Blog
Los datos abiertos de salud son uno de los activos más valiosos de nuestra sociedad. Bien gestionados y compartidos de forma responsable, pueden salvar vidas, impulsar descubrimientos médicos o incluso optimizar recursos hospitalarios. Sin embargo, durante décadas, estos datos han permanecido fragmentados en silos institucionales, con formatos incompatibles y barreras técnicas y legales que dificultaban su reutilización. Ahora, la Unión Europea está cambiando radicalmente el panorama con una estrategia ambiciosa que combina dos enfoques complementarios:
- Facilitar el acceso abierto a estadísticas y datos agregados no sensibles.
- Crear infraestructuras seguras para compartir datos personales de salud bajo estrictas garantías de privacidad.
En España, esta transformación ya está en marcha a través del Espacio Nacional de Datos de Salud o grupos de investigación que están a la vanguardia en el uso innovador de datos de salud. Iniciativas como IMPACT-Data, que integra datos médicos para impulsar la medicina de precisión, demuestran el potencial de trabajar con datos de salud de manera estructurada y segura. Y para facilitar que todos estos datos sean fáciles de encontrar y reutilizar se implementan estándares como HealthDCAT-AP.
Todo ello está perfectamente alineado con la estrategia europea del Reglamento del Espacio Europeo de Datos de Salud (EHDS), publicado oficialmente en marzo de 2025 que se integra también con la Directiva de Datos Abiertos (ODD), en vigor desde 2019. Aunque ambos marcos regulatorios tienen alcances distintos, su interacción ofrece oportunidades extraordinarias para la innovación, la investigación y la mejora de la atención sanitaria en toda Europa.
Un reciente informe elaborado por Capgemini Invent para data.europa.eu analiza estas sinergias. En este post, exploramos las principales conclusiones de este trabajo y reflexionamos sobre su relevancia para el ecosistema español de datos abiertos.
Dos marcos complementarios para un objetivo común
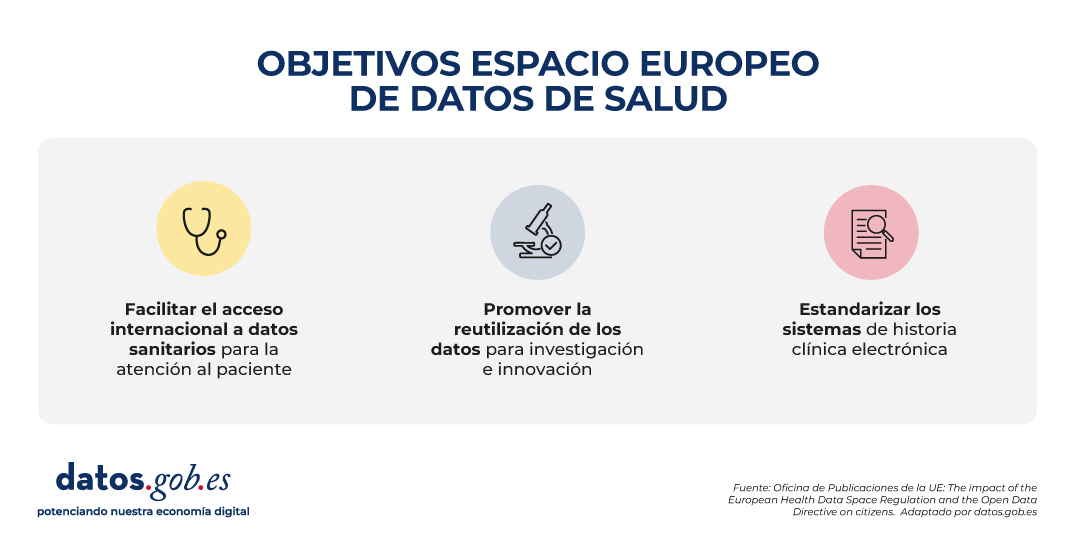
Por un lado, el Espacio Europeo de Datos de Salud se centra específicamente en datos de salud y persigue tres objetivos fundamentales:
- Facilitar el acceso internacional a datos sanitarios para la atención al paciente (uso primario).
- Promover la reutilización de estos datos para investigación, políticas públicas e innovación (uso secundario).
- Estandarizar técnicamente los sistemas de historia clínica electrónica (HCE) para mejorar la interoperabilidad transfronteriza.
Por su parte, la Directiva de Datos Abiertos tiene un alcance más amplio: promueve que el sector público ponga a disposición de cualquier usuario datos gubernamentales para su reutilización libre. Esto incluye los conjuntos de datos de alto valor (High-Value Datasets) que deben publicarse gratuitamente, en formatos legibles por máquina y a través de API en seis categorías entre las que no se encontraba “salud” originalmente. Sin embargo, en la propuesta de ampliación de las nuevas categorías que publicó la UE sí aparece la categoría de salud.
La complementariedad entre ambos marcos regulatorios es evidente: mientras la ODD facilita el acceso abierto a estadísticas sanitarias agregadas y no sensibles, el EHDS regula el acceso controlado a datos individuales de salud bajo condiciones estrictas de seguridad, consentimiento y gobernanza. Juntos, conforman un sistema escalonado de compartición de datos que maximiza su valor social sin comprometer la privacidad, en total cumplimiento con el Reglamento General de Protección de Datos (RGPD).
Principales beneficios ordenador por grupos de usuarios
El informe analiza cuatro grupos de usuarios principales y examina tanto los beneficios potenciales como los desafíos que enfrentan al combinar datos del EHDS con datos abiertos.
-
Pacientes: empoderamiento informado con barreras prácticas
Los pacientes europeos obtendrán acceso más rápido y seguro a sus propias historias clínicas electrónicas, especialmente en contextos transfronterizos gracias a infraestructuras como MyHealth@EU. Este proyecto resulta especialmente útil para ciudadanos europeos que se encuentren desplazados en otro país europeo. .
Otro proyecto interesante que informa a la ciudadanía es PatientsLikeMe que reúne a más 850.000 pacientes con enfermedades raras o crónicas en una comunidad online que comparte información de interés sobre tratamientos y otras cuestiones.
-
Profesionales de la salud potencial subordinado a la integración
Por otro lado, los profesionales sanitarios podrán acceder antes y de manera más sencilla a datos clínicos de pacientes, incluso a través de fronteras, mejorando la continuidad asistencial y la calidad del diagnóstico y tratamiento.
La combinación con datos abiertos podría amplificar estos beneficios si se desarrollan herramientas que integren ambas fuentes de información directamente en los sistemas de historia clínica electrónica.
3. Responsables políticos: datos para mejores decisiones
Los cargos públicos son beneficiarios naturales de la convergencia entre EHDS y datos abiertos. La posibilidad de combinar datos salud detallados (previa solicitud y autorización a través de los Organismos de Acceso a Datos Sanitarios que cada Estado miembro debe establecer) con información estadística y contextual abierta permitiría desarrollar políticas basadas en evidencia mucho más sólida.
El informe menciona casos de uso como la combinación de datos de salud con información medioambiental para evaluar impactos sanitarios. Un ejemplo real es el proyecto francés Green Data for Health, que cruza datos abiertos sobre contaminación acústica con información sobre prescripciones de medicamentos para el sueño de más de 10 millones de habitantes, investigando correlaciones entre ruido ambiental y trastornos del sueño.
4. Investigadores y reutilizadores: los principales beneficiarios inmediatos
Los investigadores, académicos e innovadores constituyen el grupo que más directamente se beneficiará de la sinergia EHDS-ODD ya que disponen de las habilidades y herramientas necesarias para localizar, acceder, combinar y analizar datos de múltiples fuentes. Además, su trabajo ya implica habitualmente la integración de diversos conjuntos de datos.
Un estudio reciente publicado en PLOS Digital Health sobre el caso de Andalucía demuestra cómo los datos abiertos en salud pueden democratizar la investigación en IA sanitaria y mejorar la equidad en el tratamiento.
El desarrollo del EHDS está siendo apoyado por programas europeos como EU4Health, Horizon Europe y proyectos específicos como TEHDAS2, que ayudan a definir estándares técnicos y pilotar aplicaciones reales.
Recomendaciones para maximizar el impacto
El informe concluye con cuatro recomendaciones clave que resultan particularmente relevantes para el ecosistema español de datos abiertos:
- Estimular la investigación en la intersección EHDS-datos abiertos mediante financiación específica. Es fundamental incentivar que los investigadores que combinan estas fuentes traduzcan sus hallazgos en aplicaciones prácticas: protocolos clínicos mejorados, herramientas de decisión, estándares de calidad actualizados.
- Evaluar y facilitar el uso directo por profesionales y pacientes. Promover la alfabetización en datos y desarrollar aplicaciones intuitivas integradas en los sistemas existentes (como las historias clínicas electrónicas) podría cambiar esta situación.
- Fortalecer la gobernanza mediante educación y marcos regulatorios claros. A medida que se vayan operativizando las entidades técnicas del EHDS , será esencial contar con una regulación clara que defina unos marcos regulatorios comunes..
- Monitorizar, evaluar y adaptar. El período 2025-2031 verá la entrada en vigor gradual de los distintos requisitos del EHDS. Se recomienda realizar evaluaciones periódicas para valorar cómo se está utilizando realmente el EHDS, qué combinaciones con datos abiertos están generando más valor, y qué ajustes son necesarios.
Además, para que todo esto funcione, el informe sugiere que portales como data.europa.eu (y por extensión, datos.gob.es) deberían destacar ejemplos prácticos que demuestren cómo se complementan los datos abiertos con los datos protegidos de espacios sectoriales, inspirando así nuevas aplicaciones.
En general, el papel de los portales de datos abiertos será fundamental en este ecosistema emergente: no solo como proveedores de conjuntos de datos de calidad, sino también como facilitadores de conocimiento, espacios de encuentro entre comunidades y catalizadores de innovación. El futuro de la sanidad europea se está escribiendo ahora, y los datos abiertos tienen un papel protagonista en esa historia.
Blog
La Unión Europea tiene como objetivo potenciar la Economía del Dato, impulsando el flujo libre de datos entre los estados miembros y entre sectores estratégicos, en beneficio de empresas, investigadores, administraciones públicas y ciudadanos. Sin duda, los datos son un factor crítico en la revolución industrial y tecnológica que estamos viviendo, y por ello una de las prioridades digitales de la UE pasa por capitalizar su valor latente, apoyándose para ello en un mercado único donde estos puedan compartirse bajo condiciones de seguridad, y sobre todo de soberanía, pues sólo así se garantizarán los indiscutibles valores y derechos europeos.
Así, la Estrategia Europea de Datos busca potenciar su intercambio a gran escala, bajo entornos distribuidos y federados, pero que sin embargo garanticen la ciberseguridad y la transparencia. Para lograr escala, y liberar todo el potencial de los datos en la economía digital, un elemento fundamental es la generación de confianza. Esta, como elemento basal que condiciona la liquidez del ecosistema, debe desarrollarse coherentemente a lo largo de diferentes ámbitos y entre diferentes actores (proveedores de datos, usuarios, intermediarios, plataformas de servicios, desarrolladores, …). Por ende, su articulación afecta a diferentes perspectivas, incluida la de negocio y funcional, la legal y regulatoria, la operacional, e incluso la tecnológica. Por tanto, el éxito en estos proyectos de alta complejidad pasa por desarrollar estrategias que busquen minimizar las barreras de entrada a los participantes, y maximizar la eficacia y sostenibilidad de los servicios ofrecidos. Esto a su vez se traduce en el desarrollo de infraestructuras y modelos de gobernanza para los datos que sean fácilmente escalables, y que sirvan de base para un intercambio efectivo de datos con que generar valor para todos sus participantes.
Una metodología para impulsar los espacios de datos
España ha hecho suyo el cometido de llevar a la práctica esa estrategia europea, y desde hace años se trabaja en crear el entorno propicio para facilitar el despliegue y asentamiento de una Economía del Dato Soberana, apoyándose, entre otros instrumentos, en el Plan de Recuperación, Transformación y Resiliencia. En este sentido, y desde su papel coordinador y posibilista, la Oficina del Dato ha desplegado esfuerzos en el diseño de una metodología conceptual general, agnóstica a un sector concreto. Esta configura la creación de ecosistemas de datos alrededor de proyectos prácticos que aporten valor a los miembros de dicho ecosistema.
Por ello, la metodología consta de varios elementos, siendo la experimentación uno de ellos. Esto es así debido a que, por su naturaleza flexible, los datos pueden ser tratados, modelizados, y por ende interpretados, desde distintas perspectivas. Por este motivo, la experimentación resulta clave para calibrar adecuadamente aquellos procesos y tratamientos necesarios para llegar al mercado con pilotos o casos de negocio ya cercanos a las industrias, de modo que estén más cerca a generar un impacto positivo. En este sentido, se hace necesario demostrar el valor tangible y apuntalar su sostenibilidad, lo que implica contar, como mínimo, con:
- Marcos de referencia para una gobernanza efectiva de datos
- Actuaciones para mejorar la disponibilidad y la calidad de los datos, buscando también incrementar su interoperabilidad por diseño
- Herramientas y plataformas de intercambio y explotación de datos.
Así mismo, y dado que cada sector tiene su propia especificidad en lo que respecta a tipos y semánticas de datos, modelos de negocio, y necesidades de los participantes, la creación de comunidades de expertos, representando la voz del mercado, es otro elemento fundamental de cara a generar proyectos de utilidad. En base a esta escucha activa, que conduzca a la compresión de las dinámicas del dato en cada sector, se logra caracterizar las condiciones de mercado y de gobernanza necesarias para el despliegue de los espacios de datos en sectores estratégicos como el turismo, la movilidad, agroalimentación, comercio, salud o la industria.
En este proceso de generación de comunidad, las cooperativas de datos juegan un papel fundamental, así como la figura más general del intermediario de datos, que sirve para sensibilizar sobre la oportunidad existente y favorecer la creación y consolidación efectiva de estos nuevos modelos de negocio.
Todos estos elementos son distintas piezas de un puzle con que explorar nuevas oportunidades de desarrollo de negocio, así como para el diseño de proyectos tangibles con que demostrar el valor diferencial que la compartición de datos aportará a la realidad de las industrias. Así, y desde la perspectiva operativa, el último elemento de la metodología es el desarrollo de casos de uso concretos. Estos también permitirán desplegar iterativamente un catálogo de experiencias y recursos de datos reutilizables en cada sector, con que facilitar la construcción de nuevos proyectos. Este catálogo se convierte así en la pieza central de una plataforma común sectorial y federada, y cuya arquitectura distribuida facilita también la interconexión intersectorial.
Sobre hombros de gigantes
Hay que destacar que España no parte de cero, pues cuenta ya con un potente ecosistema de innovación y experimentación en datos, que ofrece servicios avanzados. Creemos por tanto interesante progresar en la armonización o complementariedad de sus objetivos, así como en la difusión de sus capacidades para ganar capilaridad. Además, la metodología planteada refuerza el alineamiento con los proyectos europeos del mismo ámbito, lo que servirá para conectar los aprendizajes y avances desde la escala nacional a los realizados a nivel UE, así como para poner en práctica las tareas de diseño de los "cianotipos" promulgados por la Comisión Europea a través del Data Spaces Support Centre.
Por último, el impulso de proyectos experimentales o piloto permite también el desarrollo de estándares para tecnologías innovadoras de datos, guardando una estrecha relación con el proyecto Gaia-X. Así, el Hub Gaia-X España cuenta con un nodo de interoperabilidad, que sirve para certificar el cumplimiento de las reglas prescritas por cada sector, y por ende para generar la citada confianza digital en base a sus necesidades específicas.
Desde la Oficina del Dato, creemos que la interconexión y la escalabilidad a futuro de los proyectos de datos se encuentran en el centro del esfuerzo de implementación de la Estrategia Europea de Datos, y resultan cruciales para alcanzar una Economía del Dato dinámica y rica, pero a su vez garante de los valores europeos y donde la trazabilidad y la transparencia ayuden a colectivizar el valor del dato, catalizando una economía más fuerte y cohesionadora.
Blog
La European Open Science Cloud (EOSC) es una iniciativa de la Unión Europea que tiene como objetivo promover la ciencia abierta a través de la creación de una infraestructura digital de investigación abierta, colaborativa y sostenible. El objetivo principal de EOSC es el de proporcionar a los investigadores europeos un acceso más fácil a los datos, las herramientas y los recursos necesarios para poder llevar a cabo investigaciones de calidad.
EOSC en la agenda europea de investigación y datos
EOSC forma parte de las 20 acciones de la agenda 2022-2024 del Espacio Europeo de Investigación (ERA) y se reconoce como el espacio europeo de datos de ciencia, investigación e innovación, llamado a integrarse con otros espacios de datos sectoriales definidos en la estrategia europea para los datos. Entre los beneficios que se esperan obtener gracias a esta plataforma se encuentran:
-
Una mejora en la confianza, calidad y productividad de la ciencia europea.
- El desarrollo de nuevos productos y servicios innovadores.
- Una mejora en el impacto de la investigación a la hora de afrontar los mayores desafíos sociales.
La plataforma EOSC
EOSC es en realidad un proceso continuo que marca una hoja de ruta en la que todos los Estados Europeos participan, basándose en la idea central de que los datos de investigación son un bien público que debe estar disponible para todos los investigadores, independientemente de su ubicación o afiliación. Mediante este modelo se persigue que los resultados científicos cumplan con los Principios FAIR (Findable, Accesible, Interoperable, Reusable) para facilitar la reutilización, al igual que en cualquier otro espacio de datos.
No obstante, la parte más visible de ESCO es su plataforma que da acceso a millones de recursos aportados por cientos de proveedores de contenido. Dicha plataforma está diseñada para facilitar la búsqueda, el descubrimiento y la interoperabilidad de los datos y otros contenidos como recursos formativos, de seguridad, de análisis, herramientas, etc. Para ello, entre los elementos clave de la arquitectura prevista en EOSC encontramos dos componentes principales:
- EOSC Core: que proporciona todos los elementos básicos necesarios para descubrir, compartir, acceder y reutilizar recursos – autenticación, gestión de metadatos, métricas, identificadores persistentes, etc.
- EOSC Exchange: para asegurar que los servicios comunes y temáticos para la gestión y explotación de los datos estén disponibles a la comunidad científica.
A lo anterior hay que sumar el Framework de interoperabilidad de ESOC (EOSC-IF), un conjunto de políticas y directrices que habilitan la interoperabilidad entre distintos recursos y servicios y facilitan su posterior combinación.
En la actualidad la plataforma está disponible en 24 idiomas y se actualiza continuamente para añadir nuevos datos y servicios. Para los próximos siete años se prevé una inversión conjunta por parte de los socios de la Unión Europea de al menos 1.000 millones de euros para continuar con su desarrollo.
Participación en EOSC
La evolución de EOSC está siendo guiada por un organismo de coordinación tripartito formado por la propia Comisión Europea, los países participantes representados en la Junta Directiva de EOSC y la comunidad de investigación representada mediante la Asociación EOSC. Además, para poder formar parte de la comunidad ESCO tan sólo hay que seguir una serie de reglas mínimas de participación:
-
Todo el concepto de EOSC se basa en el principio general de apertura.
- Los recursos existentes en EOSC deben cumplir con los principios FAIR.
- Los servicios deben cumplir con la arquitectura y pautas de interoperabilidad de EOSC.
- EOSC sigue los principios de comportamiento ético e integridad en la investigación.
- Se espera que los usuarios de EOSC también contribuyan a EOSC.
- Los usuarios deben cumplir los términos y condiciones asociados a los datos que usen.
- Los usuarios de EOSC siempre citan las fuentes de los recursos que usen en su trabajo.
- La participación en EOSC está sujeta a las políticas y legislaciones aplicables.
EOSC en España
El Consejo Superior de Investigaciones Científicas (CSIC) de España fue uno de los 4 miembros fundadores de la asociación y actualmente es miembro encomendado de la misma, encargado de la coordinación a nivel nacional.
El CSIC lleva ya años trabajando en su repositorio de acceso abierto DIGITAL.CSIC como paso previo a su futura integración en EOSC. Dentro de su trabajo en ciencia abierta podemos señalar por ejemplo la adopción de los Current Research Information System (CRIS), sistemas de información diseñados para ayudar a las instituciones de investigación a recopilar, organizar y gestionar datos sobre su actividad investigadora: investigadores, proyectos, publicaciones, patentes, colaboraciones, financiación, etc.
Los CRIS son ya de por sí herramientas importantes a la hora de ayudar a las instituciones a rastrear y administrar su producción científica, promoviendo la transparencia y el acceso abierto a la investigación. Pero, además, pueden también desempeñar un papel relevante como fuentes de información que alimentan la EOSC, ya que los datos recopilados en los CRIS pueden ser también fácilmente compartidos y utilizados a través de la EOSC.
El camino hacia la ciencia abierta
La colaboración entre los CRIS y la EOSC tiene el potencial de mejorar significativamente la accesibilidad y la reutilización de los datos de investigación, pero hay también otras acciones de transición que se pueden adoptar en el camino hacia la producción de una ciencia cada vez más abierta:
-
Garantizar la calidad de los metadatos para facilitar el intercambio abierto de datos.
- Divulgar los principios FAIR entre la comunidad investigadora.
- Promover y desarrollar estándares comunes para facilitar la interoperabilidad.
- Fomentar la utilización de repositorios abiertos.
- Contribuir compartiendo recursos con el resto de la comunidad.
Todo ello ayudará a impulsar la ciencia abierta, aumentando la eficiencia, transparencia y replicabilidad de las investigaciones.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Europa está desarrollando un espacio común de datos para el turismo, que busca integrar a múltiples actores, incluyendo autoridades locales y regionales, el sector privado y varios Estados miembro. Entre ellos podemos encontrar también a España, donde ya se han llevado a cabo varios talleres de trabajo como parte del proceso de dinamización del espacio de datos de turismo nacional y con el objetivo de debatir los retos y oportunidades o los casos de uso del sector.
El futuro espacio de datos de turismo está en el centro de la transición hacia una mayor sostenibilidad y una profunda digitalización en el sector. Esta actuación se enmarca también dentro de la estrategia europea de datos, que tiene como visión común la creación de un mercado único donde la información pueda ser compartida libremente, buscando impulsar la innovación en diferentes sectores económicos y en ciertas áreas de interés público. Así mismo, los futuros espacios de datos tienen también gran importancia dentro de la necesidad de recuperar la soberanía digital de Europa, recuperando el control sobre nuestros datos, nuestra capacidad de innovación y la capacidad de elaborar y aplicar nuestra propia legislación en el entorno digital.
Ya en la conferencia del año pasado sobre el Futuro de la Unión Europea se destacó la importancia de los espacios de datos en áreas como el turismo y la movilidad, reconociéndolos como sectores clave para considerar en la transformación digital. El turismo, en particular, se considera un sector especialmente beneficiado por este tipo de iniciativas, dada su naturaleza basada en las experiencias de los usuarios –que son dinámicas y en constante evolución– y en donde el acceso a la información necesaria en el momento adecuado será por tanto clave.
Así pues, el espacio común Europeo de datos para el turismo busca aumentar el intercambio y la reutilización de datos, estableciendo para ello un modelo de gobernanza que respete la legislación existente. El objetivo final es que todos los interesados se puedan beneficiar de esos datos compartidos de múltiples formas:
- Fomentando la innovación en el sector, mejorando y personalizando los servicios gracias a contar con más información de calidad;
- Ayudando a las autoridades públicas en la toma de decisiones para la sostenibilidad de su oferta turística que estén basadas en datos relevantes;
- Apoyando a las empresas especializadas para que puedan proporcionar mejores servicios basados en el análisis de los datos y de las tendencias del mercado;
- Consiguiendo que las empresas del sector tengan mayor facilidad de acceso al mercado Europeo;
- Mejorando la disponibilidad de fuentes de datos para la elaboración de estadísticas oficiales de calidad.
Sin embargo, existen también varios desafíos que se deben afrontar a la hora de compartir los datos existentes dentro del sector turístico, debido principalmente a reticencias respecto a la reciprocidad y la reutilización de la información. Estos desafíos se podrían resumir como:
- Interoperabilidad de los datos: Diseñar y gestionar una experiencia turística en Europa implica gestionar una gran diversidad de datos no personales en dominios tan diversos como la movilidad, la gestión medioambiental o el patrimonio cultural, que servirán para enriquecer la experiencia turística. El principal desafío en este ámbito radica en poder compartir y contrastar información de distintas fuentes sin duplicidades, con un marco de referencia que promueva la interoperabilidad entre diferentes sectores, y utilizando estándares ya existentes en la medida de los posible.
- Acceso a los datos: A diferencia de otros sectores, el ecosistema turístico de la Unión Europea carece de una plataforma única de mercado. Las distintas ofertas son modeladas y catalogadas por diferentes actores, tanto públicos como privados, ya sea a nivel nacional como regional o local. Este enfoque da lugar a un panorama diverso, rico y multilingüe. Aunque el espacio de datos de turismo no pretende servir como nodo de centralización de las reservas, puede contribuir enormemente proporcionando herramientas eficaces de búsqueda de información, facilitando el acceso a los datos necesarios, la toma de decisiones y también la innovación en el sector.
- Provisión de datos por parte de entidades públicas y privadas: Existe una variedad de datos en este sector, desde datos abiertos como horarios y condiciones climáticas, hasta otros privados y comerciales como datos de búsquedas, reservas y pagos. Una gran parte de estos datos comerciales son gestionados por un pequeño grupo de grandes entidades privadas, por lo que será necesario establecer un diálogo inclusivo para establecer reglas justas y adecuadas sobre el acceso a estos datos dentro del espacio de datos compartido.
Con el objetivo de poder consolidar esta iniciativa, la Senda de la Transición para el Turismo, introdujo la necesidad de avanzar en la creación y optimización de un espacio de datos específico para el sector turístico, buscando modernizar y potenciar este importante sector económico en Europa a través de las siguientes acciones clave:
- Gobernanza: La gobernanza del espacio de datos turísticos determinará cómo se relacionarán los principales habilitadores necesarios para garantizar la interoperabilidad. El objetivo es conseguir que los datos se accedan, compartan y utilicen de manera lícita, justa, transparente, proporcional y no discriminatoria para generar confianza, apoyar la investigación y la innovación dentro del sector.
- Semántica para la interoperabilidad: Se necesitan modelos y vocabularios de datos comunes para conseguir una interoperabilidad efectiva. Tanto las agencias nacionales de estadística como el Eurostat cuentan ya con ciertas definiciones consensuadas, pero su adopción por parte del sector turísticos es todavía irregular. Es por ello crucial aclarar las definiciones dentro del universo multilingüe de la Unión para conseguir un modelo de datos común Europeo que cuente también con guías para su implementación. En nuestro país se han llevado ya a cabo actividades pioneras en relación a la interoperabilidad semántica, como por ejemplo el desarrollo de la Ontología del Turismo, la norma técnica de semántica aplicada a destinos turísticos inteligentes o el modelo de recogida, explotación y análisis de datos turísticos.
- Estándares técnicos para la interoperabilidad: El Centro de Soporte para los Espacios de Datos (DSSC) está ya trabajando para poder identificar estándares técnicos comunes que puedan ser reutilizados, teniendo en cuenta las iniciativas y los marcos regulatorios ya existentes o en marcha. Además, todos los espacios de datos se beneficiarán también de Simpl, un middleware para federaciones en la nube que servirá de base para las principales iniciativas de datos financiadas por la Comisión Europea. Por otro lado, existen también otros estándares técnicos específicos del sector, como los desarrollados por Eurostat para poder compartir datos de alojamientos.
- Definición del papel del sector privado: El espacio común de datos europeo para el turismo se beneficiará claramente de la cooperación con el sector privado y del mercado de nuevos servicios y herramientas que éste podrá ofrecer. Algunas plataformas ya comparten datos con Eurostat y se están desarrollando también nuevos acuerdos para compartir otros datos no personales del sector turismo, además de la elaboración de un nuevo código de conducta para fomentar la confianza entre los diversos actores.
- Apoyo a las PYMEs en la transición hacia un espacio de datos: La Comisión Europea brinda desde hace tiempo apoyo específico a las PYMEs a través de los Centros de Innovación Digital (EDIH) y de la Red Europea de Empresas (EEN) – que vienen ofreciendo apoyo técnico y financiero, además de soporte en el desarrollo de nuevas habilidades digitales. Incluso algunos de estos centros están especializados en el área del turismo. Además, la Red Europea de Empresas de Turismo (SGT) – con 61 miembros en 23 países – ofrece también apoyo en materia de digitalización e internacionalización. Este apoyo las PYMES cobra especial relevancia cuando tenemos en cuenta que éstas representan casi la totalidad de las empresas en el sector turístico – concretamente el 99,9%; de las cuales el 91% son microempresas.
- Apoyo a los destinos turísticos en la transición hacia un espacio de datos: Los destinos turísticos deben integrar el turismo en sus planes urbanos para poder garantizar un turismo sostenible y beneficioso para sus residentes y el entorno en el que habitan. Varias iniciativas de la Comisión fortalecen la disponibilidad de la información necesaria para la gestión turística y el intercambio de buenas prácticas, promoviendo la cooperación entre destinos y proponiendo acciones para mejorar los servicios digitales.
- Prueba de concepto para el espacio de datos turísticos: La Comisión Europea, junto con varios estados miembros y otros actores privados, está ya en la actualidad llevando a cabo una serie de pruebas piloto para los espacios de datos de turismo a través de las acciones de coordinación y apoyo (CSAs) DSFT y DATES. El objetivo principal de estas pruebas es alinearse con los estándares técnicos existentes para los datos de alojamiento y mostrar el valor de la interoperabilidad y los modelos de negocio que surgen gracias a poder compartir los datos mediante un enfoque realista e inclusivo, centrado en alquileres a corto plazo y alojamiento. En España, el informe sobre la radiografía del espacio de datos de turismo explica el momento en el que se encuentra actualmente el diseño del espacio de datos nacional.
En definitiva, la Comisión Europea se compromete firmemente a apoyar la creación de un espacio donde los datos relacionados con el turismo fluyan respetando los principios de equidad, accesibilidad, seguridad y privacidad – en línea con la estrategia europea de datos y con el Pacto por el desarrollo de nuevas competencias. Con ello lo que se persigue es poder construir un espacio común de datos para el turismo que sea progresivo, sólido, e integrado en el marco de interoperabilidad ya existente. Para ello la Comisión insta a todos los actores a compartir datos para el mutuo beneficio de todos los actores involucrados en un ecosistema que será clave para el conjunto de la economía Europea.
A finales de octubre podremos contar también con una nueva oportunidad para saber más sobre el espacio de datos de turismo, y sobre los retos asociados a los espacios de datos en general, a través del European Big Data Value Forum en Valencia.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En la era digital, los avances tecnológicos han transformado el sector de la investigación médica. Uno de los factores que contribuyen al desarrollo tecnológico en este ámbito son los datos y, en especial, los datos abiertos. La apertura y disponibilidad de la información que se obtiene de investigaciones sanitarias aporta múltiples beneficios a la comunidad científica. Los datos abiertos en el sector salud fomentan la colaboración entre investigadores, aceleran el proceso de validación de resultados en estudios y, en definitiva, ayudan a salvar vidas.
La relevancia de este tipo de datos también se manifiesta en la intención prioritaria de constituir el proyecto de espacio europeo de datos sanitarios (EEDS), el primer espacio común de datos de la UE que surge de la Estrategia Europea de Datos y una de las prioridades de la Comisión para el período 2019-2025. Tal y como plantea la Comisión Europea en su propuesta, el EEDS este espacio contribuirá a promover un mejor intercambio y acceso a diferentes tipos de datos sanitarios, no solo para apoyar la prestación de asistencia médica sino también para la investigación sanitaria y la elaboración de políticas en el ámbito de la salud.
Sin embargo, el tratamiento de este tipo de datos debe de ser adecuado, debido a la información sensible que albergan. Los datos personales relativos a la salud están considerados como una categoría especial por la Agencia Española de Protección de Datos (AEPD) y una brecha de datos personales, especialmente, en el sector de la salud, tiene un alto impacto personal y social.
Para evitar estos riesgos, los datos médicos se pueden anonimizar garantizando el cumplimiento normativo y de los derechos fundamentales y, así, proteger la privacidad de los pacientes. La Guía básica de anonimización elaborada por la AEPD a partir de la Personal Data Protection Commission Singapore (PDPC) define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
Una vez se realiza ese proceso, los datos médicos pueden contribuir a la investigación sobre enfermedades, lo que se traduce en mejoras en la eficacia de tratamientos y en el desarrollo de tecnologías de asistencia médica. Además, los datos abiertos en el sector salud permiten que los científicos compartan información, resultados y hallazgos de manera rápida y accesible, fomentando así la colaboración y la replicabilidad de los estudios.
En este sentido, existen diversas instituciones que comparten sus datos anonimizados para contribuir a la investigación sanitaria y el desarrollo de la ciencia. Una de ellas es la Fundación FISABIO (Fundación para el Fomento de la Investigación Sanitaria y Biomédica de la Comunitat Valenciana) que se ha convertido en un referente en el campo de la medicina gracias a su compromiso con la apertura y compartición de datos médicos. Como parte de esta institución, ubicada en la Comunidad Valenciana, existe la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) que se dedica, entre otras tareas, al estudio y desarrollo de técnicas avanzadas de imagen médica para mejorar el diagnóstico y tratamiento de enfermedades.
Este grupo de investigación ha desarrollado diferentes proyectos sobre análisis de imagen médica. El resultado de todo su trabajo se publica bajo licencias de código abierto: desde el resultado de sus investigaciones hasta los repositorios de datos que emplean para entrenar modelos de inteligencia artificial y machine learning.
Para proteger los datos sensibles de los pacientes, también han desarrollado sus propias técnicas de anonimización y seudonimización de imágenes e informes médicos mediante un modelo de Procesamiento del Lenguaje Natural (NLP) por el que los datos anonimizados se pueden sustituir por valores sintéticos. Siguiendo su técnica, se puede borrar la información facial de resonancias magnéticas cerebrales empleando un software libre de deep learning.
BIMCV: Banco de imágenes médicas de la Comunidad Valenciana
Uno de los mayores hitos de la Conselleria de Sanidad Universal y Salud Pública, a través de la Fundación y el hospital San Juan de Alicante, es la creación y mantenimiento del Banco de Imágenes Médicas de la Comunidad Valenciana, BIMCV (por sus siglas en inglés, Medical Imaging Databank of the Valencia Region), un repositorio de conocimiento para lograr “avances tecnológicos en imágenes médicas y proporcionar servicios de cobertura tecnológica para apoyar proyectos de I+D”, tal y como explican en su web.
BIMCV se aloja en XNAT, una plataforma que contiene imágenes de código abierto para la investigación basada en imágenes, y que es accesible bajo previo registro y/o bajo demanda. Actualmente, el Banco de Imágenes Médicas de la Comunidad Valenciana incluye datos abiertos procedentes de investigaciones realizada en diversos centros sanitarios de la región: alberga datos de más de 90.000 sujetos recogidos en más de 150.000 sesiones.
Nuevo conjunto de datos de imágenes radiológicas
Recientemente, la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) ha publicado en abierto la tercera y última iteración de datos del proyecto BIMCV-COVID-19: iniciativa con la que liberaron datos de imagen de radiologías de tórax realizadas a pacientes con COVID-19, así como los modelos que habían entrenado para detección de diferentes patologías de Rx tórax, gracias al apoyo de la Conselleria de Innovación, la Conselleria de Sanidad y los Fondos de la Unión Europea REACT-UE. Todo ello, “para que pueda ser utilizado por empresas del sector o simplemente para investigación”, explica María de la Iglesia, directora de la Unidad. “Creemos que la reproducibilidad es de gran relevancia e importancia en el sector salud", añade. Los conjuntos de datos y el resultado de sus investigaciones se pueden consultar aquí.
Los hallazgos están mapeados en terminología estándar del Sistema Unificado de Lenguaje Médico (UMLS) (como propuesta de los resultados de la tesis doctoral de la Oncóloga e Ingeniera Informática Dra. Aurelia Bustos)y almacenados en alta resolución con etiquetas anatómicas en un formato de Estructura de Datos de Imágenes Médicas (MIDS). Entre la información almacenada, se encuentran datos demográficos del paciente, el tipo de proyección y los parámetros de adquisición del estudio de imagen, entre otros, todo ello anonimizado.
La contribución que este tipo de proyectos sobre datos abiertos aportan a la sociedad, no solo beneficia a los investigadores y profesionales de la salud, sino que también permite el desarrollo de soluciones que pueden tener un impacto relevante en la mejora de la atención médica. Una de ellas puede ser la IA generativa que proporciona interesantes resultados que los profesionales sanitarios, priorizando su criterio, pueden tomar en consideración para personalizar el diagnóstico y proponer un tratamiento más eficaz.
Por otro lado, la digitalización de los sistemas sanitarios ya es una realidad: impresión 3D, gemelos digitales aplicados a la medicina, consultas telemáticas o dispositivos médicos portátiles. En este contexto, la colaboración y compartición de datos médicos, siempre y cuando se garantice su protección, contribuye a impulsar la investigación e innovación en el sector. Es decir, las iniciativas de datos abiertos para la investigación médica estimulan este avance tecnológico en la salud.
Por todo ello, la Fundación FISABIO conjuntamente con el Centro de Investigación Príncipe Felipe en donde se ubica la plataforma que alberga BIMCV, se destaca como un ejemplo destacado al promover la apertura y compartición de datos en el campo de la medicina. A medida que avanza la era digital, es fundamental seguir fomentando la apertura de datos y promoviendo su uso responsable en la investigación médica, en beneficio de toda la sociedad.
Blog
Vivimos en la era de los datos, palanca de transformación digital y un activo estratégico para la innovación y el desarrollo de nuevas tecnologías y servicios. Los datos, más allá de las habilidades que aportan al generador y/o dueño de los mismos, tienen además la peculiaridad de ser un activo no-rival. Esto quiere decir que pueden ser reutilizados sin que ello suponga un detrimento para el dueño de los derechos originales, lo que los convierte en un recurso con un alto grado de escalabilidad en su compartición y explotación.
Esta posibilidad de compartición no-rival, además de abrir potenciales nuevas líneas de negocio a los dueños originales, conlleva también un ingente valor latente para el desarrollo de nuevos modelos de negocio. Y aunque la compartición no es algo novedoso, ésta se encuentra todavía muy limitada a contextos nicho de especialización sectorial, mediados bien por la confianza entre partes (generalmente forjada de antemano), o tediosas y disciplinadas condiciones contractuales. Es por ello que surge el innovador concepto de espacio de datos, que en su acepción más simplificada no es más que la modelización de las condiciones generales con que desplegar una compartición voluntaria, soberana y segura de datos. Una vez modelizadas, la prescripción de consideraciones y metodologías (tanto tecnológicas, como organizativas y operativas) permite hacer tangible esa compartición en base a interacciones punto a punto, que conjuntamente dan forma a ecosistemas federados de conjuntos y servicios de datos.
Por ello, y dada la naturaleza distribuida de los espacios de datos (no son un sistema informático monolítico, ni una plataforma centralizada), una manera óptima de aproximarse de su construcción es a través de la creación y despliegue de casos de uso.
La Oficina del Dato ha creado esta infografía de un ‘Modelo de desarrollo de casos de uso dentro de los espacios de datos’, con el objetivo de definir sintéticamente las fases de ese viaje iterativo, que progresivamente va dando forma a un espacio de datos. Este modelo sirve además de marco general para otros entregables técnicos y metodológicos venideros, como por ejemplo la ‘Guía de Evaluación de Viabilidad de Casos de Uso’, o la ‘Guía de Diseño de Casos de Uso’, elementos con que facilitar la puesta en marcha de experiencias prácticas (y escalables por diseño) de compartición de datos, condición sine qua non para articular el ansiado mercado único de datos europeo.
El reto de construir un espacio de datos
Para hacer más accesible el proceso de desarrollar un espacio de datos, podríamos asimilar la definición y construcción de un caso de uso como un proyecto de construcción, en el que desde un problema de negocio inicial (necesidades o retos, deseos, o problemas a resolver) se llega a una meta en la que se aporta valor al negocio, dando solución a esas necesidades iniciales. Esta infografía ofrece una síntesis de ese viaje.
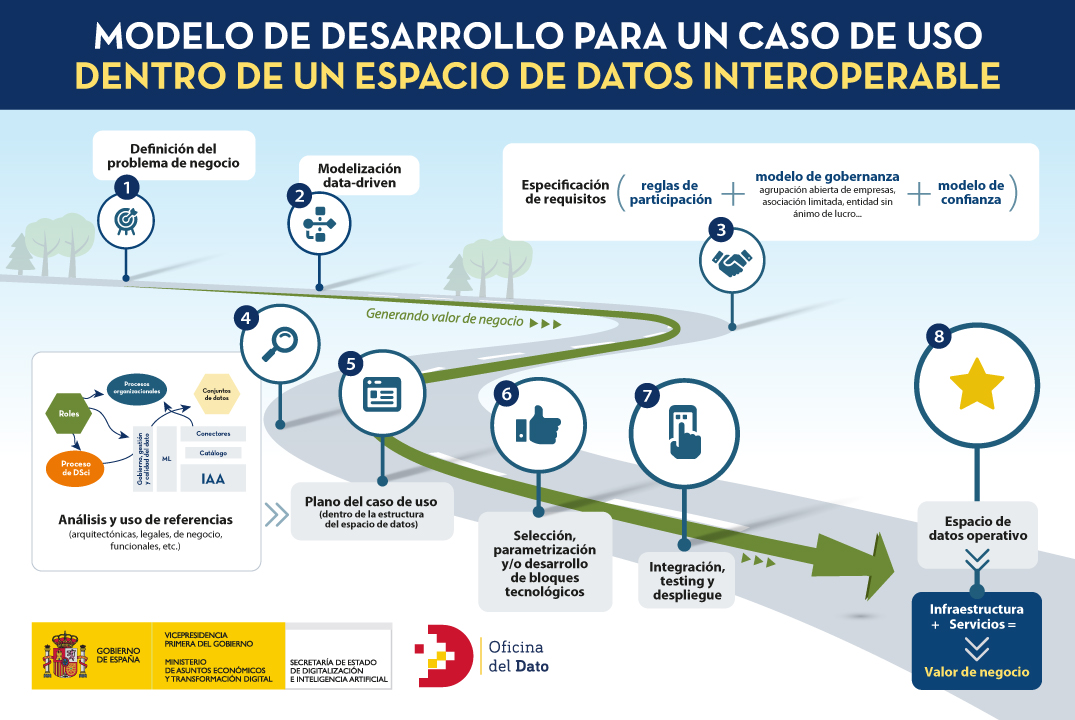
Estas son las fases del modelo:
- FASE 1: Definición del problema de negocio. En esta fase un grupo de potenciales participantes detecta una oportunidad alrededor de la compartición de sus datos (hasta ahora en silos) y su correspondiente explotación. Esta oportunidad puede ser nuevos productos o servicios (innovación), mejoras de eficiencia, o la resolución de un problema de negocio. Es decir, existe un objetivo de negocio que el grupo es capaz de resolver de forma conjunta, compartiendo datos.
- FASE 2: Modelización data-driven. En esta fase se identificarán aquellos elementos que sirvan para estructurar y organizar los datos para la toma de decisiones estratégicas en base a su explotación. Implica definir un modelo que posiblemente emplee herramientas multidisciplinarias para conseguir resultados de negocio. Es la parte que tradicionalmente se asocia a tareas de la ciencia de datos.
- FASE 3: Consenso en la especificación de requisitos. Aquí, los actores que auspician el caso de uso deben establecer el modelo de relación a tener durante este proyecto colaborativo alrededor de los datos. Dicha fórmula debe: (i) definir y establecer las reglas de participación, (ii) definir un conjunto común de políticas y modelo de gobierno, y (iii) definir un modelo de confianza que actúe como raíz de dicha relación.
- FASES 4 y 5: Plano del caso de uso. Como en un proyecto de construcción, el plano es el medio de expresión de las ideas de quienes han definido y acordado el caso de uso, y debe recoger de forma explícita las soluciones planteadas para cada una de las partes del desarrollo del mismo. Ese plano es único para cada caso de uso, y la fase 5 corresponde a su construcción. Sin embargo, no se crea desde la nada, sino que existen múltiples referencias que permiten utilizar materiales y técnicas previamente identificadas. Por ejemplo, modelos, metodologías, artefactos, plantillas, componentes tecnológicos o soluciones como servicio. Así, al igual que un arquitecto proyectando un edificio puede reutilizar estándares reconocidos, en el mundo de los espacios de datos también existen modelos sobre los que pintar los componentes y procesos de un caso de uso. El análisis y síntesis de esas referencias es la fase 4.
- FASE 6: Selección, parametrización y/o desarrollo tecnológico. La tecnología habilita el despliegue de la transformación y explotación del dato, favoreciendo todo el ciclo de vida, desde su recopilación hasta su puesta en valor. En esta fase se implementa la infraestructura que da soporte al caso de uso, entendida ésta como la colección de herramientas, plataformas, aplicaciones y/o piezas de software necesarias para la operación del aplicativo.
- FASE 7: Integración, test y despliegue. Como todo proceso de construcción tecnológico, el caso de uso pasará por las fases de integración, prueba y despliegue. Los trabajos de trabajos de integración y las pruebas funcionales, de usabilidad, de carácter exploratorio, de aceptación, etc. nos ayudarán a alcanzar la configuración deseada para el despliegue operativo del caso de uso. En el caso de desear la incorporación de un caso de uso a un espacio de datos preexistente, la integración buscaría encaje dentro de su estructura, lo que supone modelizar los requisitos de dicho caso de uso dentro de los procesos y bloques constructivos del espacio de datos.
- FASE 8: Espacio de datos operativo. El punto de llegada de este viaje es el caso de uso en funcionamiento, que empleará servicios digitales desplegados por encima de la estructura del espacio de datos, y cuya arquitectura da soporte a diferentes recursos y funcionalidades federada por diseño. Esto implica que se habría articulado eficientemente el ciclo de vida de creación de valor en base a los datos compartidos, y se obtiene rédito de negocio según el planteamiento original. Sin embargo, esto no impide que el espacio de datos pueda seguir evolucionando a posteriori, ya que su vocación es crecer bien con la entrada de nuevos retos, o actores a casos de uso ya existentes. De hecho, la escalabilidad del modelo es una de sus bondades singulares.
En esencia, los datos compartidos por medio de un ecosistema federado e interoperable son la entrada que alimenta una capa de servicios que generará valor y resolverá las necesidades y retos originales planteados, en un viaje que va desde la definición de un problema de negocio hasta su resolución.
Blog
Detrás de un asistente virtual de voz, la recomendación de una película en una plataforma de streaming o el desarrollo de algunas vacunas contra el covid-19 existen modelos de machine learning. Esta rama de la inteligencia artificial permite que los sistemas aprendan y mejoren su funcionamiento.
El machine learning (ML) o aprendizaje automático es uno de los campos que impulsa el avance tecnológico del presente y sus aplicaciones crecen cada día. Como ejemplos de soluciones desarrolladas con machine learning podemos mencionar DALL-E, el conjunto de modelos del lenguaje en español MarIA o incluso Chat GPT-3, herramienta de IA generativa que es capaz de crear contenido de todo tipo, como, por ejemplo, código para programar visualizaciones con datos del catálogo datos.gob.es.
Todas estas soluciones funcionan gracias a grandes repositorios de datos que hacen posible el aprendizaje de los sistemas. Entre estos, los datos abiertos juegan un papel fundamental para el desarrollo de la inteligencia artificial ya que pueden servir de entrenamiento para los modelos de aprendizaje automático.
Bajo esta premisa, sumado al esfuerzo permanente de las administraciones por la apertura de datos, existen organizaciones no gubernamentales y asociaciones que contribuyen desarrollando aplicaciones que usan técnicas de machine learning dirigidas a mejorar la vida de la ciudadanía. Destacamos tres de ellas:
ML Commons impulsa un sistema de aprendizaje automático mejor para todos
Esta iniciativa pretende mejorar el impacto positivo del aprendizaje automático en la sociedad y acelerar la innovación ofreciendo herramientas como conjuntos de datos, mejores prácticas y algoritmos abiertos. Entre sus miembros fundadores se encuentran empresas como Google, Microsoft, DELL, Intel AI, Facebook AI, entre otras.
Según ML Commons, en torno al 80% de las investigaciones realizadas en el ámbito del machine learning se basan en datos abiertos. Por lo tanto, los datos abiertos son vitales para acelerar la innovación en esta materia. Sin embargo, hoy en día, “la mayoría de los ficheros de datos públicos disponibles son pequeños, estáticos, tienen restricciones legales y no son redistribuibles”, tal y como asegura David Kanter, director de ML Commons.
En esta línea, las tecnologías innovadoras de ML necesitan grandes conjuntos de datos con licencias que permitan su reutilización, que puedan ser redistribuibles y que estén en continua mejora. Por ello, la misión de ML Commons es contribuir a mitigar esa brecha y para así impulsar la innovación en machine learning.
El principal objetivo de esta organización es crear una comunidad de datos abiertos para el desarrollo de aplicaciones machine learning. Su estrategia se basa en tres pilares:
En primer lugar, crear y mantener conjuntos de datos abiertos completos. Entre otros: The People’s Speech, con más de 30.000 horas de discurso en inglés para entrenar modelos de procesamiento del lenguaje natural (PLN), Multilingual Spoken Words, con más de 23 millones de expresiones en 50 idiomas diferentes o Dollar Street, con más de 38.000 imágenes de hogares de todo el mundo en situaciones socioeconómicas variadas. El segundo pilar consiste en impulsar buenas prácticas que faciliten la estandarización. Ejemplo de ello es el proyecto MLCube que propone estandarizar el proceso de contenedores para modelos ML para facilitar su uso compartido. Y, por último, realizar benchmarking en grupos de estudios para definir puntos de referencia para la comunidad desarrolladora e investigadora.
Aprovechar las ventajas y formar parte de la comunidad ML Commons es gratuito para las instituciones académicas y las empresas pequeñas (menos de diez trabajadores).
Datacommons sintetiza diferentes fuentes de datos abiertos en un único portal
Datacommons busca potenciar los flujos democráticos de datos dentro de la economía cooperativa y solidaria y tiene como objetivo principal ofrecer datos depurados, normalizados e interoperables.
La variedad de formato e información que ofrecen los portales públicos de datos abiertos puede llegar a ser un obstáculo para la investigación. El objetivo de Datacommons es compilar datos abiertos en una web enciclopédica que ordena todos los dataset mediante nodos. De esta manera, el usuario puede acceder a la fuente que más le interesa.
Esta plataforma, que fue diseñada con fines educativos y de investigación periodística, funciona como herramienta de referencia para navegar entre distintas fuentes de datos. El equipo de colaboradores trabaja para mantener la información actualizada e interactúa con la comunidad a través de su e-mail (support@datacommons.org) o foro de GitHub.
Papers with Code: el repositorio de materiales en abierto para alimentar modelos machine learning
Se trata de un portal que ofrece código, informes, datos, métodos y tablas de evaluación en formato abierto y gratuito. Todo el contenido de la web está bajo licencia CC-BY-SA, es decir, permite copiar, distribuir, exhibir y modificar la obra incluso con fines comerciales compartiendo las contribuciones realizadas con la misma licencia original.
Cualquier usuario puede contribuir aportando contenido e, incluso, participar en el canal de Slack de la comunidad que está moderado por responsables que protegen la política de inclusión definida por la plataforma.
A día de hoy, Papers with Code aloja 7806 conjuntos de datos que se pueden filtrar según formato (gráfico, texto, imagen, tabular etc.), tarea (detección de objeto, consultas, clasificación de imágenes etc.) o idioma. El equipo que mantiene Papers with Code pertenece al instituto de investigación de Meta.
El objetivo de ML Commons, Data Commons y Papers with Code es mantener y hacer crecer comunidades de datos abiertos que contribuyan al desarrollo de tecnologías innovadoras. Entre ellas, la inteligencia artificial (machine learning, deep learning etc.) con todas las posibilidades que su desarrollo puede llegar a ofrecer a la sociedad.
Como parte de este proceso, las tres organizaciones desarrollan un papel fundamental: ofrecen repositorios de datos en formato estándar y redistribuible para entrenar modelos machine learning. Son recursos útiles para realizar ejercicios académicos, impulsar la investigación y, al fin y al cabo, facilitar la innovación de tecnologías que cada día están más presentes en nuestra sociedad.
Blog
Un gráfico estadístico es una representación visual diseñada para albergar una serie de datos cuyo objetivo es evidenciar una realidad concreta. Sin embargo, transmitir de forma divulgativa un conjunto de datos no es una tarea sencilla, si queremos captar la atención y presentar la información de manera precisa
Facilitar la comparación entre los datos, destacar las tendencias, no inducir a errores de visualización e ilustrar el mensaje que se desea transmitir requiere de un mínimo conocimiento estadístico. Por ello, en función del tipo de relación que exista entre los datos que buscamos ilustrar, debemos decantarnos por un tipo de visualización u otra. Es decir, no es lo mismo representar una clasificación numérica que el grado de correlación entre las dos variables.
Con la finalidad de escoger de manera precisa cuáles son los gráficos más adecuados en función de la información a transmitir, desglosamos los más recomendados por cada tipo de asociación entre variables numéricas. Para elaborar este contenido se ha tomado como referencia la Guía de Visualización de datos para entidades locales publicada recientemente por la RED de Entidades Locales por la Transparencia y Participación Ciudadana de la FEMP, así como esta infografía elaborada por el Financial Times.

Desviación
Sirve para subrayar las variaciones numéricas desde un punto de referencia fijo. Habitualmente, el punto de referencia es cero, pero también puede ser un objetivo o un promedio a largo plazo. Además, este tipo de gráficos resultan útiles para mostrar sentimientos (positivo, neutral o negativo). Los gráficos más frecuentes son:
- Barra Divergente: Un gráfico de barras estándar simple que permite manejar valores de magnitud tanto negativos como positivos.
- Tabla de columna: Divide un valor único en 2 componentes contrastables (p. ej., masculino/femenino).
Correlación
Útil para mostrar la relación entre dos o más variables. Conviene tener en cuenta que, a menos que les diga lo contrario, muchos lectores asumirán que las relaciones que les muestra son causales. Estos son algunos de los gráficos.
- Gráfico de dispersión: La forma estándar de mostrar la relación entre dos variables continuas, cada una de las cuales tiene su propio eje.
- Línea del tiempo: Una buena manera de mostrar la relación entre una cantidad (columnas) y un ratio (línea).
Clasificación
Es necesario clasificar variables numéricas cuando la posición de un elemento en una lista ordenada es más importante que su valor absoluto o relativo. A través de los gráficos dispuestos a continuación es posible resaltar los puntos de interés.
- Gráfico de barras: Este tipo de visualizaciones permiten mostar los rangos de valores de forma sencilla cuando se ordenan.
- Diagrama tira de puntos: Los puntos están ordenados en una tira. Esta distribución ahorra espacio para diseñar rangos en múltiples categorías.
Distribución
Este tipo de gráficos buscan resaltar una serie de valores dentro de un conjunto de datos y representar con qué frecuencia ocurren. Es decir, se utilizan para mostrar cómo se distribuyen las variables a lo largo del tiempo, lo que ayuda a identificar valores atípicos y tendencias.
La forma en sí misma de una distribución puede ser una forma interesante de resaltar la falta de uniformidad o igualdad en los datos. Las visualizaciones más recomendadas para representar, por ejemplo, una distribución por edad o sexo son las siguientes:
- Histograma: Es la forma más habitual de mostrar una distribución estadística. Para desarrollarlo se recomienda mantener un pequeño espacio entre las columnas para, así, resaltar la "forma" de los datos.
- Gráfico de cajas: Eficaz para visualizar distribuciones múltiples mostrando la mediana (centro) y el rango de los datos.
- Pirámide poblacional: Conocido por mostrar la distribución de la población por sexo. De hecho, se trata de una combinación de dos gráficos de barras horizontales compartiendo el eje vertical.
Cambios en el tiempo
A través de esta combinación de variables numéricas es posible dar énfasis a tendencias cambiantes. Estos pueden ser movimientos cortos o series extendidas que atraviesan décadas o siglos. Elegir el período de tiempo correcto a representar es clave para ofrecer un contexto al lector.
- Línea: Es la forma estándar para mostrar una serie temporal cambiante. Si los datos son muy irregulares puede ser útil emplear marcadores que ayuden a representar puntos de datos.
- Mapa de calor calendario: Sirve para mostrar patrones temporales (diario, semanal, mensual). Es necesario ser muy precisos con la cantidad de datos.
Magnitud
Útil para visibilizar comparaciones de tamaño. Estas pueden ser relativas (simplemente pudiendo ver más grande/mayor) o absolutas (requiere ver diferencias más específicas). Por lo general, muestran variables que pueden ser contadas (por ejemplo, barriles, dólares o personas), en lugar de una tasa calculada o un porcentaje.
- Columnas: Una de las maneras más comunes de comparar el tamaño de las cosas. El eje siempre debe comenzar en 0.
- Gráfico de Marimekko: Ideal para mostrar el tamaño y la proporción de los datos al mismo tiempo, y siempre y cuando, los datos no sean muy complejos.
Parte de un todo
Este tipo de combinaciones numéricas son útiles para mostrar cómo una entidad en sí misma puede dividirse en los elementos que lo conforman. Por ejemplo, es común utilizar la parte de un todo para representar la asignación de unos presupuestos o resultados electorales.
- Gráfico de tarta: Uno de los gráficos más comunes para mostrar datos parciales o completos. Conviene tener presente que no es fácil comparar de forma precisa el tamaño de los distintos segmentos.
- Diagrama de Venn: Limitado a representaciones esquemáticas que permiten mostrar interrelaciones o coincidencias.
Espacial
Se recurre a este tipo de gráficos cuando las ubicaciones precisas o los patrones geográficos en los datos son más importantes para el lector que cualquier otra cosa. Algunos de los más utilizados son:
- Mapa coroplético: Se trata del enfoque estándar para colocar datos en un mapa.
- Mapa de flujo: Es utilizado para mostrar un movimiento de cualquier tipo dentro de un mismo mapa. Por ejemplo, puede emplearse para representar movimientos migratorios.
Conocer las diferentes opciones de representación estadística existentes ayuda a crear visualizaciones de datos más precisas, lo que a su vez permite que la realidad que se busca evidenciar sea concebida de forma más clara. Así, en un contexto donde cada vez la información visual tiene más peso, es clave desarrollar las herramientas necesarias para que la información contenida en los datos llegue a la ciudadanía y contribuya a mejorar la sociedad.
Blog
Muchas organizaciones y administraciones han encontrado en los datos abiertos un pilar transformacional sobre el que ejercer la estrategia hacia la cultura del dato. Tener acceso a datos de forma estructurada es la base de nuevos modelos de negocio, así como de nuevas iniciativas dirigidas al ciudadano en los diferentes ámbitos de actuación.
Sin embargo, obtener todo el potencial de los datos abiertos, requiere de una plataforma capaz de poner a disposición de terceros estos datos asegurando su calidad, entendimiento, privacidad y seguridad.
En este contexto, el libro “Designing Data Spaces”, incluye un capítulo, firmado por Fabian Kirstein and Vincent Bohlen, donde se propone el uso de la arquitectura IDS-RAM propuesta por la International Data Spaces (IDS) para el desarrollo de ecosistemas de datos abiertos. En él se aborda una prueba de concepto sobre la viabilidad de la arquitectura de IDS para disponer espacios de datos públicos con el objetivo de lograr una base sólida que permita construir y mantener ecosistemas de datos abiertos interoperables, capaces de hacer frente a los retos existentes.
A continuación, se resumen las opiniones recogidas en el capítulo.
Ecosistemas de datos abiertos
Los espacios de datos son ecosistemas donde diversos actores comparten datos de manera voluntaria y segura, siguiendo mecanismos comunes de gobernanza, organizativos, normativos y técnicos.
Con el objetivo de impulsar la economía digital global, mediante un sistema seguro y soberano de intercambio de datos en el que todos los participantes puedan obtener el máximo valor de sus datos, en 2016 surge IDSA (International Data Spaces Association), una coalición de más de 130 empresas internaciones con representación en más de 20 países en todo el mundo.
Entre otras iniciativas, promueve un modelo de referencia arquitectónico denominado IDS-RAM, que pretende facilitar el intercambio de datos para optimizar su valor, pero sin perder su control. Ofrece varios enfoques cuya aplicabilidad puede entenderse tanto en el contexto de datos privados como de datos abiertos, ya que se basa en repositorios de metadatos para compartir información. Es decir, los datos permanecen bajo el control de sus propietarios y son los metadatos estandarizados los que se gestionan de forma centralizada para su compartición.
La creación de los espacios de datos conlleva una serie de riesgos a los que hacer frente, tanto desde el punto de vista del consumidor como del proveedor. Los proveedores de datos ponen el foco en el cumplimiento legal, mediante aspectos como la propiedad de los datos. Aunque existen normas comunes para aspectos como la descripción de metadatos - La World Wide Web Consortium no es ajena al problema y por ello propuso hace ya varios años su Data Catalog Vocabulary (DCAT), un estándar para describir catálogos de datos - lo cierto es que la interoperabilidad, en ocasiones, está lejos de su mayor potencial. Esto se debe a que a veces existen metadatos incompletos, la calidad es escasa, los datos están obsoletos, existen dificultades para acceder a datos e interoperar, etc.
La aplicabilidad de IDS-RAM en entornos de datos abiertos
IDS ofrece un enfoque basado en garantizar la soberanía de los datos a los proveedores, facilitando el intercambio de datos y dando respuesta a las preocupaciones tanto de consumidores como de proveedores.
Los conceptos y tecnologías subyacentes a los datos abiertos y al IDS-RAM son muy similares. Ambas iniciativas se basan en repositorios de metadatos para compartir información sobre la disponibilidad y accesibilidad de los datos. Estos repositorios almacenan metadatos, sin necesidad de transferir los datos reales. Por lo tanto, ambos conceptos siguen los principios de descentralización y transferencia de metadatos desde y hacia los puntos centrales de acceso a la información. Los datos reales permanecen bajo el control de la infraestructura del editor de datos hasta que un usuario los solicita. Además, el modelo de información de IDS se basa en los principios de Linked Data y DCAT. Esto hace que sea un sistema fácilmente compatible con los portales de datos abiertos, impulsando la interoperabilidad entre espacios de datos y portales de datos abiertos.
La arquitectura que propone IDS se basa principalmente en dos artefactos, un conector a las fuentes de datos (Open Data Connector) y un almacén de metadatos (Open Data Broker), tal como muestra la siguiente imagen extraída del libro “Designing Data Spaces”:
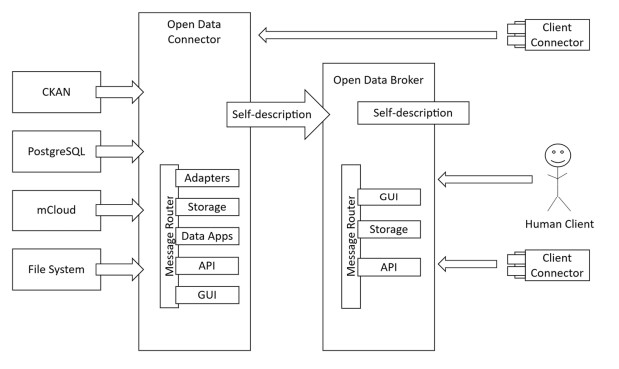
- Open Data Connector: adopta el rol de proveedor de datos abiertos. Cada entidad publicadora, aplica una instancia del conector para anunciar la disponibilidad y conceder accesos a los datos. Al tratarse de datos abiertos, y por tanto públicos, no es necesario aplicar políticas de uso o restricciones tan estrictas como cuando hablamos de otros conectores de datos privados basados en esta arquitectura, lo que permite una configuración y manejo a priori más sencillo.
- Open Data Broker: el repositorio centralizado de metadatos cumple una función similar a la de un portal de datos abiertos. A partir de estos metadatos, la interfaz de portal ofrece funcionalidades para localizar y descargar los datos desde los conectores.
Esta gestión permite agrupar por diferentes ámbitos de aplicación, es decir, se pueden crear repositorios de metadatos centralizadosde sectores como salud o turismo, así como a nivel municipal, regional, nacional o internacional.
En un ecosistema de datos como el que se propone por IDS, el conector informa sobre los datos disponibles o actualizados, y en el repositorio de metadatos estos se actualizan en consecuencia. Para ello se utilizan mecanismos de comunicación basados en el modelo de información de IDS (IDS information model) y el protocolo IDS (IDS Communication Protocol o IDSCP) que anuncian posibles modificaciones en la disponibilidad de los datos. De esta manera, se garantiza la disponibilidad de los datos actualizados.
En los portales de datos abiertos que recogen un gran número de fuentes de datos, la accesibilidad y la usabilidad general dependen de los metadatos suministrados por los proveedores de datos originales. Las normas como DCAT proporcionan una base común, pero IDS ofrece especificaciones más estrictas en el proceso de comunicación.
Aunque es una propuesta interesante, en el contexto de datos abiertos, este enfoque aún no ha sido implantada en ningún espacio. No obstante, ya se han realizado pruebas de concepto, como puede verse en el Public Data Space, un escaparate disponible desde diciembre de 2020 que reproduce cómo funciona la solución. En él, los conectores exponen la oferta de datos abiertos de diferentes portales de datos de Alemania y se registran en un almacén de metadatos.
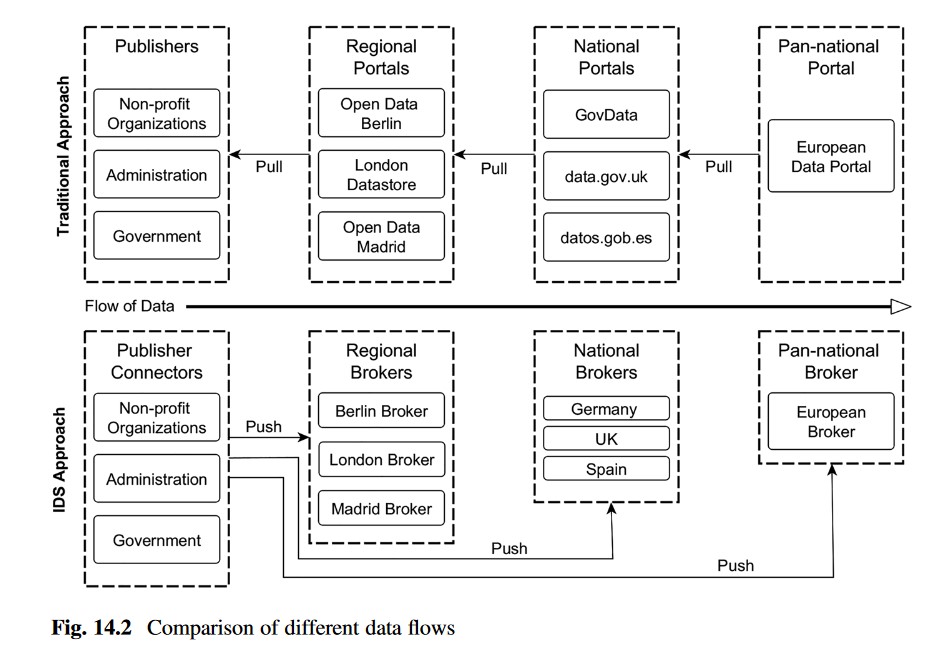
La siguiente imagen muestra el flujo de trabajo de un modelo basado en IDS-RAM versus un enfoque más tradicional:
Conclusiones
Los portales de datos abiertos suministran acceso a datos abiertos procedentes de diversos proveedores. La usabilidad general de estos portales, está supeditada en cierto modo al descubrimiento de los datos, que a su vez depende de la calidad de sus metadatos.
Para contrarrestar los problemas de datos no disponibles o enlaces muertos que en ocasiones se producen en entornos de datos abiertos, los portales recogen periódicamente los catálogos de datos del publicador y realizan comprobaciones de disponibilidad. En el ecosistema de datos abiertos basado en IDS-RAM, el conector informa al bróker sobre los conjuntos de datos disponibles o actualizados. El enfoque "pull" de la responsabilidad en los entornos habituales de datos abiertos se invierte en un enfoque "push" en el ecosistema de IDS. Este enfoque focaliza en la responsabilidad del publicador de mantener la oferta de datos y además presenta nuevas posibilidades para controlar su difusión. Utilizando IDS-RAM, el publicador elige a qué broker de metadatos se inscribe, lo que le otorga una mayor soberanía sobre sus datos.
Para los consumidores de datos, este enfoque puede suponer mejoras en cuanto a la posibilidad de encontrar los datos en el momento oportuno y reduce la fragmentación. Además, si los datos abiertos pueden adquirirse, manejarse y procesarse con las mismas herramientas y aplicaciones que ya se aplican en la industria, las posibilidades de integración y reutilización se multiplican.
Contenido elaborado por Juan Mañes, experto en Data Governance.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La economía del dato supone una gran oportunidad de negocio para empresas de todos los tamaños y sectores. De acuerdo con las estimaciones de la Comisión Europea, la Economía del Dato alcanzará un valor de 829.000 millones de euros en 2025 para los 27 países miembro. Pero para que la economía del dato se desarrolle adecuadamente, son necesarias estructuras que faciliten el intercambio de datos y, con ello, el desarrollo de modelos de negocio basados en su exploración y explotación.
Los espacios de datos cumplen esta función al facilitar el desarrollo de un ecosistema donde diversos actores comparten datos de manera voluntaria y segura. Para ello deben seguir mecanismos comunes de gobernanza, organizativos, normativos y técnicos.
Una forma de garantizar que esto se realiza adecuadamente es a través de modelos de referencia, como el modelo arquitectónico de referencia IDS-RAM (International Data Spaces Reference Architect Model), una iniciativa elaborada por la asociación del mismo nombre (International Data Space Association) y avalada por la Unión Europea.
¿Qué es la International Data Space Association?
IDSA (International Data Spaces Association) es una coalición que actualmente integran 133 empresas internacionales, sin ánimo de lucro, que surge en 2016 para trabajar en el concepto de espacio de datos y en los principios que debe seguir su diseño para obtener valor de los datos a través de la compartición, en base a mecanismos seguros, transparentes y con equidad de los participantes, que garanticen la soberanía y confianza. Estas empresas representan a decenas de sectores industriales y tienen sede en 22 países de todo el mundo.
IDSA está conectada con diferentes iniciativas europeas, incluyendo BDVA, FIWARE y Plattform Industrie 4.0, participando en más de veinte proyectos de investigación europeos, principalmente en el programa Horizonte 2020.
La misión de IDSA es impulsar la economía digital global. Para ello, entre otras cuestiones, promueve un modelo de referencia arquitectónico denominado IDS (International Data Spaces), un sistema seguro y soberano de intercambio de datos. El objetivo de este modelo es estandarizar el intercambio de datos de forma que los participantes pueden obtener todo el valor posible de su información sin perder su control, marcando las condiciones de uso de sus propios datos.
Arquitectura IDS-RAM
El modelo de arquitectura de referencia IDS-RAM (Reference Architecture model) se caracteriza por presentar una arquitectura abierta (publican su código como software de fuentes abiertas), confiable y federada para un intercambio de datos intersectorial, facilitando la soberanía y la interoperabilidad.
IDS-RAM establece una serie de roles e interacciones estandarizadas a través de una estructura en 5 capas (negocios, funcional, procesos, información y sistemas) que se abordan desde la perspectiva de la seguridad, la certificación y la gobernanza, como muestra la siguiente figura.
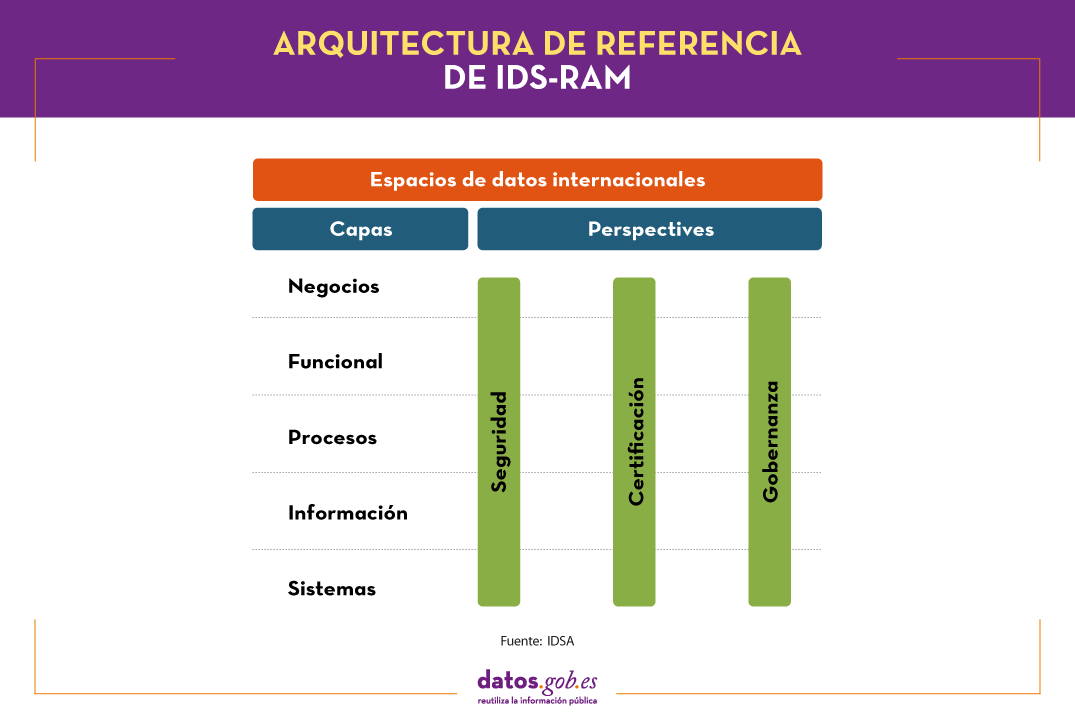
Estas capas son fundamentales para garantizar el éxito de una iniciativa de compartición de datos. Veamos cada una de ellas en base a lo indicado en el documento “Reference architecture model”, de la propia IDSA, y el informe “Posicionamiento sobre los Espacios de Datos” de Planetic, donde se analiza IDS-RAM como caso de éxito.
La capa de negocios define los diferentes roles existentes y los patrones de interacción entre ellos, incluyendo los contratos y políticas de uso de los datos. En concreto, existen cuatro roles:
- Participante esencial: cualquier organización que posea, ofrezca o consuma datos.
- Intermediario: entidades de confianza y de intermediación, como los brókers, las cámaras de compensación o los proveedores de identidades, entre otros.
- Proveedor de Servicios/Software: compañías que ofrecen servicios y/o software a los participantes.
- Órgano de gobierno: como por ejemplo los órganos de certificación, fundamentales para garantizar las capacidades de las organizaciones y generar un entorno de confianza. También entraría en este apartado la propia Asociación IDS.
Estos roles se relacionan en un ecosistema marcado por seis categorías de requisitos, definidos en la capa funcional:
- Confianza, alcanzada gracias a la gestión de identidades y la certificación de usuarios.
- Seguridad y soberanía de datos, donde se situarían la autenticación y autorización, las políticas de uso, la comunicación fiable y la certificación técnica.
- Ecosistema de datos, que incluye la descripción de las fuentes de datos, la intermediación (brokering) y los vocabularios utilizados para los metadatos.
- Estandarización e interoperabilidad, que asegura la operabilidad necesaria para alcanzar el éxito en el intercambio de datos.
- Aplicaciones de valor agregado, que permiten transformar o procesar los datos.
- Mercado de datos, que abarca aspectos como la facturación, restricciones de uso, gobernanza, etc., necesarios cuando el intercambio de datos se realiza bajo modelos de pago.
La capa de operaciones recoge las interacciones que se realizan en el marco del espacio de datos, incluyendo la incorporación de usuarios, para lo cual necesitan adquirir una
identidad proporcionada por un organismo de certificación y solicitar un conector de datos (un componente técnico a instalar) a un proveedor de software. En esta capa también se definen los procesos necesarios para el intercambio de datos y la publicación y uso de apps de datos.
La capa de información explica el modelo de información y el vocabulario común a utilizar para facilitar la compatibilidad y la interoperabilidad de tal forma que se pueda automatizar el intercambio de datos. Para su definición se utiliza una ontología propia basada en un esquema RDF.
Por último, la capa del sistema asigna una arquitectura concreta de datos y servicios a cada rol, con el fin de garantizar los requisitos funcionales.
Todas estas abstracciones de capas y perspectivas habilitan el intercambio de datos entre proveedores y consumidores de datos, utilizando los oportunos conectores software, accediendo al bróker de metadatos donde se especifican los catálogos de datos y sus condiciones de uso, existiendo la posibilidad de desplegar aplicaciones para el tratamiento de los datos y llevando un seguimiento de las transacciones realizadas (clearing house), todo ello garantizando la identidad de los participantes.
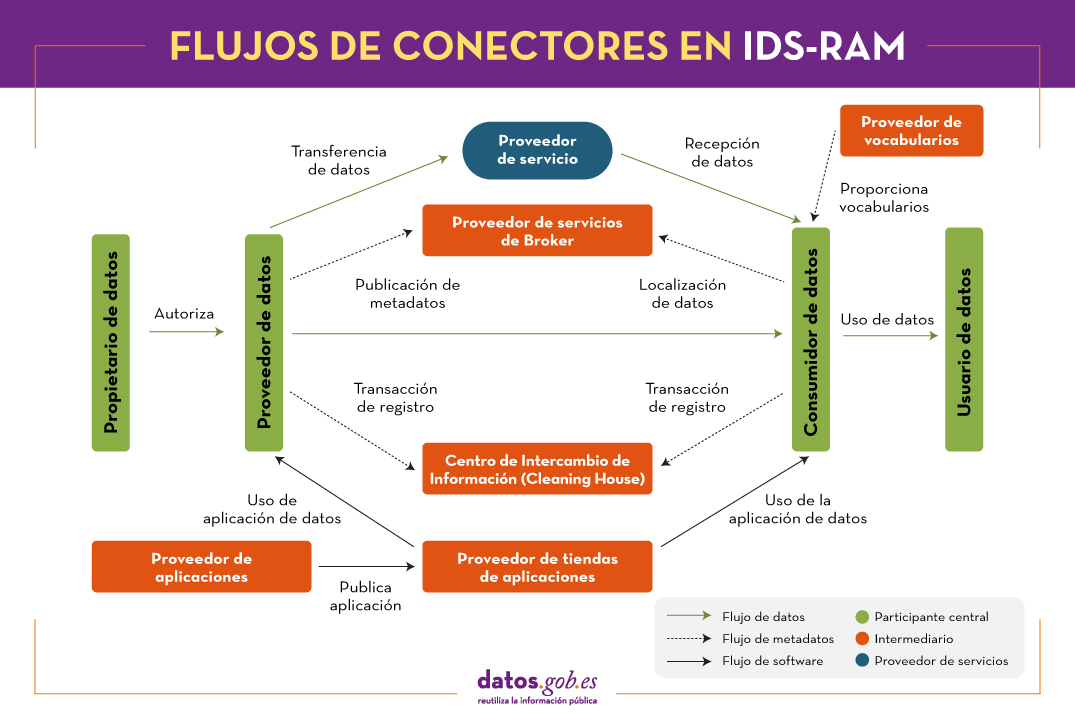
En definitiva, se trata de un marco funcional que proporciona un marco de gobernanza para logar una interoperabilidad segura y confiable, así como una arquitectura de software abierta, con el fin de garantizar su máxima adopción. En este sentido, la IDSA se ha marcado como objeticos:
- Establecer el modelo (RAM) de IDS como el estándar internacional para el intercambio de datos en la economía del futuro
- Evolucionar este modelo de referencia según casos de uso
- Desarrollar y evolucionar una estrategia de adopción del mismo
- Apoyar su despliegue en base a soluciones de software certificables y modelos comerciales
Este estándar ya está siendo utilizado por múltiples empresas tan diversas como Deutsche Telekom, IBM o Volkswagen.
El papel del IDS-RAM en Gaia-X y la Estrategia Europea de datos
El modelo de arquitectura de referencia de IDS se enmarca dentro de las iniciativas desplegadas en el marco general de la estrategia de datos de la UE.
A través de varias iniciativas, la Comisión Europea busca fomentar e interconectar los espacios de datos para impulsar la consulta, compartición y explotación cruzada de los datos disponibles, garantizando su privacidad. Es en este marco donde se ha puesto en marcha Gaia-X, una iniciativa europea del sector privado para la creación de una infraestructura de datos abierta, federada e interoperable, constituida sobre los valores de soberanía digital y disponibilidad de los datos, y el fomento de la economía del dato.
La asociación IDSA, promotora de la arquitectura de referencia IDS, participa activamente en Gaia-X, para que las iniciativas actualmente en marcha con objeto de elaborar modelos e implementaciones de referencia para la compartición de datos con soberanía y confianza, puedan confluir en un estándar de facto abierto.
Contenido elaborado por el equipo de datos.gob.es.