Noticia
Training is one of the pillars that support the open data ecosystem in Europe. Publishing data is essential, but just as important is that there are capabilities to understand, reuse and manage it properly. In this context, the European Open Data Portal (data.europa.eu) offers an online training programme that allows you to become familiar with the open data ecosystem from different angles: basic concepts, legal frameworks, emerging trends, success stories or good practices of publication and reuse.
This program has incorporated a relevant novelty in 2026: learning paths or structured learning itineraries, which allow you to advance step by step in the domain of open data.
From datos.gob.es we want to publicize this update, which reinforces the European training offer and complements already consolidated initiatives. We tell you about it in this post.
What changes in 2026? Step-by-step itineraries
The main novelty is the incorporation of learning paths, conceived as structured training paths that group content (readings, videos and quizzes) in a logical and progressive order.
Until now, the academy allowed free access to courses organized by subject (Policy, Legal, Quality, Business, Impact, Communication and Portal) and level (beginner, intermediate or advanced). With the new itineraries, learning becomes a more guided experience:
- An itinerary is chosen according to the level of experience.
- Progress is made sequentially.
- Activities and questionnaires are carried out.
- A certification is obtained at the end.
This structure makes learning particularly easy for those who are looking for an orderly training, with clear objectives and a defined progression.
The new itineraries are especially aimed at the public sector, although anyone interested can take them. They are organized into three levels.
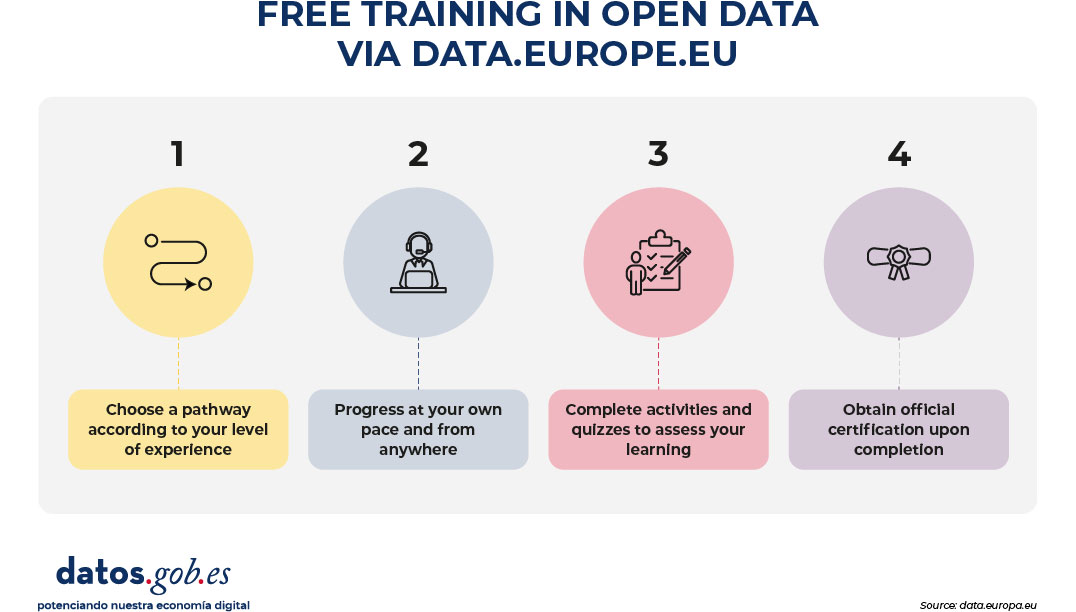
Figure 1. Free training process in open data via data.europe.eu
1. Beginner Level: The Basics of Open Data
Approximate duration: 4 hours and 23 minutes.
This itinerary provides a solid foundation for understanding:
- What is open data?
- What are its fundamental principles?
- How they are published.
- What benefits they generate for innovation, transparency and reuse.
It is intended for people who are new to working with data or want to understand the general framework of open data. It is also useful for non-technical profiles that need a strategic vision. The goal is to build a robust conceptual foundation before addressing more complex aspects.
2. Intermediate level: the legal and strategic framework
Approximate duration: 7 hours and 3 minutes.
The second itinerary delves into the legal and public policy aspects that underpin the European data strategy. Among the topics covered are:
- The European regulatory framework on data.
- The legal implications of information sharing.
- Reuse licenses.
- Regulatory compliance.
This level is especially relevant for transparency managers, legal advisors, portal managers and profiles involved in data governance.
Understanding the legal framework is a requirement to publish data with guarantees and encourage its reuse in a secure way and in accordance with European regulations.
3. Advanced level: quality and interoperability
Approximate duration: 4 hours and 39 minutes.
The third itinerary addresses two critical issues for the success of open data: quality and interoperability.
Content includes:
- Data quality principles and metrics.
- Interoperability methodologies.
- Standardization guidelines.
- Advanced metadata management.
- Application of European standards such as DCAT-AP.
This level is aimed at technical or strategic profiles that want to improve the coherence, accessibility and reuse of published data.
In a European context where cross-border interoperability is essential, adopting common standards is a condition for generating real impact.
Digital Certificates & Badges
One of the most attractive elements of the update is the possibility of obtaining official certificates upon completion of each training itinerary.
To get them, the process is simple:
- Complete all the modules of the itinerary.
- Pass the final quiz.
- Download the corresponding certificate.
In addition, the academy allows you to earn digital badges as you progress through the content. These credentials can be shared in professional profiles and are a tangible way to accredit open data competencies.
In a work environment where data literacy is increasingly in demand, having European certificates reinforces the professional profile and demonstrates commitment to continuous training.
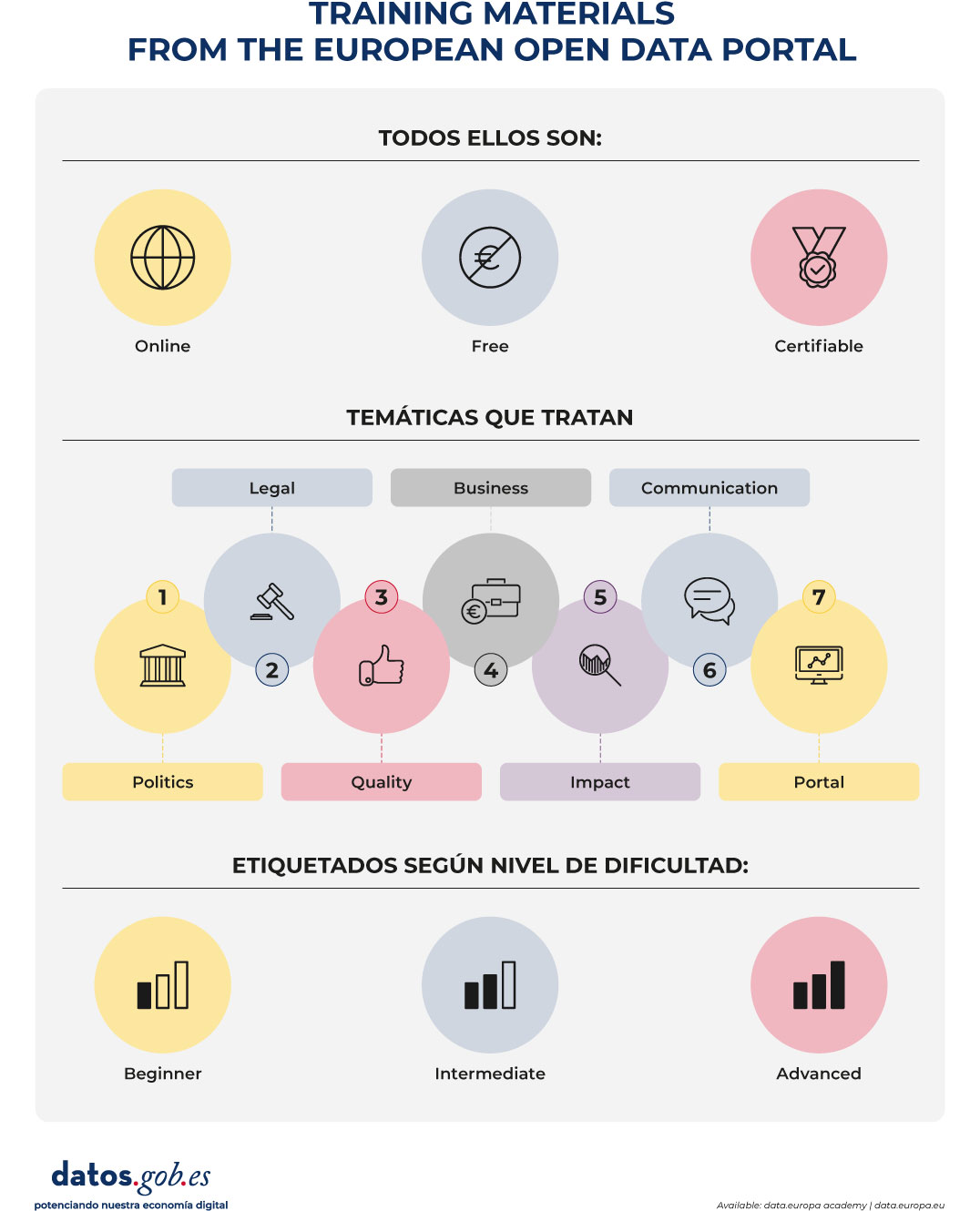
Figure 2. Training materials from the European open data portal. Source: own elaboration
Continuous training as a strategic element
One of the strengths of the academy is its applied approach. The contents show how open data is connected to specific challenges such as improving public services, promoting innovation and economic development or transparency and the evaluation of public policies.
In addition, as it is a free and accessible online platform, it eliminates economic barriers and facilitates participation from any territory.
In this sense, learning paths represent a step forward towards a more structured, coherent and recognizable training. Because, by integrating content, evaluation and certification in a single journey, the academy reinforces the value of learning and makes it easier for each person to advance at their own pace.
The European data ecosystem is evolving rapidly. The European data strategy, sectoral data spaces and common interoperability standards require trained professionals aligned with a shared vision.
The incorporation of structured itineraries in the data.europa.eu academy is a commitment to strengthen the skills necessary for open data to generate public value. Because these new training itineraries define a clearer, more progressive and accessible learning path for the entire community. The academy update will roll out throughout 2026. From datos.gob.es we will continue to share relevant information for the Spanish open data community.
Blog
In recent years, the need for the international scientific community to have agile mechanisms to share research results in order to respond to challenges such as pandemics, the climate crisis, biodiversity loss or the energy transition has become clear. In this sense, R+D tasks have become intensive in the use of both data and specialized software. A concrete example occurred during the COVID-19 pandemic, when data sharing enabled rapid sequencing of the SARS-CoV-2 genome, which was essential for the development of the COVID-19 vaccine in record time.
It is, therefore, time to promote open science. But for open science to become a reality, it is essential to avoid the fragmentation of R+D resources. Beyond scientific publications, it is necessary to connect distributed data repositories and promote software tools that are interoperable to facilitate the effective reuse of scientific datasets.
In this context, EOSC (European Open Science Cloud) was born, a European initiative that aims to connect the scientific community to make open science a reality and maximize its impact on society. EOSC offers researchers in Europe a multidisciplinary, open and trusted environment where they can publish, discover and reuse data, as well as software tools and services in the scientific field.
What is EOSC? Federated access to scientific resources
The European Open Science Cloud is the European initiative to create an open and trusted environment where the research community can publish, discover and reuse scientific data, as well as research software services. Its focus is to federate and scale scientific resources in Europe, promoting interoperability between disciplines. EOSC's ambition is to accelerate open science practices, increasing scientific productivity and strengthening the reproducibility of research in such a way as to maximise its impact on society. To this end, EOSC is conceived as a "system of systems", i.e. instead of centralizing all data and services on a single platform, EOSC interconnects existing platforms (i.e. performs a federation instead of an integration) such as data repositories, research infrastructures, or scientific software service providers.
The European Commission places EOSC as the common European space for R+D data and aligns it with the European objective of achieving a data-driven economy and society. In terms of impact, this favors the following aspects:
- Collaborative research, not only within the same scientific discipline but also between different disciplines and different territories.
- Reuse and combination of digital scientific resources (such as datasets or software services), as well as the promotion of citizen science.
- Impact on society through evidence-based policies, by improving the traceability, availability and interoperability of data that underpin public decisions.
To make EOSC a reality, a federated model is built based on nodes that act as coordinated entry points. Common policies and shared capabilities (e.g. federated authentication, catalogues and interoperability guides) are established on top of these that allow the reuse of data and services. This approach is embodied in the EOSC Federation, which connects infrastructures and communities to provide more homogeneous access to and reuse of scientific resources.
What is the EOSC Federation?
According to the EOSC Federation Handbook (a reference document describing its operational structure, legal and governance framework, and technical operation), the EOSC Federation is a distributed network of nodes. These nodes are interconnected and are able to collaborate to share and manage scientific knowledge and resources (such as datasets, software and services) across thematic and geographical communities, in compliance with FAIR principles. In other words, it is a distributed network that enables capacities to develop interoperable, secure and reliable open science at European level, across disciplines and borders.
As we have seen, the basic element of this federation are the EOSC Nodes (EOSC nodes) that function as entry points for the scientific community to the federation. These are platforms operated by organizations or consortia of territorial or thematic scope, which comprise:
- A set of capabilities essential to operating, such as authentication and access services or resource catalog.
- A set of resources, such as research data products.
A portion of those resources is selected as the Node Exchange, representing what the node shares with the federation. By aggregating the contributions of multiple nodes, they constitute the EOSC Exchange, i.e., the global supply of resources in the federation.
For all this to work, Federating Capabilities are defined as common capabilities (technical and also organizational, such as user support) that allow services to work between nodes and not as isolated silos. These capabilities are enabled by federating services operated by one or more nodes and are supported by interfaces and interoperability guides included in the EOSC Interoperability Framework. The following image graphically represents this process:
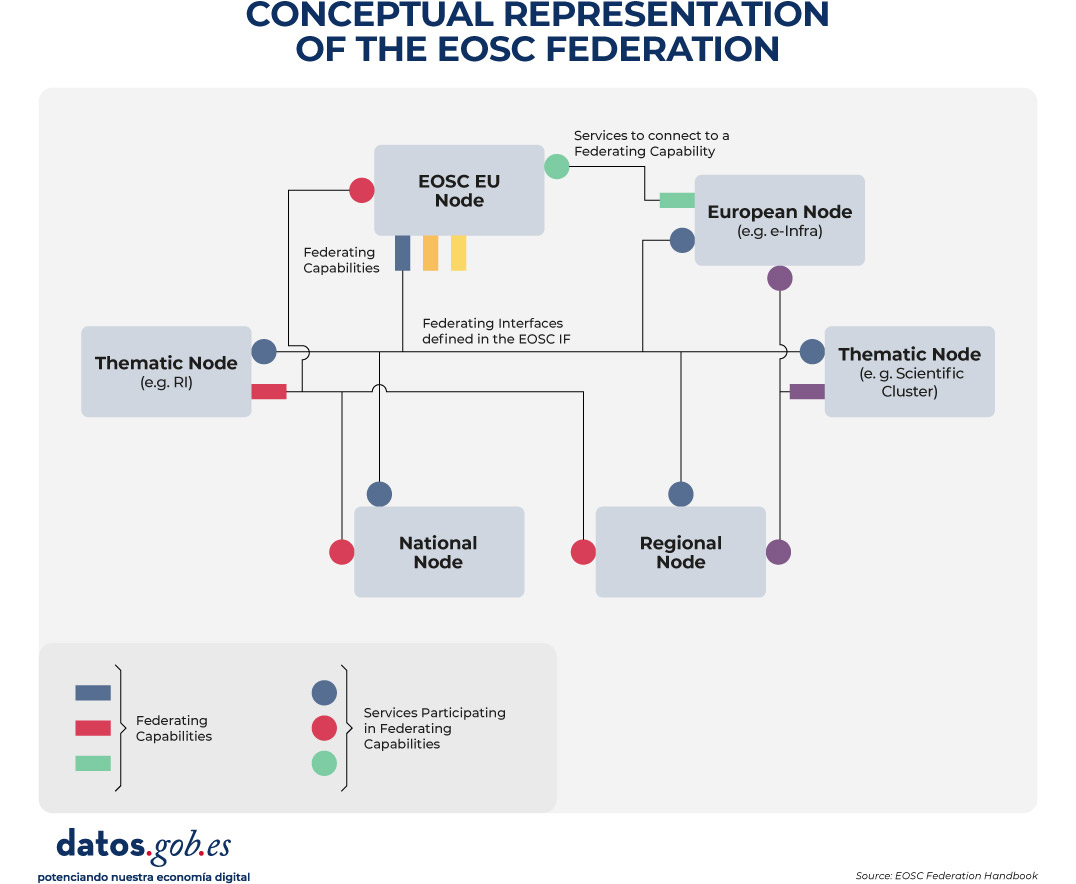
Figure 1. Conceptual representation of the EOSC Federation (source: EOSC Federation Handbook).
There are two mandatory federated capabilities: on the one hand, the authentication and authorization infrastructure (AAI) and, on the other, the resource catalogs that allow the scientific community to discover and access resources offered by the nodes, not only manually but also through computer services. These first capabilities are articulated in the EOSC EU Node.
EOSC EU Node: the first operational node
In this federated model, the EOSC EU Node (promoted by the European Commission) is especially relevant as the first node of the EOSC Federation, providing an initial set of data, tools and services, and acting as a reference node to facilitate the interconnection of other nodes.
This node allows researchers to access with institutional credentials capabilities such as virtual machines, resources such as GPUs, interactive notebooks, containerized scientific workflows, storage, data transfer, and collaborative tools, as well as connect to a catalog of resources to discover research results (scientific datasets, publications, or specialized software services) from federated infrastructures.
Conclusions
EOSC allows dispersed scientific resources to be transformed into an interoperable and reusable ecosystem that allows the scientific community to develop the objectives of open science. The EOSC Federation, through connected nodes and federated capabilities (such as AAI, catalogues or interoperability guides), facilitates access to FAIR data, services and software tools, accelerating scientific collaboration and reproducibility, as well as allowing the promotion of citizen science proposals and promoting the impact of scientific results on society. Finally, it should be noted that EOSC does not replace what already exists, but connects it, makes it interoperable and projects it on a European scale. In Spain, the definition of a national node to connect existing capacities with the EOSC Federation is advancing. Therefore, the early participation of repositories, infrastructures, research centers, universities and service providers will be key to building a representative offer, defining priorities and maximizing scientific and social impact.
Jose Norberto Mazón, Professor of Languages and Computer Systems at the University of Alicante. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
The construction of the ecosystem for the secondary use of e-health data in the European Health Data Space (EHDS) poses a significant scenario of opportunities for Spanish research, innovation and entrepreneurship. To this end, the European Union is promoting a multitude of strategic projects in which hospitals, health research foundations, universities, research centres and Spanish companies participate. The list of projects is extensive and aims to satisfy at least two objectives: to promote the generation of infrastructures capable of generating quality datasets and to promote conditions for their reuse.
The role of Spain. Strengths in the deployment of the European Health Area
Spain offers significantly favourable conditions not only to participate but also to contribute significantly to the tasks of creating the EHDS
- First, our public health system is characterized by a high level of integration and structuring. Unlike systems based on reimbursement mechanisms, in which there may be an atomisation in the field of service provision, in our system we have a clear frame of reference in primary care, medical specialities and hospital services.
- On the other hand, the experience deployed by our health environments from the General Data Protection Regulation (GDPR) and, particularly, the lessons learned from the seventeenth additional provision on health data processing of Organic Law 3/2018, of 5 December, on the Protection of Personal Data and guarantee of digital rights (LOPDGDD) they constitute a valuable experience.
- The opening of the National Health Data Space promoted by the Government of Spain and promoted by the Ministry for Digital Transformation and Public Function, the Ministry of Health and the Autonomous Communities allows the deployment of an essential infrastructure for the EHDS.
The National Health Data space was presented on January 29. The event highlighted how this project represents a paradigm shift that revolutionizes the management of health data, promoting a federated, secure and ethical model that preserves the sovereignty and privacy of information while facilitating its use for research, innovation and public policies. Its operation is based on a federated catalog of metadata and a rigorous process of access and analysis in secure environments, which seeks to promote open science and scientific and technological advances, benefiting patients, researchers, managers and industry.
Lessons learned from European Projects
The path taken by Regulation (EU) 2025/327 of the European Parliament and of the Council of 11 February 2025 on the European Health Data Space, amending Directive 2011/24/EU and Regulation (EU) 2024/2847 (EEDSR), poses significant challenges that are addressed in research projects funded by European and national funds. The lessons learned in some of them can be extraordinarily useful for the research and entrepreneurship community in our country. We cannot forget that we start from significant strengths.
1.-Compliance by design
The existence of a new regulation requires a rigorous analysis of the state of the art in our organizations, not only to implement its deployment but also to ensure the preconditions of legal reliability of the datasets and the research that is proposed.
2.-Accountability: proactive responsibility and documentary strength
In our country we come from a long tradition of accountability. The EEDSR will impose on the data requester a set of relevant documentary requirements, such as, for example, having provided safeguards to prevent any misuse of electronic health data. This issue cannot be neglected from the point of view of data holders, who will also have to meet certain requirements. For example, proving that data is legitimate and reusable is an ethical and legally documentable issue; and the simplified procedure for accessing electronic health data through a trusted health data holder requires the latter to document the security of its data space or capabilities to evaluate requests for access to health data.
One of the main obstacles we face in this intermediate period of implementation of the EHDS lies precisely in the organizational culture for the generation of verifiable evidence. As standardization and the set of common rules of the EEDS scale, it will be necessary to deepen the dynamics of proactive responsibility understood as demonstrated responsibility.
3. Secure processing environments
In our country, health environments by their very definition must be safe environments. The deployment of the National Security Scheme (ENS) and the GDPR have allowed the entire health system, public or private, to adopt maturity models that are perfectly consistent with the conditions of the secure processing environments defined by the EEDSR.
Challenges of the Spanish system
Along with the inherent strengths of our system, it is necessary to consider those aspects that present themselves as challenges.
1. Anonymisation and pseudonymisation
In the national context, the aforementioned seventeenth additional provision of Organic Law 3/2018, of 5 December, on the Protection of Personal Data and guarantee of digital rights, defines specific conditions for pseudonymisation. These consist of the functional separation between the teams that pseudonymize and those that reuse data, and the definition of a secure environment that prevents any attempt at re-identification. In addition, there are legal guarantees in terms of individual commitments not to re-identify, deployment of the impact assessment tool related to data protection and supervision by ethics committees. The challenge of anonymization is more demanding, since it implies the impossibility of linking health data with those of the original patient under any conditions.
2. Reeskilling of teams
The European Health Data Space (EHDS) will pose an unprecedented training challenge that will cut across all sectors involved in the health data ecosystem. Research ethics committees should familiarise themselves not only with the permissible secondary uses of health data, but also with the integration of the Artificial Intelligence Regulation and with the ethical principles of the ALTAI (Assessment List for Trustworthy Artificial Intelligence) framework. This need for reeskilling will also extend to health systems and health administration, where Health Data Access Bodies will require highly qualified personnel in these new ethical and regulatory frameworks, as well as reliable data holders who will safeguard sensitive information. Development staff and IT teams will also need to acquire new skills in critical technical areas, such as cataloguing, validation, and curation of data, as well as in interoperability standards that enable effective communication between systems. Perhaps the most sensitive training challenge will fall on new entrants, who will be able to take advantage of opportunities to access datasets for innovative secondary uses. This especially concerns technology startups in the health sector. To face a very demanding regulatory framework (GDPR, Regalmento de AI, EEDSR), the resources and capabilities for legal compliance in Spanish SMEs is notably limited. For this reason, it will be necessary to build a solid culture of data protection and ethical development of reliable artificial intelligence systems from the beginning.
3. Data cataloguing: the challenge of quality and standardization
In the context of the European Health Data Space, deepen the standardization of data through the most functional methodologies – such as OMOP CDM for observational clinical data, HL7 FHIR for dynamic information exchange, DICOM for medical imaging, or reference terminologies such as SNOMED CT, LOINC and RxNorm— is presented as a key strategic element for the creation and re-use of high-quality datasets. However, the adoption of these standards is not enough on its own: the processes of validation, semantic annotation and data enrichment require highly qualified human resources capable of ensuring the coherence, completeness and accuracy of the information, making this training a real precondition for effective participation in the European health data ecosystem. Alignment with the standardized cataloguing of datasets following the HealthDCAT-AP (Health Data Catalog Application Profile) standard, which allows the descriptive metadata of health data resources to be described in a homogeneous way, is presented as one of the immediate challenges, along with the implementation of the work that has been deployed in relation to the data utility quality label, a quality label that assesses the real usefulness of data for secondary uses and is becoming a seal of trust for users and researchers.
If previously in this article the very high capacities of the Spanish health system to generate health data in a systematic way and in significant volumes were highlighted, these aspects of cataloguing, standardization and quality certification will occupy an absolutely central place in designing optimal conditions of European competitiveness in their reuse, transforming the abundance of data into a real strategic advantage that allows Spain to position itself as a relevant player in the research and innovation landscape with electronic health data.
The experience of the EUCAIM project (Cancer Image EU)
The European Health Data Space Regulation aims to enable the secondary use of electronic health data across Europe through harmonised rules in a federated ecosystem. In the cancer arena, fragmented access to high-quality datasets slows down research, limits reproducibility and undermines Europe's ability to develop and validate reliable AI tools for oncology.
EUCAIM demonstrates the viability of an ecosystem for the secondary use of cancer through a federated model that allows cross-border access under harmonized rules guaranteeing adequate control of resources at the local level. And this is deployed through a set of enabling components:
1) A Secure Processing Environment (SPE) federated at European level
EUCAIM is creating a federated PES to enforce data access conditions, control processing, and support secure cross-border analysis under EEDS restrictions. This PES is fully in line with the requirements and measures laid down in Article 73 EEDSR for safe environments.
2) Overcoming the "anonymisation barrier"
EUCAIM promotes a layered anonymization strategy that combines dataholder-autonomous local anonymization processes with platform controls to enable datasets to remain useful for AI research and development. The importance of this approach lies in the fact that it aims to reconcile the protection of privacy with the practical need to have sets with large volumes of data characterized by their diversity.
3) Data cataloguing and standardization
EUCAIM aligns cataloguing with the HealthDCAT-AP principles whose main objective is to apply the FAIR principles, that is, to ensure that data is findable, accessible, interoperable and reusable.
4) Reduction of legal costs
EUCAIM has deployed its own compliance framework aimed at the General Data Protection Regulation and the Artificial Intelligence Regulation. To do this, a robust compliance framework is in place at the platform level that is deployed across complex data ecosystems. This is based on data protection impact assessments (included in the GDPR) with a particular focus on fundamental rights. It also incorporates training and professional retraining of users as a functional requirement, so that compliance capability becomes an essential feature.
5) Support for data users
EUCAIM offers significant advantages to data users, including researchers and AI developers, by establishing a transparent and well-governed environment for data access. The adoption of transparent governance criteria, clearly defined obligations and their technical application by the platform, provide data users with the guarantee that their access is adequate and lawful, fully auditable and remains stable over time. The platform's design ensures that users can leverage powerful data for advanced analytics, including federated processing in a secure environment. Through mandatory training and implementation of standardized procedures, teams benefit from less uncertainty and are better equipped to align with compliance requirements set forth by the EEDSR, GDPR, and AI governance frameworks.
6) Guarantee of patients' rights
EUCAIM's approach is based on data protection by design and by default that unites organisational safeguards with robust technical controls. This framework has been purpose-built to minimise the risk of data misuse, while supporting safe and effective cross-border cancer research and innovation. The result is a system in which the protection of privacy is not an obstacle but a fundamental element that allows the responsible use of data for the benefit of society and science. The model reinforces accountability for the secondary use of health data by combining strong governance oversight, a comprehensive record of actions, and strict and enforceable obligations for all participating entities. All actions taken with patient data are recorded and reviewed, ensuring that all uses are fully auditable. This traceability ensures that the processing of data is kept within the limits of the permitted use and that any deviations can be identified and addressed quickly.
Multi-level governance: the key to sustainable success
The most relevant lesson learned at EUCAIM concerns the imperative need for articulated, coherent and operational multilevel governance. In a broad sense, it is essential to provide effective governance tools and frameworks on three fundamental dimensions:
- Firstly, on the processes for generating datasets and their sharing conditions, establishing clear criteria on what data is generated, how it is standardised, who holds rights over it and under what licences and restrictions it can be shared with third parties.
- Second, on data access request processes, defining transparent and efficient procedures so that researchers, innovators, and policymakers can identify, request, and obtain access to the data needed for their projects, minimizing administrative burdens without compromising ethical and legal guarantees.
- Thirdly, on the processes of validating the correctness of the datasets and adherence to the system, as well as the procedures for authorising access to data, ensuring that only data of certified quality feed the infrastructure and that only authorised users with legitimate purposes access sensitive information.
This procedural governance cannot function without strategic and operational decisions regarding the definition of human resources roles and functions. To do this, it is necessary to have the necessary professional profiles such as data managers, experts in research ethics, cybersecurity specialists, data curators and quality managers. Secondly, it will be essential to define the secure processing environments where analyses are carried out on sensitive data, ensuring that these spaces comply with the highest technical standards of security, traceability, auditing and privacy preservation, and that they are designed to operate under the principle of zero trust) adapted to the health context. Only through this multi-level governance architecture, which integrates technical, organizational, ethical and legal dimensions at all levels of decision-making – from the design of national policies to the day-to-day operational management of platforms – will it be possible to build health data infrastructures that are truly sustainable, reliable and capable of generating long-term social, scientific and economic value. positioning the Spanish healthcare system as a strategic player in the European healthcare innovation ecosystem.
Content prepared by Ricard Martínez Martínez, Director of the Chair of Privacy and Digital Transformation, Department of Constitutional Law, University of Valencia. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
The Open Data Maturity Report is an annual evaluation that since 2015 has analysed the development and evolution of open data initiatives in the European Union. Coordinated by the European Data Portal (data.europa.eu) and carried out in collaboration with the European Commission, this report assesses 36 participating countries: the 27 EU Member States, 3 European Free Trade Association countries (Iceland, Norway and Switzerland) and 6 candidate countries.
The report assesses four key dimensions:
- Policy (strategies and regulatory frameworks)
- Portal (functionalities and usability)
- Quality (metadata and data standards)
- Impact (reuse and benefits generated)
In the 2025 edition, Spain stood out with a score of 100% in the impact block compared to the European average of 82.1%. In general terms, it occupies the fifth position among the countries of the European Union with a total score of 95.6%, forming part of the group of countries that prescribe trends.
A differential aspect of this edition of the report is the incorporation of a descriptive and contextual approach that complements the traditional regulatory model, creating clusters of countries to allow fairer comparisons. These clusters group countries with similar economic, social, political, and digital characteristics, and are based on profiles that explain how open data policies are implemented, not just what results are obtained. The aim is to invite countries to look at their peers , learn from comparable experiences and promote more effective peer-to-peer learning than based solely on general rankings.
In addition to quantifying it, the report includes use cases and good practices carried out by countries to open and reuse public sector data. In this post, we highlight some of them that can serve as inspiration to continue improving our open data ecosystem.
Croatia's inclusive and coordinated governance
One of the most noteworthy aspects of the 2025 report is how some countries have managed to establish strong governance structures that ensure coordination between different levels of administration and multi-stakeholder participation.
Croatia stands out for having established in 2025 the Coordination for the Implementation of the Open Data Policy, a multisectoral body that monitors regulatory compliance, improves data accessibility, and supports authorities. This model ensures broad participation and ensures that national and local initiatives are aligned. The national portal functions as a central hub, complemented by local portals such as the one for the city of Zagreb. In addition, knowledge exchanges are encouraged through coordination meetings, regular updates and collaborations with universities, such as the Faculty of Electrical and Computer Engineering at the University of Zagreb.
France's complete data governance structure
This country leads the ranking of the Open Data Maturity Report thanks, among others, to its comprehensive governance model that integrates open data roles at all administrative levels. At the national level, the General Data Administrator coordinates public data policy and oversees a network of chief data officers in each ministry. Etalab, the national open data and digital innovation unit, manages this network and provides technical support.
At the ministerial level, each data controller manages the data policy (openness, quality and reuse), supported by Etalab. Some ministries also appoint specific open data officers and data stewards who handle technical and organizational aspects of the publication. At the local level, each regional representative (préfet) designates a referent for data, algorithms and source codes. The Digital Inter-Ministerial Directorate also coordinates a network of API managers to enable dynamic access to data. They also ensure compliance with DCAT-AP in their metadata, as we do in Spain.
Effective implementation: from strategy to action in Italy
Italian public administrations are obliged to adopt data publication plans, following national guidelines, which prioritise high-value datasets, dynamic data and user-requested information. The implementation is supported by a robust monitoring system. The Agency for Digital Italy (AgID) tracks progress through its Digital Transformation Dashboard, which reports the growth of datasets in dati.gov.it.
Policies are updated regularly: the latest three-year plan (2024-2026) was adopted in December 2024. To assist data holders and officials, AgID provides guidance, conducts webinars, and launched the AgID Academy to strengthen digital competencies.
Culture of reuse in Poland and Ukraine
A crucial aspect of encouraging open data is to provide practical resources to guide public organizations throughout the process. Poland stands out for its open data manual, the second edition of which was published by the Ministry of Digital Affairs.
This updated handbook introduces new categories of data, explains how regulations shape open data policies, and introduces the Poland Data Portal.
The handbook functions as a checklist for offices, guiding them through their responsibilities to open data and foster a culture of reuse and include tools such as an openness checklist for compliance.
In this regard, Ukraine has also adopted an approach towards reuse and the generation of resources that incentivise this reuse of data. The Ministry of Digital Transformation has developed a comprehensive set of resources and tools including detailed technical documentation and templates to help prepare and publish datasets aligned with national standards, covering metadata structuring, licensing, and compliance with the DCAT-AP standard.
The national portal includes functionalities for tracking the publication and reuse of datasets. Suppliers receive feedback on the quality and completeness of their metadata, helping them identify areas for improvement. In addition, regular training sessions and workshops are organized to develop the skills of publishers, promoting a shared understanding of open data principles and technical requirements.
Albania: comprehensive redesign of the portal
This country exemplifies the maturity improvements that can be achieved through a comprehensive update of the national open data portal. The large-scale revamp of the portal improved usability, transparency, and user engagement.
The updated portal now features a dataset rating system (1-5 stars), a dedicated news section on open data topics , and multiple notification options, including RSS and Atom feeds, and email. Users can track the progress of their data requests, which are actively monitored and responses summarized in publicly available reports.
To better understand and respond to user needs, the portal team tracks search keywords, analyzes traffic, and conducts user surveys and workshops.
Lithuania: official monitoring methodology
One of the key practices highlighted in the report is the adoption of formal frameworks and structured methodologies that provide a systematic way to assess the impact of open data. Lithuania excels with a comprehensive approach because it defines how institutions should report on open data activities, ensuring consistency, accountability, and compliance across the public sector.
In addition, the Ministry of Economy and Innovation made calculations to estimate the economic impact of open data. This analysis provides quantifiable evidence of the contribution of open data to innovation, productivity and job creation. The results show that open data in Lithuania creates a market value of approximately €566 billion (around 1.2% of GDP) and supports close to 8,000 value-added jobs.
Germany: systematic funding for collaboration
Germany's mFund initiative provides structured financial support for mobility-related data projects, fostering partnerships beyond government.
An example is the miki (mobil im Kiez) project, which develops navigation and orientation solutions for people with limited mobility through the active engagement of civil society. The team created a national prototype with visualizations for cities such as Cologne, Kassel, Munich, Potsdam and Saarbrücken, showing building barriers and road surfaces. These visualizations will be integrated into Wheelmap.org, helping individuals with mobility disabilities.
Conclusion
In conclusion, the Open Data Maturity Report 2025 demonstrates that the most open data mature European countries share common characteristics: inclusive and well-structured governance, effective implementation supported by planning and monitoring, practical support to data publishers, continuous technical innovation in portals and, crucially, systematic impact measurement.
The good practices highlighted here are transferable and adaptable. We invite Spanish public administrations to explore these experiences, adapt them to their local contexts and share their own innovations, thus contributing to an increasingly robust and impact-oriented European open data ecosystem.
Blog
In the era of Artificial Intelligence (AI), data has ceased to be simple records and has become the essential fuel of innovation. However, for this fuel to really drive new services, more effective public policies or advanced AI models, it is not enough to have large volumes of information: the data must be varied, of quality and, above all, accessible.
In this context, the data pooling or Data Clustering, a practice that consists of Pooling data to generate greater value from their joint use. Far from being an abstract idea, the data pooling is emerging as one of the key mechanisms for transforming the data economy in Europe and has just received a new impetus with the proposal of the Digital Omnibus, aimed at simplifying and strengthening the European data-sharing framework.
As we already analyzed in our recent post on the Data Union Strategy, the European Union aspires to build a Single Data Market in which information can flow safely and with guarantees. The data pooling it is, precisely, the Operational tool which makes this vision tangible, connecting data that is now dispersed between administrations, companies and sectors.
But what exactly does "data pooling" mean? Why is this concept being talked about more and more in the context of the European data strategy and the new Digital Omnibus? And, above all, what opportunities does it open up for public administrations, companies and data reusers? In this article we try to answer these questions.
What is data pooling, how does it work and what is it for?
To understand what data pooling is, it can be helpful to think about a traditional agricultural cooperative. In it, small producers who, individually, have limited resources decide to pool their production and their means. By doing so, they gain scale, access better tools, and can compete in markets they wouldn't reach separately.
In the digital realm, data pooling works in a very similar way. It consists of combining or grouping datasets from different organizations or sources to analyze or reuse them with a shared goal. Creating this "common repository" of information—physical or logical—enables more complex and valuable analyses that could hardly be performed from a single isolated source.
This "pooling of data" can take different forms, depending on the technical and organizational needs of each initiative:
- Shared repositories, where multiple organizations contribute data to the same platform.
- Joint or federated access, where data remains in its source systems, but can be analyzed in a coordinated way.
- Governance agreements, which set out clear rules about who can access data, for what purpose, and under what conditions.
In all cases, the central idea is the same: each participant contributes their data and, in return, everyone benefits from a greater volume, diversity and richness of information, always under previously agreed rules.
What is the purpose of sharing data?
The growing interest in data pooling is no coincidence. Sharing data in a structured way allows, among other things:
- Detect patterns that are not visible with isolated data, especially in complex areas such as mobility, health, energy or the environment.
- Enhance the development of artificial intelligence, which needs diverse, quality data at scale to generate reliable results.
- Avoiding duplication, reducing costs and efforts in both the public and private sectors.
- To promote innovation, facilitating new services, comparative studies or predictive analysis.
- Strengthen evidence-based decision-making, a particularly relevant aspect in the design of public policies.
In other words, data pooling multiplies the value of existing data without the need to always generate new sets of information.
Different types of data pooling and their value
Not all data pools are created equal. Depending on the context and the objective pursued, different models of data grouping can be identified:
- M2M (Machine-to-Machine) data pooling, very common in the Internet of Things (IoT). For example, when industrial sensor manufacturers pool data from thousands of machines to anticipate failures or improve maintenance.
- Cross-sector or cross-sector data pooling, which combines data from different sectors – such as transport and energy – to optimise services, for example, the management of electric vehicle charging in smart cities.
- Data pooling for research, especially relevant in the field of health, where hospitals or research centers share anonymized data to train algorithms capable of detecting rare diseases or improving diagnoses.
These examples show that data pooling is not a single solution, but a set of adaptable practices, capable of generating economic, social and scientific value when applied with the appropriate guarantees.
From potential to practice: guarantees, clear rules and new opportunities for data pooling
Talking about sharing data does not mean doing it without limits. For data pooling to build trust and sustainable value, it is imperative to address how to share data responsibly. This has been, in fact, one of the great challenges that have conditioned its adoption in recent years.
Among the main concerns are the Protection of personal data, ensuring compliance with the General Data Protection Regulation (GDPR) and minimizing risks of re-identification; the confidentiality and the protection of trade secrets, especially when companies are involved; as well as the Quality and interoperability of the data, as combining inconsistent information can lead to erroneous conclusions. To all this is added a transversal element: the Trust between the parties, without which no sharing mechanism can function.
For this reason, data pooling is not just a technical issue. It requires clear legal frameworks, strong governance models, and trust mechanisms, which provide security to both those who share the data and those who reuse it.
Europe's role: from sharing data to creating ecosystems
Aware of these challenges, the European Union has been working for years to build a Single Data Market, where sharing information is simpler, safer and more beneficial for all actors involved. In this context, key initiatives have emerged, such as the European Data Spaces, organized by strategic sectors (health, mobility, industry, energy, agriculture), the promotion of Standards and Interoperability, and the appearance of Data Brokers as trusted third parties who facilitate sharing.
Data pooling fits fully into this vision: it is one of the practical mechanisms that allow these data spaces to work and generate real value. By facilitating the aggregation and joint use of data, pooling acts as the "engine" that makes many of these ecosystems operational.
All this is part of the Data Union Strategy, which seeks to connect policies, infrastructures and standards so that data can flow safely and efficiently throughout Europe.
The big brake: regulatory fragmentation
Until recently, this potential was met with a major hurdle: the Complexity of the European legal framework on data. An organization that would like to participate in a data pool cross-border had to navigate between multiple rules – GDPR, Data Governance Act, Data Act, Open Data Directive and sectoral or national regulations—with definitions, obligations, and competent authorities that are not always aligned. This fragmentation generated legal uncertainty: doubts about responsibilities, fear of sanctions, or uncertainty about the real protection of trade secrets. In practice, this "normative labyrinth" has for years held back the development of many common data spaces and limited the adoption of the data pooling, especially among SMEs and medium-sized companies with less legal and technical capacity.
The Digital Omnibus: Simplifying for Data Pooling to Scale
This is where the Digital Omnibus, the European Commission's proposal to simplify and harmonise the digital legal framework, comes into play. Far from adding new regulatory layers, the objective of the Omnibus is to organize, consolidate and reduce administrative burdens, making it easier to share data in practice.
From a data pooling perspective, the message is clear: less fragmentation, more clarity, and greater trust. The Omnibus seeks to concentrate the rules in a more coherent framework, avoid duplication and remove unnecessary barriers that until now discouraged data-driven collaboration, especially in cross-border projects.
In addition, the role of data intermediation services, key actors in organizing pooling in a neutral and reliable way, is reinforced. By clarifying their role and reducing certain burdens, it favors the emergence of new models – including technology startups – capable of acting as "arbiters" of data exchange between multiple participants.
Another particularly relevant element is the strengthening of the protection of trade secrets, allowing data holders to limit or deny access when there is a real risk of misuse or transfer to environments without adequate guarantees. This point is key for industrial and strategic sectors, where trust is an essential condition for sharing data.
New opportunities for data pooling: public sector, companies and data reuse
The regulatory simplification and confidence-building introduced by the Digital Omnibus is not an end in itself. Its true value lies in the concrete opportunities that data pooling opens up for different actors in the data ecosystem, especially for the public sector, companies and information reusers.
In the case of public administrations, data pooling offers particularly relevant potential. It allows data from different sources and administrative levels to be combined to improve the design and evaluation of public policies, move towards evidence-based decision-making and offer more effective and personalised services to citizens. At the same time, it facilitates the breaking down of information silos, the reuse of already available data and the reduction of duplications, with the consequent savings in costs and efforts.
In addition, data pooling reinforces collaboration between the public sector, the research field and the private sector, always under secure and transparent frameworks. In this context, it does not compete with open data, but complements it, making it possible to connect datasets that are currently published in a fragmented way and enabling more advanced analyses that expand their social and economic value.
From a business point of view, the Digital Omnibus introduces a significant novelty by expanding the focus beyond traditional SMEs. The so-called small mid-caps, mid-cap companies that also suffer the impact of bureaucracy, are now benefiting from regulatory simplification. This significantly increases the base of organizations capable of participating in data pooling schemes and expands the volume and diversity of data available in strategic sectors such as industry, automotive or chemicals.
The economic impact of this new scenario is also relevant. The European Commission estimates significant savings in administrative and operational costs, both for companies and public administrations. But beyond the numbers, these savings represent freed up capacity to innovate, invest in new digital services, and develop more advanced AI models, fueled by data that can now be shared more securely.
In short, data pooling is consolidated as a key lever to move from the punctual sharing of data to the systematic generation of value, laying the foundations for a more collaborative, efficient and competitive data economy in Europe.
Conclusion: Cooperate to compete
The proposal of data pooling in the Digital Omnibus marks a before and after in the way we understand the ownership of information. Europe has understood that, in the global data economy, sovereignty is not defended by closing borders, but by creating secure environments where collaboration is the simplest and most profitable option.
Data pooling is at the heart of this transformation. By cutting red tape, simplifying notifications, and protecting trade secrets, the Omnibus is taking the stones out of the way so that businesses and citizens can enjoy the benefits of a true Data Union.
In short, it is a question of moving from an economy of isolated silos to one of connected networks. Because, in the world of data, sharing is not losing control, it is gaining scale.
Content created by Dr. Fernando Gualo, Professor at UCLM and Government and Data Quality Consultant. The content and views expressed in this publication are the sole responsibility of the author.
Blog
To speak of the public domain is to speak of free access to knowledge, shared culture and open innovation. The concept has become a key piece in understanding how information circulates and how the common heritage of humanity is built.
In this post we will explore what the public domain means and show you examples of repositories where you can discover and enjoy works that are already part of everyone.
What is the public domain?
Surely at some point in your life you have seen the image of Mickey Mouse Handling the helm on a steamboat. A characteristic image of the Disney company that you can now use freely in your own works. This is because this first version of Mickey (Steamboat Willie, 1928) entered the public domain in January 2024 -be careful, only the version of that date is "free", subsequent adaptations do continue to be protected, as we will explain later-.
When we talk about the public domain, we refer to the body of knowledge, i nformation, works and creations (books, music, films, photos, software, etc.) that are not protected by copyright. Because of this , anyone can reproduce, copy, adapt and distribute them without having to ask permission or pay licenses. However, the moral rights of the author must always be respected, which are inalienable and do not expire. These rights include always respecting the authorship and integrity of the work*.
The public domain, therefore, shapes the cultural space where works become the common heritage of society, which entails multiple benefits:
- Free access to culture and knowledge: any citizen can read, watch, listen to or download these works without paying for licenses or subscriptions. This favors education, research and universal access to culture.
- Preservation of memory and heritage: the public domain ensures that an important part of our history, science and art remains accessible to present and future generations, without being limited by legal restrictions.
- Encourages creativity and innovation: artists, developers, companies, etc. can reuse and mix works from the public domain to create new products (such as adaptations, new editions, video games, comics, etc.) without fear of infringing rights.
- Technological boost: archives, museums and libraries can freely digitise and disseminate their holdings in the public domain, creating opportunities for digital projects and the development of new tools. For example, these works can be used to train artificial intelligence models and natural language processing tools.
What works and elements belong to the public domain, according to Spanish law?
In the public domain we find both content whose copyright has expired and content that has never been protected. Let's see what Spanish legislation says about it:
Works whose copyright protection has expired.
To know if a work belongs to the public domain, we must look at the date of the death of its author. In this sense, in Spain, there is a turning point: 1987. From that year on, and according to the intellectual property law, artistic works enter the public domain 70 years after the death of their author. However, perpetrators who died before that year are subject to the 1879 Law, where the term was generally 80 years – with exceptions.
Only "original literary, artistic or scientific" creations that involve a sufficient level of creativity are protected, regardless of their medium (paper, digital, audiovisual, etc.). This includes books, musical compositions, theatrical, audiovisual or pictorial works and sculptures to graphics, maps and designs related to topography, geography and science or computer programs, among others.
It should be noted that translations and adaptations, revisions, updates and annotations; compendiums, summaries and extracts; musical arrangements, collections of other people's works, such as anthologies or any transformations of a literary, artistic or scientific work, are also subject to intellectual property. Therefore, a recent adaptation of Don Quixote will have its own protection.
Works that are not eligible for copyright protection.
As we saw, not everything that is produced can be covered by copyright, some examples are:
- Official documents: laws, decrees, judgments and other official texts are not subject to copyright. They are considered too relevant to public life to be restricted, and are therefore in the public domain from the moment of publication.
- Works voluntarily transferred: The rights holders themselves can decide to release their works before the legal term expires. For this there are tools such as the license Creative Commons CC0 , which makes it possible to renounce protection and make the work directly available to everyone.
- Facts and Information: Copyright does not cover facts or data. Information and events are common heritage and can be used freely by anyone.
Europeana and its defence of the public domain
Europeana is Europe's great digital library, a project promoted by the European Union that brings together millions of cultural resources from archives, museums and libraries throughout the territory. Its mission is to facilitate free and open access to European cultural heritage, and in that sense the public domain is at the heart of it. Europeana advocates that works that have lost their copyright protection should remain unrestricted, even when digitized, because they are part of the common heritage of humanity.
As a result of its commitment, it has recently updated its Public Domain Charter, which includes a series of essential principles and guidelines for a robust and vibrant public domain in the digital environment. Among other issues, it mentions how technological advances and regulatory changes have expanded the possibilities of access to cultural heritage, but have also generated risks for the availability and reuse of materials in the public domain. Therefore, it proposes eight measures to protect and strengthen the public domain:
- Advocate against extending the terms or scope of copyright, which limits citizens' access to shared culture.
- Oppose attempts to undue control over free materials, avoiding licenses, fees, or contractual restrictions that reconstitute rights.
- Ensure that digital reproductions do not generate new layers of protection, including photos or 3D models, unless they are original creations.
- Avoid contracts that restrict reuse: Financing digitalisation should not translate into legal barriers.
- Clearly and accurately label works in the public domain, providing data such as author and date to facilitate identification.
- Balancing access with other legitimate interests, respecting laws, cultural values and the protection of vulnerable groups.
- Safeguard the availability of heritage, in the face of threats such as conflicts, climate change or the fragility of digital platforms, promoting sustainable preservation.
- To offer high-quality, reusable reproductions and metadata, in open, machine-readable formats, to enhance their creative and educational use.
Other platforms to access works in the public domain
In addition to Europeana, in Spain we have an ecosystem of projects that make cultural heritage in the public domain available to everyone:
- The National Library of Spain (BNE) plays a key role: every year it publishes the list of Spanish authors who enter the public domain and offers access to their digitized works through BNE Digital, a portal that allows you to consult manuscripts, books, engravings and other historical materials. Thus, we can find works by authors of the stature of Antonio Machado or Federico García Lorca. In addition, the BNE publishes the dataset with information on authors in the public domain in the open air.
- The Virtual Library of Bibliographic Heritage (BVPB), promoted by the Ministry of Culture, brings together thousands of digitized ancient works, ensuring that fundamental texts and materials of our literary and scientific history can be preserved and reused without restrictions. It includes digital facsimile reproductions of manuscripts, printed books, historical photographs, cartographic materials, sheet music, maps, etc.
- Hispana acts as a large national aggregator by connecting digital collections from Spanish archives, libraries, and museums, offering unified access to materials that are part of the public domain. To do this, it collects and makes accessible the metadata of digital objects, allowing these objects to be viewed through links that lead to the pages of the owner institutions.
Together, all these initiatives reinforce the idea that the public domain is not an abstract concept, but a living and accessible resource that expands every year and that allows our culture to continue circulating, inspiring and generating new forms of knowledge.
Thanks to Europeana, BNE Digital, the BVPB, Hispana and many other projects of this type, today we have the possibility of accessing an immense cultural heritage that connects us with our past and propels us towards the future. Each work that enters the public domain expands opportunities for learning, innovation and collective enjoyment, reminding us that culture, when shared, multiplies.
*In accordance with the Intellectual Property Law, the integrity of the work refers to preventing any distortion, modification, alteration or attack against it that damages its legitimate interests or damages its reputation.
Noticia
Spain once again stands out in the European open data landscape. The Open Data Maturity 2025 report places our country among the leaders in the opening and reuse of public sector information, consolidating an upward trajectory in digital innovation.
The report, produced annually by the European data portal, data.europa.eu, assesses the degree of maturity of open data in Europe. To do this, it analyzes several indicators, grouped into four dimensions: policy, portal, quality and impact. This year's edition has involved 36 countries, including the 27 Member States of the European Union (EU), three European Free Trade Association countries (Iceland, Norway and Switzerland) and six candidate countries (Albania, Bosnia and Herzegovina, Montenegro, North Macedonia, Serbia and Ukraine).
This year, Spain is in fifth position among the countries of the European Union and sixth out of the total number of countries analysed, tied with Italy. Specifically, a total score of 95.6% was obtained, well above the average of the countries analysed (81.1%). With this data, Spain improves its score compared to 2024, when it obtained 94.8%.
Spain, among the European leaders
With this position, Spain is once again among the countries that prescribe open data (trendsetters), i.e. those that set trends and serve as an example of good practices to other States. Spain shares a group with France, Lithuania, Poland, Ukraine, Ireland, the aforementioned Italy, Slovakia, Cyprus, Portugal, Estonia and the Czech Republic.
The countries in this group have advanced open data policies, aligned with the technical and political progress of the European Union, including the publication of high-value datasets. In addition, there is strong coordination of open data initiatives at all levels of government. Its national portals offer comprehensive features and quality metadata, with few limitations on publication or use. This means that published data can be more easily reused for multiple purposes, helping to generate a positive impact in different areas.
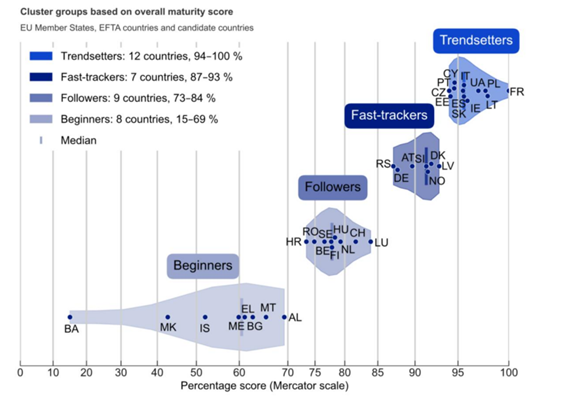
Figure 1. Member countries of the different clusters.
The keys to Spain's progress
According to the report, Spain strengthened its leadership in open data through strategic policy development, technical modernization, and reuse-driven innovation. In particular, improvements in the political sphere are what have boosted Spain's growth:
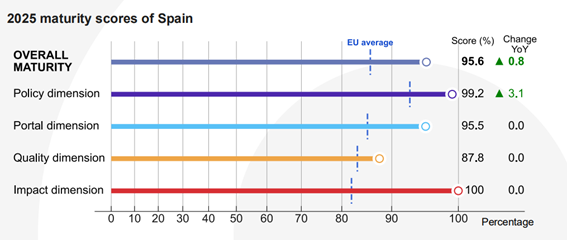
Figure 2. Spain's score in the different dimensions together with growth over the previous year.
As shown in the image, the political dimension has reached a score of 99.2% compared to 96% last year, standing out from the European average of 93.1%. The reason for this growth is the progress in the regulatory framework. In this regard, the report highlights the configuration of the V Open Government Plan, developed through a co-creation process in which all stakeholders participated. This plan has introduced new initiatives related to the governance and reuse of open data. Another noteworthy issue is that Spain promoted the publication of high-value datasets, in line with Implementing Regulation (EU) 2023/138.
The rest of the dimensions remain stable, all of them with scores above the European average: in the portal dimension, 95.5% has been obtained compared to 85.45% in Europe, while the quality dimension has been valued with 87.8% compared to 83.4% in the rest of the countries analysed. The Impact block continues to be our great asset, with 100% compared to 82.1% in Europe. In this dimension, we continue to position ourselves as great leaders, thanks to a clear definition of reuse, the systematic measurement of data use and the existence of examples of impact in the governmental, social, environmental and economic spheres.
Although there have not been major movements in the score of these dimensions, the report does highlight milestones in Spain in all areas. For example, the datos.gob.es platform underwent a major redesign, including adjustments to the DCAT-AP-ES metadata profile, in order to improve quality and interoperability. In this regard, a specific implementation guide was published and a learning and development community was consolidated through GitHub. In addition, the portal's search engine and monitoring tools were improved, including tracking external reuse through GitHub references and rich analytics through interactive dashboards.
The involvement of the infomediary sector has been key in strengthening Spain's leadership in open data. The report highlights the importance of activities such as the National Open Data Meeting, with challenges that are worked on jointly by a multidisciplinary team with representatives of public, private and academic institutions, edition after edition. In addition, the Spanish Federation of Municipalities and Provinces identified 80 essential data sets on which local governments should focus when advancing in the opening of information, promoting coherence and reuse at the municipal level.
The following image shows the specific score for each of the subdimensions analyzed:
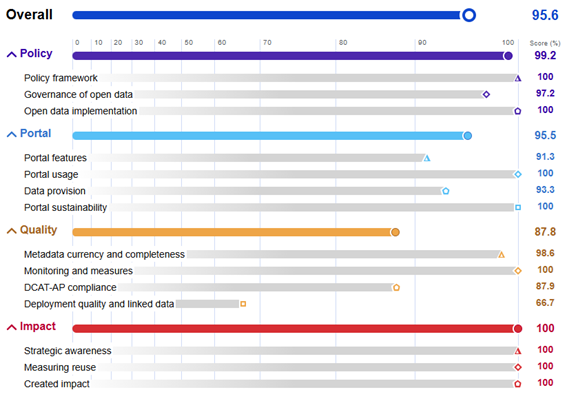
Figure 3. Spain's score in the different dimensions and subcategories.
You can see the details of the report for Spain on the website of the European portal.
Next steps and common challenges
The report concludes with a series of specific recommendations for each group of countries. For the group of trendsetters, in which Spain is located, the recommendations are not so much focused on reaching maturity – already achieved – but on deepening and expanding their role as European benchmarks. Some of the recommendations are:
- Consolidate thematic ecosystems (supplier and reuser communities) and prioritize high-value data in a systematic way.
- Align local action with the national strategy, enabling "data-driven" policies.
- Cooperate with data.europa.eu and other countries to implement and adapt an impact assessment framework with domain-by-domain metrics.
- Develop user profiles and allow their contributions to the national portal.
- Improve data and metadata quality and localization through validation tools, artificial intelligence, and user-centric flows.
- Apply domain-specific standards to harmonize datasets and maximize interoperability, quality, and reusability.
- Offer advanced and certified training in regulations and data literacy.
- Collaborate internationally on reusable solutions, such as shared or open source software.
Spain is already working on many of these points to continue improving its open data offer. The aim is for more and more reusers to be able to easily take advantage of the potential of public information to generate services and solutions that generate a positive impact on society as a whole.
The position achieved by Spain in this European ranking is the result of the work of all public initiatives, companies, user communities and reusers linked to open data, which promote an ecosystem that does not stop growing. Thank you for the effort!
Noticia
On 19 November, the European Commission presented the Data Union Strategy, a roadmap that seeks to consolidate a robust, secure and competitive European data ecosystem. This strategy is built around three key pillars: expanding access to quality data for artificial intelligence and innovation, simplifying the existing regulatory framework, and protecting European digital sovereignty. In this post, we will explain each of these pillars in detail, as well as the implementation timeline of the plan planned for the next two years.
Pillar 1: Expanding access to quality data for AI and innovation
The first pillar of the strategy focuses on ensuring that companies, researchers and public administrations have access to high-quality data that allows the development of innovative applications, especially in the field of artificial intelligence. To this end, the Commission proposes a number of interconnected initiatives ranging from the creation of infrastructure to the development of standards and technical enablers. A series of actions are established as part of this pillar: the expansion of common European data spaces, the development of data labs, the promotion of the Cloud and AI Development Act, the expansion of strategic data assets and the development of facilitators to implement these measures.
1.1 Extension of the Common European Data Spaces (ECSs)
Common European Data Spaces are one of the central elements of this strategy:
-
Planned investment: 100 million euros for its deployment.
-
Priority sectors: health, mobility, energy, (legal) public administration and environment.
-
Interoperability: SIMPL is committed to interoperability between data spaces with the support of the European Data Spaces Support Center (DSSC).
-
Key Applications:
-
European Health Data Space (EHDS): Special mention for its role as a bridge between health data systems and the development of AI.
-
New Defence Data Space: for the development of state-of-the-art systems, coordinated by the European Defence Agency.
-
1.2 Data Labs: the new ecosystem for connecting data and AI development
The strategy proposes to use Data Labs as points of connection between the development of artificial intelligence and European data.
These labs employ data pooling, a process of combining and sharing public and restricted data from multiple sources in a centralized repository or shared environment. All this facilitates access and use of information. Specifically, the services offered by Data Labs are:
-
Makes it easy to access data.
-
Technical infrastructure and tools.
-
Data pooling.
-
Data filtering and labeling
-
Regulatory guidance and training.
-
Bridging the gap between data spaces and AI ecosystems.
Implementation plan:
-
First phase: the first Data Labs will be established within the framework of AI Factories (AI gigafactories), offering data services to connect AI development with European data spaces.
-
Sectoral Data Labs: will be established independently in other areas to cover specific needs, for example, in the energy sector.
-
Self-sustaining model: It is envisaged that the Data Labs model can be deployed commercially, making it a self-sustaining ecosystem that connects data and AI.
1.3 Cloud and AI Development Act: boosting the sovereign cloud
To promote cloud technology, the Commission will propose this new regulation in the first quarter of 2026. There is currently an open public consultation in which you can participate here.
1.4 Strategic data assets: public sector, scientific, cultural and linguistic resources
On the one hand, in 2026 it will be proposed to expand the list of high-value data in English or HVDS to include legal, judicial and administrative data, among others. And on the other hand, the Commission will map existing bases and finance new digital infrastructure.
1.5 Horizontal enablers: synthetic data, data pooling, and standards
The European Commission will develop guidelines and standards on synthetic data and advanced R+D in techniques for its generation will be funded through Horizon Europe.
Another issue that the EU wants to promote is data pooling, as we explained above. Sharing data from early stages of the production cycle can generate collective benefits, but barriers persist due to legal uncertainty and fear of violating competition rules. Its purpose? Make data pooling a reliable and legally secure option to accelerate progress in critical sectors.
Finally, in terms of standardisation, the European standardisation organisations (CEN/CENELEC) will be asked to develop new technical standards in two key areas: data quality and labelling. These standards will make it possible to establish common criteria on how data should be to ensure its reliability and how it should be labelled to facilitate its identification and use in different contexts.
Pillar 2: Regulatory simplification
The second pillar addresses one of the challenges most highlighted by companies and organisations: the complexity of the European regulatory framework on data. The strategy proposes a series of measures aimed at simplifying and consolidating existing legislation.
2.1 Derogations and regulatory consolidation: towards a more coherent framework
The aim is to eliminate regulations whose functions are already covered by more recent legislation, thus avoiding duplication and contradictions. Firstly, the Free Flow of Non-Personal Data Regulation (FFoNPD) will be repealed, as its functions are now covered by the Data Act. However, the prohibition of unjustified data localisation, a fundamental principle for the Digital Single Market, will be explicitly preserved.
Similarly, the Data Governance Act (European Data Governance Regulation or DGA) will be eliminated as a stand-alone rule, migrating its essential provisions to the Data Act. This move simplifies the regulatory framework and also eases the administrative burden: obligations for data intermediaries will become lighter and more voluntary.
As for the public sector, the strategy proposes an important consolidation. The rules on public data sharing, currently dispersed between the DGA and the Open Data Directive, will be merged into a single chapter within the Data Act. This unification will facilitate both the application and the understanding of the legal framework by public administrations.
2.2 Cookie reform: balancing protection and usability
Another relevant detail is the regulation of cookies, which will undergo a significant modernization, being integrated into the framework of the General Data Protection Regulation (GDPR). The reform seeks a balance: on the one hand, low-risk uses that currently generate legal uncertainty will be legalized; on the other, consent banners will be simplified through "one-click" systems. The goal is clear: to reduce the so-called "user fatigue" in the face of the repetitive requests for consent that we all know when browsing the Internet.
2.3 Adjustments to the GDPR to facilitate AI development
The General Data Protection Regulation will also be subject to a targeted reform, specifically designed to release data responsibly for the benefit of the development of artificial intelligence. This surgical intervention addresses three specific aspects:
-
It clarifies when legitimate interest for AI model training may apply.
-
It defines more precisely the distinction between anonymised and pseudonymised data, especially in relation to the risk of re-identification.
-
It harmonises data protection impact assessments, facilitating their consistent application across the Union.
2. 4 Implementation and Support for the Data Act
The recently approved Data Act will be subject to adjustments to improve its application. On the one hand, the scope of business-to-government ( B2G) data sharing is refined, strictly limiting it to emergency situations. On the other hand, the umbrella of protection is extended: the favourable conditions currently enjoyed by small and medium-sized enterprises (SMEs) will also be extended to medium-sized companies or small mid-caps, those with between 250 and 749 employees.
To facilitate the practical implementation of the standard, a model contractual clause for data exchange has already been published , thus providing a template that organizations can use directly. In addition, two additional guides will be published during the first quarter of 2026: one on the concept of "reasonable compensation" in data exchanges, and another aimed at clarifying the key definitions of the Data Act that may generate interpretative doubts.
Aware that SMEs may struggle to navigate this new legal framework, a Legal Helpdesk will be set up in the fourth quarter of 2025. This helpdesk will provide direct advice on the implementation of the Data Act, giving priority precisely to small and medium-sized enterprises that lack specialised legal departments.
2.5 Evolving governance: towards a more coordinated ecosystem
The governance architecture of the European data ecosystem is also undergoing significant changes. The European Data Innovation Board (EDIB) evolves from a primarily advisory body to a forum for more technical and strategic discussions, bringing together both Member States and industry representatives. To this end, its articles will be modified with two objectives: to allow the inclusion of the competent authorities in the debates on Data Act, and to provide greater flexibility to the European Commission in the composition and operation of the body.
In addition, two additional mechanisms of feedback and anticipation are articulated. The Apply AI Alliance will channel sectoral feedback, collecting the specific experiences and needs of each industry. For its part, the AI Observatory will act as a trend radar, identifying emerging developments in the field of artificial intelligence and translating them into public policy recommendations. In this way, a virtuous circle is closed where politics is constantly nourished by the reality of the field.
Pillar 3: Protecting European data sovereignty
The third pillar focuses on ensuring that European data is treated fairly and securely, both inside and outside the Union's borders. The intention is that data will only be shared with countries with the same regulatory vision.
3.1 Specific measures to protect European data
-
Publication of guides to assess the fair treatment of EU data abroad (Q2 2026):
-
Publication of the Unfair Practices Toolbox (Q2 2026):
-
Unjustified location.
-
Exclusion.
-
Weak safeguards.
-
The data leak.
-
-
Taking measures to protect sensitive non-personal data.
All these measures are planned to be implemented from the last quarter of 2025 and throughout 2026 in a progressive deployment that will allow a gradual and coordinated adoption of the different measures, as established in the Data Union Strategy.
In short, the Data Union Strategy represents a comprehensive effort to consolidate European leadership in the data economy. To this end, data pooling and data spaces in the Member States will be promoted, Data Labs and AI gigafactories will be committed to and regulatory simplification will be encouraged.
Noticia
The European open data portal has published the third volume of its Use Case Observatory, a report that compiles the evolution of data reuse projects across Europe. This initiative highlights the progress made in four areas: economic, governmental, social and environmental impact.
The closure of a three-year investigation
Between 2022 and 2025, the European Open Data Portal has systematically monitored the evolution of various European projects. The research began with an initial selection of 30 representative initiatives, which were analyzed in depth to identify their potential for impact.
After two years, 13 projects continued in the study, including three Spanish ones: Planttes, Tangible Data and UniversiDATA-Lab. Its development over time was studied to understand how the reuse of open data can generate real and sustainable benefits.
The publication of volume III in October 2025 marks the closure of this series of reports, following volume I (2022) and volume II (2024). This last document offers a longitudinal view, showing how the projects have matured in three years of observation and what concrete impacts they have generated in their respective contexts.
Common conclusions
This third and final report compiles a number of key findings:
Economic impact
Open data drives growth and efficiency across industries. They contribute to job creation, both directly and indirectly, facilitate smarter recruitment processes and stimulate innovation in areas such as urban planning and digital services.
The report shows the example of:
- Naar Jobs (Belgium): an application for job search close to users' homes and focused on the available transport options.
This application demonstrates how open data can become a driver for regional employment and business development.
Government impact
The opening of data strengthens transparency, accountability and citizen participation.
Two use cases analysed belong to this field:
- Waar is mijn stemlokaal? (Netherlands): platform for the search for polling stations.
- Statsregnskapet.no (Norway): website to visualize government revenues and expenditures.
Both examples show how access to public information empowers citizens, enriches the work of the media, and supports evidence-based policymaking. All of this helps to strengthen democratic processes and trust in institutions.
Social impact
Open data promotes inclusion, collaboration, and well-being.
The following initiatives analysed belong to this field:
- UniversiDATA-Lab (Spain): university data repository that facilitates analytical applications.
- VisImE-360 (Italy): a tool to map visual impairment and guide health resources.
- Tangible Data (Spain): a company focused on making physical sculptures that turn data into accessible experiences.
- EU Twinnings (Netherlands): platform that compares European regions to find "twin cities"
- Open Food Facts (France): collaborative database on food products.
- Integreat (Germany): application that centralizes public information to support the integration of migrants.
All of them show how data-driven solutions can amplify the voice of vulnerable groups, improve health outcomes and open up new educational opportunities. Even the smallest effects, such as improvement in a single person's life, can prove significant and long-lasting.
Environmental impact
Open data acts as a powerful enabler of sustainability.
As with environmental impact, in this area we find a large number of use cases:
- Digital Forest Dryads (Estonia): a project that uses data to monitor forests and promote their conservation.
- Air Quality in Cyprus (Cyprus): platform that reports on air quality and supports environmental policies.
- Planttes (Spain): citizen science app that helps people with pollen allergies by tracking plant phenology.
- Environ-Mate (Ireland): a tool that promotes sustainable habits and ecological awareness.
These initiatives highlight how data reuse contributes to raising awareness, driving behavioural change and enabling targeted interventions to protect ecosystems and strengthen climate resilience.
Volume III also points to common challenges: the need for sustainable financing, the importance of combining institutional data with citizen-generated data, and the desirability of involving end-users throughout the project lifecycle. In addition, it underlines the importance of European collaboration and transnational interoperability to scale impact.
Overall, the report reinforces the relevance of continuing to invest in open data ecosystems as a key tool to address societal challenges and promote inclusive transformation.
The impact of Spanish projects on the reuse of open data
As we have mentioned, three of the use cases analysed in the Use Case Observatory have a Spanish stamp. These initiatives stand out for their ability to combine technological innovation with social and environmental impact, and highlight Spain 's relevance within the European open data ecosystem. His career demonstrates how our country actively contributes to transforming data into solutions that improve people's lives and reinforce sustainability and inclusion. Below, we zoom in on what the report says about them.
This citizen science initiative helps people with pollen allergies through real-time information about allergenic plants in bloom. Since its appearance in Volume I of the Use Case Observatory, it has evolved as a participatory platform in which users contribute photos and phenological data to create a personalized risk map. This participatory model has made it possible to maintain a constant flow of information validated by researchers and to offer increasingly complete maps. With more than 1,000 initial downloads and about 65,000 annual visitors to its website, it is a useful tool for people with allergies, educators and researchers.
The project has strengthened its digital presence, with increasing visibility thanks to the support of institutions such as the Autonomous University of Barcelona and the University of Granada, in addition to the promotion carried out by the company Thigis.
Its challenges include expanding geographical coverage beyond Catalonia and Granada and sustaining data participation and validation. Therefore, looking to the future, it seeks to extend its territorial reach, strengthen collaboration with schools and communities, integrate more data in real time and improve its predictive capabilities.
Throughout this time, Planttes has established herself as an example of how citizen-driven science can improve public health and environmental awareness, demonstrating the value of citizen science in environmental education, allergy management, and climate change monitoring.
The project transforms datasets into physical sculptures that represent global challenges such as climate change or poverty, integrating QR codes and NFC to contextualize the information. Recognized at the EU Open Data Days 2025, Tangible Data has inaugurated its installation Tangible climate at the National Museum of Natural Sciences in Madrid.
Tangible Data has evolved in three years from a prototype project based on 3D sculptures to visualize sustainability data to become an educational and cultural platform that connects open data with society. Volume III of the Use Case Observatory reflects its expansion into schools and museums, the creation of an educational program for 15-year-old students, and the development of interactive experiences with artificial intelligence, consolidating its commitment to accessibility and social impact.
Its challenges include funding and scaling up the education programme, while its future goals include scaling up school activities, displaying large-format sculptures in public spaces, and strengthening collaboration with artists and museums. Overall, it remains true to its mission of making data tangible, inclusive, and actionable.
UniversiDATA-Lab is a dynamic repository of analytical applications based on open data from Spanish universities, created in 2020 as a public-private collaboration and currently made up of six institutions. Its unified infrastructure facilitates the publication and reuse of data in standardized formats, reducing barriers and allowing students, researchers, companies and citizens to access useful information for education, research and decision-making.
Over the past three years, the project has grown from a prototype to a consolidated platform, with active applications such as the budget and retirement viewer, and a hiring viewer in beta. In addition, it organizes a periodic datathon that promotes innovation and projects with social impact.
Its challenges include internal resistance at some universities and the complex anonymization of sensitive data, although it has responded with robust protocols and a focus on transparency. Looking to the future, it seeks to expand its catalogue, add new universities and launch applications on emerging issues such as school dropouts, teacher diversity or sustainability, aspiring to become a European benchmark in the reuse of open data in higher education.
Conclusion
In conclusion, the third volume of the Use Case Observatory confirms that open data has established itself as a key tool to boost innovation, transparency and sustainability in Europe. The projects analysed – and in particular the Spanish initiatives Planttes, Tangible Data and UniversiDATA-Lab – demonstrate that the reuse of public information can translate into concrete benefits for citizens, education, research and the environment.
Noticia
Did you know that less than two out of ten European companies use artificial intelligence (AI) in their operations? This data, corresponding to 2024, reveals the margin for improvement in the adoption of this technology. To reverse this situation and take advantage of the transformative potential of AI, the European Union has designed a comprehensive strategic framework that combines investment in computing infrastructure, access to quality data and specific measures for key sectors such as health, mobility or energy.
In this article we explain the main European strategies in this area, with a special focus on the Apply AI Strategy or the AI Continent Action Plan , adopted this year in October and April respectively. In addition, we will tell you how these initiatives complement other European strategies to create a comprehensive innovation ecosystem.
Context: Action plan and strategic sectors
On the one hand, the AI Continent Action Plan establishes five strategic pillars:
- Computing infrastructures: scaling computing capacity through AI Factories, AI Gigafactories and the Cloud and AI Act, specifically:
- AI factories: infrastructures to train and improve artificial intelligence models will be promoted. This strategic axis has a budget of 10,000 million euros and is expected to lead to at least 13 AI factories by 2026.
- Gigafactorie AI: the infrastructures needed to train and develop complex AI models will also be taken into account, quadrupling the capacity of AI factories. In this case, 20,000 million euros are invested for the development of 5 gigafactories.
- Cloud and AI Act: Work is being done on a regulatory framework to boost research into highly sustainable infrastructure, encourage investments and triple the capacity of EU data centres over the next five to seven years.
- Access to quality data: facilitate access to robust and well-organized datasets through the so-called Data Labs in AI Factories.
- Talent and skills: strengthening AI skills across the population, specifically:
- Create international collaboration agreements.
- To offer scholarships in AI for the best students, researchers and professionals in the sector.
- Promote skills in these technologies through a specific academy.
- Test a specific degree in generative AI.
- Support training updating through the European Digital Innovation Hub.
- Development and adoption of algorithms: promoting the use of artificial intelligence in strategic sectors.
- Regulatory framework: Facilitate compliance with the AI Regulation in a simple and innovative way and provide free and adaptable tools for companies.
On the other hand, the recently presented, in October 2025, Apply AI Strategy seeks to boost the competitiveness of strategic sectors and strengthen the EU's technological sovereignty, driving AI adoption and innovation across Europe, particularly among small and medium-sized enterprises. How? The strategy promotes an "AI first" policy, which encourages organizations to consider artificial intelligence as a potential solution whenever they make strategic or policy decisions, carefully evaluating both the benefits and risks of the technology. In addition, it encourages a European procurement approach, i.e. organisations, particularly public administrations, prioritise solutions developed in Europe. Moreover, special importance is given to open source AI solutions, because they offer greater transparency and adaptability, less dependence on external providers and are aligned with the European values of openness and shared innovation.
The Apply AI Strategy is structured in three main sections:
Flagship sectoral initiatives
The strategy identifies 11 priority areas where AI can have the greatest impact and where Europe has competitive strengths:
- Healthcare and pharmaceuticals: AI-powered advanced European screening centres will be established to accelerate the introduction of innovative prevention and diagnostic tools, with a particular focus on cardiovascular diseases and cancer.
- Robotics: Adoption will be driven for the adoption of European robotics connecting developers and user industries, driving AI-powered robotics solutions.
- Manufacturing, engineering and construction: the development of cutting-edge AI models adapted to industry will be supported, facilitating the creation of digital twins and optimisation of production processes.
- Defence, security and space: the development of AI-enabled European situational awareness and control capabilities will be accelerated, as well as highly secure computing infrastructure for defence and space AI models.
- Mobility, transport and automotive: the "Autonomous Drive Ambition Cities" initiative will be launched to accelerate the deployment of autonomous vehicles in European cities.
- Electronic communications: a European AI platform for telecommunications will be created that will allow operators, suppliers and user industries to collaborate on the development of open source technological elements.
- Energy: the development of AI models will be supported to improve the forecasting, optimization and balance of the energy system.
- Climate and environment: An open-source AI model of the Earth system and related applications will be deployed to enable better weather forecasting, Earth monitoring, and what-if scenarios.
- Agri-food: the creation of an agri-food AI platform will be promoted to facilitate the adoption of agricultural tools enabled by this technology.
- Cultural and creative sectors, and media: the development of micro-studios specialising in AI-enhanced virtual production and pan-European platforms using multilingual AI technologies will be incentivised.
- Public sector: A dedicated AI toolkit for public administrations will be built with a shared repository of good practices, open source and reusable, and the adoption of scalable generative AI solutions will be accelerated.
Cross-cutting support measures
For the adoption of artificial intelligence to be effective, the strategy addresses challenges common to all sectors, specifically:
- Opportunities for European SMEs: The more than 250 European Digital Innovation Hubs have been transformed into AI Centres of Expertise. These centres act as privileged access points to the European AI innovation ecosystem, connecting companies with AI Factories, data labs and testing facilities.
- AI-ready workforce: Access to practical AI literacy training, tailored to sectors and professional profiles, will be provided through the AI Skills Academy.
- Supporting the development of advanced AI: The Frontier AI Initiative seeks to accelerate progress on cutting-edge AI capabilities in Europe. Through this project, competitions will be created to develop advanced open-source artificial intelligence models, which will be available to public administrations, the scientific community and the European business sector.
- Trust in the European market: Disclosure will be strengthened to ensure compliance with the European Union's AI Regulation, providing guidance on the classification of high-risk systems and on the interaction of the Regulation with other sectoral legislation.
New governance system
In this context, it is particularly important to ensure proper coordination of the strategy. Therefore, the following is proposed:
- Apply AI Alliance: The existing AI Alliance becomes the premier coordination forum that brings together AI vendors, industry leaders, academia, and the public sector. Sector-specific groups will allow the implementation of the strategy to be discussed and monitored.
- AI Observatory: An AI Observatory will be established to provide robust indicators assessing its impact on currently listed and future sectors, monitor developments and trends.
Complementary strategies: science and data as the main axes
The Apply AI Strategy does not act in isolation, but is complemented by two other fundamental strategies: the AI in Science Strategy and the Data Union Strategy.
AI in Science Strategy
Presented together with the Apply AI Strategy, this strategy supports and incentivises the development and use of artificial intelligence by the European scientific community. Its central element is RAISE (Resource for AI Science in Europe), which was presented in November at the AI in Science Summit and will bring together strategic resources: funding, computing capacity, data and talent. RAISE will operate on two pillars: Science for AI (basic research to advance fundamental capabilities) and AI in Science (use of artificial intelligence for progress in different scientific disciplines).
Data Union Strategy
This strategy will focus on ensuring the availability of high-quality, large-scale datasets, essential for training AI models. A key element will be the Data Labs associated with the AI Factories, which will bring together and federate data from different sectors, linking with the corresponding European Common Data Spaces, making them available to developers under the appropriate conditions.
In short, through significant investments in infrastructure, access to quality data, talent development and a regulatory framework that promotes responsible innovation, the European Union is creating the necessary conditions for companies, public administrations and citizens to take advantage of the full transformative potential of artificial intelligence. The success of these strategies will depend on collaboration between European institutions, national governments, businesses, researchers and developers.