentives, in the case of the Geographic Institute of Aragon, it was seen that the profile entering the geoportal was very technical. The formats used were also very technical, which meant that the general public was not reached. To solve this problem, we promoted portals such as the IDE didactica, a portal for teaching geography, which reaches any citizen who wants to learn about the territory of Aragon.
Paloma Abad Power: I would like to highlight the economic benefit of this, as was shown, for example, in the economic study carried out by the National Centre for Graphic Information with the University of Leuven to measure the economic benefit of the Spatial Data Infrastructure of Spain. It measure the benefit of private companies using free and open services, rather than using, for example, Google Maps or other non-open sources..
Rafael Martínez Cebolla: For better and for worse, because the quality of the official data sometimes we wish it were better. Both Paloma in the General State Administration and I in the regional administration sometimes know that there are official data where more money needs to be invested so that the quality of the data would be better and could be reusable.
But it is true that these studies are key to know in which dimension high-value datasets move. That is to say, having studies that report on the real benefit of having a spatial data infrastructure at state or regional level is, for me, key for two things: for the citizen to understand its importance and, above all, for the politician who arrives every N years to understand the evolution of these platforms and the revolution in geospatial information that we have experienced in the last 20 years.
6. The Geographic Institute of Aragon has also produced a report on the advantages of reusing this type of data, is that right?
Rafael Martínez Cebolla: Yes, it was published earlier this year. We have been doing this report internally for three or four years, because we knew we were going to make the leap to a spatial knowledge infrastructure and we wanted to see the impact of implementing a knowledge graph within the data infrastructure. The Geographic Institute of Aragon has made an effort in recent years to analyse the economic benefit of having this infrastructure available for the citizens themselves, not for the administration. In other words, how much money Aragonese citizens save in their taxes by having this infrastructure. Today we know that having a geographic information platform saves approximately 2 million euros a year for the citizens of Aragon.
I would like to see the report for the next January or February, because I think the leap will be significant. The knowledge graph was implemented in April last year and this gap will be felt in the year ahead. We have noticed a significant increase in requests, both for viewing and downloading.
Basically from one year to the next, we have almost doubled both the number of accesses and downloads. This affects the technological component: you have to redesign it. More people are discovering you, more people are accessing your data and, therefore, you have to dedicate more investment to the technological component, because it is being the bottleneck.
7. What do you see as the challenges to be faced in the coming years?
Paloma Abad Power: In my opinion, the first challenge is to get to know the user in order to provide a better service. The technical user, the university students, the users on the street, etc. We are thinking of doing a survey when the user is going to use our geographic information. But of course, such surveys sometimes slow down the use of geographic information. That is the great challenge: to know the user in order to make services more user-friendly, applications, etc. and to know how to get to what they want and give it to them better.
There is also another technical challenge. When the spatial infrastructures began, the technical level was very high, you had to know what a visualisation service was, the metadata, know the parameters, etc. This has to be eliminated, the user can simply say I want, for example, to consult and visualise the length of the Ebro river, in a more user-friendly way. Or for example the word LiDAR, which was the Italian digital model with high accuracy. All these terms need to be made much more user-friendly.
Rafael Martínez Cebolla: Above all, let them be discovered. My perception is that we must continue to promote the discovery of spatial data without having to explain to the untrained user, or even to some technicians, that we must have a data, a metadata, a service..... No, no. Basically it is that generalist search engines know how to find high-value datasets without knowing that there is such a thing as spatial data infrastructure.
It is a matter of publishing the data under friendly standards, under accessible versions and, above all, publishing them in permanent URIs, which are not going to change. In other words, the data will improve in quality, but will never change.
And above all, from a technical point of view, both spatial data infrastructures and geoportals and knowledge infrastructures have to ensure that high-value information nodes are related to each other from a semantic and geographical point of view. I understand that knowledge networks will help in this regard. In other words, mobility has to be related to the observation of the territory, to public health data or to statistical data, which also have a geographical component. This geographical semantic relationship is key for me.
Interview clips
1. What are high-value datasets and why are their important?
2. Where can a user locate geographic data?
3. How is the reuse of data with a geographic component being encouraged?
Blog
For some time now we have been hearing about high-value dataset, those datasets whose re-use is associated with considerable benefits for society, the environment and the economy. They were announced in Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on open data and the re-use of public sector information, and subsequently defined in Commission Implementing Regulation (EU) 2023/138 of 21 December 2022 establishing a list of specific high-value datasets and modalities for publication and re-use.
In particular, six categories of dataset are concerned: geospatial, Earth observation and environment, meteorology, statistics, companies and company ownership, and mobility. The detail of these categories and how these datasets should be opened is summarised in the following infographic:

Click on the image or here to expand and access the accessible version
For years, even before the publication of Directive (EU) 2019/1024,Spanish organisations have been working to make this type of datasets available to developers, companies and any citizen who wants to use them, with technical characteristics that facilitate their reuse. However, the Regulation has laid down a number of specific requirements to be met. Below is a summary of the progress made in each category.
Geospatial data
For geospatial data, the implementing regulation (EU) 2023/138 takes into account the categories indicated in Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE), with the exception of agricultural and reference parcels, for which Regulation (EU) 2021/2116 of the European Parliament and of the Council of 2 December 2021applies.
Spain has complied with the INSPIRE Directive for years, thanks to the Law 14/2010 of 5 July 2010 on geographic information infrastructures and services in Spain (LISIGE), which transposes the Directive. Citizens have at their disposal the Official Catalogue of INSPIRE Data and Services of Spain, as well as the catalogues of the Spatial Data Infrastructures of the Autonomous Communities. This has resulted in comprehensive geographical coverage, with exhaustive metadata, which complies with European requirements.
- You can see the dataset currently published by our country in this category on the INSPIRE Geoportal. You can read more about it in this post.
Earth observation and environmental data
For the category of Earth observation and environment data, both the environmental and climate datasets listed in the annexes of the INSPIRE Directive and those produced in the context of a number of legal acts known as priority data, detailed in the Implementing Regulation, are taken into account.
As with the previous category, the fact of having the LISIGE law, which develops INSPIRE and goes further in the obligations set out, has meant that many of these datasets were already available prior to the Implementing Regulation.
- You can see the dataset currently published by Spain in this category in the INSPIRE Geoportal and read more about its publication in Spain here.
Meteorological data
The meteorological thematic category encompasses collections of data on observations measured by various elements, such as weather stations, radars, etc.
In Spain, the State Meteorological Agency (AEMET) has a portal, AEMET OpenData, which was a pioneer in Europe in terms of the availability of open meteorological data. In this portal we find that most of the high-value datasets are already available, grouped in the 14 categories of AEMET OpenData. Work is ongoing to expand the available datasets, their granularity and other technical aspects to further enhance their usability.
- You can see a more detailed review of the current status of the publication status of the datasets in this category in this post.
Statistical data
High statistical value data are covered by a number of legal acts detailed in the Annex to the Implementing Regulation. This category is based on the European Statistical System, which ensures quality and interoperability between states.
In line with this system, Spain has the National Statistical Plan. This plan is developed and implemented through specific annual programmes detailing statistical operations, their objectives, bodies involved and budget appropriations, many of which are aligned with the statistical packages detailed in the Implementing Regulation.
- You can see the detail of the equivalence between the high value data and the datasets published as the result of the National Statistical Plan in this article. You can also see the details of the data published by the National Statistics Institute (INE) here.
Company data and company ownership
Company and company ownership data refer to datasets containing basic company information, including company documents and accounts.
In Spain, information from the Official Gazette of the Mercantile Registry (BORME in Spanish acronyms) is offered openly, with temporal coverage since 2009. However, work continues on opening up more datasets in this category.
Mobility data
The mobility category includes datasets falling under the domain "Transport Networks", included in Annex I of the INSPIRE Directive, together with those referred to in Directive 2005/44/EC of the European Parliament and of the Council of 7 September 2005 on harmonised River Information Services (RIS) on inland waterways in the Community.
As was the case for other categories where high value dataset were already covered by the INSPIRE Directive, Spain has a large amount of dataset available on the Geoportal of the Spatial Data Infrastructure of Spain (IDEE) and the infrastructures of the Autonomous Communities and the infrastructures of the Autonomous Communities.
- You can see the dataset published in the INSPIRE Geoportal and the details of the current situation in this content.
The large amount of dataset published reflects our country's continued commitment to transparency and access to high-value dataset. This is an ongoing effort, the result of the collaboration and involvement of various organisations. Work continues to provide the public with as much quality data as possible.
Blog
The cross-cutting nature of open data on weather and climate data has favoured its use in areas as diverse as precision agriculture, fire prevention or the precision forestry. But the relevance of these datasets lies not only in their direct applicability across multiple industries, but also in their contribution to the challenges related to climate change and environmental sustainability challenges related to climate change and environmental sustainability, which the different action lines of the which the different action lines of the European Green Pact seek to address.
Meteorological data are considered by the European Commission, high value data in accordance with the annex to Regulation 2023/138. In this post we explain which specific datasets are considered to be of high value and the level of availability of this type of data in Spain.
The State Meteorological Agency
In Spain, it corresponds to the State Agency for Meteorology (AEMET) the mission of providing meteorological and climatological services at national level. As part of the Ministry for Ecological Transition and the Demographic Challenge. AEMET leads the related activities of observation, prediction and study of meteorological and climatic conditions, as well as research related to these fields. Its mission includes the provision and dissemination of essential information and forecasts of general interest. This information can also support relevant areas such as civil protection, air navigation, national defence and other sectors of activity.
In order to fulfil this mission, AEMET manages an open data portal that enables the reuse by natural or legal persons, for commercial or non-commercial purposes, of part of the data it generates, prepares and safeguards in the performance of its functions. This portal, known as AEMET OpenData currently offers two modalities for accessing and downloading data in reusable formats:
- General access, which consists of graphical access for the general public through human-friendly interfaces.
- AEMET OpenData API, designed for periodic or scheduled interactions in any programming language, which allows developers to include AEMET data in their own information systems and applications.
In addition, in accordance with Regulation 2023/138, it is envisaged to enable a third access route that would allow re-users to obtain packaged datasets for mass downloading where possible.
In order to access any of the datasets, an access key (API Key) which can be obtained through a simple request in which only an e-mail address is required, without any additional data from the applicant, for the sending of the access key. This is a control measure to ensure that the service is provided with adequate quality and in a non-discriminatory manner for all users.
AEMET OpenData also pioneered the availability of open meteorological data in Europe, reflecting AEMET''s commitment to the continuous improvement of meteorological services, support to the scientific and technological community, and the promotion of a more informed and resilient society in the face of climate challenges.
High-value meteorological datasets
The Annex to Regulation (EU) 2023/138 details five high-value meteorological data sets: weather station observations, validated weather data observations, weather warnings, radar data and numerical prediction model (NMP) data. For each of the sets, the regulation specifies the granularity and the main attributes to be published.
If we analyse the correspondence of the datasets that are currently available grouped in 14 categories in the portal AEMET OpenData portal, with the five datasets that will become mandatory in the coming months, we obtain the conclusions summarised in the following table:
| High-value meteorological datasets | Equivalence in the AEMET OpenData datasets |
|---|---|
| Observation data measured by meteorological stations | The "Conventional Observation" dataset, generated by the Observing Service, provides a large number of hourly variables on liquid and solid precipitation, wind speed and direction, humidity, pressure, air, soil and subsoil temperature, visibility, etc. It is updated twice an hour. In accordance with the Regulation, ten-minute data shall be included with continuous updating. |
| Climate data: validated observations | Within the category "Climatological Values", four datasets on climate data observations are provided: "Daily climatologies", "Monthly/annual climatologies", "Normal values" and "Recorded extremes". The validated dataset provided by the National Climatological Data Bank Service is normally updated once a day with a delay of four days due to validation processes. Attributes available include daily mean temperature, daily precipitation in its standard 07:00 to 07:00 measurement form, daily mean relative humidity, maximum gust direction, etc. In accordance with the Regulation, the inclusion of hourly climatology is planned. |
| Weather warnings | Adverse weather warnings" are provided for the whole of Spain, or segmented by province or Autonomous Community. Both the latest issued and the historical ones since 2018. They provide data on observed and/or forecast severe weather events, from the present time until the next 72 hours. These warnings refer to each meteorological parameter by warning level, for each weather zone defined in the Meteoalert Plan. It is generated by the Adverse Events Functional Groups and the information is available any time an adverse weather event is issued, in line with the Regulation, which requires the dataset to be published "as issued or hourly". In this case, AEMET announces preferential broadcasting hours: 09:00, 11:30, 23:00 y 23:50. |
| Radar data | There are two sets of data: "Regional radar graphic image" and "National radar composition image", which provide reflectivity images, but not the others described in the Regulation (backscatter, polarisation, precipitation, wind and echotop). The dataset is generated by the Land Remote Sensing group and the information is available at a periodicity of 10 minutes instead of the 5 minutes recommended in the Regulation. However, according to the Strategic Plan 2022-2025 of the AEMET the updating of the 15 weather radars and the incorporation of new radars with higher resolution is foreseen, so that in addition to strengthening the early warning system, the obligations of the Regulation can be fulfilled. |
| PMN model data | There are several datasets with forecast information, some available for download and some available on the web: weather forecast, normalised text forecast, specific forecasts, maritime forecast and maps of weather variables maps of the HARMONIE-AROME numerical models for different geographical areas and time periods. However, the AEMET, according to their frequently asked questions document does not currently consider numerical model outputs as open data. AEMET offers the possibility of requesting this or any other dataset through the general register or through the electronic site but this is not an option provided for in the Regulation. In line with this, the inclusion of numerical atmospheric and wave model outputs is foreseen. |
Figure 1: Table showing the equivalence between high value datasets and AEMET OpenData datasets.
The regulation also sets out a number of requirements for publication in terms of format, licence granted, frequency of updating and timeliness, means of access and metadata provided.
In the case of metadata, AEMET publishes, in machine-readable format, the main characteristics of the downloaded file: who prepares it, how often it is prepared, what it contains and its format, as well as information on the data fields (meteorological variable, unit of measurement, etc.). The copyright and terms of use are also specified by means of the legal notice. In this regard, it is foreseen that the current licences will be reviewed to make the datasets available under a licensing scheme compliant with the Regulation, possibly following the recommendation by adopting the license CC BY-SA 4.0.
All in all, it seems that the long track record of the State Meteorological Agency (AEMET) in providing quality open data has put it in a good position to comply with the requirements of the new regulation, making some adjustments to the datasets it already offers through AEMET OpenData to align them with the new obligations. AEMET plans to include in this service the datasets required by the Regulation and which are currently not available, as it adapts its regulations on public prices, as well as the infrastructure and systems that make this possible. Additional datasets that will be available will be ten-minute observation data, hourly climatologies and some data parameters from regional radars and numerical wave and forecast models.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
The European open data portal (data.europa.eu) regularly organises virtual training sessions on topical issues in the open data sector, the regulations they affect and related technologies. In this post, we review the key takeaways from the latest webinar on High Value Datasets (HVD).
Among other issues, this seminar focused on transmitting best practices, as well as explaining the experiences of two countries, Finland and the Czech Republic, which were part of the report "High-value Datasets Best Practices in Europe", published by data.europa.eu, together with Denmark, Estonia, Italy, the Netherlands and Romania. The study was conducted immediately after the publication of the HVD implementation regulation in February 2023.
Best practices linked to the provision of high-value data
After an introduction explaining what high-value data are and what requirements they have to meet, the scope of the report was explained in detail during the webinar. In particular, challenges, good practices and recommendations from member states were identified, as detailed below.
Political and legal framework
- There is a need to foster a government culture that is primarily practical and focused on achievable goals, building on cultural values embedded in government systems, such as transparency.
- A strategic approach based on a broader regulatory perspective is recommended, building on previous efforts to implement far-reaching directives such as INSPIRE or DCAT as a standard for data publication. In this respect, it is appropriate to prioritise actions that overlap with these existing initiatives.
- The use of Creative Commons (CC) licences is recommended.
- On a cross-cutting level, another challenge is to combine compliance with the requirements of high-value datasets with the provisions of the General Data Protection Regulation (GDPR), when dealing with sensitive or personal data.
Governance and processes
- Engaging in strategic partnerships and fostering collaboration at national level is encouraged. Among other issues, it is recommended to coordinate efforts between ministries, agencies responsible for different categories of HVD and other related actors, especially in Member States with decentralised governance structures. To this end, it is important to set up interdisciplinary working groups to facilitate a comprehensive data inventory and to clarify which agency is responsible for which dataset. These groups will enable knowledge sharing and foster a sense of community and shared responsibility, which contributes to the overall success of data governance efforts.
- It is recommended to engage in regular exchanges with other Member States, to share ideas and solutions to common challenges.
- There is a need to promote sustainability through the individual accountability of agencies for their respective datasets. Ensuring the sustainability of national data portals means making sure that metadata is maintained with the resources available.
- It is advisable to develop a comprehensive data governance framework by first assessing available resources, including technical expertise, data management tools and key stakeholder input. This assessment process allows for a clear understanding of the rules, processes and responsibilities necessary for an effective implementation of data governance.
Technical aspects, metadata quality and new requirements
- It is proposed to develop a comprehensive understanding of the specific requirements for HVD. This involves identifying existing datasets to determine their compliance with the standards described in the implementing regulation for HVD. There is a need to build a systemic basis for identifying, improving the quality and availability of data by enhancing the overall value of high-value datasets.
- It is recommended to improve the quality of metadata directly at the data source before publishing them in portals, following the DCAT-AP guidelines for publishing high-value datasets and the controlled vocabularies for the six HVD categories. There is also a need to improve the implementation of APIs and bulk downloads from each data source. Its implementation presents significant challenges due to the scarcity of resources and expertise, making capacity building and resourcing essential.
- It is suggested to strengthen the availability of high-value datasets through external funding or strategic planning. The regulation requires all HVD to be accessible free of charge, so some Member States diversify funding sources by seeking financial support through external channels, e.g. by tapping into European projects. In this respect, it is recommended to adapt business models progressively to offer free data.
Finally, the report highlights a suggested eight-step roadmap for compliance with the HVD implementation regulation:
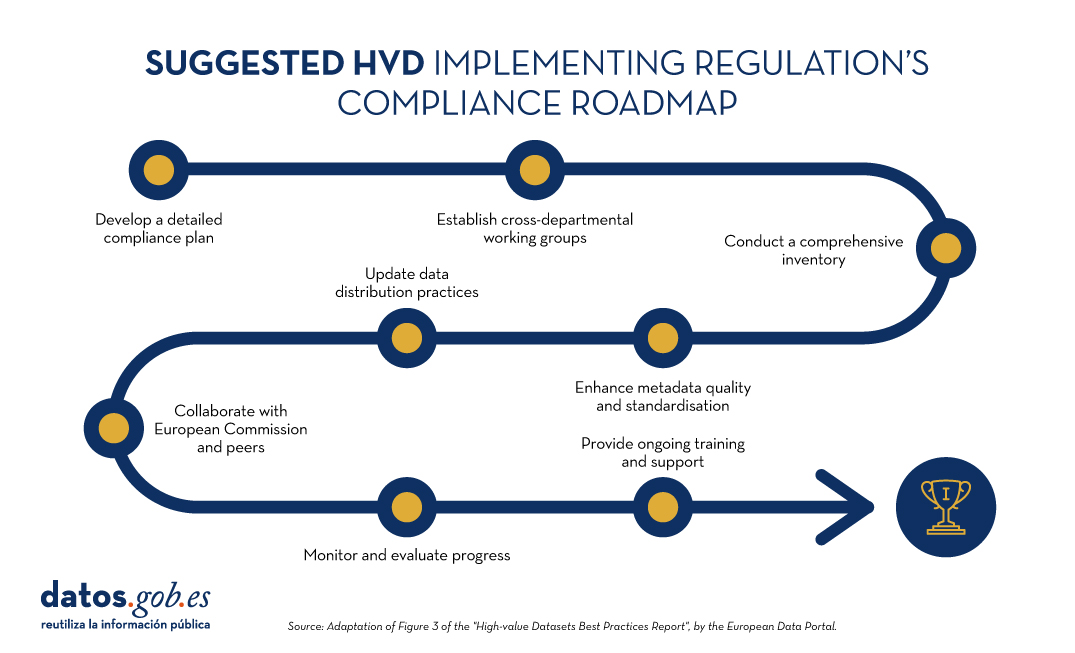
Figure 1: Suggested roadmap for HVD implementation. Adapted from Figure 3 of the European Data Portal's "High-value Datasets Best Practices Report".
The example of the Czech Republic
In a second part of the webinar, the Czech Republic presented their implementation case, which they are approaching from four main tasks: motivation, regulatory implementation, responsibility of public data provider agencies and technical requirements.
- Motivation among the different actors is being articulated through the constitution of working groups.
- Regulatory implementation focuses on dataset analysis and consistency or inconsistency with INSPIRE.
- To boost the accountability of public agencies, knowledge-sharing seminars are being held on linking INSPIRE and HVD using the DCAT-AP standard as a publication pathway.
- Regarding technical requirements, DCAT-AP and INSPIRE requirements are being integrated into metadata practices adapted to their national context. The Czech Republic has developed specifications for local open data catalogues to ensure compatibility with the National Open Data Catalogue. However, its biggest challenge is a strong dependency due to a lack of technical capacities.
The example of Finland
Finland then took the floor. Having pre-existing legislation (INSPIRE and other specific rules on open data and information management inpublic bodies), Finland required only minor adjustments to align with the national transposition of the HVD directive. The challenge is to understand and make INSPIRE and HVD coexist.
Its main strategy is based on the roadmap on information management in public bodies, which ensures harmonisation, interoperability, high quality management and security to implement the principles of open data. In addition, they have established two working groups to address the implementation of HVD:
- The first group, which is a coordinating group of data promoters, focused on practical and technical issues. As legal experts, they also provided guidance on understanding HVD regulation from a legal perspective.
- The second group is an inter-ministerial coordination group, a working group that ensures that there is no conflict or overlap between HVD regulation and national legislation. This group manages the inventory, in spreadsheet format, containing all the elements necessary for an HVD catalogue. By identifying areas where datasets do not meet these requirements, organisations can establish a roadmap to address the gaps and ensure full compliance over time.
The secretariat of the groups is provided by a geospatial data committee. Both have a wide network of stakeholders to articulate discussion and feedback on the measures taken.
Looking to the future, they highlight as a challenge the need to gain more technical and executive level experience.
End of the session
The webinar continued with the participation of Compass Gruppe (Germany), which markets, among other things, data from the Austrian commercial register. They have a portal that offers this data via APIs through a freemium business model.
In addition, it was recalled that Member States are obliged to report to Europe every two years on progress in HVD, an activity that is expected to boost the availability of harmonised federated metadata on the European data portal. The idea is that users will be able to find all HVD in the European Union, using the filtering available on the portal or through SPARQL queries.
The combination of the report's conclusions and the experiences of the rapporteur countries give us good clues to guide the implementation of HVD, in compliance with European regulations. In summary, the implementation of HVD poses the following challenges:
- Support the necessary funding to address the opening-up process.
- Overcoming technical challenges to develop efficient access APIs.
- Achieving a proper coexistence between INSPIRE and the HVD regulation
- Consolidate working groups that function as a robust mechanism for progress and convergence.
- Monitor progress and continuously follow up the process.
- Invest in technical training of staff.
- Create and maintain strong coordination in the face of the complex diversity of data holders.
- Potential quality assurance of high value datasets.
- Agree on a standardisation that is necessary from a business point of view.
By addressing these challenges, we will successfully open up high-value data, driving its re-use for the benefit of society as a whole.
You can re-watch the recording of the session here
Blog
Spain, as part of the European Union, is committed to the implementation of the European directives on open data and re-use of public sector information. This includes the adoption of initiatives such as the Implementing Regulation (EU) 2023/138 issued by the European Commission, which defines specific guidelines for government entities with regard to the availability of High value datasets (HVD). These data are categorised into themes previously detailed in earlier discussions: Geospatial, Earth Observation and Environment, Meteorology, Statistics, Societies and Societal Properties, and Mobility. In this article we will focus on the last group mentioned.
The Mobility category encompasses data collections falling under the domain of "Transport Networks", as demarcated in Annex I of the Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE). In particular, this Directive refers to the requirement to make available to users datasets relating to road, rail, air and inland waterway networks, with their associated infrastructure, connections between different networks and the trans-European transport network, as defined by Decision No 1692/96/EC of the European Parliament and of the Council of 23 July 1996 on Community guidelines for the development of the trans-European transport network.
In addition, it includes the datasets as described in the Directive 2005/44/EC of the European Parliament and of the Council of 7 September 2005 on harmonised River Information Services (RIS) on inland waterways in the Community. The main objective of the Directive is to improve inland waterway traffic and transport, and it applies to canals, rivers, lakes and ports capable of accommodating vessels of between 1,000 and 1,500 tonnes. These datasets include:
| Data type | Inland waterways datasets |
|---|---|
| Static data |
|
| Dynamic data |
|
| Inland electronic and navigational charts (Inland ENC according to the Inland ECDIS Standard) |
|
Figure 1: Table with the high value datasets related to Directive 2005/44/EC for the creation of a trans-European river information network.
In order for all of us to make the most of the information available, the Regulation defines some basic rules on how this data is shared:
- Free and easy to use. The data must be ready to be used and shared with everyone for any purpose by acknowledging and citing the source of the data, as prescribed by the Creative Commons BY 4.0 licence.
- Easy to read and use. Data will be presented in a way that both people and computers can easily understand them and everything will be explained in public.
- Direct and easy access. There will be special ways (called APIs) that allow programs to access data automatically. In addition, the user can alternatively download a lot of information at once.
- Always up to date. It is important that data is up to date, so there will be access to the most recent version. But if the user needs to access previous data, it will also be possible to view previous versions.
- Detailed and precise. Data will be shared in as much detail as possible, to a very fine level of accuracy, so that the whole territory is covered when combined.
- Information on information. There will be "information about the information" (metadata) that will tell everything about the data. The metadata shall contain at least the elements listed in the Annex to Commission Regulation (EC) No 1205/2008 of 3 December 2008.
- Understandable and orderly: It will explain well how the data are organised and what all means, in a way that is easy for everyone to understand (structure and semantics).
- Common language. Data shall use vocabularies, code lists and categories that are recognised and accepted at European or global level.
in Spain, who is responsible for the creation and maintenance of mobility data?
In Spain, the responsibility for the creation and maintenance of mobility data generally lies with different governmental entities, depending on the type of mobility and the territorial scope:
- Level national level. The Ministry of Transport and Sustainable Mobility is the main body in charge of mobility in terms of infrastructure and transport at national level. This would include data on roads, railways, air and maritime transport.
- Regional and local level. Autonomous communities and municipalities also play an important role in urban and regional mobility. They are responsible for urban mobility, public transport and public roads, within their respective jurisdictions.
- Public business entities. There are entities such as ADIF (acronym for Administrador de Infraestructuras Ferroviarias, that is Railway Infrastructure Administrator), AENA (acronym for Aeropuertos Españoles y Navegación Aérea, that is Spanish Airports and Air Navigation), Puertos del Estado (State Ports) and others tentities hat manage specific data related to their field of action in rail, air and maritime transport, respectively.
In Spain, the Ministry of Transport and Sustainable Mobility, in collaboration with the autonomous communities, plays a key role in providing access to a wide range of mobility data. In compliance with INSPIRE and LISIGE (Law 14/2010 of 5 July 2010 on geographic information infrastructures and services in Spain, which transposes the INSPIRE Directive), it offers resources such as the Geoportal of the Spatial Data Infrastructure of Spain (IDEE in Spanish acronyms) where citizens and professionals can access geographic data and services, especially with regard to mobility.
Does Spain comply with the HVD Mobility Regulation?
To solve this question we have to go to the INSPIRE Geoportal where official information classified as high value datasets in Europe is available. Specifically in the mobility category.

Figure 2: Screenshot of the Inspire Geoportal.
As of April 2024 Spain has published the following information in the INSPIRE Geoportal:
- Port service areas in Spain. The port service areas include the cartographic and alphanumeric information of the land service area and water areas I and II. The Spanish State-owned Port System is made up of 46 ports of general interest, managed by 28 Port Authorities.
- Spanish Transport Networks. The Transport Network of the Geographic Reference Information of the National Cartographic System of Spain is a three-dimensional network of national coverage, defined and published in accordance with the INSPIRE Directive, which contemplates five modes of transport: road, rail, inland waterways, air and cable, together with their respective intermodal connections and the infrastructures associated with each mode. This information has the linear geometry of the roads and the punctual geometry of the portals and kilometre points.
- ADIF''s Spanish Rail Transport Network. Public geographic dataset on the adaptation of the Spanish ADIF Common Traamification to the INSPIRE regulations (Transport Networks Annex I).
The publication of these high-value datasets responds positively to the question of Spain''s compliance with the HVD regulation, and is an achievement that reflects Spain''s continued commitment to transparency and access to mobility data.
The joint effort between the Ministry of Transport, Mobility and Urban Agenda, the National Cartographic System and the Autonomous Communities and Public Business Entities underlines the importance of a collaborative approach to mobility information management.
The availability of this data highlights Spain''s commitment to publishing high-value datasets and underlines the importance of continuously improving access to information to optimise inland navigation and mobility data.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
The European Commission Implementing Regulation (EU) 2023/138 sets clear guidelines for public bodies on the availability of high-value datasets within 16 months from 20 January 2023. These high-value high value datasets (High value datasets or HVD) are grouped into the following themes, which were already described in this post: geospatial Earth observation and environment, Meteorology, Statistics, Societies and corporate ownership, and Mobility.
This article focuses on the category of Earth observation and environment, referred to as High Value Datasets for Earth Observation and Environment (HVDOM ).
Earth observation and environmental data in the regulation of high-value arrays
The HVDOM include data obtained in the following areas:
- Spatial or remotely sensed data.
- Ground or in situ data.
In particular, public bodies are faced with the obligation to make available to citizens high-value datasets that appear in various pieces of legislation:
- The environmental and climate datasets listed in the annexes of the Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in Europe ( INSPIRE) indicated in the following visual:
| Inspire theme | Appendix |
|---|---|
| Hydrography | I |
| Protected sites | I |
| Elevations | II |
| Geology | II |
| Land cover | II |
| Orthoimaging | II |
| Areas to management, restrictions or regulations and reporting units | III |
| Biogeographical regions | III |
| Energy resources | III |
| Environmental observation facilities | III |
| Habitats and biotopes | III |
| Land use | III |
| Mineral resources | III |
| Natural hazard zones | III |
| Oceanographic geographical features | III |
| Production and industrial facilities | III |
| Marine regions | III |
| Soils | III |
| Species distribution | III |
2. Data sets produced in the context of legal acts and known as priority data, defined in the table below:
| Ámbito Medioambiental | Actos jurídicos que establecen las principales variables | |
|---|---|---|
| Air | Directive 2008/50/CE | Air Quality Directive |
| Directive 2004/107/CE | It adresses arsenic, cadmium, mercury, nickel and polycyclic aromatic hydrocarbons in ambient air. | |
| Climate | Regulation (UE) 2018/1999 | Governance of the Energy Union and Climate Action. |
| Regulation (CE) 1005/2009 | Substances that deplete the ozone layer. | |
| Emissions | Directive 2010/75/UE | Industrial Emissions Directive. |
| Directive 2012/18/UE | SEVESO III Directive. | |
| Directive 91/676/CEE | Nitrates Directive. | |
| Regulation (CE) 166/2006 | European Pollutant Release and Transfer Register. | |
| Regulation (UE) 2017/852 | Mercury Regulation. | |
| Directive (EU) 2016/2284 | Reduction of national emissions of certain atmospheric pollutants. | |
| Nature protection and biodiversity | Directive 2009/147/CE | Birds directive |
| Directive 92/43/CEE | Habitats Directive | |
| Regulation (UE) 1143/2014 | Invasive Alien Species Directive | |
| Data for the inventory of nationally designated protected areas (NDAAs), national biogeographic regions | EEA Annual Work Programme - Nationally Designated Areas - CDDA National legislation - National biogeographic regions | |
| Noise | Directive 2002/49/CE | Noise Directive |
| Waste | Directive 1999/31/CE | Landfill Directive |
| Directive 2006/21/CE | Directive on extractive waste | |
| Directive 86/278/CEE | Sewage Sludge Directive | |
| Directive 91/271/CEE | Urban Waste Water Treatment Directive | |
| Regulation (UE) 2019/1021 | Persistent Organic Pollutants (POPs) Regulation | |
| Recommendation 2014/70/UE | Recommendation on hydraulic fracturing | |
| Water | Directive 91/271/CEE | Urban Waste Water Treatment Directive |
| Directive 98/83/CE | Drinking Water Directive | |
| Directive 2006/7/CE | Bathing Water Directive | |
| Directive 2000/60/CE | Water Framework Directive | |
| Directive 2006/118/CE | Groundwater Directive | |
| Directive 2008/105/CE | Environmental Quality Standards Directive | |
| Directive 2020/2184/UE | Drinking Water Directive | |
| Directive 2007/60/CE | Floods Directive | |
| Directive 2008/56/CE | Marine Strategy Framework Directive | |
| Horizontal legislation | Directive 2004/35/CE | Prevention and remediation of environmental damage |
| Regulation (UE) 2020/852 | EU Taxonomy | |
At this URL of the INSPIRE register, the list of datasets related to environmental reporting, to be made available by Member States in a step-by-step manner, is published.
To ensure the accessibility and re-use of all these valuable datasets, it is imperative to follow certain provisions to facilitate their publication. Here are the key requirements, which are common to all categories:
- Open licence: All datasets must be made available for reuse under a licence Creative Commons BY 4.0 or any equivalent less restrictive open licence. This encourages the freedom to share and adapt information.
- Open and machine-readable format: Data should be presented in an open, machine-readable format and be publicly documented. This ensures that the information is easily understandable and accessible to any person or automated system.
- Application Programming Interfaces (APIs) and bulk downloading: Application programming interfaces (APIs) should be provided to facilitate programmatic access to data such as direct access download services like Web Feature Services, WFS. In addition, direct bulk downloading of datasets should be possible, allowing flexible options for users according to their needs
- Updated version: The availability of datasets in their most up-to-date version is essential. This ensures that users have access to the latest information, promoting the relevance and accuracy of data. Therefore, it will be necessary to have the most up-to-date datasets as well as historical versions of the available datasets.
- Scale and granularity: Data will need to be published at the available levels of generalisation up to the scale of 1:5000, and covering the whole Member State when combined. If datasets are not available at this scale, but are available at higher spatial resolutions, they shall be provided at the available spatial resolution.
- Metadata: The metadata describing the data concerning the set of themes within the scope of the INSPIRE infrastructure for spatial information shall contain at least the metadata elements set out in the Annex to the Commission Regulation (EC) No 1205/2008 of 3 December 2008of 3 December 2008.
- Semantics: The datasets shall be described in a comprehensive and publicly available online documentation describing at least the data structure and semantics.
- Vocabularies: The datasets shall use Union-controlled or internationally recognised and publicly documented vocabularies and taxonomies. Such as the checklists defined in the INSPIRE register.
In Spain, who is responsible for the creation and maintenance of the Earth Observation and Environment HVDs ?
There are several organisations responsible for these datasets, for example, at the national level, we highlight:
- The National Cartographic System (NCS), which publishes orthoimagery, hydrography, elevations, land use or land cover.
- The Geological and Mining Institute (IGME), responsible for geological data.
- The Spanish Institute of Oceanography (IEO) of the Spanish National Research Council (CSIC) is responsible for oceanographic features.
- The General Directorate of Cultural Heritage and Fine Arts of the Ministry of Culture publishes the protected sites of historical heritage and culture.
- The Ministry for Ecological Transition and Demographic Challenge (MITECO) and the Ministry of Agriculture, Fisheries and Food (MAPA) are responsible for the datasets subject to other environmental legislation, the priority data.
All these organisations play a crucial role in the implementation and enforcement of the INSPIRE Directives INSPIRE Directives y LISIGE (Law on Geographic Information Infrastructures and Services in Spain), both of which are fundamental in the management of geographic and environmental information.
- The INSPIRE Directive was developed in cooperation with the Member States and accession countries of the European Union. Its main objective is to make available the geographical information needed for the management of EU environmental policies.
- In Spain, it is transposed by Law 14/2010, known as LISIGE, which was subsequently amended by Law 2/2018 Law 2/2018. This law regulates geographic data and services, applying to those that refer to a geographic area of the national territory and that have been generated or are under the responsibility of public administrations. These data must be in electronic format and be the responsibility of a public sector administration or body.
Both the SCN an instrument regulated by the LISIGE that publishes geographic information through the coordination of national organisations and the Autonomous Communities, has been set up by the LISIGE. The Spanish and Spanish public administrations, such as MITECO and MAPA, in coordination with the autonomous communities, provide access to a wide range of data and information related to biodiversity, climate change, environmental quality and many other environmental issues. This includes the maintenance of the Spatial Data Infrastructure (SDI) of MITECO and MAPA, which is aligned with the INSPIRE, environmental and LISIGE Directives, publishing the datasets through interoperable services and locatable in the Official Catalogue of INSPIRE Data and Services (CODSI)where geographic data and services regulated by the LISIGE on environmental and Earth observation matters are available .
We highlight, for example, that MITECO is making efforts to ensure the adaptation of the main datasets of the Spanish Inventory of Natural Heritage and Biodiversity to the INSPIRE Directive, covering topics such as biogeographic regions, habitats, biotopes and species distribution.
MITECO plays an essential role in the implementation of the INSPIRE and LISIGE Directives in Spain, providing access to key geographic data and information for the management of environmental policies and the protection of natural heritage, as historical and cultural heritage falls under the Ministry of Culture.
Does Spain comply with the HVD Regulation on Earth observation and environment?
Thanks to the continued work of the Consejo Directivo de la Infraestructura de Información Geográfica de España (CODIIGE) since the implementation of LISIGE, Spain has reached an important achievement. Currently, in the INSPIRE Geoportal portal is currently available a wide variety of information, classified as high-value Earth observation and environmental datasets. This information comes from the resources stored in CODSI.

As of May 2024, Spain has published the following information on the CODSI Geoportal:
- INSPIRE Datasets: The number of datasets published by Spain in each of the mandatory INSPIRE themes is shown below.
| INSPIRE Themes | Number of published datasets |
|---|---|
| Hydrography | 33 |
| Protected sites | 27 |
| Elevations | 20 |
| Geology | 10 |
| Land cover | 60 |
| Orthoimaging | 16 |
| Areas to management, restrictions or regulations and reporting units | 147 |
| Biogeographical regions | 1 |
| Environmental observation facilities | 100 |
| Energy resources | 10 |
| Habitats and biotopes | 9 |
| Land use | 25 |
| Mineral resources | 0 |
| Natural risk areasl | 70 |
| Oceanographic geographical features | 2 |
| Facilities production and industrial | 27 |
| Species distributions | 10 |
| Soil | 17 |
| Marine regions | 9 |
| GENERAL TOTAL | 593 |
See here for the definition of each of the INSPIRE themes.
- Environmental legislation: refers to priority datasets grouped by relevant environmental reporting legislation. The commission called these datasets "Priority Data" to reinforce their importance once the baseline data were already published


https://inspire-geoportal.ec.europa.eu/srv/eng/catalog.search#/qsEnvDom…
All categories are listed below (also indicating those that do not apply to Spain with the acronym N/D):
| Environment | Legal acts establishing the main variables | ||
|---|---|---|---|
| Air | Directive 2008/50/CE | Air Quality Directive | 4 |
| Directive 2004/107/CE | It adresses arsenic, cadmium, mercury, nickel and polycyclic aromatic hydrocarbons in ambient air. | N/D* | |
| Climate | Regulation (UE) 2018/1999 | Governance of the Energy Union and Climate Action. | 0 |
| Regulation (CE) 1005/2009 | Substance that deplete the ozone layer | 0 | |
| Emissions | Directive 2010/75/UE | Industrial Emissions Directive | 1 |
| Directive 2012/18/UE | SEVESO III Directive | 0 | |
| Directive 91/676/CEE | Nitrates Directive | 5 | |
| Regulation (CE) 166/2006 | European Pollutant Release and Transfer Register | 2 | |
| Regulation (UE) 2017/852 | Mercury Regulation | 0 | |
| Directive (EU) 2016/2284 | Reduction of national emissions of certain atmospheric pollutants | 0 | |
| Nature protection and biodiversity | Directive 2009/147/CE | Birds Directive | 3 |
| Directive 92/43/CEE | Habitats Directive | 8 | |
| Regulation (UE) 1143/2014 | Invasive Alien Species Directive | 1 | |
| Data for the inventory of nationally designated protected areas (NDAAs), national biogeographic regions | EEA Annual Work Programme - Nationally Designated Areas - CDDA and National Legislation - National Biogeographic Regions | 0 | |
| Noise | Directive 2002/49/CE | Noise Directive | 0 |
| Waste | Directive 1999/31/CE | Landfill Directive | 2 |
| Directive 2006/21/CE | Directive on extractive waste | 1 | |
| Directive 86/278/CEE | Sewage Sludge Directive | 1 | |
| Directiva 91/271/CEE | Urban Waste Water Treatment Directive | 9 | |
| Regulation (UE) 2019/1021 | Persistent Organic Pollutants (POPs) Regulation | 0 | |
| Recommendation 2014/70/UE | Recomendation on hydraulic fracturing | 0 | |
| Water | Directive 91/271/CEE | Urban Waste Water Treatment Directive | 9 |
| Directive 98/83/CE | Drinking Water Directive | 0 | |
| Directive 2006/7/CE | Bathing Water Directive | 1 | |
| Directive 2000/60/CE | Water Framework Directive | 17 | |
| Directive 2006/118/CE | Groundwater Framework Directive | N/D* | |
| Directive 2008/105/CE | Environmental Quality Standards Directive | 0 | |
| Directive 2020/2184/UE | Drinking Water Directive | 0 | |
| Directive 2007/60/CE | Floods Directive | 31 | |
| Directive 2008/56/CE | Marine Strategy Framework Directive | 4 | |
| Horizontal legislation | Directive 2004/35/CE | Prevention and remediation of environmental damage | N/D* |
| Regulation (UE) 2020/852 | EU Taxonomy | N/D* | |
| Total | 99 | ||
*N/D= No data, these categories do not apply to Spain
The publication of all these high-value datasets is an achievement that reflects our country''s continued commitment to transparency and access to high-quality environmental and Earth observation data.
Spain has made significant progress in complying with the High Value Sets of Earth Observation and Environment Regulation, with a remarkable amount of datasets available through the INSPIRE Geoportal. This ranges from Directive 2008/50/EC on air quality to Directive 2008/56/EC on Marine Strategy, reflecting a holistic approach to environmental information management.
Compliance with European Directives and regulations demonstrates Spain''s commitment to transparency and access to high quality environmental information. In addition, efforts to ensure the updating and accessibility of data are highlighted, including the adaptation of the main datasets of the Spanish Inventory of Natural Heritage and Biodiversity to the INSPIRE Directive.
The joint effort between MITECO, MAPA and the National Cartographic System and the autonomous communities underlines the importance of a collaborative approach to the management of environmental information and Earth observation, fundamental in the protection and sustainable development of natural heritage.
In short, we can say that Spain currently complies with the HVD Regulation in almost all categories, but does not comply in the following categories:
No API or bulk download
- Orthoimaging
- Oceanographic geographical features
Lack of data related to the following environmental legislation:
- Directive 98/83/EC - Drinking Water Directive
- Directive 2002/49/EC - Noise Directive
- Directive 2012/18/EU - SEVESO III Directive
- National legislation - National bio-geographical regions
- Recommendation 2014/70/EU - Recommendation on hydraulic fracturing
- Regulation (EU) 2017/852 - Regulation of Mercury
In summary, Spain has demonstrated a strong commitment to transparency and accessibility to high quality environmental information, complying with most European directives, although it still needs to improve in specific areas such as the provision of APIs and the updating of certain environmental datasets.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.