Blog
La creciente adopción de sistemas de inteligencia artificial (IA) en ámbitos críticos como la administración pública, los servicios financieros o la atención sanitaria ha puesto en primer plano la necesidad de transparencia algorítmica. La complejidad de los modelos de IA que se utilizan para tomar decisiones como la concesión de un crédito o la realización de un diagnóstico médico, especialmente en lo que se refiere a algoritmos de aprendizaje profundo, a menudo da lugar a lo que comúnmente se conoce como el problema de la "caja negra", esto es, la dificultad de interpretar y comprender cómo y por qué un modelo de IA llega a una determinada conclusión. Los LLM o SLM que tanto utilizamos últimamente son un claro ejemplo de un sistema de caja negra donde ni los propios desarrolladores son capaces de prever sus comportamientos.
En sectores regulados, como el financiero o el sanitario, las decisiones basadas en IA pueden afectar significativamente la vida de las personas y, por tanto, no es admisible que generan dudas sobre su posible sesgo o atribución de responsabilidades. Por ello, los gobiernos han comenzado a desarrollar marcos normativos como el Reglamento de Inteligencia Artificial que exigen mayor explicabilidad y supervisión en el uso de estos sistemas con el fin adicional de generar confianza en los avances de la economía digital.
La inteligencia artificial explicable (conocida como XAI, del inglés explainable artificial intelligence) es la disciplina que surge como respuesta a este desafío, proponiendo métodos para hacer comprensibles las decisiones de los modelos de IA. Al igual que en otras áreas relacionados con la inteligencia artificial, como el entrenamiento de los LLM, los datos abiertos son un aliado importante de la inteligencia artificial explicable para construir mecanismos de auditoría y verificación de los algoritmos y sus decisiones.
¿Qué es la IA explicable (XAI)?
La IA explicable se refiere a métodos y herramientas que permiten a los humanos comprender y confiar en los resultados de los modelos de aprendizaje automático. Según el Instituto Nacional de Estándares y Tecnología (NIST) de EE. UU. son cuatro los principios clave de la Inteligencia Artificial Explicable de forma que se pueda garantizar que los sistemas de IA sean transparentes, comprensibles y confiables para los usuarios:
- Explicabilidad (Explainability): la IA debe proporcionar explicaciones claras y comprensibles sobre cómo llega a sus decisiones y recomendaciones.
- Justificabilidad (Meaningful): las explicaciones deben ser significativas y comprensibles para los usuarios.
- Precisión (Accuracy): la IA debe generar resultados precisos y confiables, y la explicación de estos resultados debe reflejar fielmente su desempeño.
- Límites del conocimiento (Knowledge Limits): la IA debe reconocer cuándo no tiene suficiente información o confianza en una decisión y abstenerse de emitir respuestas en esos casos.
A diferencia de los sistemas de IA tradicionales de "caja negra", que generan resultados sin revelar su lógica interna, XAI trabaja sobre la trazabilidad, interpretabilidad y responsabilidad de estas decisiones. Por ejemplo, si una red neuronal rechaza una solicitud de préstamo, las técnicas de XAI pueden destacar los factores específicos que influyeron en la decisión. De este modo, mientras un modelo tradicional simplemente devolvería una calificación numérica del expediente de crédito, un sistema XAI podría decirnos además algo como que "El historial de pagos (23%), la estabilidad laboral (38%) y el nivel de endeudamiento actual (32%) fueron los factores determinantes en la denegación del préstamo”. Esta transparencia es vital no solo para el cumplimiento normativo, sino también para fomentar la confianza del usuario y la mejora de los propios sistemas de IA.
Técnicas clave en XAI
El Catálogo de herramientas y métricas IA confiable del Observatorio de Políticas de Inteligencia Artificial de la OCDE (OECD.AI) recopila y comparte herramientas y métricas diseñadas para ayudar a los actores de la IA a desarrollar sistemas confiables que respeten los derechos humanos y sean justos, transparentes, explicables, robustos, seguros y confiables. Por ejemplo, dos metodologías ampliamente adoptadas en XAI son Local Interpretable Model-agnostic Explanations (LIME) y SHapley Additive exPlanations (SHAP).
- LIME aproxima modelos complejos con versiones más simples e interpretables para explicar predicciones individuales. Es una técnica en general útil para interpretaciones rápidas, pero no muy estable en la asignación de la importancia de las variables entre unos ejemplos y otros.
- SHAP cuantifica la contribución exacta de cada variable de entrada a una predicción utilizando principios de teoría de juegos. Se trata de una técnica más precisa y matemáticamente sólida, pero mucho más costosa computacionalmente.
Por ejemplo, en un sistema de diagnóstico médico, tanto LIME como SHAP podrían ayudarnos a interpretar que la edad y la presión arterial de un paciente fueron los principales factores que concluyeron en un diagnóstico de alto riesgo de infarto, aunque SHAP nos daría la contribución exacta de cada variable a la decisión.
Uno de los desafíos más importantes en XAI es encontrar el equilibrio entre la capacidad predictiva de un modelo y su explicabilidad. Por ello suelen utilizarse enfoques híbridos que integren métodos de explicación a posteriori de las decisiones tomadas con modelos complejos. Por ejemplo, un banco podría implementar un sistema de aprendizaje profundo para la detección de fraude, pero usar valores SHAP para auditar sus decisiones y garantizar que no se toman decisiones discriminatorias.
Los datos abiertos en la XAI
Existen, al menos, dos escenarios en los que se puede generar valor combinando datos abiertos con técnicas de inteligencia artificial explicable:
- El primero de ellos es el enriquecimiento y validación de las explicaciones obtenidas con técnicas XAI. Los datos abiertos permiten añadir capas de contexto a muchas explicaciones técnicas, algo que también es válido para la explicabilidad de los modelos de IA. Por ejemplo, si un sistema XAI indica que la contaminación atmosférica influyó en un diagnóstico de asma, vincular este resultado con conjuntos de datos abiertos de calidad del aire de las áreas de residencia de los pacientes permitiría validar si el resultado es correcto.
- La mejora del rendimiento de los propios modelos de IA es otra área en el que los datos abiertos aportan valor. Por ejemplo, si un sistema XAI identifica que la densidad de espacios verdes urbanos afecta significativamente los diagnósticos de riesgo cardiovascular, se podrían utilizar datos abiertos de urbanismo para mejorar la precisión del algoritmo.
Sería ideal que se pudiesen compartir como datos abiertos los conjuntos de datos de entrenamiento de los modelos de IA, de forma que fuese posible verificar el entrenamiento del modelo y replicar los resultados. En todo caso, lo que sí es posible es compartir de forma abierta son metadatos detallados sobre dichos entrenamientos como promueve la iniciativa Model Cards de Google, facilitando así explicaciones post-hoc de las decisiones de los modelos. En este caso se trata de un instrumento más orientado a los desarrolladores que a los usuarios finales de los algoritmos.
En España, en una iniciativa más dirigida a los ciudadanos, pero igualmente destinada a fomentar la transparencia en el uso de algoritmos de inteligencia artificial, la Administración Abierta de Cataluña ha comenzado a publicar fichas comprensibles para cada algoritmo de IA aplicado a los servicios de administración digital. Ya están disponibles algunas, como, por ejemplo, la de los Chatbots conversacionales de la AOC o la de la Videoidentificación para obtener el idCat Móvil.
Ejemplos reales de datos abiertos y XAI
Un artículo reciente publicado en Applied Sciences por investigadores portugueses ejemplifica la sinergia entre XAI y datos abiertos en el ámbito de la predicción de precios inmobiliarios en ciudades inteligentes. La investigación destaca cómo la integración de conjuntos de datos abiertos que abarcan características de propiedades, infraestructuras urbanas y redes de transporte, con técnicas de inteligencia artificial explicable, como el análisis SHAP, permite desentrañar los factores clave que influyen en los valores de las propiedades. Este enfoque pretende apoyar la generación de políticas de planificación urbana que respondan a las necesidades y tendencias evolutivas del mercado inmobiliario, promoviendo un crecimiento sostenible y equitativo de las ciudades.
Otro estudio realizado por investigadores de INRIA (Instituto francés de investigación en ciencias y tecnologías digitales), también sobre datos inmobiliarios, profundiza en los métodos y desafíos asociados a la interpretabilidad en el aprendizaje automático apoyándose en datos abiertos enlazados. El artículo analiza tanto técnicas intrínsecas, que integran la explicabilidad en el diseño del modelo, como métodos post hoc que permiten examinar y explicar las decisiones de sistemas complejos para fomentar la adopción de sistemas de IA transparentes, éticos y confiables.
A medida que la IA continúa evolucionando, las consideraciones éticas y las medidas regulatorias tienen un papel cada vez más relevante en la creación de un ecosistema de IA más transparente y confiable. La inteligencia artificial explicable y los datos abiertos están interconectados en su objetivo de fomentar la transparencia, la confianza y la responsabilidad en la toma de decisiones basadas en IA. Mientras que la XAI ofrece las herramientas para diseccionar la toma de decisiones de la IA, los datos abiertos proporcionan la materia prima no solo para el entrenamiento, sino para comprobar algunas explicaciones de la XAI y mejorar los rendimientos de los modelos. A medida que la IA continúa permeando en cada faceta de nuestras vidas, fomentar esta sinergia contribuirá a construir sistemas que no solo sean más inteligentes, sino también más justos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Desde la semana pasada, ya están disponibles los modelos de lenguaje de inteligencia artificial (IA) entrenados en español, catalán, gallego, valenciano y euskera, que se han desarrollado dentro de ALIA, la infraestructura pública de recursos de IA. A través de ALIA Kit los usuarios pueden acceder a toda la familia de modelos y conocer la metodología utilizada, la documentación relacionada y los conjuntos de datos de entrenamiento y evaluación. En este artículo te contamos sus claves.
¿Qué es ALIA?
ALIA es un proyecto coordinado por el Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS). Su objetivo es proporcionar una infraestructura pública de recursos de inteligencia artificial abiertos y transparentes, capaces de generar valor tanto en el sector público como en el privado.
En concreto, ALIA es una familia de modelos de texto, voz y traducción automática. El entrenamiento de sistemas de inteligencia artificial demanda una gran cantidad de recursos computacionales, ya que es necesario procesar y analizar enormes volúmenes de datos. Estos modelos han sido entrenados en español, una lengua que hablan más de 600 millones de personas en todo el mundo, pero también en las cuatro lenguas cooficiales. Para ello, se ha contado con la colaboración de la Real Academia Española (RAE) y la Asociación de Academias de la Lengua Española, que agrupa a las entidades del español existentes en todo el mundo.
Para el entrenamiento se ha utilizado el MareNostrum 5, uno de los superordenadores más potentes del mundo, que se encuentra en el Barcelona Supercomputing Center. Han sido necesarias miles de horas de trabajo para tratar varios miles de millones de palabras a una velocidad de 314.000 billones de cálculos por segundo.
Una familia de modelos abiertos y transparentes
Con el desarrollo de estos modelos se proporciona una alternativa que incorpora datos locales. Una de las prioridades de ALIA es ser una red abierta y transparente, lo que significa que los usuarios, además de poder acceder a los modelos, tienen la posibilidad de conocer y descargar los conjuntos de datos utilizados y toda la documentación relacionada. Esta documentación facilita la comprensión del funcionamiento de los modelos y, además, detectar más fácilmente en qué fallan, algo fundamental para evitar sesgos y resultados erróneos. La apertura de los modelos y la transparencia de los datos son fundamentales, ya que crea modelos más inclusivos y socialmente justos, que benefician a la sociedad en su conjunto.
Contar con modelos abiertos y transparentes fomenta la innovación, la investigación y democratiza el acceso a la inteligencia artificial, asegurando además que se parte de datos de entrenamiento de calidad.
¿Qué puedo encontrar en ALIA Kit?
A través de ALIA Kit, es posible acceder actualmente a cinco modelos masivos de lenguaje (LLM) de propósito general, de los que dos han sido entrenados con instrucciones de varios corpus abiertos. Igualmente, están disponibles nueve modelos de traducción automática multilingüe, algunos de ellos entrenados desde cero, como uno de traducción automática entre el gallego y el catalán, o entre el euskera y el catalán. Además, se han entrenado modelos de traducción al aranés, el aragonés y el asturiano.
También encontramos los datos y herramientas utilizadas para elaborar y evaluar los modelos de texto, como el corpus textual masivo CATalog, formado por 17,45 mil millones de palabras (alrededor de 23.000 millones de tokens), distribuidos en 34,8 millones de documentos procedentes de una gran variedad de fuentes, que han sido revisados en buena parte manualmente.
Para entrenar los modelos de voz se han utilizado diferentes corpus de voz con transcripción, como, por ejemplo, un conjunto de datos de las Cortes Valencianas con más de 270 horas de grabación de sus sesiones. Igualmente, es posible conocer los corpus utilizados para el entrenamiento de los modelos de traducción automática.
A través del ALIA Kit también está disponible una API gratuita (desde Python, Javascript o Curl), con la que se pueden realizar pruebas.
¿Para qué se pueden usar estos modelos?
Los modelos desarrollados por ALIA están diseñados para ser adaptables a una amplia gama de tareas de procesamiento del lenguaje natural. Sin embargo, cuando se trata de necesidades específicas es preferible utilizar modelos especializados, que permiten obtener mayor precisión y consumen menos recursos.
Como hemos visto, los modelos están disponibles para todos los usuarios interesados, como desarrolladores independientes, investigadores, empresas, universidades o instituciones. Entre los principales beneficiarios de estas herramientas se encuentran los desarrolladores y las pequeñas y medianas empresas, para quienes no es viable desarrollar modelos propios desde cero, tanto por cuestiones económicas como técnicas. Gracias a ALIA pueden adaptar los modelos ya existentes a sus necesidades específicas.
Los desarrolladores encontrarán recursos para crear aplicaciones que reflejen la riqueza lingüística del castellano y de las lenguas cooficiales. Por su parte, las empresas podrán desarrollar nuevas aplicaciones, productos o servicios orientados al amplio mercado internacional que ofrece la lengua castellana, abriendo nuevas oportunidades de negocio y expansión.
Un proyecto innovador financiado con fondos públicos
El proyecto ALIA está financiado íntegramente con fondos públicos con el objetivo de impulsar la innovación y la adopción de tecnologías que generen valor tanto en el sector público como en el privado. Contar con una infraestructura de IA pública democratiza el acceso a tecnologías avanzadas, permitiendo que pequeñas empresas, instituciones y gobiernos aprovechen todo su potencial para innovar y mejorar sus servicios. Además, facilita el control ético del desarrollo de la IA y fomenta la innovación.
ALIA forma parte de la Estrategia de Inteligencia Artificial 2024 de España, que tiene entre sus objetivos dotar al país de las capacidades necesarias para hacer frente a una demanda creciente de productos y servicios IA e impulsar la adopción de esta tecnología, especialmente en el sector público y pymes. Dentro del eje 1 de dicha estrategia, se encuentra la llamada Palanca 3, que se centra en la generación de modelos y corpus para una infraestructura pública de modelos de lenguaje. Con la publicación de esta familia de modelos, se avanza en el desarrollo de recursos de inteligencia artificial en España.
Blog
Los modelos de lenguaje se encuentran en el epicentro del cambio de paradigma tecnológico que está protagonizando la inteligencia artificial (IA) generativa en los últimos dos años. Desde las herramientas con las que interaccionamos en lenguaje natural para generar texto, imágenes o vídeos y que utilizamos para crear contenido creativo, diseñar prototipos o producir material educativo, hasta aplicaciones más complejas en investigación y desarrollo que incluso han contribuido de forma decisiva a la consecución del Premio Nobel de Química de 2024, los modelos de lenguaje están demostrando su utilidad en una gran variedad de aplicaciones, que por otra parte, aún estamos explorando.
Desde que en 2017 Google publicó el influyente artículo "Attention is all you need", donde se describió la arquitectura de los Transformers, tecnología que sustenta las nuevas capacidades que OpenAI popularizó a finales de 2022 con el lanzamiento de ChatGPT, la evolución de los modelos de lenguaje ha sido más que vertiginosa. En apenas dos años, hemos pasado de modelos centrados únicamente en la generación de texto a versiones multimodales que integran la interacción y generación de texto, imágenes y audio.
Esta rápida evolución ha dado lugar a dos categorías de modelos de lenguaje: los SLM (Small Language Models), más ligeros y eficientes, y los LLM (Large Language Models), más pesados y potentes. Lejos de considerarlos competidores, debemos analizar los SLM y LLM como tecnologías complementarias. Mientras los LLM ofrecen capacidades generales de procesamiento y generación de contenido, los SLM pueden proporcionar soporte a soluciones más ágiles y especializadas para necesidades concretas. Sin embargo, ambos comparten un elemento esencial: dependen de grandes volúmenes de datos para su entrenamiento y en el corazón de sus capacidades están los datos abiertos, que son parte del combustible que se utiliza para entrenar estos modelos de lenguaje en los que se basan las aplicaciones de IA generativa.
LLM: potencia impulsada por datos masivos
Los LLM son modelos de lenguaje a gran escala que cuentan con miles de millones, e incluso billones, de parámetros. Estos parámetros son las unidades matemáticas que permiten al modelo identificar y aprender patrones en los datos de entrenamiento, lo que les proporciona una extraordinaria capacidad para generar texto (u otros formatos) coherente y adaptado al contexto de los usuarios. Estos modelos, como la familia GPT de OpenAI, Gemini de Google o Llama de Meta, se entrenan con inmensos volúmenes de datos y son capaces de realizar tareas complejas, algunas incluso para las que no fueron explícitamente entrenados.
De este modo, los LLM son capaces de realizar tareas como la generación de contenido original, la respuesta a preguntas con información relevante y bien estructurada o la generación de código de software, todas ellas con un nivel de competencia igual o superior al de los humanos especializados en dichas tareas y siempre manteniendo conversaciones complejas y fluidas.
Los LLM se basan en cantidades masivas de datos para alcanzar su nivel de desempeño actual: desde repositorios como Common Crawl, que recopila datos de millones de páginas web, hasta fuentes estructuradas como Wikipedia o conjuntos especializados como PubMed Open Access en el campo biomédico. Sin acceso a estos corpus masivos de datos abiertos, la capacidad de estos modelos para generalizar y adaptarse a múltiples tareas sería mucho más limitada.
Sin embargo, a medida que los LLM continúan evolucionando, la necesidad de datos abiertos aumenta para conseguir progresos específicos como:
- Mayor diversidad lingüística y cultural: aunque los LLM actuales manejan múltiples idiomas, en general están dominados por datos en inglés y otros idiomas mayoritarios. La falta de datos abiertos en otras lenguas limita la capacidad de estos modelos para ser verdaderamente inclusivos y diversos. Más datos abiertos en idiomas diversos garantizarían que los LLM puedan ser útiles para todas las comunidades, preservando al mismo tiempo la riqueza cultural y lingüística del mundo.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. Esto, en ocasiones, genera respuestas que perpetúan estereotipos o desigualdades. Incorporar más datos abiertos cuidadosamente seleccionados, especialmente de fuentes que promuevan la diversidad y la igualdad, es fundamental para construir modelos que representen de manera justa y equitativa a diferentes grupos sociales.
- Actualización constante: los datos en la web y en otros recursos abiertos cambian constantemente. Sin acceso a datos actualizados, los LLM generan respuestas obsoletas muy rápidamente. Por ello, incrementar la disponibilidad de datos abiertos frescos y relevantes permitiría a los LLM mantenerse alineados con la actualidad.
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Los datos abiertos permiten que desarrolladores independientes, universidades y pequeñas empresas entrenen y afinen sus propios modelos sin necesidad de costosas adquisiciones de datos. De este modo se democratiza el acceso a la inteligencia artificial y se fomenta la innovación global.
Para solucionar algunos de estos retos, en la nueva Estrategia de Inteligencia Artificial 2024 se han incluido medidas destinadas a generar modelos y corpus en castellano y lenguas cooficiales, incluyendo también el desarrollo de conjuntos de datos de evaluación que consideran la evaluación ética.
SLM: eficiencia optimizada con datos específicos
Por otra parte, los SLM han emergido como una alternativa eficiente y especializada que utiliza un número más reducido de parámetros (generalmente en millones) y que están diseñados para ser ligeros y rápidos. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
Para ello, los SLM también dependen de datos abiertos, pero en este caso, la calidad y relevancia de los conjuntos de datos son más importantes que su volumen, por ello los retos que les afectan están más relacionados con la limpieza y especialización de los datos. Estos modelos requieren conjuntos que estén cuidadosamente seleccionados y adaptados al dominio específico para el que se van a utilizar, ya que cualquier error, sesgo o falta de representatividad en los datos puede tener un impacto mucho mayor en su desempeño. Además, debido a su enfoque en tareas especializadas, los SLM enfrentan desafíos adicionales relacionados con la accesibilidad de datos abiertos en campos específicos. Por ejemplo, en sectores como la medicina, la ingeniería o el derecho, los datos abiertos relevantes suelen estar protegidos por restricciones legales y/o éticas, lo que dificulta su uso para entrenar modelos de lenguaje.
Los SLM se entrenan con datos cuidadosamente seleccionados y alineados con el dominio en el que se utilizarán, lo que les permite superar a los LLM en precisión y especificidad en tareas concretas, como por ejemplo:
- Autocompletado de textos: un SLM para autocompletado en español puede entrenarse con una selección de libros, textos educativos o corpus como los que se impulsarán en la ya mencionada Estrategia de IA, siendo mucho más eficiente que un LLM de propósito general para esta tarea.
- Consultas jurídicas: un SLM entrenado con conjuntos de datos jurídicos abiertos pueden proporcionar respuestas precisas y contextualizadas a preguntas legales o procesar documentos contractuales de forma más eficaz que un LLM.
- Educación personalizada: en el sector educativo, SLM entrenados con datos abiertos de recursos didácticos pueden generar explicaciones específicas, ejercicios personalizados o incluso evaluaciones automáticas, adaptadas al nivel y las necesidades del estudiante.
- Diagnóstico médico: un SLM entrenado con conjuntos de datos médicos, como resúmenes clínicos o publicaciones abiertas, puede asistir a médicos en tareas como la identificación de diagnósticos preliminares, la interpretación de imágenes médicas mediante descripciones textuales o el análisis de estudios clínicos.
Desafíos y consideraciones éticas
No debemos olvidar que, a pesar de los beneficios, el uso de datos abiertos en modelos de lenguaje presenta desafíos significativos. Uno de los principales retos es, como ya hemos mencionado, garantizar la calidad y neutralidad de los datos para que estén libres de sesgos, ya que estos pueden amplificarse en los modelos, perpetuando desigualdades o prejuicios.
Aunque un conjunto de datos sea técnicamente abierto, su utilización en modelos de inteligencia artificial siempre plantea algunas implicaciones éticas. Por ejemplo, es necesario evitar que información personal o sensible se filtre o pueda deducirse de los resultados generados por los modelos, ya que esto podría causar daños a la privacidad de las personas.
También debe tenerse en cuenta la cuestión de la atribución y propiedad intelectual de los datos. El uso de datos abiertos en modelos comerciales debe abordar cómo se reconoce y compensa adecuadamente a los creadores originales de los datos para que sigan existiendo incentivos a los creadores.
Los datos abiertos son el motor que impulsa las asombrosas capacidades de los modelos de lenguaje, tanto en el caso de los SLM como de los LLM. Mientras que los SLM destacan por su eficiencia y accesibilidad, los LLM abren puertas a aplicaciones avanzadas que no hace mucho nos parecían imposibles. Sin embargo, el camino hacia el desarrollo de modelos más capaces, pero también más sostenibles y representativos, depende en gran medida de cómo gestionemos y aprovechemos los datos abiertos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En el vertiginoso mundo de la Inteligencia Artificial (IA) Generativa, encontramos diversos conceptos que se han convertido en fundamentales para comprender y aprovechar el potencial de esta tecnología. Hoy nos centramos en cuatro: los Modelos de Lenguaje Pequeños (SLM, por sus siglas en inglés), los Modelos de Lenguaje Grandes (LLM), la Generación Aumentada por Recuperación (RAG) y el Fine-tuning. En este artículo, exploraremos cada uno de estos términos, sus interrelaciones y cómo están moldeando el futuro de la IA generativa.
Empecemos por el principio. Definiciones.
Antes de sumergirnos en los detalles, es importante entender brevemente qué representa cada uno de estos términos. Los dos primeros conceptos (SLM y LLM) que abordamos, son lo que se conoce cómo modelos del lenguaje. Un modelo de lenguaje es un sistema de inteligencia artificial que entiende y genera texto en lenguaje humano, como lo hacen los chatbots o los asistentes virtuales. Los siguientes dos conceptos (Fine Tuning y RAG), podríamos definirlos cómo técnicas de optimización de estos modelos del lenguaje previos. En definitiva, estás técnicas, con sus respectivos enfoques, que veremos más adelante, mejoran las respuestas y el contenido que devuelven al que pregunta. Vamos a por los detalles:
- SLM (Small Language Models): Modelos de lenguaje más compactos y especializados, diseñados para tareas específicas o dominios concretos.
- LLM (Large Language Models): Modelos de lenguaje de gran escala, entrenados con vastas cantidades de datos y capaces de realizar una amplia gama de tareas lingüísticas.
- RAG (Retrieval-Augmented Generation): Una técnica que combina la recuperación de información relevante con la generación de texto para producir respuestas más precisas y contextualizadas.
- Fine-tuning: El proceso de ajustar un modelo pre-entrenado para una tarea o dominio específico, mejorando su rendimiento en aplicaciones concretas.
Ahora, profundicemos en cada concepto y exploremos cómo se interrelacionan en el ecosistema de la IA Generativa.
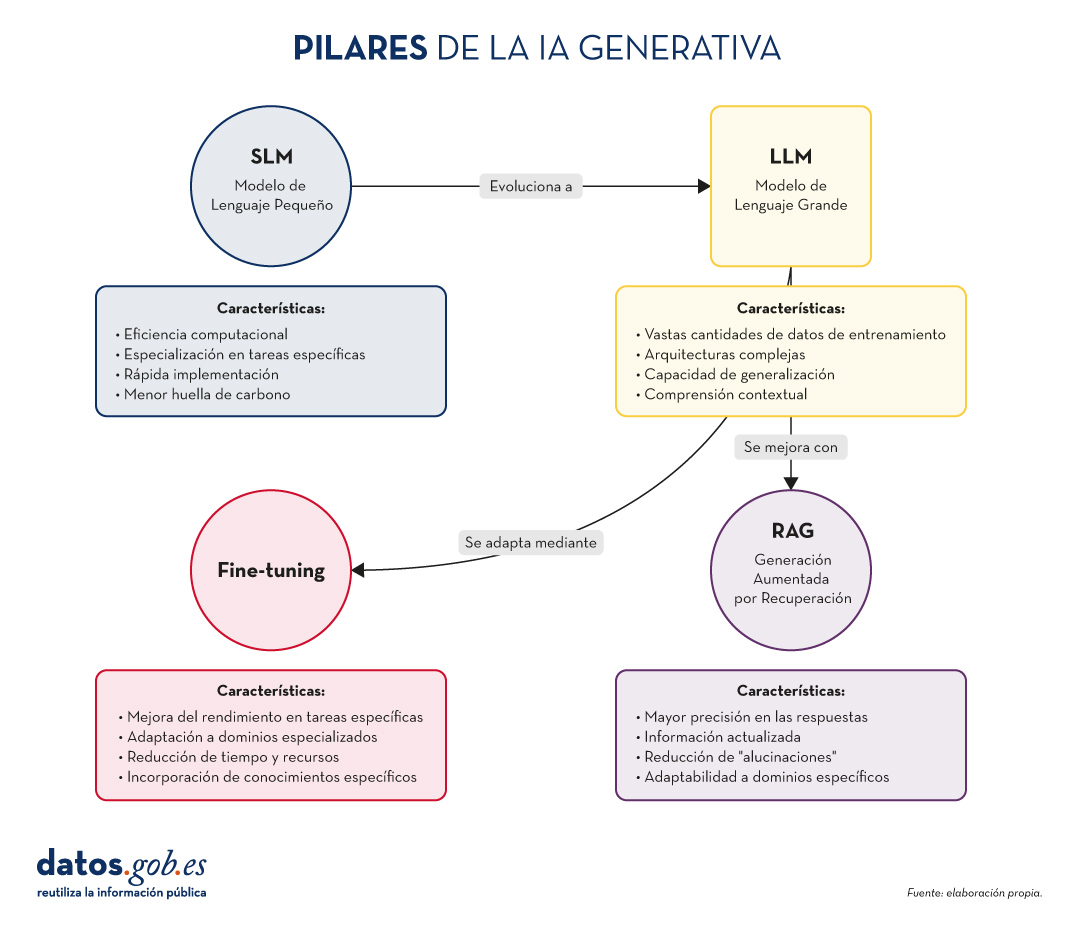
Figura 1. Pilares de la IA genrativa. Elaboración propia.
SLM: La potencia en la especialización
Mayor eficiencia para tareas concretas
Los Modelos de Lenguaje Pequeños (SLM) son modelos de IA diseñados para ser más ligeros y eficientes que sus contrapartes más grandes. Aunque tienen menos parámetros, están optimizados para tareas específicas o dominios concretos.
Características clave de los SLM:
- Eficiencia computacional: requieren menos recursos para su entrenamiento y ejecución.
- Especialización: se centran en tareas o dominios específicos, logrando un alto rendimiento en áreas concretas.
- Rápida implementación: ideal para dispositivos con recursos limitados o aplicaciones que requieren respuestas en tiempo real.
- Menor huella de carbono: al ser más pequeños, su entrenamiento y uso consumen menos energía.
Aplicaciones de los SLM:
- Asistentes virtuales para tareas específicas (por ejemplo, reserva de citas).
- Sistemas de recomendación personalizados.
- Análisis de sentimientos en redes sociales.
- Traducción automática para pares de idiomas específicos.
LLM: El poder de la generalización
La revolución de los Modelos de Lenguaje Grandes
Los LLM han transformado el panorama de la IA Generativa, ofreciendo capacidades sorprendentes en una amplia gama de tareas lingüísticas.
Características clave de los LLM:
- Vastas cantidades de datos de entrenamiento: se entrenan con enormes corpus de texto, abarcando diversos temas y estilos.
- Arquitecturas complejas: utilizan arquitecturas avanzadas, como Transformers, con miles de millones de parámetros.
- Capacidad de generalización: pueden abordar una amplia variedad de tareas sin necesidad de entrenamiento específico para cada una.
- Comprensión contextual: son capaces de entender y generar texto considerando contextos complejos.
Aplicaciones de los LLM:
- Generación de texto creativo (historias, poesía, guiones).
- Respuesta a preguntas complejas y razonamientos.
- Análisis y resumen de documentos extensos.
- Traducción multilingüe avanzada.
RAG: Potenciando la precisión y relevancia
La sinergia entre recuperación y generación
Como ya exploramos en nuestro artículo anterior, RAG combina la potencia de los modelos de recuperación de información con la capacidad generativa de los LLM. Sus aspectos fundamentales son:
Características clave de RAG:
- Mayor precisión en las respuestas.
- Capacidad de proporcionar información actualizada.
- Reducción de "alucinaciones" o información incorrecta.
- Adaptabilidad a dominios específicos sin necesidad de reentrenar completamente el modelo.
Aplicaciones de RAG:
- Sistemas de atención al cliente avanzados.
- Asistentes de investigación académica.
- Herramientas de fact-checking para periodismo.
- Sistemas de diagnóstico médico asistido por IA.
Fine-tuning: Adaptación y especialización
Perfeccionando modelos para tareas específicas
El fine-tuning es el proceso de ajustar un modelo pre-entrenado (generalmente un LLM) para mejorar su rendimiento en una tarea o dominio específico. Sus elementos principales son los siguientes:
Características clave del fine-tuning:
- Mejora significativa del rendimiento en tareas específicas.
- Adaptación a dominios especializados o nichos.
- Reducción del tiempo y recursos necesarios en comparación con el entrenamiento desde cero.
- Posibilidad de incorporar conocimientos específicos de la organización o industria.
Aplicaciones del fine-tuning:
- Modelos de lenguaje específicos para industrias (legal, médica, financiera).
- Asistentes virtuales personalizados para empresas.
- Sistemas de generación de contenido adaptados a estilos o marcas particulares.
- Herramientas de análisis de datos especializadas.
Pongamos algunos ejemplos
A muchos de los que estéis familiarizados con las últimas noticias en IA generativa os sonarán estos ejemplos que citamos a continuación.
SLM: La potencia en la especialización
Ejemplo: BERT para análisis de sentimientos
BERT (Bidirectional Encoder Representations from Transformers) es un ejemplo de SLM cuando se utiliza para tareas específicas. Aunque BERT en sí es un modelo de lenguaje grande, versiones más pequeñas y especializadas de BERT se han desarrollado para análisis de sentimientos en redes sociales.
Por ejemplo, DistilBERT, una versión reducida de BERT, se ha utilizado para crear modelos de análisis de sentimientos en X (Twitter). Estos modelos pueden clasificar rápidamente tweets como positivos, negativos o neutros, siendo mucho más eficientes en términos de recursos computacionales que modelos más grandes.
LLM: El poder de la generalización
Ejemplo: GPT-3 de OpenAI
GPT-3 (Generative Pre-trained Transformer 3) es uno de los LLM más conocidos y utilizados. Con 175 mil millones de parámetros, GPT-3 es capaz de realizar una amplia variedad de tareas de procesamiento de lenguaje natural sin necesidad de un entrenamiento específico para cada tarea.
Una aplicación práctica y conocida de GPT-3 es ChatGPT, el chatbot conversacional de OpenAI. ChatGPT puede mantener conversaciones sobre una gran variedad de temas, responder preguntas, ayudar con tareas de escritura y programación, e incluso generar contenido creativo, todo ello utilizando el mismo modelo base.
Ya a finales de 2020 introducimos en este espacio el primer post sobre GPT-3 como gran modelo del lenguaje. Para los más nostálgicos, podéis consultar el post original aquí.
RAG: Potenciando la precisión y relevancia
Ejemplo: El asistente virtual de Anthropic, Claude
Claude, el asistente virtual desarrollado por Anthropic, es un ejemplo de aplicación que utiliza técnicas RAG. Aunque los detalles exactos de su implementación no son públicos, Claude es conocido por su capacidad para proporcionar respuestas precisas y actualizadas, incluso sobre eventos recientes.
De hecho, la mayoría de asistentes conversacionales basados en IA generativa incorporan técnicas RAG para mejorar la precisión y el contexto de sus respuestas. Así, ChatGPT, la citada Claude, MS Bing y otras similares usan RAG.
Fine-tuning: Adaptación y especialización
Ejemplo: GPT-3 fine-tuned para GitHub Copilot
GitHub Copilot, el asistente de programación de GitHub y OpenAI, es un excelente ejemplo de fine-tuning aplicado a un LLM. Copilot está basado en un modelo GPT (posiblemente una variante de GPT-3) que ha sido específicamente ajustado (fine-tuned) para tareas de programación.
El modelo base se entrenó adicionalmente con una gran cantidad de código fuente de repositorios públicos de GitHub, lo que le permite generar sugerencias de código relevantes y sintácticamente correctas en una variedad de lenguajes de programación. Este es un claro ejemplo de cómo el fine-tuning puede adaptar un modelo de propósito general a una tarea altamente especializada.
Otro ejemplo: en el blog de datos.gob.es, también escribimos un post sobre aplicaciones que utilizaban GPT-3 como LLM base para construir productos concretos ajustados específicamente.
Interrelaciones y sinergias
Estos cuatro conceptos no operan de forma aislada, sino que se entrelazan y complementan en el ecosistema de la IA Generativa:
- SLM y LLM: Mientras que los LLM ofrecen versatilidad y capacidad de generalización, los SLM proporcionan eficiencia y especialización. La elección entre uno u otro dependerá de las necesidades específicas del proyecto y los recursos disponibles.
- RAG y LLM: RAG potencia las capacidades de los LLM al proporcionarles acceso a información actualizada y relevante. Esto mejora la precisión y utilidad de las respuestas generadas.
- Fine-tuning y LLM: El fine-tuning permite adaptar LLM genéricos a tareas o dominios específicos, combinando la potencia de los modelos grandes con la especialización necesaria para ciertas aplicaciones.
- RAG y Fine-tuning: Estas técnicas pueden combinarse para crear sistemas altamente especializados y precisos. Por ejemplo, un LLM con fine-tuning para un dominio específico puede utilizarse como componente generativo en un sistema RAG.
- SLM y Fine-tuning: El fine-tuning también puede aplicarse a SLM para mejorar aún más su rendimiento en tareas específicas, creando modelos altamente eficientes y especializados.
Conclusiones y futuro de la IA
La combinación de estos cuatro pilares está abriendo nuevas posibilidades en el campo de la IA Generativa:
- Sistemas híbridos: combinación de SLM y LLM para diferentes aspectos de una misma aplicación, optimizando rendimiento y eficiencia.
- RAG avanzado: implementación de sistemas RAG más sofisticados que utilicen múltiples fuentes de información y técnicas de recuperación más avanzadas.
- Fine-tuning continuo: desarrollo de técnicas para el ajuste continuo de modelos en tiempo real, adaptándose a nuevos datos y necesidades.
- Personalización a escala: creación de modelos altamente personalizados para individuos o pequeños grupos, combinando fine-tuning y RAG.
- IA Generativa ética y responsable: implementación de estas técnicas con un enfoque en la transparencia, la verificabilidad y la reducción de sesgos.
SLM, LLM, RAG y Fine-tuning representan los pilares fundamentales sobre los que se está construyendo el futuro de la IA Generativa. Cada uno de estos conceptos aporta fortalezas únicas:
- Los SLM ofrecen eficiencia y especialización.
- Los LLM proporcionan versatilidad y capacidad de generalización.
- RAG mejora la precisión y relevancia de las respuestas.
- El Fine-tuning permite la adaptación y personalización de modelos.
La verdadera magia ocurre cuando estos elementos se combinan de formas innovadoras, creando sistemas de IA Generativa más potentes, precisos y adaptables que nunca. A medida que estas tecnologías continúen evolucionando, podemos esperar ver aplicaciones cada vez más sofisticadas y útiles en una amplia gama de campos, desde la atención médica hasta la creación de contenido creativo.
El desafío para los desarrolladores e investigadores será encontrar el equilibrio óptimo entre estos elementos, considerando factores como la eficiencia computacional, la precisión, la adaptabilidad y la ética. El futuro de la IA Generativa promete ser fascinante, y estos cuatro conceptos estarán sin duda en el centro de su desarrollo y aplicación en los años venideros.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En los últimos meses hemos visto cómo los grandes modelos del lenguaje (LLM en sus siglas en inglés) que habilitan las aplicaciones de Inteligencia artificial generativa (GenAI) han ido mejorando en cuanto a su precisión y confiabilidad. Las técnicas de RAG (Retrieval Augmented Generation) nos han permitido utilizar toda la potencia de la comunicación en lenguaje natural (NLP) con las máquinas para explorar bases de conocimiento propias y extraer información procesada en forma de respuestas a nuestras preguntas. En este artículo profundizamos en las técnicas RAG con el objetivo de conocer mejor su funcionamiento y todas las posibilidades que nos ofrecen en el contexto de la IA generativa.
¿Qué son las técnicas RAG?
No es la primera vez que hablamos de las técnicas RAG. En este artículo ya introdujimos el tema, explicando de forma sencilla en qué consisten, cuáles son sus principales ventajas y qué beneficios aporta en el uso de la IA Generativa.
Recordemos por un momento sus principales claves. RAG, del inglés, Retrieval Augmented Generation, viene a traducirse cómo Generación Aumentada por Recuperación (de información). Es decir, RAG consiste en lo siguiente: cuando un usuario realiza una pregunta -normalmente en un interfaz conversacional-, la Inteligencia Artificial (IA), antes de proporcionar la respuesta directa -que podría dar haciendo uso de la base de conocimiento (fijo) con la que ha sido entrenada-, realiza un proceso de búsqueda y procesamiento de información en una base de datos específica proporcionada previamente, complementaria a la del entrenamiento. Cuando hablamos de una base de datos nos referimos a una base de conocimiento previamente preparada a partir de un conjunto de documentos que el sistema utilizará para proporcionar respuestas más precisas. De esta forma, cuando hacen uso de las técnicas RAG, las interfaces conversacionales producen respuestas más precisas y adaptadas a un contexto concreto.
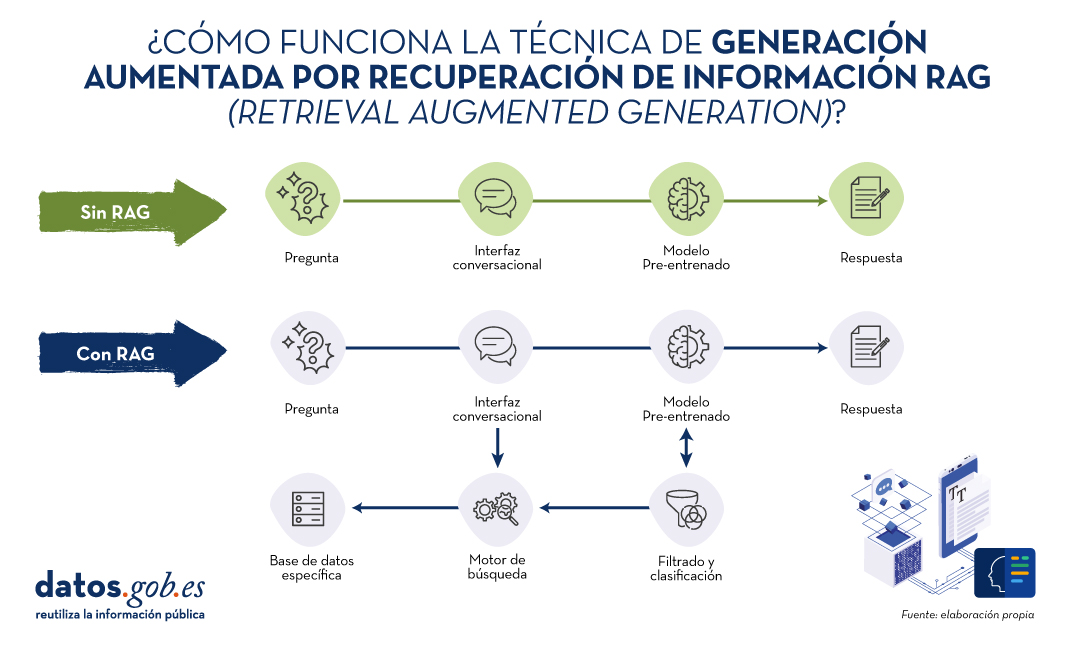
Fuente: Elaboración propia
Diagrama conceptual del funcionamiento de un asistente o interfaz conversacional sin hacer uso de RAG (arriba) y haciendo uso de RAG (abajo).
Haciendo un símil con el ámbito médico, podríamos decir que el uso de RAG es como si un médico, con amplia experiencia y, por lo tanto, altamente entrenado, además de los conocimientos adquiridos durante su formación académica y años de experiencia, tuviera acceso rápido y sin esfuerzo a los últimos estudios, análisis y bases de datos médicas al instante, antes de proporcionar un diagnóstico. La formación académica y los años de experiencia equivalen al entrenamiento del modelo grande del lenguaje (LLM) y el “mágico” acceso a los últimos estudios y bases de datos específicas pueden asimilarse a lo que proporciona las técnicas RAG.
Evidentemente, en el ejemplo que acabamos de poner, la buena práctica médica hace indispensables ambos elementos que el cerebro humano sabe combinar de forma natural, aunque no sin esfuerzo y tiempo, incluso disponiendo de las herramientas digitales actuales, que hacen más sencilla e inmediata la búsqueda de información.
RAG en detalle
Fundamentos de RAG
RAG combina dos fases para conseguir su objetivo: la recuperación y la generación. En la primera, se buscan documentos relevantes en una base de datos que contiene información pertinente a la pregunta planteada (por ejemplo, una base de datos clínicos o una base de conocimiento de preguntas y respuestas más habituales). En la segunda, se utiliza un LLM para generar una respuesta basada en los documentos recuperados. Este enfoque asegura que las respuestas no solo sean coherentes sino también precisas y respaldadas por datos verificables.
Componentes del Sistema RAG
A continuación, vamos a describir los componentes que utiliza un algoritmo de RAG para cumplir con su función. Para ello, en cada componente, vamos a explicar qué función cumple, qué tecnologías se utilizan para cumplir esta función y un ejemplo de la parte del proceso RAG en el que interviene ese componente.
1. Modelo de Recuperación:
- Función: Identifica y recupera documentos relevantes de una base de datos grande en respuesta a una consulta.
- Tecnología: Generalmente utiliza técnicas de recuperación de información (Information Retrieval en inglés o IR) como BM25 o modelos de recuperación basados en embeddings como Dense Passage Retrieval (DPR).
- Proceso: Dada una pregunta, el modelo de recuperación busca en una base de datos para encontrar los documentos más relevantes y los presenta como contexto para la generación de la respuesta.
2. Modelo de Generación:
- Función: Generar respuestas coherentes y contextualmente relevantes utilizando los documentos recuperados.
- Tecnología: Basado en algunos de los principales grandes modelos de Lenguaje (LLM) como GPT-3.5, T5, o BERT, Llama.
- Proceso: El modelo de generación toma la consulta del usuario y los documentos recuperados y utiliza esta información combinada para producir una respuesta precisa.
Proceso Detallado de RAG1
En detalle, un algoritmo RAG realiza las siguientes etapas:
1. Recepción de la pregunta. El sistema recibe una pregunta del usuario. Esta pregunta se procesa para extraer las palabras clave y entender la intención.
2. Recuperación de documentos. La pregunta se envía al modelo de recuperación.
- Ejemplo de Recuperación basada en embeddings:
- La pregunta se convierte en un vector de embeddings utilizando un modelo pre-entrenado.
- Este vector se compara con los vectores de documentos en la base de datos.
- Se seleccionan los documentos con mayor similitud.
- Ejemplo de BM25:
- Se tokeniza la pregunta y se comparan las palabras clave con los índices invertidos de la base de datos.
- Se recuperan los documentos más relevantes según una puntuación de relevancia.
3. Filtrado y clasificación. Los documentos recuperados se filtran para eliminar redundancias y clasificarlos según su relevancia. Pueden aplicarse técnicas adicionales como reranking utilizando modelos más sofisticados.
4. Generación de la respuesta. Los documentos filtrados se concatenan con la pregunta del usuario y se introducen en el modelo de generación. El LLM utiliza la información combinada para generar una respuesta que es coherente y directamente relevante a la pregunta. Por ejemplo, si utilizamos GPT-3.5 como LLM, la entrada al modelo incluye tanto la pregunta del usuario como fragmentos de los documentos recuperados. Finalmente, el modelo genera texto utilizando su capacidad para comprender el contexto de la información proporcionada.
En la siguiente sección vamos a ver algunas aplicaciones en las que la Inteligencia Artificial y los modelos grandes del lenguaje juegan un papel diferenciador y, en concreto, vamos a analizar cómo se benefician estos casos de usos de la aplicación de las técnicas RAG.
Ejemplos de casos de uso que se benefician sustancialmente de usar RAG frente a no usar RAG
1. Atención al Cliente en eCommerce
- Sin RAG:
- Un chatbot básico puede dar respuestas genéricas y potencialmente incorrectas sobre políticas de devolución.
- Ejemplo: Por favor, revise nuestra política de devoluciones en el sitio web.
- Con RAG:
- El chatbot accede a la base de datos de políticas actualizadas y proporciona una respuesta específica y precisa.
- Ejemplo: Puede devolver los productos dentro de 30 días desde la compra, siempre que estén en su embalaje original. Consulte más detalles [aquí].
2. Diagnóstico Médico
- Sin RAG:
- Un asistente virtual de salud podría ofrecer recomendaciones basadas solo en su entrenamiento previo, sin acceso a la información médica más reciente.
- Ejemplo: Es posible que tenga gripe. Consulte a su médico
- Con RAG:
- El asistente puede recuperar información de bases de datos médicas recientes y proporcionar un diagnóstico más preciso y actualizado.
- Ejemplo: Según los síntomas y los estudios recientes publicados en PubMed, podría estar enfrentando una infección viral. Consulte a su médico para un diagnóstico preciso.
3. Asistencia en Investigación Académica
- Sin RAG:
- Un investigador recibe respuestas limitadas a lo que el modelo ya sabe, lo que puede no ser suficiente para temas altamente especializados.
- Ejemplo: Los modelos de crecimiento económico son importantes para entender la economía.
- Con RAG:
- El asistente recupera y analiza artículos académicos relevantes, proporcionando información detallada y precisa.
- Ejemplo: Según el estudio de 2023 en 'Journal of Economic Growth', el modelo XYZ ha mostrado un 20% más de precisión en la predicción de tendencias económicas en mercados emergentes.
4. Periodismo
- Sin RAG:
- Un periodista recibe información genérica que puede no estar actualizada ni ser precisa.
- Ejemplo: La inteligencia artificial está cambiando muchas industrias.
- Con RAG:
- El asistente recupera datos específicos de estudios y artículos recientes, ofreciendo una base sólida para el artículo.
- Ejemplo: Según un informe de 2024 de 'TechCrunch', la adopción de IA en el sector financiero ha aumentado en un 35% en el último año, mejorando la eficiencia operativa y reduciendo costos.
Por supuesto, para la mayoría de los usuarios que hemos experimentado los interfaces conversacionales más accesibles, como ChatGPT, Gemini o Bing, podemos constatar que las respuestas suelen ser completas y bastante precisas cuando se trata de preguntas de ámbito general. Esto es porque estos agentes hacen uso de métodos RAG y otras técnicas avanzadas para proporcionar las respuestas. Sin embargo, no hay que remontarse mucho tiempo atrás en el que los asistentes conversacionales, como Alexa, Siri u OK Google, proporcionaban respuestas extremadamente simples y muy similares a las que explicamos en los ejemplos anteriores cuando no se hace uso de RAG.
Conclusiones
Las técnicas de Generación Aumentada por Recuperación (RAG) mejora la precisión y relevancia de las respuestas de los modelos de lenguaje al combinar recuperación de documentos y generación de texto. Utilizando métodos de recuperación como BM25 o DPR y modelos avanzados de lenguaje, RAG proporciona respuestas más contextualizadas, actualizadas y precisas. En la actualidad, RAG es la clave para el desarrollo exponencial de la IA en el ámbito de los datos privados de empresas y organizaciones. En los próximos meses se espera una adopción masiva de RAG en diversas industrias, optimizando la atención al cliente, diagnósticos médicos, investigación académica y periodismo, gracias a su capacidad para integrar información relevante y actual en tiempo real.
1. Para entender mejor esta sección, recomendamos al lector la lectura de este trabajo previo en el que explicamos de forma didáctica los fundamentos del procesamiento del lenguaje natural y cómo enseñamos a leer a las máquinas.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La era de la digitalización en la que nos encontramos ha llenado nuestra vida diaria de productos de datos o productos basados en datos. En este post te descubrimos en qué consisten y te mostramos una de las tecnologías de datos clave para diseñar y construir este tipo de productos: GraphQL.
Introducción
Empecemos por el principio, ¿qué es un producto de datos? Un producto de datos es un contenedor digital (una pieza de software) que incluye, datos, metadatos y ciertas lógicas funcionales (qué y cómo manejo los datos). El objetivo de este tipo de productos es facilitar la interacción de los usuarios con un conjunto de datos. Algunos ejemplos son:
- Cuadro de mando de ventas: Los negocios online cuentan con herramientas para conocer la evolución de sus ventas, con gráficos que muestran las tendencias y rankings, para ayudar en la toma de decisiones
- Apps de recomendaciones: Los servicios de TV en streaming disponen de funcionalidades que muestran recomendaciones de contenidos basándose en los gustos históricos del usuario.
- Apps de movilidad. Las aplicaciones móviles de los nuevos servicios de movilidad (como Cabify, Uber, Bolt, etc.) combinan datos y metadatos de usuarios y conductores con algoritmos predictivos, como el cálculo dinámico del precio del viaje o la asignación óptima de conductor, con el fin de ofrecer una experiencia única al usuario.
- Apps de salud: Estas aplicaciones hacen un uso masivo de los datos capturados por gadgets tecnológicos (como el propio dispositivo, los relojes inteligentes, etc.) que se pueden integrar con otros datos externos como registros clínicos y pruebas diagnósticas.
- Monitoreo ambiental: Existen apps que capturan y combinan datos de servicios de predicción meteorológica, sistemas de calidad del aire, información de tráfico en tiempo real, etc. para emitir recomendaciones personalizadas a los usuarios (por ejemplo, la mejor hora para programar una sesión de entrenamiento, disfrutar al aire libre o viajar en coche).
Como vemos, los productos de datos nos acompañan en el día a día, sin que muchos usuarios se den siquiera cuenta. Pero, ¿cómo se captura esa gran cantidad de información heterogénea de diferentes sistemas tecnológicos y se combina para proporcionar interfaces y vías de interacción con el usuario final? Aquí es donde GraphQL se posiciona como una tecnología clave para acelerar la creación de productos de datos, al mismo tiempo que mejora considerablemente su flexibilidad y la capacidad de adaptación a las nuevas funcionalidades deseadas por los usuarios.
¿Qué es GraphQL?
GraphQL vio la luz en Facebook en 2012 y se liberó como Open Source en 2015. Puede definirse como un lenguaje y un intérprete de ese lenguaje, de forma que un desarrollador de productos de datos puede inventarse una forma de describir su producto en base a un modelo (una estructura de datos) que hace uso de los datos disponibles mediante APIs.
Antes de la aparición de GraphQL, teníamos (y tenemos) la tecnología REST, que utiliza el protocolo HTTPs para hacer preguntas y obtener respuestas en base a los datos. En 2021, introducimos un post donde presentamos la tecnológica y realizamos un pequeño ejemplo demostrativo sobre su funcionamiento. En él, explicamos REST API como la tecnología estándar que soporta el acceso a datos por programas informáticos. También destacamos cómo REST es una tecnología fundamentalmente diseñada para integrar servicios (como un servicio de autenticación o login).
De forma sencilla, podemos utilizar la siguiente analogía. Es como si REST fuera el mecanismo que nos da acceso a un diccionario completo. Es decir, si necesitamos buscar cualquier palabra, tenemos un método de acceso al diccionario que es la búsqueda alfabética. Es un mecanismo general para encontrar cualquier palabra disponible en el diccionario. Sin embargo, GraphQL nos permite, previamente, crear un modelo de diccionario para nuestro caso de uso (lo que conocemos como “modelo de datos”). Así por ejemplo, si nuestra aplicación final es un recetario, lo que hacemos es seleccionar un subconjunto de palabras del diccionario que estén relacionadas con recetas de cocina.
Para utilizar GraphQL los datos tienen que estar siempre disponibles mediante una API. GraphQL facilita una descripción completa y comprensible de los datos de dicha API, ofreciendo a los clientes (humanos o aplicación) la posibilidad de solicitar exactamente lo que necesitan. Tal y como citan en este post, GraphQL es como un API al que le añadimos una sentencia “Dónde” al estilo SQL.
A continuación, analizamos en detalle las virtudes de GraphQL cuando el foco se pone en el desarrollo de productos de datos.
Beneficios de usar GraphQL en productos de datos:
- Con GraphQL se optimiza de forma considerable la cantidad de datos y consultas sobre las APIs. Las APIs de acceso a determinados datos no están pensadas para un producto (o un caso de uso) específico sino como una especificación general de acceso (véase el ejemplo anterior del diccionario). Esto hace que, en muchas ocasiones, para acceder a un subconjunto de datos disponibles en un API, tengamos que realizar varias consultas encadenadas, descartando la mayor parte de información por el camino. GraphQL optimiza este proceso, puesto que define un modelo de consumo predefinido (aunque adaptable a futuro) por encima de una API técnica. Reducir la cantidad de datos solicitados impacta positivamente en la racionalización de recursos informáticos, como el ancho de banda o el almacenamiento transitorio (cachés), y mejora la velocidad de respuesta de los sistemas.
- Lo anterior, tiene un efecto inmediato sobre la estandarización de acceso a datos. El modelo definido gracias a GraphQL crea un estándar de consumo de datos para una familia de casos de uso. De nuevo, en el contexto de una red social, si lo que queremos es identificar conexiones entre personas, no nos interesa un mecanismo general de acceso a todas las personas de la red, sino un mecanismo que nos permita indicar aquellas personas con las que tengo algún tipo de conexión. Esta especie de filtro en el acceso a los datos, se puede pre-configurar gracias a GraphQL.
- Mejora de seguridad y rendimiento: A través de la definición precisa de consultas y la limitación de acceso a datos sensibles, GraphQL puede contribuir a una aplicación más segura y de mejor rendimiento.
Gracias a estas ventajas, el uso de este lenguaje representa una evolución significativa en la manera de interactuar con datos en aplicaciones web y móviles, ofreciendo ventajas claras sobre enfoques más tradicionales como REST.
La Inteligencia Artificial generativa. Un nuevo superhéroe en la ciudad.
Si el uso del lenguaje GraphQL para acceder a los datos de forma mucho más eficiente y estándar es una evolución significativa para los productos de datos, ¿qué pasará si podemos interactuar con nuestro producto en lenguaje natural? Esto es ahora posible gracias a la explosiva evolución en los últimos 24 meses de los LLMs (Modelos Grandes del Lenguaje) y la IA generativa.
La siguiente imagen muestra el esquema conceptual de un producto de datos, integrado con LLMS: un contenedor digital que incluye datos, metadatos y funciones lógicas que se expresan como funcionalidades para el usuario, junto con las últimas tecnologías para exponer información de forma flexible, como GraphQL y las interfaces conversacionales construidas sobre Modelos Grandes del Lenguaje (LLMs).

¿Cómo se pueden beneficiar los productos de datos de la combinación de GraphQLy el uso de los LLMs?
- Mejora de la experiencia de usuario. Mediante la integración de LLMs, las personas puedan hacer preguntas a los productos de datos usando lenguaje natural. Esto representa un cambio significativo en cómo interactuamos con los datos, haciendo que el proceso sea más accesible y menos técnico. De forma práctica sustituiremos los clicks por frases en el momento de pedir un taxi.
- Mejoras en la seguridad a lo largo de la cadena de interacción en el uso de un producto de datos. Para que esta interacción sea posible, se necesita un mecanismo que conecte de manera eficaz el backend (donde residen los datos) con el frontend (donde se hacen las preguntas). GraphQL se presenta como la solución ideal debido a su flexibilidad y capacidad para adaptarse a las necesidades cambiantes de los usuarios, ofreciendo un enlace directo y seguro entre los datos y las preguntas realizadas en lenguaje natural. Es decir, GraphQL puede pre-seleccionar los datos que se van a mostrar en una consulta, evitando así que la consulta general pueda hacer visibles algunos datos privados o innecesarios para una aplicación particular.
- Potenciando las consultas con Inteligencia Artificial: La inteligencia artificial no solo juega un papel en la interacción en lenguaje natural con el usuario. Se puede pensar en escenarios donde el propio modelo que se define con GraphQL esté asistido por la propia inteligencia artificial. Esto enriquecería las interacciones con los productos de datos, permitiendo una comprensión más profunda y una exploración más rica de la información disponible. Por ejemplo, le podemos pedir a una IA generativa (como ChatGPT) que tome estos datos del catálogo que se exponen como un API y que nos cree un modelo y un endpoint de GraphQL.
En definitiva, la combinación de GraphQL y los LLMs, supone una auténtica evolución en la forma en la que accedemos a los datos. La integración de GraphQL con los LLMs apunta hacia un futuro donde el acceso a los datos puede ser tan preciso como intuitivo, marcando un avance hacia sistemas de información más integrados, accesibles para todos y altamente reconfigurables para los diferentes casos de uso. Este enfoque abre la puerta a una interacción más humana y natural con las tecnologías de información, alineando la inteligencia artificial con nuestras experiencias cotidianas de comunicación usando productos de datos en nuestro día a día.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La estandarización es fundamental para mejorar la eficiencia y la interoperabilidad en el gobierno y la gestión de datos. La adopción de estándares proporciona un marco común para organizar, intercambiar e interpretar los datos, facilitando la colaboración y garantizando la consistencia y calidad de los mismos. Los estándares ISO, elaborados a nivel internacional y las normas UNE, desarrolladas específicamente para el mercado español, son ampliamente reconocidos en este ámbito. Ambos catálogos de buenas prácticas, aunque comparten objetivos similares, difieren en su alcance geográfico y enfoque de desarrollo, permitiendo a las organizaciones seleccionar las normas más adecuadas para sus necesidades y contexto específico.
Ante la publicación, hace unos meses, de las especificaciones UNE 0077, 0078, 0079, 0080, y 0081 sobre gobierno, gestión, calidad, madurez, y evaluación de calidad de datos, los usuarios pueden tener dudas sobre cómo se relacionan estas y las normas ISO que ya tienen implementadas en su organización. Con este post se busca contribuir a paliar estas dudas. Para ello, se presenta un resumen de los principales estándares relacionados con las TIC, poniendo el foco en dos de ellos: ISO 20000 sobre gestión del servicio, e ISO 27000, sobre seguridad y privacidad de la información, y se establece la relación entre estos y las especificaciones UNE.
Normas ISO más habituales relacionadas con el dato
Los estándares ISO tiene la gran ventaja de ser abiertos, dinámicos y agnósticos a las tecnologías subyacentes. Del mismo modo, se encargan de aunar las mejores prácticas consensuadas y decididas por distintos grupos de profesionales e investigadores en cada uno de los campos de actuación. Si ponemos el foco en los estándares relacionados con las TIC, ya existe un marco de estándares sobre gobierno, gestión y calidad de los sistemas de información donde destacan, entre otras:
A nivel de gobierno:
- ISO 38500 para el gobierno de TI.
A nivel de gestión:
- ISO 8000 para sistemas de gestión de datos y datos maestros.
- ISO 20000 para la gestión de los servicios.
- ISO 25000 para la calidad del producto generado (tanto software como datos).
- ISO 27000 e ISO 27701 para la gestión de la seguridad y privacidad de la información.
- ISO 33000 para la evaluación de procesos.
A estos estándares hay que sumar otros que también son de uso habitual en las empresas como:
- Sistema de gestión de calidad basado en ISO 9000
- Sistema de gestión medioambiental propuesto en ISO 14000
Estas normas se usan desde hace años para el gobierno y gestión de las TIC y tienen la gran ventaja de que, al basarse en los mismos principios, pueden usarse perfectamente de manera conjunta. Así, por ejemplo, es muy útil reforzar mutuamente la seguridad de los sistemas de información basados en la familia de normas ISO/IEC 27000 con la gestión de servicios basados en la familia de normas ISO/IEC 20000.
La relación entre las normas ISO y las especificaciones UNE sobre el dato
Las especificaciones UNE 0077, 0078, 0079, 0080 y 0081 complementan las normas ISO existentes sobre gobierno, gestión y calidad de datos al proporcionar directrices específicas y detalladas que se enfocan en los aspectos particulares del entorno español y las necesidades del mercado nacional.
Cuando se plantearon las especificaciones UNE 0077, 0078, 0079, 0080, y 0081, se basaron en los principales estándares ISO, con el fin de integrarse fácilmente en los sistemas de gestión ya disponibles en las organizaciones (mencionados anteriormente), como puede verse en la siguiente figura:

Figura 1. Relación de las especificaciones UNE con los diferentes estándares ISO para las TIC.
Ejemplo de aplicación de la norma UNE 0078
A continuación, se presenta un ejemplo para ver cómo se integran de una forma más clara las normas UNE y las ISO que muchas organizaciones ya tienen implantadas desde hace años, tomando como referencia la UNE 0078. Aunque todas las especificaciones UNE del dato se encuentran entrelazadas con la mayoría de las normas ISO de gobierno, gestión y calidad de TI, la especificación UNE 0078 de gestión de datos está más relacionada con los sistemas de gestión de seguridad de la información (ISO 27000) y gestión de los servicios de TI (ISO 20000). En la Tabla 1 se puede ver la relación para cada proceso con cada estándar ISO.
| Proceso UNE 0078: Gestión de Datos | Relacionado con ISO 20000 | Relacionado con ISO 27000 |
|---|---|---|
| (ProcDat) Procesamiento del dato | ||
| (InfrTec) Gestión de la infraestructura tecnológica | X | X |
| (ReqDat) Gestión de requisitos del dato | X | X |
| (ConfDat) Gestión de la configuración del dato | ||
| (DatHist) Gestión de datos histórico | X | |
| (SegDat) Gestión de la seguridad del dato | X | X |
| (Metdat) Gestión del metadato | X | |
| (ArqDat) Gestión de la arquitectura y diseño del metadato | X | |
| (CIIDat) Compartición, intermediación e integración del dato | X | |
| (MDM) Gestión del dato maestro | ||
| (RRHH) Gestión de recursos humanos | ||
| (CVidDat) Gestión del ciclo de vida del dato | X | |
| D(AnaDat) Análisis del dato esigualdad |
Figura 2. Relación de procesos de UNE 0078 con ISO 27000 e ISO 20000.
Relación de la norma UNE 0078 con ISO 20000
En cuanto a la interrelación ISO 20000-1 con la especificación UNE 0078 a continuación se presenta un caso de uso en el que una organización quiere poner a disposición datos relevantes para su consumo en toda la organización a través de distintos servicios. La implementación integrada de UNE 0078 e ISO 20000-1 permite a las organizaciones:
- Asegurar que los datos críticos para el negocio son gestionados y protegidos adecuadamente.
- Mejorar la eficiencia y efectividad de los servicios de TI, asegurando que la infraestructura tecnológica respalda las necesidades del negocio y de los usuarios finales
- Alinear la gestión de datos y la gestión de servicios de TI con los objetivos estratégicos de la organización, mejorando la toma de decisiones y la competitividad en el mercado
La relación entre ambas se manifiesta en cómo la infraestructura tecnológica gestionada según la UNE 0078 soporta la entrega y gestión de servicios de TI conforme a ISO 20000-1.
Para ello, es necesario contar, al menos, con:
- En primer lugar, para el caso de puesta a disposición de datos como un servicio, es necesario contar con una infraestructura de TI bien gestionada y segura. Esto es esencial, por un lado, para la implementación efectiva de procesos de gestión de servicios de TI, como los incidentes y problemas, y por otro, para asegurar la continuidad del negocio y la disponibilidad de los servicios de TI.
- En segundo lugar, una vez se dispone de la infraestructura, y se es consciente de que el dato va a ser dispuesto para su consumo en algún momento, es necesario gestionar los principios de compartición e intermediación de dicho dato. Para ello, en la especificación UNE 0078, se cuenta con el proceso de Compartición, intermediación e integración del dato. Su principal objetivo es habilitar su adquisición y/o entrega para su consumo o compartición, observando si fuese necesario el despliegue de mecanismos de intermediación, así como la integración del mismo. Este proceso de la UNE 0078 estaría relacionado con varios de los planteados en ISO 20000-1, tales como el proceso de Gestión de relaciones con el negocio, gestión de niveles de servicio, la gestión de la demanda y la gestión de la capacidad de los datos que son puestos a disposición.
Relación de la norma UNE 0078 con ISO 27000
Así mismo, la infraestructura tecnológica creada y gestionada para un objetivo específico debe asegurar unos mínimos en materia de seguridad y privacidad de datos, por lo tanto, será necesaria la implantación de buenas prácticas incluidas en ISO 27000 e ISO 27701 para gestionar la infraestructura desde la perspectiva de la seguridad y privacidad de la información, mostrando así un claro ejemplo de interrelación entre los tres sistemas de gestión: servicios, seguridad y privacidad de la información, y datos.
No solo es primordial que el dato sea puesto al servicio de las organizaciones y ciudadanos de una forma óptima, sino que es necesario además prestar especial atención a la seguridad del dato a lo largo de todo su ciclo de vida durante la puesta en servicio. Es en este punto donde el estándar ISO 27000 aporta todo su valor. El estándar ISO 27000, y en particular ISO 27001 cumple los siguientes objetivos:
- Especifica los requisitos para un sistema de gestión de seguridad de la información (SGSI).
- Se centra en la protección de la información contra accesos no autorizados, la integridad de los datos y la confidencialidad.
- Ayuda a las organizaciones a identificar, evaluar y gestionar los riesgos de seguridad de la información.
En esta línea, su interrelación con la especificación UNE 0078 de Gestión de Datos viene marcada a través del proceso de Gestión de seguridad del dato. A través de la aplicación de los distintos mecanismos de seguridad, se comprueba que la información manejada en los sistemas no tiene accesos no autorizados, manteniendo su integridad y confidencialidad a lo largo de todo el ciclo de vida del dato. Del mismo modo, se puede construir una terna en esta relación con el proceso de gestión de seguridad de datos de la especificación UNE 0078 y con el proceso de UNE 20000-1 de Operación SGSTI- Gestión de Seguridad de la Información.
A continuación, en la Figura 3 se presenta como la especificación UNE 0078 complementa a las actuales ISO 20000 e ISO 27000 aplicado al ejemplo comentado anteriormente.

Figura 3. Relación de procesos UNE 0078 con ISO 20000 e ISO 27000 aplicados al caso de compartición de datos.
A través de los casos anteriores se puede vislumbrar que la gran ventaja de la especificación UNE 0078 es que se integran perfectamente con los sistemas de gestión de seguridad y de gestión de servicios existentes en las organizaciones. Lo mismo ocurre con el resto de las normas UNE 0077, 0079, 0080, y 0081. Por lo tanto, si una organización que ya tiene implantados ISO 20000 o ISO 27000 quiere llevar a cabo iniciativas de gobierno, gestión y calidad de datos, se recomienda el alineamiento entre los distintos sistemas de gestión con las especificaciones UNE, puesto que se refuerzan mutuamente desde el punto de vista de la seguridad, de los servicios y de los datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Tras meses de novedades, no parece que el ritmo de los avances en materia de inteligencia artificial vaya a desacelerarse, sino más bien todo lo contrario. Hace pocas semanas, cuando se repasaban los últimos avances en este campo con motivo del cierre del 2023, se consideraba que la generación de video a partir de instrucciones de texto estaba aún en su infancia. Sin embargo, solo unas semanas después, hemos visto el anuncio de SORA. Con esta herramienta parece que ya está aquí la posibilidad de generar videos realistas, de hasta un minuto, a partir de descripciones textuales.
Cada día, las herramientas a las que vamos teniendo acceso se vuelven más sofisticadas y no deja de asombrarnos su capacidad para realizar tareas que antes parecían exclusivas de la mente humana. Nos hemos acostumbrado muy rápidamente a la generación de texto e imágenes a partir de instrucciones escritas y hemos incorporado estas herramientas a nuestro día a día, para potenciar y mejorar la forma en la que hacemos nuestros trabajos. Con cada nuevo avance, que empuja los límites un poco más lejos de lo que imaginábamos, las posibilidades nos acaban pareciendo infinitas.
Los avances en Inteligencia Artificial, potenciados por los datos abiertos y otras tecnologías como las asociadas a la Web, están ayudando a repensar el futuro de prácticamente todos los campos de nuestra actividad: desde las soluciones para abordar los desafíos del cambio climático, hasta la creación artística, ya sea música, literatura o pintura, pasando por el diagnóstico médico, la agricultura o la generación de confianza para impulsar la creación de valor social y económico.
En este artículo vamos a repasar los avances que impactan en un campo donde, en los próximos años, se producirán, probablemente, interesantes avances gracias a la combinación de inteligencia artificial y datos abiertos. Nos referimos al diseño y planificación de ciudades más inteligentes, sostenibles y habitables para todos sus habitantes.
Planificación y Gestión Urbana
La planificación y gestión urbana es complicada, porque es necesario prever, analizar y dar solución a innumerables interacciones de gran complejidad. Por ello, es razonable esperar importantes avances fruto del análisis de los datos que las ciudades abren cada vez con más frecuencia sobre movilidad, consumo de energía, climatología y contaminación, planificación y uso del suelo, etc. Las nuevas técnicas y herramientas que nos proporciona la inteligencia artificial generativa combinada, por ejemplo, con los agentes inteligentes permitirán una interpretación y simulación más profundas de las dinámicas urbanas.
En este sentido, esta nueva combinación de tecnologías podría ser utilizada por ejemplo para diseñar ciudades más eficientes, sostenibles y habitables, anticipando las necesidades futuras de la población y adaptándose dinámicamente a los cambios en tiempo real. Así, los nuevos modelos urbanos inteligentes se utilizarían para optimizar desde el flujo del tráfico, hasta la distribución de los recursos, gracias a la simulación del comportamiento a través de agentes inteligentes.

Figura 1: Imágenes generadas por Urbanistai.com
Urbanist.ai es uno de los primeros ejemplos de plataforma avanzada de análisis urbano, basada en inteligencia artificial generativa, que pretende transformar la forma en que se conciben actualmente las tareas de planificación urbana. Los servicios que provee actualmente ya permiten la transformación participativa de espacios urbanos a partir de imágenes, pero su ambición va más allá y prevén incorporar nuevas técnicas que redefinan la forma en la que se planifican las ciudades. Existe incluso una versión de UrbanistAI pensada para que los niños puedan introducirse en el mundo de la planificación urbana.
Si vamos un paso más allá, la generación de modelos de ciudades en tres dimensiones es algo que herramientas como InfiniCity ya han puesto a disposición de los usuarios. Aunque aún hay muchos retos que resolver, los resultados son francamente prometedores. Gracias estas tecnologías se podría abaratar sustancialmente la generación de gemelos digitales en los que realizar simulaciones que anticipen problemas antes de su construcción.
Datos disponibles
Sin embargo, como ocurre con otros avances basados en IA Generativa, estas cuestiones no serían posibles sin los datos y, muy especialmente, sin los datos abiertos. Todos los nuevos avances en IA usan una combinación de datos privados y públicos en su entrenamiento, pero en pocos casos se sabe con certeza cuál es el dataset de entrenamiento, ya que no se hace público. Los datos pueden provenir de una gran variedad de fuentes, como sensores IoT, registros gubernamentales o sistemas de transporte público, y son la base para proporcionar una visión integral de cómo funcionan las ciudades y cómo interactúan sus habitantes con el entorno urbano.
La creciente importancia de los datos abiertos para el entrenamiento de estos modelos se refleja en iniciativas como el Grupo de Trabajo sobre activos de datos de IA y Gobierno Abierto, puesto en marcha por el Departamento de Comercio de los Estados Unidos, y que se encargará de preparar los datos públicos abiertos para la Inteligencia Artificial. Esto significa que no sólo tengan formatos legibles por máquinas, sino que también cuenten con metadatos que sean comprensibles por máquinas. Con los datos abiertos enriquecidos por metadatos y organizados en formatos interpretables, podría conseguirse que los modelos de inteligencia artificial arrojasen resultados mucho más precisos.
Una fuente de datos básica y de larga trayectoria es OpenStreetmap (OSM), un proyecto colaborativo que pone a disposición de la comunidad un mapa libre y editable con datos geográficos abiertos a nivel global. Incluye información detallada sobre calles, plazas, parques, edificios, etc. que resulta crucial como base para el análisis de la movilidad urbana, la planificación del transporte o la gestión de infraestructuras. El inmenso coste de elaborar un recurso de estas características sólo está al alcance de las grandes compañías de tecnología, por lo que su valor es incalculable para todas las iniciativas que lo utilizan como base.

Figura 2: Imágenes de OpenStreetmap (OSM)
Otros conjuntos de datos más específicos como HoliCity, un activo de datos 3D con información estructural rica, que incluye 6.300 vistas del mundo real, están demostrando un gran valor. Por ejemplo, un reciente trabajo científico basado en este conjunto de datos ha demostrado que es posible que un modelo alimentado con millones de imágenes de calles pueda predecir características de un vecindario, como pueden ser el valor de las viviendas o las tasas de criminalidad.
En esta línea, Microsoft ha liberado una extensa colección de contornos de edificios generados automáticamente a partir de imágenes de satélite, cubriendo gran cantidad de países y regiones.

Figura 3: Imágenes de Urban Atlas.
Los Microsoft Building Footprints proporcionan una base detallada para el modelado 3D de ciudades, análisis de densidad urbana, planificación de infraestructuras y gestión de riesgos naturales, que ofrecen una visión precisa de la estructura física de las ciudades.
También disponemos de Urban Atlas, una iniciativa que ofrece un acceso gratuito y abierto a información detallada de uso y cobertura del suelo para más de 788 Áreas Urbanas Funcionales en Europa. Forma parte del programa Copernicus Land Monitoring Service, y proporciona una perspectiva muy valiosa sobre la distribución espacial de las características urbanas, incluyendo áreas residenciales, comerciales, industriales, áreas verdes y cuerpos de agua, mapas de árboles en las calles, mediciones de la altura de los bloques de edificios e, incluso, estimaciones de población.
Riesgos y consideraciones éticas
Sin embargo, no debemos perder de vista los riesgos que supone, al igual que en otros dominios, la incorporación de inteligencia artificial a la planificación y gestión de las ciudades, tal y como se analiza en el informe de Naciones Unidas sobre “Riesgos, Aplicaciones y Gobierno de la IA para las ciudades. Por ejemplo, las preocupaciones sobre la privacidad y la seguridad de la información personal que plantea la recopilación masiva de datos, o el riesgo de sesgos algorítmicos que pueden ahondar en las desigualdades ya existentes. Por ello, resulta fundamental garantizar que la recopilación y el uso de datos se realicen de manera ética y transparente, con un enfoque en la equidad y la inclusión.
Es por ello por lo que, a medida que el diseño de ciudades avanza en la adopción de la inteligencia artificial, el diálogo y la colaboración entre tecnólogos, planificadores urbanos, legisladores y la sociedad en general será clave para asegurar que el desarrollo de ciudades inteligentes se alinea con los valores de sostenibilidad, equidad e inclusión. Solo así podremos garantizar que las ciudades del futuro no solo sean más eficientes y tecnológicamente avanzadas, sino también más humanas y acogedoras para todos sus habitantes.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La alineación de la inteligencia artificial es un término establecido desde los años sesenta, según el que orientamos los objetivos de los sistemas inteligentes en la dirección exacta de los valores humanos. La llegada de los modelos generativos ha vuelto a poner de moda este concepto de alineación, que se vuelve más urgente cuanta más inteligencia y autonomía muestran los sistemas. Sin embargo, no hay alineamiento posible sin una definición anterior, consensuada y precisa de estos valores. El reto hoy es encontrar objetivos enriquecedores donde la aplicación de la IA tenga un efecto positivo y transformador en el conocimiento, la organización social y la convivencia.
El derecho a entender
En este contexto, uno de los grandes pilares de la IA actual, el procesamiento del lenguaje lleva años haciendo aportes de valor a la comunicación clara y, en concreto, al lenguaje claro. Veamos qué son estos conceptos:
- La comunicación clara, como disciplina, tiene como objetivo hacer la información accesible y comprensible para todas las personas, utilizando recursos de redacción, pero también visuales, de diseño, infografía, experiencia de usuario y accesibilidad.
- El lenguaje claro se enfoca en la composición de los textos, con técnicas para presentar las ideas de manera directa y concisa, sin excesos estilísticos ni omisiones de la información fundamental.
Ambos conceptos están estrechamente vinculados con el derecho a entender de las personas.
Antes de chatGPT: aproximaciones analíticas
Antes de la llegada de la IA generativa y la popularización de las capacidades GPT, la inteligencia artificial se aplicaba al lenguaje claro desde un punto de vista analítico, con diferentes técnicas de clasificación y búsqueda de patrones. La principal necesidad entonces era que un sistema pudiera evaluar si un texto era o no comprensible, pero no existía aún la expectativa de que ese mismo sistema pudiera reescribir nuestro texto de una manera más clara. Veamos un par de ejemplos:
Este es el caso de Clara, un sistema de IA analítica disponible en abierto en versión beta. Clara es un sistema mixto: por un lado, ha aprendido qué patrones caracterizan a los textos claros y no claros a partir de la observación de un corpus de pares preparado por especialistas en Comunicación Clara. Por otro lado, maneja nueve métricas diseñadas por lingüistas computacionales para decidir si un texto cumple o no los requisitos mínimos de claridad, por ejemplo, el número medio de palabras por frase, los tecnicismos utilizados o la frecuencia de los conectores. Finalmente, Clara devuelve una puntuación en porcentaje para indicar si el texto escrito está más o menos cerca de ser un texto claro. Esto permite al usuario corregir el texto en función de las indicaciones de Clara y someterlo a evaluación de nuevo.

No obstante, otros sistemas analíticos han establecido una aproximación diferente, como Artext claro. Artext es más parecido a un editor de textos tradicional, y en él podemos redactar nuestro texto y activar una serie de revisiones, como los participios, las nominalizaciones verbales o el uso de la negación. Artext señala en color palabras o expresiones en nuestro texto y nos aconseja en un menú lateral qué tenemos que tener en cuenta al utilizarlas. El usuario puede reescribir el texto hasta que, en las diferentes revisiones, vayan desapareciendo las palabras y expresiones marcadas en color.
Tanto Clara como Artext están especializadas en textos administrativos y financieros, con el fin de ser de utilidad principalmente a la administración pública, las entidades financieras y otras fuentes de textos de difícil comprensión que impactan en la ciudadanía.
La revolución generativa
Las herramientas de IA analítica son útiles y muy valiosas si lo que queremos es evaluar un texto sobre el que necesitamos tener un mayor control. Sin embargo, tras la llegada de chatGPT en noviembre de 2022, las expectativas de los usuarios se sitúan más allá. No solo necesitamos un evaluador, sino que esperamos un traductor, un transformador automático de nuestro texto a una versión más clara. Insertamos la versión original del texto en el chat y, a través de una instrucción directa llamada prompt, le pedimos que lo transforme en un texto más claro y sencillo, comprensible por cualquier persona.

Si necesitamos mayor claridad, solo tenemos que repetir la instrucción y el texto vuelve a simplificarse ante nuestros ojos.

Utilizando IA generativa estamos reduciendo el esfuerzo cognitivo, pero también estamos perdiendo gran parte del control sobre el texto. Principalmente, no vamos a conocer cuáles son las modificaciones que se están realizando y por qué, por lo que podemos incurrir en la pérdida o alteración de información. Si queremos aumentar el control y seguir el rastro de los cambios, eliminaciones y añadidos que realiza chatGPT sobre el texto, podemos utilizar un plug-in como EditGPT, disponible como extensión para Google Chrome, que nos permite llevar un control de cambios similar al de Word en nuestras interacciones con el chat. No obstante, no llegaríamos a entender el fundamento de los cambios realizados, como sí haríamos con herramientas como Clara o Artext diseñadas por profesionales de la lengua. Una opción límite es pedirle al chat que nos justifique cada uno de estos cambios, pero la interacción se convertiría en farragosa, compleja y poco eficiente, sin contar con el entusiasmo excesivo con el que el modelo trataría de justificar sus correcciones.
Ejemplos de clarificación generativa
Más allá de la rapidez en la transformación, la IA generativa presenta otras ventajas frente a la analítica, como ciertos elementos que solo pueden identificarse con capacidades GPT. Por ejemplo, detectar en un texto si una sigla o acrónimo ha sido desarrollada previamente, o si un tecnicismo está explicado inmediatamente después de su aparición. Esto requiere un análisis semántico muy complejo para la IA analítica o los modelos basados en reglas. En cambio, un gran modelo de lenguaje es capaz de establecer una relación inteligente entre la sigla y su desarrollo, o entre el tecnicismo y su significado, reconocer si esta explicación existe en algún punto del texto, y además añadirla donde sea pertinente.

Datos abiertos para nutrir la clarificación
El acceso universal a los datos abiertos, y especialmente cuando estos se encuentran preparados para el tratamiento computacional, los hace imprescindibles para el entrenamiento de los grandes modelos lingüísticos. Enormes fuentes de información no estructurada como Wikipedia, el proyecto Common Crawl o Gutenberg permiten a los sistemas aprender el funcionamiento del lenguaje. Y, sobre esta base generalista, es posible ajustar los modelos con conjuntos de datos especializados para que sean más precisos en la tarea de clarificar texto.
En la aplicación de la inteligencia artificial generativa al lenguaje claro tenemos el ejemplo perfecto de un fin valioso, útil a la ciudadanía y positivo para el desarrollo social. Más allá de la fascinación que ha despertado, tenemos la oportunidad de utilizar su potencial en un caso de uso que favorece la igualdad y la inclusividad. La tecnología existe, solo nos falta recorrer el difícil camino de la integración.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Enseñar a los ordenadores a entender cómo hablan y escriben los humanos es un viejo desafío en el campo de la inteligencia artificial, conocido como procesamiento de lenguaje natural (PLN). Sin embargo, desde hace poco más de dos años, estamos asistiendo a la caída de este antiguo bastión con la llegada de los modelos grandes del lenguaje (LLM) y los interfaces conversacionales. En este post, vamos a tratar de explicar una de las técnicas clave que hace posible que estos sistemas nos respondan con relativa precisión a las preguntas que les hacemos.
Introducción
En 2020, Patrick Lewis, un joven doctor en el campo de los modelos del lenguaje que trabajaba en la antigua Facebook AI Research (ahora Meta AI Research) publica junto a Ethan Perez de la Universidad de Nueva York un artículo titulado: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks en el que explicaban una técnica para hacer más precisos y concretos los modelos del lenguaje actuales. El artículo es complejo para el público en general. Sin embargo, en su blog, varios de los autores del artículo explican de manera más asequible cómo funciona la técnica del RAG. En este post vamos a tratar de explicarlo de la forma más sencilla posible.
Los modelos grandes del lenguaje o Large Language Models (hay cosas que es mejor no traducir…) son modelos de inteligencia artificial que se entrenan utilizando algoritmos de Deep Learning sobre conjuntos enormes de información generada por humanos. De esta manera, una vez entrenados, han aprendido la forma en la que los humanos utilizamos la palabra hablada y escrita, así que son capaces de ofrecernos respuestas generales y con un patrón muy humano a las preguntas que les hacemos. Sin embargo, si buscamos respuestas precisas en un contexto determinado, los LLM por sí solos no proporcionarán respuestas específicas o habrá una alta probabilidad de que alucinen y se inventen completamente la respuesta. Que los LLM alucinen significa que generan texto inexacto, sin sentido o desconectado. Este efecto plantea riesgos y desafíos potenciales para las organizaciones que utilizan estos modelos fuera del entorno doméstico o cotidiano del uso personal de los LLM. La prevalencia de la alucinación en los LLMs, estimada en un 15% o 20% para ChatGPT, puede tener implicaciones profundas para la reputación de las empresas y la fiabilidad de los sistemas de IA.
¿Qué es un RAG?
Precisamente, las técnicas RAG se han desarrollado para mejorar la calidad de las respuestas en contextos específicos, como por ejemplo, en una disciplina concreta o en base a repositorios de conocimiento privados como bases de datos de empresas.
RAG es una técnica extra dentro de los marcos de trabajo de la inteligencia artificial, cuyo objetivo es recuperar hechos de una base de conocimientos externa para garantizar que los modelos de lenguaje devuelven información precisa y actualizada. Un sistema RAG típico (ver imágen) incluye un LLM, una base de datos vectorial (para almacenar convenientemente los datos externos) y una serie de comandos o preguntas. Es decir, de forma simplificada, cuándo hacemos una pregunta en lenguaje natural a un asistente cómo ChatGPT, lo que ocurre entre la pregunta y la respuesta es algo como:
- El usuario realiza la consulta, también denominada técnicamente prompt.
- El RAG se encarga de enriquecer ese prompt o pregunta con datos y hechos que ha obtenido de una base de datos externa que contiene información relevante relativa a la pregunta que ha realizado el usuario. A esta etapa se le denomina retrieval.
- El RAG se encarga de enviar el prompt del usuario enriquecido o aumentado al LLM que se encarga de generar una respuesta en lenguaje natural aprovechando toda la potencia del lenguaje humano que ha aprendido con sus datos de entrenamiento genéricos, pero también con los datos específicos proporcionados en la etapa de retrieval.
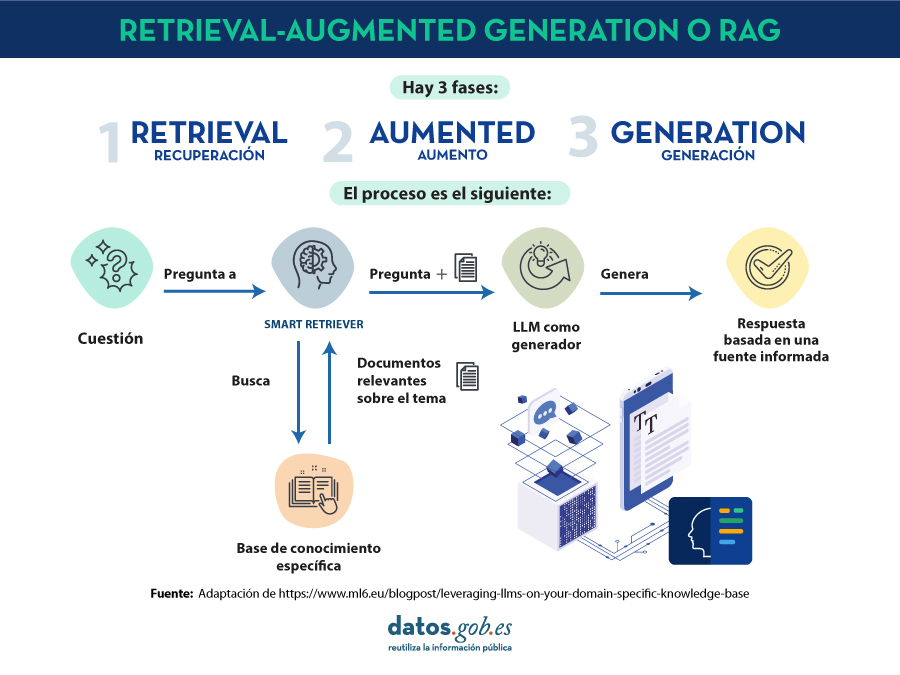
Entendiendo RAG con ejemplos
Pongamos un ejemplo concreto. Imagina que estás intentando responder una pregunta sobre dinosaurios. Un LLM generalista puede inventarse una respuesta perfectamente plausible, de forma que una persona no experta en la materia no la diferencia de una respuesta con base científica. Por el contrario, con el uso de RAG, el LLM buscaría en una base de datos de información sobre dinosaurios y recuperaría los hechos más relevantes para generar una respuesta completa.
Lo mismo ocurría si buscamos una información concreta en una base de datos privada. Por ejemplo, pensemos en un responsable de recursos humanos de una empresa. Éste desea recuperar información resumida y agregada sobre uno o varios empleados cuyos registros se encuentran en diferentes bases de datos de la empresa. Pensemos que podemos estar tratando de obtener información a partir de tablas salariales, encuestas de satisfacción, registros laborales, etc. Un LLM es de gran utilidad para generar una respuesta con un patrón humano. Sin embargo, es imposible que ofrezca datos coherentes y precisos puesto que nunca ha sido entrenado con esa información debido a su carácter privado. En este caso, RAG asiste al LLM para proporcionarle datos y contexto específico con el que poder devolver la respuesta adecuada.
De la misma forma, un LLM complementado con RAG sobre registros médicos podría ser un gran asistente en el ámbito clínico. También los analistas financieros se beneficiarían de un asistente vinculado a datos actualizados del mercado de valores. Prácticamente, cualquier caso de uso se beneficia de las técnicas RAG para enriquecer las capacidades de los LLM con datos de contexto específicos.
Recursos adicionales para entender mejor RAG
Cómo os podéis imaginar, tan pronto como nos asomamos por un momento a la parte más técnica de entender los LLM o RAG, las cosas se complican enormemente. En este post hemos tratado de explicar con palabras sencillas y ejemplos cotidianos cómo funciona la técnica de RAG para obtener respuestas más precisas y contextualizadas a las preguntas que le hacemos a un asistente conversacional como ChatGPT, Bard o cualquier otro. Sin embargo, para todos aquellos que tengáis ganas y fuerzas para profundizar en el tema, os dejamos una serie de recursos web disponibles para tratar de entender un poco más cómo se combinan los LLM con RAG y otras técnicas como la ingeniería de prompts para ofrecer las mejores apps de IA generativa posibles.
Videos introductorios:
Artículos de contenido de LLMs y RAG para principiantes:
- DEV - LLM for dummies
-
Digital Native - LLMs for Dummies
-
Hopsworks.ai - Retrieval Augmented Generation (RAG) for LLMs
-
Datalytyx - RAG For Dummies
¿Quieres pasar al siguiente nivel? Algunas herramientas para probar:
- LangChain. LangChain es un marco (framework) de desarrollo que facilita la construcción de aplicaciones usando LLMs, como GPT-3 y GPT-4. LangChain es para desarrolladores de software y permite integrar y gestionar varios LLMs, creando aplicaciones como chatbots y agentes virtuales. Su principal ventaja es simplificar la interacción y orquestación de LLMs para una amplia gama de aplicaciones, desde análisis de texto hasta asistencia virtual.
-
Hugging Face. Hugging Face es una plataforma con más de 350 mil modelos, 75 mil conjuntos de datos y 150 mil aplicaciones de demostración, todos ellos de código abierto y disponibles públicamente online donde la gente puede colaborar fácilmente y construir modelos de inteligencia artificial.
-
OpenAI. OpenAI es la plataforma más conocida en lo que a modelos de LLM e interfaces conversacionales se refiere. Los creadores de ChatGTP ponen a disposición de la comunidad de desarrolladores un conjunto de librerías para utilizar el API de OpenAI y poder crear sus propias aplicaciones utilizando los modelos GPT-3.5 y GPT- 4. Como ejemplo, os proponemos visitar la documentación de la librería de Python para entender cómo, con muy pocas líneas de código, podemos estar usando un LLM en nuestra propia aplicación. Aunque las interfaces conversacionales de OpenAI como ChatGPT, utilizan su propio sistema RAG, también podemos combinar los modelos GPT con nuestra propia RAG, como por ejemplo, lo que proponen en este artículo.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.